
2018
文章目录
- [1、Basic Idea of GAN](#1、Basic Idea of GAN)
- [2、GAN as Structured Learning](#2、GAN as Structured Learning)
- [3、Can Generator Learn by Itself?](#3、Can Generator Learn by Itself?)
- [4、Can Discriminator generate?](#4、Can Discriminator generate?)
- 参考
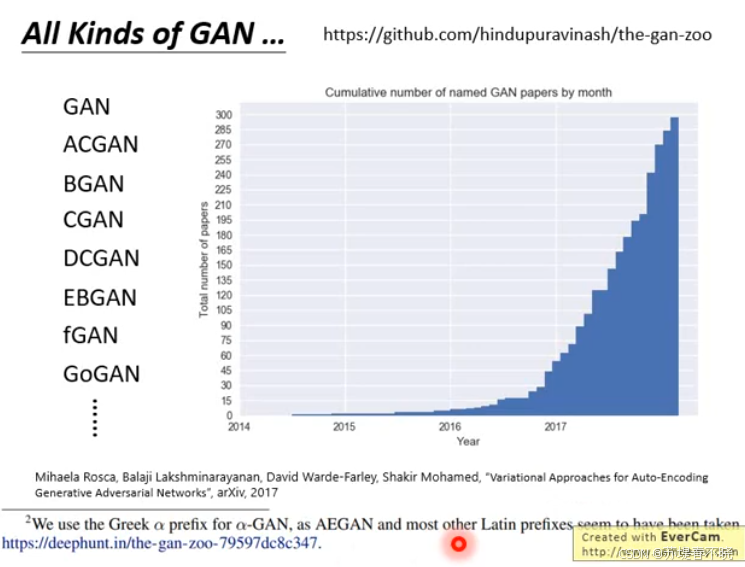
All kinds of GAN
The GAN zoo
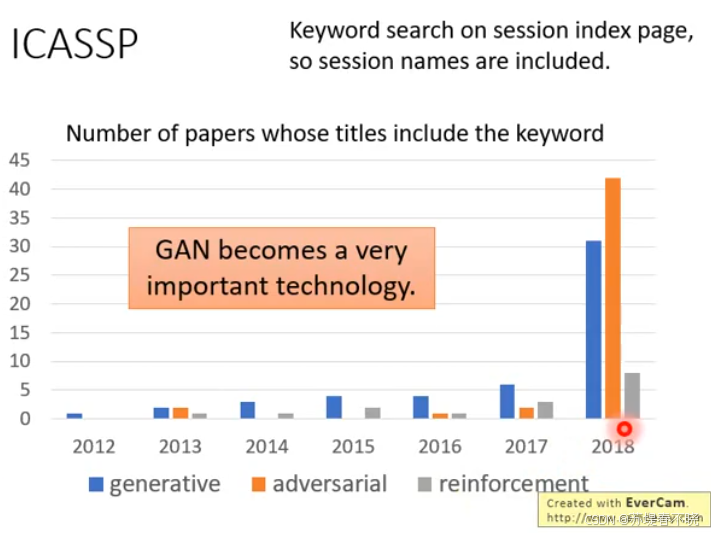
ICASSP 会议可以看出,GAN 变化趋势,becomes a very important technology
1、Basic Idea of GAN
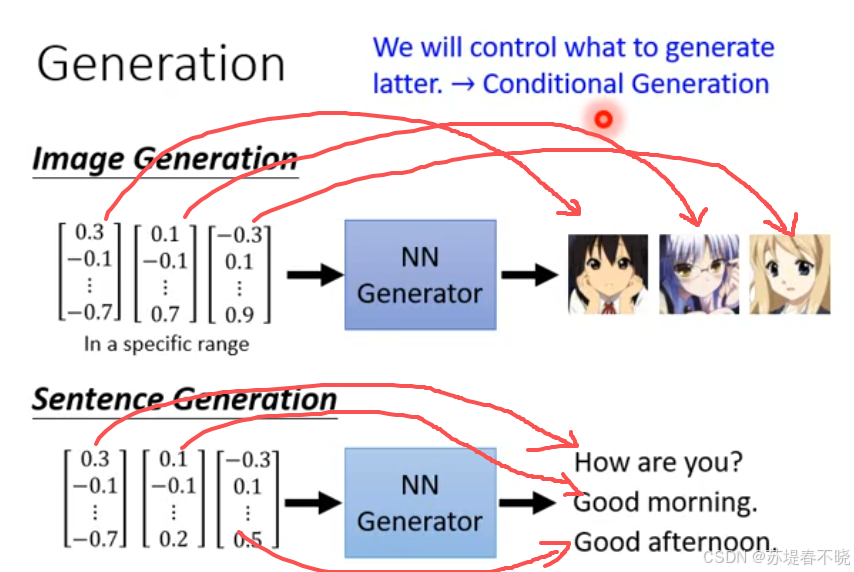
Conditional Generation
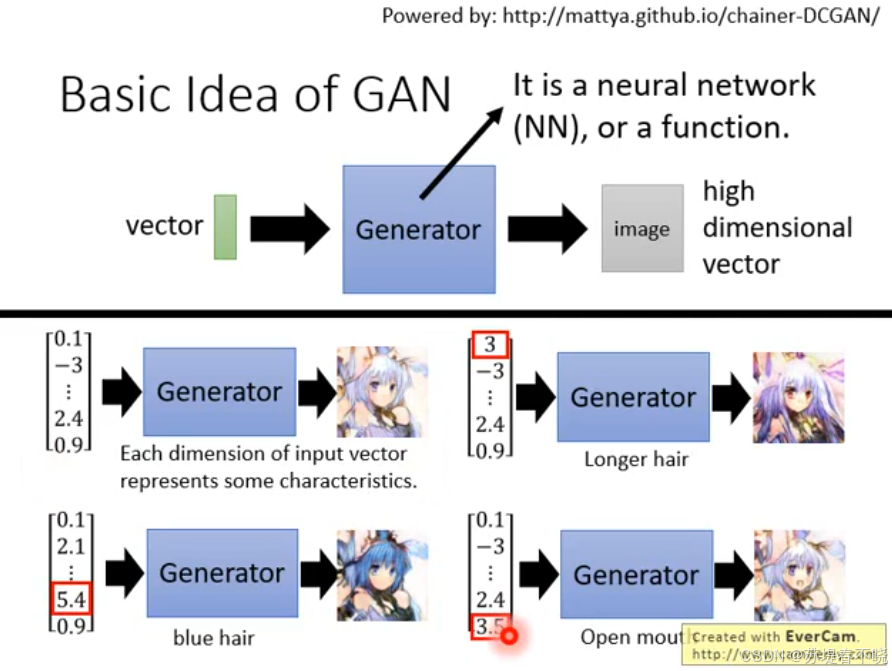
vector -> neural network -> high dimensional vector
each dimension of input vector represents some characteristics,eg 眼睛颜色、头发颜色、嘴巴开闭
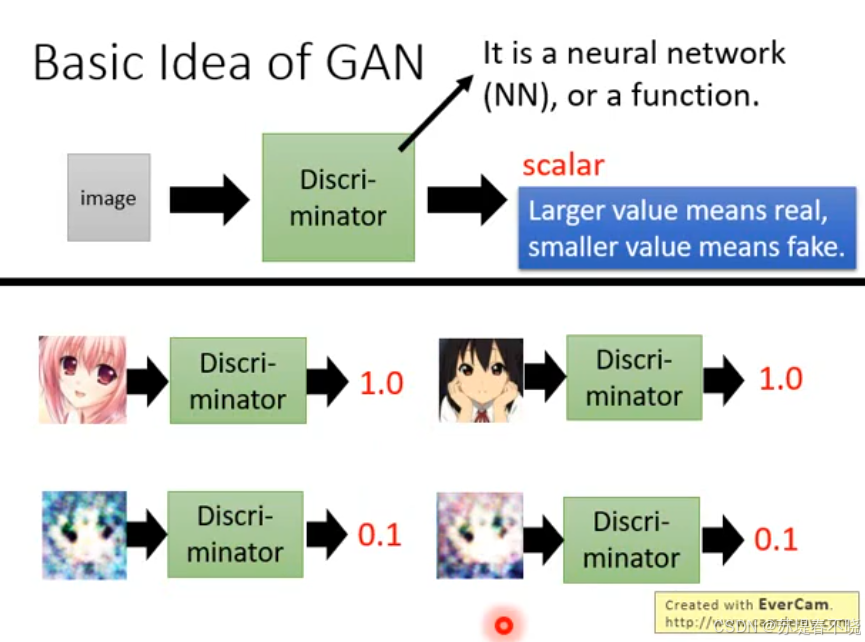
image -> discriminator -> scalar,larger value means real,smaller value means fake.
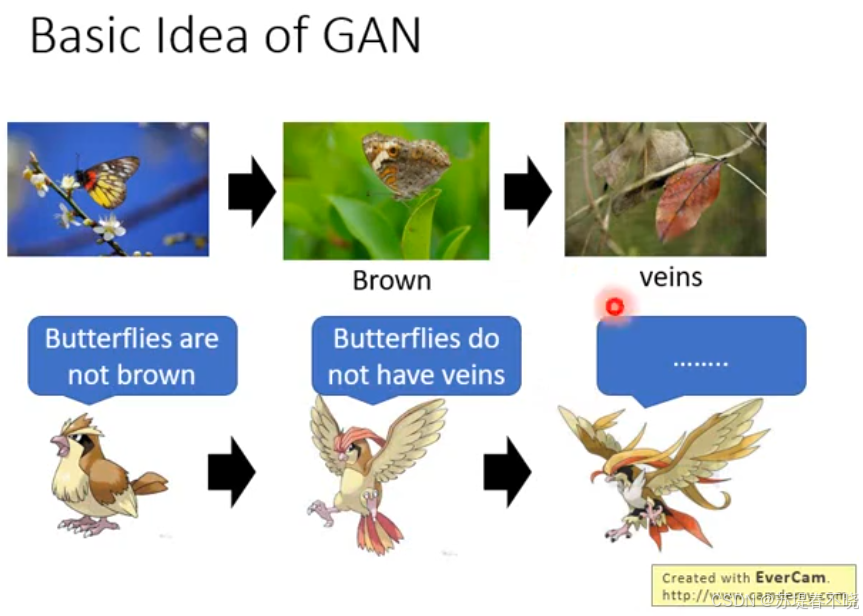
GAN 的 generator 和 discriminator 就像猎食者和天敌,交替进化
上面的例子是枯叶蝶和其天敌之间的进化过程
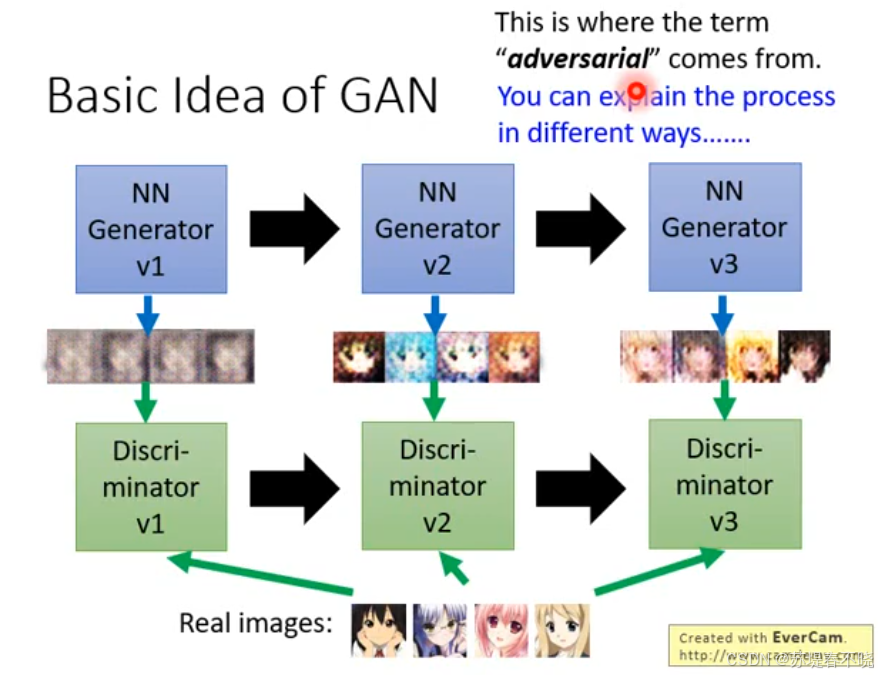
this is where the term 'adversarial' comes from.
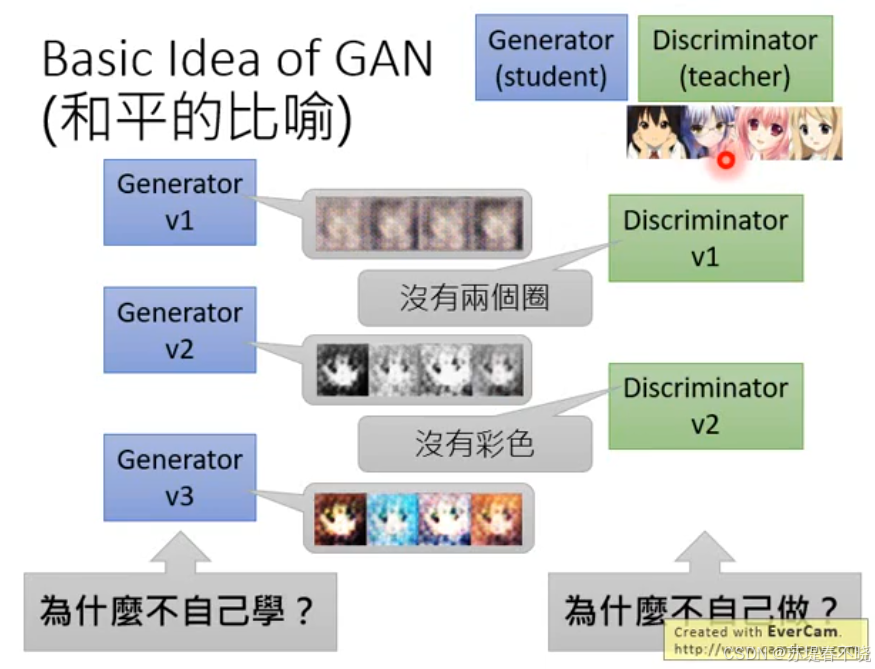
Basic Idea of GAN(不要用警察和小偷视角看)
-
一年级的学生 vs 一年级老师
-
二年级的学生 vs 二年级老师
合作的视角来看待 GAN
问题:
-
generator 为什么不自己学?(非要discriminator 来判断,非要老师来教)
-
discriminator 为什么不自己做?(老师为什么都是用嘴巴编程,哈哈哈)

