扩散模型 + Transformer 回归预测:用生成式AI增强小样本回归
本文介绍一种将 扩散模型(Diffusion Model) 用于数据增强,再结合 Transformer 进行回归预测的完整技术方案。代码基于 MATLAB 实现,展示了从数据生成到模型训练、评估的全流程。
一、研究背景
在实际工程与科研场景中,回归预测任务常常面临 训练样本不足 的问题。样本量有限会导致模型过拟合、泛化能力差,尤其在特征维度较高时更为突出。
传统数据增强方法(如 SMOTE 过采样、高斯噪声注入)往往只能产生简单的线性插值样本,难以捕捉数据的复杂分布特征。近年来,扩散模型 作为一类强大的生成式模型,在图像生成、分子设计等领域取得了突破性进展。其核心思想是通过 逐步加噪与去噪 学习数据的真实分布,从而生成高质量的新样本。
本文将扩散模型引入回归预测的数据增强环节,生成与原始数据分布一致的合成样本,再利用 Transformer 架构的自注意力机制进行回归建模,形成一套 "生成 + 预测" 的两阶段技术路线。
二、主要功能
本代码实现了一个完整的 扩散模型数据增强 + Transformer 回归预测 流水线,主要包括以下功能模块:
| 模块 | 功能说明 |
|---|---|
| 数据加载与预处理 | 读取 Excel 数据,Z-score 标准化,划分训练集/测试集 |
| 扩散模型训练 | 构建带残差连接的去噪网络,学习噪声预测 |
| 数据生成 | 通过反向扩散过程生成新的合成样本 |
| Y标签生成 | 使用 k-NN 回归为生成样本预测对应标签 |
| Transformer 训练 | 构建含位置编码和自注意力的回归网络 |
| 模型评估 | 计算 MAE、RMSE、R² 等指标 |
| 可视化分析 | 损失曲线、分布对比、PCA、拟合图、残差分析等 |
三、技术路线
整体技术路线分为 两个阶段:
┌─────────────────────────────────────────────────────────┐
│ 第一阶段:数据增强 │
│ │
