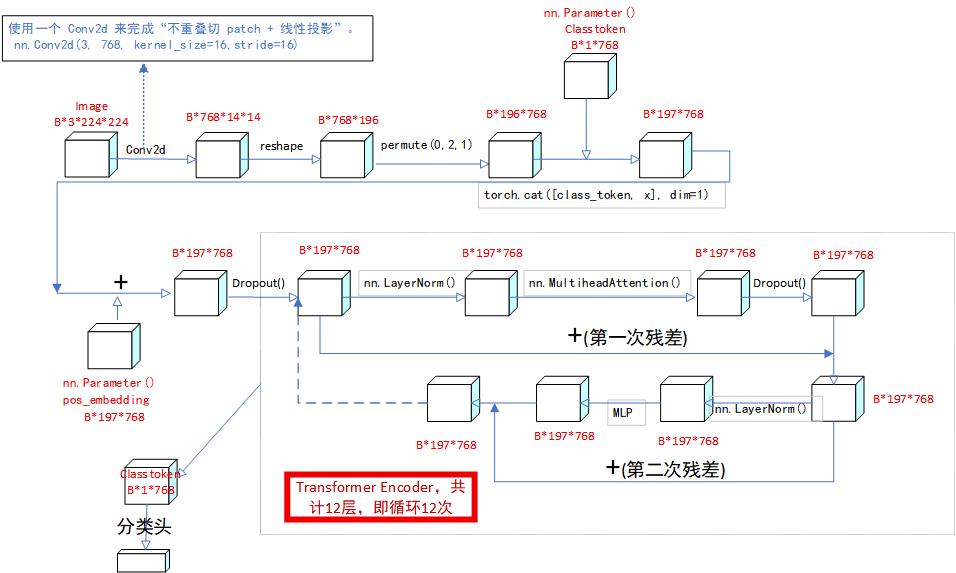
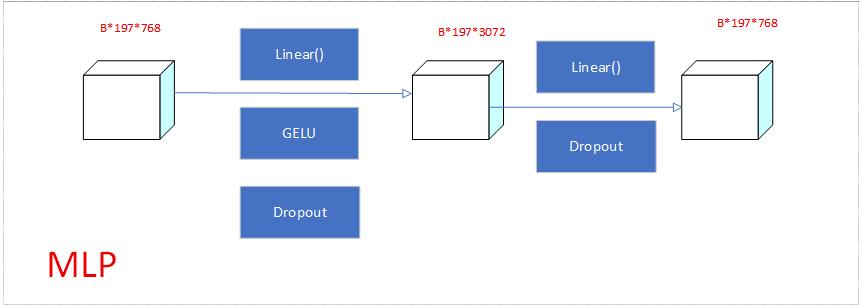
# -*- coding: utf-8 -*-
"""
Torchvision ViT-B/16 源码中文注释版
============================================================
这个文件进行中文注释整理,主要用于博客专栏讲解:
1. Torchvision 官方 VisionTransformer 的整体结构
2. ViT-B/16 的构建参数
3. Patch Embedding 的实现方式
4. Transformer Encoder / EncoderBlock 的实现方式
5. 预训练权重 WeightsEnum 的组织方式
6. 不同输入分辨率下 position embedding 的插值逻辑
注意:
- 这里尽量保留原始代码结构,仅增加中文注释。
- 如果你要直接运行该文件,需要确保本地 torchvision 版本中相关内部 API 可用。
- 本文件更适合作为源码解析材料,而不是重新发布一个独立库。
"""
import math
from collections import OrderedDict
from functools import partial
from typing import Any, Callable, Dict, List, NamedTuple, Optional
import torch
import torch.nn as nn
# torchvision 中的一些工具模块:
# Conv2dNormActivation:卷积 + 归一化 + 激活函数的组合模块,常用于 Conv Stem。
# MLP:torchvision 封装好的多层感知机模块,这里被 MLPBlock 继承。
from torchvision.ops.misc import Conv2dNormActivation, MLP
# ImageClassification:torchvision 权重对象中常用的图像分类预处理 preset。
# InterpolationMode:插值方式枚举,例如 BICUBIC。
from torchvision.transforms._presets import ImageClassification, InterpolationMode
# _log_api_usage_once:torchvision 内部用于记录 API 使用情况的工具。
from torchvision.utils import _log_api_usage_once
# register_model:模型注册装饰器;Weights / WeightsEnum:官方权重管理机制。
# 在这个精简文件中 register_model 没有实际使用,但它通常会出现在 torchvision 官方源码中。
from torchvision.models._api import register_model, Weights, WeightsEnum
# ImageNet-1K 的类别名称列表。
from torchvision.models._meta import _IMAGENET_CATEGORIES
# _ovewrite_named_param:当加载预训练权重时,用权重元信息覆盖用户传入参数。
# handle_legacy_interface:兼容旧版 pretrained=True 接口的工具。
from torchvision.models._utils import _ovewrite_named_param, handle_legacy_interface
# __all__ 控制 from models import * 时会导出的名称。
# 这里对外暴露 VisionTransformer 模型类和 ViT_B_16_Weights 权重枚举。
__all__ = [
"VisionTransformer",
"ViT_B_16_Weights",
]
class ConvStemConfig(NamedTuple):
"""
Conv Stem 的单层配置。
原始 ViT 通常直接使用一个大 kernel、大 stride 的 Conv2d 完成 patch embedding:
Conv2d(3, hidden_dim, kernel_size=patch_size, stride=patch_size)
但 torchvision 官方实现额外支持一种 conv stem 形式:
多个小卷积层 + 最后一个 1x1 卷积投影到 hidden_dim。
这个 ConvStemConfig 就是用来描述 conv stem 中每一层卷积的参数。
"""
# 当前卷积层输出通道数。
out_channels: int
# 当前卷积层卷积核大小。
kernel_size: int
# 当前卷积层步长。
stride: int
# 当前卷积层使用的归一化层,默认 BatchNorm2d。
norm_layer: Callable[..., nn.Module] = nn.BatchNorm2d
# 当前卷积层使用的激活函数,默认 ReLU。
activation_layer: Callable[..., nn.Module] = nn.ReLU
class MLPBlock(MLP):
"""
Transformer Encoder Block 中的 MLP 部分。
在 ViT 中,每个 Encoder Block 通常包含两部分:
1. Multi-Head Self-Attention
2. MLP / Feed Forward Network
这里的 MLPBlock 继承自 torchvision.ops.misc.MLP。
它的结构大致是:
Linear(in_dim -> mlp_dim)
GELU
Dropout
Linear(mlp_dim -> in_dim)
Dropout
对于 ViT-B/16:
in_dim = hidden_dim = 768
mlp_dim = 3072
"""
# _version 用于 checkpoint 兼容。
# torchvision 以前的 MLPBlock 参数命名和现在的 MLP 命名不完全一致,
# 因此通过 version 来判断是否需要迁移旧权重的 key。
_version = 2
def __init__(self, in_dim: int, mlp_dim: int, dropout: float):
"""
Args:
in_dim: 输入 token 的特征维度,也就是 hidden_dim。
mlp_dim: MLP 中间隐藏层维度,ViT-B/16 中通常是 3072。
dropout: MLP 中使用的 dropout 概率。
"""
# 调用 torchvision 的 MLP:
# MLP(in_channels, hidden_channels, activation_layer, inplace, dropout)
#
# 这里 hidden_channels=[mlp_dim, in_dim] 表示两层 Linear:
# Linear(in_dim -> mlp_dim)
# Linear(mlp_dim -> in_dim)
#
# activation_layer=nn.GELU 对应 Transformer 中常用的 GELU 激活函数。
super().__init__(in_dim, [mlp_dim, in_dim], activation_layer=nn.GELU, inplace=None, dropout=dropout)