写作敌人,念作朋友
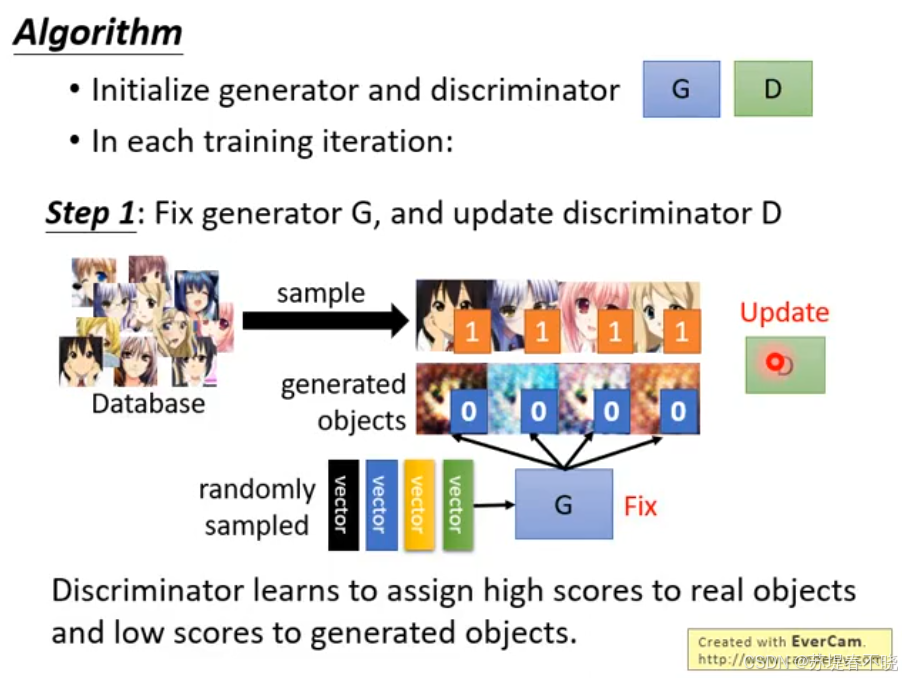
in each training iteration
- Step1:Fix generator G,and update discriminator D(discriminator learns to assign high scores to real objects and low scores to generated objects)
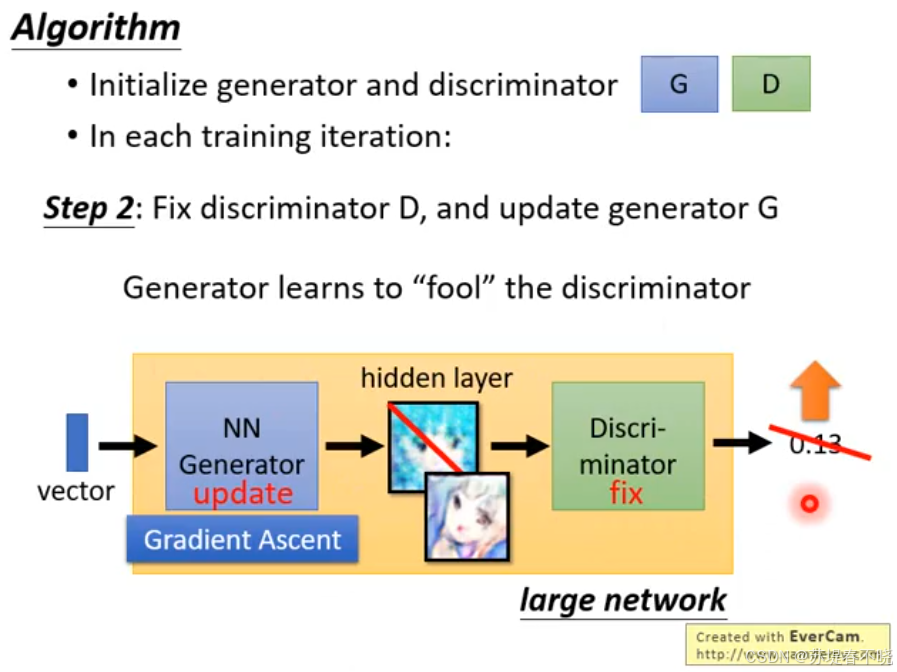
Step2:Fix discriminator D,and update generator G(generator learns to 'fool' the discriminator,G 为下一次 D 的 train 生成高质量 negative samples)

