下面是list数据结构的示意图,以及起相关指令所起作用的位置示意:
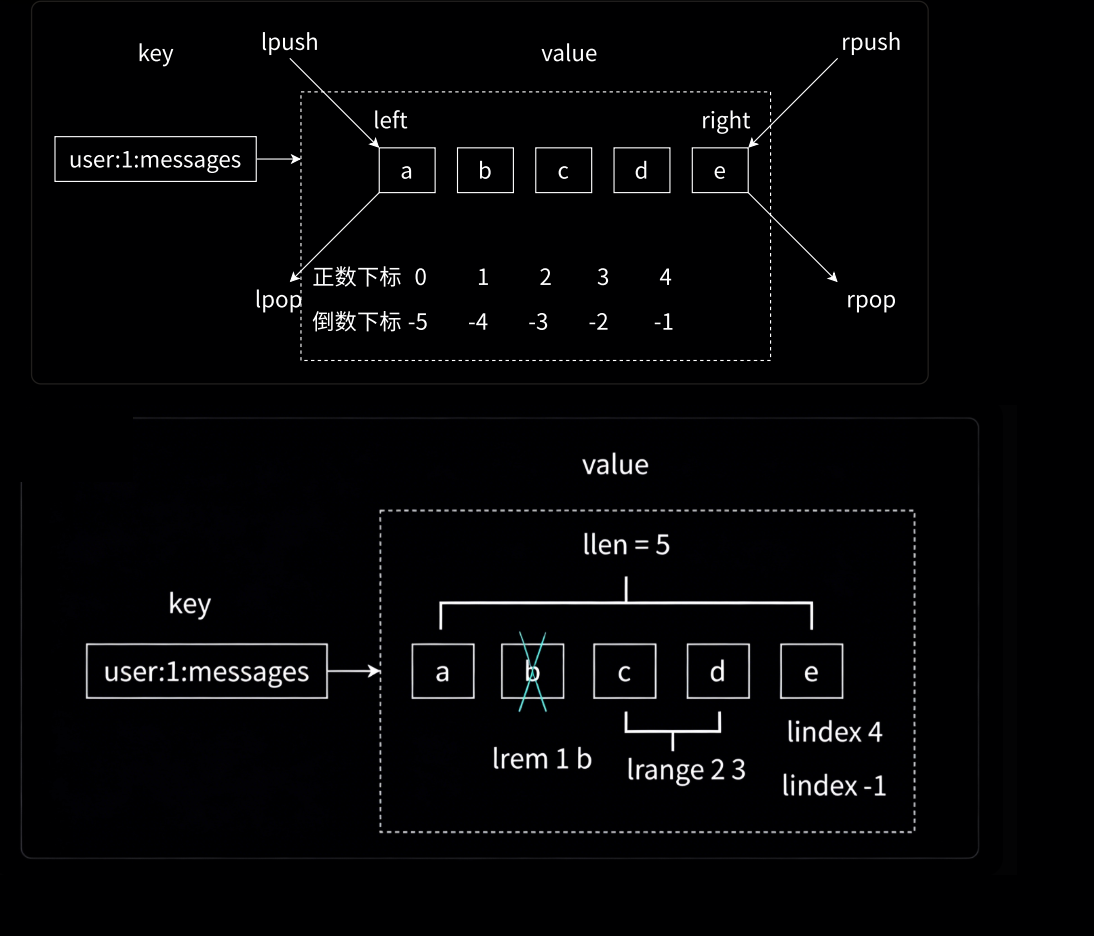
说明:
lpush相当于头插,lindex相当于根据下标获取列表中的一个元素。
头部添加元素(左进)
sql
LPUSH key v1 v2 ... //向列表头部插入一个或多个元素,key不存在会自动创建空列表再插入。返回值:插入后列表的总长度
LPUSHX key v1 v2 ...//向列表头部插入一个或多个元素,key不存在会插入失败。返回值:插入后列表的总长度尾部添加元素(右进)
sql
RPUSH key v1 v2 ... //向列表尾部插入一个或多个元素,key不存在会自动创建空列表再插入。返回值:插入后列表的总长度
RPUSHX key v1 v2 ... //向列表尾部插入一个或多个元素,key不存在会插入失败。返回值:插入后列表的总长度头部弹出元素(左出)
LPOP key //移除并返回列表头部第一个元素
//key不存在或列表为空,返回 nil尾部弹出元素(右出)
sql
RPOP key//移除并返回列表尾部最后一个元素
//key不存在或列表为空,返回 nil获取指定范围元素
sql
LRANGE key start end //获取列表中[start, end]区间的所有元素
//下标规则:0=第一个元素,-1=最后一个元素,-2=倒数第二个
//start超过列表长度:返回空列表
//end超过列表长度:默认取到列表末尾
//key不存在:返回空列表指定位置插入元素
sql
LINSERT key BEFORE|AFTER pivot value //在列表中指定基准元素的前面或后面插入新元素
BEFORE:在基准元素 pivot 之前插入
AFTER:在基准元素 pivot 之后插入
key 不存在或者列表中不存在 pivot 元素,返回 0,插入成功返回插入后列表总长度
如果list中存在多个基准元素,以第一个基准元素为准获取列表长度
sql
LLEN key //返回列表中元素的总个数,key不存在或列表为空,返回 0根据下标获取元素
LINDEX key index //获取列表中指定下标位置的元素
//index为负数表示倒数位置
//下标越界或key不存在,返回 nil删除元素
sql
LREM key count value //根据 count 值删除列表中指定的 value 元素.返回值:实际被删除的元素个数,key 不存在时,统一返回 0
