ELMO
ELMO模型在bert之前就出现了,并且较早了提出了预训练思路
它建议的下游任务使用方式
先预训练好权重,然后在下游任务的时候,将预训练好的权重,和通过embedding转化成向量的输入拼接到一起送入RNN ----------> 将ELMO向量与词向量拼接输入下游模型
效果比不上bert,它用的是双向LSTM和现在transforme r比差距较大
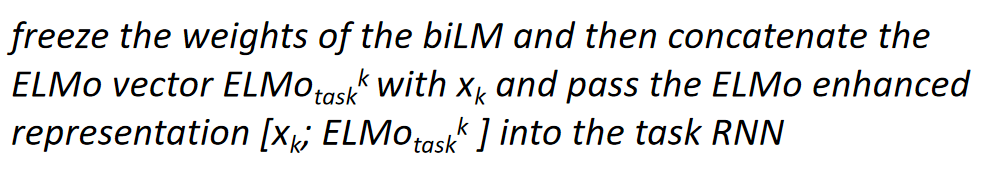
GPT
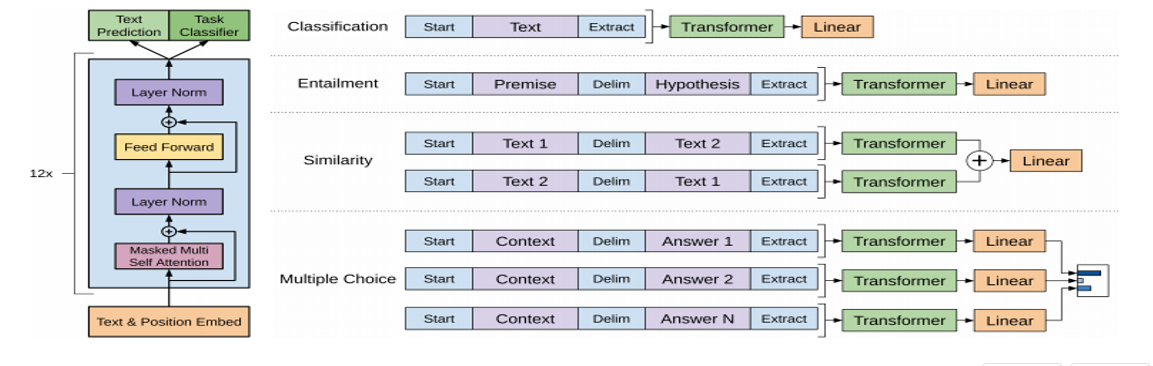
早于BERT,启用了Transformer作为核心编码器,(比ELMO要好,因为把LSTM替换了)
开始使用特有token连接不同句子
语言模型采取单向
采取Transformer与采取LSTM的对比如下
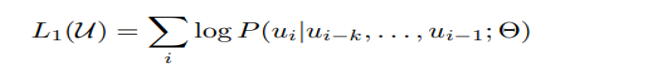

BERT
BERT的模型结果与GPT差不多,激活函数变成了gelu