标准训练算法流程。将训练过程分为两个主要部分:判别器(Discriminator, D) 的学习和 生成器(Generator, G) 的学习。
(1)初始化 (Initialization)
- θ d \theta_d θd 和 θ g \theta_g θg:分别代表判别器和生成器的网络参数。在训练开始前,需要对它们进行随机初始化。
(2)学习判别器 (Learning D)
判别器的目标是"鉴宝师",它需要准确区分真实数据和伪造数据。
- 采样 :从数据库中提取 m m m 个真实样本 { x 1 , . . . , x m } \{x^1, ..., x^m\} {x1,...,xm},并从先验分布(通常是高斯噪声)中提取 m m m 个噪声样本 { z 1 , . . . , z m } \{z^1, ..., z^m\} {z1,...,zm}。
- 生成数据 :通过生成器将噪声转化为伪造数据 x ~ i = G ( z i ) \tilde{x}^i = G(z^i) x~i=G(zi)。
- 目标函数 V ~ \tilde{V} V~ :判别器试图最大化 这个函数:
V ~ = 1 m ∑ i = 1 m log D ( x i ) + 1 m ∑ i = 1 m log ( 1 − D ( x ~ i ) ) \tilde{V} = \frac{1}{m} \sum_{i=1}^{m} \log D(x^i) + \frac{1}{m} \sum_{i=1}^{m} \log (1 - D(\tilde{x}^i)) V~=m1i=1∑mlogD(xi)+m1i=1∑mlog(1−D(x~i))- log D ( x i ) \log D(x^i) logD(xi):判别器对真实样本打分。越大,表示 D 越认为它是真的。
- log ( 1 − D ( x ~ i ) ) \log (1 - D(\tilde{x}^i)) log(1−D(x~i)) :判别器对生成样本打分。 D ( x ~ i ) D(\tilde{x}^i) D(x~i) 越小(趋近于0),这一项就越大,表示 D 成功识别出了伪造品。
- 参数更新 :使用梯度上升法更新 θ d \theta_d θd,使判别能力变强。
(3)学习生成器 (Learning G)
生成器的目标是"造假者",它需要通过进化来"骗过"判别器。
- 采样 :再次提取 m m m 个新的噪声样本。
- 目标函数 V ~ \tilde{V} V~ :生成器试图最大化 这个简化后的函数(在实际代码中,这通常等同于让判别器对假数据打高分):
V ~ = 1 m ∑ i = 1 m log ( D ( G ( z i ) ) ) \tilde{V} = \frac{1}{m} \sum_{i=1}^{m} \log(D(G(z^i))) V~=m1i=1∑mlog(D(G(zi)))- D ( G ( z i ) ) D(G(z^i)) D(G(zi)):这是判别器对生成数据给出的概率值。生成器希望这个值越接近 1 越好(即判别器被骗了,认为假货是真的)。
- 参数更新 :更新 θ g \theta_g θg,使生成的数据越来越像真实数据。
这是一个博弈过程:
- D 在进化:为了更精准地识别真伪。
- G 在进化:为了生成更难以辨认的图像。
这种相互竞争最终会达到一个平衡点(纳什平衡),此时生成器产生的数据足以乱真,而判别器对真假数据的判断概率趋近于 50%。
下面看个 anime face generation 的例子


