目录
[1 · 双向链表的结构](#1 · 双向链表的结构)
[2 · 双向链表的实现](#2 · 双向链表的实现)
[2 - 1 · 接口总览与结构定义](#2 - 1 · 接口总览与结构定义)
[2 - 2 · 初始化,销毁,打印](#2 - 2 · 初始化,销毁,打印)
[2 - 2 - 1 · 初始化](#2 - 2 - 1 · 初始化)
[2 - 2 - 2 · 销毁](#2 - 2 - 2 · 销毁)
[2 - 2 - 3 · 打印](#2 - 2 - 3 · 打印)
[2 - 2 - 4 · 测试](#2 - 2 - 4 · 测试)
[2 - 3 · 头插,头删](#2 - 3 · 头插,头删)
[2 - 3 - 1 · 头插](#2 - 3 - 1 · 头插)
[2 - 3 - 2 · 头删](#2 - 3 - 2 · 头删)
[2 - 3 - 3 · 测试](#2 - 3 - 3 · 测试)
[2 - 4 · 尾插,尾删](#2 - 4 · 尾插,尾删)
[2 - 4 - 1 · 尾插](#2 - 4 - 1 · 尾插)
[2 - 4 - 2 · 尾删](#2 - 4 - 2 · 尾删)
[2 - 4 - 3 · 测试](#2 - 4 - 3 · 测试)
[2 - 5 · 查找,指定位置之前插入,指定位置删除](#2 - 5 · 查找,指定位置之前插入,指定位置删除)
[2 - 5 - 1 · 查找](#2 - 5 - 1 · 查找)
[2 - 5 - 2 · 指定位置之前插入](#2 - 5 - 2 · 指定位置之前插入)
[2 - 5 - 3 · 指定位置删除](#2 - 5 - 3 · 指定位置删除)
[2 - 5 - 4 · 测试](#2 - 5 - 4 · 测试)
[3 · 顺序表和链表的区别](#3 · 顺序表和链表的区别)
[3 - 1 · 缓存利用率](#3 - 1 · 缓存利用率)
1 · 双向链表的结构
双向链表,全称带头 双向 循环链表,下面这张图便是:

带头链表的头结点,也就是上面的 head 结点,也称为哨兵位,哨兵位不存放任何有效元素,只是在这里放哨的。
借助哨兵位,我们可以实现接口一致,并且可以作为我们循环链表遍历的结束条件。
2 · 双向链表的实现
2 - 1 · 接口总览与结构定义
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int LTDatatype;
typedef struct ListNode
{
int val;
struct ListNode* prev;
struct ListNode* next;
}ListNode;
//初始化,创建哨兵位
ListNode* ListInit();
//销毁