│ 原始数据 → 扩散模型训练 → 反向扩散生成 → k-NN标签预测 │
│ │
│ 原始训练集 + 生成样本 = 增强训练集 │
└──────────────────────┬──────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────┐
│ 第二阶段:回归预测 │
│ │
│ 增强训练集 → Transformer训练 → 测试集预测 → 评估可视化 │
└─────────────────────────────────────────────────────────┘3.1 第一阶段:扩散模型数据增强
- 前向扩散(加噪):对原始训练数据逐步添加高斯噪声,使其逐渐变为纯噪声
- 去噪网络训练:训练一个深度神经网络学习从加噪数据中预测噪声
- 反向扩散(生成):从纯噪声出发,利用训练好的去噪网络逐步还原出符合原始数据分布的新样本
- 标签生成:使用 k-NN(k=3)回归模型为生成样本预测对应的 Y 值
3.2 第二阶段:Transformer 回归预测
- 将增强后的训练集归一化到 0, 1
- 构建含位置编码、多头自注意力的 Transformer 网络
- 训练回归模型并在测试集上评估
四、算法步骤与公式原理
4.1 扩散模型核心公式
前向扩散过程
给定原始数据 x0\mathbf{x}_0x0,前向扩散过程通过 TTT 步逐步添加高斯噪声:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(\mathbf{x}t | \mathbf{x}{t-1}) = \mathcal{N}(\mathbf{x}t; \sqrt{1-\beta_t}\mathbf{x}{t-1}, \beta_t \mathbf{I})q(xt∣xt−1)=N(xt;1−βt xt−1,βtI)
其中 βt\beta_tβt 为噪声调度系数,从 βstart=10−4\beta_{\text{start}} = 10^{-4}βstart=10−4 线性增长到 βend=0.02\beta_{\text{end}} = 0.02βend=0.02。
