前言
想象一下这个场景:你想训练一架四旋翼无人机在茂密的森林里高速穿梭避障。如果用纯强化学习(RL),它可能会在学会正确飞行之前先撞坏100架无人机------毕竟对于这种不稳定的系统,一个微小的错误就会导致灾难性的炸机。如果用纯模型预测控制(MPC),它需要精确的全局位置估计和实时的轨迹优化,在没有GPS的复杂环境下根本无法工作。
这就是2016年伯克利团队提出MPC-Guided Policy Search(MPC-GPS)时要解决的核心问题。他们创造性地将MPC的安全性和RL的灵活性结合起来:训练时用MPC在有全状态观测的环境中生成安全的专家数据,测试时用一个只需要原始传感器输入的深度神经网络来控制无人机。这个方法不仅彻底解决了训练时的炸机问题,还让最终的控制策略比MPC快100倍以上。
论文信息
- 标题:Learning Deep Control Policies for Autonomous Aerial Vehicles with MPC-Guided Policy Search
- 会议:ICRA 2016
- 单位:加州大学伯克利分校
- 代码:github.com/your-username/mpc-guided-policy-search (现代PyTorch实现)
- 论文:https://arxiv.org/pdf/1509.06791
一、为什么我们需要MPC引导的策略搜索?
在机器人控制领域,MPC和RL是两种最主流的方法,但它们各自有着致命的缺点:
1.1 模型预测控制(MPC)的优缺点
优点:
- 非常稳定,对中等程度的模型误差有很好的鲁棒性
- 可以直接处理约束条件(比如最大速度、最小安全距离)
- 不需要大量的真实世界数据
缺点:
- 计算量极大,尤其是对于高维系统和长预测 horizon
- 必须知道系统的完整状态(位置、速度、姿态等),这在复杂环境中很难获得
- 难以直接处理原始传感器数据(比如激光雷达、摄像头)
1.2 强化学习(RL)的优缺点
优点:
- 可以直接学习从原始传感器到动作的映射,不需要显式的状态估计
- 一旦训练完成,推理速度极快
- 可以处理复杂的、难以建模的环境
缺点:
- 训练过程极其危险,对于无人机这种不稳定系统,部分训练的策略几乎肯定会导致炸机
- 样本效率极低,需要大量的真实世界交互
- 训练过程不稳定,容易发散
1.3 引导策略搜索(GPS):两全其美的方案
引导策略搜索是一种介于MPC和RL之间的方法,它将RL问题转化为监督学习问题:
- 用一个最优控制算法(比如DDP、iLQG)生成专家轨迹
- 用这些轨迹作为监督数据训练一个神经网络策略
- 交替进行这两个步骤,直到收敛
但传统的GPS使用离线轨迹优化,当模型不准确时,生成的轨迹在真实系统上执行时仍然会导致失败。这就是为什么作者们提出用在线MPC来代替离线轨迹优化------MPC可以在每一步重新规划轨迹,对模型误差有更强的鲁棒性。
二、核心思想:让MPC当老师,神经网络当学生
MPC-GPS的核心思想非常简单:让安全可靠的MPC当老师,教灵活高效的神经网络当学生。整个过程分为两个完全分离的阶段:
2.1 训练阶段:MPC老师教学生
在训练阶段,我们有一个"仪器化"的环境,可以获得系统的完整状态(比如用运动捕捉系统)。我们交替执行以下两个步骤:
- MPC生成数据:运行MPC控制器,让无人机完成任务,同时记录下所有的状态、观测和动作
- 监督学习训练:用MPC生成的数据训练一个神经网络,让它学会只根据原始传感器观测来预测MPC会选择的动作
这个过程的关键在于:在整个训练过程中,无人机的动作永远是由MPC选择的,而不是由部分训练的神经网络选择的。这就从根本上避免了训练时的灾难性失败。
2.2 测试阶段:神经网络学生独立工作
训练完成后,我们就可以完全抛弃MPC控制器了。此时的神经网络已经学会了如何只根据原始传感器输入来控制无人机,它:
- 不需要任何状态估计
- 推理速度比MPC快100倍以上
- 可以泛化到训练中没有见过的新环境
整个方法的流程如下图所示:
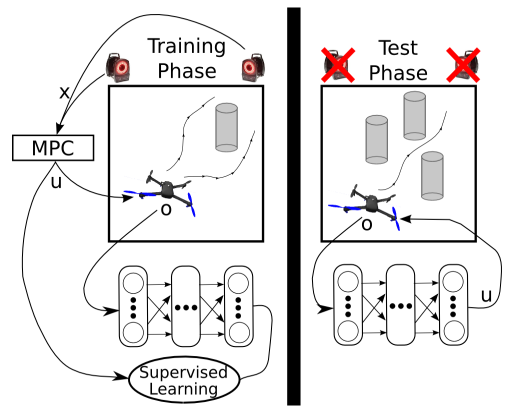
图1:MPC引导的策略搜索方法流程图(出处:原文Figure 1)
通俗解释:这就像你学开车。训练时,教练(MPC)坐在副驾驶,随时准备踩刹车,并且告诉你在每个情况下应该怎么做。你(神经网络)只需要观察路况(原始传感器),然后模仿教练的操作。当你学得足够好之后,教练就可以下车了,你自己就能安全地开车了。
