1. 引言
内存函数是计算机科学中连接底层硬件与高级编程的关键桥梁。它们直接操作内存字节,是构建高效、可靠软件的基础。无论是操作系统内核、数据库系统,还是高性能网络服务,都离不开对内存函数的深刻理解和娴熟运用。本文旨在为有一定编程基础的开发者提供一个系统性的学习路径,从基本概念入手,逐步深入到原理、安全、性能优化及现代语言中的实践,帮助读者全面掌握内存函数这一核心工具。
2. 内存函数的基本概念
什么是内存函数?
内存函数是指那些直接对内存区域(通常以字节为单位)进行操作的函数。它们不关心内存中数据的语义(如整数、字符串或结构体),只负责字节的复制、比较、设置和移动等底层任务。在C/C++等系统编程语言中,这类函数通常定义在 <string.h> 或 <cstring> 头文件中。重点是这些系列的内存函数通常是以字节为单位进行对数据的复制,粘贴和设置,而且也不关心这些数据是以什么形式展现(例如整型,浮点型,字符型数据),也就是说无论是什么类型的数据,mem系列的函数都能对其进行访问操作,比str系列的函数的适用性更广泛。
内存函数与普通函数的本质区别
普通函数(如字符串处理函数 strcpy, strcmp)通常以 \0 作为结束符,操作的是具有特定语义的数据。而内存函数(如 memcpy, memcmp)则基于指定的字节长度进行操作,适用于任何类型的数据块,包括结构体、数组和原始二进制数据。
常见的内存函数分类
- 复制类 :
memcpy,memmove - 比较类 :
memcmp - 设置类 :
memset - 搜索类 :
memchr(在内存块中查找特定字节)
3. 标准库中的内存函数详解
3.1 memcpy - 内存复制
memcpy 用于将源内存区域的内容复制到目标内存区域。
c
void *memcpy(void *dest, const void *src, size_t n);- 参数说明 :
dest是目标指针,src是源指针,n是要复制的字节数。 - 使用场景与注意事项 :适用于源和目标内存区域不重叠 的情况。如果区域重叠,行为是未定义的,此时应使用
memmove。 - 特别注意 :
n是以字节为单位的,指定了要访问的字节数,一个数据的类型大小是不一样的,比如一个字符型数据的大小是1个字节,而一个整型数据的大小是4个字节,这点需要想清楚。 - 经典代码示例:
c
#include <stdio.h>
#include <string.h>
int main()
{
char source1[] = "hello world";
char dest1[20] = "0";
memcpy(dest1, source1, sizeof(source1));
printf("copied string:%s \n", dest1);
int source2[] = { 1,2,3,4,5 };
int dest2[5] = { 0 };
memcpy(dest2, source2, sizeof(source2));
for (int i = 0;i < 5;i++)
{
printf("%d ",dest2[i]);
}
return 0;
}这个代码说明了memcpy可以实现对任意类型数据的复制操作。
3.2 memmove - 内存移动
memmove 与 memcpy 功能类似,但能正确处理源和目标内存区域重叠的情况。
c
void *memmove(void *dest, const void *src, size_t n);- 与 memcpy 的区别 :
memmove会先检查重叠区域。如果dest在src之后且有重叠,它会从后向前复制以避免数据被覆盖。也就是说memmove可以处理dest与src之间重叠的情况。 - 适用场景分析:在缓冲区内部移动数据、实现队列或环形缓冲区时非常有用。
- 性能对比 :由于需要检查重叠,
memmove在非重叠情况下可能比memcpy稍慢,但差异通常很小,在安全优先的场景下推荐使用。 - memmove 代码的示例与模拟 :
