APP UI自动化测试发展了十余年,从早期的脚本录制回放,到后来的控件树定位,再到如今的AI赋能,工具在进化,但核心痛点始终没有根本改变:手工用例到自动化脚本的转化率长期维持在低位,大量边缘场景和复杂交互仍依赖人工执行;跨设备适配需要投入大量人力维护;UI变化后脚本脆弱得像纸糊的;断言能力只能做文本和元素级别的简单比对,无法理解语义。
AI Agent被视为破局的关键。业界对Agent的定义五花八门,有的把RAG+LLM叫Agent,有的把CoT+Tool叫Agent,还有的把多模型协作叫Agent。当这些概念应用到测试领域,一个问题浮出水面:什么才是真正"完美"的AI测试Agent?
这篇文章不是要写一个Agent原型演示,也不是要做行业趋势分析。我试图回答一个更本质的问题:从架构设计到能力规格,一个专注于APP UI自动化的完美AI测试Agent,应该长什么样?
我会从五层架构(感知层、决策层、执行层、验证层、记忆层)完整定义每个模块要解决什么问题、达到什么能力标准、当前行业差距在哪里。文章中会给出量化数据对比、真实技术实现思路,以及从现状到完美状态的演进路径。期望读者看完后能清晰判断:自己的Agent在哪个能力维度存在短板,以及应该朝什么方向建设。
一、为什么需要重新定义"完美"
谈完美之前,先看看当前APP UI自动化的真实处境。
手工用例的自动化转化率是首要痛点。我见过很多团队的自动化覆盖率报表很好看,但仔细看会发现大量用例是"happy path"------主流程能跑通,边缘场景和异常路径几乎全部缺失。根本原因不是团队不愿意写,而是复杂交互(弹窗处理、动态内容、状态依赖)的自动化实现成本太高,性价比不够。
跨设备兼容性的问题更突出。国内Android市场的碎片化程度远超想象,同样一套自动化脚本,在MODEL_A上运行成功率95%,到了MODEL_B可能只剩70%。设备分辨率、系统版本、定制ROM的差异都会导致定位策略失效。每次新机型发布,自动化团队都要投入人力做适配,这种持续消耗让很多团队对跨设备覆盖率望而却步。
维护成本高企是第三个拦路虎。APP一次UI改版,可能导致20%的自动化用例失败。传统自动化脚本的维护方式是"发现一个修一个",完全是被动响应。而UI变化在迭代快的团队是家常便饭,长期下来维护成本远超开发成本。
断言能力弱是第四个问题。传统自动化的断言只能是"元素A可见"、"文本B等于'提交成功'"。但测试真正想验证的是业务逻辑------"用户完成支付后,订单状态是否正确变为已支付"、"页面显示的金额是否与订单详情一致"。这些语义级别的验证,传统自动化做不到。
所以"完美"的定义很清楚:手工用例可自动化转化率接近100%,跨设备零成本适配,UI变化后自动修复,语义级别的智能断言。这四个目标,每一个都是当前行业难以企及的标准。但正因为难,才值得我们去定义清晰的目标和路径。
二、完美Agent的核心架构
完美AI测试Agent不是一个大模型加几个工具调用就能搞定的。它需要清晰的架构分层,每层解决特定问题,层与层之间有明确的信息流动和协作机制。
我认为一个完整的AI测试Agent应该包含五层架构:
感知层负责让Agent"看懂"屏幕。截图、控件树、OCR都是感知能力的组成部分,但关键在于多模态融合------视觉模型的语义理解、控件树的结构化信息、OCR的文字识别,三路信息交叉校验才能形成对页面的完整认知。
决策层负责从用例到操作序列的推理。把"验证MODEL_A车型下单流程"这样的自然语言用例,分解成具体的操作步骤,并且能够根据当前页面状态动态调整策略。决策层还要处理探索和回退------遇到未知页面怎么试探,主路径失败后怎么规划替代路径。
执行层负责把决策转化为设备操作。点击坐标怎么计算、滑动手势怎么注入、输入怎么模拟。执行层还需要处理弹窗、异常恢复、设备状态检测等边界情况。核心挑战是跨设备自适应------同样的操作在MODEL_A和MODEL_B上的实现方式可能完全不同。
验证层负责判断操作结果是否符合预期。不是简单的文本比对,而是包含元素级、文本级、语义级、业务级四级断言体系。验证层还要做视觉回归检测,发现非预期的UI变化。
