引言:为什么要学习 CNN 和 RNN?
在深度学习的世界里,有两大神经网络架构堪称基石------卷积神经网络 (CNN)和循环神经网络 (RNN)。它们分别统治着计算机视觉和自然语言处理两大领域,是每一位 AI 入门者必须掌握的核心技术。
-
CNN让计算机看懂图像:从手机的面部解锁,到自动驾驶的目标检测,再到医学影像的智能诊断
-
RNN让计算机理解语言:从 ChatGPT 的对话生成,到机器翻译,再到语音识别
本文将用通俗易懂的方式,配合精心绘制的示意图,带你从零开始掌握这两大神经网络的核心原理。
第一部分:卷积神经网络 (CNN)
1.1 图像基础:计算机如何看图片?
在深入 CNN 之前,我们首先要理解:计算机眼中的图片是什么样子的?
三个基本概念:高、宽、通道
每张图片都可以用三个维度来描述:
-
Height (高):图片的垂直像素数,单位是像素
-
Width (宽):图片的水平像素数,单位是像素
-
Channel (通道):颜色信息的维度
关于颜色的小知识:
-
0 代表黑色,255 代表白色
-
RGB 图像有 3 个通道:红 (Red)、绿 (Green)、蓝 (Blue)
-
每个通道的取值范围都是 0-255
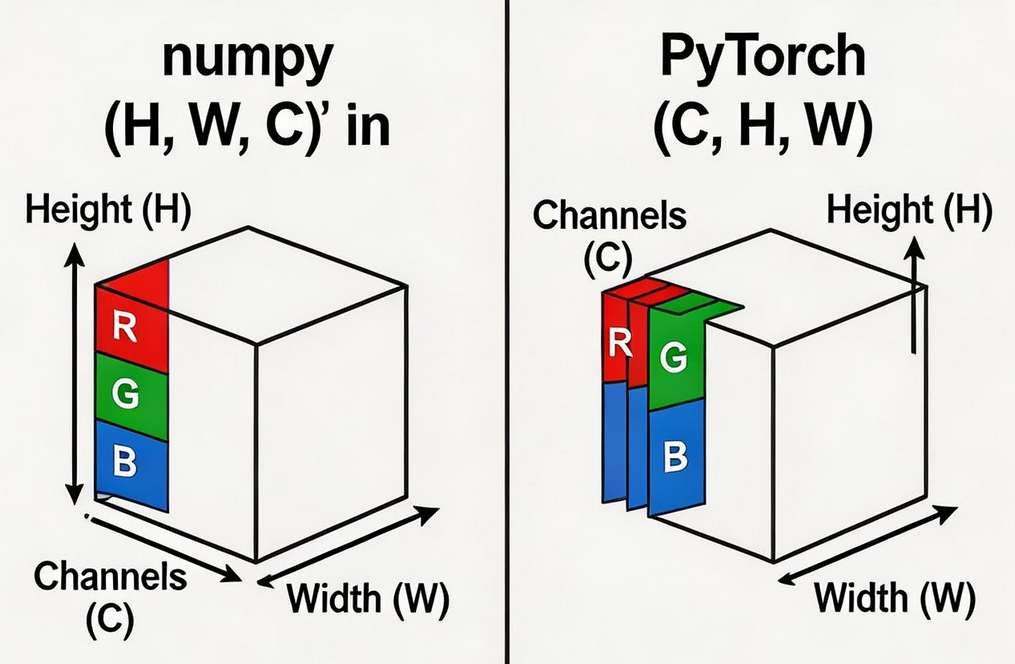
numpy vs PyTorch:数据格式的差异
这是新手最容易踩坑的地方!不同框架存储图片的顺序不一样:
-
numpy 格式 :
(H, W, C)- 通道在最后一维- 例如:一张 224×224 的 RGB 图片 →
(224, 224, 3)
- 例如:一张 224×224 的 RGB 图片 →
-
PyTorch 格式 :
(C, H, W)- 通道在第一维- 例如:一张 224×224 的 RGB 图片 →
(3, 224, 224)
- 例如:一张 224×224 的 RGB 图片 →
💡 记住这个区别:在 PyTorch 中做图像处理时,一定要记得把 numpy 的 (H,W,C) 转成 (C,H,W)!
