摘要
决策树作为机器学习中最具解释性的算法之一,以其直观的分而治之思想和强大的非线性拟合能力,成为数据科学领域的基石。而集成学习通过三个臭皮匠顶个诸葛亮的智慧,将多个弱学习器组合成强学习器,在各类机器学习竞赛和工业应用中屡创佳绩。本文将从数学原理出发,系统讲解决策树的构建过程、三大分裂准则(信息增益、信息增益比、基尼系数),深入剖析集成学习的三大范式(Bagging、Boosting、Stacking),并对随机森林、AdaBoost、GBDT、XGBoost 四大经典算法进行源码级解析。同时,本文提供完整的 Python 代码实现和三大工业应用案例,帮助读者从理论到实践全面掌握树模型的精髓。
一、决策树基础:分而治之的智慧
1. 决策树简介(入门引导)
决策树是一种树形结构,其中:
-
内部节点:表示一个特征上的判断
-
分支:代表一个判断结果的输出
-
叶子节点:代表最终的分类结果
决策树建立的三个核心步骤:
-
特征选择:选取有较强分类能力的特征
-
决策树生成:根据选择的特征生成决策树
-
剪枝:决策树容易过拟合,采用剪枝方法缓解过拟合问题
直观案例:相亲决策树
通过年龄→长相→收入→公务员的逐层判断,最终决定见或不见,完美体现了决策树的分层决策逻辑。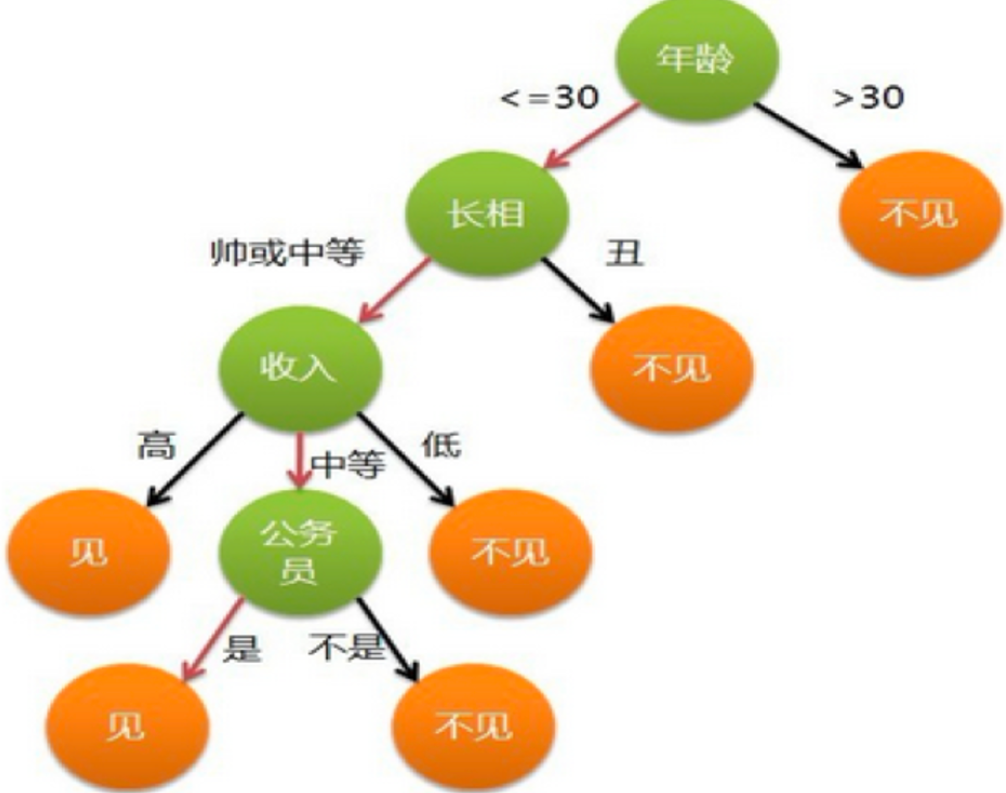
1.1 什么是决策树
决策树(Decision Tree)是一种基于树结构进行决策的监督学习算法。它模拟人类决策过程,通过一系列 "是 / 否" 问题的回答,最终得出分类或回归结果。从根节点开始,每个内部节点代表一个特征测试,每个分支代表测试结果,每个叶子节点代表最终的决策输出。
决策树的核心思想:将复杂的决策问题分解为一系列简单的子问题,通过递归划分实现对数据空间的超矩形划分。
1.2 决策树的基本组成
一棵完整的决策树包含以下要素:
-
根节点(Root Node):整个树的起点,包含全部训练数据
-
内部节点(Internal Node):代表某个特征的测试条件
-
分支(Branch):代表测试条件的可能取值
-
叶子节点(Leaf Node):最终的决策结果(类别或数值)
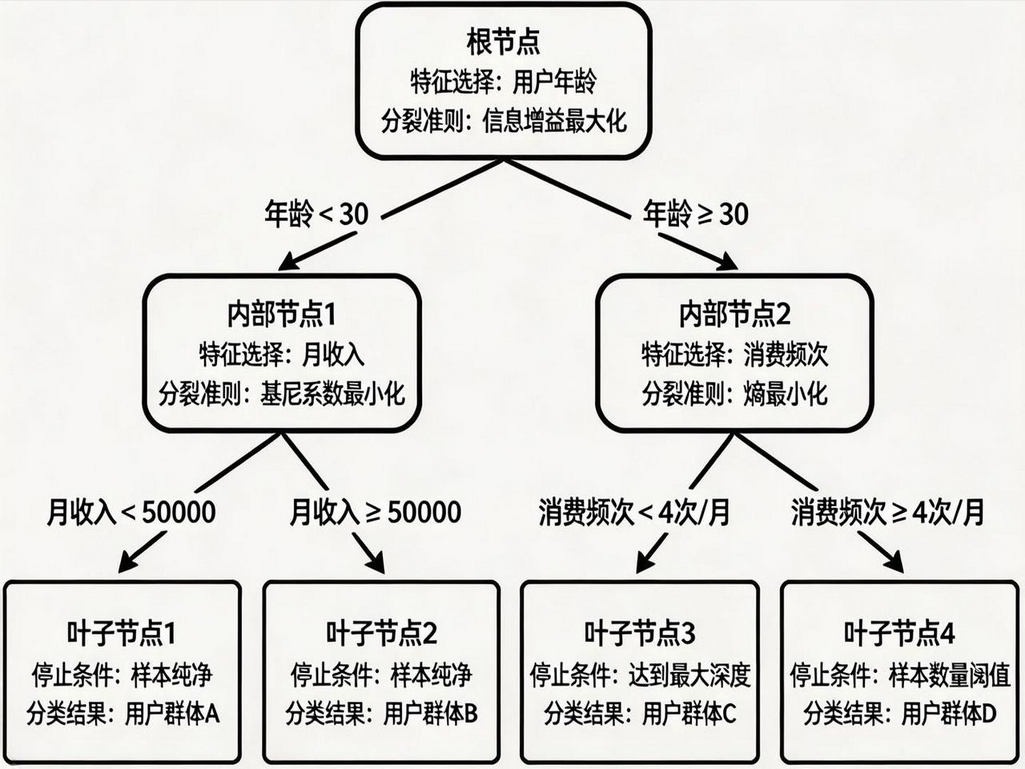
1.3 决策树的递归构建过程
决策树的构建是一个递归过程,遵循以下步骤:
-
开始:所有样本位于根节点
-
特征选择:选择最优特征作为当前节点的分裂依据
-
节点分裂:根据特征取值将样本划分到不同子节点
-
递归处理:对每个子节点重复步骤 2-3
-
停止条件:满足以下任一条件时停止分裂:
-
节点样本属于同一类别(样本纯净)
-
没有更多特征可供分裂
-
达到预设的最大深度
-
节点样本数小于最小分裂阈值
-
1.4 决策树的数学本质
从几何角度看,决策树本质上是对特征空间进行轴平行的超矩形划分。每一次分裂相当于在某个特征维度上画一条垂直于坐标轴的分割线,将当前区域划分为两个子区域。经过多次分裂后,整个特征空间被划分为若干不重叠的超矩形,每个矩形对应一个叶子节点的输出值。
从信息论角度看,决策树的每一次分裂都在降低系统的不确定性(熵或基尼系数),使得子节点的样本纯度高于父节点。
二、决策树构建:特征选择与分裂准则
2.1 特征选择的核心问题
特征选择是决策树构建中最关键的一步。其核心问题是:在当前节点,选择哪个特征进行分裂能最大程度地提升样本纯度?