void ListDestroy(ListNode* phead);
//打印
void ListPrint(ListNode* phead);
//头插
void ListPushFront(ListNode* phead, LTDatatype x);
//头删
void ListPopFront(ListNode* phead);
//尾插
void ListPushBack(ListNode* phead, LTDatatype x);
//尾删
void ListPopBack(ListNode* phead);
//查找
ListNode* ListFind(ListNode* phead, LTDatatype x);
//指定位置的前一个位置插入
void ListInsert(ListNode* pos, LTDatatype x);
//指定位置删除
void ListErase(ListNode* pos);这里用到了 typedef ,最上面的是方便进行存储类型的修改,在代码实现中用 LTDataType,到时候如果想要修改存储的类型,只需要改这里一处即可。
下面在结构体 这里的 typedef 是方便后续使用,可以少写 struct。
与单链表的结构定义同理,结构体中的成员变量的 struct 不能省略。
定义了两个结构体指针,一个指向前一个结点,一个指向后一个结点。
2 - 2 · 初始化,销毁,打印
2 - 2 - 1 · 初始化
代码如下:
#include "DoublyLinkedList.h"
ListNode* BuyNode(LTDatatype x)
{
ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));
if (newnode == NULL)
{
perror("malloc");
exit(1);
}
newnode->val = x;
newnode->next = newnode->prev = newnode;
return newnode;
}
ListNode* ListInit()
{
return BuyNode(-1);
}双向链表的初始化就是创建一个哨兵位。
我们写了一个 BuyNode ,方便初始化以及后续申请结点。
由于是双向循环链表,那么新的结点的 prev 与 next 指针是不能够置空的,因此在创建新结点的时候,将这两个指针都指向自己即可。
那么在初始化这个接口中,只需要调用BuyNode 即可,由于哨兵位不存放任何有效元素,我们在链表遍历访问时也不会访问哨兵位存放的元素,这里我们给哨兵位的元素存了 -1。
2 - 2 - 2 · 销毁
代码如下:
void ListDestroy(ListNode* phead)
{
