现在主流的 AI coding agent 各有所长,Claude Code 的 plan、Codex 的 debug、Copilot CLI 的 GitHub 工作流、Gemini 的 UI 直觉,没一个是真正全能的。我做了一个叫 CodeMux 的客户端,让它们之间能互相接力------一个出方案,一个查 bug, 一个写代码,共享同一份上下文。 这两年 AI coding agent 出得快,社交平台上隔一阵就吵一波"哪个最强"。我自己倒没太纠结过这件事------打开终端会看到四个 agent 的窗口同时挂着:Claude Code、Codex、Copilot CLI, 还有跑在 OpenCode 里的 Gemini。一开始只是想都试试看哪个顺手,用着用着就再也合不回一个了。
现在主流的 AI coding agent, 没有一个是真正全能的。Claude Code 的 plan 拆解我用得最多,长上下文也耐受得住,但偶尔 debug 时会绕远路;同样的问题丢给 Codex 反而经常能挖到根因。Copilot CLI 的强项也不在模型,而在它对 GitHub 工作流的熟悉度------处理 issue 和 code review 自带一种肌肉记忆。Gemini 我用得没那么频繁,但出 UI 草图时常常给我一些惊喜。
各有各的擅长,也各有各的死角。与其逼一个 agent 把全部活都干了,不如让它们各自做最对味的事------这是过去几个月我用下来的核心体感。
我手头这几个 Agent, 各自管什么活
具体到工作流里,这几个 agent 在我这有相对固定的分工。
Claude Code 是我的主 agent,coding plan 和 codebase analysis 几乎都交给它。它的 harness 设计得很扎实,长上下文里追溯多个文件之间的关系不容易掉链子。我习惯让它先做架构层面的判断------"这个改动应该改哪几个模块、依赖关系会不会出问题、有没有更小的 patch 能达到同样目的", 这类问题它经常能给出比我自己想得更全面的答案。
