word2vec 中 W_in、h、W_out 的作用
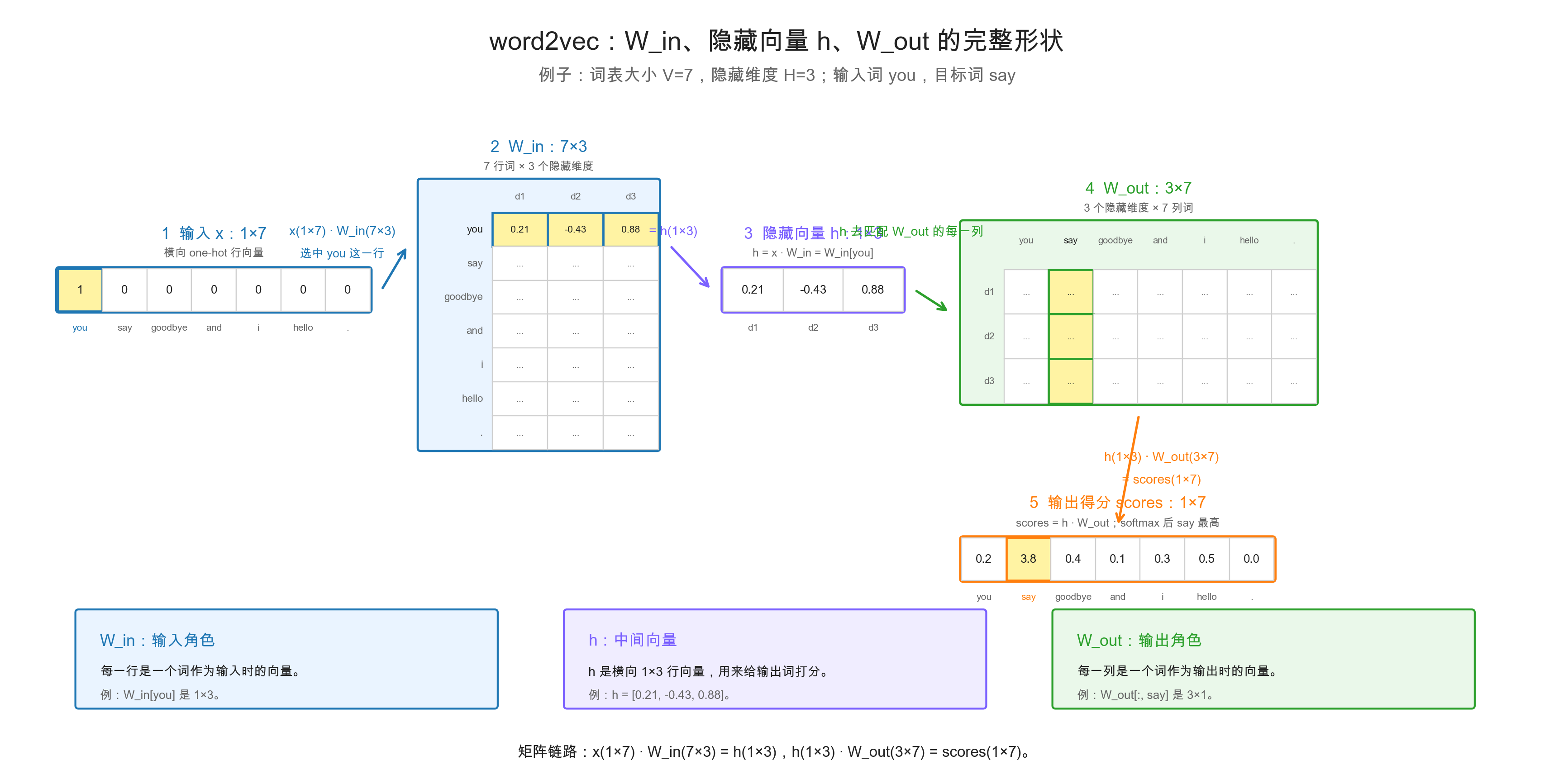
例子:
text
词表大小 V = 7
隐藏维度 H = 3
输入词:you
目标词:say1. W_in 做什么?
W_in 是输入侧矩阵。
text
you_one_hot · W_in = h
形状:
1×7 · 7×3 = 1×3因为 you_one_hot 只有 you 的位置是 1,所以乘 W_in 等于取出 W_in 的 you 这一行。
所以:
text
W_in[you] = you 作为输入词时的向量 = h
形状:
W_in[you] 是 1×3
h 也是 1×3它表示:看到 you 后,模型带着什么信息去预测周围词。
2. h 长什么样?
h 是一个普通数字向量,形状是 1×3:
text
h = [0.21, -0.43, 0.88]它不是 one-hot,也不是概率。
在这个例子里:
text
h = W_in[you]所以 h 就是 you 的输入侧词向量。
3. h 用来干什么?
h 用来和 W_out 的每一列做点积,给每个候选输出词打分:
text
scores = h · W_out
形状:
1×3 · 3×7 = 1×7展开看就是:
text
score(you) = h · W_out[:, you]
score(say) = h · W_out[:, say]
score(.) = h · W_out[:, .]如果:
text
h · W_out[:, say]最大,那么模型就倾向于预测 say。
4. W_out 做什么?
W_out 是输出侧矩阵。
text
W_out[:, say] = say 作为输出词时的向量
形状:
W_out[:, say] 是 3×1它表示:什么样的 h 应该把 say 预测出来。
5. 最短总结
text
x(1×7) · W_in(7×3) = h(1×3)
h(1×3) · W_out(3×7) = scores(1×7)
text
W_in:把输入词 you 变成隐藏向量 h。
h:拿去和每个候选输出词做匹配。
W_out:存放每个候选输出词的向量,用来打分。所以:
text
W_in 的行:词作为输入时的向量。
W_out 的列:词作为输出时的向量。