c
int main()
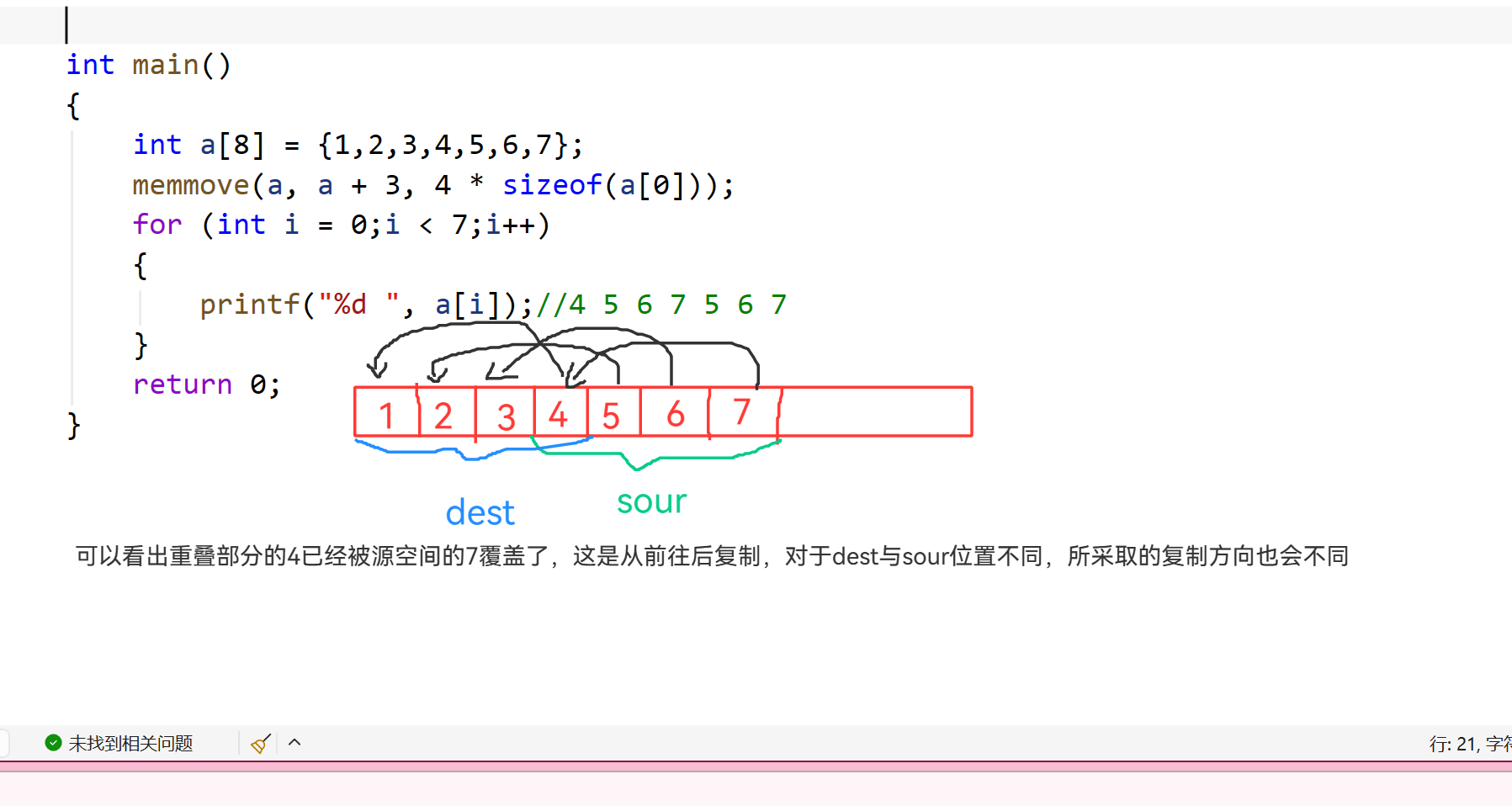
{
int a[8] = {1,2,3,4,5,6,7};
memmove(a, a + 3, 4 * sizeof(a[0]));
for (int i = 0;i < 7;i++)
{
printf("%d ", a[i]);//4 5 6 7 5 6 7
}
return 0;
}
c
void* my_memmove(void* dest, void* sour, size_t n)
{
assert(dest && sour);
char* d = (char*)dest;
char* s = (char*)sour;
//判断d和s的相对位置
if (d <= s)
{
//从前往后复制
for (int i = 0;i < n;i++)
{
d[i] = s[i];
}
}
else
{
//从后往前复制
while (n--)
{
*(d + n) = *(s + n);
}
}
return dest;
}如果d<=s,复制就从前往后复制,如果d>s,复制就从后往前复制,这样就能避免了源空间数据的覆盖
3.3 memset - 内存设置
memset 将内存区域的前 n 个字节设置为特定的值(通常用于清零或填充)。
c
void *memset(void *s, int c, size_t n);- 初始化内存区域:常用于将数组或结构体初始化为0。
- 常见用法与陷阱:
c
int arr[100];
memset(arr, 0, sizeof(arr)); // 正确:将整型数组清零
char buffer[1024];
memset(buffer, 'A', 100); // 正确:将前100字节填充为'A'
// 陷阱:用于初始化非字符类型为特定值可能不符合预期
int val[10];
memset(val, 1, sizeof(val)); // 错误:不会将每个int设为1,而是每个字节设为0x01关于第三个例子,整型数据是由4个字节构成的,如果按例子所示填充数组,就意味着每个整型数据所构成的字节都填充为0x01010101(15),明显不是1
- 模拟实现:
c
void* my_memset(void* dst, int val, size_t n)
{
assert(dst);
char* d = (char*)dst;
char v = (char)val;
while (n--)
{
*d++ = val;
}
return dst;
}3.4 memcmp - 内存比较
memcmp 按字节比较两块内存区域的内容。
c
int memcmp(const void *s1, const void *s2, size_t n);- 按字节比较的工作原理 :从两个指针开始,逐字节比较,返回第一个不匹配字节的差值(
s1 - s2)。如果所有n个字节都相同,则返回0。 - 在数据结构比较中的应用:可用于比较结构体、网络数据包或任何二进制数据块。
- 前两个指针是待比较的指针所指向的内存空间,返回值为所比较的第一个不同字节的差值(*s1-*s2)
c
struct Point { int x; int y; };
struct Point p1 = {1, 2};
struct Point p2 = {1, 2};
if (memcmp(&p1, &p2, sizeof(struct Point)) == 0) {
printf("Points are equal.\n");
}
// 注意:如果结构体包含填充字节,memcmp可能因填充内容不同而误判。- 模拟实现:
c
int my_memcmp(const void* buffer1,const void*buffer2,size_t n)
{
const char* b1 = (const char*)buffer1;
const char* b2 = (const char*)buffer2;
