PyTorch 的 torch 模块,是整个 PyTorch 框架中最基础、最核心的模块。它提供了张量创建、张量运算、形状变换、索引切片、数据类型转换、设备迁移、随机数生成、保存与加载等基础能力。
简单地说,torch 模块回答的是:数据在 PyTorch 中如何表示、如何计算、如何移动到 GPU 上,以及如何作为模型的输入、输出和参数参与训练。
在 PyTorch 中,最重要的数据结构是张量(Tensor)。输入数据、模型参数、中间激活值、损失值和梯度,通常都以张量形式存在。因此,学习 PyTorch 的第一步,不是直接编写复杂神经网络,而是理解张量与基础计算。
一、认识 torch 模块
torch 是 PyTorch 中最常用的基础模块。它既可以创建张量,也可以对张量进行数学运算、形状调整、数据类型转换和设备管理。
一个最基本的使用方式如下:
apache
import torch
# 创建一个一维浮点张量x = torch.tensor([1.0, 2.0, 3.0])
print(x)print(type(x))输出结果类似:
apache
tensor([1., 2., 3.])<class 'torch.Tensor'>可以简单理解为:torch 模块不是专门用来定义神经网络的模块,而是 PyTorch 的基础计算层。
后面学习的许多内容,都会建立在 torch 模块之上:
• 神经网络层会用张量表示模型参数和中间计算结果
• 自动求导机制会根据张量运算过程计算梯度
• 优化器会根据张量梯度更新模型参数
• 数据加载器读取出来的数据通常也会被组织为张量
因此,torch 模块是理解 PyTorch 的入口。
二、什么是张量
张量(Tensor)可以看作是多维数组。根据维度不同,张量可以表示标量、向量、矩阵和更高维的数据。
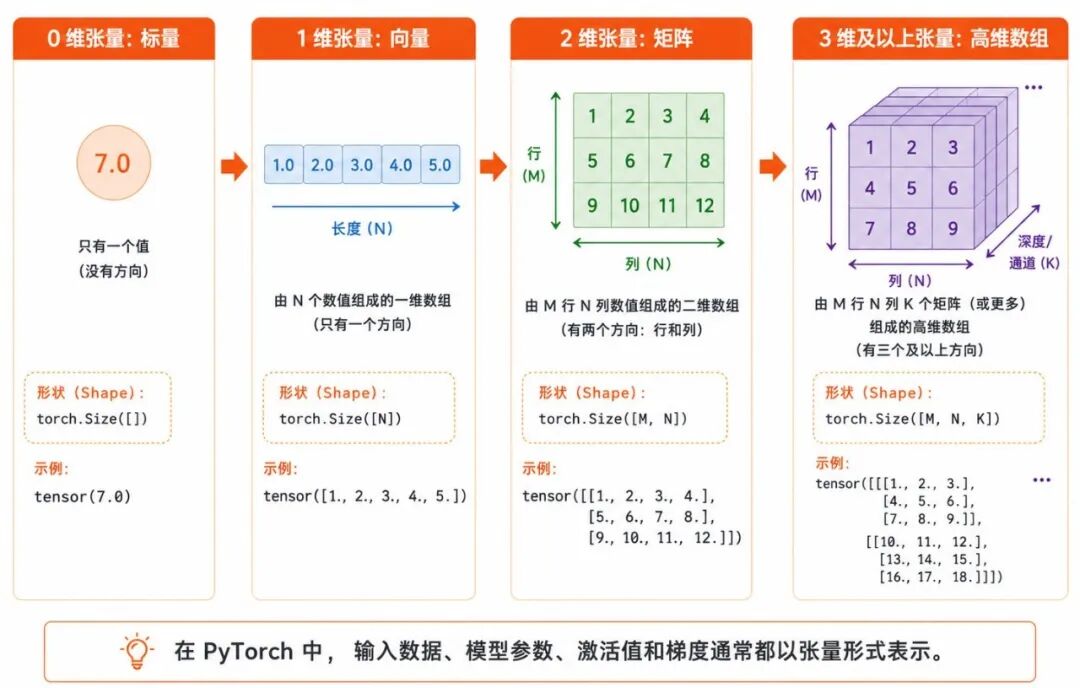
图 1:PyTorch 张量的维度
例如:
apache
import torch
# 0 维张量:一个数,也叫标量a = torch.tensor(3.14)
# 1 维张量:一组数,也叫向量b = torch.tensor([1, 2, 3])
# 2 维张量:二维表格,也叫矩阵c = torch.tensor([[1, 2], [3, 4]])
# 3 维张量:可以理解为多个矩阵堆叠在一起d = torch.randn(2, 3, 4)
print(a.shape)print(b.shape)print(c.shape)print(d.shape)输出结果类似:
apache
torch.Size([])torch.Size([3])torch.Size([2, 2])torch.Size([2, 3, 4])在深度学习中,张量不只是"数学对象",也是数据在程序中的主要表示方式。
例如,在图像任务中,一个常见输入张量形状是:
css
(batch_size, channels, height, width)对应代码可以写成:
apache
import torch
# 32 张图像,每张图像有 3 个颜色通道,高和宽都是 224x = torch.randn(32, 3, 224, 224)
print(x.shape)# torch.Size([32, 3, 224, 224])这里:
• 32 表示一批中有 32 张图像
• 3 表示 RGB 三个颜色通道
• 224 表示图像高度
• 224 表示图像宽度
理解张量形状,是学习卷积神经网络、图像分类、目标检测和视觉模型的基础。
三、创建张量的常用方式
PyTorch 提供了多种创建张量的方法。
1、使用 torch.tensor() 创建张量
最直接的方式是使用 torch.tensor():
apache
import torch
# 从一维列表创建整数张量x = torch.tensor([1, 2, 3])
# 从二维列表创建浮点张量y = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
print(x)print(y)输出结果类似:
css
tensor([1, 2, 3])
tensor([[1., 2.], [3., 4.]])torch.tensor() 会根据输入数据自动推断数据类型。例如,输入整数时通常得到整数张量,输入浮点数时通常得到浮点张量。
如果希望明确控制数据类型,可以直接指定 dtype:
apache
import torch
# 显式创建 32 位浮点张量x = torch.tensor([1, 2, 3], dtype=torch.float32)
print(x)print(x.dtype)输出结果类似:
apache
tensor([1., 2., 3.])torch.float32在深度学习中,输入特征通常使用浮点张量;分类标签通常使用整数张量。数据类型如果不符合函数要求,程序可能会报错,或者得到不符合预期的结果。
2、创建全 0、全 1 和未初始化张量
apache
import torch
# 创建 2 行 3 列的全 0 张量a = torch.zeros(2, 3)
# 创建 2 行 3 列的全 1 张量b = torch.ones(2, 3)
# 创建 2 行 3 列的未初始化张量,数值内容不确定c = torch.empty(2, 3)
print(a)print(b)print(c)需要注意的是,torch.empty() 只是分配内存,并不会把里面的数值初始化为 0。因此,它输出的内容可能看起来像随机值,但这些值只是内存中原有的数据。
在初学阶段,如果没有特殊需求,通常更建议使用 zeros()、ones() 或随机初始化函数,而不是直接使用 empty()。
3、创建随机张量
apache
import torch
# 生成 0 到 1 之间均匀分布的随机数a = torch.rand(2, 3)
# 生成标准正态分布随机数b = torch.randn(2, 3)
# 生成 0 到 9 之间的随机整数c = torch.randint(0, 10, (2, 3))
print(a)print(b)print(c)随机张量常用于参数初始化、模拟输入数据、构造测试样本和调试模型流程。
例如,构造一批模拟输入数据和类别标签:
apache
import torch
# 100 个样本,每个样本有 4 个特征X = torch.randn(100, 4)
# 100 个类别标签,类别编号为 0、1、2y = torch.randint(0, 3, (100,))
print(X.shape)print(y.shape)这类写法常用于教学示例和模型调试。它可以在没有真实数据的情况下,先检查模型结构、输入输出形状和训练流程是否能够正常运行。
4、创建数值序列张量
apache
import torch
# 从 0 到 10,步长为 2,不包含 10a = torch.arange(0, 10, 2)
# 从 0 到 1 均匀生成 5 个数b = torch.linspace(0, 1, 5)
print(a) # tensor([0, 2, 4, 6, 8])print(b) # tensor([0.0000, 0.2500, 0.5000, 0.7500, 1.0000])这类函数常用于构造坐标、时间步、测试数据或绘图数据。
5、根据已有张量创建新张量
makefile
import torch
x = torch.randn(2, 3)
# 创建与 x 形状相同的全 0 张量a = torch.zeros_like(x)
# 创建与 x 形状相同的全 1 张量b = torch.ones_like(x)
# 创建与 x 形状相同的标准正态随机张量c = torch.randn_like(x)
print(a)print(b)print(c)这类函数的好处是不用手动写形状,能减少形状不一致带来的错误。尤其是在模型内部创建与输入同形状的掩码、噪声或中间变量时,非常方便。
四、查看张量的基本属性
创建张量之后,通常需要查看它的形状、维度、元素数量、数据类型和所在设备。
python
import torch