assert(phead);
//遍历,销毁
ListNode* pcur = phead->next;
while (pcur != phead)
{
ListNode* next = pcur->next;
free(pcur);
pcur = next;
}
free(phead);
phead = NULL;
}进行遍历,然后一个个销毁。
定义一个 pcur 指向哨兵位的 next ,pcur 一步步往后走,当pcur走到了表尾,下一步就会循环回到哨兵位,而此时便说明遍历已完成。
在销毁时,如果直接free(pcur),此时会找不到下一个结点,因此要先将下一个结点的地址保存。
当遍历并销毁之后,最后将哨兵位销毁。
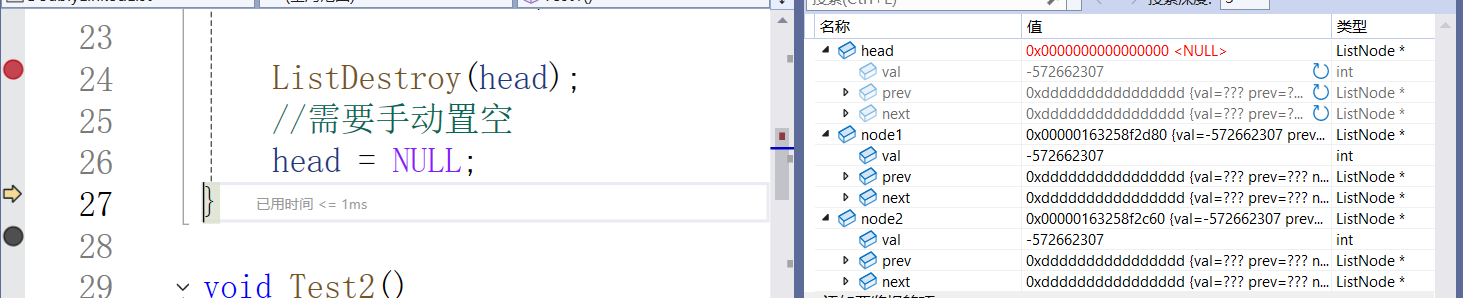
注意:为了保证接口一致,这里的形参phead是使用一级指针接收的,当初始化时,由于我们只能拿到哨兵位的地址,所以传参时传的也是一级指针,那么此时对形参的修改 是影响不到实参的。因此在调用完 ListDestroy 后,我们要手动将实参置空。
2 - 2 - 3 · 打印
代码如下:
void ListPrint(ListNode* phead)
{
ListNode* pcur = phead->next;
while (pcur != phead)
{
printf("%d -> ", pcur->val);
pcur = pcur->next;
}
printf("NULL\n");
}简单的遍历,打印。
为了更加直观,所以在打印的时候加上了箭头(->)。
哨兵位不存放任何有效元素,因此无需打印哨兵位的元素。
2 - 2 - 4 · 测试
我们对上面的功能测试一下:
#include "DoublyLinkedList.h"
ListNode* BuyNode(LTDatatype x);
void Test1()
{
ListNode* head = ListInit();
ListNode* node1 = BuyNode(1);
ListNode* node2 = BuyNode(2);
head->next = node1;
node1->next = node2;
node2->next = head;
head->prev = node2;
node2->prev = node1;
node1->prev = head;
ListPrint(head);
ListDestroy(head);
//需要手动置空
head = NULL;
}
int main()
{
Test1();
//Test2();
//Test3();
//Test4();
return 0;
}这里手动连接了这个双向链表。
运行一下:
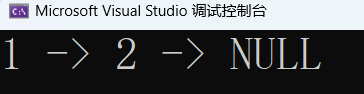
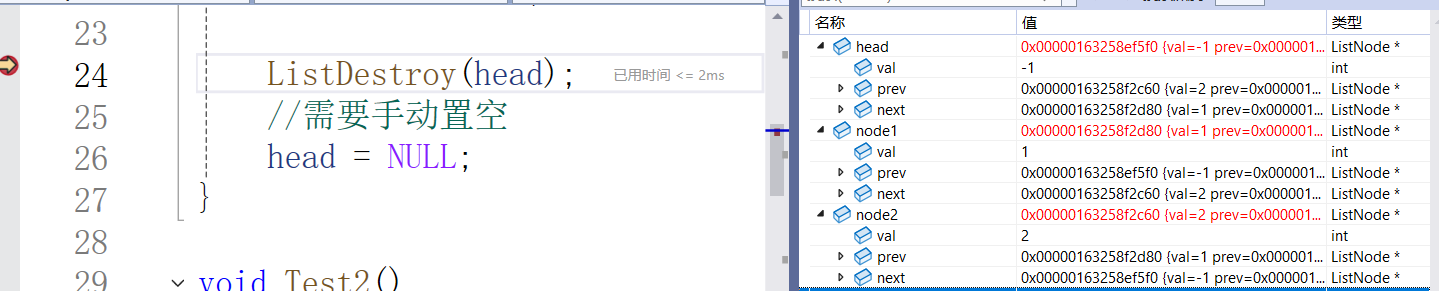
监视窗口看看销毁:
销毁前:
销毁后:
2 - 3 · 头插,头删
2 - 3 - 1 · 头插
头插就是在表头进行插入,有哨兵位的存在,表头结点是哨兵位的下一个结点。
代码如下:
void ListPushFront(ListNode* phead, LTDatatype x)
{
assert(phead);
ListNode* newnode = BuyNode(x);
newnode->next = phead->next;
newnode->prev = phead;
phead->next->prev = newnode;
phead->next = newnode;
}方便理解过程,我们画个图:
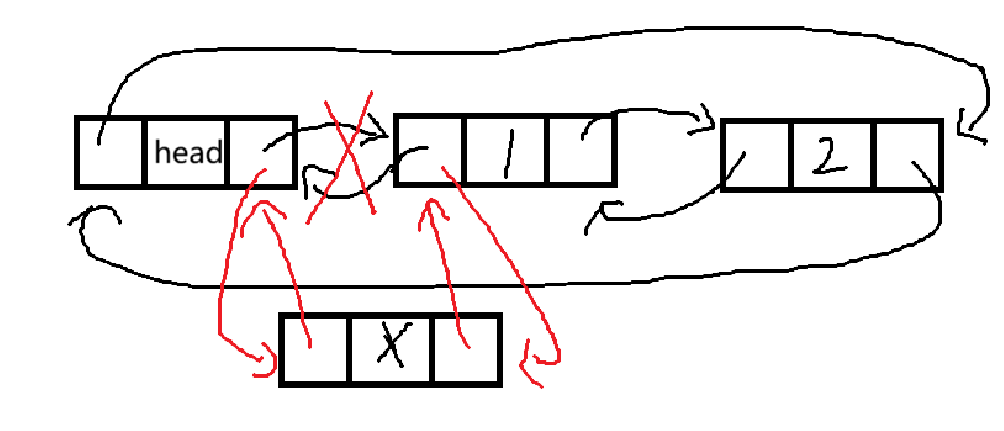
其中 红色的部分是我们应进行的操作
一共有四步需要操作,那么这其中就会有顺序问题。
为了确保不发生问题,我们先完成对将要被插入的 newnode 的指针域的修改,newnode 还未插入表中,先对 newnode 的指针域进行修改不会影响到原链表的顺序。
随后的两步其实可以随意,就算先改动了哨兵位的next指针 ,也可以通过newnode 的 next指针找到原来的哨兵位的next指向的结点。
对于空表的情况,此时哨兵位的 next指针和 prev指针都指向自身,我们写的代码也是能够应付这种情况的。
2 - 3 - 2 · 头删
头删就是对表头结点进行删除,有哨兵位的存在,表头结点是哨兵位的下一个结点。
代码如下:
void ListPopFront(ListNode* phead)
{
assert(phead);
//空表不能删
assert(phead->next != phead);
ListNode* delnode = phead->next;
//先改指针域
phead->next = delnode->next;
delnode->next->prev = phead;
free(delnode);
delnode = NULL;
}方便理解过程,我们画张图:
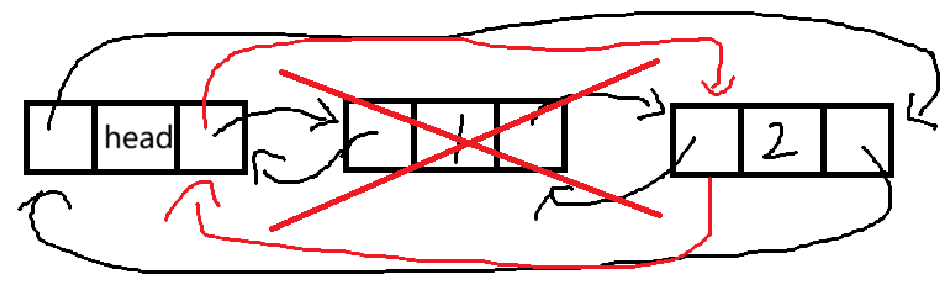
红色是我们需要进行的操作。
如果直接进行free,会导致很难找到被删除结点的下一个结点,所以最好先对指针域进行修改。
对于链表中只有一个结点的情况,我们写的代码也是可以应付的。
2 - 3 - 3 · 测试
我们对上面写的功能测试一下:
void Test2()
{
ListNode* head = ListInit();
ListPushFront(head, 1);