真正棘手的 bug 我会丢给 Codex, 挂 GPT-5.5。 这是我后来摸出来的搭配。有些 bug 不是表面的 typo 或者 null check, 是工程师自己看了半天都觉得"这地方逻辑没毛病但就是不对"的那种------可能涉及多线程时序、可能是某个第三方库的隐式假设、可能是状态机里被忽略的边界 case。Codex 在这类问题上的"思考深度"我感受得很明显,它愿意去挖根因而不是给一个"试试这样改"的快修。
Copilot CLI 是我处理 GitHub 相关任务的首选。 这一点不太被讨论,但我猜它训练数据里塞了大量真实开源项目的 issue / PR / review 历史------所以让它读 issue 找 root cause、起草 review comment、按 maintainer 的语气回复 contributor, 它做出来的东西比通用模型自然得多。同样一份 PR diff,Claude Code 的 review 是"这里逻辑可以改成 X",Copilot CLI 给出来的会带"我们 repo 里另一处类似的实现是 Y, 要不要保持一致"------这种 codebase 内部一致性的视角,挺加分的。
Gemini 我主要用在 UI/UX 设计上, 挂在 OpenCode 里跑。3.1 推出之后我做前端原型时偶尔会试一下,它对视觉层级、信息密度的直觉确实和写代码的模型不太一样。
把这几个组合起来用,月度 token 用量在 billion 量级。原因不是我故意烧,是好用之后回不去单引擎模式了------同样的需求,正确的 agent 一次就能给出能用的结果,错的 agent 来回拉扯几轮反而更贵。
真正卡人的不是模型,是切换
但同时挂着四个 agent 用,会很快撞到一个问题:它们之间什么都不共享。
最典型的场景是这样的:Claude Code 帮我把一个新 feature 的方案想清楚了,plan 写得很完整,接下来就该动手了。这时候按我的工作流应该切到 Codex 或者别的 agent 去执行------但 plan 是 Claude 自己 session 里的产物,Codex 看不见。我得手动复制 plan、贴到 Codex 的输入框里、再补一段背景"我在做 X 项目,目前的代码结构大概是 Y, 你按这个 plan 帮我实现"。每次切换 agent 都来一遍,每次都要重新讲一遍上下文。