图像的四种类型
| 图像类型 | 通道数 | 取值范围 | 说明 |
|---|---|---|---|
| 二值图像 | 1 | 0/1 | 只有黑白两种颜色 |
| 灰度图像 | 1 | 0-255 | 从黑到白的 256 级灰度 |
| 索引图像 | 1 | 索引值 | 存储索引,通过颜色表查找 RGB |
| RGB 图像 | 3 | 0-255 | 真彩色图像,红 + 绿 + 蓝三通道 |
图像处理三大 API
python
# 读取图片:将图片文件转为像素矩阵
image = cv2.imread("cat.jpg") # 返回numpy数组 (H, W, C)
# 显示图片:根据像素矩阵绘制图像
cv2.imshow("image", image)
# 保存图片:将像素矩阵保存为文件
cv2.imwrite("output.jpg", image)1.2 CNN 是什么?
卷积神经网络 (Convolutional Neural Network, CNN) 是一种专门用于处理网格结构数据(如图像)的神经网络。
CNN 的四大组成部分
-
输入层:接收图像、视频、音频频谱图等数据
-
卷积层:提取图像特征图(核心!)
-
池化层:降低特征图维度,减少计算量
-
输出层:输出最终预测结果(分类、检测等)
CNN 的典型应用场景
-
✅ 图像分类:识别猫 / 狗 / 汽车
-
✅ 目标检测:在图中框出人和物体
-
✅ 面部解锁:手机人脸识别
-
✅ 自动驾驶:道路和交通标志识别
-
✅ 医学影像:CT/MRI 病灶检测
1.3 卷积层:特征提取的核心
卷积层是 CNN 的灵魂,它的作用是自动提取图像的特征。
什么是卷积核 / 滤波器?
卷积核(也叫滤波器)可以理解为带有共享参数的神经元。一个 3×3 的卷积核就是 9 个可学习的参数。
有多少个卷积核,就相当于有多少个神经元,每个神经元负责提取一种特征。
卷积计算过程
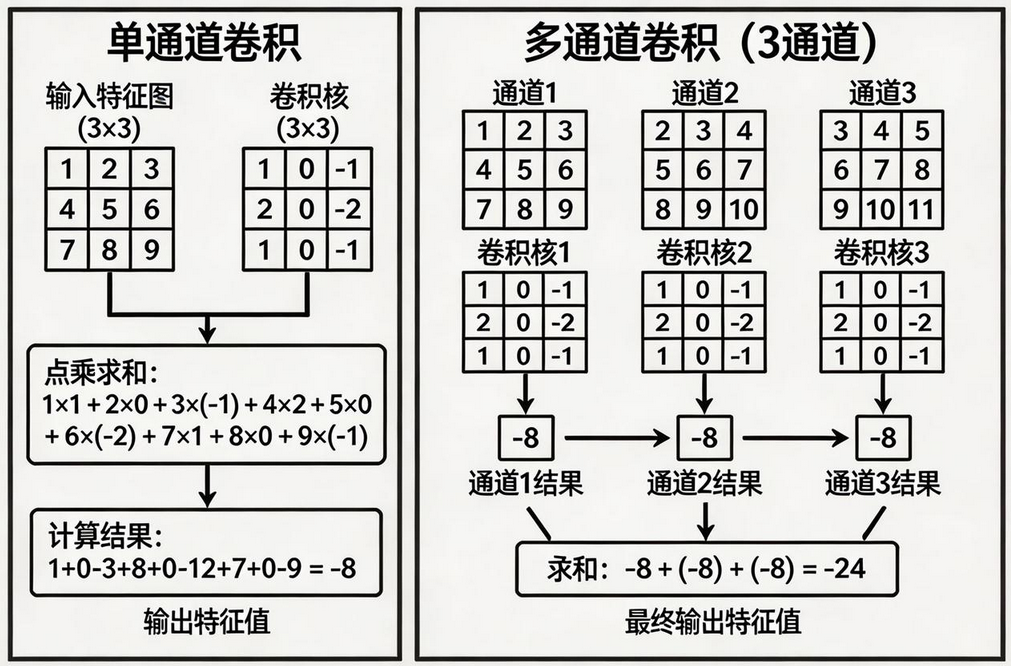
单通道卷积计算步骤:
-
将卷积核与特征图对应位置的数值相乘
-
将所有乘积相加,得到一个输出值
-
滑动窗口,重复上述过程
多通道卷积计算步骤:
-
每个通道分别与对应卷积核做卷积计算
-
将所有通道的计算结果相加
-
最终得到一个二维特征图
💡 关键点:输入有多少个通道,卷积核就必须有多少个通道!