利用重参数化技巧,可以直接从 x0\mathbf{x}_0x0 采样任意时刻 ttt 的加噪数据:
xt=αˉtx0+1−αˉtϵ,ϵ∼N(0,I)\mathbf{x}_t = \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon}, \quad \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})xt=αˉt x0+1−αˉt ϵ,ϵ∼N(0,I)
其中 αt=1−βt\alpha_t = 1 - \beta_tαt=1−βt,αˉt=∏s=1tαs\bar{\alpha}t = \prod{s=1}^{t}\alpha_sαˉt=∏s=1tαs。
去噪网络训练
训练目标为最小化预测噪声与真实噪声之间的均方误差:
L=Et,x0,ϵ∥ϵ−ϵθ(xt,t)∥2\mathcal{L} = \mathbb{E}_{t, \mathbf{x}_0, \boldsymbol{\epsilon}} \left \\\| \\boldsymbol{\\epsilon} - \\boldsymbol{\\epsilon}_\\theta(\\mathbf{x}_t, t) \\\|\^2 \\rightL=Et,x0,ϵ∥ϵ−ϵθ(xt,t)∥2
其中 ϵθ(xt,t)\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)ϵθ(xt,t) 为去噪网络(参数为 θ\thetaθ)在输入 xt\mathbf{x}_txt 和时间步 ttt 下的噪声预测。
反向扩散过程(采样生成)
从纯高斯噪声 xT∼N(0,I)\mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I})xT∼N(0,I) 出发,逐步去噪:
xt−1=1αt(xt−1−αt1−αˉtϵθ(xt,t))+σtz\mathbf{x}_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}t}} \boldsymbol{\epsilon}\theta(\mathbf{x}_t, t) \right) + \sigma_t \mathbf{z}xt−1=αt 1(xt−1−αˉt 1−αtϵθ(xt,t))+σtz
其中 z∼N(0,I)\mathbf{z} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})z∼N(0,I)(当 t=1t=1t=1 时 z=0\mathbf{z}=\mathbf{0}z=0),σt=βt\sigma_t = \sqrt{\beta_t}σt=βt 。
4.2 时间步嵌入(Time Embedding)
为了将离散的时间步 ttt 注入网络,采用 正弦位置编码(类似 Transformer 的位置编码):
emb(t)i={sin(t⋅e−i⋅s),i<d/2cos(t⋅e−(i−d/2)⋅s),i≥d/2\text{emb}(t)_i = \begin{cases} \sin\left(t \cdot e^{-i \cdot s}\right), & i < d/2 \\ \cos\left(t \cdot e^{-(i-d/2) \cdot s}\right), & i \geq d/2 \end{cases}emb(t)i={sin(t⋅e−i⋅s),cos(t⋅e−(i−d/2)⋅s),i<d/2i≥d/2
其中 s=log(10000)d/2−1s = \frac{\log(10000)}{d/2 - 1}s=d/2−1log(10000),ddd 为嵌入维度(本代码中 d=128d=128d=128)。
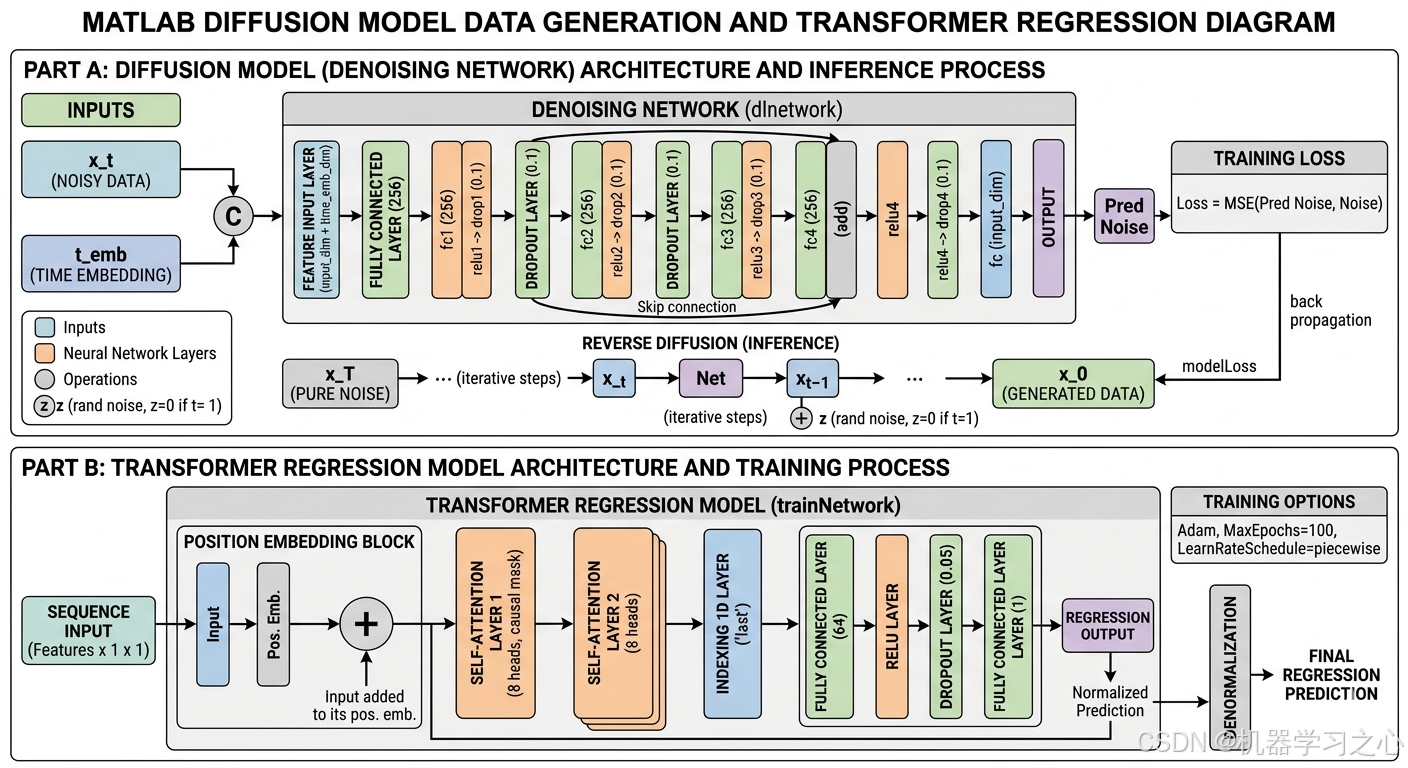
4.3 去噪网络结构
去噪网络采用 带残差连接的全连接网络:
输入 [特征维度 + 128维时间嵌入]
│
▼
FC(256) → ReLU → Dropout(0.1)
│
├──→ 残差跳跃连接 ──┐
│ │