更烦的是 debug 场景。Claude 跑了半天没找到根因,我想换 Codex 试试------但 Codex 没有"刚才尝试过哪些假设、排除了什么"的记忆,我要么自己总结一遍,要么让 Codex 从头开始走一次相同的探索路径,白白烧 token。
问题不在模型本身,在工具链没有为"多 agent 协作"设计过。 现在的 coding agent 客户端基本都假设你只用一个 agent------ Cursor 锁 Claude,Codex 锁自家模型,各家原生 CLI 又各自为政。想跨 agent 接力,只能靠人肉做 context broker。
我也不是没考虑过让一个 agent 包打天下------但前面说过了,真正逼我多 agent 切换的不是好奇心,是每个 agent 的 harness 和模型都有自己的脾气,硬塞同一个干所有活,效率反而更低。再说一个现实问题:好模型的 token 收费很高。 顶配模型用来做 90% 的常规任务是浪费,只在它真正擅长的环节用,能省下来的成本远超工具切换的麻烦。
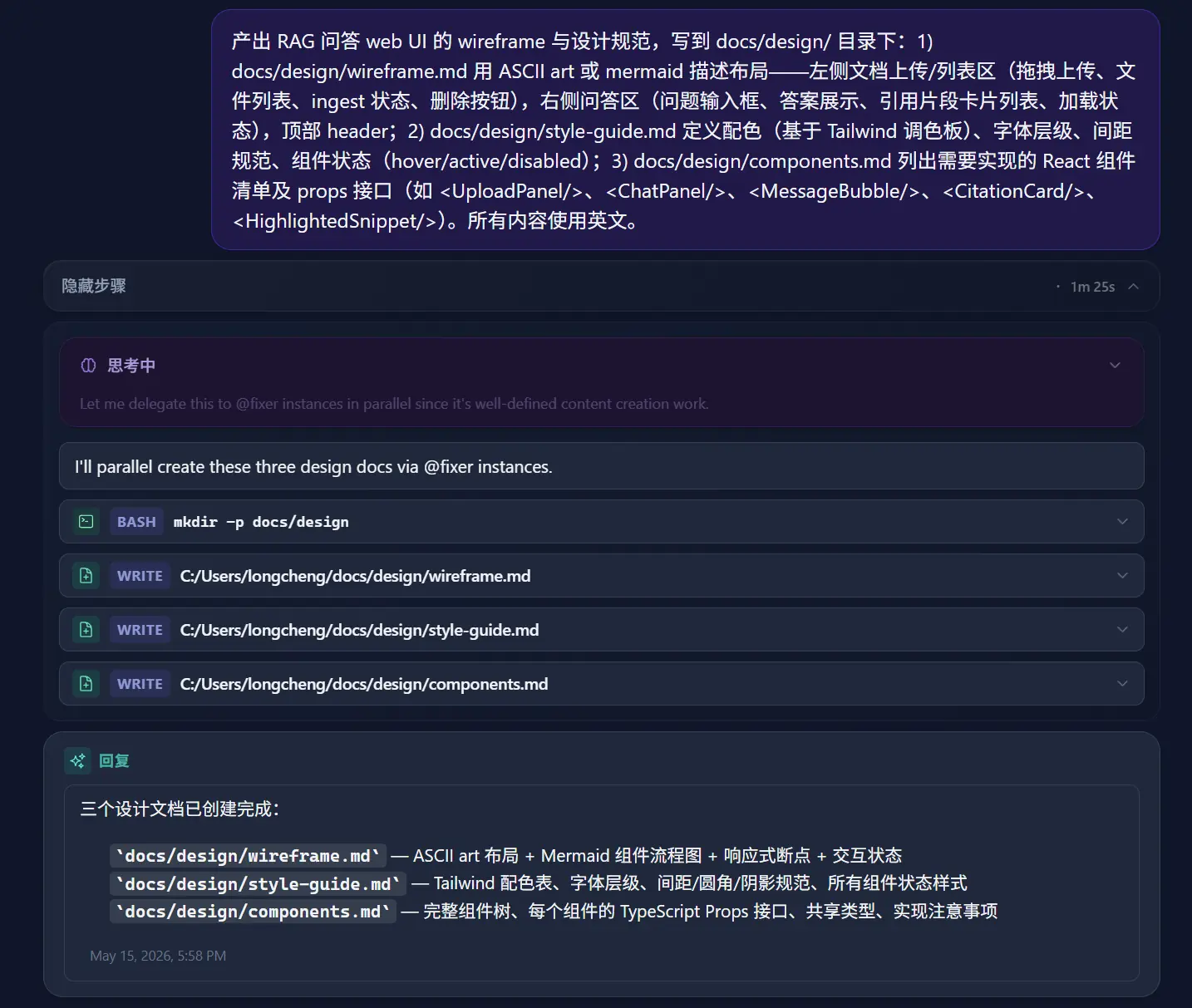
所以问题就变成了:能不能有个东西,把"哪个 agent 做什么"和"它们之间怎么共享上下文"这两件事接管下来,我只管定义任务? CodeMux 是我对这个问题做的回答。
把"用谁"和"做什么"拆开
CodeMux 的核心抽象其实很简单------它把角色 (role) 和引擎 (engine) 拆成了两个独立维度。
平时我们说"我用 Claude Code 做 plan", 这句话里其实捆了两件事:角色是"做 plan 的那个人", 引擎是"Claude Code"。但这两件事不应该耦合------做 plan 的角色今天可以是 Claude, 明天可以是 Codex, 后天 Gemini 出新版了也可以挂上去试试。
CodeMux 里有 5 个预定义角色:explorer(探索 codebase)、researcher(查资料)、reviewer(审查产出)、designer(出设计)、coder(写代码)。每个角色独立挂载一个引擎------同一个 explorer 角色,可以挂 Claude 也可以挂 Codex, 看你当前任务更需要哪种风格。
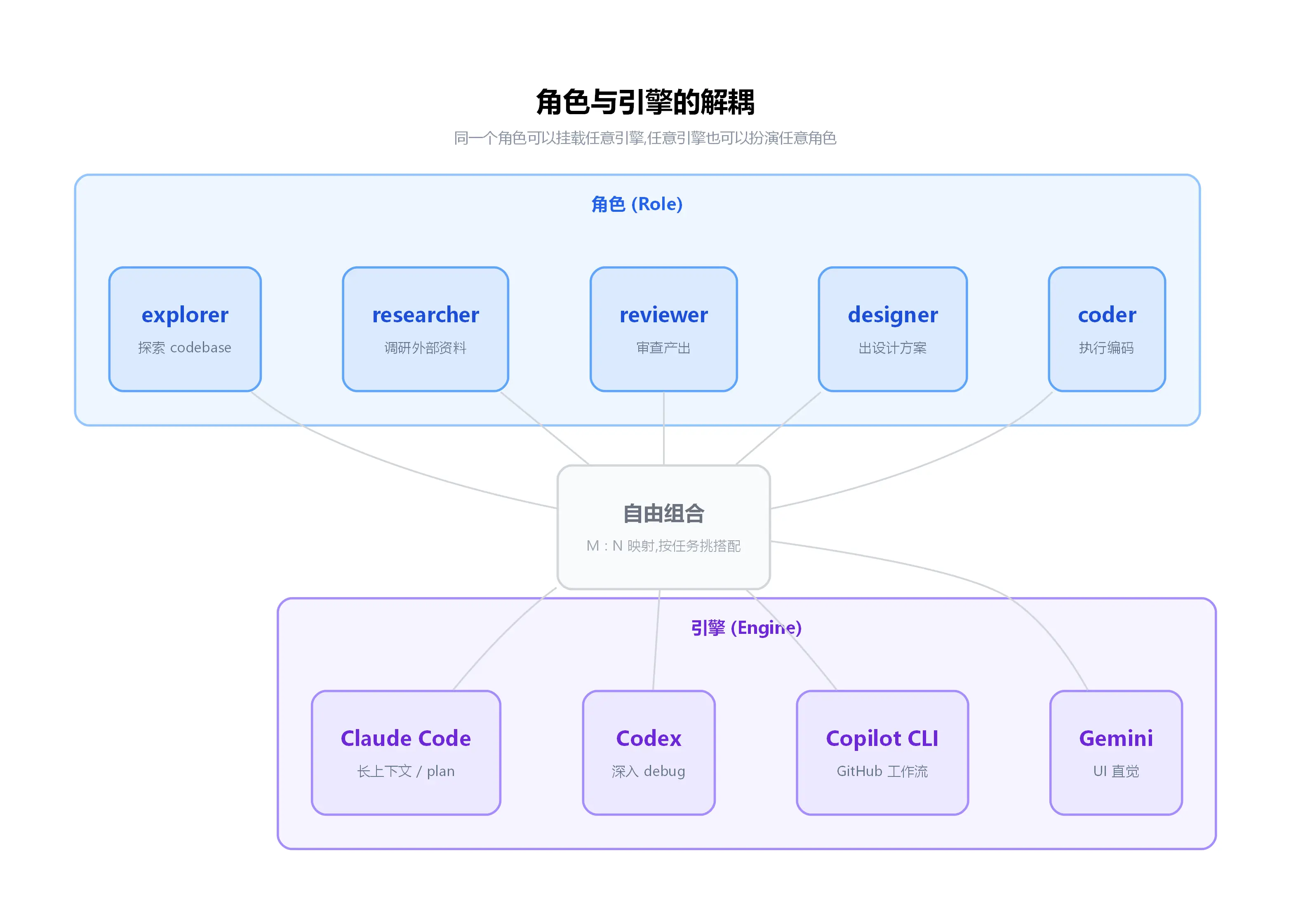
