一、核心功能
AEC3 (Acoustic Echo Canceller v3) 是 WebRTC 中负责消除"声学回声"的核心模块。其主要承担四项职责:
- 回声路径建模与线性消除:基于参考信号
x[n](远端 render)估计扬声器-->空气-->麦克风之间的脉冲响应h[n],从近端麦克风信号y[n]中减去线性估计ŷ[n],得到误差信号e[n](echo_canceller3.h接口层、subtractor.cc)。 - 延迟估计与对齐:自动估计 render 与 capture 之间的时序对齐,并补偿时钟漂移 (
echo_path_delay_estimator.cc、render_delay_controller.cc、matched_filter.cc、clockdrift_detector.cc)。 - 残余回声抑制:在线性滤波后通过频域时变增益做非线性抑制 (
residual_echo_estimator.cc、suppression_gain.cc、suppression_filter.cc)。 - 舒适噪声生成 (CNG) 与状态管理:在被抑制的频段填充与底噪匹配的舒适噪声 (
comfort_noise_generator.cc),并由AecState管理收敛、饱和、透明模式、混响等所有上下文。
入口类 EchoCanceller3 实现 EchoControl 接口,处理 4ms / 10ms 的分带子帧,并将其切分成 64 样本/4ms 的 Block 传给底层流水线。
cpp
class EchoCanceller3 : public EchoControl {
public:
// ...
void AnalyzeRender(AudioBuffer* render) override { AnalyzeRender(*render); }
void AnalyzeCapture(AudioBuffer* capture) override { ... }
void ProcessCapture(AudioBuffer* capture, bool level_change) override;
void ProcessCapture(AudioBuffer* capture,
AudioBuffer* linear_output,
bool level_change) override;
Metrics GetMetrics() const override;
void SetAudioBufferDelay(int delay_ms) override;
void SetCaptureOutputUsage(bool capture_output_used) override;
// ...
};二、核心算法原理
AEC3 是经典的"线性自适应滤波 + 后置非线性抑制"两级 AEC,但在每一级都做了大量工程级强化。
2.1 自适应线性滤波(频域分块 NLMS)
信号模型:
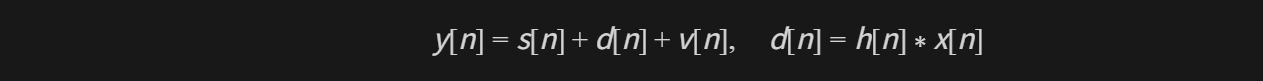
其中 s[n] 为近端语音,d[n] 为回声,v[n] 为噪声。AEC3 用频域分块卷积估计 ĥ[n]:
- 滤波器以 64 样本为一个分块(partition)。
kBlockSize = kFftLengthBy2 = 64,FFT 长度 128(aec3_common.h)。 - 参考信号被切成多个 partition
X_p(k),滤波器同样按 partition 存储为H_p(k),再做 partitioned-block-frequency-domain (PBFDAF) 卷积:
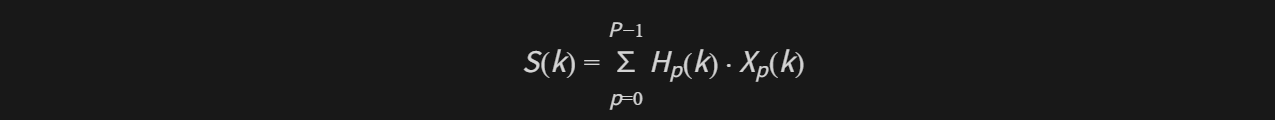
- 时域误差
e[n] = y[n] - s[n],再做 0-padding + Hanning windowed FFT 得到E(k)。
更新公式(频域 NLMS,见 refined_filter_update_gain.cc):
cpp
// mu = H_error / (0.5* H_error* X2 + n * E2).
for (size_t k = 0; k < kFftLengthBy2Plus1; ++k) {
if (X2[k] >= current_config_.noise_gate) {
mu[k] = H_error_[k] /
(0.5f * H_error_[k] * X2[k] + size_partitions * E2_refined[k]);
} else {
mu[k] = 0.f;
}
}
// Avoid updating the filter close to narrow bands in the render signals.
render_signal_analyzer.MaskRegionsAroundNarrowBands(&mu);
// H_error = H_error - 0.5 * mu * X2 * H_error.
for (size_t k = 0; k < kFftLengthBy2Plus1; ++k) {
H_error_[k] -= 0.5f * mu[k] * X2[k] * H_error_[k];
}
// G = mu * E.