一个好的分裂准则应该满足:
-
分裂后的子节点纯度显著高于父节点
-
计算效率高,适合大规模数据
-
对不同类型的特征(离散 / 连续)有良好适应性
-
对异常值和噪声具有鲁棒性
2.2 纯度度量的数学基础
在深入三大分裂准则之前,我们首先理解纯度的数学定义。对于一个包含 K 个类别的节点,设第 k 类样本的比例为pkp_kpk,则:
纯度 = 1 - 不同类别样本混合的程度
当节点中所有样本属于同一类别时,纯度达到最大值 1;当各类别样本均匀分布时,纯度达到最小值。
三、三大分裂准则深度对比
3.1 信息增益(ID3 算法)
3.1.1 熵的定义
信息增益基于香农熵(Shannon Entropy),熵是衡量系统不确定性的指标:
H(D)=−∑k=1Kpklog2pkH(D) = -\sum_{k=1}^{K} p_k \log_2 p_kH(D)=−∑k=1Kpklog2pk
其中:
-
DDD 表示当前节点的数据集
-
pkp_kpk 表示第 k 类样本在 D 中的比例
-
约定 0log20=00 \log_2 0 = 00log20=0
熵的性质:
-
当所有样本属于同一类时,H(D)=0H(D) = 0H(D)=0(完全确定)
-
当各类别均匀分布时,H(D)=log2KH(D) = \log_2 KH(D)=log2K(最大不确定性)
-
熵值越大,系统越混乱,纯度越低
3.1.2 条件熵
条件熵表示在已知特征 A 的条件下,数据集 D 的不确定性:
H(D∣A)=∑v=1V∣Dv∣∣D∣H(Dv)H(D|A) = \sum_{v=1}^{V} \frac{|D_v|}{|D|} H(D_v)H(D∣A)=∑v=1V∣D∣∣Dv∣H(Dv)
其中:
-
VVV 是特征 A 的取值个数
-
DvD_vDv 是特征 A 取第 v 个值的样本子集
3.1.3 信息增益
信息增益 = 原始熵 - 条件熵,表示通过特征 A 分裂后不确定性减少的程度:
g(D,A)=H(D)−H(D∣A)g(D, A) = H(D) - H(D|A)g(D,A)=H(D)−H(D∣A)
ID3 算法核心:在每个节点选择信息增益最大的特征进行分裂。
3.1.4 ID3 的局限性
-
偏向取值多的特征:取值数目多的特征往往信息增益更大(如 ID 类特征)
-
只能处理离散特征:无法直接处理连续值
-
对缺失值敏感:缺失值会影响熵的计算
-
容易过拟合:没有剪枝机制
3.2 信息增益比(C4.5 算法)
为解决 ID3 偏向多值特征的问题,Ross Quinlan 提出了信息增益比:
gR(D,A)=g(D,A)HA(D)g_R(D, A) = \frac{g(D, A)}{H_A(D)}gR(D,A)=HA(D)g(D,A)
其中,HA(D)H_A(D)HA(D) 是特征 A 的固有值(Intrinsic Value):
HA(D)=−∑v=1V∣Dv∣∣D∣log2∣Dv∣∣D∣H_A(D) = -\sum_{v=1}^{V} \frac{|D_v|}{|D|} \log_2 \frac{|D_v|}{|D|}HA(D)=−∑v=1V∣D∣∣Dv∣log2∣D∣∣Dv∣
C4.5 的改进:
-
使用信息增益比代替信息增益,惩罚取值多的特征
-
支持连续特征离散化(二分法)
-
支持缺失值处理(概率加权)
-
引入剪枝机制(悲观剪枝)
3.3 基尼系数(CART 算法)
3.3.0 CART 树初识
CART 全称:分类与回归树(Classification and Regression Tree)
你可以把它想象成一棵倒过来的树,通过一层一层的是 / 否问题,不断对数据进行逻辑判断和划分,把一堆杂乱的数据分到不同的小群体里,最终得出一个明确的结论。
两大核心功能:
-
分类功能(Classification):判断一件事属于哪一类(离散值输出)
- 示例:判断一封邮件是不是垃圾邮件?这个西瓜甜不甜?这篇新闻是属于体育还是财经?
-
回归功能(Regression):预测一个具体的数值(连续值输出)
- 示例:预测明天的房价是多少?这个学生期末考试能考多少分?下个月店铺的营业额大概是多少?