这种解耦带来的直接好处是搭配自由。我自己常用的一套配置是:
- explorer 挂 Claude Code, 负责吃透项目结构、给主 agent 喂 context
- coder 挂 Codex, 因为它写代码时对 plan 的执行度最稳
- reviewer 也挂 Codex, 跨视角看代码更容易发现问题
- designer 挂 OpenCode + Gemini, 出 UI 部分
但你完全可以反过来------让 Codex 做 explorer 因为它读代码细致,让 Claude 做 reviewer 因为它表达更结构化。配置存在 settings 里,跨任务复用,不用每次重新搭。
权限也是按角色分的。explorer 和 reviewer 默认 readonly------它们只该读,不该改。这不是靠 prompt 约束的,是 CodeMux 在调起子 agent 时直接通过 CLI 参数把 write 权限关掉。如果一条规则重要,就别交给 LLM 去自觉遵守。
为什么是 DAG, 不是一个长 prompt
光有角色还不够,真正让多 agent 协作跑起来的,是任务编排那一层。
最朴素的做法是这样:把整个需求扔给一个"主 agent", 让它自己决定先做什么后做什么、什么时候调谁。这种做法在 demo 里看着很厉害,实际跑起来问题很多------agent 容易在长流程里失焦、回头改前面已经做完的事、或者干脆陷入"再分析一轮看看"的死循环。
CodeMux 选了另一条路:主 agent 只做一次拆解,把任务拆成一张 DAG, 后续调度由系统接管。
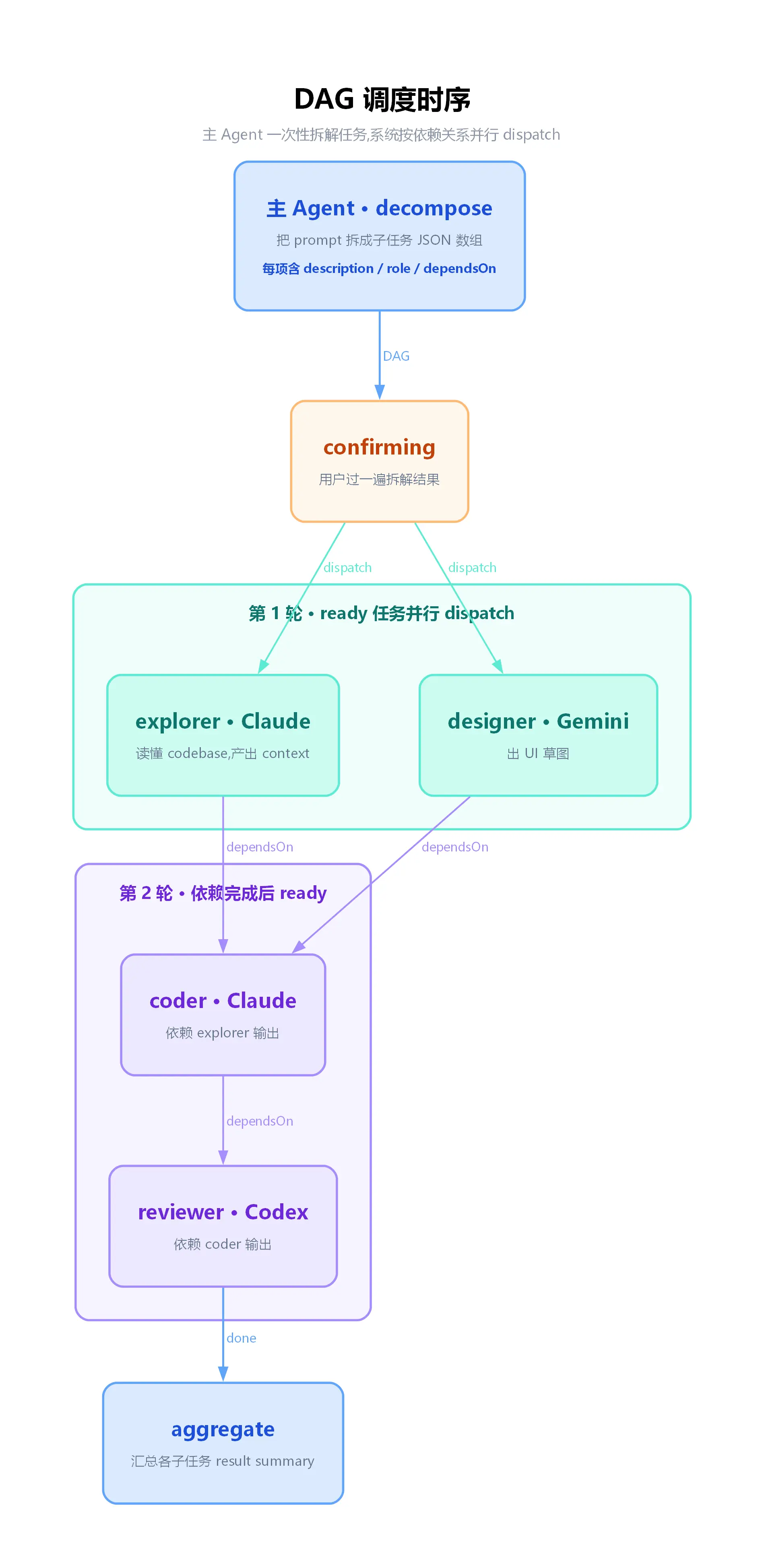
具体流程是这样:用户给一个 prompt, 主 agent 收到之后做的第一件事是 decomposeTask------它输出一个 JSON 数组,每一项是一个子任务,带 description、role(谁来做)、dependsOn(依赖哪些子任务)。这一步主 agent 必须先把整体上下文吃透,因为它需要判断"什么任务可以并行、什么必须串行、谁的输出是谁的输入"。