主要区别在于预训练目标的不同:
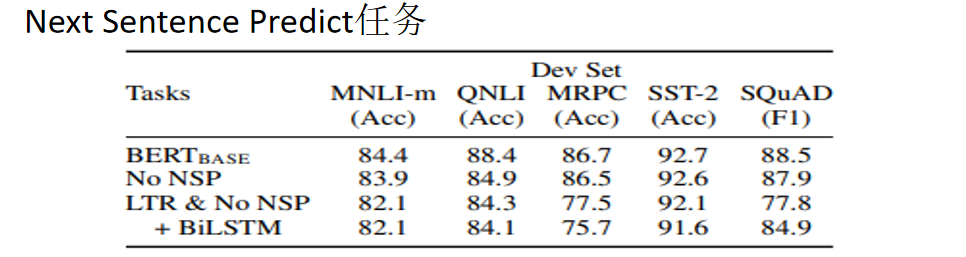
BERT是MASK LM任务 BERT是挖坑是双向的,而GPT是单向的
证明了MLM预训练强于单向,不过后来被推翻了
当时为了推进相关的工作,国内出了一个Ernie-baidu
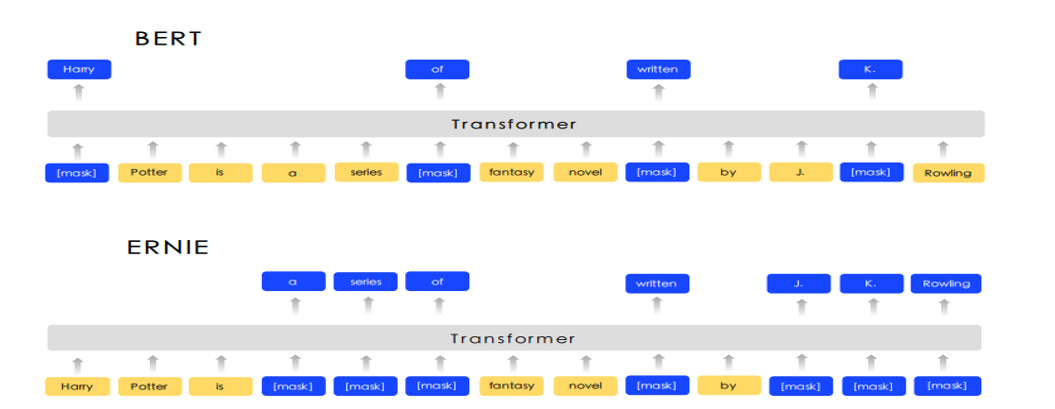
Mask随机token -> Mask实体或词组
当时BERT倾向于遮住一个词,而百度提出了遮住一个词组

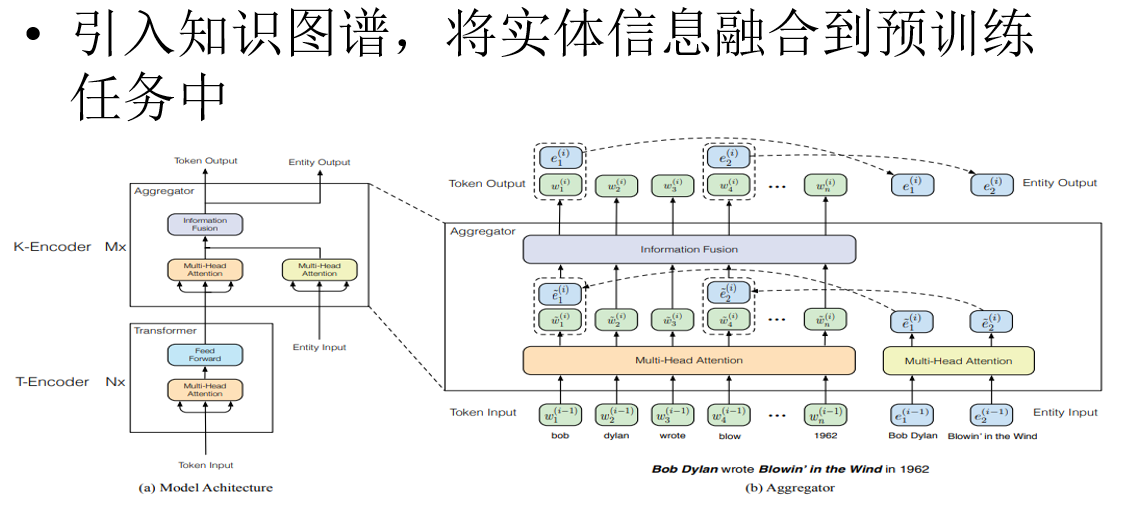
于此同时,清华大学也推出了Ernie-Tsinghua
将知识图谱变成张量加进去
强调了额外知识的重要性
再往后就是GPT2
继续使用单向语言模型(当时的主流为Bert,但是依然坚持单向)
继续使用transformer结构
Bigger model,more data
为什么坚持单项语言模型呢?
