大O表示法
O(1) < O(log2 n) < O(n) < O(nlog2 n) < O(n^2) < O(2^n) < O(n!) < O(n^n)
加法规则:多项相加,保留最高阶,系数化为1
乘法规则:多项相乘都保留,系数1
T(n)=n^2 * n^3=n^5=O(n^5)
时间复杂度与空间复杂度
时间复杂度:看循环次数
空间复杂度:看数组维度
空间复杂度不考虑输入的,只考虑算法中开辟的空间
渐进符号
1.渐进上界 O(n) >= 时间复杂度估算结果
2.渐进下界
3.渐进紧致界
递归式时间
递归次数*每次递归时间复杂度
递归式主方法


线性结构与线性表定义
顺序存储:数组,可以随机存取,但插入删除复杂
插入时间复杂度: 最好O(1)
最坏O(n)
平均O(n)
删除时间复杂度: 最好O(1)
最坏O(n)
平均O(n)
查找时间复杂度: 最好O(1)
最坏O(1)
平均O(1)
链式存储:
数据域+指针域
头结点:第0个结点
带头结点插入时间复杂度:最好O(1)
最坏O(n)
平均O(n)
不带头结点同上
删除时间复杂度: 最好O(1)
最坏O(n)
平均O(n)
查找时间复杂度: 最好O(1)
最坏O(n)
平均O(n)
通过元素在存储空间中的相对位置表示数据元素间的逻辑关系,是顺序存储的特点
栈
进行插入与删除的一端是栈顶
另一端是栈底
1.顺序存储
2.链式存储
栈用来实现递归
队列
插入元素的一端:队尾
删除元素:队头
循环队列
(front+1)%N
(rear+1)%N
1.已知队尾Q.rear,容量M,队列长度Q.len,求队头:(Q.rear-Q.len+1+M)%M
2.已知队头Q.front,容量M,队列长度Q.len,求队尾:(Q.front+Q.len-1+M)%M
3.求长度:(Q.rear-Q.front+M)%M
循环队列优点:入队与出队都不需要移动队列中其他元素
若问题规模n确定,则顺序存储比链式存储效率更高利用两个栈可以模拟一个队列
但是两个队列无法模拟栈!
入栈与出栈序列关系可以为1:n(有多种出栈顺序)
入队与出队关系只能为1:1(先进先出,没有别的顺序)
串
串是特殊的线性结构
串的长度:串中所含字符的个数(包括空串)
匹配时间复杂度:最好O(m)
最坏O(n*m)
平均O(n+m)
next求值
next1=0
next2=1
nexti=从1~i-1串中最长相等前后缀长度+1
数组
求二位数组元素位置时,区分按行存储,按列存储
对称矩阵
三对角矩阵
稀疏矩阵
三元组顺序表和十字链表是对稀疏矩阵进行压缩存储的方式
注意下标从0还是1开始
这类题画图求规律,
用代入法最简洁
树
结点的度:孩子的个数
结点层次:根是第一层
数的高度:深度
1.树中节点总数=树中所有结点度数之和+1(1是根)
2.度为m的树中第i层至多有m^(i-1)个结点
3.高度为h的m次树至多有(m^h-1)/(m-1)个结点(等比数列求和)
4.具有n个结点、度为m的树的最小高度为logm(n(m-1)+1)
3.和4.互逆
二叉树
1.第i层最多有2^(i-1)个结点
2.高度为h的二叉树最多2^h-1个结点
3.度为0的结点=度为2的结点数+1
满二叉树:全满
完全二叉树:叶子节点左节点
完全二叉树适合顺序存储
i的左孩子:2i;
右孩子:2i+1