x = torch.randn(2, 3, 4)
# 查看张量形状print("形状:", x.shape)
# 查看张量维度数print("维度数:", x.ndim)
# 查看张量中元素总数print("元素总数:", x.numel())
# 查看张量数据类型print("数据类型:", x.dtype)
# 查看张量所在设备print("所在设备:", x.device)在调试 PyTorch 代码时,shape、dtype 和 device 是最常检查的三个信息。
五、张量的数据类型
张量中的元素必须有明确的数据类型。常见数据类型包括:
• torch.float32:32 位浮点数,深度学习中最常用
• torch.float64:64 位浮点数,精度更高,但计算开销更大
• torch.float16:16 位浮点数,常用于混合精度训练
• torch.bfloat16:常用于深度学习加速的低精度格式
• torch.int64:64 位整数,分类标签中很常见
• torch.int32:32 位整数
• torch.bool:布尔类型
可以在创建张量时指定类型:
apache
import torch
# 输入特征常用浮点张量x = torch.tensor([1, 2, 3], dtype=torch.float32)
# 分类标签常用整数张量,torch.long 等价于 torch.int64y = torch.tensor([0, 1, 2], dtype=torch.long)
print(x.dtype)print(y.dtype)也可以使用 .to() 改变数据类型:
apache
import torch
x = torch.tensor([1, 2, 3])
# 转为 32 位浮点数x_float = x.to(torch.float32)
# 转为 64 位整数x_long = x.to(torch.long)
print(x_float.dtype)print(x_long.dtype)在深度学习任务中,数据类型不仅影响计算效率,也影响函数能否正常运行。
例如,在多分类任务中,模型输出通常是浮点张量,而类别标签通常是整数张量:
apache
import torch
# 8 个样本,每个样本对应 3 个类别的预测分数logits = torch.randn(8, 3)
# 8 个样本的真实类别编号target = torch.randint(0, 3, (8,))
print(logits.dtype)print(target.dtype)如果把标签错误地处理成浮点类型或错误形状,某些损失函数可能无法按预期工作。
六、张量的形状变换
张量形状变换是 PyTorch 中非常常见的操作。模型输入、卷积输出、全连接层输入、序列数据重排,都离不开形状变换。
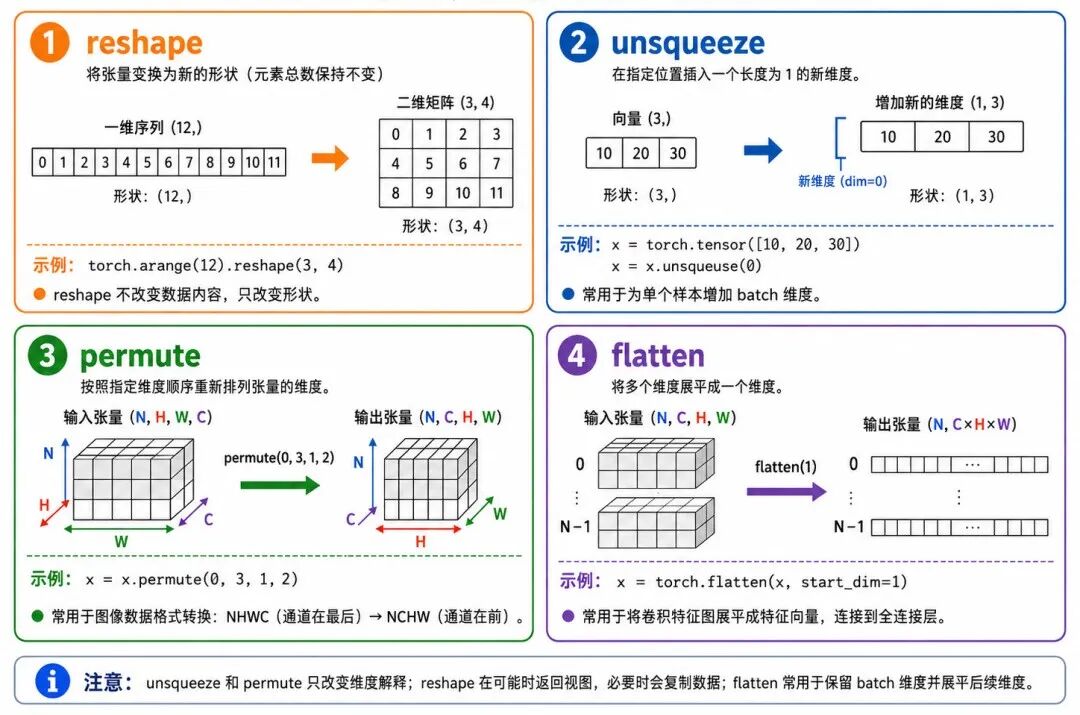
图 2:PyTorch 张量形状变换
1、reshape():改变张量形状
apache
import torch
# 创建包含 12 个元素的一维张量x = torch.arange(12)
# 将一维张量改成 3 行 4 列的二维张量y = x.reshape(3, 4)
print(x)print(y)形状变换有一个基本前提:元素总数不能改变。上面例子中,原张量有 12 个元素,新形状 (3, 4) 也需要 12 个元素。
也可以使用 -1 让 PyTorch 自动推断某一维:
apache
import torch
x = torch.arange(24)
# 第一维指定为 2,第二维自动推断为 12y = x.reshape(2, -1)
print(y.shape) # torch.Size([2, 12])-1 很适合在不想手动计算某一维大小时使用。但一个形状中通常只能有一个 -1,否则无法确定唯一结果。
2、view():以视图方式改变形状
apache
import torch
x = torch.arange(12)