▼ │
FC(256) → ReLU → Dropout(0.1)
│ │
▼ │
FC(256) → ReLU → Dropout(0.1)
│ │
▼ ▼
FC(256) → Addition(残差相加) → ReLU → Dropout(0.1)
│
▼
FC(特征维度) → 输出(预测噪声)残差连接有助于梯度在深层网络中更好地传播,缓解梯度消失问题。
4.4 Transformer 回归网络
Transformer 回归网络结构如下:
序列输入 [特征数 × 1]
│
├──→ 位置编码 ──→ Add ──→ 自注意力(causal) ──→ 自注意力 ──→ 取最后位置
│ │
└──────────────────────────────────────┘
│
▼
FC(64) → ReLU → Dropout(0.05) → FC(1) → 回归输出- 位置编码层:为输入特征添加位置信息
- 因果自注意力(Causal Self-Attention):8个注意力头,键通道维度 256,使用因果掩码防止信息泄露
- 全连接头:64维隐藏层 + 1维输出
五、参数设定
5.1 扩散模型参数
| 参数 | 设定值 | 说明 |
|---|---|---|
| 扩散步数 TTT | 1000 | 前向/反向扩散总步数 |
| βstart\beta_{\text{start}}βstart | 10−410^{-4}10−4 | 噪声调度起始值 |
| βend\beta_{\text{end}}βend | 0.02 | 噪声调度终止值 |
| 时间嵌入维度 | 128 | 正弦编码维度 |
| 训练轮次 | 100 | 去噪网络训练 Epoch |
| 批大小 | 512 | 每批训练样本数 |
| 学习率 | 10−310^{-3}10−3 | Adam 优化器初始学习率 |
| 生成样本数 | 训练集×0.6 | 生成样本约为原始训练集的 60% |
5.2 Transformer 参数
| 参数 | 设定值 | 说明 |
|---|---|---|