背景说明:CART 树的提出正是为了解决 ID3/C4.5 等前辈算法的局限性。
3.3.1 基尼系数的定义
基尼系数衡量从数据集中随机抽取两个样本,其类别标记不一致的概率:
Gini(D)=1−∑k=1Kpk2Gini(D) = 1 - \sum_{k=1}^{K} p_k^2Gini(D)=1−∑k=1Kpk2
基尼系数的性质:
-
取值范围:0,1−1K0, 1-\\frac{1}{K}0,1−K1
-
基尼系数越小,样本纯度越高
-
计算无需对数运算,速度更快
3.3.2 基尼指数
特征 A 的基尼指数定义为:
Gini(D,A)=∑v=1V∣Dv∣∣D∣Gini(Dv)Gini(D, A) = \sum_{v=1}^{V} \frac{|D_v|}{|D|} Gini(D_v)Gini(D,A)=∑v=1V∣D∣∣Dv∣Gini(Dv)
CART 算法核心:选择基尼指数最小的特征进行分裂。

3.3.3 CART 的特点
-
二叉树结构:每次分裂只产生两个子节点(无论特征取值多少)
-
支持分类和回归:
-
分类:使用基尼系数
-
回归:使用均方误差(MSE)或绝对误差(MAE)
-
-
连续特征处理:自动寻找最优分裂点
-
剪枝策略:代价复杂度剪枝(CCP)
3.4 三大准则对比总结
| 特性 | 信息增益 (ID3) | 信息增益比 (C4.5) | 基尼系数 (CART) |
|---|---|---|---|
| 数学基础 | 熵 | 熵 + 固有值 | 基尼不纯度 |
| 计算复杂度 | 高(对数) | 高(对数) | 低(平方) |
| 偏向性 | 偏向多值特征 | 偏向少值特征 | 适中 |
| 树结构 | 多叉树 | 多叉树 | 二叉树 |
| 任务类型 | 仅分类 | 仅分类 | 分类 + 回归 |
| 连续特征 | 不支持 | 支持(二分) | 支持 |
| 缺失值 | 不支持 | 支持 | 支持 |
工程实践建议:
-
优先使用 CART(sklearn 默认),计算效率高且功能全面
-
当特征取值数目差异很大时,考虑 C4.5 的信息增益比
-
解释性要求高的场景,CART 二叉树更易理解
四、决策树剪枝与优化
4.1 为什么需要剪枝
决策树具有强大的拟合能力,如果不加限制,会一直分裂直到每个叶子节点只有一个样本,这就是过拟合。过拟合的决策树在训练集上表现完美,但在测试集上泛化能力极差。
剪枝的核心思想:通过主动去掉一些分支,降低模型复杂度,提高泛化能力。
4.2 预剪枝(Pre-pruning)
预剪枝是在树构建过程中就进行限制,常用的预剪枝参数:
-
max_depth:树的最大深度
-
min_samples_split:节点分裂所需的最小样本数
-
min_samples_leaf:叶子节点所需的最小样本数
-
max_leaf_nodes:最大叶子节点数
-
min_impurity_decrease:分裂所需的最小不纯度下降值
优点 :计算效率高,直接在构建过程中控制
缺点:可能出现欠剪枝,提前停止可能错过更好的分裂
4.3 后剪枝(Post-pruning)
后剪枝是先生成一棵完整的决策树,然后自底向上对非叶子节点进行评估,如果将该节点替换为叶子节点能提升泛化性能,则进行剪枝。
4.3.1 代价复杂度剪枝(CCP)
CART 使用的剪枝方法,定义损失函数:
Cα(T)=C(T)+α∣T∣C_\alpha(T) = C(T) + \alpha |T|Cα(T)=C(T)+α∣T∣
其中:
-
C(T)C(T)C(T) 是训练误差(分类用基尼,回归用 MSE)
-
∣T∣|T|∣T∣ 是叶子节点数
-
α\alphaα 是正则化参数,控制剪枝强度
剪枝过程:
-
从完整树开始,计算每个非叶子节点的剪枝收益
-
剪掉收益最小的节点,生成子树序列
-
通过交叉验证选择最优的α\alphaα和对应的子树
4.4 决策树的优缺点分析
优点
-
解释性强:树结构可视化,决策过程清晰
-
数据预处理要求低:无需归一化,对特征尺度不敏感
-
可处理混合类型:同时支持离散和连续特征
-
天然支持多分类:无需修改即可处理多类别问题
-
可解释特征重要性:能输出每个特征的重要程度
缺点
-
容易过拟合:需要精心调参和剪枝
-
不稳定:数据微小变化可能导致完全不同的树结构
-
表达能力有限:只能学习轴平行的决策边界
-
对不平衡数据敏感:偏向多数类
-
无法建模特征间的复杂交互(如 XOR 问题)
五、集成学习核心思想
5.0 集成学习定义(入门引导)
集成学习是机器学习中的一种核心思想,它通过多个弱学习器的组合形成一个精度更高的强学习器。
训练时,使用训练集训练出这些弱学习器;对未知样本进行预测时,使用这些弱学习器联合进行预测。
集成学习基本架构:
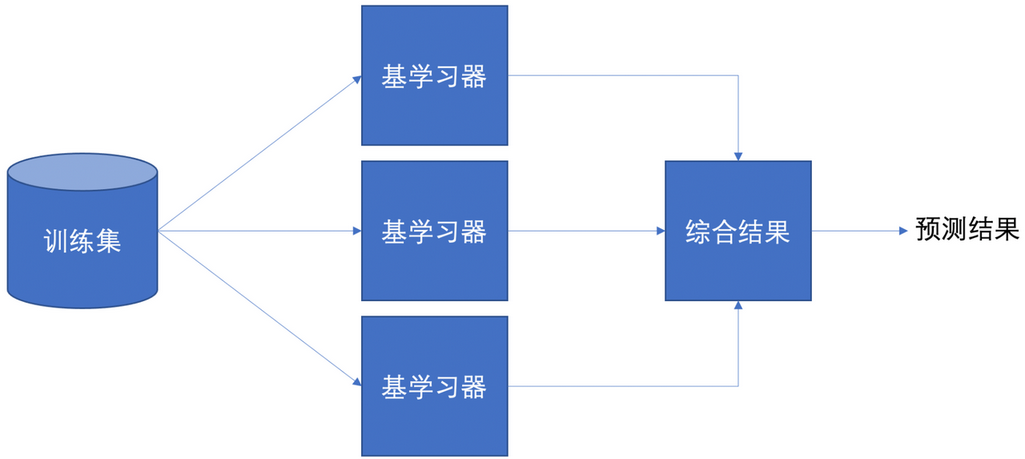
训练集 → 多个基学习器独立学习 → 综合各学习器结果 → 最终预测结果
5.1 三个臭皮匠顶个诸葛亮
集成学习(Ensemble Learning)的核心思想是:通过组合多个弱学习器(Weak Learner),形成一个强学习器(Strong Learner)。
关键洞察:
-
单个学习器可能在某些样本上犯错,但多个学习器同时犯错的概率很低
-
只要学习器之间具有多样性(Diversity),集成就能显著提升性能
5.2 集成学习的两大核心要素
要素 1:准确性(Accuracy)
每个基学习器的性能不能太差,至少要优于随机猜测。垃圾进,垃圾出,如果基学习器都是随机猜测,集成也无济于事。
要素 2:多样性(Diversity)
基学习器之间要存在差异,它们犯错的样本应该尽可能不重叠。多样性是集成效果的关键保障。
增加多样性的常用方法:
-
数据样本扰动:Bootstrap 抽样
-
输入特征扰动:随机子空间
-
算法参数扰动:不同超参数
-
输出表示扰动:不同标签处理
5.3 集成学习的误差分解
集成的泛化误差可以分解为:
Error=Bias2+Variance+NoiseError = Bias^2 + Variance + NoiseError=Bias2+Variance+Noise
-
Bias(偏差):模型预测的期望与真实值的差异,衡量拟合能力
-
Variance(方差):模型在不同训练集上的波动,衡量稳定性
-
Noise(噪声):数据本身的不可约误差
不同集成范式的侧重点:
-
Bagging:主要降低方差(Variance)
-
Boosting:主要降低偏差(Bias)
六、三大集成范式详解
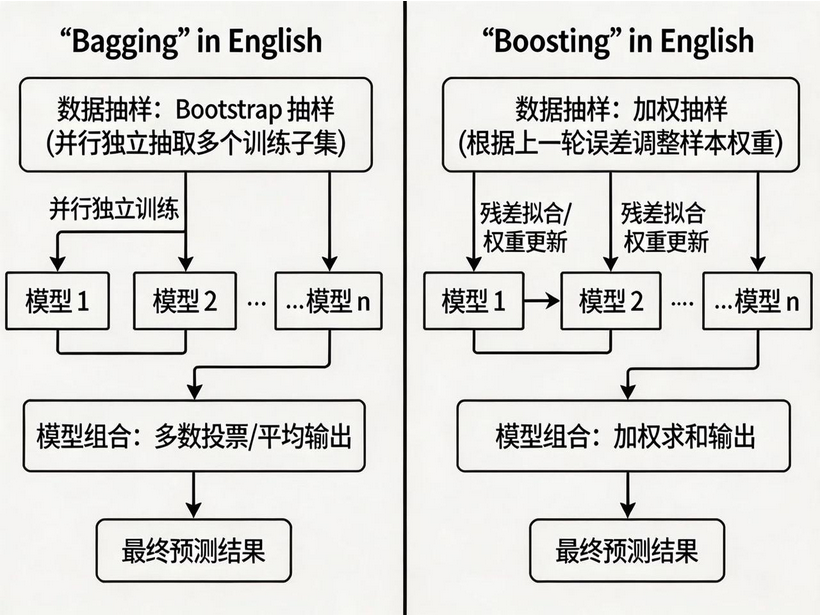
6.1 Bagging:并行集成
6.1.0 Bagging 核心思想
Bagging 方法的核心特点:
-
有放回抽样:通过 bootstrap(自助法)有放回抽样产生不同的训练集,从而训练不同的学习器
-
平权投票:通过平权投票、多数表决的方式决定最终预测结果
-
并行训练:弱学习器之间没有依赖关系,可以完全并行训练
Bagging 思想架构图:
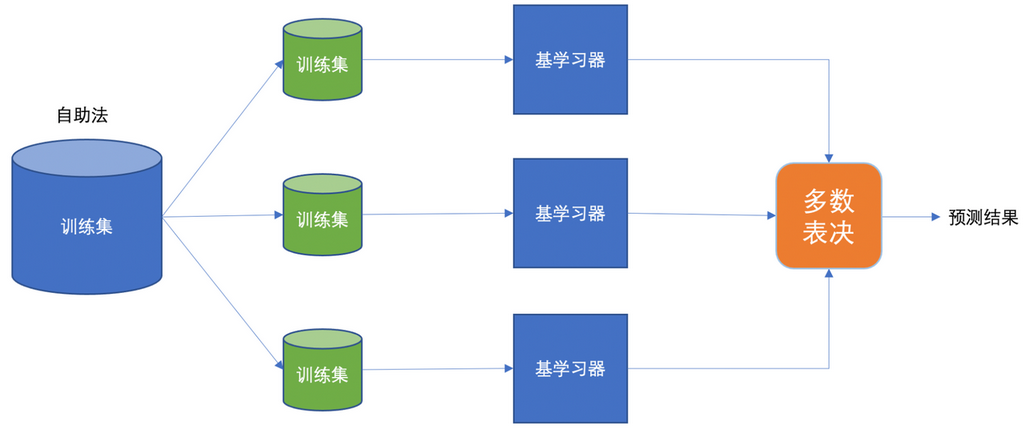
Bagging(Bootstrap Aggregating)由 Leo Breiman 于 1996 年提出,是最经典的并行集成方法。
6.1.1 Bootstrap 抽样
Bootstrap 是有放回的随机抽样:
-
从 N 个样本中有放回地抽取 N 个样本
-
理论上,每个样本被抽到的概率约为 63.2%
-
约 36.8% 的样本不会被抽到(称为 OOB 样本)
6.1.2 Bagging 算法流程
-
对于t=1t = 1t=1到TTT:
-
从原始训练集中进行 Bootstrap 抽样,得到子训练集DtD_tDt
-
在DtD_tDt上训练基学习器hth_tht
-
-
预测阶段:
-
分类任务:多数投票(Majority Voting)
-
回归任务:简单平均(Simple Averaging)
-
6.1.3 Bagging 的核心特点
-
并行训练:所有基学习器独立训练,可完全并行化
-
降低方差:通过平均多个模型的预测,显著降低方差
-
对不稳定学习器效果显著:如决策树、神经网络
-
OOB 估计:可利用袋外样本进行无偏验证
6.2 Boosting:串行集成
6.2.0 Boosting 核心思想
Boosting 方法的核心特点:
-
关注不足:每一个训练器重点关注前一个训练器不足的地方进行训练
-
加权投票:通过加权投票的方式得出预测结果,性能更好的学习器获得更高权重
-
串行训练:学习器有先后顺序,必须串行训练,后一个学习器依赖前一个的结果
Boosting 思想架构图:
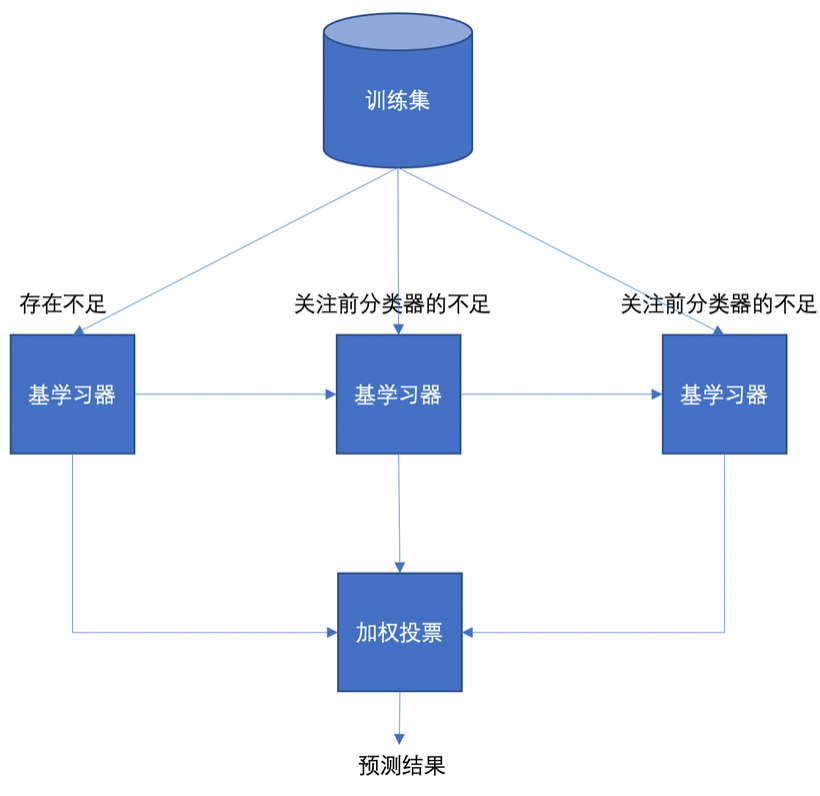
Boosting 是串行集成的代表,通过迭代训练,每一轮重点关注上一轮分错的样本。
6.2.1 Boosting 的核心思想
-
初始时所有样本权重相同
-
每轮训练一个弱学习器
-
根据学习器表现更新样本权重:
-
分对的样本:降低权重
-
分错的样本:提高权重
-
-
下一轮重点训练被错分的样本
-
最终将所有学习器加权组合
6.2.2 Boosting 的理论基础
强可学习与弱可学习等价定理(Schapire, 1990):
在概率近似正确(PAC)学习框架下,一个概念是强可学习的当且仅当它是弱可学习的。
这意味着:只要能找到比随机猜测略好的弱学习器,就一定能将其提升为强学习器!
