自然语言处理-入门 语音识别
个人导航
知乎:https://www.zhihu.com/people/byzh_rc
CSDN:https://blog.csdn.net/qq_54636039
注:本文仅对所述内容做了框架性引导,具体细节可查询其余相关资料or源码
参考文章:各方资料
文章目录
- [自然语言处理-入门 语音识别](#[自然语言处理-入门] 语音识别)
- 个人导航
- [词元 Token](#词元 Token)
-
-
- [1. 语音Speech & 文本Text](#1. 语音Speech & 文本Text)
- [2. Token](#2. Token)
-
- [声学特征 Acoustic Feature](#声学特征 Acoustic Feature)
- [序列到序列基础 Sequence to Sequence](#序列到序列基础 Sequence to Sequence)
- [Seq2Seq 主流模型](#Seq2Seq 主流模型)
-
-
-
- [1. LAS (Listen, Attend and Spell)](#1. LAS (Listen, Attend and Spell))
- [2. CTC (Connectionist Temporal Classification)](#2. CTC (Connectionist Temporal Classification))
- [3. RNN-T](#3. RNN-T)
- [4. Neural Transducer](#4. Neural Transducer)
- [5. MoChA](#5. MoChA)
-
-
词元 Token
1. 语音Speech & 文本Text

语音: 长度 T、维度 d 的向量序列
语音 = 第 1 片数字,第 2 片数字,......,第 T 片数字
- T:声音被切成了多少片
- d:每一片声音用多少个数字表示
比如 MFCC 用 39 个数字描述一帧 → d=39
(MFCC: 传统语音识别最常用 -> 把声音变成稳定、好识别的特征向量)
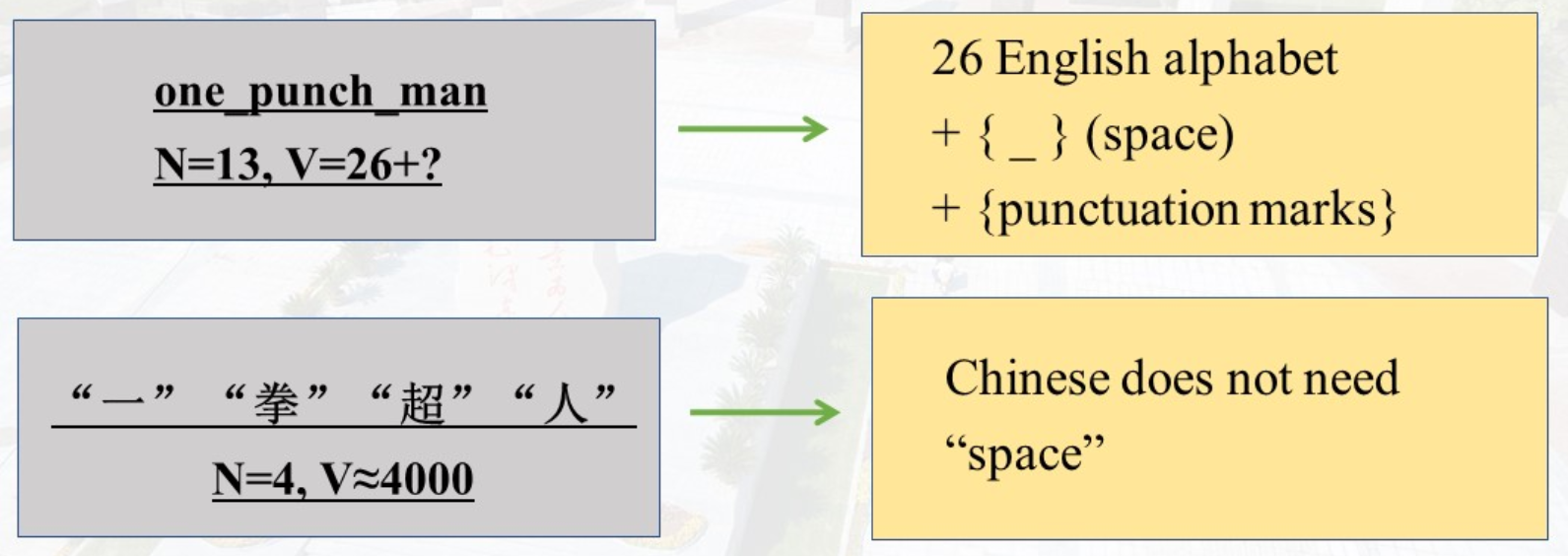
文本: 长度 N、共 V 种不同 Token 的序列
文本 = 第 1 个 Token,第 2 个 Token,......,第 N 个 Token
- N:这句话有多少个 Token
- V:世界上一共有多少种不同的 Token
英文字母:V≈26 + 符号
中文常用字:V≈4000
2. Token
语音识别最终要把声音转成符号序列,要懂这 5 种 T
-
Phoneme(音素) :声音最小单位,单词由音素组成
cat = /k/ + /æ/ + /t/
good = /g/ + /ʌ/ + /d/
-
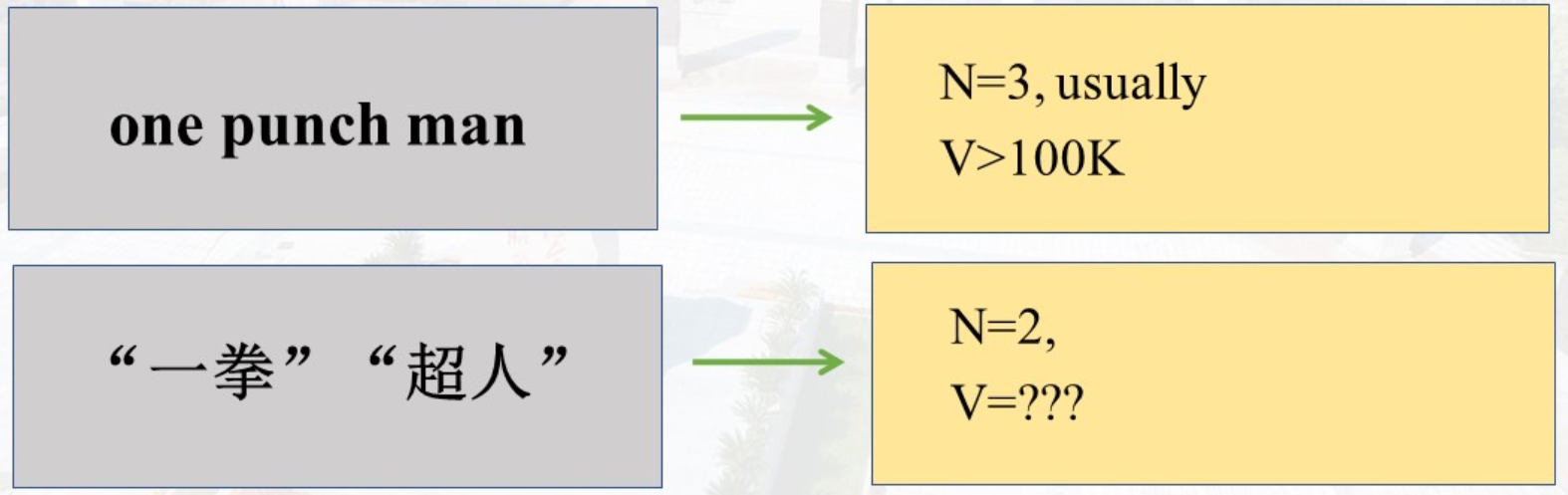
Grapheme(字素):书写最小单位 (英文字母/汉字)
英文:字母 a-z
中文:一个字
-
Morpheme(词素):最小有意义单位 (比单词小,比字母大)
unbreakable → un + break + able