1000 updates 后开始出现眼睛

2000 updates 后开始出现嘴巴

5000 updates 后直到要生成卡姿兰大眼睛

10,000 updates 后,像水彩画晕开的感觉,细节不够好

20,000 updates

50,000 updates

上面数据集生成比较好的最终效果如上图所示

2、GAN as Structured Learning
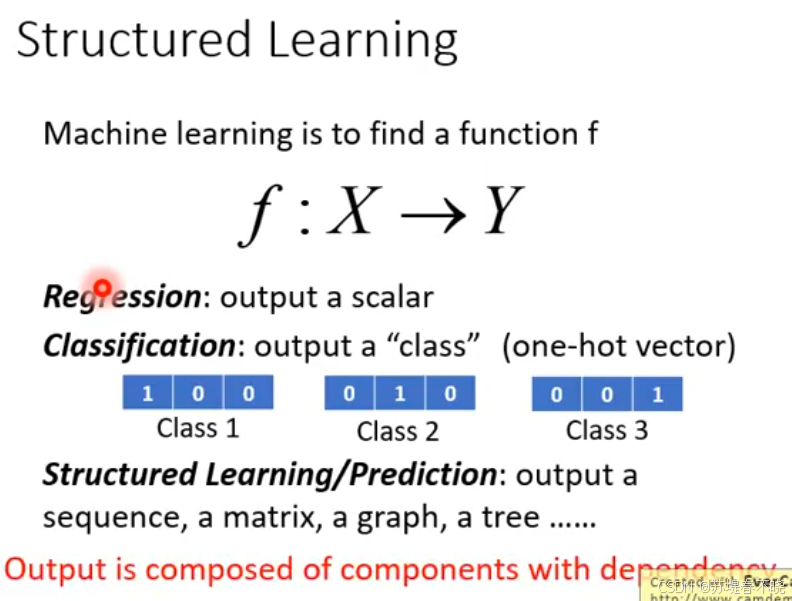
structured learning
output is composed of components with dependency,"输出由具有依赖关系的组件组成"
这正是 Structured Learning(结构化学习)的核心特点------输出的各个部分之间不是独立的,而是存在依赖关系。
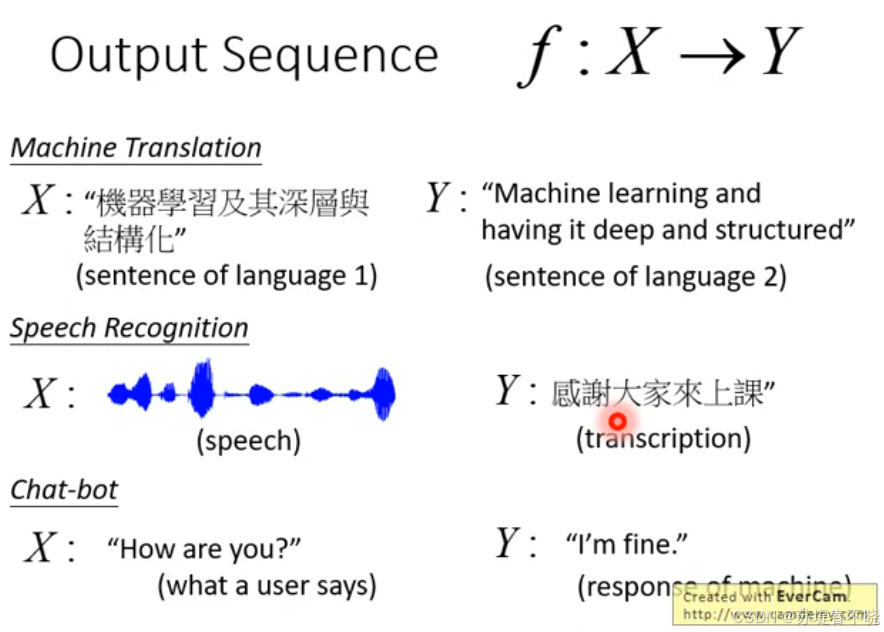
Output Sequence
- machine translation
- speech recognition
- chat-bot

Output Matrix
- Image to Image
- colorization
- Text to image

why structured learning challenging
- one-shot / zero-shot learning,machine has to create new stuff during testing
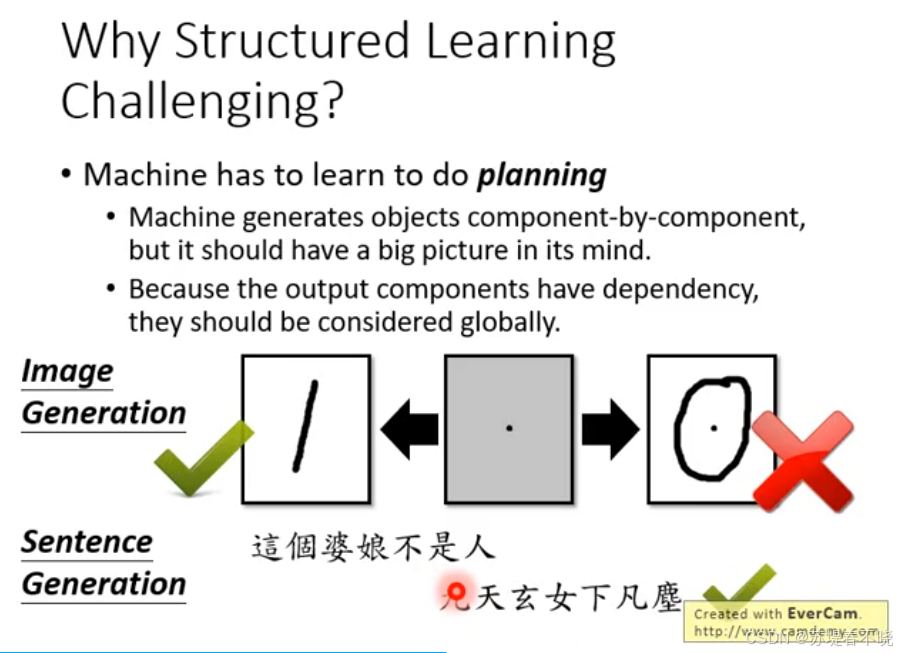
machine has to learn to do planning
- should have a big picture in its mind(大局观),eg:这个婆娘不是人,只看前一句,爆炸,来后一句,九天玄女下凡尘,瞬间喜笑颜开,太会夸人了
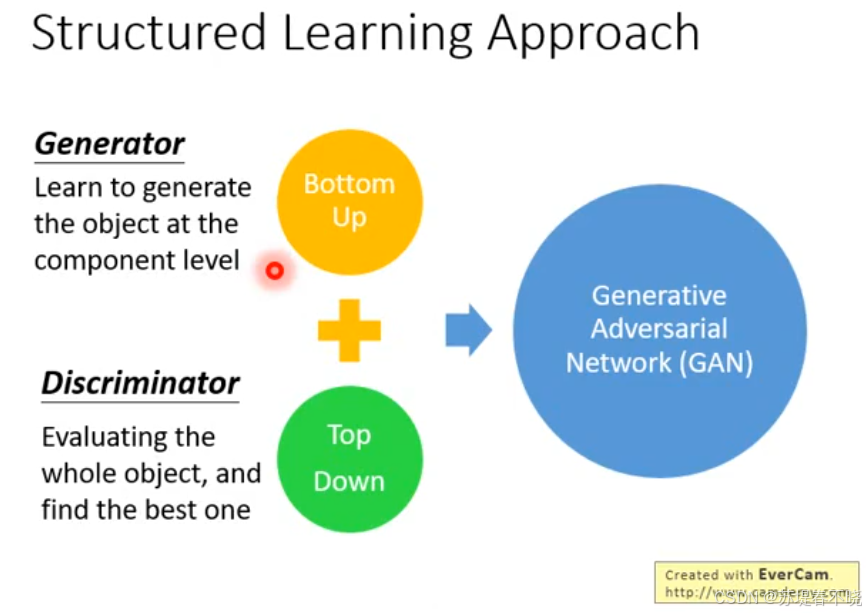
之前的 structured learning approach 包含 bottom up 和 top down 两种,GAN 有效的将其整合在了一起,取长补短
1. 生成器 (Generator):自下而上的局部构建 (Bottom-Up)
- 角色定位:生成器的任务是"创造"。
- Bottom-Up 逻辑 :在生成图片(结构化对象)时,生成器通常是在组件层面(Component level)进行学习。
- 例如:它学习如何画出像素点、线条、纹理,并将这些小组件组合成一个大对象。
- 局限性:由于它过于关注"局部"的拼凑,往往很难把握全局的连贯性。就像写文章时只注意单词拼写,却忽略了逻辑一致性,容易产生"局部看起来是对的,整体却很怪异"的结果。
2. 判别器 (Discriminator):自上而下的全局评估 (Top-Down)
- 角色定位:判别器的任务是"审美"与"评判"。
- Top-Down 逻辑 :判别器站在全局视角(The whole object),审视生成的对象是否像一个整体。
- 它不需要学习如何一步步构建对象,而是直接判断:这个结构是否符合真实世界的统计规律?
- 作用:它能发现局部组件之间不合理的结构关系。例如,生成器画了两只眼睛(局部正确),但判别器会指出这两只眼睛长在额头上是不对的(全局错误)。
3. GAN = Bottom-Up + Top-Down
这张图的核心观点是:GAN 实际上是将两种经典方法的优势结合在了一起。
| 维度 | 生成器 (G) | 判别器 (D) |
|---|---|---|
| 思维方式 | Bottom-Up (由碎块到整体) | Top-Down (由整体到评价) |
| 关注点 | 局部的细节生成 | 全局的结构合理性 |
| 在 GAN 中 | 负责提出一个结构化候选方案 | 负责筛选并找出"最好的"那个方案 |
总结
-
在结构化学习的语境下,GAN 解决了一个长期存在的难题:单纯靠 Bottom-Up 容易失去大局观,单纯靠 Top-Down(如传统的能量模型)则很难高效地采样和生成。
-
通过这种"生成器负责细节,判别器负责大局"的对抗机制,GAN 能够学习到数据中复杂的底层结构,从而生成具有高度一致性的高质量对象。
Top-Down