# 对 MLP 中所有 Linear 层进行初始化。
# weight 使用 Xavier Uniform 初始化。
# bias 使用均值为 0、标准差为 1e-6 的正态分布初始化。
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.normal_(m.bias, std=1e-6)
def _load_from_state_dict(
self,
state_dict,
prefix,
local_metadata,
strict,
missing_keys,
unexpected_keys,
error_msgs,
):
"""
加载 checkpoint 时的兼容逻辑。
torchvision 历史版本中,MLPBlock 的线性层 key 可能类似:
linear_1.weight
linear_1.bias
linear_2.weight
linear_2.bias
新版 MLP 继承结构中,Sequential 内部层的 key 可能类似:
0.weight
0.bias
3.weight
3.bias
因此这里会在加载旧权重时,把旧 key 转换成新 key。
"""
version = local_metadata.get("version", None)
# 如果 checkpoint 没有 version,或者 version < 2,说明可能是旧格式。
if version is None or version < 2:
# Replacing legacy MLPBlock with MLP. See https://github.com/pytorch/vision/pull/6053
for i in range(2):
for type in ["weight", "bias"]:
# 旧版 key,例如 linear_1.weight / linear_2.bias。
old_key = f"{prefix}linear_{i+1}.{type}"
# 新版 key。
# i=0 -> 0.weight / 0.bias
# i=1 -> 3.weight / 3.bias
# 这里的 3 通常对应 Sequential 中第二个 Linear 的位置。
new_key = f"{prefix}{3*i}.{type}"
# 如果旧 key 存在,就迁移到新 key。
if old_key in state_dict:
state_dict[new_key] = state_dict.pop(old_key)
# 调用父类的加载逻辑。
super()._load_from_state_dict(
state_dict,
prefix,
local_metadata,
strict,
missing_keys,
unexpected_keys,
error_msgs,
)
class EncoderBlock(nn.Module):
"""
一个 Transformer Encoder Block。
在 ViT 中,一个 EncoderBlock 的结构是 Pre-Norm 结构:
输入 x
↓
LayerNorm
↓
Multi-Head Self-Attention
↓
Dropout
↓
残差连接:x = x + input
↓
LayerNorm
↓
MLP
↓
残差连接:output = x + y
对应公式:
x = x + MSA(LN(x))
x = x + MLP(LN(x))
其中:
MSA = Multi-Head Self-Attention
LN = LayerNorm
"""
def __init__(
self,
num_heads: int,
hidden_dim: int,
mlp_dim: int,
dropout: float,
attention_dropout: float,
norm_layer: Callable[..., torch.nn.Module] = partial(nn.LayerNorm, eps=1e-6),
):
"""
Args:
num_heads: 多头注意力 head 数量。ViT-B/16 中为 12。
hidden_dim: token embedding 维度。ViT-B/16 中为 768。
mlp_dim: MLP 隐藏层维度。ViT-B/16 中为 3072。
dropout: attention 输出和 MLP 中使用的 dropout。
attention_dropout: attention 权重上的 dropout。
norm_layer: 归一化层,默认 LayerNorm(eps=1e-6)。
"""
super().__init__()
self.num_heads = num_heads
# -------------------------
# 1. Attention block
# -------------------------
# 第一层 LayerNorm。
# 由于这是 Pre-Norm 结构,所以先 LN,再进入 self-attention。
self.ln_1 = norm_layer(hidden_dim)
# PyTorch 内置多头注意力模块。
#
# hidden_dim: 输入 embedding 维度。
# num_heads: 注意力头数量。
# dropout: attention 权重上的 dropout。
# batch_first=True 表示输入张量格式是 [B, N, D],
# 而不是 nn.MultiheadAttention 默认的 [N, B, D]。
self.self_attention = nn.MultiheadAttention(hidden_dim, num_heads, dropout=attention_dropout, batch_first=True)
# attention 输出之后的 dropout。
self.dropout = nn.Dropout(dropout)
# -------------------------
# 2. MLP block
# -------------------------
# 第二层 LayerNorm,进入 MLP 前使用。
self.ln_2 = norm_layer(hidden_dim)
# Transformer 中的前馈网络。
self.mlp = MLPBlock(hidden_dim, mlp_dim, dropout)
def forward(self, input: torch.Tensor):
"""
Args:
input: [batch_size, seq_length, hidden_dim]
对 ViT-B/16 来说通常是 [B, 197, 768]。
Returns:
输出形状仍然是 [batch_size, seq_length, hidden_dim]。
"""
# print("==================================")
# 检查输入必须是 3 维:
# [B, N, D] = [batch_size, token 数量, embedding 维度]
torch._assert(input.dim() == 3, f"Expected (batch_size, seq_length, hidden_dim) got {input.shape}")
# -------------------------
# 第一部分:Self-Attention + 残差连接
# -------------------------
# Pre-Norm:先对输入做 LayerNorm。
x = self.ln_1(input)