# 将张量视为 3 行 4 列y = x.view(3, 4)
print(y)view() 与 reshape() 很相似,但 view() 对张量在内存中的连续性更敏感。如果张量不是连续存储的,view() 可能会报错。
在初学阶段,可以优先使用 reshape()。等到需要更深入理解内存布局和性能优化时,再仔细区分 view() 与 reshape()。
3、unsqueeze() 与 squeeze():增加或删除长度为 1 的维度
apache
import torch
x = torch.tensor([1, 2, 3])
# 在第 0 维增加一个维度:(3,) -> (1, 3)y = x.unsqueeze(0)
# 在第 1 维增加一个维度:(3,) -> (3, 1)z = x.unsqueeze(1)
print(x.shape) # torch.Size([3])print(y.shape) # torch.Size([1, 3])print(z.shape) # torch.Size([3, 1])squeeze() 用于删除长度为 1 的维度:
apache
import torch
x = torch.randn(1, 3, 1, 4)
# 删除所有长度为 1 的维度y = x.squeeze()
print(x.shape) # torch.Size([1, 3, 1, 4])print(y.shape) # torch.Size([3, 4])这类操作常用于处理批次维度、通道维度和模型输出维度。
例如,一个单独样本的特征向量形状是 (4,),但模型可能希望输入形状是 (1, 4),此时就可以使用:
ini
x = x.unsqueeze(0)这里增加的第 0 维,通常表示"批次维度"。
4、transpose() 与 permute():交换维度
apache
import torch
x = torch.randn(2, 3)
# 交换第 0 维和第 1 维:(2, 3) -> (3, 2)y = x.transpose(0, 1)
print(x.shape) # torch.Size([2, 3])print(y.shape) # torch.Size([3, 2])permute() 可以重新排列多个维度:
apache
import torch
# 假设图像数据形状为 (N, H, W, C)x = torch.randn(32, 224, 224, 3)
# 转换为 PyTorch 卷积层常用格式 (N, C, H, W)y = x.permute(0, 3, 1, 2)
print(y.shape) # torch.Size([32, 3, 224, 224])在图像任务中,维度顺序非常重要。很多图像数据默认是 (N, H, W, C),而 PyTorch 卷积网络通常使用 (N, C, H, W)。这时应使用 permute() 调整维度顺序,而不是使用 reshape() 强行改变形状。
5、flatten():展平张量
apache
import torch
# 32 张图像,每张图像有 3 个通道,尺寸为 28×28x = torch.randn(32, 3, 28, 28)
# 保留第 0 维批次维度,从第 1 维开始展平y = torch.flatten(x, start_dim=1)
print(y.shape) # torch.Size([32, 2352])这里:
• 原始张量表示 32 张图像
• 每张图像形状为 3 × 28 × 28
• 展平后,每个样本变成长度为 2352 的向量
这类操作常用于卷积层之后、全连接层之前。需要注意的是,第 0 维通常是批次维度,不能随意一起展平,否则会把不同样本混在一起。
七、张量的基础数学运算
torch 模块提供了大量数学运算。常见运算包括逐元素运算、数学函数、聚合运算和矩阵乘法。
1、逐元素运算
apache
import torch
a = torch.tensor([1.0, 2.0, 3.0])b = torch.tensor([10.0, 20.0, 30.0])
