
个人主页:小则又沐风
个人专栏:<数据结构>
<竞赛专栏>
<Linux>
座右铭
路虽远,行则将至;事虽难,做则必成
目录
前言
在上一章的进程的讲解中我们初步认识了进程状态,并且知道了进程的调度实际上依靠cpu上的调度队列的.但是我们并不知道这个调度队列的原理.
今天我们就来了解一下cpu是怎么进行进程的调度的
进程优先级
我们知道cpu的资源是有限的,所以有的进程的对这些资源利用的优先级就会更高点,这就是进程的优先级,但是这仅仅是一个抽象的概念,那么进程的优先级在Linux下的具体的体现是什么呢???
我们来查看一个进程的信息先

一步步来介绍这些信息
- UID指的是执行这个进程的身份
- PID是这个进程的代号
- PPID是衍生出这个进程的进程的代号也就是我们常常说的父进程
- PRI就是这个进程的优先级,这个数字越小优先级就越大
- NI代表这个进程的nice值
PRI和NI
那么从上面的信息我们就可以知道了,进程的优先级是与PRI和NI有关的
从上面我们可以得知的是这个进程的优先级的默认的值是80
那么我们自己先创建出来一个进程来对这个进程的优先级进行操作
cpp
#include<stdio.h>
int main()
{
while(1)
{
}
return 0;
}
现在我们需要修改这个进程的优先级我们就需要修改这个进程的NI值
我们可以使用这个命令:
rnice -n 修改的NI值 -p 修改进程的pid

下面我们再来查看一下这个进程的优先级

可以看到这个PRI从80变成了90是符合我们的逻辑的,这个NI的确是起到了优先级的偏移量的作用.
那么我们尝试把这个进程的优先级变大

这里好像出现了一些的问题我们的NI变成了-10是不假的,但是这个PRI怎么变成了70,不应该是刚才的90-10变成80吗
这是因为进程的优先级计算的规则是默认初始值+偏移量
在这里的默认初始值是80
所以80+-10==70;
那么我们现在来查看一下进程优先级的区间

可以看到进程最小的是60

优先级最大是99
所以优先级的区间就是
[60,100);
补充:
在这里我们的进程的信息是有运行它的身份的,那么在我们学习权限的时候我们的文件是怎么知道运行他的人的身份的,我们需要知道的是无论是打开文件还是写文件的都是进程,进程中的信息就有这个进程的身份,这个身份就会在文件上的权限进行比对看看是属于于那一个的组别中.
为什么要这么设计进程的优先级?
这样的问题我还回答不了但是我可以回答的是:
如果进程的优先级设计的不合理,如果一个进程的优先级是一个1000000那么来一个进程都是排在他的前面的,那么这个进程就会因为长期得不到cpu的资源而导致进程饥饿
补充概念-竞争、独⽴、并⾏、并发
下面我们来了解一下进程的特点
- 竞争:系统进程数⽬众多,⽽CPU资源只有少量,甚⾄1个,所以进程之间是具有竞争属性的。为 了⾼效完成任务,更合理竞争相关资源,便具有了优先级
- 独立:这个的话就是我们说的每一个进程之间是相互不影响的
- 并行:如果有多个cpu的话,可以多个进程在多个cpu上同时运行
- 并发:多个进程在⼀个CPU下采⽤进程切换的⽅式,在⼀段时间之内,让多个进程都得以推进,称 之为并发
这时候我们就有一个疑问了在一个cpu下,按道理说是一个cpu是不能同时运行多个进程的,但是我们平常在使用的时候明明感觉是多个进程同时在运行啊这是怎么个情况???
下面我们就来看一下进程调度的原理
进程切换
现在我们来看一个场景哈,我们运行了一个不会终止的进程也就是我们常说的死循环的代码
那么cpu会在这个进程上一直运行吗???不会的我们需要知道的是其实我们打开的每一个app都是一个死循环的进程,当你关闭他的时候他才会真正的关闭,那么怎么做到的同时运行多个进程的呢???
这就是因为我们的cpu规定了一个进程运行的时间(也就是时间片),如果在这个时间片中这个进程还没有结束那么就会把这个进程从cpu中拿下来,换一个进程继续运行,
那么这时候就会出现一个问题:我之前那么进程运行过程被中断了但是我运行期间得到的信息不会丢失了吧?
不会的,我们的cpu中有寄存器地存在这个寄存器就会把这个进程运行的临时的数据存储在这个寄存器中.
举一个生活中的例子:
在大学中不少人会在上大学的时候选择了当兵但是如果他是没有向学校报备的话,那么就会认为这个人逃学了那么这个人的信息就会因为它逃学删除,但是这个人向学校的相关的部门进行了信息的确认,那么学校就会留下他的档案,等待它退伍.这就是寄存器把他的临时的信息存储起来了
所以现在我们来理解一下为什么一个cpu可以在我们眼中同时运行多个进程,这是因为其实cpu还是运行的一个进程但是这个进程运行了一个时间片就会从cpu中拿下来然后换成另一个进程,
因为这个时间片太短了这个进程的切换的时间太短了,所以在我们看来进程是同时运行的
那么进程是怎么带走自己的临时的数据的呢?
进程是通过吧临时的数据放到了task_strutc中的TSS的结构体中了这个结构体就是专门来存储的是进程的临时数据的
那么cpu是怎么知道一个进程它是否被调度过呢?
这样的信息也是存储在task_struct中的,在这个结构体中有一个变量就是来表示是否被调度过的信息的