记忆层 负责让Agent越用越聪明。短期记忆记录当前会话的状态和操作历史,中期记忆管理相似场景的策略,长期记忆沉淀业务规则和历史经验。记忆层是Agent能否持续进化的关键。
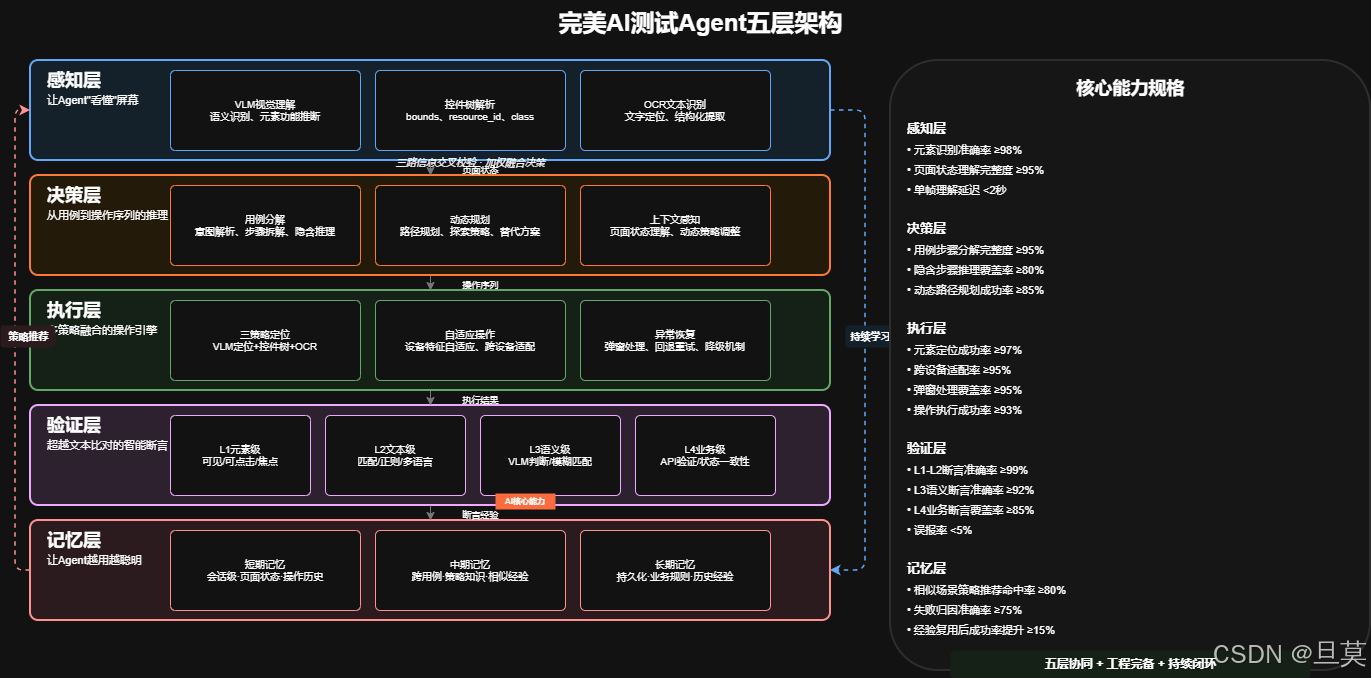
这五层不是孤立的。感知层给决策层提供页面状态输入,决策层输出操作序列给执行层,执行层反馈结果给验证层,验证层和执行层的经验回流到记忆层,记忆层反过来支撑决策层的策略选择。这是一个闭环系统,每一层的能力上限都影响整体表现。
三、感知层:让Agent真正"看懂"屏幕
感知层是整个Agent的基础。Agent做的所有决策都基于对屏幕的理解,如果感知错了,后续所有步骤都是徒劳。
3.1 多模态屏幕理解
当前很多AI测试工具的感知能力是"截图+视觉模型+坐标"这个组合。这套方案能work,但不够精准。完美Agent的感知层应该是三路信息融合:
VLM视觉理解是第一路。视觉语言模型能够理解截图的语义内容,识别可交互元素,推断元素功能。这路的优势是对复杂布局和自定义控件有效,劣势是定位精度有限,对密集排列的小按钮容易误识别。
控件树解析是第二路。通过ADB dump或者uiautomator的hierarchy接口获取页面结构。这路信息是结构化的,包含元素的bounds、resource_id、content_desc、class等属性。优势是定位精度高,劣势是对自定义控件和无障碍信息不完整的元素识别能力差。
OCR文本识别是第三路。补充视觉模型和控件树都无法覆盖的文字信息。OCR的优势是文字定位精准,劣势是只能识别文字本身,无法理解文字的语义和功能。
三路信息需要交叉校验。一个按钮,控件树报告在坐标(100, 200),VLM识别出"确认"文字,OCR也识别到"确认"在相近位置------三个信号一致,置信度就高。如果三路信息冲突,就需要进入不确定状态,标记为需要补充验证。
融合的策略可以用加权投票,也可以用更复杂的注意力机制。关键是每路信息的置信度评估要准确,这需要历史数据的积累和校准。
python
# 元素位置融合的简化示例
class ElementFusion:
def __init__(self):
self.vlm_weight = 0.3 # 视觉模型权重
self.tree_weight = 0.5 # 控件树权重
self.ocr_weight = 0.2 # OCR权重
def fuse_position(self, vlm_pos, tree_pos, ocr_pos):
# 计算加权中心点
fused_x = (vlm_pos[0] * self.vlm_weight +
tree_pos[0] * self.tree_weight +
ocr_pos[0] * self.ocr_weight)
fused_y = (vlm_pos[1] * self.vlm_weight +
tree_pos[1] * self.tree_weight +
ocr_pos[1] * self.ocr_weight)
# 计算位置偏差
deviations = self._calc_deviations(vlm_pos, tree_pos, ocr_pos)
# 偏差过大时标记不确定性
if max(deviations) > 15: # 像素阈值
return PositionResult(fused_x, fused_y, confidence=0.7)
return PositionResult(fused_x, fused_y, confidence=0.95)3.2 页面状态建模
感知层不仅要识别单个元素,还要对整个页面形成完整的状态模型。
一个完整的页面状态描述应该包含:页面类型识别(首页/详情页/设置页等)、关键元素清单(包含每个元素的类型、位置、状态、语义标签)、元素间关系(哪些元素是导航关系、哪些是并列关系、哪些是层级关系)、可执行操作列表(基于当前页面状态,Agent可以做什么操作)。
页面变化检测是另一个关键能力。每次操作执行后,需要对比操作前后的页面差异,精确定位变化区域。这不仅用于验证操作是否成功("点击了MODEL_A详情按钮,页面是否跳转到了详情页"),还用于异常检测("页面出现了未知的弹窗")。