# 逐元素相加print(a + b) # tensor([11., 22., 33.])
# 逐元素相减print(a - b) # tensor([ -9., -18., -27.])
# 逐元素相乘print(a * b) # tensor([10., 40., 90.])
# 逐元素相除print(a / b) # tensor([0.1000, 0.1000, 0.1000])逐元素运算要求两个张量的形状相同,或者能够通过广播机制对齐。否则,程序会因为形状不匹配而报错。
2、常用数学函数
apache
import torch
x = torch.tensor([1.0, 2.0, 3.0])
# 平方根print(torch.sqrt(x))
# 指数函数print(torch.exp(x))
# 自然对数print(torch.log(x))
# 正弦函数print(torch.sin(x))
# 绝对值print(torch.abs(torch.tensor([-1.0, 2.0, -3.0])))这些函数通常会对张量中的每个元素分别计算。
例如,torch.clamp() 可以把数值限制在指定范围内:
apache
import torch
x = torch.tensor([-2.0, -0.5, 0.5, 2.0])
# 将所有数值限制在 [0, 1] 区间内y = torch.clamp(x, min=0.0, max=1.0)
print(y) # tensor([0.0000, 0.0000, 0.5000, 1.0000])torch.clamp() 常用于限制数值范围,在数值稳定性处理中很常见。
3、聚合运算
python
import torch
x = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
# 所有元素求和print(torch.sum(x))
# 所有元素求平均print(torch.mean(x))
# 所有元素中的最大值print(torch.max(x))
# 所有元素中的最小值print(torch.min(x))也可以沿指定维度聚合:
python
import torch
x = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
# 沿第 0 维聚合,相当于按列求和print(torch.sum(x, dim=0)) # tensor([5., 7., 9.])
# 沿第 1 维聚合,相当于按行求和print(torch.sum(x, dim=1)) # tensor([ 6., 15.])在深度学习中,dim 参数非常重要。例如,对类别维度做归一化、对批次维度求平均、对空间维度做池化,都需要明确指定维度。
如果 dim 写错,代码可能不会报错,但计算含义会完全改变。
4、矩阵乘法
矩阵乘法是神经网络计算的基础。
apache
import torch
A = torch.randn(2, 3)B = torch.randn(3, 4)
# 矩阵乘法:(2, 3) @ (3, 4) -> (2, 4)C = torch.matmul(A, B)
print(C.shape)也可以使用 @ 运算符:
ini
C = A @ B在全连接层中,核心计算可以简单理解为:
Y = X @ W + b
其中:
• X 是输入特征矩阵
• W 是权重矩阵
• b 是偏置
• Y 是输出结果
这也是后续理解 nn.Linear 的基础。
八、广播机制
广播(Broadcasting)允许不同形状的张量在满足规则时进行运算。它可以减少手动复制数据的需求。
例如:
makefile
import torch
x = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
# 形状为 (3,) 的向量会自动扩展到每一行b = torch.tensor([10.0, 20.0, 30.0])
y = x + b
print(y)输出结果类似:
css
tensor([[11., 22., 33.], [14., 25., 36.]])这里:
• x 的形状是 (2, 3)
• b 的形状是 (3,)
• b 会自动扩展到每一行,与 x 相加
广播机制常见于:
• 给每个样本加同一个偏置
• 对每一列做标准化
• 对批量数据应用同一组参数
• 在注意力机制中对齐不同维度
• 在损失计算中自动匹配形状
例如,按列标准化可以写成:
apache
import torch
X = torch.randn(100, 4)
# 每一列的均值,形状为 (4,)mean = X.mean(dim=0)
# 每一列的标准差,形状为 (4,)std = X.std(dim=0)
# mean 和 std 会自动广播到每一行X_scaled = (X - mean) / std
print(X_scaled.shape)广播非常方便,但也容易造成隐蔽错误。尤其当张量形状刚好"可以广播",但并不是你想要的广播方式时,代码可能不会报错,却会得到错误结果。
因此,涉及广播时,要特别关注每个张量的形状。