3、Can Generator Learn by Itself?
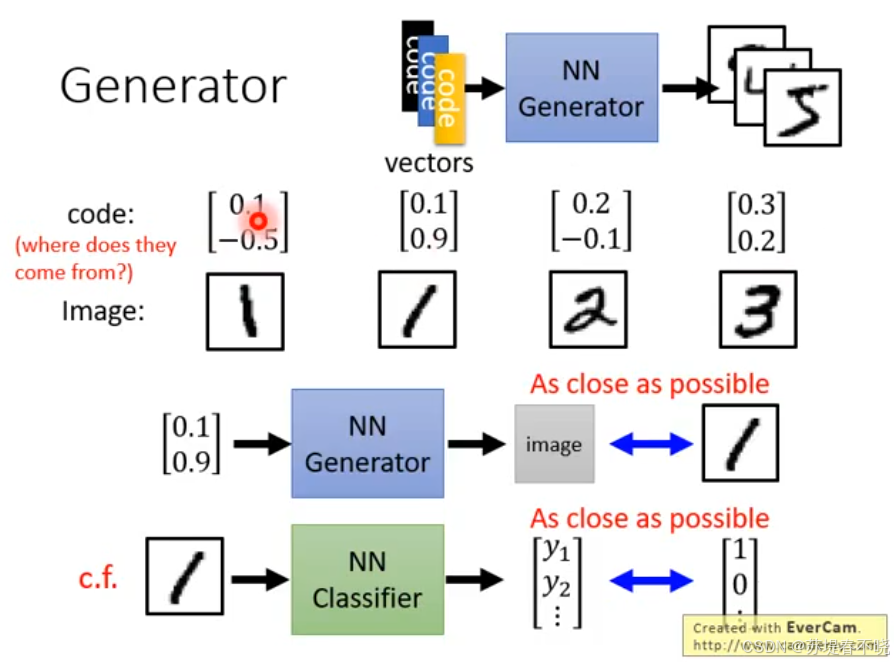
Code:where does they come from?
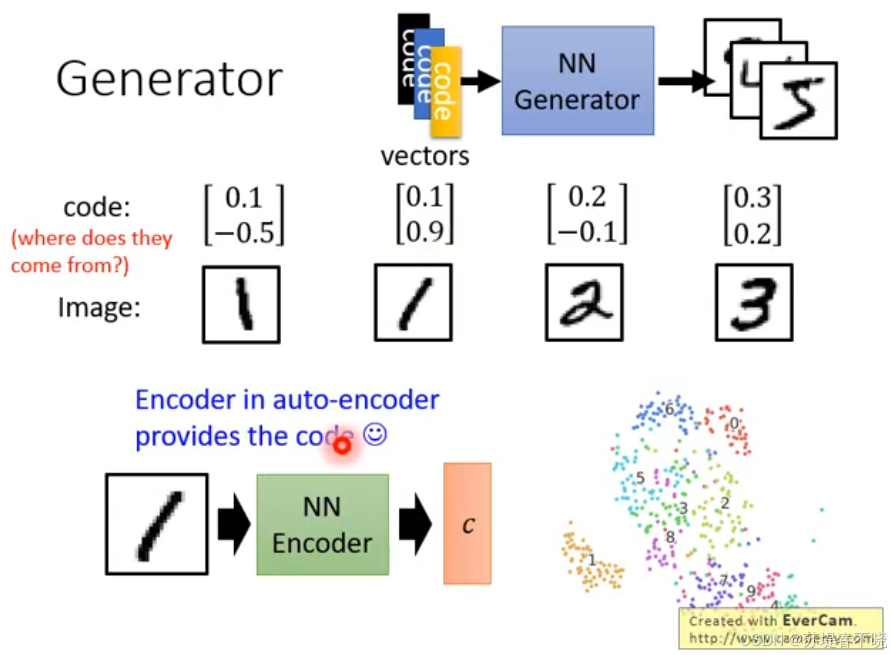
encoder in auto-encoder provides the code
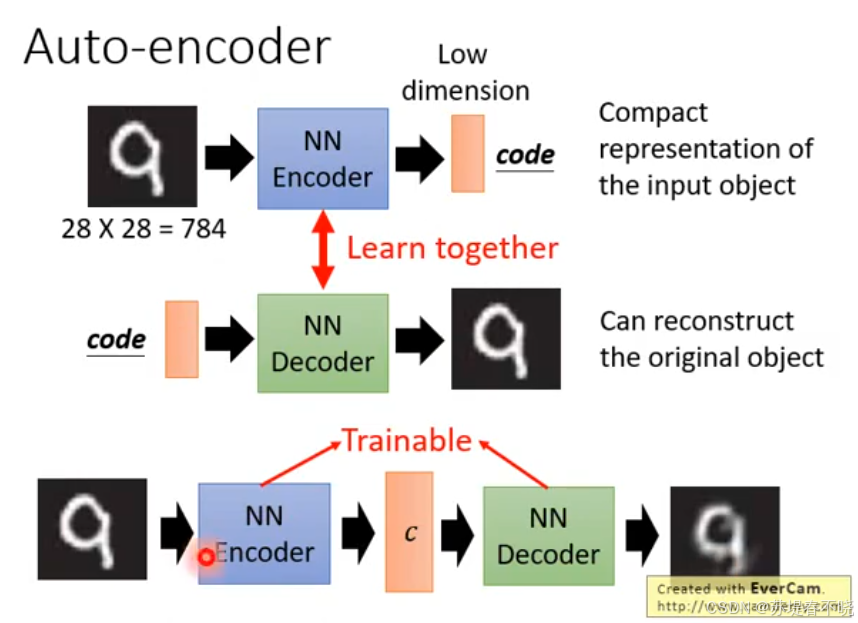
encoder compact representation of the input object
decoder can reconstruct the original object
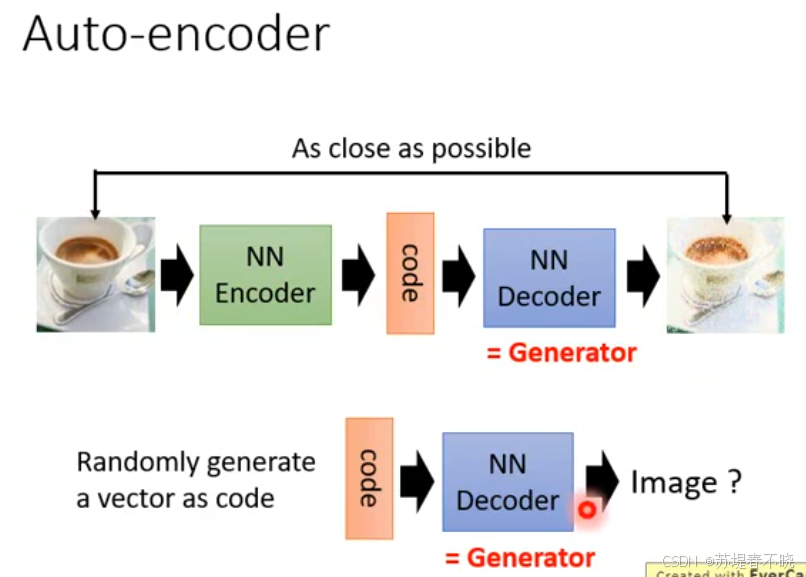
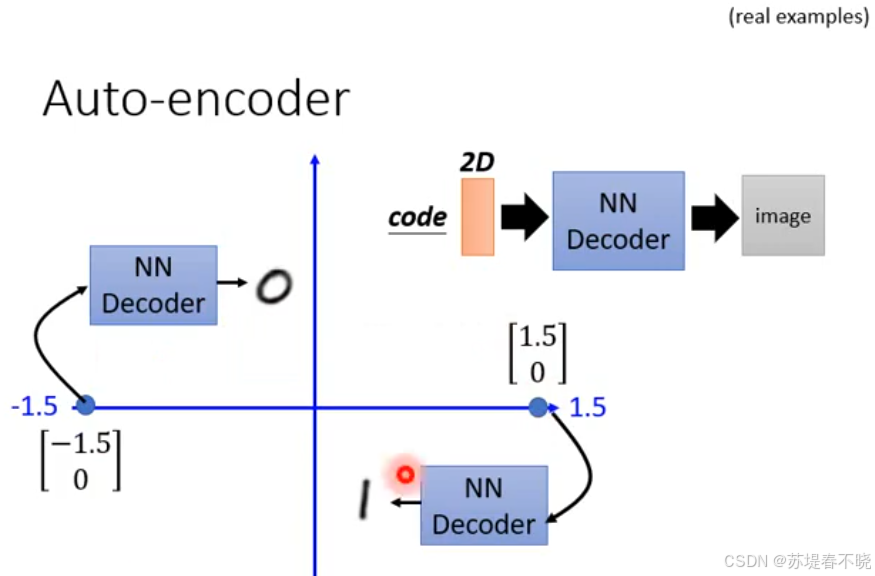
decoder 就是 generator