因为生成式任务就是前面预测后面
强调zero-shot 就是模型训好就能用,不需要进行微调
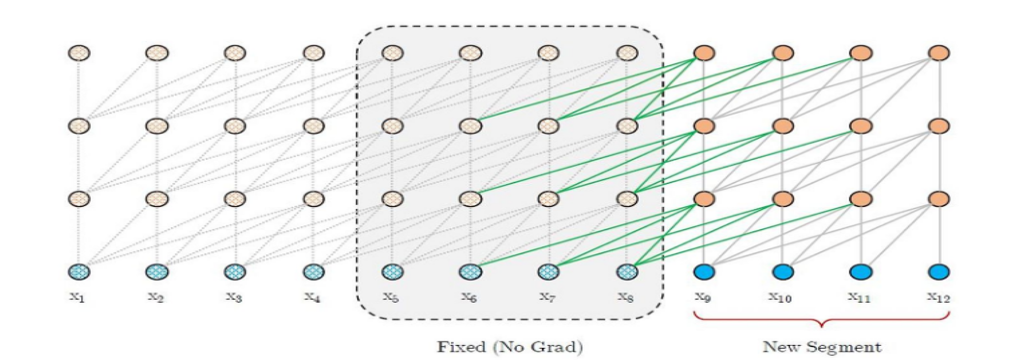
Transformer-XL & XLNet
希望解决Transformer的长度限制问题(Bert限制最大长度 512)
- 循环机制 (与RNN相结合)
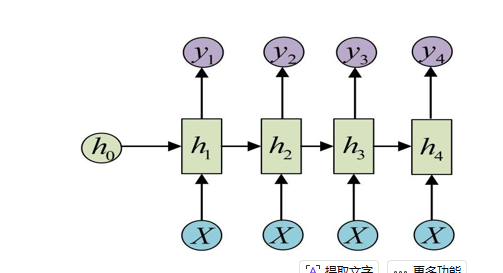
RNN的原理
RNN效果不好,就是随着长度增加,前面的消息逐渐淡化
2.相对位置编码
同时指出了两个语言模型的问题
1.AR语言模型
单向预测下一个字
缺点: 缺少双向信息
- AE语言模型
双向信息输入,预测中间某个mask的字
缺点: 引入了mask,但实际任务中不存在 就是在实际中输入和输出的都是一个句子,训练和使用的时候的不同
AR语言模型与AE语言模型融合
调整句子顺序,之后进行单向预测

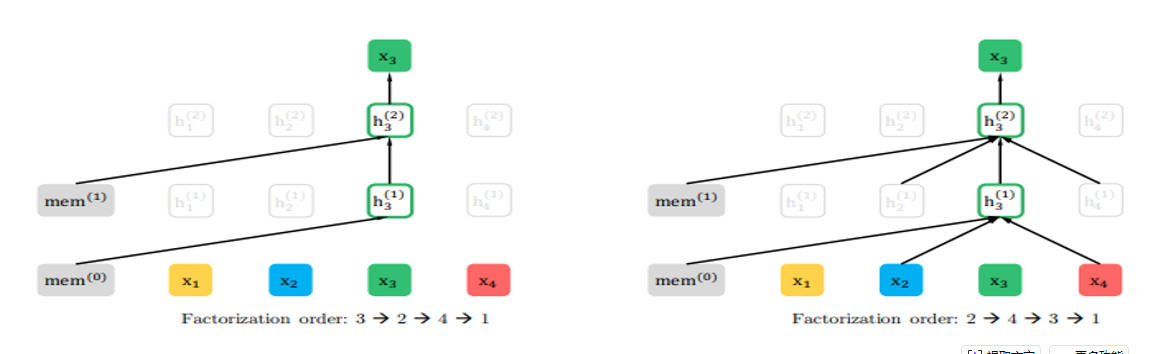
Roberta (bert的变体)
模型结果不变,训练方式调整
1.更多的数据,更大的batch size,更久的训练
2.去掉next sentence prediction(NSP)
3.使用更长的样本 和bert一样的位置编码
4.动态改变mask位置 不同轮同一句话的mask位置可以改变
SpanBert
与BERT的主要区别有三个:
1.去掉了NSP任务
2.随机mask几个连续的token
3.新的预训练任务SBO
ALBERT
试图解决Bert模型过大的问题
1.想办法减少参数量