九、索引与切片
张量支持类似 Python 列表的索引方式。
apache
import torch
x = torch.arange(12).reshape(3, 4)
print(x)
# 取第 0 行print(x[0])
# 取第 0 行第 1 列元素print(x[0, 1])
# 取所有行的第 0 列print(x[:, 0])
# 取第 1 行之后、第 2 列之后的子矩阵print(x[1:, 2:])索引与切片常用于选取样本、选取特征、截取序列和构造子张量。
也可以使用布尔索引:
apache
import torch
x = torch.tensor([1, 5, 2, 8, 3])
# 构造布尔掩码mask = x > 3
# 只取大于 3 的元素selected = x[mask]
print(mask)print(selected)输出结果类似:
python
tensor([False, True, False, True, False])tensor([5, 8])布尔索引常用于筛选满足条件的元素,例如:
• 筛选大于某个阈值的预测结果
• 筛选有效标签
• 筛选非零元素
• 构造掩码张量
例如:
apache
import torch
scores = torch.tensor([0.2, 0.7, 0.9, 0.4])
# 选出分数不低于 0.5 的元素selected = scores[scores >= 0.5]
print(selected)布尔索引写法很直观,但要注意:布尔掩码的形状通常需要与被筛选张量的相关维度匹配。
十、拼接与堆叠
在数据处理和模型计算中,经常需要把多个张量合并起来。最常见的两个函数是 torch.cat() 和 torch.stack()。
1、cat():沿已有维度拼接
apache
import torch
a = torch.randn(2, 3)b = torch.randn(2, 3)
# 沿第 0 维拼接,样本数量增加:(2, 3) + (2, 3) -> (4, 3)c = torch.cat([a, b], dim=0)
# 沿第 1 维拼接,特征数量增加:(2, 3) + (2, 3) -> (2, 6)d = torch.cat([a, b], dim=1)
print(c.shape) # torch.Size([4, 3])print(d.shape) # torch.Size([2, 6])可以简单理解为:
• dim=0 常对应"增加样本数量"
• dim=1 常对应"增加特征数量"
使用 cat() 时,除了拼接的那个维度,其他维度通常必须一致。
2、stack():沿新维度堆叠
apache
import torch
a = torch.tensor([1, 2, 3])b = torch.tensor([4, 5, 6])
# 在第 0 维新建一个维度,把两个向量堆成二维张量c = torch.stack([a, b], dim=0)
# 在第 1 维新建一个维度d = torch.stack([a, b], dim=1)
print(c)print(d)print(c.shape)print(d.shape)输出结果类似:
css
tensor([[1, 2, 3], [4, 5, 6]])
tensor([[1, 4], [2, 5], [3, 6]])
torch.Size([2, 3])torch.Size([3, 2])可以简单理解为:
• cat() 是在已有维度上接起来
• stack() 是先增加一个新维度,再把张量放进去
例如,把多张单独图像合成一个批次时,常常可以使用 stack()。
十一、CPU、GPU 与设备迁移
PyTorch 张量可以运行在 CPU、GPU 或其他计算设备上。默认情况下,张量通常创建在 CPU 上。
可以查看张量所在设备:
apache
import torch
x = torch.randn(2, 3)
# 查看张量当前所在设备print(x.device)输出结果通常是:
go
cpu如果有可用的 GPU,可以写成:
makefile
import torch
# 如果 CUDA 可用,则使用 GPU;否则使用 CPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 把张量移动到指定设备x = torch.randn(2, 3).to(device)
print(x.device)如果使用支持相关加速后端的 Apple 设备,也可以写成:
css
import torch
# 如果 MPS 可用,则使用 mps;否则使用 CPUif torch.backends.mps.is_available(): device = torch.device("mps")else: device = torch.device("cpu")
x = torch.randn(2, 3).to(device)
print(x.device)需要注意的是,参与同一次计算的张量通常必须在同一个设备上。
例如:
apache
import torch
