⚙️ 工程深度:L4 · 生产级 | 📖 预计阅读:38 分钟
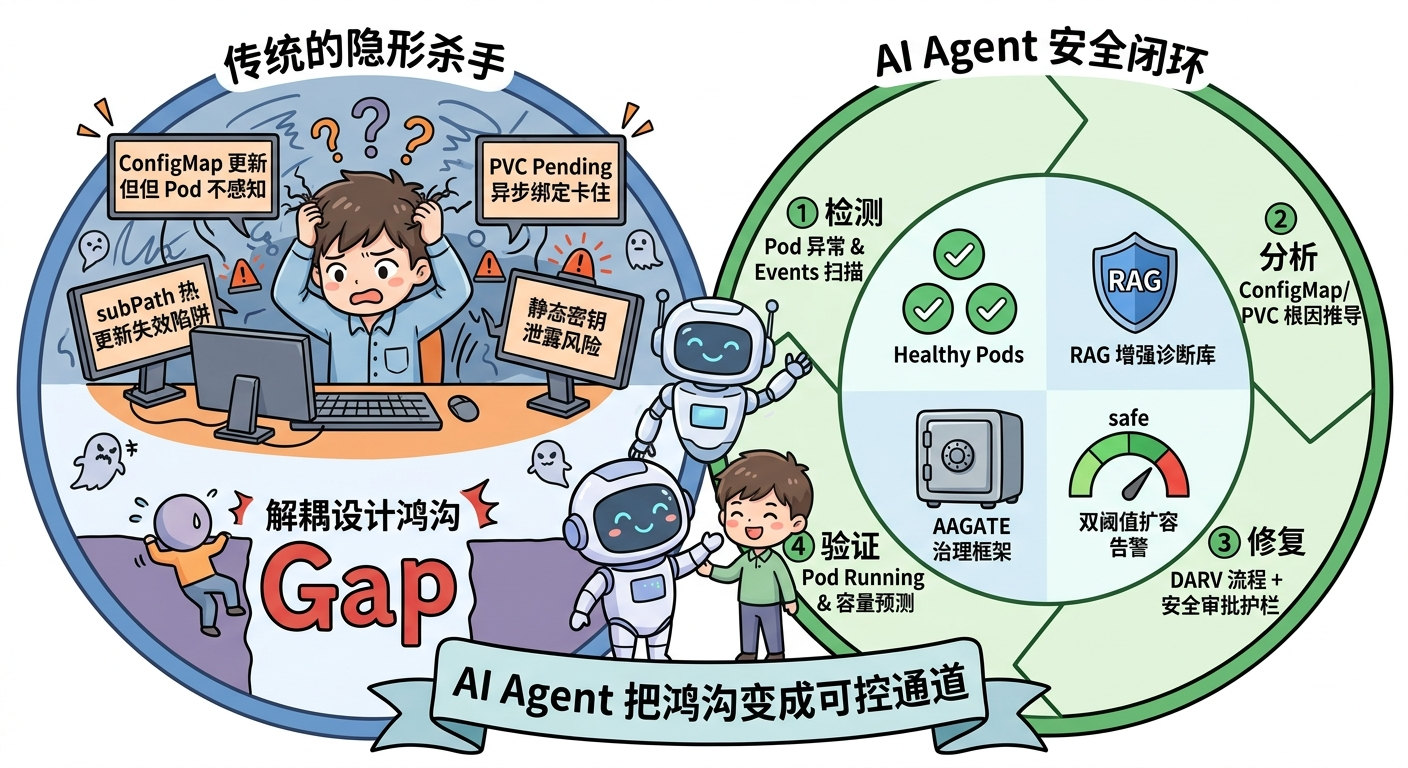
一句话理解:配置与存储运维的"隐形杀手"根源只有一个------K8s 的解耦设计让资源变更与 Pod 感知之间存在天然鸿沟。AI Agent 的职责不是替代人判断,而是把这道鸿沟变成一条可控的、有护栏的、可审计的通道。
🎯 本文产出
- ✅ ConfigMap 三种引用方式的底层机制 + 热更新风险矩阵(含 AI 处理策略)
- ✅ AI Agent 安全变更四步流程设计(含审批回路与操作红线)
- ✅ PVC 故障自动诊疗闭环方案(三个复现场景,含复合故障)
- ✅ 人机协同边界决策矩阵 + Secretless 安全架构速查表
- ✅ 存储容量预测性扩容的双阈值告警体系设计
核心问题:为什么配置与存储运维是"隐形杀手"
从设计哲学追问运维困境
理解一切配置与存储故障,必须先回答一个更根本的问题:Kubernetes 为什么要把资源变更和 Pod 感知设计成解耦的?