# self_attention(query, key, value)
#
# 由于这里是 Self-Attention,所以 Q、K、V 全部来自同一个 x。
# need_weights=False 表示不返回 attention 权重,可以减少额外开销。
#
# 输出:
# x: [B, N, D]
# _: attention weights,这里不使用。
x, _ = self.self_attention(x, x, x, need_weights=False)
# 对 attention 输出做 dropout。
x = self.dropout(x)
# 残差连接:
# 原始输入 input 与 attention 输出相加。
x = x + input
# -------------------------
# 第二部分:MLP + 残差连接
# -------------------------
# 再次 Pre-Norm。
y = self.ln_2(x)
# 进入 MLP,形状仍然保持 [B, N, D]。
y = self.mlp(y)
# 第二次残差连接。
return x + y
class Encoder(nn.Module):
"""
ViT 中的 Transformer Encoder。
这里的 Encoder 负责三件事:
1. 定义可学习的位置编码 pos_embedding
2. 堆叠 num_layers 个 EncoderBlock
3. 在所有 EncoderBlock 之后再接一个 LayerNorm
注意:
这个类名和 NLP 中"sequence to sequence translation"的 Encoder 类似,
但在 ViT 里它处理的是图像 patch token 序列。
"""
def __init__(
self,
seq_length: int,
num_layers: int,
num_heads: int,
hidden_dim: int,
mlp_dim: int,
dropout: float,
attention_dropout: float,
norm_layer: Callable[..., torch.nn.Module] = partial(nn.LayerNorm, eps=1e-6),
):
"""
Args:
seq_length: token 序列长度。
对 ViT-B/16 且 224 输入来说:
196 个 patch token + 1 个 class token = 197。
num_layers: EncoderBlock 数量。ViT-B/16 中为 12。
num_heads: 每个 EncoderBlock 中的 attention head 数量。
hidden_dim: token embedding 维度。
mlp_dim: MLP 隐藏层维度。
dropout: token embedding 和 MLP 中的 dropout。
attention_dropout: attention 权重上的 dropout。
norm_layer: LayerNorm 构造函数。
"""
super().__init__()
# 注意:这里使用 batch_first=True,因此后续 token 序列形状是 [B, N, D]。
# pos_embedding 的形状是 [1, seq_length, hidden_dim]。
# 其中第 1 维为 1,是为了在 batch 维度上自动广播。
#
# ViT-B/16 中:
# seq_length = 197
# hidden_dim = 768
# pos_embedding = [1, 197, 768]
#
# normal_(std=0.02) 是 BERT/Transformer 中常见的位置编码初始化方式。
self.pos_embedding = nn.Parameter(torch.empty(1, seq_length, hidden_dim).normal_(std=0.02)) # from BERT
# 输入 token 加上位置编码之后的 dropout。
self.dropout = nn.Dropout(dropout)
# 用 OrderedDict 保存每一层 EncoderBlock,使打印模型结构时层名更清晰。
layers: OrderedDict[str, nn.Module] = OrderedDict()
# 堆叠 num_layers 个 Transformer EncoderBlock。
for i in range(num_layers):
layers[f"encoder_layer_{i}"] = EncoderBlock(
num_heads,
hidden_dim,
mlp_dim,
dropout,
attention_dropout,
norm_layer,
)
# 使用 nn.Sequential 顺序执行所有 EncoderBlock。
self.layers = nn.Sequential(layers)
# 所有 EncoderBlock 之后的最终 LayerNorm。
self.ln = norm_layer(hidden_dim)
def forward(self, input: torch.Tensor):
"""
Args:
input: [batch_size, seq_length, hidden_dim]
此时已经包含 class token。
Returns:
output: [batch_size, seq_length, hidden_dim]
"""
# 检查输入维度。
torch._assert(input.dim() == 3, f"Expected (batch_size, seq_length, hidden_dim) got {input.shape}")
# 加入位置编码。
# input: [B, N, D]
# pos_embedding: [1, N, D]
# 广播相加后仍为 [B, N, D]
input = input + self.pos_embedding
input=self.dropout(input)
input=self.layers(input)
input=self.ln(input)
return input
# Dropout -> 多层 EncoderBlock -> 最终 LayerNorm。
# return self.ln(self.layers(self.dropout(input)))
class VisionTransformer(nn.Module):
"""
Vision Transformer 主体类。
对应 ViT 原论文:
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
整体流程:
输入图像 [B, 3, H, W]
↓
conv_proj 完成 Patch Embedding
↓
reshape / permute 得到 patch token 序列 [B, num_patches, hidden_dim]
↓
拼接 class token
↓
Encoder 内部加入 position embedding 并通过多层 Transformer EncoderBlock
↓
取第 0 个 token,也就是 class token
↓
分类头 heads 输出类别 logits
"""
def __init__(
self,
image_size: int,
patch_size: int,
num_layers: int,
num_heads: int,
hidden_dim: int,
mlp_dim: int,
dropout: float = 0.0,
attention_dropout: float = 0.0,
num_classes: int = 1000,