a = torch.randn(2, 3).to("cpu")
if torch.cuda.is_available(): b = torch.randn(2, 3).to("cuda") # c = a + b # 这通常会报错,因为 a 和 b 不在同一设备正确做法是把相关张量移动到同一设备:
makefile
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
a = torch.randn(2, 3).to(device)b = torch.randn(2, 3).to(device)
c = a + b在真实训练中,模型和数据也要放在同一设备上:
ini
# 模型移动到指定设备model = model.to(device)
# 每个批次的数据也移动到同一设备batch_X = batch_X.to(device)batch_y = batch_y.to(device)这是 PyTorch 初学者非常容易遇到的问题之一。如果看到类似"设备不一致"的报错,首先应检查模型参数、输入数据和标签是否都在同一个设备上。
十二、与 NumPy 的相互转换
PyTorch 张量和 NumPy 数组可以相互转换。在数据处理、绘图和模型推理结果分析时,这一点很常用。
1、NumPy 数组转张量
apache
import torchimport numpy as np
arr = np.array([1, 2, 3])
# 将 NumPy 数组转换为 PyTorch 张量x = torch.from_numpy(arr)
print(x) # tensor([1, 2, 3])需要注意的是,torch.from_numpy() 创建的张量通常与原 NumPy 数组共享底层数据:
apache
import torchimport numpy as np
arr = np.array([1, 2, 3])x = torch.from_numpy(arr)
# 修改 NumPy 数组arr[0] = 100
print(arr) # [100 2 3]print(x) # tensor([100, 2, 3])这说明修改 NumPy 数组后,张量也发生了变化。在需要避免相互影响时,可以额外复制数据。
2、张量转 NumPy 数组
apache
import torch
x = torch.tensor([1, 2, 3])
# 将 CPU 张量转换为 NumPy 数组arr = x.numpy()
print(arr) # [1 2 3]通常只有 CPU 上的张量才能直接转换为 NumPy 数组。如果张量在 GPU 上,需要先移动到 CPU:
ini
# detach() 表示从计算图中分离# cpu() 表示移动到 CPU# numpy() 表示转换为 NumPy 数组arr = x.detach().cpu().numpy()这在模型推理结果转换为普通数组时非常常见。例如,模型预测结果通常先是张量,如果要进一步绘图、保存或交给其他数据分析代码处理,就可能需要转换为 NumPy 数组。
十三、随机数与可复现实验
深度学习中很多过程具有随机性,例如参数初始化、数据打乱、随机增强和 Dropout 等。为了让实验结果尽量可复现,通常会设置随机种子。
apache
import torch
# 设置随机种子torch.manual_seed(42)
a = torch.randn(3)
# 再次设置相同随机种子torch.manual_seed(42)
b = torch.randn(3)
print(a)print(b)两次生成的结果通常相同。可以简单理解为:
• 随机种子控制随机数生成的起点
• 相同随机种子通常会产生相同随机序列
• 可复现实验需要尽量控制随机性来源
在入门阶段,先理解 torch.manual_seed() 的作用即可。实际工程中,还可能需要同时控制数据加载、多进程、GPU 算子等因素。
十四、保存与加载张量
torch.save() 和 torch.load() 可以保存与加载张量或其他 PyTorch 对象。
apache
import torch
x = torch.randn(2, 3)
# 保存张量到文件torch.save(x, "tensor.pt")
# 从文件加载张量y = torch.load("tensor.pt")
print(y)这类操作可以用于:
• 保存中间计算结果
• 保存处理后的训练数据
• 保存模型参数
• 加载已有实验结果
在模型训练中,更常见的是保存模型参数:
apache
# 保存模型参数torch.save(model.state_dict(), "model.pth")加载时可以写成:
apache
# 加载模型参数model.load_state_dict(torch.load("model.pth"))不过,模型保存与加载属于更完整的模型工程主题。对于本文来说,只需要先知道:torch 模块已经提供了基础的保存与加载能力。
十五、一个完整示例:用 torch 完成基础线性计算
下面用一个简单例子说明 torch 模块如何完成基础计算。我们构造输入矩阵 X、权重矩阵 W 和偏置 b,计算线性输出。