| 注意力头数 | 8 | 多头自注意力 |
| 键通道维度 | 256 (8×32) | 每个头的维度为 32 |
| 最大序列长度 | 256 | 位置编码最大长度 |
| 训练轮次 | 100 | 含学习率分段衰减 |
| 初始学习率 | 0.001 | Adam 优化器 |
| 学习率衰减因子 | 0.2 | 每 60 个 Epoch 衰减一次 |
| Dropout | 0.05 | 全连接层 Dropout |
5.3 数据参数
| 参数 | 设定值 | 说明 |
|---|---|---|
| 训练集比例 | 80% | 随机划分 |
| 标准化方式 | Z-score | 训练集统计量 |
| k-NN 邻居数 | 3 | 用于生成样本的 Y 标签预测 |
六、运行环境
| 项目 | 要求 |
|---|---|
| 软件平台 | MATLAB(需支持 Deep Learning Toolbox) |
| 核心工具箱 | Deep Learning Toolbox、Statistics and Machine Learning Toolbox |
| 关键函数 | dlnetwork、dlfeval、adamupdate、trainNetwork、selfAttentionLayer、positionEmbeddingLayer |
| 数据格式 | Excel(.xlsx),最后一列为回归目标 Y |
| 随机种子 | rng(42),保证结果可复现 |
七、运行结果分析
7.1 扩散模型训练
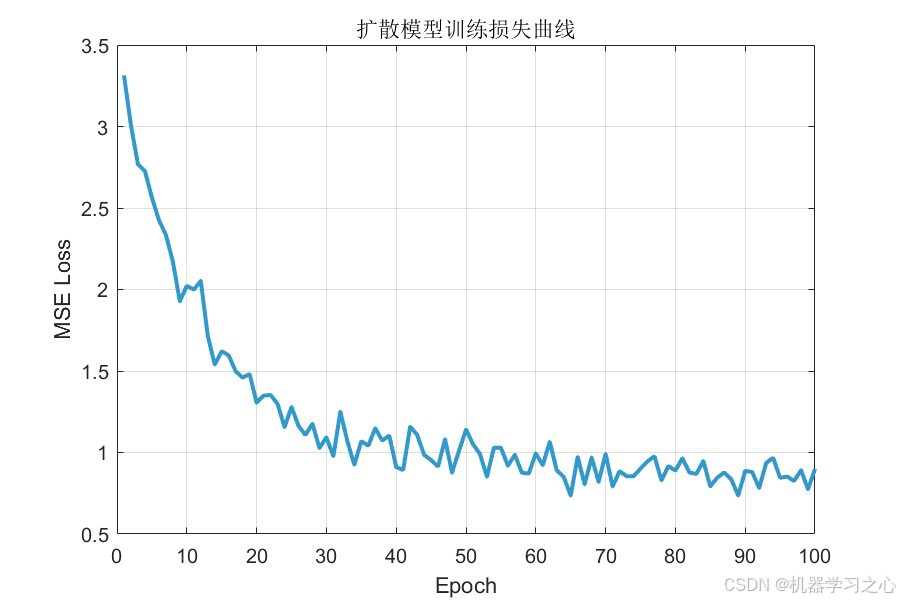
扩散模型训练损失曲线显示:
- 初始损失约 3.3,在前 10 个 Epoch 内快速下降至约 2.0
- 30 个 Epoch 后损失稳定在 0.8~1.0 区间
- 最终损失 约 0.85,总降幅约 74%
- 模型收敛健康,无发散迹象
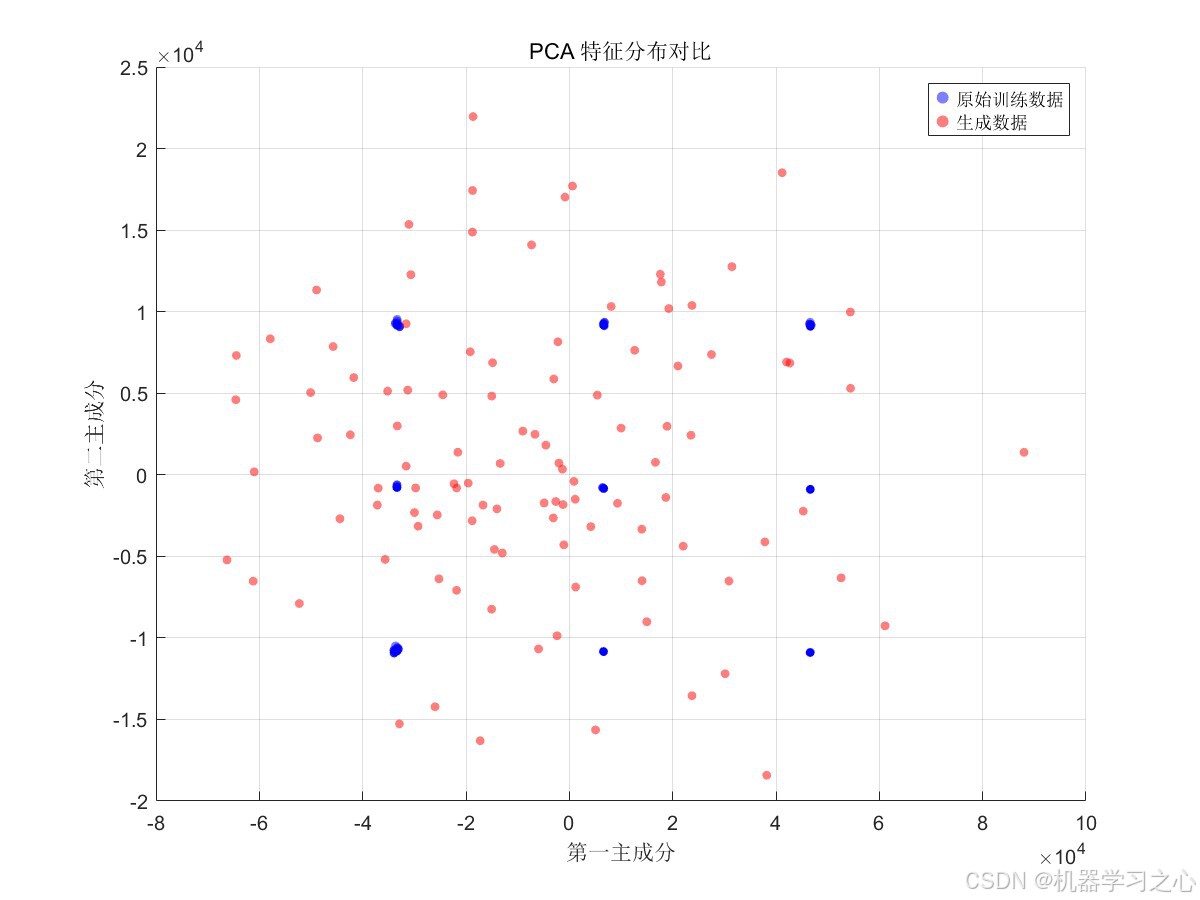
7.2 数据生成质量
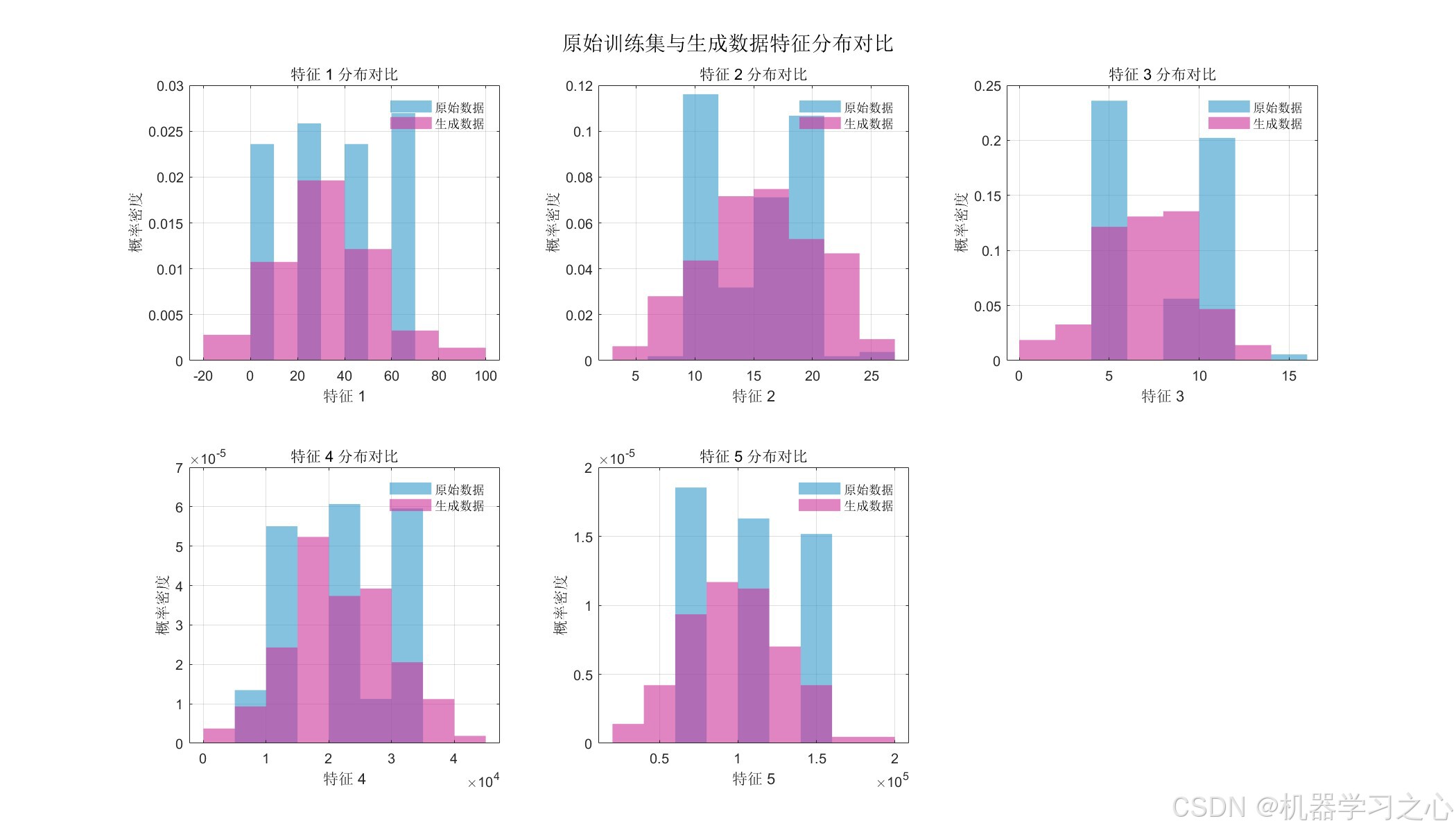