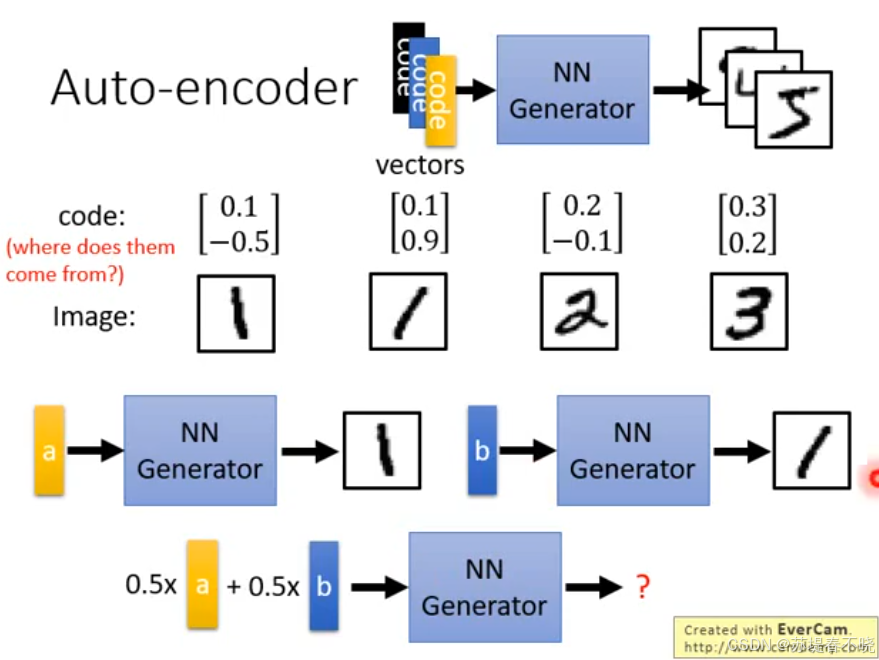
AE 中 0.5 x a + 0.5 x b 可能产生出来的是 noise
AE 看到 vector a 要产生数字,看到 vector b 要产生数字
VAE 看到 vector a 加一些 noise 也要产生数字,看到 vector b 加一些 noise 也要产生数字
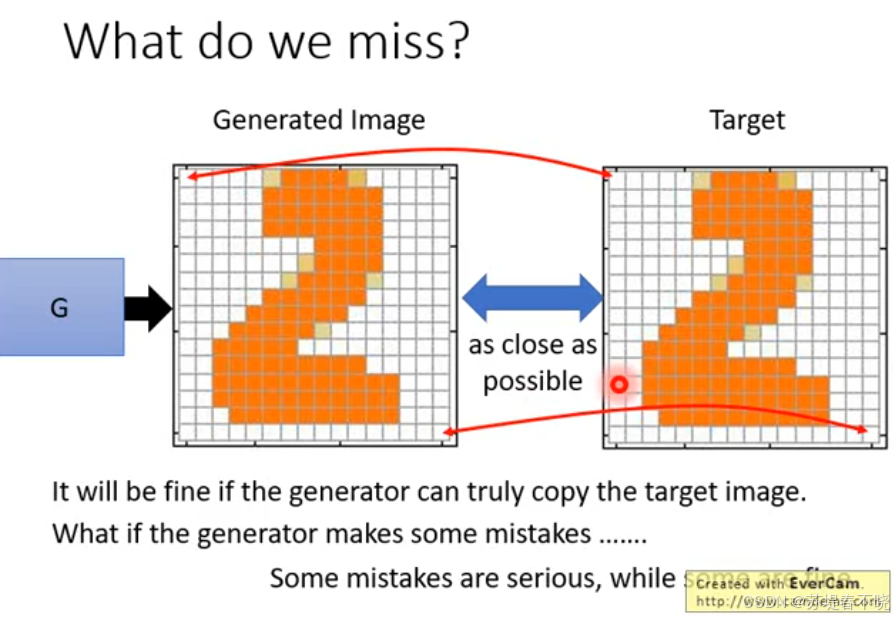
some mistakes are serious, while some are fine