for (size_t k = 0; k < kFftLengthBy2Plus1; ++k) {
G->re[k] = mu[k] * E_refined.re[k];
G->im[k] = mu[k] * E_refined.im[k];
}可见步长 µ(k) 不是常数,而是基于"估计的系数误差能量 H_error"自适应得到的最优维纳步长------本质上是一个简化的频域 Kalman / IPNLMS 思想:参考能量大、误差小时步长大;反之保守。H_error 自己也是迭代更新的:每次梯度下降按 µ·X²·H_error 缩小,每个 block 用 leakage * erl 注入泄漏量,避免长期低估。
cpp
for (size_t k = 0; k < kFftLengthBy2Plus1; ++k) {
if (E2_refined[k] <= E2_coarse[k] || disallow_leakage_diverged) {
H_error_[k] += current_config_.leakage_converged * erl[k];
} else {
H_error_[k] += current_config_.leakage_diverged * erl[k];
}
H_error_[k] = std::max(H_error_[k], current_config_.error_floor);
H_error_[k] = std::min(H_error_[k], current_config_.error_ceil);
}2.2 双线性滤波器架构(Refined + Coarse)
Subtractor 同时维护两个并行的 AdaptiveFirFilter:
| 滤波器 | 长度 | 步长 | 用途 |
|---|---|---|---|
| Refined | 长(默认 13 blocks ≈ 52ms) | 小(精细收敛) | 提供高质量线性输出与 ERLE/ERL 估计 |
| Coarse | 短(默认 5 blocks) | 大(快速跟踪) | 快速响应路径变化、用于双讲检测的对照 |
每个 block:若 e²_refined > e²_coarse 持续 5 次(说明 refined 发散),就用 coarse 直接覆盖 refined------这是 AEC3 处理路径突变的关键机制。
cpp
poor_coarse_filter_counters_[ch] =
output.e2_refined < output.e2_coarse
? poor_coarse_filter_counters_[ch] + 1
: 0;
if (poor_coarse_filter_counters_[ch] < 5) {
coarse_gains_[ch]->Compute(X2_coarse, render_signal_analyzer, E_coarse, ...);
} else {
poor_coarse_filter_counters_[ch] = 0;
coarse_filter_[ch]->SetFilter(refined_filters_[ch]->SizePartitions(),
refined_filters_[ch]->GetFilter());
...
}2.3 延迟估计(Matched Filter + Lag Aggregator)
AEC3 不依赖外部精确延迟,而通过对下采样信号做匹配滤波估计 render→capture 的延迟:
- 下采样(默认 4x,48kHz→12kHz 量级)降低复杂度;
- 在多个候选位移上维护滑窗匹配滤波器(cross-correlation NLMS),计算每个位移上的误差能量;
MatchedFilterLagAggregator聚合多帧的最佳 lag,给出coarse或refined两级置信度;ClockdriftDetector用 lag 的漂移率检测时钟漂移;- 还可检测 pre-echo(前置回声,对应早期反射或采集系统提前抓到的样本)。
cpp
absl::optional<DelayEstimate> EchoPathDelayEstimator::EstimateDelay(...) {
...
capture_mixer_.ProduceOutput(capture, downmixed_capture);
capture_decimator_.Decimate(downmixed_capture, downsampled_capture);
...
matched_filter_.Update(render_buffer, downsampled_capture,
matched_filter_lag_aggregator_.ReliableDelayFound());
absl::optional<DelayEstimate> aggregated_matched_filter_lag =
matched_filter_lag_aggregator_.Aggregate(
matched_filter_.GetBestLagEstimate());
if (aggregated_matched_filter_lag &&
... == DelayEstimate::Quality::kRefined)
clockdrift_detector_.Update(matched_filter_lag_aggregator_.GetDelayAtHighestPeak());
...
}2.4 残余回声估计与抑制(Wiener-like Gain)
线性滤波后还剩"残余回声 R²",AEC3 用两种模型:
- 线性模式:
R²(k) = S²_linear(k) / ERLE(k),依赖滤波器输出能量与"回声回波损失增强" ERLE; - 非线性模式(滤波器未收敛时):
R²(k) = X²(k) · g_echo_path²,直接用参考能量乘以一个保守的路径增益。
随后叠加一个指数衰减混响模型(reverb_model.cc/reverb_decay_estimator.cc):
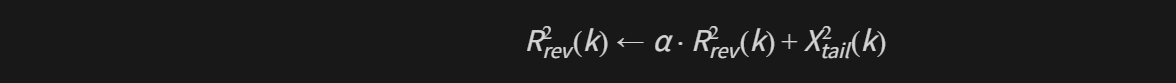
抑制增益核心来自 SuppressionGain::GainToNoAudibleEcho:
cpp
void SuppressionGain::GainToNoAudibleEcho(
const std::array<float, kFftLengthBy2Plus1>& nearend,
const std::array<float, kFftLengthBy2Plus1>& echo,
const std::array<float, kFftLengthBy2Plus1>& masker,
std::array<float, kFftLengthBy2Plus1>* gain) const {
const auto& p = dominant_nearend_detector_->IsNearendState() ? nearend_params_
: normal_params_;
for (size_t k = 0; k < gain->size(); ++k) {
float enr = echo[k] / (nearend[k] + 1.f); // Echo-to-nearend ratio.
float emr = echo[k] / (masker[k] + 1.f); // Echo-to-masker (noise) ratio.