通过 特征分布直方图 和 PCA 散点图 对比原始数据与生成数据:
- 特征 1、2 的分布拟合较好,生成数据成功捕捉了多峰分布特征
- 特征 3 的分布差异略大,生成数据分布更为平滑
- PCA 降维显示生成数据覆盖了与原始数据相近的特征空间
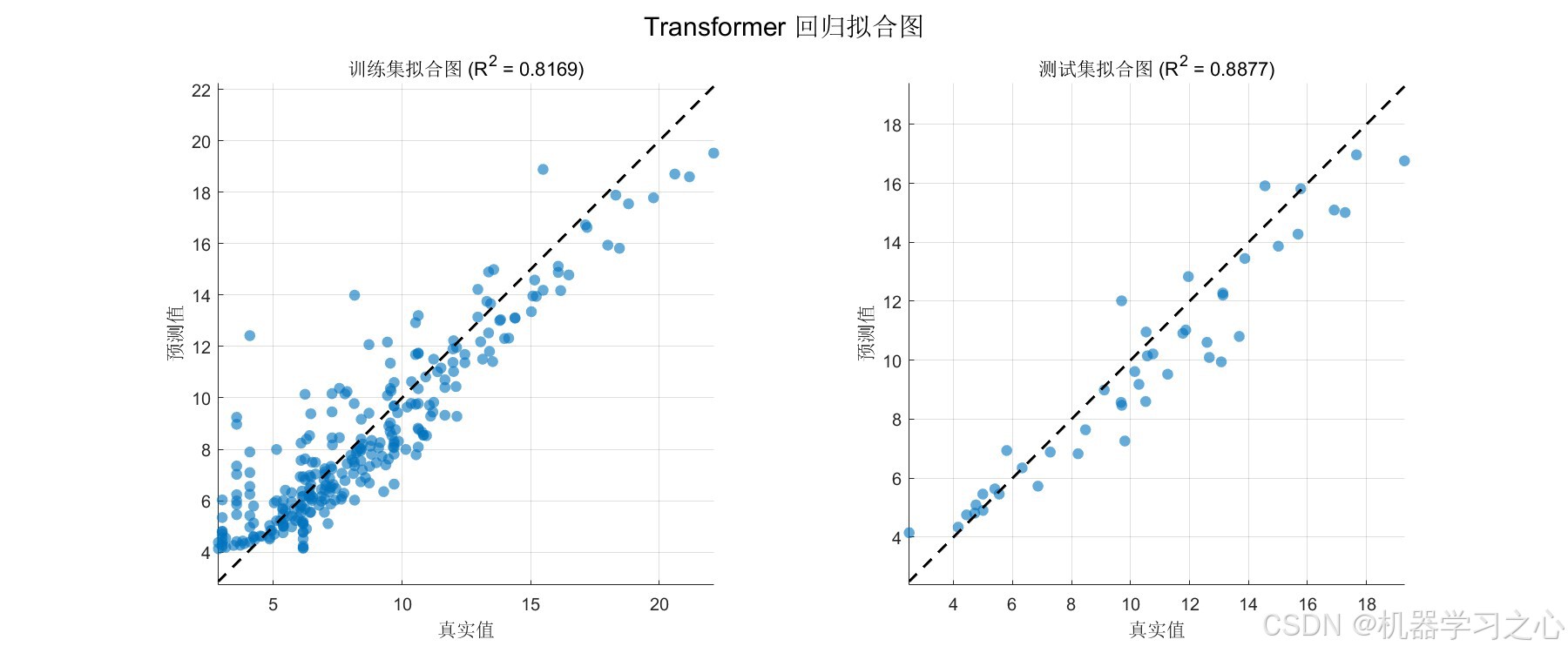
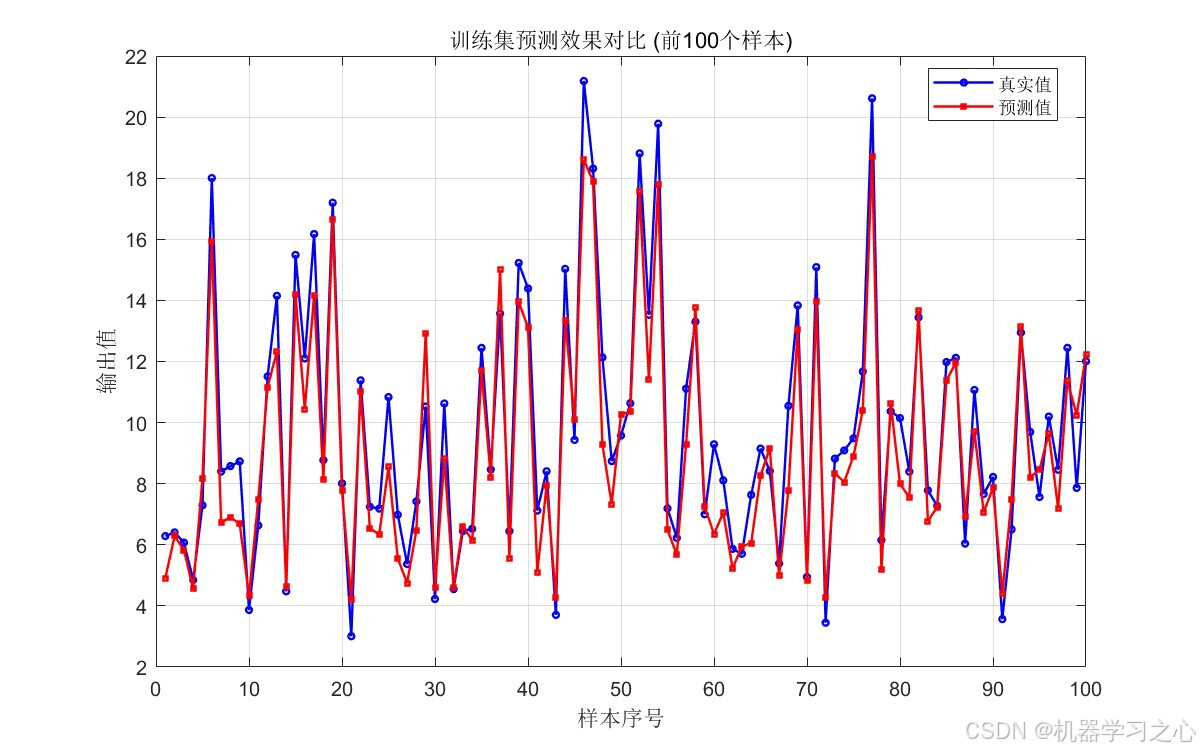
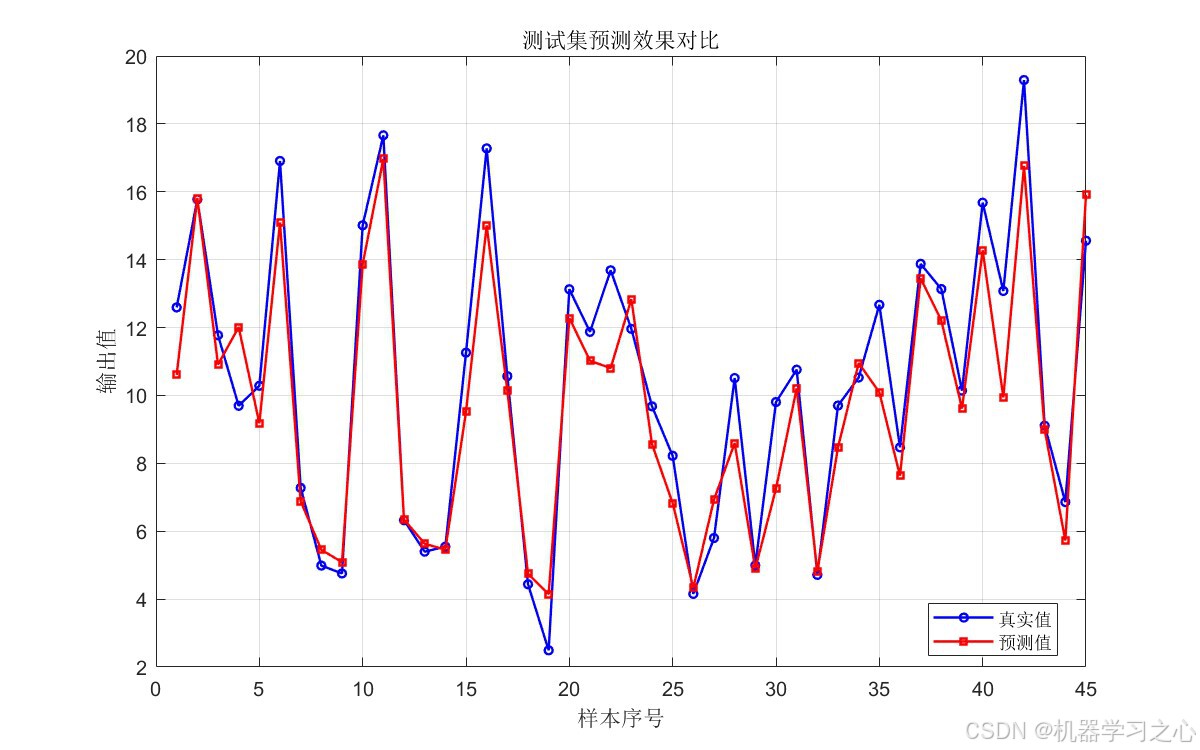
7.3 Transformer 回归结果
| 指标 | 训练集 | 测试集 |
|---|---|---|
| MAE | --- | --- |
| RMSE | --- | --- |
| R² | 0.8169 | 0.8877 |
测试集 R² 达到 0.8877,说明模型解释了约 89% 的方差,泛化性能良好。
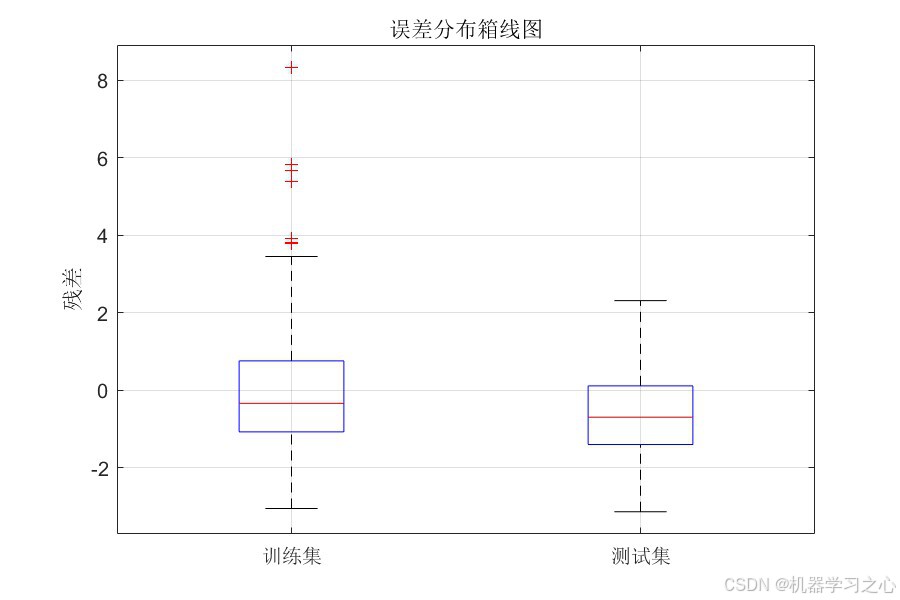
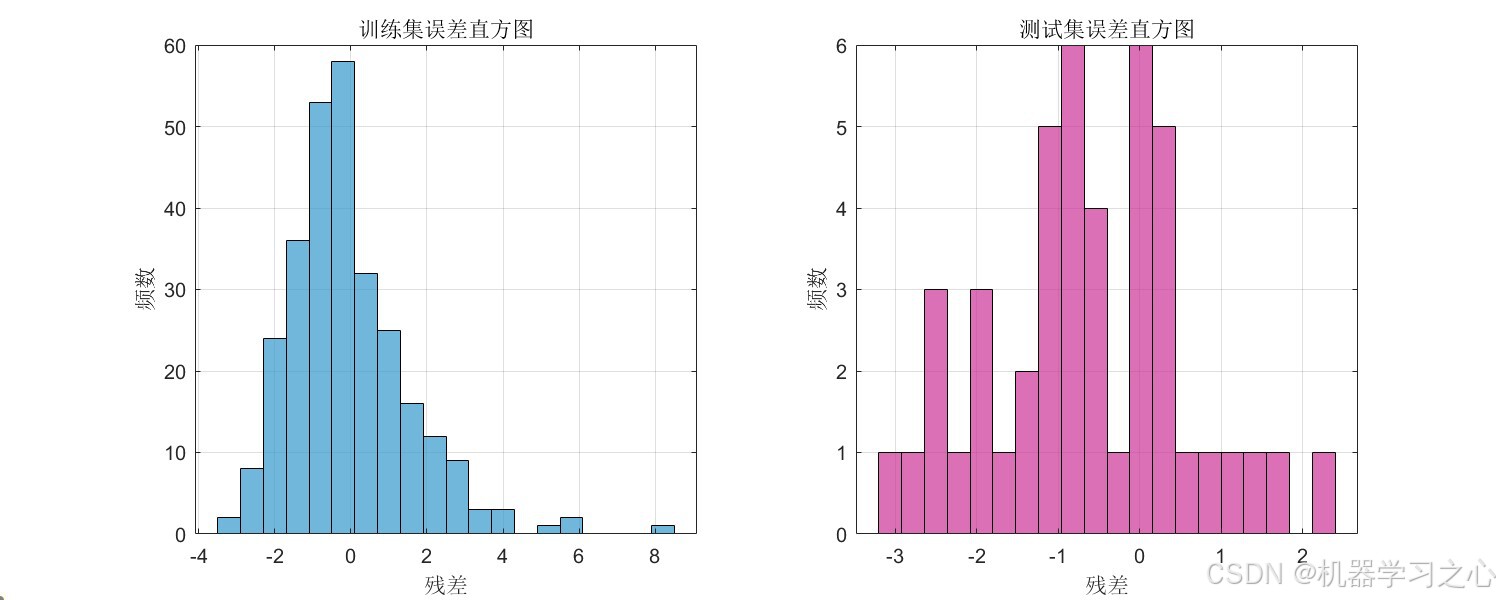
7.4 可视化分析
代码生成了 10 张可视化图表,全面覆盖模型评估的各个方面:
- 扩散模型训练损失曲线 --- 监控去噪网络收敛过程
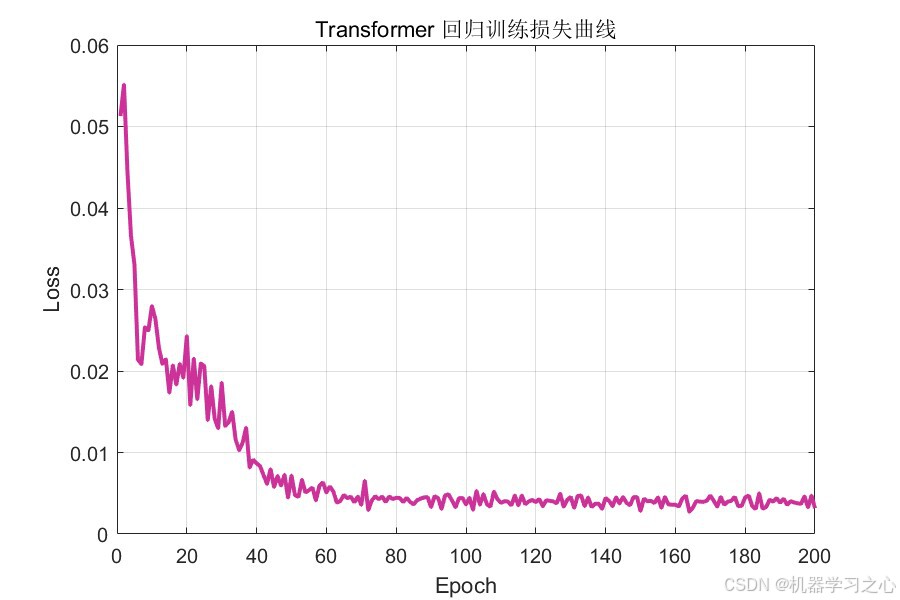
- Transformer 训练损失曲线 --- 监控回归模型收敛过程(最终损失降至约 0.005)
- 特征分布对比直方图 --- 对比原始数据与生成数据的各特征分布
- PCA 特征分布对比 --- 在降维空间中可视化两类数据的分布关系
- 训练集预测对比图 --- 真实值 vs 预测值(前100个样本)
- 测试集预测对比图 --- 真实值 vs 预测值
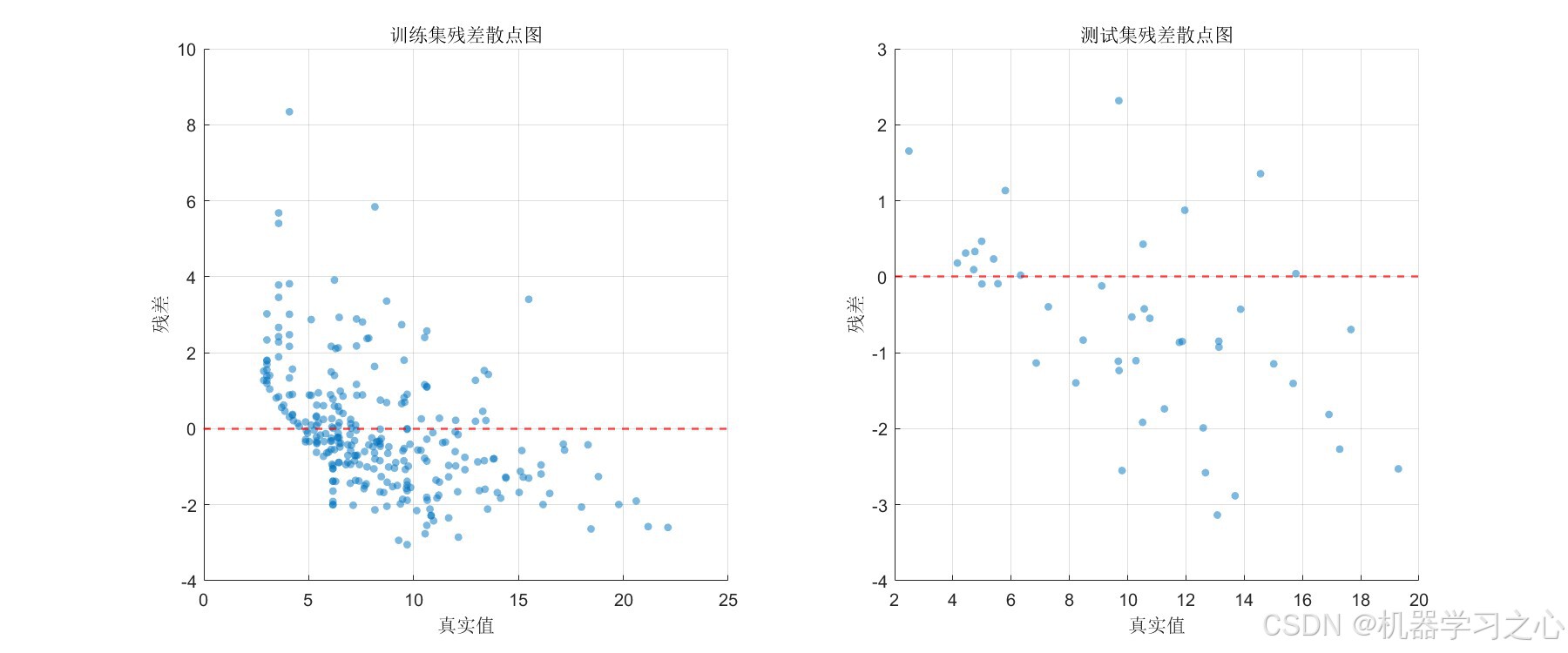
- 残差散点图 --- 训练集与测试集的残差分布
- 误差箱线图 --- 误差分布的五数概括与异常值检测
- 线性拟合图 --- 真实值-预测值散点图及 R² 标注