-
Word(单词):完整语义单位,词表大 (V大)
-
Byte(字节):跨语言通用, 用 0/1 表示, 词表固定 256
声学特征 Acoustic Feature
把人耳听到的声音 → 变成电脑能看懂的数字
语音信号要先转成向量才能进模型
常用特征:MFCC(39 维)、Filter Bank(80 维)、语谱图Spectrogram
- MFCC: 最经典,维度 39 维
- FBank: 深度学习最常用,维度 80 维
- Spectrogram: 声音的 "图像",像热力图
处理流程:
- FBank 流程: 波形 → 分帧 → FFT → 梅尔滤波 → 对数 → 80 维 FBank
- MFCC 流程: 波形 → 分帧 → FFT → 梅尔滤波 → 对数 → DCT → 39 维 MFCC
FBank 是基础特征,MFCC 是 FBank 做 DCT 压缩后的特征
序列到序列基础 Sequence to Sequence
核心结构:Encoder + Decoder
- Encoder:把语音序列编码成上下文向量 C
- Decoder:用 C 自回归 生成文本,直到
<EOS>结束 - 基础网络:RNN、LSTM
-> 局限:早期只用最后一个状态做上下文,信息丢失
Seq2Seq 主流模型
1. LAS (Listen, Attend and Spell)
典型带注意力的 seq2seq
- Listen:编码, 语音特征
- Attend:注意力, 加权语音帧
- Spell:解码, 自回归生成文本
训练用Teacher Forcing(用真实标签加速)
2. CTC (Connectionist Temporal Classification)
每一帧语音独立输出一个符号,最后合并去空
输入:T 帧语音 → 输出:T 个符号(包含空白符 φ)
-
规则:合并重复字符 + 去掉空白 φ
φ φ d d φ e φ e φ p p→ deep
φ φ d d φ e e e φ p p→ dep
好 好 棒 棒 棒 棒 棒→ 好棒
好 φ 棒 φ 棒 φ φ→ 好棒棒
-
训练:自动枚举所有可能对齐,不用人工标对齐
-
缺点:各帧独立预测,没有上下文语言关系
-
地位:语音识别对齐基石,现在常和 LAS 一起用
3. RNN-T
一帧语音可以输出多个字,支持真正流式
(流式识别常用)
- 改进 CTC:一帧 → 多符号,不是只能一帧一个
- 自带语言模型,能利用上文输出决定下文
- 可以一边说话一边出字,不用等整句话
- 地位:手机 / 语音助手标配
4. Neural Transducer
按 窗口(window) 一块一块读语音的 RNN-T
- 不是一帧一帧,而是一次看一小段窗口
- 加了注意力,效果更好
- 介于 RNN-T 和 MoChA 之间
5. MoChA
MoChA: Monotonic Chunkwise Attention -> 最高级、速度快
窗口会自己动、自己选位置的最强流式注意力
- 自动决定要不要输出、窗口要不要移
- 注意力只看局部,又快又准
- 流式 + 高精度 = 目前最先进方案之一