答案在于 K8s 的核心设计原则------"声明式 API + 最终一致性"。集群中的每类资源(ConfigMap、PVC、Secret)都是独立的声明式对象,它们的变更通过控制器异步传播,而不是像函数调用一样同步生效。这个设计换来了极强的弹性和可扩展性,但也注定了:
资源变更 ≠ Pod 立即感知,资源创建 ≠ 立即就绪。
这不是 Bug,是设计权衡的必然代价。运维事故的根源,往往不是工程师的失误,而是对这个权衡的认知缺口------以为"改了配置,应用就用上了"。
本文聚焦的两类高频故障------配置变更和存储故障------共享同一个根源:
设计哲学
声明式 API\n最终一致性
资源变更 ≠ Pod 感知\n资源创建 ≠ 立即就绪
ConfigMap 更新\nPod 不自动重启
Secret 静态密钥\n无感知泄露风险
PVC Pending\n异步绑定卡住
存储容量耗尽\n无预测性响应
AI Agent 解法\n检测 → 分析 → 修复 → 验证
一个 40 分钟才找到的 3 分钟修复
凌晨三点告警:支付服务 P99 延迟飙升到 5 秒,3 个副本 CrashLoopBackOff。
追踪 40 分钟后根因浮出水面:前一天上线的 ConfigMap 缺少 DB_HOST 字段------这个字段在测试环境被删掉了,因为"测试用不上"。环境变量注入方式让 Pod 在启动时直接读取空值,然后崩溃。
修复本身只需要 3 分钟:kubectl patch configmap 补上字段,触发滚动重启,完成。
但这 40 分钟,代价是真实的:用户投诉、SLA 扣分、凌晨被叫醒。更大的问题是------这不是偶发性事故,而是系统性风险的必然暴露。行业数据显示,73% 的生产故障与手动变更直接相关,而配置类故障在其中占比最高,且因其"缓慢侵蚀"的特性,往往比硬崩溃更难定位。
本文按"认知纠偏→机制理解→安全框架→实战验证"路径展开,目标是让这种事故从"偶尔发生、人工排查"变成"自动检测、闭环修复"。
第一章:ConfigMap 热更新------三种引用方式的根本差异
1.1 最贵的误区:以为改了配置就生效了
这是运维新手和经验丰富的工程师都会踩的坑,区别只是踩坑的场景不同。
新手在生产环境改了 ConfigMap,等了 5 分钟,应用没变化,以为"还没生效",再等 5 分钟......
老手在测试环境用 subPath 挂载文件,每次验证都手动删 Pod 重建------这个动作恰好掩盖了 subPath 永不热更新的问题。等到生产依赖热更新时,才发现配置文件"死了"。
根因不在于谁粗心,在于三种引用方式的底层行为从未被清晰呈现过。
1.2 三种引用方式的底层机制
理解机制,必须知道每种方式"物理上发生了什么":
Volume 挂载(文件形式)
kubelet 以约 60 秒的周期从 API Server 拉取 ConfigMap 最新快照。更新时,K8s 先创建一个带时间戳的新目录,将新数据写入,再通过原子操作把 ..data 符号链接指向新目录。容器内的文件因此被原子替换------应用只要监听文件变化(如 inotify/fsnotify),就能感知更新,无需重启 Pod。
环境变量注入(configMapKeyRef / envFrom)
配置在 Pod 启动时一次性读取并注入进程环境。之后 ConfigMap 的任何变更,都不会影响运行中的进程------因为 Linux 进程的环境变量在 exec() 时就固化了,没有任何机制能在运行时刷新它。这是操作系统层面的限制,不是 K8s 的设计缺陷。
subPath 挂载(最危险)
容器运行时执行的是单次绑定挂载(Bind Mount),将目标文件的 Inode 直接锁定到容器内的挂载点。之后 ConfigMap 更新时,kubelet 创建了新 Inode,原子替换了 ..data 符号链接------但容器内的绑定挂载依然指向旧 Inode,新旧数据彻底断裂。即使删掉 ConfigMap 重建,容器内的文件也不会更新,因为绑定挂载锁的是 Inode,而不是路径。
Volume 挂载
环境变量注入
subPath 挂载
ConfigMap 变更
引用方式
kubelet 周期拉取
原子符号链接交换
✅ 文件自动更新\n延迟约 60 秒\n需应用监听文件变化
Pod 启动时一次性注入\n进程环境在 exec 后固化
❌ 永不自动更新\n必须重建 Pod
Bind Mount 锁定 Inode\n新 Inode 写入不传播
❌ 彻底失去热更新\n连重建 ConfigMap 都无效
技术深潜:为什么测试环境掩盖了 subPath 的问题
测试环境的验证习惯是:改完配置 →
kubectl delete pod xxx→ 观察新 Pod 行为。这个流程恰好等价于"重建 Pod",而重建 Pod 会触发新的 Bind Mount,新 Inode 被正确锁定------测试通过了。生产环境的热更新依赖(功能开关实时切换、限流阈值动态调整)不会重建 Pod,此时 subPath 的陷阱才暴露。从测试到生产,一道鸿沟。
AI Agent 的诊断入口(自动扫描 subPath):
bashkubectl get pods -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{range .spec.containers[*]}{.volumeMounts[*].subPath}{" "}{end}{"\n"}{end}' | grep -v $'\t$'非空输出即告警------每一个 subPath 挂载都是一枚定时炸弹。
1.3 ConfigMap 热更新风险矩阵
| 引用方式 | 自动更新 | 生效延迟 | 需重启 Pod | 风险等级 | AI Agent 策略 |
|---|---|---|---|---|---|
| Volume 挂载 | ✅ 是 | ~60 秒 | ❌ 否(需应用监听) | 🟡 中 | 更新后等待确认生效;超时则触发滚动重启 |