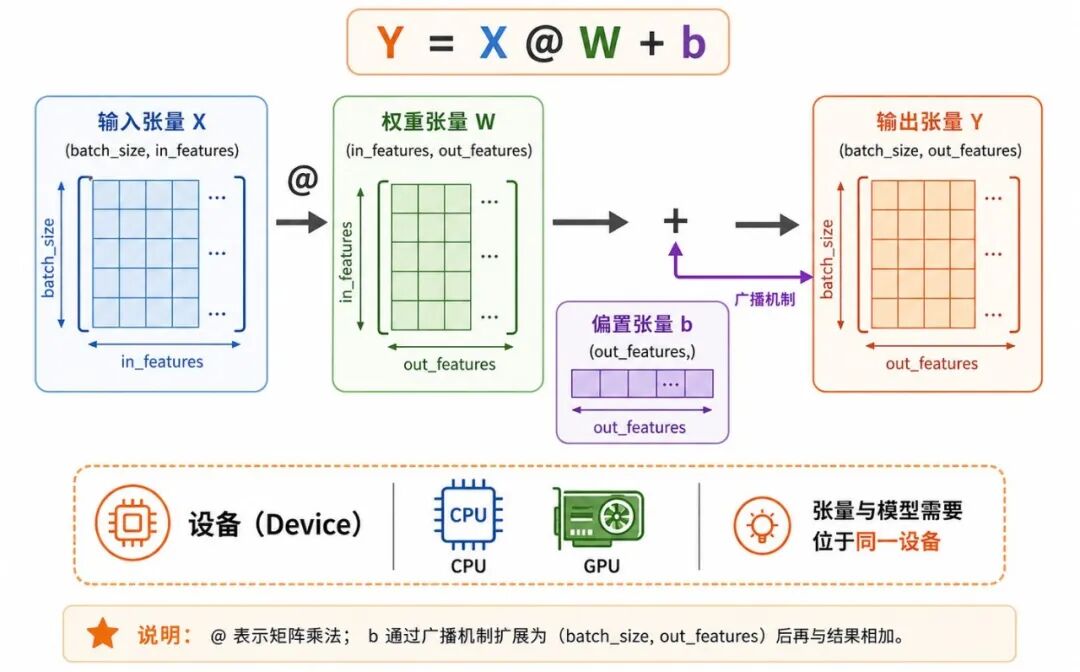
图 3:PyTorch 基础计算流程
python
import torch
# 1. 构造输入数据:5 个样本,每个样本 3 个特征X = torch.randn(5, 3)
# 2. 构造权重:3 个输入特征映射到 2 个输出W = torch.randn(3, 2)
# 3. 构造偏置:每个输出维度一个偏置b = torch.randn(2)
# 4. 线性计算:(5, 3) @ (3, 2) -> (5, 2)# b 的形状是 (2,),会自动广播到每一行Y = X @ W + b
print("X 的形状:", X.shape)print("W 的形状:", W.shape)print("b 的形状:", b.shape)print("Y 的形状:", Y.shape)print(Y)这里最值得关注的是形状关系:
• X 的形状是 (5, 3)
• W 的形状是 (3, 2)
• X @ W 的形状是 (5, 2)
• b 的形状是 (2,),会通过广播加到每一行
• 最终输出 Y 的形状是 (5, 2)
这个例子已经接近神经网络中全连接层的核心计算。后续使用 nn.Linear 时,底层思想与此类似,只是参数管理、自动求导和模块封装由 PyTorch 自动完成。
十六、使用 torch 模块时应注意的问题
1、先看形状,再看数值
很多 PyTorch 错误首先是形状错误,而不是算法错误。
例如:
apache
import torch
A = torch.randn(2, 3)B = torch.randn(4, 5)
# 形状不匹配,无法矩阵乘法# C = A @ B矩阵乘法要求前一个矩阵的列数等于后一个矩阵的行数。这里 A 是 (2, 3),B 是 (4, 5),中间维度 3 和 4 不一致,因此不能相乘。
调试时可以多打印:
bash
print(x.shape)print(x.dtype)print(x.device)这三个信息往往能帮助快速定位问题。
2、注意数据类型是否符合函数要求
有些函数要求输入是浮点张量,有些函数要求标签是整数张量。
例如:
apache
import torch
# 模型输出通常是浮点张量logits = torch.randn(8, 3)
# 多分类标签通常是整数类别索引target = torch.randint(0, 3, (8,))如果把标签错误地处理成浮点类型或错误形状,某些损失函数可能无法按预期工作。
因此,在训练代码出错时,不要只检查形状,也要检查 dtype。
3、注意张量是否在同一设备
CPU 张量和 GPU 张量不能随意直接混合计算。常见错误是模型在 GPU 上,而输入数据仍在 CPU 上。
推荐写法是统一使用 device:
ini
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)x = x.to(device)y = y.to(device)这样可以减少设备不一致导致的错误。
4、区分 reshape、view、permute 的作用
这几个函数都与形状有关,但含义不同:
• reshape():改变形状,常用且方便
• view():返回共享数据的新形状视图,对内存连续性更敏感
• permute():重新排列维度顺序
• transpose():交换两个维度
• flatten():展平多个维度
例如,图像张量从 (N, H, W, C) 转为 (N, C, H, W),应使用 permute(),而不是简单使用 reshape()。
reshape() 改变的是"如何看待这批元素的形状",而 permute() 改变的是"维度顺序"。两者不能混用。
5、理解广播,而不是滥用广播
广播可以让代码更简洁,但也可能让错误更隐蔽。
例如,一个张量形状是 (100, 4),另一个张量形状是 (4,),它们相加通常是合理的,因为 (4,) 可以看作对每个样本的 4 个特征分别加偏置。
但如果本来想对每个样本加不同的数,却误写成了 (4,),代码可能仍然能运行,但含义已经错了。
因此,使用广播时应先问清楚:
• 哪个维度表示样本?
• 哪个维度表示特征?
• 哪个张量会被自动扩展?
• 扩展方向是否符合预期?
6、不要把 torch 模块只理解为"创建数组"
torch 模块不仅是创建数组的工具。它是 PyTorch 的基础计算层,承担了张量表示、数学运算、设备管理、随机数、保存加载等多种职责。
在后续学习中:
• 神经网络层会基于张量进行计算
• 自动求导会跟踪张量运算过程
• 优化器会根据张量梯度更新参数
• 数据加载器会把数据组织成批量张量
因此,理解 torch 模块,是理解整个 PyTorch 的基础。
📘 小结
PyTorch 的 torch 模块负责张量表示与基础计算,是整个框架的底层入口。学习这一模块,重点不只是记住函数名称,而是理解张量的形状、数据类型、设备、运算规则和广播机制。掌握这些内容,才能更顺利地学习自动求导、神经网络建模和完整训练流程。

"点赞有美意,赞赏是鼓励"