representation_size: Optional[int] = None,
norm_layer: Callable[..., torch.nn.Module] = partial(nn.LayerNorm, eps=1e-6),
conv_stem_configs: Optional[List[ConvStemConfig]] = None,
):
"""
Args:
image_size: 输入图像大小。官方 ViT-B/16 默认 224。
patch_size: patch 大小。ViT-B/16 中为 16。
num_layers: Transformer EncoderBlock 数量。ViT-B/16 中为 12。
num_heads: attention head 数量。ViT-B/16 中为 12。
hidden_dim: token embedding 维度。ViT-B/16 中为 768。
mlp_dim: MLP 隐藏层维度。ViT-B/16 中为 3072。
dropout: dropout 概率。
attention_dropout: attention 权重 dropout 概率。
num_classes: 分类类别数,ImageNet-1K 为 1000。
representation_size: 如果不为 None,则在分类头前增加 pre_logits 层。
norm_layer: 归一化层,默认 LayerNorm(eps=1e-6)。
conv_stem_configs: 如果提供,则使用卷积 stem 替代单层 patch embedding。
"""
super().__init__()
# 记录 API 使用情况,torchvision 内部工具,不影响模型计算。
_log_api_usage_once(self)
# 输入图像尺寸必须能被 patch_size 整除,否则无法整齐切 patch。
# 例如 224 % 16 = 0。
torch._assert(image_size % patch_size == 0, "Input shape indivisible by patch size!")
# 保存模型核心超参数。
self.image_size = image_size
self.patch_size = patch_size
self.hidden_dim = hidden_dim
self.mlp_dim = mlp_dim
self.attention_dropout = attention_dropout
self.dropout = dropout
self.num_classes = num_classes
self.representation_size = representation_size
self.norm_layer = norm_layer
# ------------------------------------------------------------
# 1. Patch Embedding / Conv Stem
# ------------------------------------------------------------
if conv_stem_configs is not None:
# 如果用户提供了 conv_stem_configs,则使用卷积 stem。
# 这类设计来自一些改进 ViT 的工作:先用多层小卷积提取低级局部特征,
# 再投影到 Transformer 的 hidden_dim。
#
# 相比原始 ViT 的单层 patchify conv,这种方式引入了更强的 CNN 归纳偏置。
# As per https://arxiv.org/abs/2106.14881
seq_proj = nn.Sequential()
prev_channels = 3
# 依次添加 conv + norm + activation 模块。
for i, conv_stem_layer_config in enumerate(conv_stem_configs):
seq_proj.add_module(
f"conv_bn_relu_{i}",
Conv2dNormActivation(
in_channels=prev_channels,
out_channels=conv_stem_layer_config.out_channels,
kernel_size=conv_stem_layer_config.kernel_size,
stride=conv_stem_layer_config.stride,
norm_layer=conv_stem_layer_config.norm_layer,
activation_layer=conv_stem_layer_config.activation_layer,
),
)
prev_channels = conv_stem_layer_config.out_channels
# 最后一层 1x1 卷积,把通道数投影到 hidden_dim。
seq_proj.add_module(
"conv_last", nn.Conv2d(in_channels=prev_channels, out_channels=hidden_dim, kernel_size=1)
)
# self.conv_proj 统一表示图像到 patch embedding 的投影模块。
self.conv_proj: nn.Module = seq_proj
else:
# 原始 ViT 的 patch embedding 实现方式:
# 使用一个 Conv2d 来完成"不重叠切 patch + 线性投影"。
#
# 对 ViT-B/16:
# nn.Conv2d(3, 768, kernel_size=16, stride=16)
#
# 输入:
# [B, 3, 224, 224]
#
# 输出:
# [B, 768, 14, 14]
#
# 其中 14 x 14 = 196 个 patch。
self.conv_proj = nn.Conv2d(
in_channels=3, out_channels=hidden_dim, kernel_size=patch_size, stride=patch_size
)
# ------------------------------------------------------------
# 2. 计算 patch token 序列长度
# ------------------------------------------------------------
# patch token 数量:
# (image_size / patch_size) ^ 2
#
# ViT-B/16:
# (224 / 16)^2 = 14^2 = 196
seq_length = (image_size // patch_size) ** 2
# ------------------------------------------------------------
# 3. Class Token
# ------------------------------------------------------------
# class_token 是一个可学习参数,不来自图像本身。
#
# 形状:
# [1, 1, hidden_dim]
#
# forward 时会 expand 到:
# [B, 1, hidden_dim]
#
# 然后拼接到 patch token 序列最前面。
self.class_token = nn.Parameter(torch.zeros(1, 1, hidden_dim))