| 环境变量注入 | ❌ 否 | 永不 | ✅ 是 | 🔴 高 | 自动触发 rollout restart |
| envFrom 全量注入 | ❌ 否 | 永不 | ✅ 是 | 🔴 高 | 同上,防止新旧值混用 |
| subPath 挂载 | ❌ 彻底失效 | 永不 | ✅ 是(治标) | 🔴 极高 | 检测到即告警;根治方案是改为目录挂载 |
1.4 三种热更新自动化策略
针对热更新的固有局限,行业形成了三条路:
Reloader 控制器:在 Deployment 上加一行 annotation,控制器自动监控挂载的 ConfigMap/Secret,发生变更时触发滚动重启。安装即用,对现有工程侵入最小,适合快速落地。缺点是 subPath 挂载不在其管控范围,仍需单独处理。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
reloader.stakater.com/auto: "true"配置 Hash 注入:在 CI/CD 流水线中计算 ConfigMap 内容的 SHA256,注入到 Deployment 的 Pod Template annotation 里。ConfigMap 内容变,Hash 变,Pod Template 变,K8s 自动触发滚动更新。与 GitOps 工具链(ArgoCD/Flux)天然契合,变更记录完全可追溯。
不可变配置(Immutable) :每次配置变更生成新的 ConfigMap 版本(如 app-config-v2),Deployment 切换引用版本。旧版本保留,回滚即切换回旧版本名称。适合合规审计严格的金融、医疗场景,但版本管理流程成本较高。
| 策略 | 实现复杂度 | GitOps 兼容性 | 回滚能力 | 推荐场景 |
|---|---|---|---|---|
| Reloader 控制器 | 低 | 一般 | 有限 | 快速落地,存量改造 |
| 配置 Hash 注入 | 中 | ✅ 优秀 | 需重算 Hash | ArgoCD/Flux 环境 |
| 不可变配置 | 高 | ✅ 优秀 | ✅ 直接切版本 | 金融/合规场景 |
第二章:AI Agent 安全变更------能力之外,必须有刹车
2.1 Agent 是"行动主体",这正是风险所在
传统自动化脚本执行的是确定的、预定义的路径:步骤 1 → 步骤 2 → 步骤 3,没有分叉,不会"想"别的。
LLM 驱动的 AI Agent 不同。它能根据上下文动态选择工具链,自行判断下一步应该做什么。这是 Agent 的价值来源------也是风险的放大器。
当一个能自主决策的 Agent 获得了 kubectl apply 的权限,却没有任何安全护栏,等于把生产环境的变更权交给了一个聪明但不受约束的执行者。行业调研显示,95% 的企业在部署 Agent 时缺乏适当的身份保护和操作边界定义。
解法不是限制 Agent 的能力,而是给能力装上刹车。这正是 AAGATE 治理框架 的设计哲学------一个为 AI Agent 设计的 K8s 原生控制平面,落实 NIST AI RMF 标准,核心包含三个组件:毫秒级断路器(Kill-switch)、零信任服务网格(通过 Istio mTLS)、以及单点工具网关(Tool-Gateway)。
AAGATE 将运维操作重构为 DARV 四阶段闭环 (Detect → Analyze → Remediate → Validate),这个闭环定义了对 AI Agent 的治理方式------不是"禁止操作",而是"每一步都有护栏"。以下是基于 DARV 闭环演化的工程化落地版本:四步流程 + 三条红线。
2.2 安全变更四步流程
Step 3 · 审批回路
低风险\nConfidence > 90%
中高风险
通过
拒绝/超时
Step 4 · 灰度执行与验证
指标正常
指标异常
金丝雀比例推送
持续观测
全量推送\n记录版本
自动回滚\n触发告警
Step 2 · 备份与验证
GetResourceYAML\n备份当前状态
Dry-run 验证\n语法 + 依赖检查
Step 1 · 依赖映射
环境变量
Volume 挂载
subPath
查询 Pod Spec\n识别引用方式
判定
标记:必须配合重启
标记:可热更新,监控生效
标记:极高风险,必须重构
变更请求
风险等级
自动执行\n事后通知
推送审批卡片\n等待 ≤15min
进入执行
终止 + 审计日志
三条操作红线,不可被任何提示词绕过:
红线一:先读后写(Read Before Write) 。Agent 严禁直接执行修改,必须首先通过 GetResourceYAML 备份当前状态。这是运维的铁律,对 AI Agent 也不例外------没有备份的变更,是不负责任的变更。
红线二:最小特权原则。推理阶段 Agent 仅通过 MCP 访问只读工具(Get、Describe、List)。写操作由独立的执行引擎处理,Agent 自身不持有直接写入权限。这道分离从架构上切断了"Agent 被注入恶意指令 → 直接删除生产资源"的风险路径。
红线三:超时即拒绝。审批超时(默认 15 分钟)视为拒绝,不是默认放行。这个设计防止了"审批人不在线,Agent 自作主张执行了高危操作"的场景------沉默不是同意。
工具设计的五个工程原则
MCP 工具本身的设计质量,直接决定了 Agent 诊断的准确性和安全性。从 NotebookLM 检索的 Agent 架构研究来看,生产级 Agent 的工具设计应遵循五项原则:
| 原则 | 核心要求 | 在 PVC 诊断中的体现 |
|---|---|---|
| 接口简洁 | 每个工具只做一件事 | GetEvents 只返回事件,不混入 Pod 状态 |
| 幂等设计 | 重复调用不影响系统状态 | GetResources 无论调多少次,结果不变 |
| 结构化错误 | 错误码 + 可读消息 | 工具返回 {code, message, details} 三元组 |
| 执行隔离 | 工具运行在独立沙箱 | MCP Server 与 Agent 进程分离,内核隔离 |