float g = 1.0f;
if (enr > p.enr_transparent_[k] && emr > p.emr_transparent_[k]) {
g = (p.enr_suppress_[k] - enr) / (p.enr_suppress_[k] - p.enr_transparent_[k]);
g = std::max(g, p.emr_transparent_[k] / emr);
}
(*gain)[k] = g;
}
}这是基于听觉掩蔽的 Wiener 增益:
- 当
ENR (echo-to-nearend)与EMR (echo-to-masker)均超过透明阈值时,按线性插值压低增益; - 同时考虑 noise masking,让回声"被噪声盖住即可",避免过度抑制语音;
dominant_nearend_detector_在"近端语音占主导"时切换到更保守的nearend_params_,保护双讲。
2.5 状态机:AecState
AecState 是整个算法的"大脑",决定:
- 当前是否处于初始 (filter not converged) 状态;
- 线性输出是否可用(
UsableLinearEstimate); - 是否进入透明模式(无回声场景,绕过抑制);
- 是否饱和;
- 直达声延迟、ERL/ERLE/混响等。
三、关键数据结构
| 数据结构 | 文件 | 角色 |
|---|---|---|
Block |
block.h |
一个 4ms / 64-sample 的多带多声道时域块,AEC3 的最小处理单元 |
FftData |
fft_data.h |
65 点单边 FFT 容器(re[65], im[65]),16 字节对齐 |
RenderBuffer / SpectrumBuffer / FftBuffer / BlockBuffer |
render_buffer.* |
多视图环形缓冲,分别存时域、功率谱、复频谱 |
DownsampledRenderBuffer |
downsampled_render_buffer.* |
用于延迟估计的下采样时域环形缓冲 |
RenderDelayBuffer |
render_delay_buffer.cc |
渲染端总抽象:写入 → 下采样 → 对齐 → 输出给 EchoRemover |
AdaptiveFirFilter |
adaptive_fir_filter.* |
频域分块自适应 FIR(partitioned FFT filter):H_[p][ch] |
SubtractorOutput |
subtractor_output.h |
单 channel 滤波结果:e_refined, e_coarse, s_refined, E_refined, E2_*, e2_*, s2_*, y2 |
AecState |
aec_state.h |
包含 InitialState / FilterDelay / FilteringQualityAnalyzer / SaturationDetector 等子状态 |
EchoPathVariability |
echo_path_variability.h |
回声路径变化标记(gain/delay change),驱动 reset 行为 |
DelayEstimate |
delay_estimate.h |
{delay, quality(kCoarse / kRefined)} |
MatchedFilter::LagEstimate |
matched_filter.h |
{lag, pre_echo_lag} |
ReverbModel / ReverbModelEstimator |
reverb_*.* |
指数衰减拖尾混响估计 |
SubtractorOutput 是非常关键的"中间产物",串联起线性滤波 → AecState 更新 → 残余回声估计:
cpp
struct SubtractorOutput {
std::array<float, kBlockSize> s_refined;
std::array<float, kBlockSize> s_coarse;
std::array<float, kBlockSize> e_refined;
std::array<float, kBlockSize> e_coarse;
FftData E_refined;
std::array<float, kFftLengthBy2Plus1> E2_refined;
std::array<float, kFftLengthBy2Plus1> E2_coarse;
float s2_refined = 0.f;
float s2_coarse = 0.f;
float e2_refined = 0.f;
float e2_coarse = 0.f;
float y2 = 0.f;
float s_refined_max_abs = 0.f;
float s_coarse_max_abs = 0.f;
void Reset();
void ComputeMetrics(rtc::ArrayView<const float> y);
};四、核心方法详解
4.1 EchoCanceller3::ProcessCapture ------ 顶层入口
按子帧 (10ms = 2×5ms 子帧) 操作:
AnalyzeCapture检测麦克风饱和;- 从 SwapQueue 拉取已分析的 render 帧,喂给
block_processor_->BufferRender; - 子帧切块 →
block_processor_->ProcessCapture(...); - 再帧化输出。
4.2 BlockProcessor::ProcessCapture ------ 分块协调器
cpp
void BlockProcessorImpl::ProcessCapture(bool echo_path_gain_change,
bool capture_signal_saturation,
Block* linear_output,
Block* capture_block) {
...
if (render_properly_started_) {
if (!capture_properly_started_) { capture_properly_started_ = true; ... }
} else { render_buffer_->HandleSkippedCaptureProcessing(); return; }
EchoPathVariability echo_path_variability(...);
if (render_event_ == ...kRenderOverrun ...) {
echo_path_variability.delay_change = ...::kBufferFlush;
delay_controller_->Reset(true);
}
RenderDelayBuffer::BufferingEvent buffer_event =
render_buffer_->PrepareCaptureProcessing();
...
if (has_delay_estimator) {
estimated_delay_ = delay_controller_->GetDelay(...);
if (estimated_delay_) {
bool delay_change = render_buffer_->AlignFromDelay(estimated_delay_->delay);
if (delay_change) echo_path_variability.delay_change = ...::kNewDetectedDelay;
}
echo_path_variability.clock_drift = delay_controller_->HasClockdrift();
} else { render_buffer_->AlignFromExternalDelay(); }
if (has_delay_estimator || render_buffer_->HasReceivedBufferDelay()) {
echo_remover_->ProcessCapture(echo_path_variability, capture_signal_saturation,
estimated_delay_,
render_buffer_->GetRenderBuffer(),
linear_output, capture_block);
}
...