# 加入 class token 后,序列长度 +1。
# ViT-B/16:196 + 1 = 197。
seq_length += 1
# ------------------------------------------------------------
# 4. Transformer Encoder
# ------------------------------------------------------------
# Encoder 内部会:
# 1. 定义 position embedding
# 2. 堆叠 num_layers 个 EncoderBlock
# 3. 做最后一层 LayerNorm
self.encoder = Encoder(
seq_length,
num_layers,
num_heads,
hidden_dim,
mlp_dim,
dropout,
attention_dropout,
norm_layer,
)
# 保存最终 token 序列长度。
self.seq_length = seq_length
# ------------------------------------------------------------
# 5. 分类头 heads
# ------------------------------------------------------------
heads_layers: OrderedDict[str, nn.Module] = OrderedDict()
if representation_size is None:
# 标准情况:直接用 hidden_dim -> num_classes 的 Linear 做分类。
#
# ViT-B/16 ImageNet:
# Linear(768, 1000)
heads_layers["head"] = nn.Linear(hidden_dim, num_classes)
else:
# 如果 representation_size 不为 None,则添加一个 pre_logits 层。
#
# 结构:
# Linear(hidden_dim -> representation_size)
# Tanh
# Linear(representation_size -> num_classes)
#
# 这是早期 ViT / JAX 实现中可能出现的 representation layer。
heads_layers["pre_logits"] = nn.Linear(hidden_dim, representation_size)
heads_layers["act"] = nn.Tanh()
heads_layers["head"] = nn.Linear(representation_size, num_classes)
# 使用 Sequential 包装分类头。
self.heads = nn.Sequential(heads_layers)
# ------------------------------------------------------------
# 6. 权重初始化
# ------------------------------------------------------------
if isinstance(self.conv_proj, nn.Conv2d):
# 如果使用的是标准 patchify stem,即单个 Conv2d,则初始化该卷积层。
#
# fan_in = 输入通道数 * kernel_h * kernel_w。
# 对 ViT-B/16:
# fan_in = 3 * 16 * 16 = 768
#
# std = sqrt(1 / fan_in)。
fan_in = self.conv_proj.in_channels * self.conv_proj.kernel_size[0] * self.conv_proj.kernel_size[1]
# 截断正态分布初始化 patch embedding 卷积权重。
nn.init.trunc_normal_(self.conv_proj.weight, std=math.sqrt(1 / fan_in))
# bias 初始化为 0。
if self.conv_proj.bias is not None:
nn.init.zeros_(self.conv_proj.bias)
elif self.conv_proj.conv_last is not None and isinstance(self.conv_proj.conv_last, nn.Conv2d):
# 如果使用 conv stem,则初始化最后一个 1x1 conv。
nn.init.normal_(
self.conv_proj.conv_last.weight, mean=0.0, std=math.sqrt(2.0 / self.conv_proj.conv_last.out_channels)
)
if self.conv_proj.conv_last.bias is not None:
nn.init.zeros_(self.conv_proj.conv_last.bias)
# 如果存在 pre_logits 层,则初始化它。
if hasattr(self.heads, "pre_logits") and isinstance(self.heads.pre_logits, nn.Linear):
fan_in = self.heads.pre_logits.in_features
nn.init.trunc_normal_(self.heads.pre_logits.weight, std=math.sqrt(1 / fan_in))
nn.init.zeros_(self.heads.pre_logits.bias)
# 分类头最后一层初始化为 0。
# 注意:加载预训练权重时,这些初始化值会被 checkpoint 覆盖。
if isinstance(self.heads.head, nn.Linear):
nn.init.zeros_(self.heads.head.weight)
nn.init.zeros_(self.heads.head.bias)
def _process_input(self, x: torch.Tensor) -> torch.Tensor:
"""
将输入图像转换为 patch token 序列。
输入:
x: [n, c, h, w]
输出:
x: [n, num_patches, hidden_dim]
对 ViT-B/16:
输入:
[B, 3, 224, 224]
conv_proj 后:
[B, 768, 14, 14]
reshape 后:
[B, 768, 196]
permute 后:
[B, 196, 768]
"""
# n: batch size
# c: channel 数,RGB 图像通常是 3
# h: 图像高度
# w: 图像宽度
n, c, h, w = x.shape
# patch 大小。
p = self.patch_size
# 官方实现要求输入图像大小必须等于模型构建时的 image_size。
# 如果使用不同分辨率,需要重新构建模型并处理 position embedding。
torch._assert(h == self.image_size, f"Wrong image height! Expected {self.image_size} but got {h}!")
torch._assert(w == self.image_size, f"Wrong image width! Expected {self.image_size} but got {w}!")
