案例2:成年人群体收入预测
案例背景
下面我们通过一个案例来具体说明决策树的方法。本案例使用的数据集包含资本原始积累、每周工作时长、教育程度等字段。我们需要通过这些字段来预测这些人的收入状况,判断是否是高收入人群(收入大于50K)
数据读取与划分
python
# 读入相应的文件
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, roc_auc_score, roc_curve, accuracy_score
from sklearn.tree import export_graphviz
import graphviz
df = pd.read_csv("./adult.csv")
df.head()| | age | workclass | fnlwgt | education | education.num | marital.status | occupation | relationship | race | sex | capital.gain | capital.loss | hours.per.week | native.country | income |
| 0 | 90 | ? | 77053 | HS-grad | 9 | Widowed | ? | Not-in-family | White | Female | 0 | 4356 | 40 | United-States | <=50K |
| 1 | 82 | Private | 132870 | HS-grad | 9 | Widowed | Exec-managerial | Not-in-family | White | Female | 0 | 4356 | 18 | United-States | <=50K |
| 2 | 66 | ? | 186061 | Some-college | 10 | Widowed | ? | Unmarried | Black | Female | 0 | 4356 | 40 | United-States | <=50K |
| 3 | 54 | Private | 140359 | 7th-8th | 4 | Divorced | Machine-op-inspct | Unmarried | White | Female | 0 | 3900 | 40 | United-States | <=50K |
| 4 | 41 | Private | 264663 | Some-college | 10 | Separated | Prof-specialty | Own-child | White | Female | 0 | 3900 | 40 | United-States | <=50K |
|---|
python
# 查看后我们发现有些是数值型的列,有些是标签或分类,因此我们接下来可能需要对标签列进行数值化处理
df.columns = ["age", "workclass", "fnlwgt", "education", "education_num", "marital_status",
"occupation", "relationship", "race", "sex", "capital_gain", "capital_loss",
"hours_per_week", "native_country", "income"]
df.isnull().sum()age 0
workclass 0
fnlwgt 0
education 0
education_num 0
marital_status 0
occupation 0
relationship 0
race 0
sex 0
capital_gain 0
capital_loss 0
hours_per_week 0
native_country 0
income 0
dtype: int64
python
# 文件中不存在值为NaN的值,但是数据中存在大量的?,这些?需要我们进一步处理
numeric = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
categorical = ["workclass", "education", "marital_status", "occupation",
"relationship", "race", "sex", "native_country", "income"]
df = df[~df[categorical].apply(lambda row: row.str.contains('\?', na=False)).any(axis=1)]
df = df[df.workclass != "never-worked"]
df = df[df.workclass != "without-pay"]
df = df[df.occupation != "Armed-Forces"]
df = df[df.native_country != "Holand-Netherlands"]
# 对education这一档进行处理
df["education"] = df["education"].str.replace("1st-4th", "Elementary-School")
df["education"] = df["education"].str.replace("5th-6th", "Elementary-School")
df["education"] = df["education"].str.replace("7th-8th", "Elementary-School")
df["education"] = df["education"].str.replace("9th", "High-School")
df["education"] = df["education"].str.replace("10th", "High-School")
df["education"] = df["education"].str.replace("11th", "High-School")
df["education"] = df["education"].str.replace("12th", "High-School")
df["education"] = df["education"].str.replace("Masters", "Postgraduate")
df["education"] = df["education"].str.replace("Doctorate", "Postgraduate")
df["education"] = df["education"].str.replace("Bachelors", "Undergraduate")
df["education"] = df["education"].str.replace("Some-college", "Undergraduate")
python
# 对标签或分类的列进行处理,需要将他们转换成为数值型
def label_encoder(column):
le = LabelEncoder().fit(column)
return le.transform(column)
for col in categorical:
df[col] = label_encoder(df[col])
df.head()| | age | workclass | fnlwgt | education | education_num | marital_status | occupation | relationship | race | sex | capital_gain | capital_loss | hours_per_week | native_country | income |
| 1 | 82 | 2 | 132870 | 3 | 9 | 6 | 2 | 1 | 4 | 0 | 0 | 4356 | 18 | 37 | 0 |
| 3 | 54 | 2 | 140359 | 2 | 4 | 0 | 5 | 4 | 4 | 0 | 0 | 3900 | 40 | 37 | 0 |
| 4 | 41 | 2 | 264663 | 8 | 10 | 5 | 8 | 3 | 4 | 0 | 0 | 3900 | 40 | 37 | 0 |
| 5 | 34 | 2 | 216864 | 3 | 9 | 0 | 6 | 4 | 4 | 0 | 0 | 3770 | 45 | 37 | 0 |
| 6 | 38 | 2 | 150601 | 4 | 6 | 5 | 0 | 4 | 4 | 1 | 0 | 3770 | 40 | 37 | 0 |
|---|
python
# 训练集和测试集的划分
data = df
labels = np.array(data.pop('income'))
train, test, train_labels, test_labels = train_test_split(data, labels,
stratify = labels,
test_size = 0.3,
random_state = 514)
train = train.fillna(train.mean())
test = test.fillna(test.mean())
features = list(train.columns)模型搭建与训练
python
# 决策树的模型训练
tree = DecisionTreeClassifier(random_state=42, max_depth=3,max_leaf_nodes=5)
tree.fit(train, train_labels)
print(f'Decision tree has {tree.tree_.node_count} nodes with maximum depth {tree.tree_.max_depth}.')Decision tree has 9 nodes with maximum depth 3.