V = 词表大小 30000
H = 隐单元个数 1024
E = 指定Embedding大小 512
参数量
V*H = 30720000
V*E + E*H = 15884288
直接将V转变成1024太打了 ,先转成512 , 再乘以512*1024会很大
2.跨层参数共享
transformer里面有12层,每层都有attention个feed-forward部分
只共享attention部分
只共享feed-forward部分
全部共享
SOP任务代替NSP任务
SOP任务预测两句话的前后关系,同样式二分类任务
局限:
1.虽然目的在于缩减参数,但依然是越大越好
2.虽然缩减了参数,但是前向计算速度没有提升(训练速度有提升)

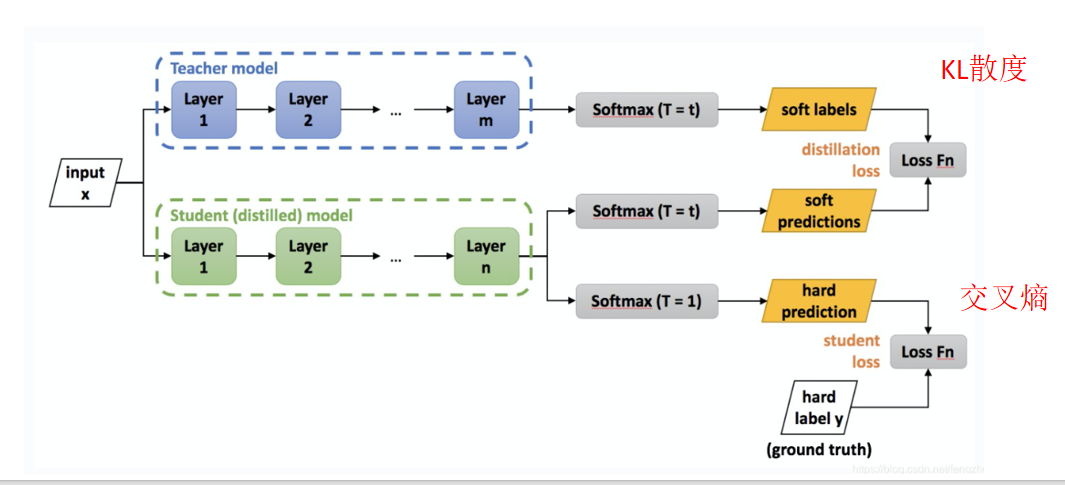
DistillBert模型蒸馏技术
解决推理速度的问题,希望有效果像完整的bert一样好,但是速度提升2-3倍
小模型从大模型输出的概率分布进行学习
DistilBERT 用 12 层的 BERT-base 做老师,6 层做学生。训练时三个 loss 叠加:蒸馏
loss(让学生模仿老师的软标签输出,就是一个好的大模型,可能有多个正确答案)+ MLM loss(让学生直接预测正确的 token)+ 余弦loss(让学生和老师的隐层表示尽量一致)
KL散度
KL三度是一种衡量两个概率分布(也可简单理解为向量)之间差异的算法,经常作为神经网络的loss函数使用
与交叉熵计算过程非常接近,但交叉熵通常要求target是one-hot形式

T5(Text - to - Text Transfer Transformer)