# patch 网格的高和宽。
# 例如 224 / 16 = 14。
n_h = h // p
n_w = w // p
# ------------------------------------------------------------
# 1. Patch Embedding
# ------------------------------------------------------------
# (n, c, h, w) -> (n, hidden_dim, n_h, n_w)
#
# 对 ViT-B/16:
# [B, 3, 224, 224] -> [B, 768, 14, 14]
x = self.conv_proj(x)
# ------------------------------------------------------------
# 2. 展平 patch 网格
# ------------------------------------------------------------
# (n, hidden_dim, n_h, n_w) -> (n, hidden_dim, n_h * n_w)
#
# 对 ViT-B/16:
# [B, 768, 14, 14] -> [B, 768, 196]
x = x.reshape(n, self.hidden_dim, n_h * n_w)
# ------------------------------------------------------------
# 3. 调整维度顺序,得到 Transformer 需要的 token 序列格式
# ------------------------------------------------------------
# (n, hidden_dim, n_h * n_w) -> (n, n_h * n_w, hidden_dim)
#
# 对 ViT-B/16:
# [B, 768, 196] -> [B, 196, 768]
#
# 由于 EncoderBlock 中 nn.MultiheadAttention 设置了 batch_first=True,
# 所以它期望输入格式是:
# [batch_size, seq_length, embedding_dim]
x = x.permute(0, 2, 1)
return x
def forward(self, x: torch.Tensor):
"""
ViT 前向传播流程。
输入:
x: [B, 3, image_size, image_size]
输出:
logits: [B, num_classes]
"""
# 1. 图像转 patch token。
# [B, 3, 224, 224] -> [B, 196, 768]
x = self._process_input(x)
# batch size。
n = x.shape[0]
# 2. 扩展 class token 到整个 batch。
#
# self.class_token: [1, 1, hidden_dim]
# expand 后:
# [B, 1, hidden_dim]
#
# expand 不会真正复制数据,只是创建一个广播视图,内存更省。
batch_class_token = self.class_token.expand(n, -1, -1)
# 3. 将 class token 拼接到 patch token 序列最前面。
#
# patch tokens:
# [B, 196, 768]
# class token:
# [B, 1, 768]
# concat 后:
# [B, 197, 768]
x = torch.cat([batch_class_token, x], dim=1)
# 4. 输入 Transformer Encoder。
#
# Encoder 内部会先加 position embedding:
# [B, 197, 768] + [1, 197, 768]
#
# 然后经过 12 个 EncoderBlock。
x = self.encoder(x)
# 5. 取第 0 个 token,即 class token 的最终输出。
#
# x: [B, 197, 768]
# x[:, 0]: [B, 768]
#
# 这个 class token 表示整张图像的全局特征。
x = x[:, 0]
# 6. 分类头输出 logits。
#
# [B, 768] -> [B, num_classes]
x = self.heads(x)
return x
def _vision_transformer(
patch_size: int,
num_layers: int,
num_heads: int,
hidden_dim: int,
mlp_dim: int,
weights: Optional[WeightsEnum],
progress: bool,
**kwargs: Any,
) -> VisionTransformer:
"""
Torchvision 内部用于构建 VisionTransformer 的通用函数。
不同 ViT 变体,例如 vit_b_16、vit_b_32、vit_l_16,本质上都是调用这个函数,
只是传入的参数不同。
对 ViT-B/16,典型参数为:
patch_size = 16
num_layers = 12
num_heads = 12
hidden_dim = 768
mlp_dim = 3072
"""
if weights is not None:
# 如果使用预训练权重,则用权重元信息覆盖 num_classes。
# 例如 ImageNet-1K 权重对应 1000 类。
_ovewrite_named_param(kwargs, "num_classes", len(weights.meta["categories"]))
# 权重元信息中的 min_size 应该是正方形,例如 (224, 224) 或 (384, 384)。
assert weights.meta["min_size"][0] == weights.meta["min_size"][1]
# 如果使用权重,则把 image_size 设置为该权重要求的最小输入尺寸。
# 例如 IMAGENET1K_V1 是 224,SWAG_E2E_V1 是 384。
_ovewrite_named_param(kwargs, "image_size", weights.meta["min_size"][0])
# 如果 kwargs 中没有 image_size,则默认 224。
image_size = kwargs.pop("image_size", 224)
# 创建 VisionTransformer 模型。
model = VisionTransformer(
image_size=image_size,
patch_size=patch_size,
num_layers=num_layers,
num_heads=num_heads,
hidden_dim=hidden_dim,
mlp_dim=mlp_dim,
**kwargs,
)
# 如果提供了预训练权重,则加载 state_dict。
if weights:
model.load_state_dict(weights.get_state_dict(progress=progress))
return model
# 通用元信息:ImageNet 类别名称。
_COMMON_META: Dict[str, Any] = {
"categories": _IMAGENET_CATEGORIES,
}
# SWAG 权重的通用元信息。
_COMMON_SWAG_META = {
**_COMMON_META,
"recipe": "https://github.com/facebookresearch/SWAG",
"license": "https://github.com/facebookresearch/SWAG/blob/main/LICENSE",
}
class ViT_B_16_Weights(WeightsEnum):
"""
ViT-B/16 的官方预训练权重枚举。
Torchvision 新版推荐通过 weights 参数加载权重,例如:
from torchvision.models import vit_b_16, ViT_B_16_Weights
weights = ViT_B_16_Weights.DEFAULT
model = vit_b_16(weights=weights)
这个类中定义了多个 ViT-B/16 权重版本:
1. IMAGENET1K_V1
2. IMAGENET1K_SWAG_E2E_V1
3. IMAGENET1K_SWAG_LINEAR_V1
"""
IMAGENET1K_V1 = Weights(
# 权重下载地址。
url="https://download.pytorch.org/models/vit_b_16-c867db91.pth",
# 对应的图像预处理方式。
# ImageClassification(crop_size=224) 通常包含 resize、center crop、to tensor、normalize 等步骤。
transforms=partial(ImageClassification, crop_size=224),
# 权重元信息。
meta={
**_COMMON_META,
# 模型参数量。
"num_params": 86567656,
# 该权重对应的最小输入尺寸。
"min_size": (224, 224),
# 训练 recipe 链接。
"recipe": "https://github.com/pytorch/vision/tree/main/references/classification#vit_b_16",
# ImageNet-1K 上的精度指标。
"_metrics": {
"ImageNet-1K": {
"acc@1": 81.072,
"acc@5": 95.318,
}
},
# 计算量,单位通常是 GMACs 或类似统计。
"_ops": 17.564,
# 权重文件大小,单位 MB。
"_file_size": 330.285,
# 文档说明。
"_docs": """
These weights were trained from scratch by using a modified version of `DeIT
<https://arxiv.org/abs/2012.12877>`_'s training recipe.
""",
},
)
IMAGENET1K_SWAG_E2E_V1 = Weights(
# SWAG E2E fine-tuning 权重。
url="https://download.pytorch.org/models/vit_b_16_swag-9ac1b537.pth",
# 这个权重使用 384x384 输入,且使用 bicubic 插值。
transforms=partial(
ImageClassification,
crop_size=384,
resize_size=384,
interpolation=InterpolationMode.BICUBIC,
),
meta={
**_COMMON_SWAG_META,
"num_params": 86859496,
"min_size": (384, 384),
"_metrics": {
"ImageNet-1K": {
"acc@1": 85.304,
"acc@5": 97.650,
}
},
"_ops": 55.484,
"_file_size": 331.398,
"_docs": """
These weights are learnt via transfer learning by end-to-end fine-tuning the original
`SWAG <https://arxiv.org/abs/2201.08371>`_ weights on ImageNet-1K data.
""",
},
)
IMAGENET1K_SWAG_LINEAR_V1 = Weights(
# SWAG frozen trunk + linear classifier 权重。
url="https://download.pytorch.org/models/vit_b_16_lc_swag-4e70ced5.pth",
# 输入尺寸为 224x224,bicubic 插值。
transforms=partial(
ImageClassification,
crop_size=224,
resize_size=224,
interpolation=InterpolationMode.BICUBIC,
),
meta={
**_COMMON_SWAG_META,
"recipe": "https://github.com/pytorch/vision/pull/5793",
"num_params": 86567656,
"min_size": (224, 224),
"_metrics": {
"ImageNet-1K": {
"acc@1": 81.886,
"acc@5": 96.180,
}
},
"_ops": 17.564,
"_file_size": 330.285,
"_docs": """
These weights are composed of the original frozen `SWAG <https://arxiv.org/abs/2201.08371>`_ trunk
weights and a linear classifier learnt on top of them trained on ImageNet-1K data.
""",
},
)
# DEFAULT 表示默认权重。
# 使用 ViT_B_16_Weights.DEFAULT 时,实际使用 IMAGENET1K_V1。
DEFAULT = IMAGENET1K_V1
def interpolate_embeddings(
image_size: int,
patch_size: int,
model_state: "OrderedDict[str, torch.Tensor]",
interpolation_mode: str = "bicubic",
reset_heads: bool = False,
) -> "OrderedDict[str, torch.Tensor]":
"""
对 position embedding 进行插值,用于加载不同输入分辨率的预训练权重。
为什么需要这个函数?