}要点:
- render-leading 协议:必须先有 render 数据才处理 capture,否则跳过(避免无参考状态下的发散);
- 处理 buffer overrun/underrun,发生即 reset;
- 把"延迟变化"、"增益变化"、"时钟漂移"封装进
EchoPathVariability透传给EchoRemover。
4.3 EchoRemoverImpl::ProcessCapture ------ 单 block 核心流水线
参见 echo_remover.cc 中 ProcessCapture(前面已贴),关键步骤按序:
- 饱和与路径变化处理:
subtractor_.HandleEchoPathChange()、aec_state_.HandleEchoPathChange(),并对 hangover 计数(避免帧内多次 gain reset)。 render_signal_analyzer_.Update:检测窄带峰值,用于掩蔽窄带位置上的滤波器更新(避免单频信号导致系数漂移)。subtractor_.Process:跑双线性滤波器,输出subtractor_output[ch]。FormLinearFilterOutput:在 refined/coarse 间软切换(30 样本线性过渡),避免毛刺。- 谱计算:对
y、e做 sqrt-Hanning + zero-pad FFT,得到Y, E, Y², E², S²_linear。 aec_state_.Update:更新 ERL、ERLE、滤波器收敛性、混响等状态。cng_.Compute:估计舒适噪声谱。residual_echo_estimator_.Estimate→R²/R²_unbounded。suppression_gain_.GetGain→ 低带增益G[k]、高带增益high_bands_gain。suppression_filter_.ApplyGain:频域应用增益 + 加入舒适噪声 + IFFT + OLA 合成时域。- 指标更新与数据 dump。
4.4 Subtractor::Process ------ 双线性滤波器联合更新
cpp
// 1) 计算 render 在两个 partition 数下的功率谱 X2_refined / X2_coarse
// 2) refined / coarse 滤波 → 时域误差(PredictionError 做 IFFT 取后半)
refined_filters_[ch]->Filter(render_buffer, &S);
PredictionError(fft_, S, y, &e_refined, &output.s_refined);
coarse_filter_[ch]->Filter(render_buffer, &S);
PredictionError(fft_, S, y, &e_coarse, &output.s_coarse);
// 3) 失调估计(FilterMisadjustmentEstimator):若 e²/y² 异常大,整体缩放滤波器
// 避免长时间发散
if (filter_misadjustment_estimators_[ch].IsAdjustmentNeeded()) {
float scale = ...;
refined_filters_[ch]->ScaleFilter(scale);
ScaleFilterOutput(y, scale, e_refined, output.s_refined);
}
// 4) FFT 误差 → 增益计算(RefinedFilterUpdateGain / CoarseFilterUpdateGain)
// → 频域自适应 Adapt(H += G·conj(X))→ ComputeFrequencyResponse