为什么是 DAG 不是一个长 prompt? 因为依赖关系本身就是图结构。 把它显式化,有几个直接的好处: 第一,ready 状态的子任务可以并行 dispatch 。系统每轮扫一遍所有 blocked 状态的子任务,把"依赖全部完成"的提到 pending 然后丢进执行队列。Claude 在做模块 A 的同时,Codex 可以同时做不依赖 A 的模块 B, 而不是傻傻地等。
第二,主 agent 不用记住整个流程的状态 。每个子任务跑完之后,把 result summary 写回 DAG, 系统拿这些 summary 去满足下一批子任务的依赖输入------主 agent 只需要在最后做一次 aggregate, 根本不需要在中途维护一个超长的"我做到哪一步了"的心智状态。
第三,子任务可以跑在隔离的 git worktree 里。CodeMux 自动给每次编排开一个 worktree, 每个 coder 子任务在独立目录里改文件,跑完之后再统一合并回主分支。这样并行的 coder 之间不会互相覆盖,主仓库也不会在编排过程中被半成品代码污染。
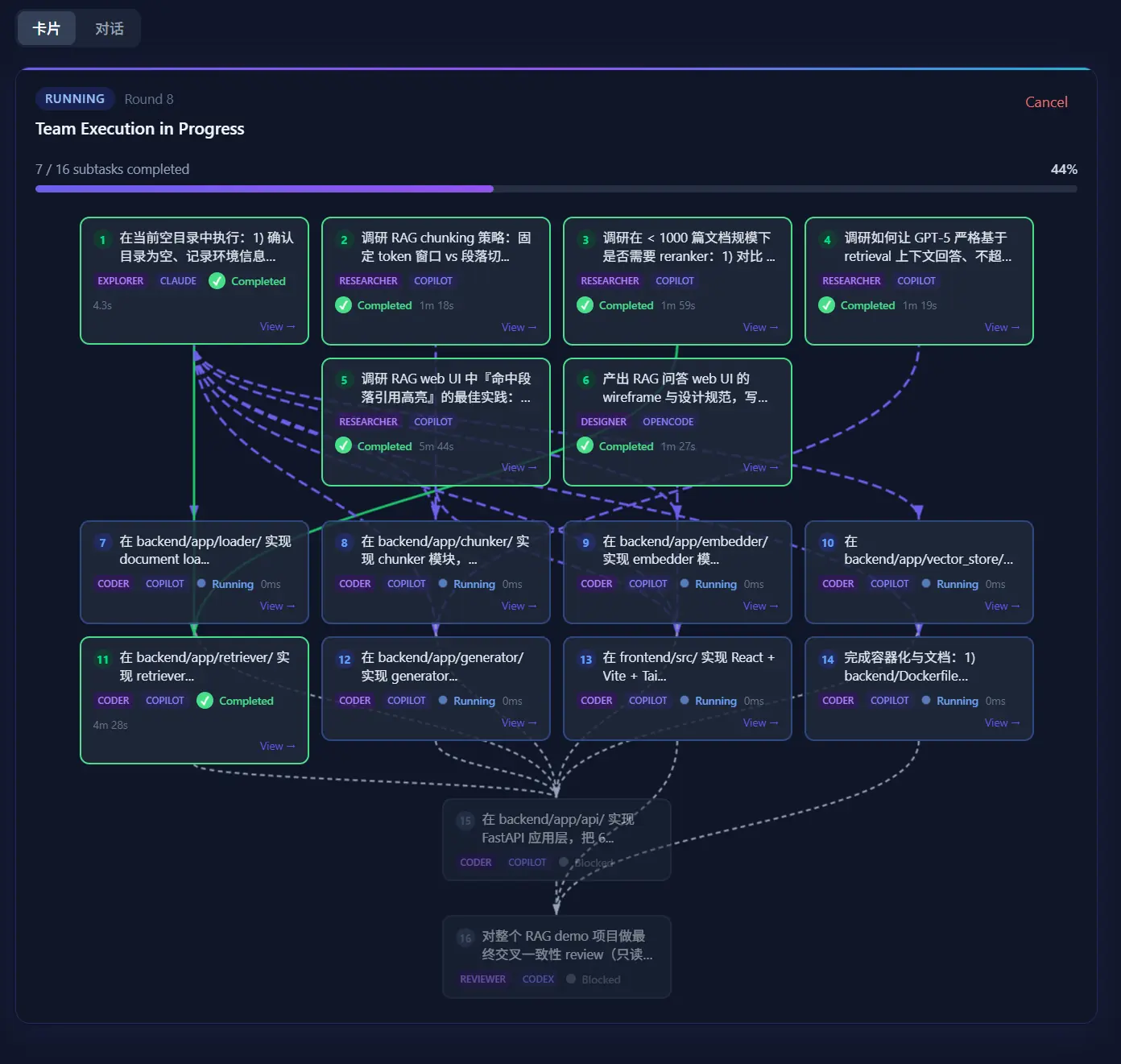
我承认这套机制不是没有局限------拆解质量高度依赖主 agent 的能力,主 agent 拆错了后面就全跑偏。所以我习惯在主 agent 拆完之后会有一个 confirming 状态,让我自己过一遍 subtask 列表,改掉不合理的拆分再 dispatch。这一步在自动化和可控性之间找了个平衡------纯人工太累,纯自动信不过。
单 Agent 用着也省心
写到这可能有人觉得 CodeMux 是个重型编排工具,只有跑大任务才划算。其实不是------它日常作为单 agent 客户端用也挺顺手的, 这部分我反而花了更多精力打磨。
最实在的一点是多引擎共存于同一个窗口。我不需要在四个 terminal 之间 alt-tab,sidebar 里就能看到 Claude / Codex / Copilot / Gemini 各自的 session 列表,点一下就切过去。每个 engine 的 session 历史独立保存,切回来还在原地。
第二是完整的思维链可见。Claude Code 的 reasoning、tool call 的 input/output、plan 模式下的步骤树、permission 请求的上下文------这些底层 CLI 通常折叠掉或者只显示一行的内容,在 CodeMux 里都展开成可读的格式。我经常在 agent 走错的时候靠这层可见性回溯哪一步开始判断错了,这件事在原生 CLI 里几乎做不到。