ListPrint(head);
ListPushFront(head, 2);
ListPrint(head);
ListPopFront(head);
ListPrint(head);
ListPopFront(head);
ListPrint(head);
/*ListPopFront(head);
ListPrint(head);*/
ListDestroy(head);
head = NULL;
}运行一下:

此时再进行一次头删便会触发assert断言。
2 - 4 · 尾插,尾删
2 - 4 - 1 · 尾插
尾插就是在表尾进行插入。
代码如下:
void ListPushBack(ListNode* phead, LTDatatype x)
{
assert(phead);
ListNode* newnode = BuyNode(x);
newnode->next = phead;
newnode->prev = phead->prev;
phead->prev->next = newnode;
phead->prev = newnode;
}方便理解过程,我们画张图:
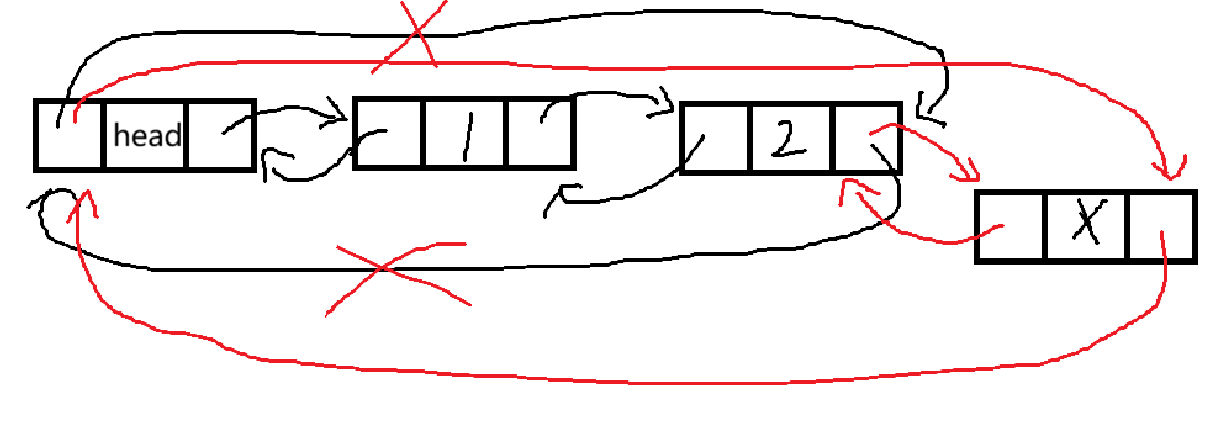
其中红色是我们要进行的操作。
与头插的操作类似,先改newnode 的指针域,随后入表,连接。
对于空表的情况,我们写的代码也是能够应付的。
2 - 4 - 2 · 尾删
尾删就是对表尾进行删除。
代码如下:
void ListPopBack(ListNode* phead)
{
assert(phead);
//空表不能删
assert(phead->next != phead);
ListNode* delnode = phead->prev;
phead->prev = delnode->prev;
delnode->prev->next = phead;
free(delnode);
delnode = NULL;
}方便理解过程,我们画个图:
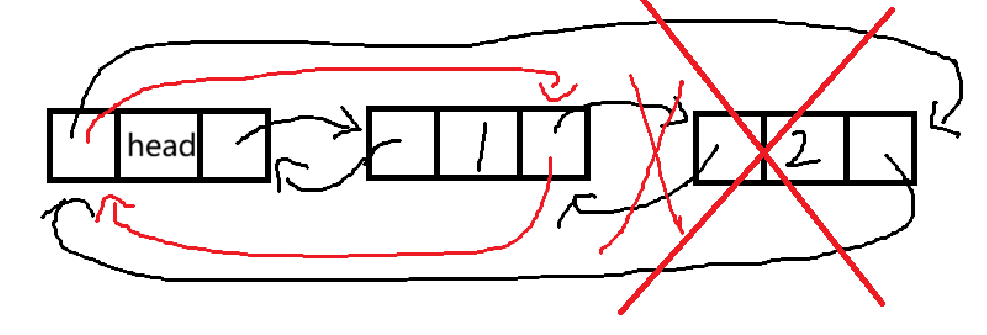
与头删操作类似,先修改指针域,再进行删除。
对于链表中只有一个结点的情况,我们写的代码也是可以应付的。
2 - 4 - 3 · 测试
测试一下:
void Test3()
{
ListNode* head = ListInit();
ListPushBack(head, 1);
ListPrint(head);
ListPushBack(head, 2);
ListPrint(head);
ListPopBack(head);
ListPrint(head);
ListPopBack(head);
ListPrint(head);