二叉树遍历
1.先序遍历:根左右
2.中序遍历:左根右
3.后序遍历:左右根
先根据中序遍历找到"左" "右"
先序+中序
后序+中序
层序+中序
一步步缩小中序里面的根
构造二叉树时必须有中序遍历
平衡二叉树
二叉树中任意一个结点的左右子树高度差<=1
二叉排序树
根节点>左子树所有的
根节点<右子树所有的
中序遍历得到一个有序数列
最优二叉树(哈夫曼树)
WPL=路径长度*叶子结点权值
每个结点的度只能为0/2
路径长度:分支个数
构造:1.排序 2.每次选最小的两个合并
每次挑两个最小权值合并,直到只剩一个根节点,权值大的节点尽量靠近根(路径短)
哈夫曼编码
左0右1
压缩比=(等长编码-哈夫曼编码)/等长编码
等长编码=x*权值(2^x=字母个数)
哈夫曼编码=哈夫曼长度*权值
图
有向图a->b <a,b>
无向图a-b (a,b)
完全图:每个顶点与其他顶点间都有边
含有n个顶点的无向完全图有n(n-1)/2条边
含有n个顶点的有向完全图有n(n-1)条边
顶点的度:边的数目
边数=总度数/2
连通图
在无向图中,a-b有路径
最少n-1条
最多n(n-1)/2
强连通图
在有向图中a->b且b->a都存在
最少n
最多n(n-1)
邻接矩阵
无向图的邻接矩阵是对称的
邻接链表
a->第一条边b地址->第二条边c地址 (a-c a-b两条边)
稠密图
边数多,用邻接矩阵
稀疏图
边数少,用邻接表
网
边或弧带权值的图称为网
深度优先遍历(栈)
实质是对某个点查找其邻接点的过程
邻接矩阵时间复杂度:O(n^2)
邻接表时间复杂度:O(n+e) e是边数
广度优先搜索(队列)
图的遍历是从任意一个顶点出发
拓扑排序
(1)找到入度为0的点
(2)删除点相关的弧度以及该点
(3)重复
在有向无环图的拓扑排序中,a在b之前则:
可能存在a->b的路径
一定不存在b->a的路径
查找
静态查找:顺序查找,折半查找,分块查找
动态查找(插入与删除):二叉排序树,二叉平衡树,B_树,哈希表
1.顺序查找
平均查找长度:(n+1)*n/2*1/n = (1+n)/2
2.折半查找
平均查找长度:log2 (n+1)
哈希表
表长m,模m取余,出现相同余数加d再取余,d为增量
d=1,2,3...线性探测法(第一次冲突取1,第二次取2,不同的数重新从1开始递增)
d=1,-1,2^2,-2^2,3^2,-3^2.........(1,-1,4,-4,9,-9...)
装填因子a是装入记录与表长之比
堆
小顶堆
大顶堆
排序
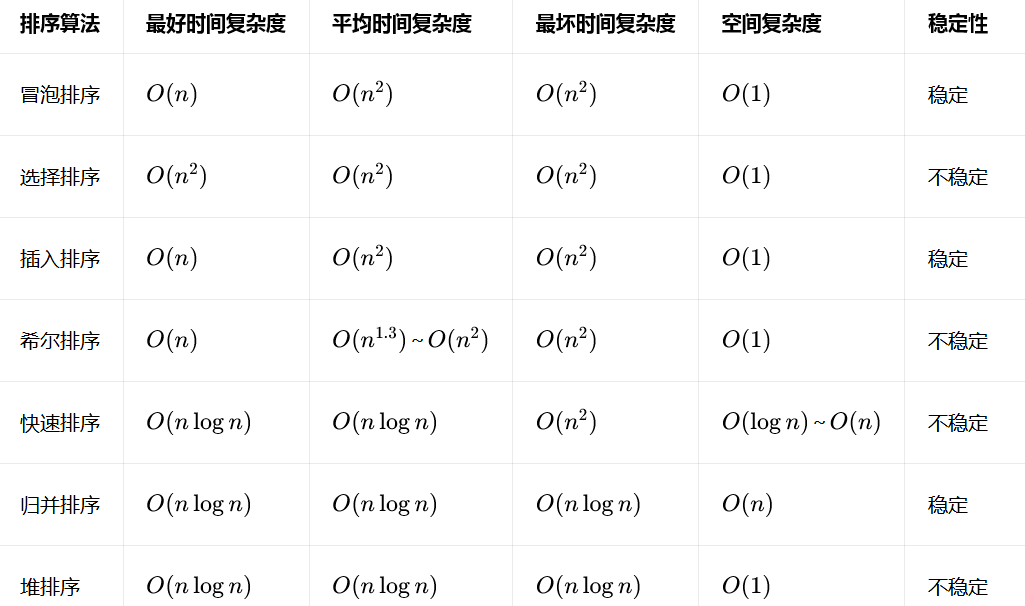
插入排序
插入时和已经排好的比较,从后往前倒着比
基本有序适合于插入排序
计数排序:适合只有0-9的数字
简单选择排序
每一次找到最小的元素,第i次找到第i小的元素
堆排序
每一次找元素正确位置
两个元素相同,插入排序稳定,可以保证两元素相对位置不变
简单选择排序不稳定,两元素相对位置改变
冒泡排序
交换相邻两个元素按照正确大小排序
快速排序
轴值,交换,轴值左侧小于它,右侧大于它
基本有序(顺或逆)时最坏情况,O(n^2)
平均n^logn
不稳定
归并排序
稳定
1.插入排序:每插入一个数字从后往前进行比较
2.归并排序:左右第一个元素分别设置i,j,进行比较后挪动