while (n--)
{
if (*b1 != *b2)
{
int ret = (int)*b1 - *b2;
return ret;
}
b1++;
b2++;
}
}4. 内存函数的底层实现原理
汇编层面的优化策略
编译器(如GCC、Clang)和标准库(如glibc)会针对不同CPU架构(x86, ARM)提供高度优化的汇编实现。这些实现可能使用:
- 字长操作:一次复制一个机器字(如4或8字节),而非单字节。
- 循环展开:减少循环开销。
- 对齐访问:确保内存地址对齐,以利用CPU的快速对齐加载/存储指令。
现代 CPU 的 SIMD 指令集应用
对于大块内存操作,现代库会使用SIMD(单指令多数据)指令集:
- x86 的 SSE/AVX:一次可处理16、32甚至64字节。
- ARM 的 NEON :提供类似的并行处理能力。
这使得memcpy和memset的性能得到数量级提升。
编译器如何优化内存函数
编译器在遇到小尺寸的、编译时常量的内存操作时,可能会直接将其内联展开为一系列寄存器操作,完全避免函数调用开销。
5. 内存函数的安全性问题
缓冲区溢出漏洞
这是内存函数最常见的安全问题。如果目标缓冲区大小小于复制的字节数 n,就会发生缓冲区溢出,可能导致程序崩溃、数据损坏或被攻击者利用执行任意代码。
c
char small_buf[10];
char large_input[100] = "This is a very long string...";
memcpy(small_buf, large_input, strlen(large_input)); // 缓冲区溢出!使用不当导致的未定义行为
- 使用未初始化的指针作为源或目标。
- 传递的
n参数超过实际分配的内存大小。 - 源和目标指针类型不兼容(违反严格别名规则)。
安全编程实践建议
- 始终进行边界检查 :在调用
memcpy,memmove,memset前,确保目标缓冲区足够大。 - 使用安全函数变体 :某些平台提供
memcpy_s,memset_s等带长度检查的函数。 - 优先使用高级抽象 :在C++中,优先使用
std::copy,std::fill等算法,它们能提供类型安全并减少错误。 - 利用静态分析工具 :使用编译器警告(如
-Wall -Wextra)和工具(如Clang Static Analyzer)来捕捉潜在问题。
6. 高性能内存函数设计
内存对齐的重要性
CPU访问对齐的内存地址(如4字节对齐的地址是4的倍数)速度更快。高性能的内存函数实现会:
- 处理开头未对齐的字节(逐字节复制)。
- 对中间对齐的主体部分进行字长或SIMD操作。
- 处理结尾未对齐的字节。
分块处理与流水线优化
对于极大的内存块,可以将其分成多个子块,利用CPU的多级缓存和预取机制,实现类似流水线的并行处理,最大化内存带宽利用率。
多线程环境下的内存操作
在多线程中并发进行大内存操作时,需要注意:
- 避免虚假共享:确保不同线程操作的内存区域位于不同的缓存行(通常64字节)。
- 使用线程局部存储:如果每个线程都有独立的内存操作任务,使用线程局部缓冲区可以减少锁竞争。
7. 实际应用案例
7.1 数据结构实现
自定义内存分配器
内存池、对象池等自定义分配器大量使用 memcpy 和 memset 来管理内存块。例如,在分配新对象时,使用 memset 清零;在重新分配或移动对象时,使用 memmove。
序列化与反序列化
将结构体序列化为字节流通过网络发送,或从字节流反序列化回结构体时,memcpy 是最高效的方式。
c
struct Packet {
uint32_t id;
uint32_t length;
char data[1024];
};
// 序列化
char buffer[sizeof(struct Packet)];
memcpy(buffer, &packet, sizeof(struct Packet));
// 发送 buffer ...