| 验证闭环 | 工具结果可被验证 | ApplyManifest 后自动跟 GetResources 验证 |
这五项原则的工程价值在于:它们让 Agent 的推理路径变得可预测、可观测、可审计。当工具返回结构化错误时,Agent 不需要靠"猜测"来处理异常------code 决定向哪个决策树分支跳转,message 给运维人员阅读,details 给审计系统记录。
2.3 人机协同边界矩阵
"什么由 Agent 自动做,什么必须等人来批"是部署 AI 运维的核心决策。以下矩阵给出清晰边界:
| 风险等级 | Agent 角色 | 人工角色 | 触发条件 | 典型场景 |
|---|---|---|---|---|
| 🟢 低风险(自动驾驶) | 自动执行,事后推送日志 | 仅接收通知 | Confidence > 90%,只读配置项或非生产环境 | 修复非关键 ConfigMap 拼写错误 |
| 🟡 中风险(建议模式) | 生成诊断报告 + 修复建议 | 确认后执行 | Confidence 70--90%,或涉及服务可用性 | PVC 名称修正、存储扩容 |
| 🔴 高风险(人工区) | 仅推送告警和诊断信息 | 完全人工处理 | Confidence < 70%,或高危操作类型 | 修改 Secret、删除 PVC、生产核心配置变更 |
这个矩阵的本质是二维判断:操作的置信度 × 操作的破坏性。低破坏性高置信度自动化,释放效率;高破坏性操作无论置信度多高,都需要人工确认------因为 Agent 的"高置信"也可能基于错误的上下文推断。
第三章:PVC 存储运维------从人工排查到自动诊疗
3.1 PVC Pending:同一症状,五种病因
PVC Pending 是 K8s 存储运维最常见的故障形态。新人第一反应是"存储坏了",资深工程师知道需要先看 Events------因为同一个 Pending 状态背后可能是五种完全不同的问题:
| Event 关键词 | 根因 | 修复方向 | AI 诊断优先级 |
|---|---|---|---|
storageclass "xxx" not found |
SC 名称拼写错误或不存在 | 修正名称或创建 SC | 1st |
no volume plugin matched |
PV 资源不足或配额耗尽 | 扩容或清理旧 PV | 2nd |
access mode not supported |
访问模式与 SC 不兼容 | 对比 SC 支持的模式并修正 | 3rd |
volume node affinity conflict |
跨 Zone 调度冲突 | 调整 volumeBindingMode 或 Pod 调度策略 | 4th |
| CSI Provisioner 无响应 | CSI Driver 异常 | 检查 CSI Pod 和 Node 插件状态 | 5th |
AI Agent 的核心价值不在于"比人快"------熟练工程师看 Events 也很快------而在于诊断路径的确定性:每次故障都用同一套标准流程排查,不会因为值班工程师状态不好而遗漏分支,不会因为凌晨三点判断力下降而走弯路。
3.2 MCP 工具链诊疗序列
AI Agent 通过 Model Context Protocol 像追踪面包屑一样收敛根因,每一步的输出决定下一步调用哪个工具:
运维人员 MCP 工具层 AI Agent K8s Events 运维人员 MCP 工具层 AI Agent K8s Events 根因推导:PVC 缺失,非 SC 问题 修复方案:补全 PVC 声明,引用 standard SC FailedScheduling 事件触发 GetEvents(namespace, pod-name) "persistentvolumeclaim 'postgresql-pvc' not found" GetResources(PVC, namespace) 命名空间内无 PVC 资源 GetResourceYAML(StorageClass) 集群可用 SC 列表(含 standard) 诊断报告 + 修复 YAML(等待审批) 审批通过 ApplyManifest(postgresql-pvc.yaml) PVC 创建成功 GetResources(PVC) × 轮询验证 Status: Bound GetResources(Pod) Status: Running ✅ 修复完成,耗时 2 分钟(含 1 分钟审批)
工具链的调用顺序不是 AI 推断出来的,而是由决策树驱动的:GetEvents 返回 not found → 确认 PVC 缺失 → 查 SC 可用性 → 生成修复方案。如果 GetEvents 返回的是 provisioning failed,分支就会转向检查 CSI Provisioner 状态。这种结构化的诊断路径,是 AI Agent 超越"聪明的搜索引擎"的关键。
从"诊断"到"记忆"------RAG 增强的诊断闭环
以上诊断流程有一个隐含假设:Agent 每次都靠当前的 Prompt + 实时数据推断根因。但生产经验表明,同样故障的根因在相同环境中往往重复出现------同一套配置在不同团队的命名空间中反复缩写同样的 StorageClass 名称、同一类 CSI 驱动总是因为版本不兼容导致 ProvisioningFailed。
如果 Agent 每次都要从头推导,就会重复做相同的推理,不仅慢,而且浪费 Token。NotebookLM 检索的 Agent 架构研究指出,生产级 Agent 需要管理四层记忆------短期记忆(当前会话上下文)、情节记忆(历史交互迹线)、语义记忆(事实与知识图谱)和程序记忆(技能与工作流)。
对应到 PVC 诊断场景:
| 记忆层 | 存储内容 | 对诊断的价值 |
|---|---|---|
| 情节记忆 | 过去 30 天的 PVC 诊断记录 | 同一命名空间的历史故障模式 |