6.3 Stacking:多层堆叠
Stacking(Stacked Generalization)是更高级的集成范式,通过元学习器组合基学习器。
6.3.1 Stacking 的两层结构
第一层(基学习器层):
-
多个不同类型的基学习器
-
每个基学习器输出预测结果作为新特征
第二层(元学习器层):
-
将基学习器的预测作为输入特征
-
训练元学习器进行最终预测
6.3.2 Stacking 的关键技巧
-
使用交叉验证生成元特征:避免信息泄露
-
基学习器多样性:尽量使用不同类型的算法
-
元学习器选择:通常使用简单模型(如逻辑回归)
七、经典算法深度解析
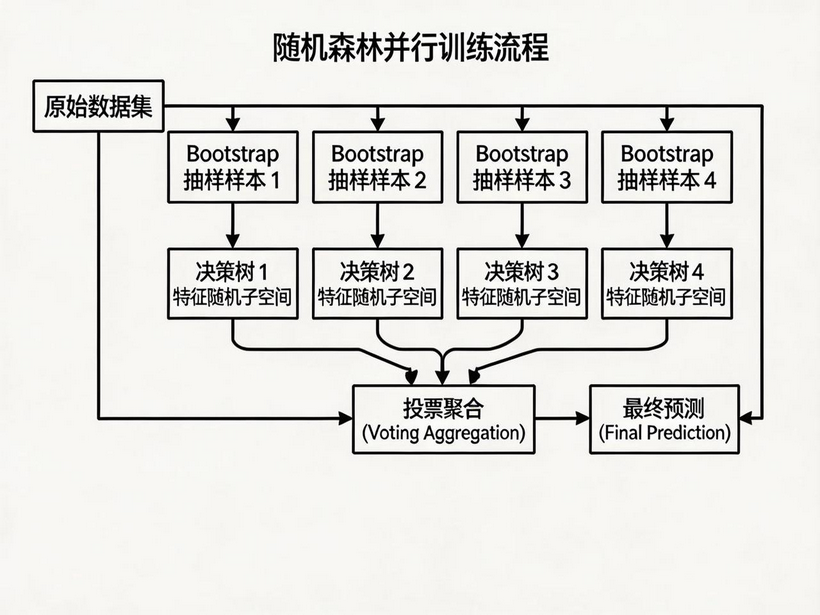
7.1 随机森林(Random Forest)
7.1.0 随机森林算法概述
随机森林是基于 Bagging 思想实现的一种集成学习算法,采用决策树模型作为每一个弱学习器。
训练特点:
-
有放回的产生训练样本(Bootstrap 抽样)
-
随机挑选 n 个特征(n 小于总特征数量)
预测方式:平权投票,多数表决输出预测结果
随机森林是 Bagging 的代表作品,由 Leo Breiman 于 2001 年提出,在 Bagging 基础上引入了特征随机子空间。
7.1.1 随机森林的两大随机性
-
样本随机性:Bootstrap 抽样(同 Bagging)
-
特征随机性:每个节点分裂时,从所有特征中随机选择 k 个特征,再从中选择最优分裂特征
推荐 k 值:
-
分类:k=dk = \sqrt{d}k=d (d 为特征总数)
-
回归:k=d/3k = d/3k=d/3
7.1.2 为什么随机森林有效
两大随机性保证了基决策树之间的多样性:
-
即使是相同的训练数据,不同树也会学到不同的模式
-
大大降低了过拟合风险
-
提升了模型的鲁棒性和泛化能力
7.1.3 特征重要性计算
随机森林可以天然计算特征重要性,常用两种方法:
方法 1:基于不纯度减少
Importance(f)=1T∑t=1T∑node∈treetΔI(node)⋅I(node.split=f)Importance(f) = \frac{1}{T} \sum_{t=1}^{T} \sum_{node \in tree_t} \Delta I(node) \cdot I(node.split = f)Importance(f)=T1∑t=1T∑node∈treetΔI(node)⋅I(node.split=f)
方法 2:基于 OOB 准确率变化(Permutation Importance)
-
计算 OOB 样本的基准准确率
-
对特征 f,随机打乱其 OOB 取值
-
计算准确率下降值,即为特征 f 的重要性
7.1.4 OOB 评估
随机森林无需单独的验证集,可直接使用 OOB 样本评估:
-
每个样本约有 36.8% 的概率成为 OOB
-
用 OOB 样本测试对应未使用它的树
-
统计所有 OOB 预测的准确率
7.2 AdaBoost:自适应提升
AdaBoost(Adaptive Boosting)由 Freund 和 Schapire 于 1997 年提出,是 Boosting 家族的经典代表。
7.2.1 AdaBoost 算法流程
输入 :训练集D=(x1,y1),...,(xN,yN)D = {(x_1,y_1),...,(x_N,y_N)}D=(x1,y1),...,(xN,yN),基学习器算法,迭代次数 T
-
初始化样本权重 :w1,i=1/N,i=1,...,Nw_{1,i} = 1/N, \quad i=1,...,Nw1,i=1/N,i=1,...,N
-
对于 t = 1 到 T :
a. 使用权重wtw_twt训练基学习器hth_tht
b. 计算hth_tht的加权错误率:
ϵt=∑i=1Nwt,iI(ht(xi)≠yi)∑i=1Nwt,i\epsilon_t = \frac{\sum_{i=1}^{N} w_{t,i} I(h_t(x_i) \neq y_i)}{\sum_{i=1}^{N} w_{t,i}}ϵt=∑i=1Nwt,i∑i=1Nwt,iI(ht(xi)=yi)c. 计算学习器权重:
αt=12ln(1−ϵtϵt)\alpha_t = \frac{1}{2} \ln\left(\frac{1-\epsilon_t}{\epsilon_t}\right)αt=21ln(ϵt1−ϵt)d. 更新样本权重:
wt+1,i=wt,iexp(−αtyiht(xi))Ztw_{t+1,i} = \frac{w_{t,i} \exp(-\alpha_t y_i h_t(x_i))}{Z_t}wt+1,i=Ztwt,iexp(−αtyiht(xi))其中ZtZ_tZt是归一化因子
-
最终强学习器 :
H(x)=sign(∑t=1Tαtht(x))H(x) = sign\left(\sum_{t=1}^{T} \alpha_t h_t(x)\right)H(x)=sign(∑t=1Tαtht(x))
7.2.2 AdaBoost 的数学解释
从指数损失函数最小化的角度,AdaBoost 每一步都在优化:
minα,h∑i=1Nexp(−yi(∑s=1t−1αshs(xi)+αh(xi)))\min_{\alpha, h} \sum_{i=1}^{N} \exp(-y_i (\sum_{s=1}^{t-1} \alpha_s h_s(x_i) + \alpha h(x_i)))minα,h∑i=1Nexp(−yi(∑s=1t−1αshs(xi)+αh(xi)))
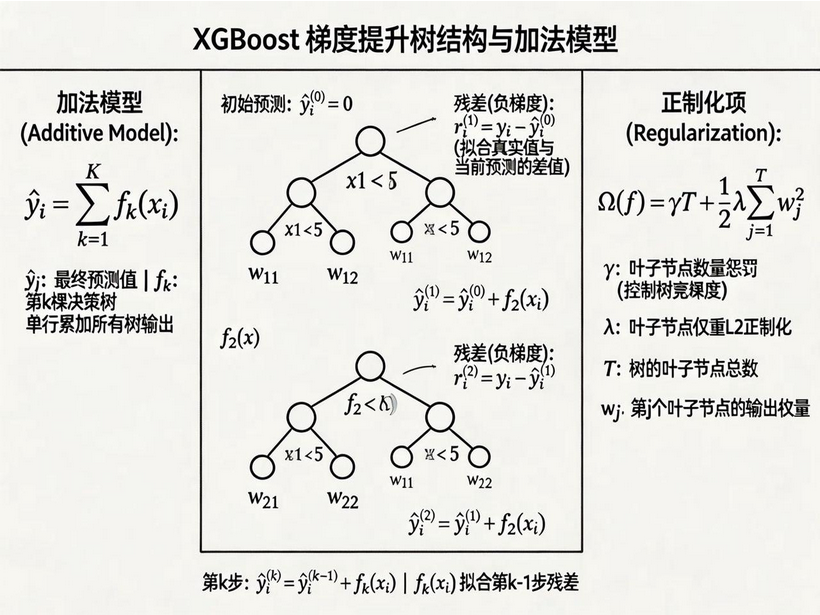
7.3 GBDT:梯度提升决策树
GBDT(Gradient Boosting Decision Tree)是 Boosting 的里程碑式工作,将梯度下降思想引入 Boosting 框架。
7.3.1 梯度提升的核心洞察
Friedman 的天才想法 :每一轮新的树,拟合损失函数的负梯度,而不是残差!