------------------------------------------------------------
ViT 的 position embedding 形状与 token 数量有关。
例如 ViT-B/16:
输入 224x224:
patch 网格 = 14x14
patch token = 196
加 CLS 后 seq_length = 197
pos_embedding = [1, 197, 768]
输入 384x384:
patch 网格 = 24x24
patch token = 576
加 CLS 后 seq_length = 577
pos_embedding = [1, 577, 768]
如果想把 224 训练好的权重加载到 384 输入的模型中,
position embedding 的长度对不上,就需要把原来的 14x14 位置编码
插值到 24x24。
但 class token 对应的位置编码不属于二维网格,因此不能参与插值,
需要单独拆出来保留。
Args:
image_size: 新模型的输入图像大小。
patch_size: 新模型的 patch 大小。
model_state: 预训练模型的 state_dict。
interpolation_mode: 插值方式,默认 bicubic。
reset_heads: 是否丢弃分类头参数。
当类别数不同或者输入尺寸变化较大时,常设置 True。
Returns:
修改后的 state_dict,可以用于新模型加载。
"""
# 取出原始 position embedding。
# 形状是 [1, seq_length, hidden_dim]。
pos_embedding = model_state["encoder.pos_embedding"]
# n 通常必须为 1,因为 position embedding 在 batch 维度上共享。
n, seq_length, hidden_dim = pos_embedding.shape
if n != 1:
raise ValueError(f"Unexpected position embedding shape: {pos_embedding.shape}")
# 新模型需要的序列长度:
# patch token 数量 + 1 个 class token
#
# 例如 image_size=384, patch_size=16:
# (384 / 16)^2 + 1 = 24^2 + 1 = 577
new_seq_length = (image_size // patch_size) ** 2 + 1
# 如果新旧 seq_length 不一样,说明需要插值。
if new_seq_length != seq_length:
# ------------------------------------------------------------
# 1. 将 class token 的位置编码和图像 patch 位置编码分离
# ------------------------------------------------------------
# 去掉 class token 后,剩下的是图像 patch token 数量。
seq_length -= 1
new_seq_length -= 1
# class token 的位置编码,形状 [1, 1, hidden_dim]。
# 它不参与二维插值,后面直接拼回去。
pos_embedding_token = pos_embedding[:, :1, :]
# 图像 patch 的位置编码,形状 [1, seq_length, hidden_dim]。
pos_embedding_img = pos_embedding[:, 1:, :]
# ------------------------------------------------------------
# 2. 将位置编码从一维 token 序列变成二维网格
# ------------------------------------------------------------
# [1, seq_length, hidden_dim] -> [1, hidden_dim, seq_length]
# 这样方便后续 reshape 成 [1, hidden_dim, H, W]。
pos_embedding_img = pos_embedding_img.permute(0, 2, 1)
# 原始 patch 网格边长。
# 例如 seq_length=196,则 sqrt(196)=14。
seq_length_1d = int(math.sqrt(seq_length))
# 位置编码必须能还原成正方形网格。
# 如果不是完全平方数,说明该 position embedding 不是标准二维 patch 网格。
if seq_length_1d * seq_length_1d != seq_length:
raise ValueError(
f"seq_length is not a perfect square! Instead got seq_length_1d * seq_length_1d = {seq_length_1d * seq_length_1d } and seq_length = {seq_length}"
)
# [1, hidden_dim, seq_length] -> [1, hidden_dim, seq_l_1d, seq_l_1d]
#
# 例如:
# [1, 768, 196] -> [1, 768, 14, 14]
pos_embedding_img = pos_embedding_img.reshape(1, hidden_dim, seq_length_1d, seq_length_1d)
# 新的 patch 网格边长。
# 例如 image_size=384, patch_size=16,则 new_seq_length_1d=24。
new_seq_length_1d = image_size // patch_size
# ------------------------------------------------------------
# 3. 对二维位置编码进行插值
# ------------------------------------------------------------
# [1, hidden_dim, old_h, old_w] -> [1, hidden_dim, new_h, new_w]
#
# 例如:
# [1, 768, 14, 14] -> [1, 768, 24, 24]
new_pos_embedding_img = nn.functional.interpolate(
pos_embedding_img,
size=new_seq_length_1d,
mode=interpolation_mode,
align_corners=True,
)
# ------------------------------------------------------------
# 4. 将二维网格重新展平成一维 token 序列
# ------------------------------------------------------------
# [1, hidden_dim, new_h, new_w] -> [1, hidden_dim, new_h * new_w]
#
# 例如:
# [1, 768, 24, 24] -> [1, 768, 576]
new_pos_embedding_img = new_pos_embedding_img.reshape(1, hidden_dim, new_seq_length)
# [1, hidden_dim, new_seq_length] -> [1, new_seq_length, hidden_dim]
#
# 例如:
# [1, 768, 576] -> [1, 576, 768]
new_pos_embedding_img = new_pos_embedding_img.permute(0, 2, 1)
# 将 class token 的位置编码拼回最前面。
#
# [1, 1, hidden_dim] + [1, new_seq_length, hidden_dim]
# -> [1, new_seq_length + 1, hidden_dim]
new_pos_embedding = torch.cat([pos_embedding_token, new_pos_embedding_img], dim=1)
# 更新 state_dict 中的位置编码。
model_state["encoder.pos_embedding"] = new_pos_embedding
# ------------------------------------------------------------
# 5. 可选:重置分类头
# ------------------------------------------------------------
if reset_heads:
# 当新任务类别数不同,或者不想沿用旧分类头时,
# 可以删除所有以 heads 开头的参数。
model_state_copy: "OrderedDict[str, torch.Tensor]" = OrderedDict()
for k, v in model_state.items():
if not k.startswith("heads"):
model_state_copy[k] = v
model_state = model_state_copy
return model_state