第三是跨设备访问。CodeMux 内置了 Cloudflare Tunnel 支持,你可以让在家里的 Mac 跑 agent, 在外面用手机或 iPad 直接访问同一个 session 继续对话。出门坐地铁时,我经常用手机看 agent 跑长任务的进度、回复 permission 请求、或者发个新指令。这个能力对"我希望让 agent 在我不在的时候自己跑"的场景特别重要。
第四是外部消息渠道。CodeMux 支持把 agent 接到飞书 / Telegram / Teams 这些 IM 上------agent 完成长任务之后会主动通知你,你也可以在 IM 里直接给它发新指令。我把它当成一种"低成本远程工位", 不需要随时盯着窗口。
现在跑成什么样
需要先做个区分。单 agent 那部分用着已经相当完善了------多引擎共存、完整思维链可见、permission 请求、skill 调用,全部跟着各家原生 CLI 走,没有阉割也没有再包一层。装上 CodeMux 之后,我日常大部分时间都跑在这一层,再也不需要为了换 agent 而在四个只支持单一引擎的客户端之间来回切换。这部分体验我打磨了挺久,可以稳定接管日常 coding。
orchestration 是另一回事------多 agent DAG 编排是最近才构思出来的架构,还比较粗糙。它能跑,我自己每天也会用,但跑得顺的场景目前比较窄。
跑得比较好的场景是有清晰边界的中等复杂度任务。比如"把这个组件的状态管理从 Context 迁移到 Zustand, 顺便补上单元测试", 这种任务拆成 3-5 个子任务、有明确依赖、最后能合并验证,DAG 调度的优势能体现出来。我最近一周用 CodeMux 做的事大概就在这个尺度------一个引擎适配器的重构、一次跨语言的字符串国际化、几个 bug 的定位和修复。
跑得不太好的场景集中在 orchestration 这一层: 任务边界模糊的探索性需求。"帮我看看这个项目能不能加个 X 功能"这种问题,主 agent 拆出来的子任务质量经常飘忽------有时候拆得过细,有时候漏掉关键步骤。这类需求我现在还是直接用单 engine 模式手动迭代,等有了清晰方向再切到编排模式。