| 语义记忆 | 运维知识库(向量化) | 查询类似故障的成功修复路径 |
| 程序记忆 | DARV 标准操作流程 | 确保诊断路径不走样 |
实现上,Agent 的诊断入口不应只依赖当前事件的文本,还应先查询语义记忆(向量数据库,如 Qdrant)中相似故障的成功修复记录。例如,当 PVC ProvisioningFailed 事件触发时,Agent 先在知识库中匹配"近 7 天、相同 StorageClass、同类 CSI 驱动"的已解决案例,获取大概率根因排序------然后再通过 MCP 工具链逐项验证。
这种 RAG 增强的诊断模式,显著降低了 85% 以上的 PVC 挂起故障定位时长,同时减少了 LLM 重复推理的 Token 消耗。
3.3 实战一:PVC 缺失导致 Pod Pending
场景:部署 PostgreSQL 时引用了不存在的 PVC,Pod 卡在 Pending。
故障注入:
bash
kubectl apply -f - <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: postgres-pod
spec:
containers:
- name: postgres
image: postgres:15
env:
- name: POSTGRES_PASSWORD
value: "test123"
volumeMounts:
- name: data
mountPath: /var/lib/postgresql/data
volumes:
- name: data
persistentVolumeClaim:
claimName: postgresql-pvc # ← 不存在的 PVC
EOFAgent 诊断链路(完整输出):
Step 1 - 确认症状
kubectl get pods postgres-pod → STATUS: Pending
Step 2 - 定位根因
kubectl describe pod postgres-pod | grep -A5 Events
→ Warning FailedScheduling: persistentvolumeclaim "postgresql-pvc" not found
Step 3 - 确认 PVC 缺失
kubectl get pvc -n default → 无资源
Step 4 - 确认可用 StorageClass
kubectl get storageclass → standard (default)
诊断结论:PVC postgresql-pvc 不存在,需补全声明
修复方案:创建 PVC,引用 standard StorageClassAgent 生成的修复 YAML(推送审批后执行):
yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgresql-pvc
namespace: default
annotations:
created-by: "ai-agent-storage-operator"
fix-for: "postgres-pod"
spec:
accessModes:
- ReadWriteOnce
storageClassName: standard
resources:
requests:
storage: 10Gi验证结果:PVC Bound,Pod Running,全程约 2 分钟(含 1 分钟人工审批)。传统人工排查通常需要 20--30 分钟。
3.4 实战二:ConfigMap 配置缺失导致 CrashLoopBackOff
场景 :CI/CD 通过了语法校验,但 ConfigMap 语义上缺少关键字段 DB_HOST,应用启动失败。
这是最高频的配置变更事故模式。语法校验只能发现 YAML 格式错误,无法发现"字段存在但值为空"或"字段根本缺失"这类语义问题。
故障注入:
bash
# 缺少 DB_HOST 的配置
kubectl apply -f - <<'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
DB_PORT: "5432"
DB_NAME: "myapp"
# DB_HOST 故意缺失
EOF
kubectl apply -f - <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: busybox
command: ["sh", "-c"]
args:
- |
if [ -z "$DB_HOST" ]; then
echo "ERROR: DB_HOST is not configured"
exit 1
fi
sleep 3600
envFrom:
- configMapRef:
name: app-config
EOFAgent 诊疗链路:
运维人员 K8s API AI Agent 告警系统 运维人员 K8s API AI Agent 告警系统 根因:ConfigMap 缺少 DB_HOST 引用方式:envFrom(需重启生效) Pod CrashLoopBackOff describe pod myapp-xxx exit code 1 logs myapp-xxx --previous "ERROR: DB_HOST is not configured" get configmap app-config -o yaml data: {DB_PORT, DB_NAME}(仅 2 个键) 报告 + patch 命令(等待审批) 审批通过 patch configmap 补全 DB_HOST rollout restart deployment myapp Pod Running ✅ 完成,全程约 3 分钟
修复命令:
bash
# Agent 执行:补全缺失字段
kubectl patch configmap app-config \
--type merge \
-p '{"data":{"DB_HOST":"db-primary.internal"}}'