Padding:保护边缘信息
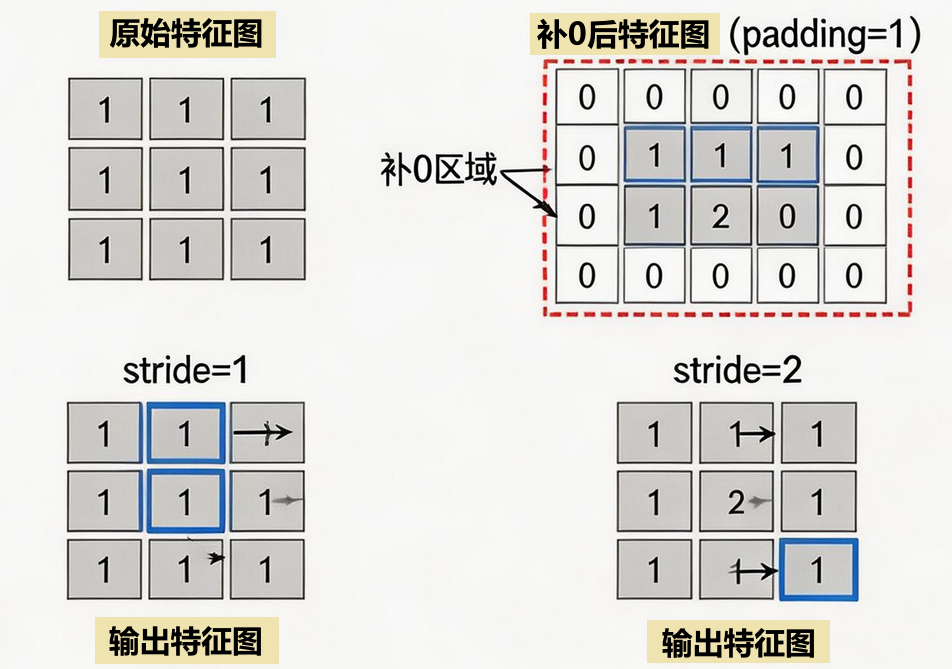
Padding 就是在特征图周围补 0,它有两个重要作用:
-
防止边缘信息丢失:如果不补 0,边缘像素只被计算一次,中间像素被计算多次
-
保持特征图形状一致:让输入和输出的尺寸相同
Stride:控制降维速度
Stride 是卷积核每次移动的步长:
-
stride=1:每次移动 1 个像素,输出尺寸接近输入
-
stride=2:每次移动 2 个像素,输出尺寸减半
Stride 的作用:
-
✅ 降维:减少特征图大小
-
✅ 扩大感受野:让每个输出看到更大的输入区域
特征图大小计算公式
Plain
N = floor((W - F + 2P) / S + 1)
其中:
W = 原特征图大小
F = 卷积核大小 (Filter size)
P = padding填充圈数
S = stride步长
floor() = 向下取整举例:输入 5×5,卷积核 3×3,padding=1,stride=1
Plain
N = (5 - 3 + 2×1)/1 + 1 = 5
输出:5×5 ✓ 尺寸不变Conv2d API 详解
python
import torch.nn as nn
# 创建卷积层
conv = nn.Conv2d(
in_channels=3, # 输入通道数(RGB是3)
out_channels=64, # 输出通道数 = 卷积核个数
kernel_size=3, # 卷积核大小 3×3
stride=1, # 步长,默认1
padding=1 # 填充,默认0
)参数说明:
-
in_channels:输入图像的通道数(RGB=3,灰度 = 1) -
out_channels:卷积核的数量,决定输出通道数 -
kernel_size:卷积核的尺寸(3 最常用) -
stride:滑动步长 -
padding:周围补 0 的圈数
1.4 池化层:高效降维
池化层的作用是在不改变通道数的前提下,降低特征图的高和宽。
⚠️ 与卷积层的核心区别:池化层没有可学习的参数(没有神经元),只有池化窗口!