// 反序列化
struct Packet recv_packet;
memcpy(&recv_packet, buffer, sizeof(struct Packet));7.2 网络编程
协议缓冲区处理
解析网络协议(如TCP/IP包头)时,经常需要将接收到的原始字节流复制到结构体中,或比较特定的协议字段。
零拷贝技术
在高性能网络框架(如DPDK, Netty)中,通过 memcpy 在不同缓冲区之间移动数据是主要的性能开销之一。零拷贝技术(如 sendfile, splice)旨在减少或消除这种复制,但对于需要在用户空间处理的数据,优化的 memcpy 仍是核心。
7.3 图形处理
图像缓冲区操作
图像处理中经常需要复制、填充或比较图像数据块(像素数组)。例如,实现一个画布滚动效果可能需要使用 memmove。
GPU 内存传输优化
在GPU计算中,主机(CPU)内存和设备(GPU)内存之间的数据传输(通过PCIe总线)是瓶颈。优化的 memcpy 实现(如CUDA的 cudaMemcpy)会使用DMA(直接内存访问)等技术来最大化传输带宽。
8. 现代编程语言中的内存函数
C/C++ 标准库演进
C11/C++11引入了边界检查函数(如 memcpy_s),并持续优化底层实现。C++的 <algorithm> 库提供了类型安全的替代品(如 std::copy_n)。
Rust 的安全内存操作
Rust通过所有权系统在编译期防止了大部分内存错误。它提供了 std::ptr::copy (类似 memcpy)、std::ptr::write_bytes (类似 memset) 等不安全函数,但要求它们在 unsafe 块中使用,以明确标记潜在风险。
Go 的切片与内存管理
Go语言的切片(slice)底层是数组,其 copy 内置函数用于切片间的复制,类似于安全的 memcpy。Go的运行时和垃圾回收器管理内存,开发者通常无需直接调用底层内存函数。
Python 的 memoryview 与缓冲区协议
Python的 memoryview 对象允许在不复制数据的情况下访问其他对象(如 bytes, bytearray, array.array)的内存。bytearray 的某些方法(如 replace)在底层可能使用类似 memmove 的优化。
9. 调试与性能分析
使用 Valgrind 检测内存错误
Valgrind的Memcheck工具可以检测:
- 使用未初始化的内存(
memset未正确初始化)。 - 内存泄漏。
- 非法读写(缓冲区溢出)。
性能 profiling 工具
perf(Linux) :可以分析memcpy等函数的热点及缓存命中率。- Intel VTune:深入分析内存操作的瓶颈,如内存带宽、延迟等。
- 简单计时:对于自定义的内存函数,可以使用高精度计时器进行基准测试。
常见性能瓶颈识别
- 缓存未命中:随机访问大内存块导致缓存效率低下。
- 分支预测失败:在内存函数内部循环中的条件判断(如处理重叠)可能导致性能下降。
- 内存带宽限制:达到系统内存带宽上限后,优化将收效甚微。
10. 总结与展望
内存函数的核心价值总结
内存函数是系统编程的基石,它们提供了直接、高效操作内存的原语。掌握它们意味着能写出更高效、更可控的代码。理解其原理有助于规避安全陷阱,并能在必要时实现自定义的高性能版本。
未来发展趋势
- 硬件加速:随着计算存储一体化(CIM)和专用内存操作指令的出现,内存函数的性能有望进一步提升。
- 语言级安全:像Rust这样的语言正在推动内存安全成为默认选项,减少对不安全底层函数的依赖。
- 异构计算:在CPU、GPU、NPU等混合系统中,内存函数的实现需要兼顾不同设备的特性。
进一步学习资源推荐
- 书籍:《C陷阱与缺陷》、《深入理解计算机系统》。
- 标准文档 :C11/C++11标准中关于
<string.h>和<cstring>的规范。 - 源码学习:阅读 glibc、musl-libc 或 LLVM libcxx 中内存函数的实现。
- 实践项目 :尝试自己实现一个
memcpy或memmove,并与标准库版本进行性能对比。
通过本文的学习,希望您不仅能熟练使用标准库提供的内存函数,更能理解其背后的原理与权衡,从而在未来的开发中做出更明智的选择。