// 5) coarse 长期劣于 refined → 拷贝 refined 系数覆盖 coarsePredictionError 用了Overlap-Save的标准技巧:取 IFFT 后半段作为线性卷积输出,前半段丢弃,避免循环卷积污染。
4.5 AdaptiveFirFilter::Adapt ------ 频域分块滤波器更新
频域系数更新:
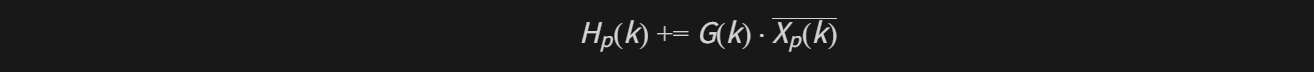
即 adaptive_fir_filter.cc::AdaptPartitions:
cpp
for (size_t p = 0; p < num_partitions; ++p) {
for (size_t ch = 0; ch < num_render_channels; ++ch) {
const FftData& X_p_ch = render_buffer_data[index][ch];
FftData& H_p_ch = (*H)[p][ch];
for (size_t k = 0; k < kFftLengthBy2Plus1; ++k) {
H_p_ch.re[k] += X_p_ch.re[k] * G.re[k] + X_p_ch.im[k] * G.im[k];
H_p_ch.im[k] += X_p_ch.re[k] * G.im[k] - X_p_ch.im[k] * G.re[k];
}
}
index = index < (render_buffer_data.size() - 1) ? index + 1 : 0;
}每个 block 还会循环约束一个 partition(Constrain):将该 partition 做 IFFT,把后半段置零再 FFT 回去------这是分块频域滤波器的线性化约束,否则会得到循环卷积而非线性卷积。每次只约束一个 partition,分散计算成本。
4.6 MatchedFilter::Update ------ 匹配滤波延迟估计
对 capture 块 y 与 render 缓冲 x:
- 维护多个候选位移上的"小型 NLMS 滤波器"
h_i,每个长度约 32 sub-block; - 累积每个滤波器的预测误差能量,最小者对应最优 lag;
- 还可计算 accumulated_error,定位最早一个误差足够低的系数作为 pre-echo lag;
- 实现了 SSE2/AVX2/NEON 三套 SIMD 加速。
4.7 SuppressionGain::GetGain ------ 时变频域增益
cpp
void SuppressionGain::GetGain(...) {
const auto echo = use_unbounded_echo_spectrum_
? residual_echo_spectrum_unbounded
: residual_echo_spectrum;
dominant_nearend_detector_->Update(nearend_spectrum, echo,
comfort_noise_spectrum, initial_state_);
bool low_noise_render = low_render_detector_.Detect(render);
LowerBandGain(low_noise_render, aec_state, nearend_spectrum,
residual_echo_spectrum, comfort_noise_spectrum, clock_drift,
low_band_gain);
const absl::optional<int> narrow_peak_band =