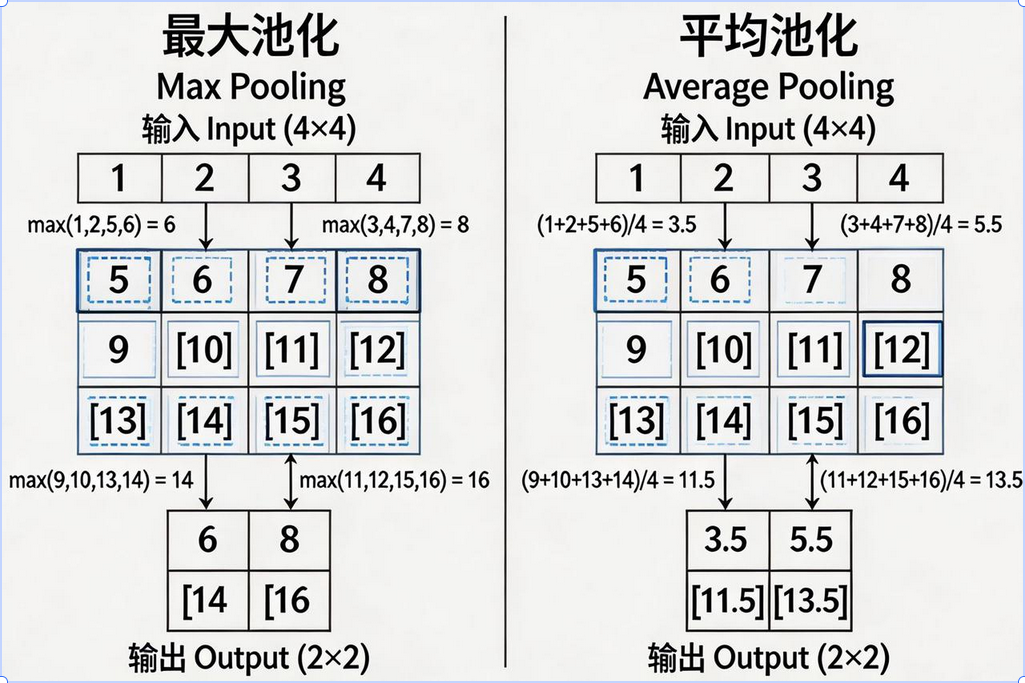
两种池化方式
1. 最大池化 (Max Pooling)
-
提取窗口内的最大值
-
作用:保留最显著的特征
-
最常用!
2. 平均池化 (Average Pooling)
-
提取窗口内的平均值
-
作用:平滑特征,减少噪声
池化的特点
-
✅ 只在 H 和 W 维度降维,通道数保持不变
-
✅ 没有参数需要学习
-
✅ 计算简单,速度快
Pooling API 详解
python
# 最大池化
max_pool = nn.MaxPool2d(
kernel_size=2, # 池化窗口大小
stride=2, # 步长,默认等于kernel_size
padding=0 # 填充,默认0
)
# 平均池化
avg_pool = nn.AvgPool2d(
kernel_size=2,
stride=2
)💡 常用技巧:kernel_size=2, stride=2 可以将特征图尺寸正好减半!
第二部分:循环神经网络 (RNN)
2.1 RNN 是什么?
循环神经网络 (Recurrent Neural Network, RNN) 是专门处理序列数据的神经网络。
什么是序列数据?
序列数据有两个特点:
-
时间步生成:数据是按顺序一个一个产生的
-
前后关联:当前数据和前面的数据有关系
例如:
-
文本:我 爱 深度 学习→ 每个词依赖前面的语境
-
语音:按时间顺序的音频波形
-
股票:按时间顺序的价格数据
RNN 的典型应用场景
-
✅ 生成式 AI 大模型(GPT、LLaMA 等)
-
✅ 机器翻译(中→英)
-
✅ 语音识别(语音→文字)
-
✅ 自然语言处理 NLP
-
✅ 时间序列预测
2.2 词嵌入层:让计算机理解词语
计算机不认识猫、狗这样的文字,我们需要把词转换成向量。
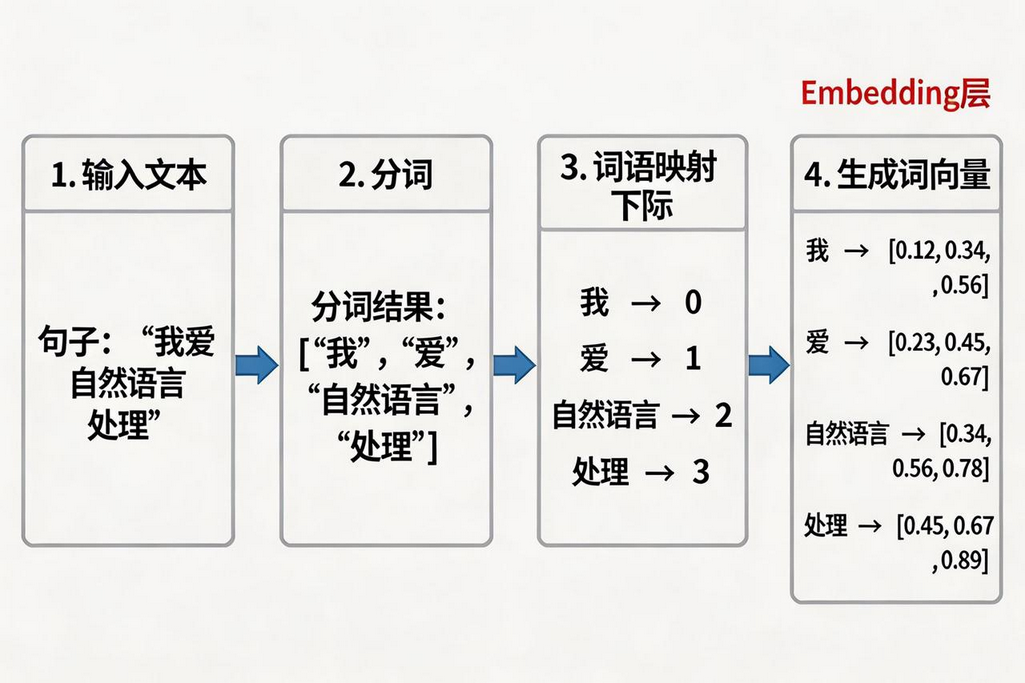
词嵌入的作用
词嵌入 (Embedding) 将离散的词语转换为低维稠密向量:
-
我 → 0.12, 0.34, 0.56, ...
-
爱 → 0.23, 0.45, 0.67, ...
为什么要这么做?
-
神经网络只能处理数值
-
相似的词在向量空间中距离更近(语义保持)
-
降低维度,避免维度灾难
词嵌入的完整流程
Plain
文本句子 → 分词 → 词语 → 下标 → 词向量
举例:
"我爱自然语言处理"
→ 分词:["我", "爱", "自然语言", "处理"]
→ 下标:[0, 1, 2, 3]
→ 向量:[[0.1,...], [0.2,...], [0.3,...], [0.4,...]]Embedding API 详解
python
# 创建词嵌入层
embedding = nn.Embedding(
num_embeddings=10000, # 词汇表大小(总词数)