对于任意可微损失函数L(y,F(x))L(y, F(x))L(y,F(x)),第 t 轮的拟合目标是:
rt,i=−∂L(yi,F(xi))∂F(xi)F(x)=Ft−1(x)r_{t,i} = -\left\\frac{\\partial L(y_i, F(x_i))}{\\partial F(x_i)}\\right{F(x) = F{t-1}(x)}rt,i=−∂F(xi)∂L(yi,F(xi))F(x)=Ft−1(x)
这就是为什么 GBDT 可以支持任意损失函数!
7.3.2 GBDT 算法流程
-
初始化 :
F0(x)=argminc∑i=1NL(yi,c)F_0(x) = \arg\min_c \sum_{i=1}^{N} L(y_i, c)F0(x)=argminc∑i=1NL(yi,c) -
对于 t = 1 到 T :
a. 计算负梯度(伪残差):
rt,i=−∂L(yi,F(xi))∂F(xi)F=Ft−1r_{t,i} = -\left\\frac{\\partial L(y_i, F(x_i))}{\\partial F(x_i)}\\right{F=F{t-1}}rt,i=−∂F(xi)∂L(yi,F(xi))F=Ft−1b. 用rt,ir_{t,i}rt,i拟合一棵回归树ht(x)h_t(x)ht(x)
c. 线性搜索最优步长:
ρt=argminρ∑i=1NL(yi,Ft−1(xi)+ρht(xi))\rho_t = \arg\min_\rho \sum_{i=1}^{N} L(y_i, F_{t-1}(x_i) + \rho h_t(x_i))ρt=argminρ∑i=1NL(yi,Ft−1(xi)+ρht(xi))d. 更新模型:
Ft(x)=Ft−1(x)+ρtht(x)F_t(x) = F_{t-1}(x) + \rho_t h_t(x)Ft(x)=Ft−1(x)+ρtht(x) -
最终模型 :FT(x)F_T(x)FT(x)
7.3.3 常用损失函数
| 任务 | 损失函数 | 负梯度 |
|---|---|---|
| 回归 | 平方损失 L=12(y−F)2L = \frac{1}{2}(y-F)^2L=21(y−F)2 | y−Fy-Fy−F(即残差) |
| 回归 | 绝对损失 L=∣y−F∣L =|y-F|L=∣y−F∣|sign(y−F)sign(y-F)sign(y−F)| | |
| 分类 | 对数似然损失 | 概率残差 |
7.4 XGBoost:极限梯度提升
XGBoost(eXtreme Gradient Boosting)由陈天奇于 2016 年提出,是 GBDT 的工程优化集大成者,被誉为竞赛神器。
7.4.1 XGBoost 的目标函数
XGBoost 从一开始就将正则化项显式写入目标函数:
Obj(θ)=L(θ)+Ω(θ)Obj(\theta) = L(\theta) + \Omega(\theta)Obj(θ)=L(θ)+Ω(θ)
其中:
-
L(θ)L(\theta)L(θ) 是训练损失(拟合数据)
-
Ω(θ)\Omega(\theta)Ω(θ) 是正则化项(控制复杂度)
7.4.2 二阶泰勒展开
XGBoost 使用二阶泰勒展开近似损失函数,这是其精度优势的关键:
L(t)=∑i=1ngift(xi)+12hift2(xi)+Ω(ft)L^{(t)} = \sum_{i=1}^{n} \left g_i f_t(x_i) + \\frac{1}{2} h_i f_t\^2(x_i) \\right + \Omega(f_t)L(t)=∑i=1ngift(xi)+21hift2(xi)+Ω(ft)
其中:
-
一阶导数 gi=∂y^(t−1)l(yi,y^(t−1))g_i = \partial_{\hat{y}^{(t-1)}} l(y_i, \hat{y}^{(t-1)})gi=∂y^(t−1)l(yi,y^(t−1))
-
二阶导数 hi=∂y^(t−1)2l(yi,y^(t−1))h_i = \partial_{\hat{y}^{(t-1)}}^2 l(y_i, \hat{y}^{(t-1)})hi=∂y^(t−1)2l(yi,y^(t−1))
7.4.3 树的复杂度正则化
Ω(ft)=γT+12λ∑j=1Twj2\Omega(f_t) = \gamma T + \frac{1}{2} \lambda \sum_{j=1}^{T} w_j^2Ω(ft)=γT+21λ∑j=1Twj2
-
γT\gamma TγT:叶子节点数 L1 正则,控制树的宽度
-
λ∑wj2\lambda \sum w_j^2λ∑wj2:叶子权重 L2 正则,防止权重过大
7.4.4 最优分裂点计算
对于每个叶子节点 j,最优权重为:
wj∗=−GjHj+λw_j^* = -\frac{G_j}{H_j + \lambda}wj∗=−Hj+λGj
对应的目标函数减少量为:
Gain=12GL2HL+λ+GR2HR+λ−(GL+GR)2HL+HR+λ−γGain = \frac{1}{2} \left \\frac{G_L\^2}{H_L + \\lambda} + \\frac{G_R\^2}{H_R + \\lambda} - \\frac{(G_L+G_R)\^2}{H_L+H_R + \\lambda} \\right - \gammaGain=21HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2−γ
这就是 XGBoost 寻找最优分裂点的核心公式!