不确定性标注很重要。感知能力不可能100%准确,完美Agent需要对自己的不确定性有清醒认知。当某个元素的识别置信度低于阈值时,应该显式标注,并在后续决策中考虑这个不确定性。比如,某个按钮的识别置信度只有0.6,Agent在决策时可以选择先尝试点击,如果失败则回退到其他策略。
3.3 完美感知层的量化标准
感知层的核心指标有几个:
元素识别准确率定义了在标准测试集上正确识别目标元素的比例。当前行业先进水平大约在85%-90%,完美状态应该达到98%以上。这个差距主要体现在特殊控件的识别上------自定义滑块、3D车模展示、动态图标等,视觉模型训练时没见过,识别率会大幅下降。
页面状态理解完整度衡量Agent对整个页面结构的认知程度。包括元素识别的完整率、元素关系推断的准确率、页面类型识别的准确率。完美状态应该达到95%以上。
单帧理解延迟是性能指标。从截图到输出完整的页面状态模型,当前行业水平在2-5秒,完美状态应该控制在2秒以内。延迟过高会影响执行效率,尤其在需要频繁感知反馈的场景。
特殊控件识别率是难点指标。自定义控件、动态内容、无障碍信息缺失的控件,识别率行业水平可能只有60%-70%,完美状态应该达到90%以上。这需要专门针对测试场景的模型优化。
四、决策层:从用例到操作序列的推理
决策层是Agent的"大脑",负责把高层目标拆解成可执行的操作序列。
4.1 用例理解与步骤分解
自然语言用例到结构化步骤的转换是第一步。输入"验证MODEL_A车型在未登录状态下无法下单",Agent需要理解这个用例的意图,然后分解成:进入车型列表→选择MODEL_A→查看详情→点击下单→验证登录拦截。这个分解过程需要领域知识支撑,理解汽车交易业务中的典型流程。
隐含步骤推理是更高级的能力。用例写"完成支付",Agent需要推理出这涉及:选择支付方式→输入支付密码/指纹→确认支付→等待回调→验证订单状态。每一步还可能涉及异常分支------密码错误怎么办、支付超时怎么办、网络断开怎么办。
上下文感知让决策更精准。同样的操作在不同的页面状态下可能有不同的实现方式。"点击确定按钮"在确认弹窗上是一个操作,在普通页面列表上可能是另一个操作。Agent需要根据当前页面状态选择最合适的操作策略。
python
class StepDecomposer:
def decompose(self, user_intent: str, page_state: PageStateModel) -> List[Operation]:
# 意图解析,提取目标操作和约束
intent = self.intent_parser.parse(user_intent)
# 基于当前页面状态推断前置步骤
required_preconditions = self._infer_preconditions(intent)
for precond in required_preconditions:
if not self._check_precondition(precond, page_state):
# 递归添加前置步骤
pre_steps = self.decompose(precond.description, page_state)
steps.extend(pre_steps)
# 主操作分解
main_steps = self._decompose_main_intent(intent, page_state)
# 隐含步骤补全
implicit_steps = self._infer_implicit_steps(main_steps)
return steps + main_steps + implicit_steps4.2 动态操作规划
静态规划解决不了所有问题。用例步骤分解是离线完成的,但执行时页面状态可能与预期不符。这时候需要动态规划能力。
探索策略处理未知页面。当Agent遇到一个没有在预期中出现的页面时,需要有系统化的试探策略。比如,尝试识别页面上可点击的元素,逐一尝试点击,观察页面变化,记录探索路径。这种探索要有边界,不能无限进行。
路径规划寻找从当前状态到目标状态的最优操作序列。这在复杂导航场景中很有价值。比如,从APP首页到达订单详情页可能有多种路径,Agent需要评估哪种路径最稳定、最快、最不容易出错。