render_signal_analyzer.NarrowPeakBand();
*high_bands_gain = UpperBandsGain(echo_spectrum, comfort_noise_spectrum,
narrow_peak_band, aec_state.SaturatedEcho(),
render, *low_band_gain);
}低带增益 LowerBandGain 流程:
- 对近端做多帧滑动平均抑制瞬时波动;
- 调用
WeightEchoForAudibility根据心理声学可听度对回声谱加权(低能量回声被弱化,避免不必要的抑制); GainToNoAudibleEcho得到基础 Wiener 增益;GetMaxGain / GetMinGain限制增益的时间方向变化率(softening,防止伪影/啸叫);LimitLowFrequencyGains / LimitHighFrequencyGains:补偿高通滤波器影响、对未收敛的高频做保守限制;sqrt转幅度域。
高带增益 UpperBandsGain:
- 单带直接返回 1;
- 反啸叫:若高频能量大于低频能量,按
sqrt(low/high)衰减; - 窄带峰值在高频时一律压低(防止啸叫起振)。
4.8 ResidualEchoEstimator::Estimate ------ 残余回声估计
策略由 AecState::UsableLinearEstimate() 决定:
cpp
if (aec_state.UsableLinearEstimate()) {
if (aec_state.SaturatedEcho()) {
// 饱和:直接用 Y² 当 R²,最大力度抑制
} else {
LinearEstimate(S2_linear, aec_state.Erle(onset_compensated), R2);
LinearEstimate(S2_linear, aec_state.ErleUnbounded(), R2_unbounded);
}
UpdateReverb(ReverbType::kLinear, ...); AddReverb(R2); AddReverb(R2_unbounded);
} else {
// 滤波器未收敛 → 非线性回退
EchoGeneratingPower(...);
for (...) X2[k] -= stationary_gate_slope * X2_noise_floor_[k]; // 减底噪
NonLinearEstimate(echo_path_gain, X2, R2);
if (model_reverb_in_nonlinear_mode && !TransparentModeActive())
UpdateReverb(ReverbType::kNonLinear, ...); AddReverb(R2);
}
if (aec_state.UseStationarityProperties()) {
// 平稳性场景再做心理声学缩放
}EchoGeneratingPower 在一个时间窗内取最大功率(pre_window/post_window 在 delay 附近),以鲁棒对抗延迟估计偏差。
4.9 AecState::Update ------ 状态综合
每 block 都调用,包含:
SubtractorOutputAnalyzer看 refined/coarse 是否收敛/发散;FilterAnalyzer在脉冲响应上找直达声延迟、估计max_echo_path_gain;delay_state_.Update:综合外部 delay + 滤波器分析延迟;- 更新激活渲染计数
blocks_with_active_render_与未饱和强渲染计数strong_not_saturated_render_blocks_; - 计算平均渲染混响谱;