调度算法
我们知道的是一个cpu是由一个调度队列的但是进程是怎么挂在这个队列上的,怎么处理一个进程的优先级的.
我们现在来仔细地研究一下
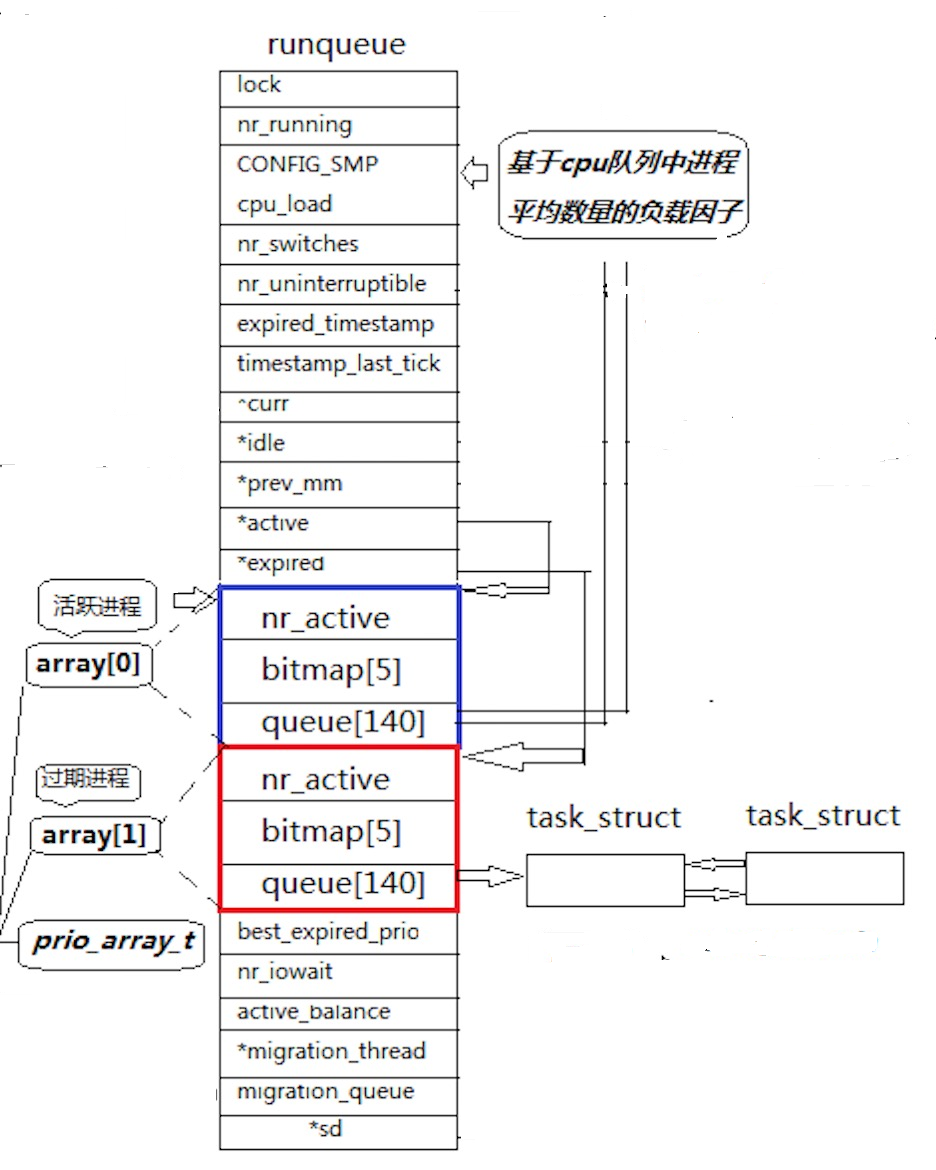
现在我们来讲解一下这个问题.
一个cpu只有一个runqueue队列,其中地这个queue地数组就是存储地是task_struct的指针那么不但可以通过这个指针找到对应的进程还可以让相同的优先级的进程挂在他的后面
那么我们就来展开讲讲这个queue
在之前的讲解中我们知道了优先级的区间是60-99但是为什么这里的数组的空间开辟了这么多?
这是因为其实我们的优先级是分成两个部分的
一个是我们刚才的优先级:普通的优先级
另一个就是比较特殊的:实时优先级
这两个优先级有什么区别呢?
我们假设一辆汽车的操作系统就是Linux的内核,那么我们进入到的是自动驾驶的模式,你也不想这个进程一会被切换到下去了.所以这个实时优先级是不受时间片的限制的,他占据了前0-99的空间
现在我们关心的则是之后的优先级
那么我们的优先级就是从100开始的40个
那么这个cpu是怎么从这个队列中挑选进程的呢?
nr_active: 总共有多少个运⾏状态的进程
先是查看这个数据是不是零,如果是零的话就代表着这个队列上的没有就绪的进程
然后从数组的0号开始遍历数组直到遇到一个数组不是空,那么这个进程就是优先级最高的进程然后开始运行这个进程
那么这样调度是可以的,但是每次我们的调度的时候cpu一个个的找是不是太麻烦了,
那么这个bitmap就出现了
这个其实就是一个位图,我们知道的是一个int占据的是32个比特位,那么5个int类型就占据了160个比特位,然后我们的queue是有140个空间的
那么我们的每一个比特位就对应一个优先级,多出来的比特位就是没有用的,我们知道0/1是可以表示很多的信息的,在这里如果一个优先级中是有进程的,那么对应的比特位图中就会变成1