失败后的替代路径规划很关键。当主路径失败时,Agent需要快速切换到替代方案。比如,"选择支付方式"这个步骤失败,可能是支付列表没有加载出来,替代方案可能是"等待页面加载"或"返回重试"。
4.3 完美决策层的量化标准
用例步骤分解完整度衡量Agent能否把用例拆解成完整的操作序列。当前行业水平约80%-85%,完美状态应该达到95%以上。不完整的分解会导致用例执行到一半无法继续。
隐含步骤推理覆盖率衡量Agent对业务逻辑的深层理解。"完成支付"这类复合操作背后有多少步骤被正确推断。当前行业水平可能只有50%-60%,完美状态应该达到80%以上。
动态路径规划成功率衡量面对非预期页面状态时的适应能力。当前行业水平约60%-70%,完美状态应该达到85%以上。这需要丰富的页面状态知识和灵活的策略选择能力。
五、执行层:多策略融合的操作引擎
执行层负责把决策层的操作意图转化为真实的设备交互。
5.1 三策略融合定位
元素定位是执行的第一步。完美Agent应该同时掌握三种定位策略,并能智能选择最优方案:
VLM视觉定位通过视觉语言模型识别目标元素的视觉特征,计算其在截图中的位置。这对没有稳定控件ID的元素特别有效,但定位精度受截图分辨率和元素视觉效果影响。
控件树定位依赖页面结构信息。resource_id最稳定但不一定存在,accessibility_id次之,xpath最灵活但最脆弱。控件树定位的优势是精度高,劣势是依赖无障碍信息的完整性。
OCR文本定位通过识别页面文字来定位元素。适合带有明确文字标签的按钮和输入框,但不适合图标按钮或无文字的控件。
策略选择逻辑需要动态调整。不同场景下策略优先级可能不同。对于MODEL_A这类主流机型,控件树信息比较完整,可以优先用控件树;对于MODEL_B这类定制ROM,控件树可能有缺失,需要优先用视觉定位。执行层需要能够感知设备特征,动态调整策略组合。
5.2 自适应操作执行
跨设备适配是执行层最大的挑战。同样的点击操作,在6寸屏的MODEL_A和7寸屏的MODEL_B上,坐标可能完全不同。
设备特征自适应通过建立设备画像来解决这个问题。每个设备记录其分辨率、DPI、系统版本、屏幕密度等参数。当执行操作时,根据目标设备特征计算实际坐标。如果设备画像数据不足,系统需要能够通过自动探测来发现设备特征。
操作方式自适应让Agent选择最合适的操作方式。同样是触发一个下拉菜单,可以点击触发图标,可以滑动手势,也可以通过长按展开。Agent需要根据目标元素的特征和当前页面状态选择最优方式。
执行验证闭环确保操作真正生效。每次操作后截图确认结果,比对操作前后的页面差异。如果页面没有预期变化,说明操作可能失败,需要进入异常处理流程。
5.3 弹窗与异常处理
弹窗是APP测试中最常见的阻断因素。权限请求弹窗、版本升级弹窗、广告弹窗、网络异常弹窗,每一种都需要不同的处理策略。
弹窗识别需要结合视觉模型和控件树。视觉模型可以识别弹窗的类型("这是一个权限请求弹窗"),控件树可以获取弹窗的按钮结构。两者结合能实现准确的弹窗分类和处理决策。
弹窗处理策略需要业务知识支撑。权限弹窗应该"允许"还是"拒绝",取决于当前用例的上下文;广告弹窗应该"关闭"还是"跳过",需要判断是否存在可用的关闭按钮;网络异常弹窗可能需要"重试"或"取消"。
异常恢复策略让Agent在操作失败后能够自我修复。回退机制在操作失败时恢复到上一个稳定状态;重试机制在瞬时失败时重新尝试;降级机制在持续失败时切换到替代方案。
5.4 完美执行层的量化标准
元素定位成功率衡量定位策略的可靠程度。当前行业水平约90%,完美状态应该达到97%以上。差距主要体现在定位策略的融合能力和特殊场景的覆盖上。
跨设备适配率衡量新增设备的无成本适配能力。当前行业需要0.5-1人天来做新机型适配,完美状态应该是零成本------Agent能够自动感知设备特征并自适应执行。
弹窗处理覆盖率衡量对常见弹窗类型的覆盖程度。当前行业约80%-85%,完美状态应该达到95%以上。覆盖率的差距在于边缘弹窗类型的识别和处理。
操作执行成功率是最终指标,衡量Agent能否把决策正确执行。当前行业约88%-90%,完美状态应该达到93%以上。