不能单纯的让生成的内容和 target 越像越好(pixel 级别)
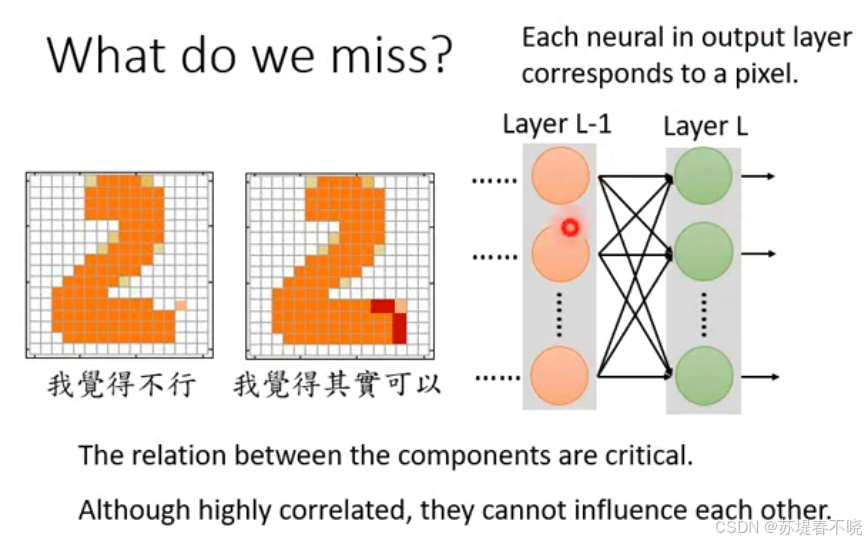
the relation between the components are critical,要有大局观
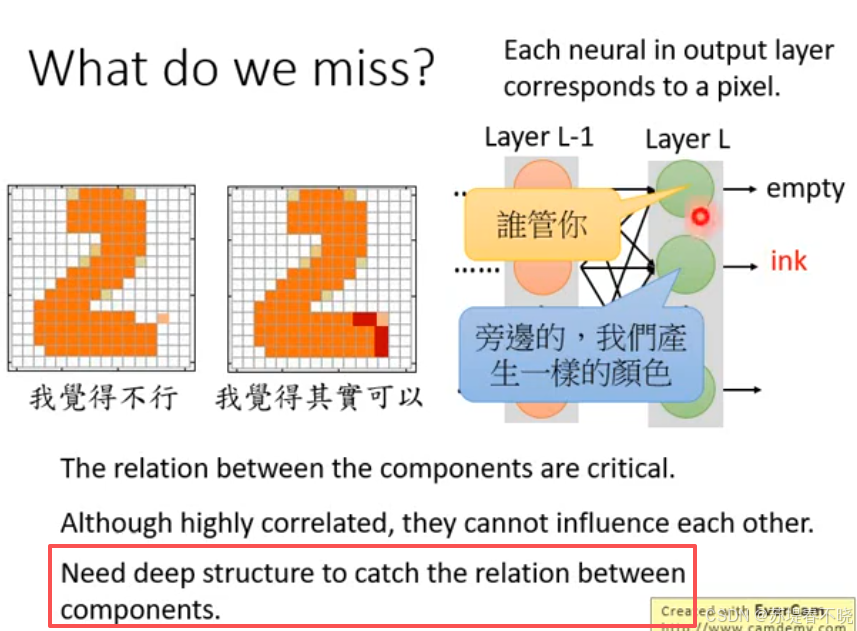
把 relationship 考虑进去,需要一个更深的 network
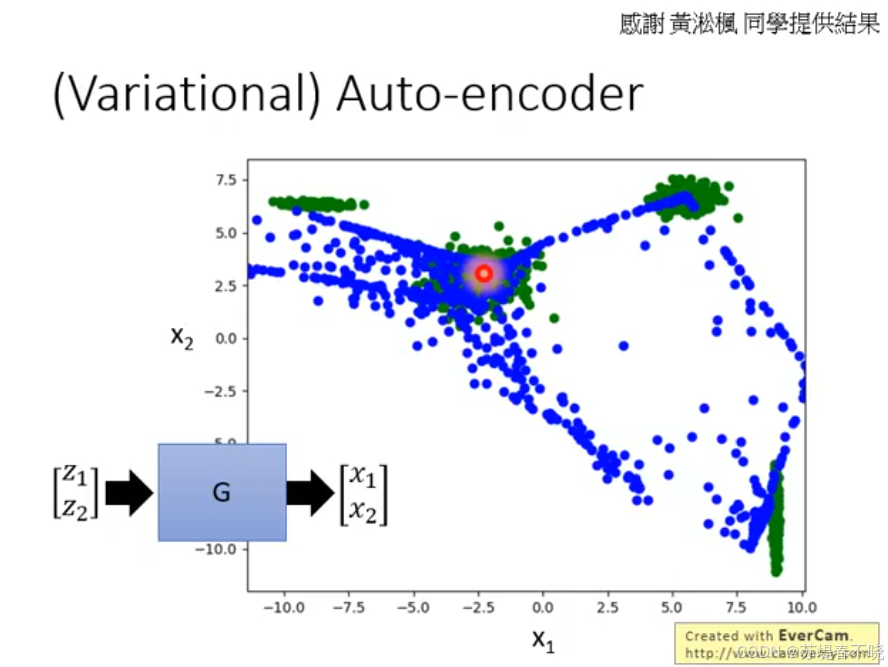
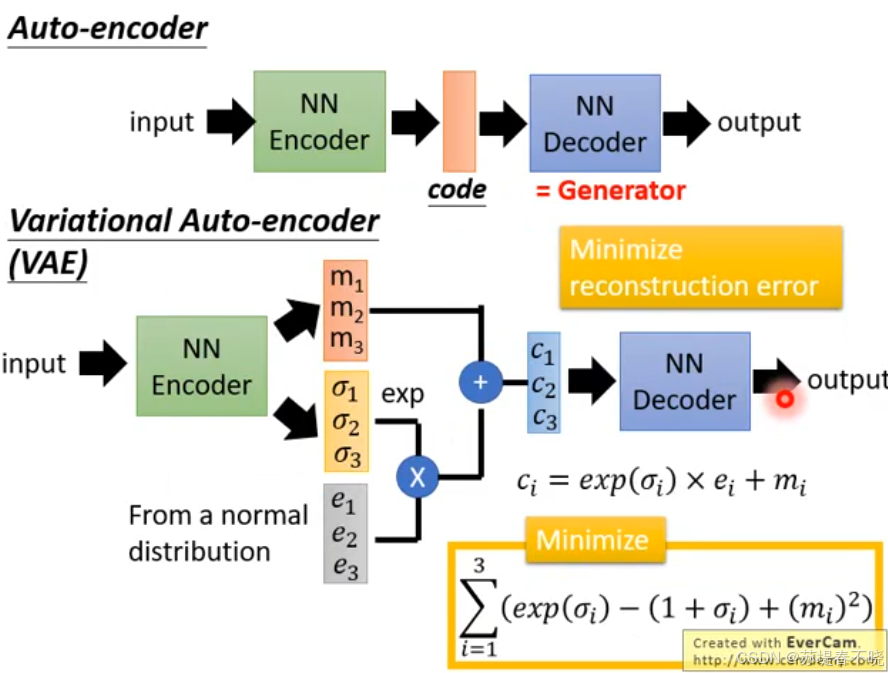
上图展示了 (变分) 自编码器 (Variational Auto-encoder, VAE) 在处理生成任务时的核心缺陷,并以此作为引入 GAN 必要性的背景。
1. 模型结构 (左下角)
- 输入 z 1 , z 2 z_1, z_2 z1,z2:代表低维的隐变量(Latent Code),通常是从正态分布中采样得到的。
- 生成器 G (即 Decoder):负责将这个低维向量映射回高维的真实数据空间。
- 输出 x 1 , x 2 x_1, x_2 x1,x2:代表生成的样本在二维空间中的坐标。
2. 数据分布可视化 (右侧散点图)
- 绿色点 (Ground Truth):代表真实数据的分布。可以看到,真实数据分布在几个孤立的"簇"中(例如左上、右上、中心、右下)。
- 蓝色点 (VAE Generated):代表 VAE 生成出来的样本。
3. 图表揭示的核心问题:VAE 的"保守"与"模糊"
这张图生动地展示了 VAE 在生成结构化数据时的痛点:
- 过度平滑与"记忆模糊":
- VAE 的目标函数通常包含重建误差(如 MSE 均方误差) 。为了最小化平均误差,模型往往会选择一种"稳妥"的策略:即生成真实数据簇之间的平均值。
- 图中可以看到,蓝色点虽然覆盖了绿色区域,但在那些原本没有数据的空白地带,也填满了大量的蓝色点。
- 无法捕捉精确的结构:
* 在两个真实数据簇(绿点)之间,VAE 生成了大量的"虚假连接"。
* 比喻 :如果绿点代表"左脸"和"右脸",VAE 可能会因为追求平均误差最小化,而在中间生成一个模糊的"中间脸",导致生成的图像看起来很模糊(Blurry)。 - 红圈标记:中心那个被红圈包裹的区域,展示了模型试图拟合中心数据簇时,由于采样和分布重叠导致的混乱。
总结
上图说明了 为什么我们需要 GAN:
- VAE 只有生成器,它只知道"模仿"看到的像素,导致它在处理复杂分布时容易产生不合理的"中间地带"。
- GAN 引入了判别器,判别器会明确告诉生成器:"虽然你生成的点在两个绿点中间,看起来挺像数据,但那里其实是空白区域,判你不及格!"
- 通过这种对抗,生成器被迫放弃这些模糊的"中间值",从而让生成的数据分布更加贴合真实数据的边界,解决模糊问题。
4、Can Discriminator generate?