//ListPopBack(head);
//ListPrint(head);
ListDestroy(head);
head = NULL;
}运行一下:

此时再进行一次尾删就会触发assert断言。
2 - 5 · 查找,指定位置之前插入,指定位置删除
2 - 5 - 1 · 查找
代码如下:
ListNode* ListFind(ListNode* phead, LTDatatype x)
{
assert(phead);
ListNode* pcur = phead->next;
//遍历
while (pcur != phead)
{
if (pcur->val == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}简单来说,就是遍历,查找,如果没找到就返回空指针。
2 - 5 - 2 · 指定位置之前插入
我们在单链表那篇中提到了单链表很难实现这个接口,而双向链表由于有了指向前驱结点的指针,实现这个接口就很方便了。
代码如下:
void ListInsert(ListNode* pos, LTDatatype x)
{
assert(pos);
ListNode* newnode = BuyNode(x);
newnode->next = pos;
newnode->prev = pos->prev;
pos->prev->next = newnode;
pos->prev = newnode;
}代码的实现与头插是十分类似的。
2 - 5 - 3 · 指定位置删除
同样的,我们提到过单链表很难实现这个接口,而双向链表有指向前驱结点的指针,实现这个接口就很方便了。
代码如下:
void ListErase(ListNode* pos)
{
assert(pos);
pos->prev->next = pos->next;
pos->next->prev = pos->prev;
free(pos);
pos = NULL;
}与前面实现删除的思路是一致的。
2 - 5 - 4 · 测试
测试一下:
void Test4()
{
ListNode* head = ListInit();
ListPushBack(head, 1);
ListPushBack(head, 2);
ListPushBack(head, 3);
ListPrint(head);
ListNode* find = ListFind(head, 2);
ListInsert(find, 4);
ListPrint(head);
find = ListFind(head, 1);
ListInsert(find, 5);
ListPrint(head);
find = ListFind(head, 1);