count > 0:从列表头部向尾部遍历,删除前 count 个 value
count < 0:从列表尾部向头部遍历,删除后 |count| 个 value
count = 0:删除列表中所有等于 value 的元素根据下标修改元素
sql
LSET key index value //将列表中指定下标位置的元素修改为value。返回值:修改成功返回 OK
//下标必须存在,否则报错截取列表
sql
LTRIM key start end //只保留列表中[start, end]区间的元素,删除其余元素,返回值:操作成功返回 OK
//常用于固定列表长度(如消息队列保留最新100条)阻塞式头部弹出
sql
BLPOP key1 key2 ... timeout //LPOP 的阻塞版本,如果链表中没有数据可以弹出,就会阻塞本客户端,但是Redis服务不会阻塞哦。支持同时监听多个链表,规则是一但有一个链表有了数据就立刻弹出数据后返回,其他链表就不管了。
timeout 这是超时时间(单位:秒),超过了这个时间客户端就不再阻塞了。
返回值:
超时无数据返回 nil
成功返回被弹出元素的链表和被弹出的元素需要注意的是:
被阻塞的客户端是有顺序的。比如说两个客户端等待同一个链表,等到链表有数据的时候,先等待的就会弹出数据并返回。
阻塞式尾部弹出
sql
BRPOP key1 key2 ... timeout
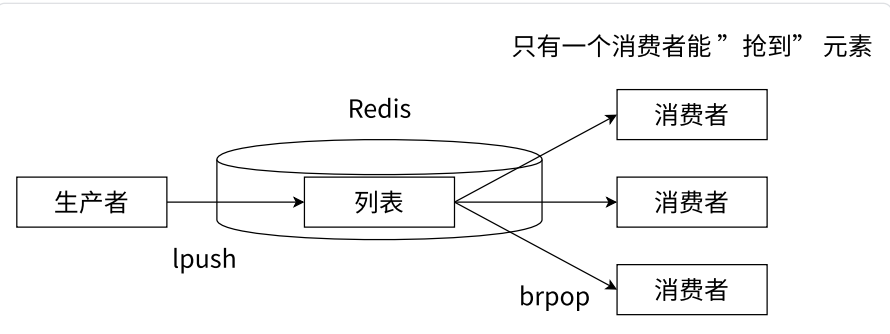
与上同理list的适用场景举例
负载均衡下要决定把任务交给哪个服务器,其中一种算法就是轮询,即:服务器轮流接任务。由于Redis中list中的brpop阻塞是有顺序(谁先阻塞谁先取)所以很自然的可以实现轮询。
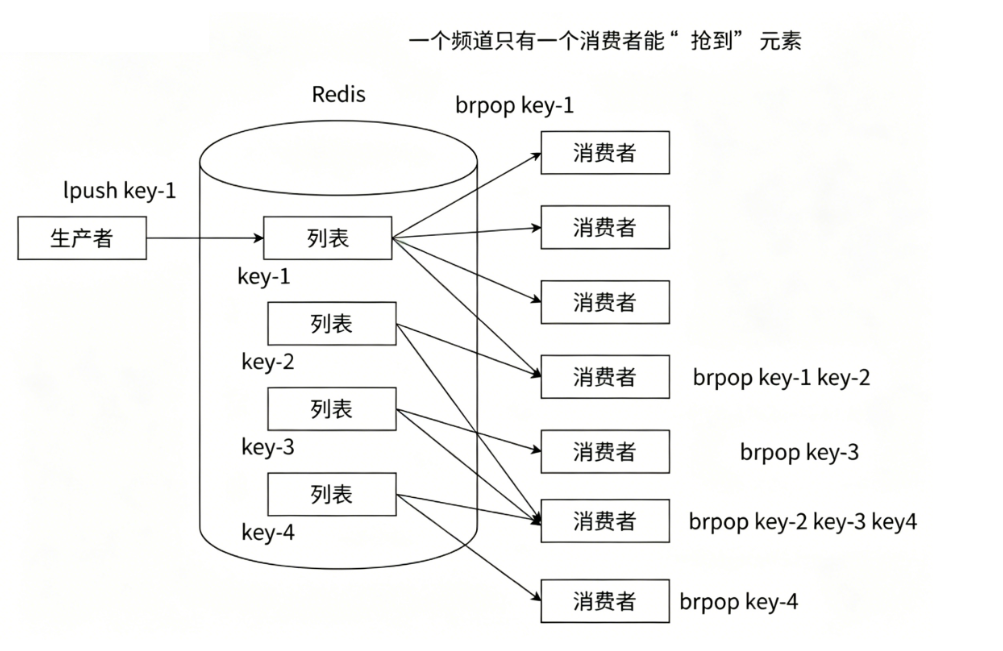
brpop 命令可以一次性等待多个链表,通过让不同链表代表不同频道**,实现消费者订阅不同频道的理念。**
除此之外,链表是有序的,并且链表支持范围查询,因此链表可以很好的支持分页显示。链表的范围查询(lrange)的时间复杂度是O(N),这在链表过长的时候消耗较大,因此可以把一个链表的内容分成多个链表存储,比如每个链表存500个,分5个链表,当我们要显示第2100-2200的数据时,直接查找最后一个链表即可,省去了很多无效遍历,本质上是一种目录的思想。