三、数学原理:从策略搜索到MPC-GPS
3.1 策略搜索的基本问题
策略搜索的目标是找到一个策略πθ(ut∣ot)\pi_\theta(u_t | o_t)πθ(ut∣ot),最小化期望代价:
minθEπθ∑t=1Tℓ(xt,ut)\min_{\theta} \mathbb{E}{\pi\theta} \left \\sum_{t=1}\^{T} \\ell(x_t, u_t) \\rightθminEπθt=1∑Tℓ(xt,ut)
其中:
- θ\thetaθ:神经网络策略的参数
- xtx_txt:系统在时间t的完整状态(位置、速度、姿态等)
- oto_tot:系统在时间t的观测(激光雷达、IMU等)
- utu_tut:系统在时间t的动作(四个旋翼的转速)
- ℓ(xt,ut)\ell(x_t, u_t)ℓ(xt,ut):代价函数,定义了任务目标(比如离目标的距离、碰撞惩罚等)
- TTT:轨迹的长度
- Eπθ\mathbb{E}{\pi\theta}Eπθ:对由策略πθ\pi_\thetaπθ产生的轨迹分布求期望
3.2 引导策略搜索的约束优化
引导策略搜索将这个问题转化为一个约束优化问题:
minθ,pEτ∼pℓ(τ)\min_{\theta, p} \mathbb{E}{\tau \sim p} \\ell(\\tau)θ,pminEτ∼pℓ(τ)
s.t. p(ut∣xt)=πθ(ut∣xt)∀t\text{s.t. } p(u_t | x_t) = \pi\theta(u_t | x_t) \quad \forall ts.t. p(ut∣xt)=πθ(ut∣xt)∀t
其中:
- p(τ)p(\tau)p(τ):引导轨迹分布,由最优控制算法生成
- πθ(ut∣xt)\pi_\theta(u_t | x_t)πθ(ut∣xt):策略在状态xtx_txt下的动作分布
- 约束条件要求引导分布和策略分布在所有状态下都一致
这个约束优化问题可以通过交替优化来求解:
- 固定策略πθ\pi_\thetaπθ,优化引导分布p(τ)p(\tau)p(τ)
- 固定引导分布p(τ)p(\tau)p(τ),优化策略πθ\pi_\thetaπθ
3.3 带KL散度惩罚的轨迹优化
为了让引导分布和策略分布保持一致,我们在轨迹优化的目标函数中加入一个KL散度惩罚项:
minpi(τ)∑t=1TEpi(xt,ut)ℓ(xt,ut)−utTλμti+νtiDKL(pi(ut∣xt)∥πθ(ut∣xt))\begin{aligned} \min_{p_i(\tau)} \sum_{t=1}^{T} \mathbb{E}_{p_i(x_t, u_t)} \Bigg \& \\ell(x_t, u_t) - u_t\^T \\lambda_{\\mu t}\^i \\\\ \& + \\nu_t\^i D_{KL}\\left( p_i(u_t \| x_t) \\parallel \\pi_\\theta(u_t \| x_t) \\right) \\Bigg \end{aligned}pi(τ)mint=1∑TEpi(xt,ut)ℓ(xt,ut)−utTλμti+νtiDKL(pi(ut∣xt)∥πθ(ut∣xt))
其中:
- λμti\lambda_{\mu t}^iλμti和νti\nu_t^iνti:拉格朗日乘子,用于调整约束的强度
- DKL(p∥q)D_{KL}(p \parallel q)DKL(p∥q):KL散度,衡量两个概率分布之间的"距离"
- πθ(ut∣xt)\pi_\theta(u_t | x_t)πθ(ut∣xt):当前神经网络策略在状态xtx_txt下的动作分布
通俗解释:KL散度惩罚项就像一个"缰绳",它不让MPC生成的动作和当前神经网络的动作差太远。如果没有这个缰绳,MPC可能会生成一些神经网络永远学不会的动作,导致训练无法收敛。
3.4 基于iLQG的MPC实现
作者们使用了一种叫做迭代线性二次调节器(iLQG)的算法来实现MPC。iLQG通过对动力学和代价函数进行局部线性-二次近似,然后递归求解最优控制问题。
iLQG的核心递推公式如下:
Qxu,xut=ℓxu,xut+fxutTVx,xt+1fxutQ_{xu,xut} = \ell_{xu,xut} + f_{xut}^T V_{x,xt+1} f_{xut}Qxu,xut=ℓxu,xut+fxutTVx,xt+1fxut