ListErase(find);
ListPrint(head);
find = ListFind(head, 3);
ListErase(find);
ListPrint(head);
//find = ListFind(head, 3);
//ListErase(find);
//ListPrint(head);
ListDestroy(head);
head = NULL;
}运行一下:
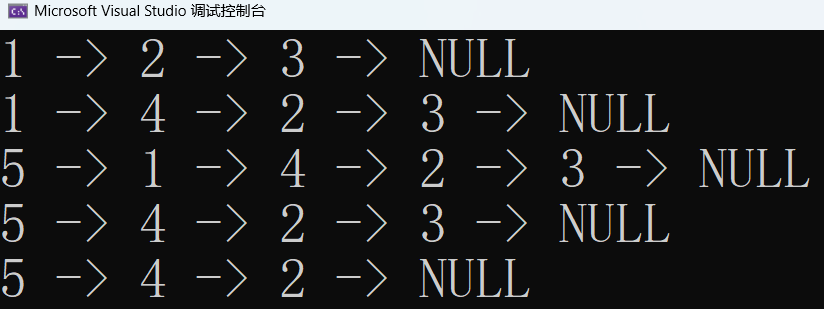
3 · 顺序表和链表的区别
如下:
|--------------|--------------------------------|-----------------------------------|
| 不同点 | 顺序表 | 链表(带头双向循环) |
| 存储空间上 | 物理结构上一定连续 | 物理结构上不一定连续 |
| 随机访问 (用下标) | 支持,时间复杂度O(1) | 不支持,时间复杂度O(N) |
| 任意位置 插入或删除元素 | 可能需要挪动元素, 效率低:O(N) | 只需要修改指针 指定位置取决于find 头/尾 插/删 为O(1) |
| 容量 | 动态,不够了就扩容 (扩容本身是有消耗的, 原地扩和异地扩) | 没有容量的概念 按需申请 |
| 应用场景 | 元素高效存储,需要频繁访问 | 需要任意位置频繁的插入或删除 |
| 缓存利用率 | 高 | 低 |
异地扩容的消耗是很大的,开空间,拷贝数据,释放旧空间。
总的来说,顺序表与链表各有优劣,这两个数据结构是互补的关系。
3 - 1 · 缓存利用率
我们先来看看存储器的结构:
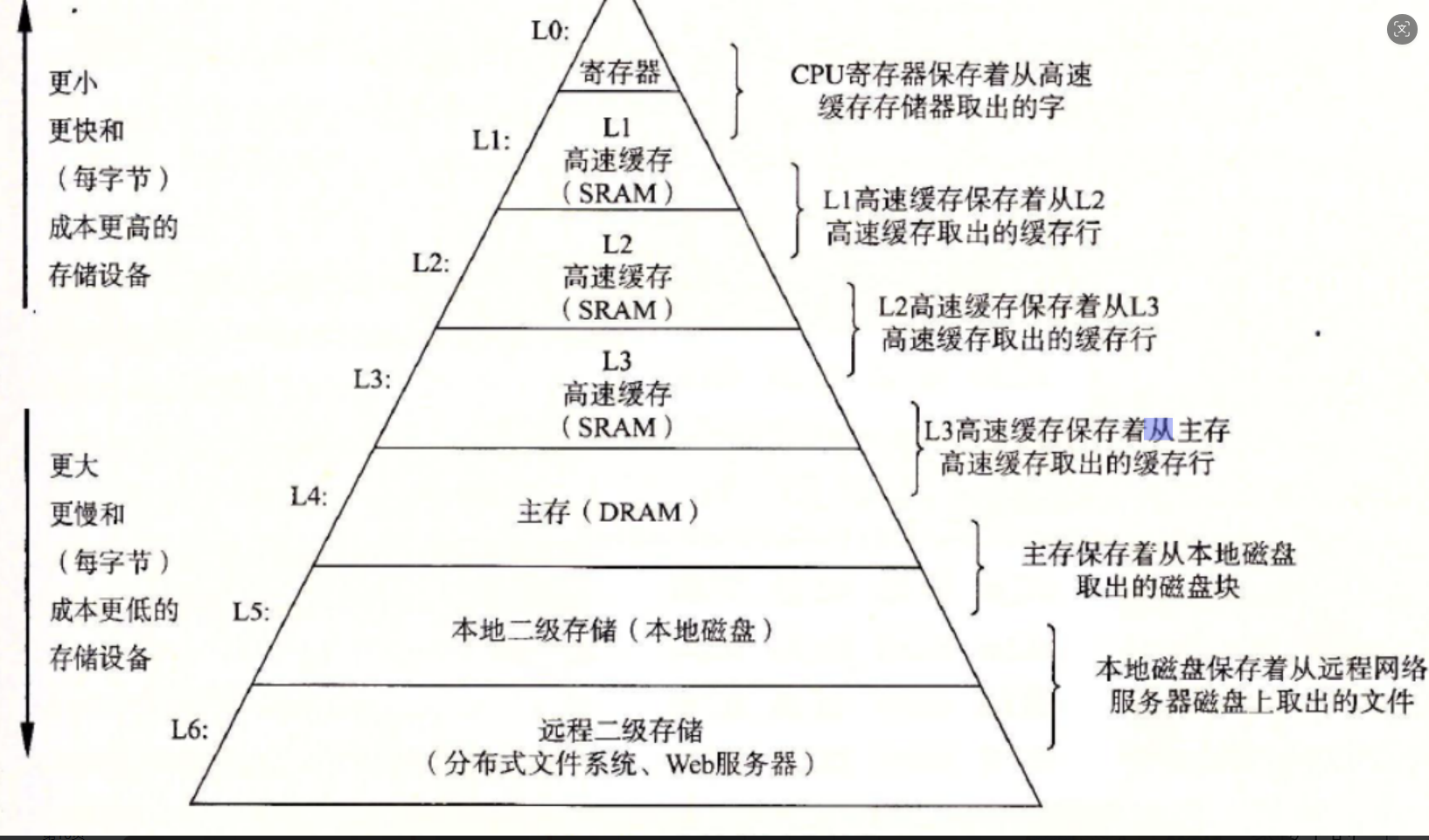
CPU的速度是很快的,而内存的速度是很慢的,所以CPU不会去内存中找数据,而是去缓存中找。
那什么是缓存呢?缓存是介于内存与CPU 之间的存储器,容量虽然小,但是速度比内存更快,用于缓解CPU的运算速度与内存条读写速度不匹配的矛盾。
缓存的工作原理是:如果CPU需要读取一个数据,首先会从缓存中找,如果找到,会立刻读取并发送给CPU进行处理,这样大大减少了CPU访问内存的时间。如果没找到,就需要从较慢速度的内存中读取并发送给CPU,同时也会将这个数据调入高速缓存中,以便CPU再次读取。
而缓存拿数据也不是一个一个拿的,而是从一个地址开始,一次拿多个。
因此,对于连续存放数据的顺序表,缓存可以一次拿到多个需要的数据,方便CPU从缓存中找到(命中)。
而对于不一定连续的链表,缓存利用率是更低的。
总结
以上简单介绍了双向链表有关内容,关于数据结构其余内容,请期待后续更新。
以上内容如有错误或不准确之处,欢迎指出,或者你有更好的想法,也欢迎交流。