六、验证层:超越文本比对的智能断言
验证层是测试Agent与传统自动化最核心的区别。传统自动化只能验证"元素A可见"、"文本B等于'成功'",完美Agent应该能理解"页面显示是否正确"。
6.1 四级断言体系
L1 元素级断言验证基本的UI元素状态。这是传统自动化最擅长的:元素是否存在、是否可见、是否可点击、是否获得焦点。完美Agent的L1断言应该与传统自动化一样可靠,准确率99%以上。
L2 文本级断言验证文本内容的正确性。元素文本是否等于预期值、是否包含关键词、是否匹配正则表达式。L2断言需要处理动态文本(时间戳、订单号等)和多语言文本。
L3 语义级断言是AI测试Agent的独特能力。通过视觉语言模型判断页面语义是否正确。比如,"MODEL_A的车型详情页是否正确显示了车辆信息"、"MODEL_B的配置选择器是否正确高亮了用户的选择"。L3断言需要模型理解业务语义,能够处理模糊匹配和部分正确的情况。
python
class SemanticAssertion:
def evaluate(self, assertion: SemanticAssertionSpec,
screenshot: Image, page_state: PageState) -> AssertionResult:
if assertion.type == 'visual_match':
# 视觉相似度比对
expected_img = self._load_expected_image(assertion.expected)
similarity = self._calculate_similarity(screenshot, expected_img)
return AssertionResult(
passed=similarity >= assertion.threshold,
confidence=similarity,
message=f"视觉相似度: {similarity:.2%}"
)
elif assertion.type == 'semantic_check':
# 语义检查
page_description = self.vlm.describe(screenshot, assertion.query)
result = self.llm.evaluate(assertion.criteria, page_description)
return AssertionResult(
passed=result.passed,
confidence=result.confidence,
message=result.reason
)
elif assertion.type == 'element_relation':
# 元素关系验证
relations = self._verify_element_relations(
assertion.expected_relations,
page_state
)
return AssertionResult(
passed=all(r.passed for r in relations),
confidence=min(r.confidence for r in relations),
message=f"关系验证: {len([r for r in relations if r.passed])}/{len(relations)}"
)L4 业务级断言结合后端数据和接口来验证业务逻辑的正确性。比如,下单后验证订单状态是否正确变更、支付后验证账户余额是否正确扣减、库存变化后验证数据是否一致。L4断言需要与后端系统打通,获取API响应和数据库状态。

6.2 视觉回归检测
视觉回归检测是验证层的重要组成部分。在UI自动化测试中,有时候我们不期望页面有任何变化,但当前用例并没有覆盖到这个细节。视觉回归检测通过对比操作前后的截图,自动发现非预期的UI变化。
实现上需要处理几个问题。首先是忽略无关变化------时间戳在变化、动态内容在变化、网络状态的图标在变化,这些不应该被报告为问题。其次是聚焦关键差异------如果MODEL_A的车型图片换了,可能是预期内的改版;如果MODEL_B的按钮位置突然错位,这可能就是Bug。最后是变化分类------预期变化、非预期变化、不确定变化,分类结果直接影响测试工程师的处理方式。