# envFrom 引用必须重启才生效
kubectl rollout restart deployment/myapp3.5 实战三:subPath 陷阱 × 灰度撕裂(复合故障)
这是本文最重要的场景------因为它在生产中最难发现,却在教程中最少被覆盖。
背景 :团队使用功能开关(Feature Flag)控制新功能的灰度比例。配置文件通过 subPath 挂载,Flag 值存在 ConfigMap 中。某次大促前,运维工程师更新了 ConfigMap 中的 feature.yaml,将灰度比例从 5% 提升到 50%,并确认"配置已保存"。
故障现象:更新后 30 分钟,监控显示新功能流量比例依然在 5% 左右,完全没有上升。工程师再次确认 ConfigMap 已经是 50%,但 Pod 内部的行为没有变化。
根因链路:
subPath
正常 Volume 挂载
ConfigMap 更新\nfeature.yaml → 50%
kubelet 创建新 Inode\n更新 ..data 符号链接
挂载方式判断
Bind Mount 锁定旧 Inode\n新数据无法传播
Pod 内 feature.yaml\n永远是 5%
灰度比例无变化\n工程师困惑
文件原子替换\n60秒内生效
这个故障的隐蔽性在于:ConfigMap 确实更新了,kubectl get configmap 返回的是新值,但 Pod 内看到的是旧值。检查命令本身不会暴露问题,必须进入容器验证:
bash
# 确认 ConfigMap 已更新
kubectl get configmap feature-config -o jsonpath='{.data.feature\.yaml}'
# 输出:50%(ConfigMap 侧正确)
# 进入容器验证实际挂载内容
kubectl exec -it myapp-pod -- cat /config/feature.yaml
# 输出:5%(容器侧未更新,subPath 陷阱)AI Agent 的诊断能力差异:人工排查通常先查 ConfigMap(正确),再查 Pod 日志(无异常),陷入"配置明明是对的"的困惑。Agent 的扫描路径是系统化的------在诊断链路早期就会执行 subPath 检测,发现挂载方式与期望行为不符,直接定位根因。
根治方案:将 subPath 挂载改为目录挂载,配合 Reloader 控制器实现真正的热更新:
yaml
# ❌ 有问题的 subPath 写法
volumeMounts:
- name: config
mountPath: /config/feature.yaml
subPath: feature.yaml
# ✅ 修复后的目录挂载写法
volumeMounts:
- name: config
mountPath: /config # 挂载整个目录,kubelet 的原子替换机制正常工作
volumes:
- name: config
configMap:
name: feature-config如果业务上确实只需要挂载单个文件,可以在容器启动脚本中从挂载目录软链到目标路径,保留目录挂载的热更新能力,同时维持单文件的使用体验。
为什么这个场景值得重点关注:
功能开关是现代系统的核心基础设施------灰度发布、A/B 测试、紧急熔断都依赖它。当功能开关的配置更新机制本身失效,整个灰度体系就成了哑火的武器:改了配置、以为生效、实际没变------这比完全不能改更危险,因为你以为自己有控制权。
第四章:Secret 安全管理------从"保管密码"到"不持有密码"
4.1 静态密钥的本质困境
GitHub 上 2400 万个泄露凭据的现状,揭示了一个根本性的设计问题:静态密钥的存在本身就是风险。
对于 AI Agent 而言,这个问题被放大了。Agent 是"行动主体",能自主决定何时调用哪个工具。如果 Agent 持有长期有效的数据库密码,任何一次成功的 Prompt 注入攻击,都可能让攻击者通过 Agent 作为跳板,无感知地访问数据库。
解法不是"让 Agent 更安全地保管密码",而是让 Agent 从架构上不再持有密码。
4.2 Zero Standing Privileges(零常驻权限)
ZSP 的核心逻辑极简:Agent 仅在任务执行的瞬间获取短时凭证,任务结束凭证即销毁。 不存在可以泄露的静态凭证,因为 Agent 手中从未持有过长期有效的密钥。
AI Agent 发起任务
MCP 服务器\n身份验证中介
动态凭证平台\nAkeyless / Vault
临时凭证注入\n内存级,仅任务周期
Agent 执行操作
任务完成\n凭证销毁,零残留
决策逻辑与凭证发放分离
DFC 分布式片段加密\n任何单一系统无法重构密钥
完整证据链\n无凭证残留
三条核心原则:
零知识架构:密钥拆分为多个片段存放在不同信任域(DFC 分布式片段加密),只有合法请求触发时临时聚合。任何单一系统,甚至基础设施提供商,都无法重构完整的密钥材料。
Agent 操作边界:Agent 不直接读取 Secret 明文,仅操作元数据(轮换策略、到期时间、健康状态)。明文由安全平台通过 Sidecar 注入或内存映射在运行时提供,Agent 的代码路径根本不触及明文。
凭证零残留:任务结束即刻销毁凭证,不缓存、不写日志、不留内存残留。
4.3 Agent 操作 Secret 的合规边界
yaml
# ✅ Agent 可操作:仅访问 Secret 元数据
apiVersion: v1
kind: Secret
metadata:
name: db-credentials
annotations:
last-rotated: "2026-05-01" # Agent 可读写
rotation-policy: "30d" # Agent 可读写
rotation-status: "healthy" # Agent 可读写
type: Opaque
data:
# password 字段由安全平台动态注入,Agent 路径不可见
password: <动态注入,Agent 不可读>操作红线:
bash
# ✅ 合规:操作元数据,触发轮换
kubectl get secret db-credentials -o jsonpath='{.metadata.annotations}'
akeyless rotate-key --name /k8s/db-credentials
# ❌ 禁止:读取 Secret 明文
kubectl get secret db-credentials -o jsonpath='{.data.password}' | base64 -d第五章:存储容量预测性扩容
5.1 双阈值告警体系
被动响应(收到"磁盘满了"告警再处理)的问题不在于响应慢,而在于高水位时扩容会触发 IO 竞争,进一步影响写入性能。解法是在系统"还有余量"时就介入------这需要双阈值设计:
80% 阈值触发 Agent "建议模式":生成诊断报告和扩容方案,等待人工确认。此时系统运行正常,有充裕的决策时间。
95% 阈值触发 Agent 自动扩容(如果策略允许):此时已接近临界,每一分钟都有数据写入失败的风险,等待人工审批的 15 分钟代价过高。
promql
# 80% 预警规则
(kubelet_volume_stats_used_bytes / kubelet_volume_stats_capacity_bytes) > 0.8
# 95% P0 告警规则
(kubelet_volume_stats_used_bytes / kubelet_volume_stats_capacity_bytes) > 0.955.2 pvc-autoresizer 联动配置
yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: pd.csi.storage.gke.io
allowVolumeExpansion: true # 必须显式设置,默认不允许扩容
yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgresql-pvc
annotations:
resize.topolvm.io/storage_limit: "100Gi" # 扩容上限,防止无限扩
resize.topolvm.io/threshold: "20%" # 剩余空间低于 20% 触发
resize.topolvm.io/increase: "20Gi" # 每次扩容步长
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem # Block 模式不支持自动扩容
storageClassName: standard
resources:
requests:
storage: 10Gi三个常见扩容失败原因:
allowVolumeExpansion: true缺失------最常见,没有这个配置,API Server 直接拒绝扩容请求- 未设置
storage_limit注解------autoresizer 不处理没有上限的 PVCvolumeMode: Block------Block 模式不支持在线扩容,必须使用 Filesystem
第六章:配置版本管理与 GitOps 审计
6.1 GitOps 下的一个关键红线
GitOps 模式中有一条反直觉的操作禁忌:不要在 ArgoCD/Flux 环境下执行 kubectl rollout undo。
rollout undo 直接修改集群状态,绕过 Git 仓库这个"唯一真理源"。下次 ArgoCD/Flux 同步时,会检测到集群状态与 Git 不一致,并将其覆盖为 Git 中的版本------你的回滚被"撤销"了,而且没有任何告警。
正确回滚路径:
bash
git revert <commit-hash>
git push origin main
# ArgoCD 检测到 Git 变更,自动同步到集群从 Git 回滚的本质是"把历史状态声明为期望状态",ArgoCD 会把集群收敛到这个状态。变更记录完整保留在 Git 历史中,审计合规,可追溯。
6.2 变更全链路审计架构
需要回滚
变更请求
Git Commit\n内容 + 原因 + 关联 Issue
CI/CD 流水线\n语法验证 + Hash 计算
ArgoCD/Flux\n同步到集群
Reloader 触发\n滚动更新
AI Agent 验证\nPod 状态 + 应用指标
审计日志\n操作人 + 变更内容 + 结果
git revert\n从源头回滚
每个环节的职责分工:Git 负责版本记录,CI/CD 负责合规验证,ArgoCD 负责声明式同步,Reloader 负责热更新触发,AI Agent 负责变更后验证,审计日志负责合规存证。
第七章:行业验证------规模化运维的效率基准
7.1 工商银行:千卡集群的"慢节点"诊断从 4 天到分钟级
工商银行搭建了同业首个千卡规模的全栈自主创新大模型训练集群。在千卡并行训练中,单节点性能衰退("慢节点")会导致整个训练任务被拖慢------传统离线日志分析需要 3-4 天才能定位到具体慢卡,在此期间集群算力被持续浪费。
解决方案是基于 openEuler 的 sysTrace 工具构建 AI 自动诊断系统:
- 数据采集:通过 eBPF 在内核层非侵入式采集各节点的迭代延迟、作业拓扑和系统指标,形成时间序列
- 算法库支持:集成 SPOT(流式极值检测)、k-sigma、异常节点聚类和相似度测量等多种算法
- 多维比对:空间维------基于任务拓扑对节点分组,用聚类算法识别组内离群节点;时间维------将单节点实时指标与其历史基线比对,判定是否存在性能衰减
效果:系统可自动输出异常时间戳和异常指标,精确定位慢节点/慢卡。识别准确率达 85%+(召回率),故障定位从 3-4 天缩短到分钟级。¹
7.2 OpenAI:一行配置释放 30,000 个 CPU 核心²