7.4.5 XGBoost 的工程优化
-
并行化:特征粒度的并行,预排序后多线程计算增益
-
缺失值处理:自动学习缺失值的最优分裂方向
-
加权分位数草图:高效寻找连续特征候选分裂点
-
缓存感知访问:优化内存访问模式,提升缓存命中率
-
核外计算:支持数据大于内存时的分块处理
八、算法对比与调参指南
8.1 Bagging 与 Boosting 核心对比
| 对比维度 | Bagging | Boosting |
|---|---|---|
| 数据采样 | 有放回采样 | 全部样本 + 调整权重 |
| 投票方式 | 平权投票 | 加权投票 |
| 学习顺序 | 并行 | 串行 |
8.2 四大算法横向对比
| 维度 | 随机森林 | AdaBoost | GBDT | XGBoost |
|---|---|---|---|---|
| 范式 | Bagging | Boosting | Boosting | Boosting |
| 训练方式 | 完全并行 | 串行 | 串行 | 特征级并行 |
| 主要解决 | 方差 | 偏差 | 偏差 | 偏差 + 工程优化 |
| 过拟合风险 | 低 | 中 | 高 | 可控(正则化) |
| 训练速度 | 快 | 中 | 慢 | 中(优化后) |
| 调参难度 | 低 | 中 | 高 | 高 |
| 对噪声 | 鲁棒 | 敏感 | 较敏感 | 较鲁棒 |
| 缺失值 | 需处理 | 需处理 | 需处理 | 自动处理 |
8.3 调参最佳实践
8.3.1 随机森林调参
核心参数:
-
n_estimators:树的数量,通常 100-1000 -
max_depth:树深,建议 3-10(太深过拟合) -
min_samples_leaf:叶子最小样本,建议 5-20 -
max_features:特征抽样比例,默认sqrt
调参顺序:
-
先调
n_estimators(越大越好,边际收益递减) -
再调
max_depth和min_samples_leaf(控制过拟合) -
最后调
max_features(控制多样性)
8.3.2 XGBoost 调参
通用参数:
-
booster:gbtree(默认) -
nthread: CPU 核心数
提升参数:
-
learning_rate(eta):0.01-0.3,越小越慢越稳定 -
n_estimators:100-10000,配合学习率
树参数:
-
max_depth: 3-8(XGBoost 不需要太深) -
min_child_weight: 1-10,控制过拟合 -
gamma: 0-5,分裂所需最小增益 -
subsample: 0.6-0.9,行采样 -
colsample_bytree: 0.6-0.9,列采样
正则化参数:
-
reg_alpha: L1 正则,0-100 -
reg_lambda: L2 正则,默认 1
调参策略(贪心搜索):
-
固定较高学习率(0.1),找最优
n_estimators -
调
max_depth和min_child_weight -
调
gamma -
调
subsample和colsample_bytree -
调正则化参数
reg_alpha、reg_lambda -
降低学习率,增加树数量
8.4 算法选择指南
| 场景 | 推荐算法 | 理由 |
|---|---|---|
| 快速基线模型 | 随机森林 | 调参少,鲁棒性强 |
| 表格数据竞赛 | XGBoost/LightGBM | 精度最高,工程优化好 |
| 高维稀疏数据 | 线性模型、GBDT | 树模型在高维稀疏无优势 |
| 解释性要求高 | 单棵决策树 | 完全可解释 |
| 不平衡数据 | XGBoost | 支持样本权重,scale_pos_weight |
| 实时预测 | 随机森林 | 树少,预测快 |
| 小数据集 | GBDT | 拟合能力强 |
| 大数据集 | LightGBM | 直方图算法,速度快 10 倍 + |
九、Python 代码实战
9.1 环境准备
python
# 机器学习库
import inline
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor, plot_tree
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.metrics import accuracy_score, roc_auc_score, mean_squared_error, classification_report
import matplotlib
matplotlib.use('TkAgg')
# XGBoost
import xgboost as xgb
from sympy.plotting.backends.matplotlibbackend import matplotlib9.2 决策树分类示例
python
# 设置风格
plt.style.use('seaborn-v0_8')
sns.set_palette("husl")
# 加载乳腺癌数据集(经典二分类)
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练决策树
dt_clf = DecisionTreeClassifier(
max_depth=4,
min_samples_leaf=5,
random_state=42
)
dt_clf.fit(X_train, y_train)
# 评估
y_pred = dt_clf.predict(X_test)
print(f"决策树测试集准确率: {accuracy_score(y_test, y_pred):.4f}")
print(f"决策树测试集AUC: {roc_auc_score(y_test, dt_clf.predict_proba(X_test)[:,1]):.4f}")
# 可视化决策树
plt.figure(figsize=(20, 10))
plot_tree(dt_clf,
feature_names=data.feature_names,
class_names=data.target_names,
filled=True,
rounded=True,
fontsize=10)
plt.title("Decision Tree Visualization", fontsize=16)
plt.show()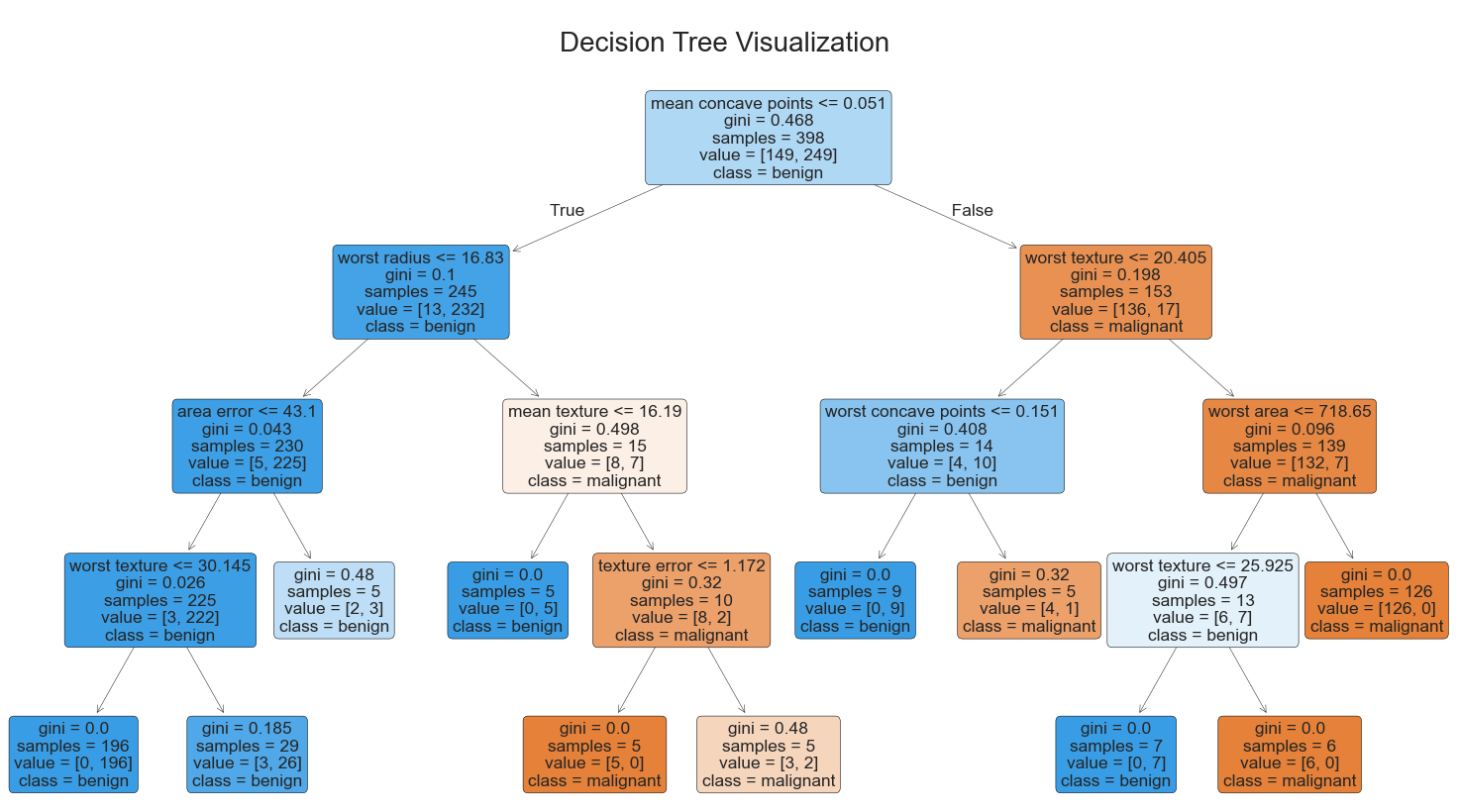
9.3 随机森林与特征重要性
python
# 训练随机森林
rf_clf = RandomForestClassifier(
n_estimators=200,
max_depth=6,
min_samples_leaf=2,
max_features='sqrt',
oob_score=True,
random_state=42,
n_jobs=-1
)
rf_clf.fit(X_train, y_train)
print(f"随机森林OOB得分: {rf_clf.oob_score_:.4f}")
print(f"随机森林测试集准确率: {accuracy_score(y_test, rf_clf.predict(X_test)):.4f}")
# 特征重要性可视化
feature_importance = pd.DataFrame({
'feature': data.feature_names,
'importance': rf_clf.feature_importances_
}).sort_values('importance', ascending=False)
plt.figure(figsize=(12, 8))
sns.barplot(x='importance', y='feature', data=feature_importance.head(15))
plt.title('Top 15 Feature Importance (Random Forest)', fontsize=14)
plt.tight_layout()
plt.show()9.4 XGBoost 实战与调参
python
# XGBoost基础用法
xgb_clf = xgb.XGBClassifier(
max_depth=4,
learning_rate=0.1,
n_estimators=200,
subsample=0.8,
colsample_bytree=0.8,
random_state=42,
use_label_encoder=False,
eval_metric='logloss'
)
# 训练并使用早停
xgb_clf.fit(
X_train, y_train,
eval_set=[(X_test, y_test)],
early_stopping_rounds=20,
verbose=False
)
print(f"XGBoost最佳迭代轮数: {xgb_clf.best_iteration}")
print(f"XGBoost测试集准确率: {accuracy_score(y_test, xgb_clf.predict(X_test)):.4f}")