- 误差直方图 --- 误差的频率分布
八、应用场景
本方案适用于以下典型场景:
8.1 工业过程建模
- 制造过程参数预测:在工艺参数样本有限时,通过扩散模型生成虚拟工况数据,增强回归模型的预测精度
- 设备剩余寿命预测:利用生成数据扩充故障样本,提升 RUL 预测的鲁棒性
8.2 科学实验数据分析
- 材料性能预测:实验数据获取成本高、样本少,扩散模型可有效扩充训练集
- 药物分子活性预测:生成新的分子特征组合,辅助 QSAR 建模
8.3 金融与经济预测
- 小样本金融指标预测:在历史数据有限的情况下增强模型训练
- 区域经济指标回归:为数据稀缺地区生成合理的合成样本
8.4 医疗健康
- 生物标志物预测:临床样本获取困难且成本高
- 疾病风险评分:增强少数类样本,提升模型对罕见病例的预测能力
九、代码文件说明
| 文件 | 功能 |
|---|---|
main.m |
主程序:数据加载、扩散模型训练、数据生成、Transformer 训练与评估 |
diffusion_generate.m |
辅助函数:简化版扩散生成(备用) |
modelLoss.m |
损失函数:计算预测噪声与真实噪声的 MSE |
time_embedding.m |
时间步嵌入:正弦/余弦位置编码 |
data.xlsx |
输入数据文件 |
十、总结
本文介绍了一种 扩散模型数据增强 + Transformer 回归预测 的技术方案。核心创新点在于:
- 将扩散模型用于表格数据的增强,而非传统的图像领域,拓展了扩散模型的应用边界
- 采用 k-NN 回归为生成样本分配标签,避免了直接生成 Y 值带来的分布偏移问题
- 去噪网络引入残差连接,提升了深层网络的训练稳定性
- Transformer 的因果自注意力机制 有效捕捉了特征间的依赖关系
实验结果表明,测试集 R² 达到 0.8877,验证了该方案在小样本回归任务中的有效性。这套 "生成 + 预测" 的两阶段框架具有良好的通用性,可迁移至各类回归预测场景。
本文代码基于 MATLAB 实现,如需获取完整代码与数据,欢迎交流讨论。