跨 agent 风格融合。 不同 agent 写代码的风格差异不小------同一个 codebase 里 Claude 写的部分和 Codex 写的部分,过几周回头看能一眼分辨。这件事 reviewer 角色可以缓解一些,但没彻底解决。
编排嵌套。 现在子任务之间不能再开新的编排,一层 DAG 就是一层。我有几个场景想要"子任务自己再 fan out 出一组并行任务", 但暂时只能在 prompt 里手动展开,这个之后想做。
总的来说,CodeMux 不是一个"装上就能让 AI 替你写代码"的工具------它更像是一个让你能更精细地组织 AI 工作流的客户端, 前提是你已经知道自己想要什么,知道哪个 agent 擅长什么。
结语
最近一直在想一个类比------之前写代码,程序员要自己装编辑器、配各种语言扩展、串好编译器和调试器、维护自己的快捷键集合。那个年代的"开发体验"很大程度上是手动凑出来的,每个人的工位都长得不一样。后来 IDE 厂商把这些抽象成了"扩展商店"和默认配置,大多数人就不再为基础设施操心了。
agent 时代的我们,正处在那个"手动凑"的阶段。每个开发者在自己机器上手动协调几个 agent CLI、手动复制 plan、手动管理 context、手动决定什么时候用谁。CodeMux 是我个人的一次尝试,看能不能把这件事抽象成一个客户端------但我并不觉得它就是终态。终态应该是更自然的:也许 agent 之间通过某种标准协议直接互通,也许操作系统级别会出现一个 agent runtime, 也许我们今天讨论的这些角色 / 编排概念,最后会被一个完全不同的范式取代。
但在那之前,我们这些每天和多个 agent 打交道的开发者,还是得有个东西把它们组织起来。如果你也在为"切换 agent 时丢上下文"、"想用最对味的 agent 干每件事但操作成本太高"这类问题烦恼,可以来 github.com/realDuang/c... 看看这个项目------开源、跨平台、windows/mac/linux全平台支持,欢迎尝鲜。
agent 不会替我们思考。能做的只是把当下的工具组织得更顺手一点,让我们多省下一点心智去想真正值得想的问题。