Qxut=ℓxut+fxutTVxt+1Q_{xut} = \ell_{xut} + f_{xut}^T V_{xt+1}Qxut=ℓxut+fxutTVxt+1
Vx,xt=Qx,xt−Qu,xtTQu,ut−1Qu,xtV_{x,xt} = Q_{x,xt} - Q_{u,xt}^T Q_{u,ut}^{-1} Q_{u,xt}Vx,xt=Qx,xt−Qu,xtTQu,ut−1Qu,xt
Vxt=Qxt−Qu,xtTQu,ut−1QutV_{xt} = Q_{xt} - Q_{u,xt}^T Q_{u,ut}^{-1} Q_{ut}Vxt=Qxt−Qu,xtTQu,ut−1Qut
其中:
- Qxu,xutQ_{xu,xut}Qxu,xut:Q函数关于状态和动作的Hessian矩阵
- QxutQ_{xut}Qxut:Q函数关于状态和动作的梯度
- Vx,xtV_{x,xt}Vx,xt:值函数关于状态的Hessian矩阵
- VxtV_{xt}Vxt:值函数关于状态的梯度
- fxutf_{xut}fxut:动力学函数关于状态和动作的雅可比矩阵
- ℓxu,xut\ell_{xu,xut}ℓxu,xut:代价函数关于状态和动作的Hessian矩阵
- ℓxut\ell_{xut}ℓxut:代价函数关于状态和动作的梯度
通过这些递推公式,我们可以得到最优控制律:
g(xt)=u^t+kt+Kt(xt−x^t)g(x_t) = \hat{u}_t + k_t + K_t (x_t - \hat{x}_t)g(xt)=u^t+kt+Kt(xt−x^t)
其中:
- Kt=−Qu,ut−1Qu,xtK_t = -Q_{u,ut}^{-1} Q_{u,xt}Kt=−Qu,ut−1Qu,xt:反馈增益矩阵
- kt=−Qu,ut−1Qutk_t = -Q_{u,ut}^{-1} Q_{ut}kt=−Qu,ut−1Qut:前馈控制项
- x^t\hat{x}_tx^t和u^t\hat{u}_tu^t:名义轨迹上的状态和动作
3.5 代替代价函数:让MPC生成好的训练数据
为了让MPC生成的轨迹更适合训练神经网络,作者们设计了一个巧妙的代替代价函数:
ℓ~(xt′,ut′)=−logpi(xt′∣xt)−νt′ilogπθ(ut′∣xt′)−ut′Tλμt′i\tilde{\ell}(x_{t'}, u_{t'}) = -\log p_i(x_{t'} | x_t) - \nu_{t'}^i \log \pi_\theta(u_{t'} | x_{t'}) - u_{t'}^T \lambda_{\mu t'}^iℓ~(xt′,ut′)=−logpi(xt′∣xt)−νt′ilogπθ(ut′∣xt′)−ut′Tλμt′i
其中:
- pi(xt′∣xt)p_i(x_{t'} | x_t)pi(xt′∣xt):离线iLQG解预测的在时间t'处于状态xt′x_{t'}xt′的概率
- πθ(ut′∣xt′)\pi_\theta(u_{t'} | x_{t'})πθ(ut′∣xt′):当前神经网络策略在状态xt′x_{t'}xt′下的动作概率
这个代替代价函数有三个作用:
- 鼓励MPC访问离线iLQG解认为重要的状态
- 鼓励MPC生成和当前神经网络策略相似的动作
- 保证生成的轨迹有好的长期行为
四、算法实现:从理论到代码
4.1 完整算法流程
MPC引导的策略搜索的完整算法流程如下:
算法1:MPC引导的策略搜索
- 初始化神经网络策略πθ\pi_\thetaπθ
- 对于每次迭代k = 1到K:
3. 使用离线iLQG优化引导轨迹分布pi(τ)p_i(\tau)pi(τ),目标函数为式(3)
4. 对于每个初始状态x1∼pi(x1)x_1 \sim p_i(x_1)x1∼pi(x1):
5. 运行MPC M次,每次使用代替代价函数式(4)
6. 记录所有的轨迹τij\tau_{ij}τij和对应的MPC控制器p~ij(τ)\tilde{p}{ij}(\tau)p~ij(τ)
7. 使用监督学习训练神经网络策略πθ\pi\thetaπθ,目标函数为式(2)
8. 使用最新的样本拟合一个时变线性高斯模型来估计πθ(ut∣xt)\pi_\theta(u_t | x_t)πθ(ut∣xt)
9. 更新拉格朗日乘子νti\nu_t^iνti和λμti\lambda_{\mu t}^iλμti - 返回优化后的神经网络策略πθ\pi_\thetaπθ