6.3 完美验证层的量化标准
L1-L2断言准确率应该达到99%以上,与传统自动化持平。这个标准不难达到,关键是把基础做扎实。
L3语义断言准确率是区分能力的关键。当前行业水平约70%-80%,完美状态应该达到92%以上。差距在于视觉模型的语义理解深度------模型不仅要识别"页面显示了什么",还要判断"显示的是否正确",这对模型的业务理解能力要求很高。
L4业务断言覆盖率衡量对核心业务逻辑的验证覆盖。当前行业可能只有60%-70%,完美状态应该达到85%以上。覆盖率不足的原因是需要与后端系统打通,开发成本较高。
误报率是验证层的重要质量指标。当前行业约8%-10%,完美状态应该控制在5%以下。误报过高会导致测试工程师对自动化结果失去信任。
七、记忆层:让Agent越用越聪明
记忆层是完美Agent的灵魂。没有记忆的Agent每次执行都是从零开始,有了记忆的Agent才能积累经验、持续进化。
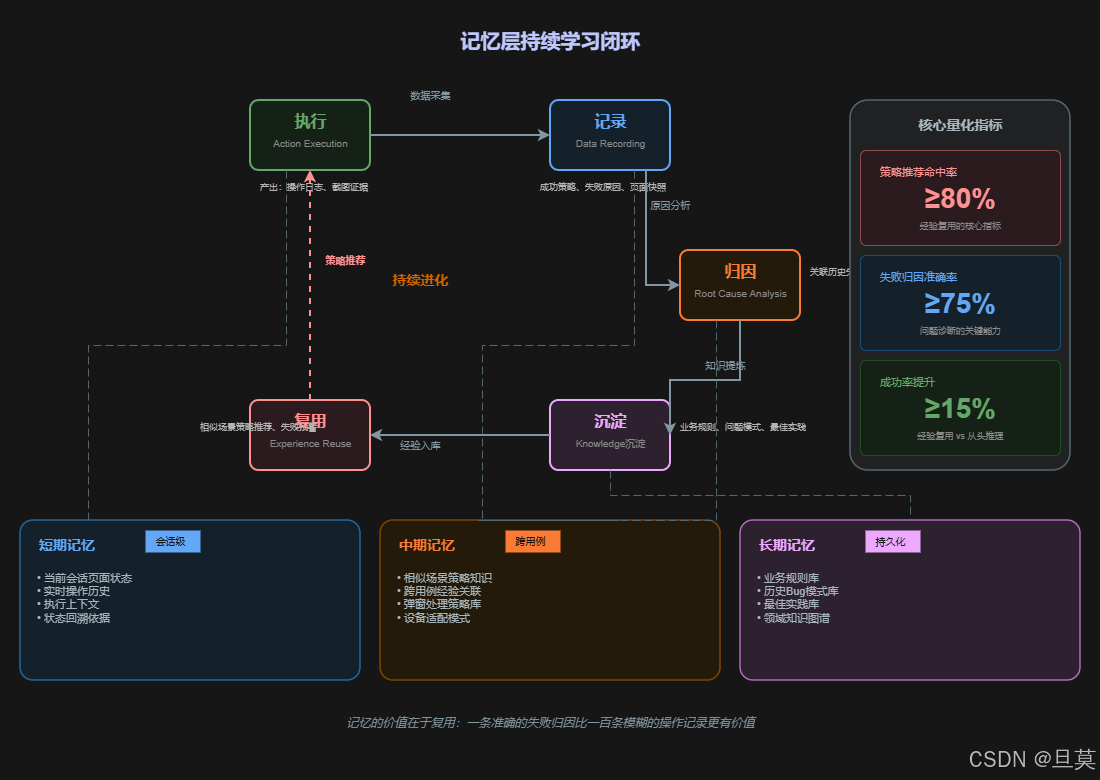
7.1 三类记忆
短期记忆记录当前测试会话中的页面状态和操作历史。这是最基础的记忆能力,用于支持会话内的上下文理解和状态回溯。当Agent在执行过程中发现当前页面与预期不符时,可以查询短期记忆了解之前发生了什么。
中期记忆管理跨用例的策略知识。比如,"MODEL_A的某个设置页面经常出现网络异常弹窗"、"MODEL_B的某个按钮点击后需要等待2秒加载"。中期记忆让Agent在遇到相似场景时能够快速复用历史策略,而不需要每次都从头推理。
长期记忆沉淀业务规则、历史Bug和执行经验。这是经过验证和沉淀的知识体系,包括:业务规则库(什么样的用户操作会导致什么样的系统行为)、问题模式库(某种页面特征通常伴随某种问题)、最佳实践库(某种场景下的最优操作序列)。
7.2 经验复用机制
记忆的价值在于复用。当Agent遇到一个新的测试场景时,应该能够从记忆中检索相似的历史经验,并基于这些经验选择最优策略。
python
class MemoryRetrieval:
def retrieve(self, context: RetrievalContext) -> List[RetrievedMemory]:
query = self._build_query(context)
# 向量检索找相似场景
similar_cases = self.vector_db.search(
query,
top_k=5,
filters={'app_type': context.app_type, 'device': context.device}
)
# 精确检索匹配完全相同的情况
exact_matches = self.exact_index.lookup(
scene_hash=context.scene_signature
)
# 融合结果
merged = self._merge_retrieval_results(similar_cases, exact_matches)
# 排序和筛选
ranked = self._rank_by_relevance(merged, context)
return ranked[:3] # 返回最相关的3条记忆失败归因是记忆层的重要能力。当执行失败时,Agent需要能够关联历史类似失败,找到失败的根本原因。这不仅帮助快速定位问题,还能避免在同一个坑里反复跌倒。
策略推荐根据当前场景主动推荐最优策略。当Agent识别到特定页面类型或操作上下文时,可以从记忆中检索最佳实践,主动提示给决策层。
7.3 持续学习闭环
记忆层需要与执行层形成闭环。执行成功时,成功的策略和经验需要沉淀到记忆中;执行失败时,失败的原因和修复方案需要记录下来供后续参考;人工反馈是最高质量的学习信号,测试工程师对执行结果的人工确认或纠正是模型优化的重要输入。
7.4 完美记忆层的量化标准
相似场景策略推荐命中率衡量记忆复用的效果。当前行业约50%-60%,完美状态应该达到80%以上。命中率取决于记忆的检索精度和策略的可用性。