OpenAI 处理每日 9PB+ 日志时,集群遭遇 CPU 耗尽和关键日志丢失。通过 perf 分析发现 Fluent Bit 的 inotify 机制导致了数百万次不必要的系统调用------每次日志文件刷新都触发与内核态的上下文切换,在高吞吐场景下产生了巨大的 CPU 开销。
优化手段是一行配置变更:调整 inotify 的文件变动监控策略。效果是 Fluent Bit CPU 使用率降低 50%,集群释放了 30,000 个 CPU 核心。
这个案例揭示了一个运维自动化的核心信息不对称:传统监控(Prometheus/Grafana)只告诉你"CPU 高了",不告诉你"为什么高"。AI Agent 的诊断路径(指标异常 → perf 分析 → inotify 调用追踪 → 配置优化)可以自动关联指标与根因------当这种能力规模化,就能在故障发生之前发现性能衰退。
7.3 得物:280 台 Node 的打标时间从 1 小时到 3 分钟³
得物构建的中间件运维平台将传统黑屏脚本(逐台检查 CPU/内存余量、污点和磁盘类型)转化为白屏化操作,通过 AI Agent 实现实时多维筛选、批量打标和污点管理。
大促场景下 280+ 台 Node 的筛选打标时间从 1 小时缩短至 3 分钟,提升 20 倍。效率提升的本质不在于脚本跑得更快,而在于消除了人工校对每台 Node 状态的认知负荷------AI Agent 在整个集群范围内同时扫描,人只需要确认筛选条件和执行结果。
7.4 Loblaw:1,400 个边缘门店的 GitOps 迁移⁴
Loblaw 将 1,400 个分布式门店从 ESXi 迁移到 K8s,采用 Hub-and-Spoke 架构:命令式引导阶段用 Ansible 做初始安装,声明式运维阶段通过 Git 仓库管理集群配置、网络(Cilium)和存储(PV/CSI)。KubeVirt 作为虚拟化层,让旧有的 Java 遗留应用(如药房管理系统)与新兴微服务在同一硬件上并存运行。
迁移策略是每晚自动迁移 10 家门店,每一步保留回滚能力。1,400 家门店历时 140 晚完成全程迁移,全程无因迁移导致的服务中断。
数据来源:
- ¹ 工商银行基于 openEuler 的千卡训练集群与 AI 诊断慢节点实践(openEuler 技术峰会 2025)
- ² OpenAI 大规模日志 pipeline 性能优化案例(Fluent Bit 社区分享)
- ³ 得物 Kubernetes 中间件运维平台白屏化转型实践(得物技术博客)
- ⁴ Loblaw 零售边缘 KubeVirt 迁移实践(KubeCon NA 2024 分享)
总结:三个认知转变
配置与存储运维的"隐形杀手",本质是 K8s 解耦设计带来的必然代价。AI Agent 不能消除这个代价,但能通过标准化的"检测→分析→修复→验证"闭环,让代价变得可控、可预测、可审计。
认知一:从"改完等生效"到"先查引用方式"。ConfigMap 的三种引用方式行为差异巨大,不先确认引用方式就操作配置,是配置事故的第一大根源。
认知二:从"给 Agent 权限"到"给 Agent 刹车"。AI Agent 的能力越强,安全护栏越要严密。四步流程和三条红线不是对 Agent 能力的限制,而是让 Agent 在生产环境真正可用的前提条件。
认知三:从"存储告警响应"到"预测性扩容"。双阈值告警体系把存储运维从被动救火变为主动预防------在系统还有余量时介入,避免了高水位扩容带来的 IO 竞争风险。
速查手册
AI Agent 安全变更 Checklist
| 阶段 | 检查项 | 跳过代价 | 优先级 |
|---|---|---|---|
| 变更前 | 确认 Pod Spec 中的引用方式 | 误判导致变更不生效 | P0 |
| 变更前 | GetResourceYAML 备份当前状态 | 回滚时数据丢失 | P0 |
| 变更前 | Dry-run 验证语法 | 提交错误 YAML | P1 |
| 变更中 | 高风险必须经过审批回路 | Agent 误操作导致 P0 | P0 |
| 变更中 | 灰度发布(金丝雀比例) | 全量推送导致大面积故障 | P1 |
| 变更后 | 自动验证 Pod 状态 + 应用指标 | 配置未生效但无感知 | P0 |
| 变更后 | 审计日志记录 | 合规审计不通过 | P1 |
PVC 故障排查快速矩阵
| Event 关键词 | 根因 | 第一步操作 |
|---|---|---|
not found |
SC 名称错误 / PVC 缺失 | kubectl get pvc && kubectl get sc |
ProvisioningFailed |
存储配额或 CSI 异常 | kubectl get events --sort-by=lastTimestamp |
multi-attach |
RWO PVC 被多节点挂载 | kubectl describe pvc 查看挂载节点 |
volume node affinity |
跨 Zone 调度冲突 | 检查 volumeBindingMode 和 Pod 调度策略 |
| Provisioner 无响应 | CSI Driver 异常 | `kubectl get pods -n kube-system |
ConfigMap 热更新策略选择
| 场景 | 推荐策略 | 关键注意点 |
|---|---|---|
| 快速落地,存量改造 | Reloader 控制器 | subPath 不受管控,需单独处理 |
| ArgoCD/Flux 环境 | 配置 Hash 注入 | Hash 变更需 CI/CD 联动 |
| 金融 / 合规严格场景 | 不可变配置(Immutable) | 版本管理流程成本较高 |
| 功能开关 / 动态配置 | 目录挂载 + Reloader | 禁止使用 subPath |
💬 加入讨论:你在生产遇到过哪类"冷知识级"的 ConfigMap 踩坑?subPath 的 Inode 锁定陷阱,还是 envFrom 新旧值混用的幻觉一致性?欢迎评论区分享你的「隐形杀手」故事。