那么我们就完成了高效率的调度进程了
- 先查看有无就绪进程
- 查看位图找出优先级最高的进程
- 进入queue拿出进程的task_struct
这样我们好像把这个进程切换的原理搞定了但是好像我们遗漏一些问题
为什么在这个runqueue中有两个这样的结构?
我们思考一下这样的问题,我们有一个优先级是挂在最后的进程,什么时候才可以轮到她??
等到它前面的进程所有运行结束之后,包括期间插入的进程,我去这叫什么事情啊,优先级低我认了
但是凭什么你后来者居上?!!!!
这就会导致这个进程迟迟得不到cpu的资源
这样的设计还是不合理的,所以我们需要再来一个这样的结构,把这一轮调度过后的进程如果他还没有结束就挂在另一个的队列中,把后来的进程也挂在上面,还有把这一轮中修改了优先级,在这一轮中他的优先级不变,在下一轮中更新优先级.
有一个活跃的指针active
有一个过期的指针expired
然后当一个队列的可执行的就绪进程没有了,就会把active的指针和过期指针的内容进行jiao'huan
这样的设计就非常人性化了,解决了优先级低的进程被欺负的问题了
总结
本文内容围绕 Linux 进程调度展开,先介绍进程优先级,区分了 PRI(进程优先级)与 NI(nice 值),说明两者共同决定进程调度权重,并补充竞争、独立、并行、并发等基础概念,帮助理解进程运行环境。随后讲解进程切换,核心是调度算法,涉及 runqueue 队列、位图加速、active/expired 双队列轮换等机制,解决进程饥饿问题,保障调度效率与公平性。整体梳理了进程从优先级管理到切换调度的完整逻辑,帮助理解 Linux 多进程并发运行的底层原理。
之后将会继续了解进程的知识,下一篇是怎么进行进程的控制
谢谢大家的观看!!!