失败归因准确率衡量问题诊断能力。当前行业约55%-65%,完美状态应该达到75%以上。准确的归因能大幅减少问题排查时间。
经验复用后执行成功率提升是最终指标。当Agent应用历史经验后,执行成功率应该比从头推理有明显提升。当前行业提升约5%-10%,完美状态应该达到15%以上。
八、完美Agent的工程能力清单
架构设计再完美,也需要工程能力来落地。不是所有能力都能靠模型解决,完美Agent还需要完备的工程基础设施。
Tool层是Agent与设备交互的接口。ADB工具包负责设备连接、截图、输入注入、控件树获取;API调用工具负责TSP接口调用、状态查询;文件传输工具负责设备与宿主机之间的文件交换。Tool的设计要稳定可靠,任何Tool的失败都会导致整个Agent的执行中断。
Skill层是特定领域能力的封装。用例解析Skill负责自然语言到结构化步骤的转换;元素定位Skill负责三策略融合定位和异常时的降级切换;弹窗处理Skill负责弹窗识别和智能处理;断言判断Skill负责四级断言的执行和结果判定;异常恢复Skill负责失败时的回退、重试和降级策略。
MCP(Model Context Protocol)层是Agent的上下文输入。页面状态上下文提供当前页面的完整结构信息;执行经验上下文提供历史策略和失败归因;业务规则上下文提供业务逻辑的约束条件。上下文的质量直接影响决策层的表现。
Server层是规模化执行的保障。设备管理服务负责设备池的分配、回收、健康检测;执行调度服务负责任务队列、并发控制、优先级排序;报告生成服务负责截图、录屏、断言结果和诊断信息的聚合输出。
编排层支持多Agent协作。大型APP测试可能涉及App端、Web端、API端、数据库端多个系统,单Agent无法覆盖所有场景。多Agent协作需要定义清晰的Agent职责边界和通信协议。
| 能力类型 | 具体能力 | 成熟度要求 |
|---|---|---|
| Tool | ADB工具包 | 高可用,支持多设备并发 |
| Tool | API调用工具 | 支持认证、重试、超时处理 |
| Skill | 用例解析Skill | 高准确率,支持复杂用例 |
| Skill | 元素定位Skill | 三策略融合,动态降级 |
| Skill | 弹窗处理Skill | 95%覆盖率的弹窗类型 |
| Skill | 断言判断Skill | 四级断言,全量覆盖 |
| Skill | 异常恢复Skill | 多级回退机制 |
| MCP | 页面状态上下文 | 实时、准确、完整 |
| MCP | 执行经验上下文 | 检索快、相关度高 |
| Server | 设备管理 | 高可用,支持横向扩展 |
| Server | 执行调度 | 高并发、低延迟 |
| Server | 报告生成 | 截图、录屏、诊断全覆盖 |
| 编排 | 多Agent协作 | 协议清晰、状态同步 |
九、完美Agent vs 当前实现:差距在哪
定义完美状态容易,真正落地难。我整理了一张能力对比表,展示完美状态和当前行业最先进实现之间的差距。
| 能力维度 | 完美状态 | 当前最先进 | 主要差距 |
|---|---|---|---|
| 元素识别准确率 | >=98% | 85-90% | 特殊控件(自定义滑块、3D模型、动态图标)识别能力不足 |
| 页面状态理解完整度 | >=95% | 75-80% | 元素关系推断和页面类型识别能力有限 |
| 单帧理解延迟 | <2秒 | 2-5秒 | 多模态融合增加延迟,优化空间在模型蒸馏 |
| 隐含步骤推理覆盖率 | >=80% | 50-60% | 业务语义理解深度不足,缺乏领域知识注入 |
| 动态路径规划成功率 | >=85% | 60-70% | 页面状态知识图谱不完善,探索策略不够系统 |
| 元素定位成功率 | >=97% | 90-93% | 三策略融合机制不成熟,降级策略不够灵活 |
| 跨设备适配率 | >=95%零成本 | 需0.5-1人天/设备 | 设备特征感知和自适应能力不够 |
| 弹窗处理覆盖率 | >=95% | 80-85% | 边缘弹窗类型识别和处理策略缺失 |