erle_estimator_.Update/erl_estimator_.Update/reverb_model_estimator_.Update;saturation_detector_.Update;transparent_state_->Update(无回声场景检测);filter_quality_state_.Update:滤波器是否可用作输出。
五、设计亮点
- 双线性滤波器(refined + coarse):用快滤波器做"安全网",慢滤波器做"高质量输出",在路径突变与稳态精度间做了优秀的工程平衡。
- 频域 Kalman-flavored 步长 (
H_error):自适应步长来自系数误差能量的递推,比固定 µ 的 NLMS 收敛更快、稳态更稳。 - partitioned FFT + 循环 constrain:把长滤波器拆成短分块,复杂度从 O(N²) → O(N logN),每帧只 constrain 一个 partition 减少 IFFT/FFT 开销。
- 延迟估计与对齐解耦:
RenderDelayBuffer通过环形 buffer 把"对齐"做成 O(1) 读指针调整,无需搬数据;MatchedFilter在下采样域做相关,复杂度低。 - PreEcho 检测:在 accumulated_error 上找最早的低误差系数,处理某些设备/驱动会"先于参考信号送入麦克风"的异常情形。
- AecState 集中状态:所有"是否能信任滤波器、是否饱和、是否透明、是否近端主导"等关键决策集中在一个对象内,避免散落 if-else。
- TransparentMode:无回声场景(如蓝牙耳机/远端无人讲话)下绕过抑制,避免破坏近端语音。
- Dominant nearend detection:双讲检测从全频带(
DominantNearendDetector)到分子带(SubbandNearendDetector)两种实现,按配置切换。 - 回声可听度加权 (
WeightEchoForAudibility):低能量回声被乘以心理声学因子衰减,让"听不见的回声不被过度抑制",保留近端自然度。 - 混响建模分两种 (kLinear / kNonLinear):与是否使用线性输出绑定,分别用不同的起始 partition 与频率响应。
- SIMD 优化全面:
adaptive_fir_filter、matched_filter、vector_math、fft_data、adaptive_fir_filter_erl均提供 SSE2/AVX2/NEON 版本。 - 多通道支持:
MultiChannelContentDetector+ConfigSelector自动在单通道与多通道配置间切换,并能识别"两路相同的伪立体声"以节省算力。 - API 抖动鲁棒性:
render_transfer_queue_(SwapQueue)+ApiCallJitterMetrics+ buffer overrun/underrun 处理机制,应对真实 WebRTC 调用中 render/capture 调用错位。 - field_trial 钩子:大量行为可被远端实验切换,便于线上灰度优化(如
WebRTC-Aec3CoarseFilterResetHangoverKillSwitch、WebRTC-Aec3StereoContentDetectionKillSwitch等)。 - Linear filter output 可选输出:
linear_output作为额外 channel 返回未经抑制器的纯线性结果,便于后续模块(如 NS、AGC、ML 后处理)独立使用。
六、典型工作流程
6.1 数据流总览(10ms 处理)