print(f"XGBoost测试集AUC: {roc_auc_score(y_test, xgb_clf.predict_proba(X_test)[:,1]):.4f}")
# 网格搜索调参示例
param_grid = {
'max_depth': [3, 4, 5],
'learning_rate': [0.01, 0.1],
'n_estimators': [100, 200]
}
grid_search = GridSearchCV(
xgb.XGBClassifier(use_label_encoder=False, eval_metric='logloss'),
param_grid, cv=5, scoring='roc_auc', n_jobs=-1
)
grid_search.fit(X_train, y_train)
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳CV得分: {grid_search.best_score_:.4f}")9.5 多算法对比实验
python
# 定义待比较的算法
models = {
'Decision Tree': DecisionTreeClassifier(max_depth=4, random_state=42),
'Random Forest': RandomForestClassifier(n_estimators=200, max_depth=6, random_state=42, n_jobs=-1),
'AdaBoost': AdaBoostClassifier(n_estimators=200, learning_rate=0.1, random_state=42),
'GBDT': GradientBoostingClassifier(n_estimators=200, max_depth=4, learning_rate=0.1, random_state=42),
'XGBoost': xgb.XGBClassifier(max_depth=4, learning_rate=0.1, n_estimators=200,
use_label_encoder=False, eval_metric='logloss', random_state=42)
}
# 5折交叉验证对比
results = {}
for name, model in models.items():
cv_scores = cross_val_score(model, X, y, cv=5, scoring='roc_auc')
results[name] = {
'mean_auc': cv_scores.mean(),
'std_auc': cv_scores.std()
}
print(f"{name:15s} | AUC: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")
# 可视化对比
results_df = pd.DataFrame(results).T
plt.figure(figsize=(10, 6))
results_df['mean_auc'].plot(kind='bar', yerr=results_df['std_auc'], capsize=5)
plt.title('Model Performance Comparison (5-fold CV AUC)', fontsize=14)
plt.ylabel('AUC Score')
plt.ylim(0.9, 1.0)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()十、工业应用案例
10.1 案例一:客户流失预测
业务背景:电信运营商每年流失率约 15-25%,获取新客户成本是保留老客户的 5 倍。
数据特征:
-
用户基本信息:年龄、性别、套餐类型
-
使用行为:通话时长、流量使用、缴费记录
-
客服交互:投诉次数、问题解决时长
建模方案:
-
特征工程:构建近 3 个月行为趋势特征
-
模型选择:XGBoost(处理不平衡 + 特征重要性)
-
阈值优化:根据业务成本调整分类阈值
-
模型解释:SHAP 值分析流失关键因素
业务价值:
-
AUC 达到 0.85,精准识别高风险流失用户
-
针对 Top 20% 高风险用户开展挽留活动
-
流失率降低 3-5%,年增收数千万元
10.2 案例二:信用评分卡
业务背景:银行消费贷款风控,预测借款人违约概率。
数据特征:
-
申请人基本信息:年龄、收入、职业
-
征信数据:历史逾期、负债比率、查询次数
-
行为数据:消费习惯、还款行为
建模方案:
-
WOE 编码 + IV 筛选:传统评分卡标准流程
-
模型融合:LR(可解释)+ XGBoost(高精度)
-
拒绝推断:处理样本选择偏差
-
校准:概率校准确保分数可解释
监管要求:
-
模型必须可解释(拒绝原因可追溯)
-
特征不能有歧视性(性别、种族等)
-
分数需单调(分数越高,违约率越低)
10.3 案例三:医疗诊断辅助
业务背景:辅助医生进行疾病早期筛查。
数据特征:
-
检验指标:血常规、生化、免疫指标
-
影像特征:CT/MRI 量化特征
-
病史信息:既往病史、家族史
建模方案:
-
多模态融合:结构化数据 + 影像特征
-
模型选择:随机森林(鲁棒性 + 置信度)
-
不确定性估计:给出预测置信区间
-
人机协作:模型输出作为医生参考
关键考量:
-
假阴性代价远高于假阳性
-
必须提供预测依据(哪些特征支持诊断)
-
持续学习:新病例不断更新模型
(十一)总结与展望
11.1 核心要点回顾
-
决策树:
-
三大分裂准则:信息增益(ID3)、信息增益比(C4.5)、基尼系数(CART)
-
剪枝是防止过拟合的关键:预剪枝简单高效,后剪枝精度更高
-
-
集成学习:
-
Bagging:并行集成,降低方差(代表:随机森林)
-
Boosting:串行集成,降低偏差(代表:GBDT、XGBoost)
-
Stacking:多层堆叠,元学习融合
-
-
四大经典算法:
-
随机森林:鲁棒性强,调参简单,首选基线
-
XGBoost:精度最高,工程优化完善,竞赛首选
-
没有免费午餐:根据数据规模、解释性要求、实时性选择
-
11.2 树模型的发展趋势
-
直方图算法:LightGBM、CatBoost 采用直方图替代预排序,速度提升 10 倍 +
-
类别特征支持:CatBoost 原生支持类别特征,无需人工编码
-
分布式训练:支持 GPU、多机分布式,处理 TB 级数据
-
可解释 AI:SHAP、LIME 等方法提升树模型的可解释性
-
与深度学习融合:Deep Forest、TabNet 等探索树模型与神经网络的结合
11.3 给从业者的建议
-
从简单开始:先用随机森林建立基线,再尝试复杂模型
-
重视特征工程:树模型的上限由特征质量决定
-
理解调参本质:不是盲目网格搜索,而是理解每个参数的作用
-
关注业务解释:模型最终要服务业务,可解释性往往比 0.1% 的精度提升更重要
-
持续学习:树模型仍在快速发展,关注 LightGBM、CatBoost 等新进展
12. 参考文献
1 Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32.
2 Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. KDD 2016.
3 Friedman, J. H. (2001). Greedy Function Approximation: A Gradient Boosting Machine. Annals of Statistics.
4 Freund, Y., & Schapire, R. E. (1997). A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. Journal of Computer and System Sciences.
5 Breiman, L. (1996). Bagging Predictors. Machine Learning, 24(2), 123-140.
6 Quinlan, J. R. (1986). Induction of Decision Trees. Machine Learning, 1(1), 81-106.
7 Quinlan, J. R. (1993). C4.5: Programs for Machine Learning. Morgan Kaufmann.
8 Mienye, I. D., & Jere, N. (2024). A Survey of Decision Trees: Concepts, Algorithms, and Applications. IEEE Access.
9 Opitz, D., & Maclin, R. (1999). Popular Ensemble Methods: An Empirical Study. Journal of Artificial Intelligence Research.
10 Ke, G., et al. (2017). LightGBM: A Highly Efficient Gradient Boosting Decision Tree. NIPS 2017.