4.2 核心代码实现
下面是一个简化的PyTorch实现,包含了iLQG MPC和神经网络策略训练的核心部分:
python
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class QuadrotorDynamics:
"""四旋翼动力学模型"""
def __init__(self, dt=0.05):
self.dt = dt
self.mass = 1.5 # kg
self.g = 9.81 # m/s^2
def forward(self, x, u):
"""
前向传播计算下一个状态
x: [p, v, q, omega] 13维状态向量
u: 4维旋翼转速向量
"""
p = x[:3]
v = x[3:6]
q = x[6:10]
omega = x[10:13]
# 简化的动力学模型
thrust = torch.sum(u) * torch.tensor([0, 0, 1.0])
acceleration = thrust / self.mass - torch.tensor([0, 0, self.g])
# 欧拉积分
p_next = p + v * self.dt
v_next = v + acceleration * self.dt
q_next = q # 简化:忽略姿态变化
omega_next = omega # 简化:忽略角速度变化
return torch.cat([p_next, v_next, q_next, omega_next])
class iLQG:
"""迭代线性二次调节器"""
def __init__(self, dynamics, cost_fn, horizon=20):
self.dynamics = dynamics
self.cost_fn = cost_fn
self.horizon = horizon
def backward_pass(self, x_nom, u_nom):
"""执行反向传播计算控制增益"""
T = len(u_nom)
Vx = torch.zeros(13)
Vxx = torch.zeros(13, 13)
k = torch.zeros(T, 4)
K = torch.zeros(T, 4, 13)
# 从最后一步开始反向传播
for t in reversed(range(T)):
x = x_nom[t]
u = u_nom[t]
# 计算代价函数的梯度和Hessian
l, lx, lu, lxx, luu, lux = self.cost_fn(x, u)
# 计算动力学的雅可比矩阵
fx = torch.autograd.functional.jacobian(lambda x: self.dynamics(x, u), x)
fu = torch.autograd.functional.jacobian(lambda u: self.dynamics(x, u), u)
# 计算Q函数的梯度和Hessian
Qx = lx + fx.T @ Vx
Qu = lu + fu.T @ Vx
Qxx = lxx + fx.T @ Vxx @ fx
Quu = luu + fu.T @ Vxx @ fu
Qux = lux + fu.T @ Vxx @ fx
# 计算控制增益
Quu_inv = torch.inverse(Quu + 1e-6 * torch.eye(4))
k[t] = -Quu_inv @ Qu
K[t] = -Quu_inv @ Qux
# 更新值函数的梯度和Hessian
Vx = Qx + K[t].T @ Quu @ k[t] + K[t].T @ Qu + Qux.T @ k[t]
Vxx = Qxx + K[t].T @ Quu @ K[t] + K[t].T @ Qux + Qux.T @ K[t]
return k, K
def forward_pass(self, x0, k, K, x_nom, u_nom):
"""执行前向传播生成新的轨迹"""
T = len(k)
x = [x0]
u = []
for t in range(T):
delta_x = x[t] - x_nom[t]
ut = u_nom[t] + k[t] + K[t] @ delta_x