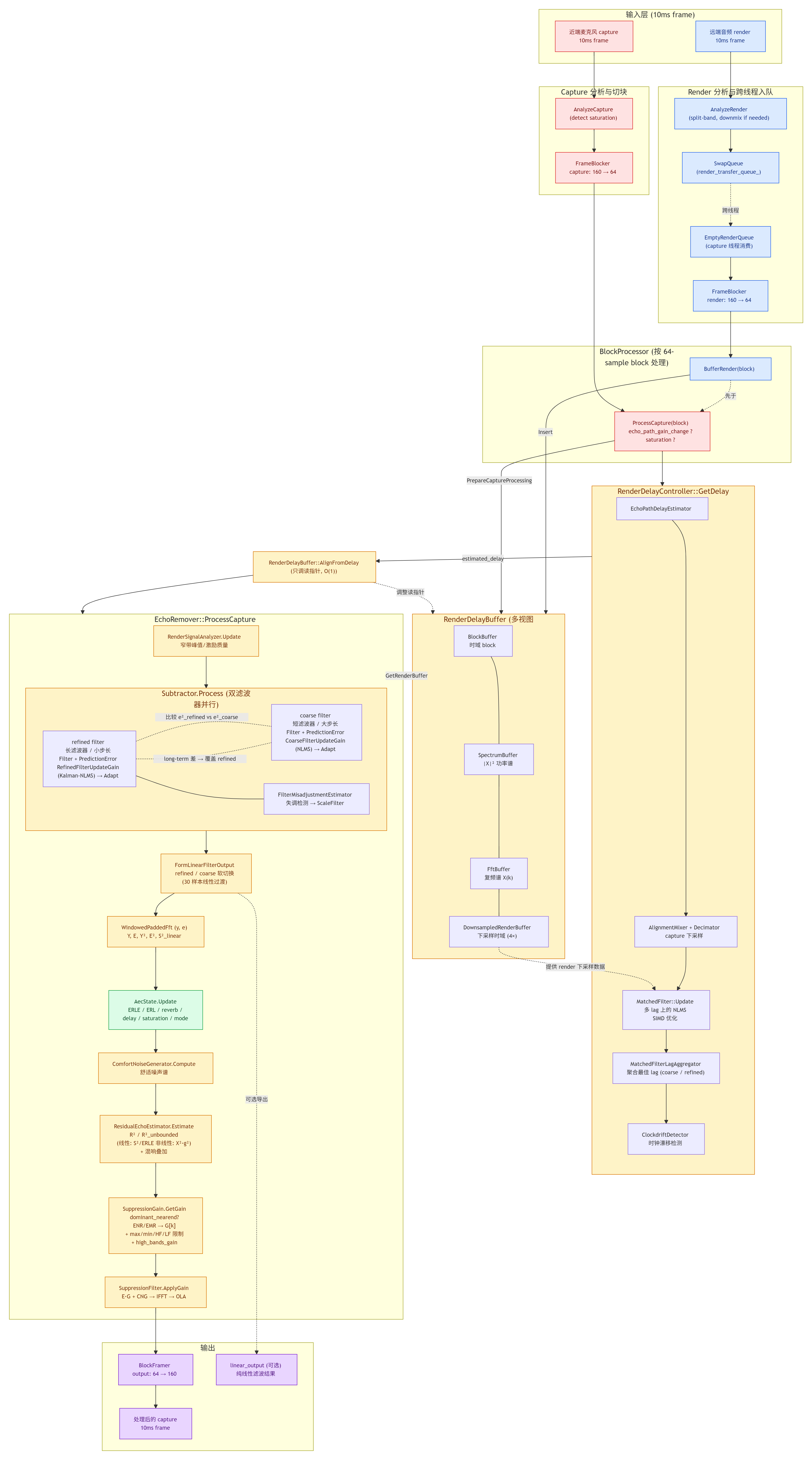
6.2 关键时序点
- 算法 warm-up:默认
initial_state_seconds(约 2.5s 或保守 5s)内使用 initial filter config,更短的滤波器 + 更激进的步长,加速首次收敛。InitialState::Update通过累积"强渲染未饱和块数"判断退出条件。 - 延迟稳定后:
consistent_estimate_counter_在 0.5s 内一致即可重置 lag aggregator,进入稳态。 - 遇到路径变化:
EchoPathVariability::delay_change != kNone触发Subtractor::HandleEchoPathChange→full_reset→AecState::HandleEchoPathChange→ ERLE/ERL/quality 全部 reset,并重启 initial config。 - 每帧 Constrain:滤波器有 P 个 partition,每帧只对一个做时域约束,约 P 帧扫一轮,分摊计算。
- 滤波器尺寸切换:从 initial 到 stable 通过
config_change_duration_blocks平滑过渡(线性插值),避免阶跃带来的伪影。
七、算法架构图
7.1 类组织视图
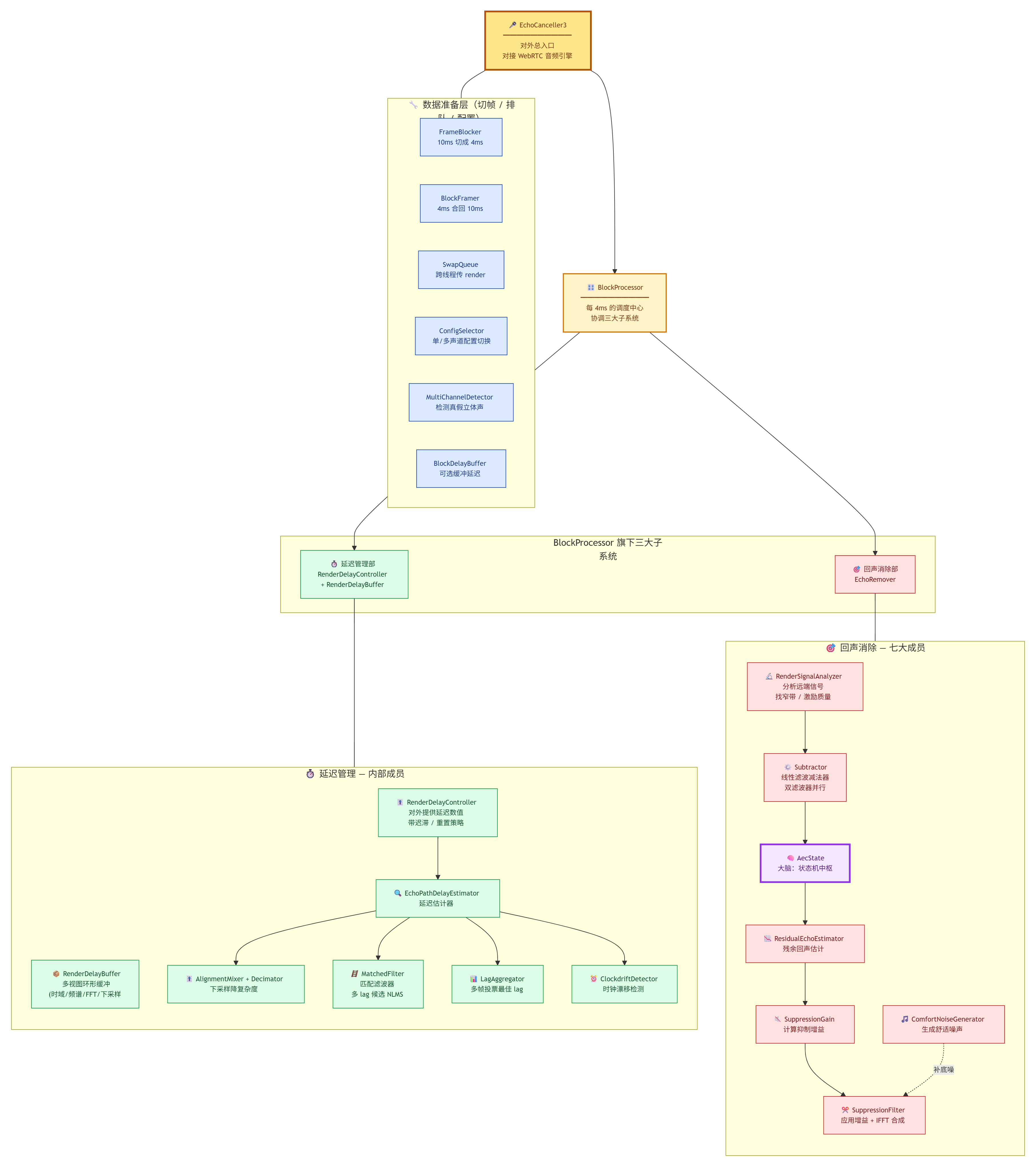
7.2 信号流视图(频域核心环路)
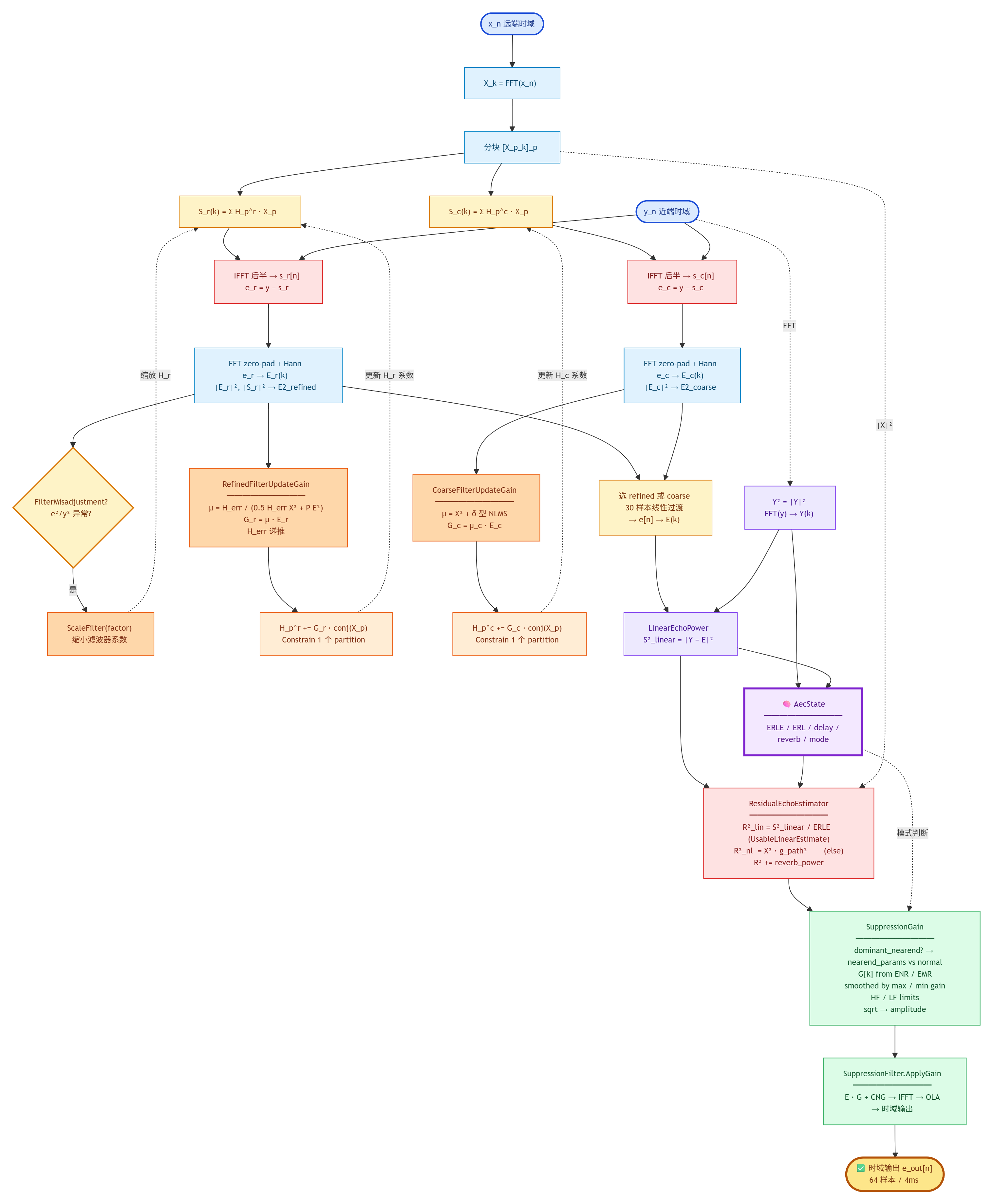
7.3 数据时间维度视图(一个 4ms block 内)
cpp
t (block)
│
│ render path: capture path:
│ x[n]──┐ y[n]
│ FFT │
│ ▼ ▼
│ X_p (push) ProcessCapture
│ │ │
│ │ ▼
│ │ DelayEstimate (downsampled MatchedFilter)
│ ▼ │
│ render buffer ◄─ AlignFromDelay
│ │ │
│ ▼ ▼
│ Subtractor.Process (refined + coarse)
│ │
│ ▼
│ e[n], E(k), S²_linear, SubtractorOutput
│ │
│ ▼
│ AecState.Update (ERLE/ERL/reverb/...)
│ │
│ ▼
│ ResidualEchoEstimator.Estimate → R²
│ │
│ ▼
│ SuppressionGain.GetGain → G[k], hi_gain
│ │
│ ▼
│ SuppressionFilter.ApplyGain → e_out[n]
│
▼总结
AEC3 在算法上仍属经典 "线性 PBFDAF + 后置 Wiener-like 抑制" 框架,但在 WebRTC 的真实音视频通信场景下做了大量"工程级补强":
- 自适应 Kalman 风格的步长 (
H_error); - refined/coarse 双线性滤波器机制;
- partitioned FFT + 循环 constrain;
- MatchedFilter + LagAggregator + Clockdrift 三位一体的延迟与时钟漂移估计;
- 心理声学加权的可听度抑制;
- AecState 集中状态机统辖 ERLE/ERL/混响/饱和/透明模式/双讲;
- 完整的 SIMD 优化、多通道、多采样率支持;
- field_trial 灰度切换钩子覆盖全部关键决策。
这些设计使其能在端到端低延迟(4ms/块)、双讲、强混响、时钟漂移、设备 jitter 的恶劣条件下稳定工作,是工业级 AEC 实现的有效方法。