python
# 模型在测试集上的表现
probs = tree.predict_proba(test)[:, 1]
predictions = tree.predict(test)
print(f'Test accuracy Score: {accuracy_score(predictions, test_labels)}')
print(f'Test ROC AUC Score: {roc_auc_score(test_labels, probs)}')Test accuracy Score: 0.8217996904709264
Test ROC AUC Score: 0.8308394043223805
python
# 影响最大的列
fi = pd.DataFrame({'feature': features,
'importance': tree.feature_importances_}).\
sort_values('importance', ascending = False)
fi.head(10)| | feature | importance |
| 7 | relationship | 0.610118 |
| 4 | education_num | 0.223226 |
| 10 | capital_gain | 0.166656 |
| 0 | age | 0.000000 |
| 1 | workclass | 0.000000 |
| 2 | fnlwgt | 0.000000 |
| 3 | education | 0.000000 |
| 5 | marital_status | 0.000000 |
| 6 | occupation | 0.000000 |
| 8 | race | 0.000000 |
|---|
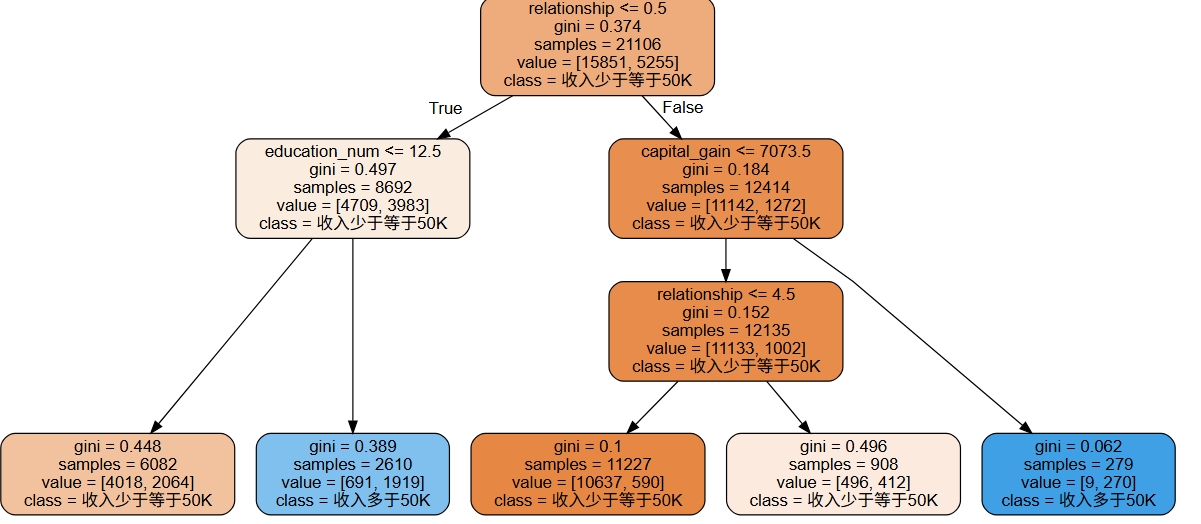
python
# 决策树的可视化
dot_data = export_graphviz(tree, rounded = True,
feature_names = features,
class_names = ['收入少于等于50K', '收入多于50K'], filled = True,leaves_parallel=True)
graph = graphviz.Source(dot_data)
graph