u.append(ut)
x.append(self.dynamics(x[t], ut))
return x[:-1], u
class NeuralNetworkPolicy(nn.Module):
"""神经网络策略"""
def __init__(self, obs_dim=40, action_dim=4, hidden_dim=40):
super().__init__()
self.net = nn.Sequential(
nn.Linear(obs_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, action_dim)
)
def forward(self, obs):
return self.net(obs)
def train_mpc_gps():
"""训练MPC引导的策略搜索"""
# 初始化组件
dynamics = QuadrotorDynamics()
cost_fn = lambda x, u: (torch.sum((x[:3] - torch.tensor([10.0, 0.0, 2.0]))**2) +
0.5 * torch.sum(u**2))
ilqg = iLQG(dynamics, cost_fn)
policy = NeuralNetworkPolicy()
optimizer = optim.Adam(policy.parameters(), lr=1e-3)
# 训练循环
for iteration in range(5):
# 步骤1:离线iLQG优化
x0 = torch.tensor([0.0, 0.0, 2.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])
x_nom, u_nom = [x0], [torch.zeros(4) for _ in range(150)]
for _ in range(10):
k, K = ilqg.backward_pass(x_nom, u_nom)
x_nom, u_nom = ilqg.forward_pass(x0, k, K, x_nom, u_nom)
# 步骤2:MPC生成训练数据
observations = []
actions = []
for _ in range(4):
x = x0
for t in range(150):
# 运行MPC选择动作
k, K = ilqg.backward_pass(x_nom[t:t+20], u_nom[t:t+20])
delta_x = x - x_nom[t]
u = u_nom[t] + k[0] + K[0] @ delta_x
# 生成观测(模拟激光雷达)
obs = torch.cat([torch.randn(30), x[3:6], x[6:10], x[10:13]])
observations.append(obs)
actions.append(u)
# 执行动作
x = dynamics(x, u)
# 步骤3:监督学习训练神经网络
observations = torch.stack(observations)
actions = torch.stack(actions)
for _ in range(20000):
optimizer.zero_grad()
pred_actions = policy(observations)
loss = nn.MSELoss()(pred_actions, actions)
loss.backward()
optimizer.step()
print(f"Iteration {iteration+1}, Loss: {loss.item():.4f}")
return policy
# 训练模型
policy = train_mpc_gps()五、实验结果:用数据说话
作者们在两个具有挑战性的模拟四旋翼任务上评估了他们的方法:单圆柱避障和走廊飞行。
5.1 实验设置
- 四旋翼模型:基于3DR IRIS+建模,重1.5kg,宽0.47m
- 观测模型:30个激光雷达测距仪,180度视场,最大量程5m
- 状态空间:13维(位置、速度、四元数姿态、角速度)
- 动作空间:4维(四个旋翼的转速)
- 神经网络策略:两个隐藏层,每层40个ReLU单元