embedding_dim=128 # 每个词向量的维度
)
# 使用:输入下标,输出向量
word_indices = torch.tensor([0, 1, 2, 3]) # 词语的下标
word_vectors = embedding(word_indices) # 输出:(4, 128)参数说明:
-
num\_embeddings:词汇表中总共有多少个不同的词 -
embedding\_dim:每个词转换成多少维的向量
2.3 RNN 循环层:具有记忆的网络
RNN 最神奇的地方就是具有记忆功能 ------ 它能记住之前看到的信息!
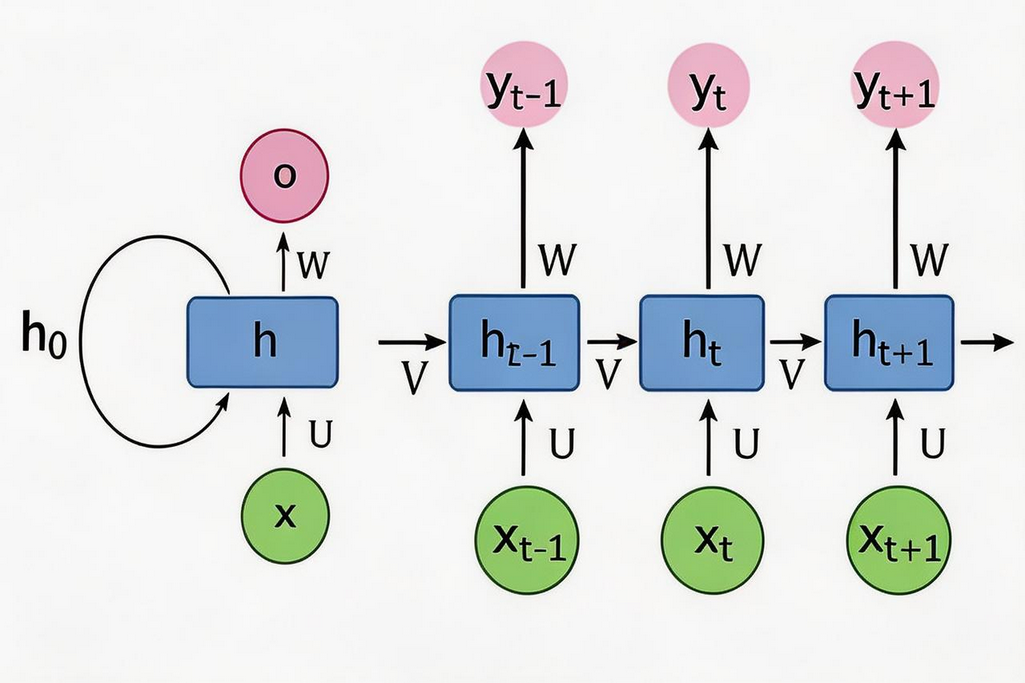
RNN 的计算原理
RNN 的核心公式:
Plain
当前隐藏状态 ht = 当前输入xt + 上一步记忆ht-1详细计算过程:
-
接收当前输入 x_t(词向量)
-
接收上一步的记忆 h_{t-1}(隐藏状态)
-
计算得到当前记忆 h_t
-
基于 h_t 输出预测结果 y_t
💡 形象理解:h 就像 RNN 的大脑,每一步都会更新记忆,然后基于记忆做出预测。
RNN API 详解
python
# 创建RNN层
rnn = nn.RNN(
input_size=128, # 输入特征维度(词向量维度)
hidden_size=256, # 隐藏层维度(记忆的大小)
num_layers=1 # RNN的层数,默认1层
)
# 使用RNN
# x: (序列长度, batch大小, 词向量维度)
# h0: (层数, batch大小, 隐藏层维度)
output, hn = rnn(x, h0)参数说明:
-
input_size:输入数据的特征维度,通常等于词向量维度 -
hidden_size:隐藏状态的维度,决定 "记忆容量" -
num_layers:堆叠多少层 RNN,层数越多能力越强但越难训练
输入输出形状:
-
输入 x:
(seq_len, batch_size, input_size) -
输入 h0:
(num_layers, batch_size, hidden_size) -
输出 output:
(seq_len, batch_size, hidden_size) -
输出 hn:
(num_layers, batch_size, hidden_size)
总结与对比
CNN vs RNN 核心对比
| 维度 | CNN | RNN |
|---|---|---|
| 处理数据 | 空间数据(图像) | 序列数据(文本 / 语音) |
| 核心思想 | 局部感受野 + 参数共享 | 循环连接 + 状态传递 |
| 记忆能力 | 无(每次独立处理) | 有(记住历史信息) |
| 擅长领域 | 计算机视觉 | 自然语言处理 |
| 输出长度 | 固定 | 可变(可生成任意长度) |
学习路线建议
-
先学 CNN:概念更直观,可视化效果好,容易建立信心