can we use the discriminator to generate objects?
yes
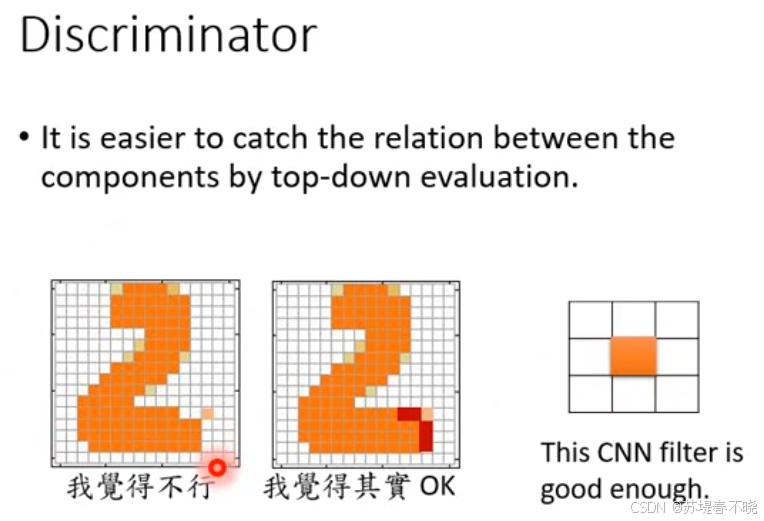
top-down evaluation
eg:空洞检测 filter,出现了就低分

穷举所有 x,给出最高分(较高分),那个 x 就是我们生成的 x,实现了生成的功能
is it feasible???
how to learn the discriminator?

discriminator training needs some negative examples(特别是高质量的)

negative examples are critical
也许生成的质量很差,但是比 random noise 好很多,可能还是会给高分
how to generate realistic negative examples?
需要 realistic negative examples 来训练得到好的 discriminator,但是需要好的 discriminator 才能找到好的 realistic negative examples,鸡生蛋,蛋生鸡

然后用 discriminator 觉得好的数据,再 train discriminator

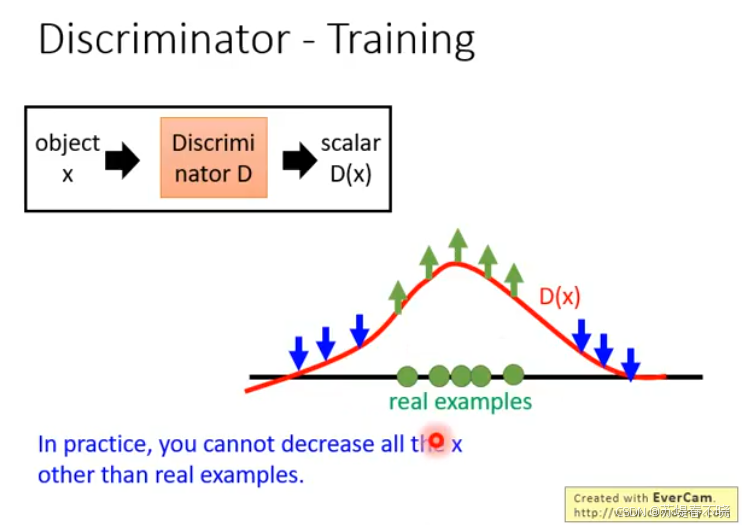
in practice,不可能穷举所有 x
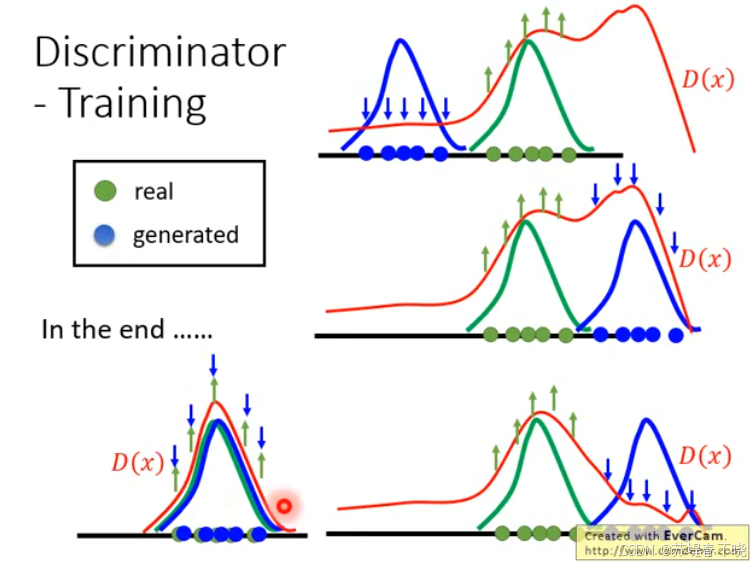
绿色:real
蓝色:generated
discriminator:拉低 generated 得分,提高 real 得分
GAN 和图网络有些共同之处,具体这里不展开

generator 和 discriminator 的优缺点


using generator to generate negative samples
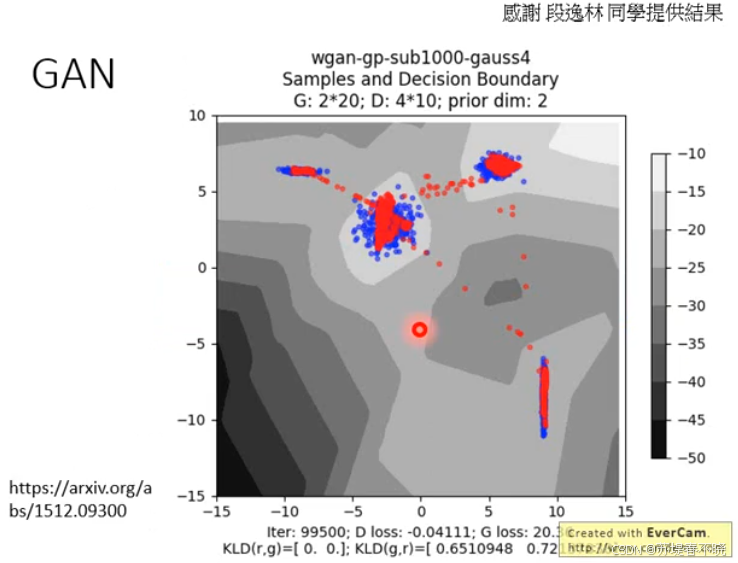
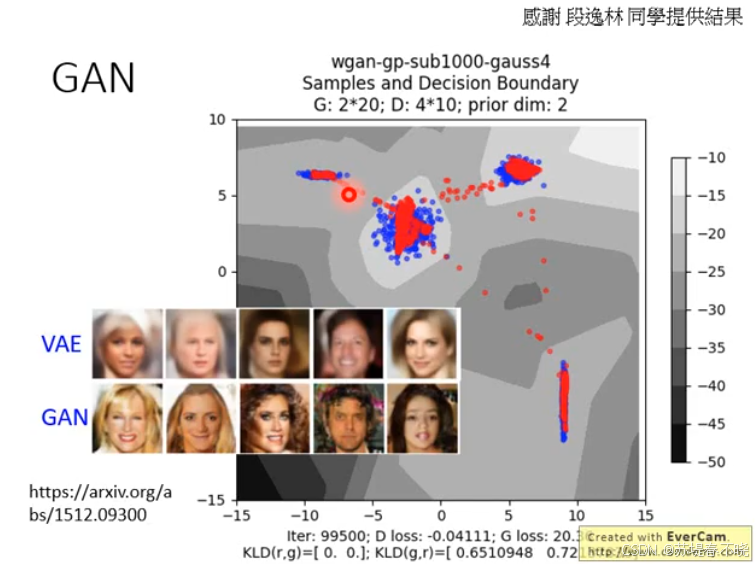
蓝色是 generator 产生的点,红色是 real
和之前的 VAE 对比看还是很明显的
FID Score 越小越真实
不同参数配置可以看到同一个方法的 range 很大(纵轴跨度),不同方法之间的差异没有那么大
VAE 更稳