实验环境如下图所示:
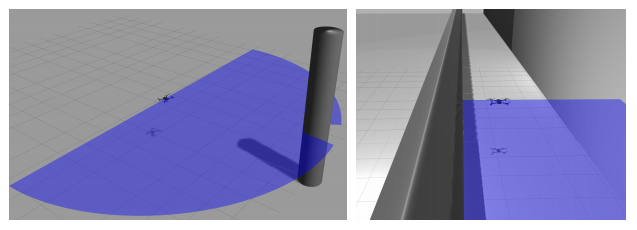
图2:两个实验环境:单圆柱避障和走廊飞行(出处:原文Figure 2)
图中蓝色的半圆表示无人机上激光雷达的探测范围。注意,无人机在测试时不知道自己的位置,只能通过激光雷达的读数来感知环境。
5.2 对比方法
作者们对比了三种不同的方法:
- 离线iLQG:直接使用离线优化得到的线性高斯控制器
- MPC原始代价:使用原始任务代价函数的MPC引导的策略搜索
- MPC代替代价:使用本文提出的代替代价函数的MPC引导的策略搜索
5.3 实验结果
实验结果如下表所示:
| 方法 | 模型误差类型 | 训练崩溃次数 | 平均测试飞行时间(秒) |
|---|---|---|---|
| 离线iLQG | 无误差 | 0 | 46.2 ± 28.4 |
| MPC原始代价 | 无误差 | 0 | 35.2 ± 13.3 |
| MPC代替代价 | 无误差 | 0 | 35.2 ± 20.0 |
| 离线iLQG | 0.05kg质量误差 | 0 | 21.7 ± 5.8 |
| MPC原始代价 | 0.05kg质量误差 | 0 | 15.7 ± 1.3 |
| MPC代替代价 | 0.05kg质量误差 | 0 | 31.8 ± 15.7 |
| 离线iLQG | 8%旋翼偏置 | 76 | 26.0 ± 21.1 |
| MPC原始代价 | 8%旋翼偏置 | 0 | 51.1 ± 28.6 |
| MPC代替代价 | 8%旋翼偏置 | 0 | 28.5 ± 16.2 |
| 离线iLQG | 严重参数扰动 | N/A | N/A |
| MPC原始代价 | 严重参数扰动 | 0 | 9.9 ± 4.2 |
| MPC代替代价 | 严重参数扰动 | 0 | 55.2 ± 17.5 |
表1:不同方法在不同模型误差下的性能对比(出处:原文Table I)
5.4 结果分析
从实验结果可以得出几个非常重要的结论:
- MPC完全避免了训练崩溃:在所有情况下,使用MPC的方法都没有发生任何训练崩溃,而离线iLQG在有8%旋翼偏置时发生了76次崩溃,在严重参数扰动时甚至无法完成训练。
- 代替代价函数显著提高了鲁棒性:在有模型误差的情况下,使用代替代价函数的MPC-GPS方法表现最好。尤其是在严重参数扰动时,它的平均飞行时间达到了55.2秒,是MPC原始代价方法的5倍以上。
- 泛化能力出色:训练在单个圆柱上的策略可以在随机生成的无限森林中连续飞行几十秒,训练在直走廊上的策略可以在有随机转弯的蜿蜒走廊中飞行。这说明神经网络真的学会了通用的避障能力,而不是死记硬背训练轨迹。
六、讨论与未来工作
6.1 方法的核心优势
MPC引导的策略搜索有三个无可替代的优势:
- 绝对安全的训练过程:在整个训练过程中,无人机的动作永远由MPC选择,永远不会发生炸机
- 无需测试时状态估计:最终的神经网络策略只需要原始传感器输入,不需要任何状态估计
- 极高的推理效率:神经网络的推理速度比MPC快100倍以上,可以在资源有限的嵌入式设备上运行
6.2 方法的局限性
这个方法也有一些局限性:
- 训练时需要全状态观测:在训练阶段,我们需要知道系统的完整状态(比如用运动捕捉系统)。这限制了它在一些无法安装动捕系统的环境中的应用。
- 依赖一个近似的动力学模型:虽然MPC对模型误差有一定的鲁棒性,但如果模型误差太大,MPC本身也会失败。
6.3 未来工作方向
作者们提出了几个有前景的未来工作方向:
- 结合状态估计:将状态估计和引导策略搜索结合起来,消除对训练时全状态观测的依赖
- 使用更先进的MPC方法:比如混合整数MPC,可以更好地处理离散障碍物
- 扩展到更复杂的传感器:比如摄像头,让无人机可以直接从视觉输入中学习控制策略
总结
MPC引导的策略搜索是机器人控制领域的一个里程碑式的工作。它创造性地将MPC的安全性和RL的灵活性结合起来,解决了长期以来困扰强化学习在不稳定系统上应用的"训练炸机"问题。
这篇论文给我们最大的启示是:我们不需要在模型和数据之间做非此即彼的选择。我们可以利用模型在训练时提供安全的指导,然后用数据训练一个灵活高效的策略来处理复杂的真实世界。
今天,MPC-GPS的思想已经被广泛应用于各种机器人系统,从四旋翼无人机到机械臂,再到自动驾驶汽车。它证明了,当我们把最优控制和深度学习巧妙地结合起来时,我们可以得到两者的优点,而避免它们的缺点。