| L3语义断言准确率 | >=92% | 70-80% | VLM对业务语义的理解深度有限 |
| L4业务断言覆盖率 | >=85% | 60-70% | 与后端系统打通程度不够 |
| 误报率 | <5% | 8-10% | 验证逻辑不够精细,边缘case处理不完善 |
| 相似场景策略推荐命中率 | >=80% | 50-60% | RAG检索精度和记忆质量不够 |
| 失败归因准确率 | >=75% | 55-65% | 失败模式库不完整,归因推理能力有限 |
| 经验复用后成功率提升 | >=15% | 5-10% | 经验沉淀和复用的闭环机制不完善 |
分析这张表可以得出几个关键发现:
感知层差距最小但最影响全局。元素识别准确率差8-10个百分点听起来不多,但这8-10%的失败会传导到后续所有层,导致整体成功率大幅下降。
决策层差距最大且最难弥补。隐含步骤推理和动态路径规划不仅依赖模型能力,还依赖领域知识的积累。没有足够的历史数据喂给模型,模型很难学会业务场景下的推理模式。
记忆层是最被忽视的能力。业界对RAG、向量检索的关注很多,但真正落地时发现记忆的质量比数量更重要。一条准确的失败归因比一百条模糊的操作记录更有价值。
十、从现在到完美:能力演进的三个阶段
完美状态不是一蹴而就的。根据当前技术成熟度和工程投入,我建议分三个阶段来建设AI测试Agent。
阶段一:感知+执行(当前可落地)
这个阶段聚焦基础能力建设,打通从截图到操作的完整链路。核心目标是让Agent能够覆盖60%以上的简单手工用例。
关键技术突破点:建立基础的屏幕感知能力,实现VLM+控件树+OCR的三路信息采集;实现基本的元素定位策略,支持resource_id和OCR两种定位方式;实现点击、滑动、输入三类基础操作;建立简单的弹窗识别和处理能力。
量化指标:用例自动转化率达到60%;元素定位成功率达到93%;单用例执行成功率达到85%。
阶段二:决策+验证(6-12个月)
这个阶段增加智能决策和语义验证能力,让Agent能够处理更复杂的场景。核心目标是覆盖80%以上的典型手工用例。
关键技术突破点:实现用例的自然语言理解和步骤分解,支持隐含步骤的推理;建立弹窗处理的策略库,覆盖95%的常见弹窗类型;实现L3语义断言,支持基于VLM的语义判断;建立设备特征库,支持主流机型的自适应执行。
量化指标:用例自动转化率达到80%;隐含步骤推理覆盖率达到70%;跨设备适配率达到80%;L3语义断言准确率达到82%。
阶段三:记忆+自愈(12-24个月)
这个阶段引入记忆机制和自愈能力,让Agent能够持续进化。核心目标是覆盖95%以上的手工用例。
关键技术突破点:建立完整的记忆系统,支持短期、中期、长期记忆的管理;实现基于RAG的经验检索和策略推荐;建立失败归因和策略修正的闭环机制;实现UI变化的自适应修复能力。
量化指标:用例自动转化率达到95%;相似场景策略推荐命中率达到75%;失败归因准确率达到70%;经验复用后执行成功率提升15%。
每个阶段的建设都不是独立的。阶段一的基础打得越扎实,阶段二和阶段三的推进就越顺利。如果感知层准确率只有85%,无论决策层多么智能,整体效果都会受限于感知层的短板。
总结
重新审视这个问题:一个完美的AI测试Agent应该是什么样的?
它不是单一模型的突破,而是五层架构协同+工程能力完备+持续学习闭环的综合体系。感知层让Agent看懂屏幕,决策层让Agent理解意图,执行层让Agent操作设备,验证层让Agent判断对错,记忆层让Agent积累经验。五层缺一不可,每一层都有清晰的量化标准。
当前最大的差距不在感知和执行------这两层已经有相对成熟的技术方案------而在决策推理和记忆复用。决策层需要深度的业务语义理解,这需要领域知识的注入和高质量训练数据的积累;记忆层需要从"存了数据"到"用了数据"的质变,这需要工程和算法的协同优化。
从现在到完美,需要系统性建设而非堆砌模型能力。建议从阶段一开始,稳扎稳打地建设基础能力,在每个阶段设定可量化的里程碑,持续验证和调整技术路径。完美状态可能永远无法100%达成,但追求完美的过程本身就是对测试能力的持续提升。
希望这篇文章能给你一些启发。如果你在建设AI测试Agent的道路上遇到具体问题,欢迎交流。