-
再学 RNN:理解记忆和序列的概念,为学习 Transformer 打基础
-
进阶学习:LSTM/GRU(解决 RNN 梯度消失)→ Transformer(注意力机制)
代码示例汇总
完整的 CNN 示例(图像分类)
python
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
# 输入: (3, 32, 32)
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1) # (16, 32, 32)
self.pool = nn.MaxPool2d(2, 2) # (16, 16, 16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1) # (32, 16, 16)
# pool后: (32, 8, 8)
self.fc = nn.Linear(32 * 8 * 8, 10) # 10分类
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.flatten(1)
x = self.fc(x)
return x完整的 RNN 示例(文本分类)
python
class SimpleRNN(nn.Module):
def __init__(self, vocab_size=10000, embed_dim=128, hidden_size=256):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.rnn = nn.RNN(embed_dim, hidden_size, num_layers=1)
self.fc = nn.Linear(hidden_size, 2) # 二分类
def forward(self, x):
# x: (序列长度, batch_size)
x = self.embedding(x) # (seq_len, batch, embed_dim)
output, hn = self.rnn(x)
# 取最后一个时间步的输出做分类
last_output = output[-1] # (batch, hidden_size)
return self.fc(last_output)写在最后
恭喜你!现在你已经掌握了 CNN 和 RNN 的核心概念:
-
CNN通过卷积核提取空间特征,是计算机视觉的基石
-
RNN通过循环状态传递记忆,是序列处理的基础
这两个网络虽然结构不同,但都体现了深度学习的核心思想 ------让神经网络自动学习特征,而不是人工设计。
掌握了这些,你就可以向更高级的模型进发了:
-
CNN 方向:ResNet、YOLO、ViT
-
RNN 方向:LSTM、GRU、Transformer、GPT
深度学习的世界很精彩,继续加油!🚀