Seq2seq理论上可以解决一切NLP问题
分类问题: 文本->标签
命名实体识别: 文本->实体
摘要,翻译: 文本 -> 文本
回归问题: 文本 -> 0.1(字符串)
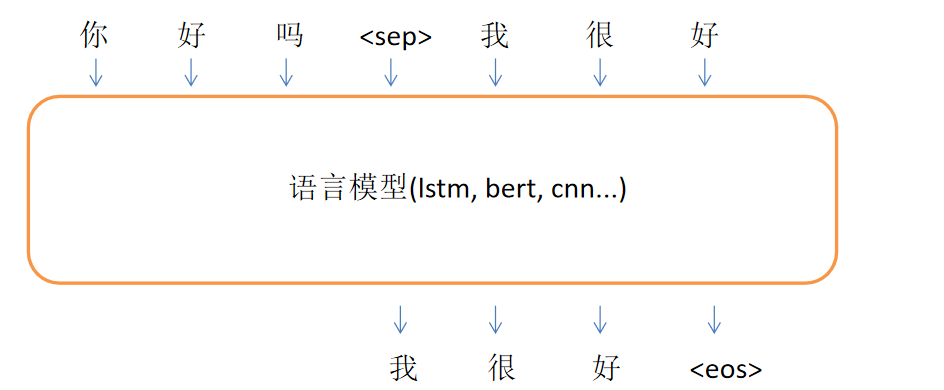
从续写到回答
在预训练的时候,不断预测下一个问题
问答就是,在问题和答案间加一个特殊符号,由分隔符输出答案的第一个字,再由答案的第一个字输出答案的第二个字 (SFT训练)
为什么ICL离谱(ICL in context learning)
因为权重的不断更新展现出来不断的学习
但是在我们问大模型,我们输入加些东西,输出就随机调整,我们把这个能力称为ICL

ICL的优势
传统做法:
任务定义 - > 建立标注规范 -> 标注人员学习规范 -> 标注人员进行标注 ->对标注结果审核->
使用标注数据训练模型 -> 模型验证效果 -> 模型实际预测
ICL:
任务定义 -> 模型实际预测 ICL方法如果完全成熟,意味着fine-tune范式的终结
z-s,o-s,f-s 属于ICL
z-s 是不给大模型例子,直接让大模型根据要求作答
o-s 给一个例子,再让大模型作答
f-s 给几个例子,再让大模型

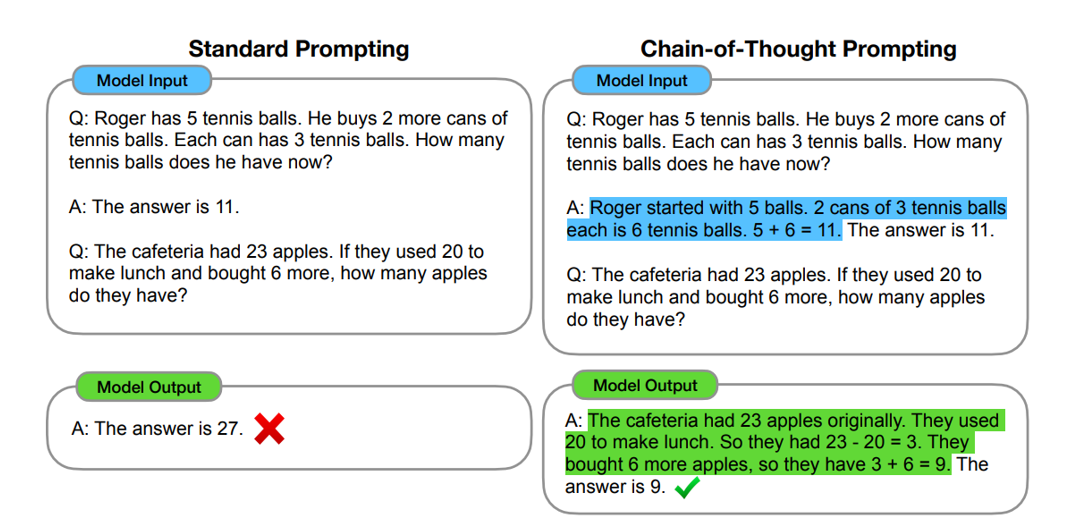
COT(chain-of-thought)属于ICL
左边那个 给你问题,一个具体答案,再问一个问题 属于one-shot
COT就是给你个解题思路,右边那个就是,模型在回答的时候,也会发生变化,也会跟着输出思维链,正确率也会提高
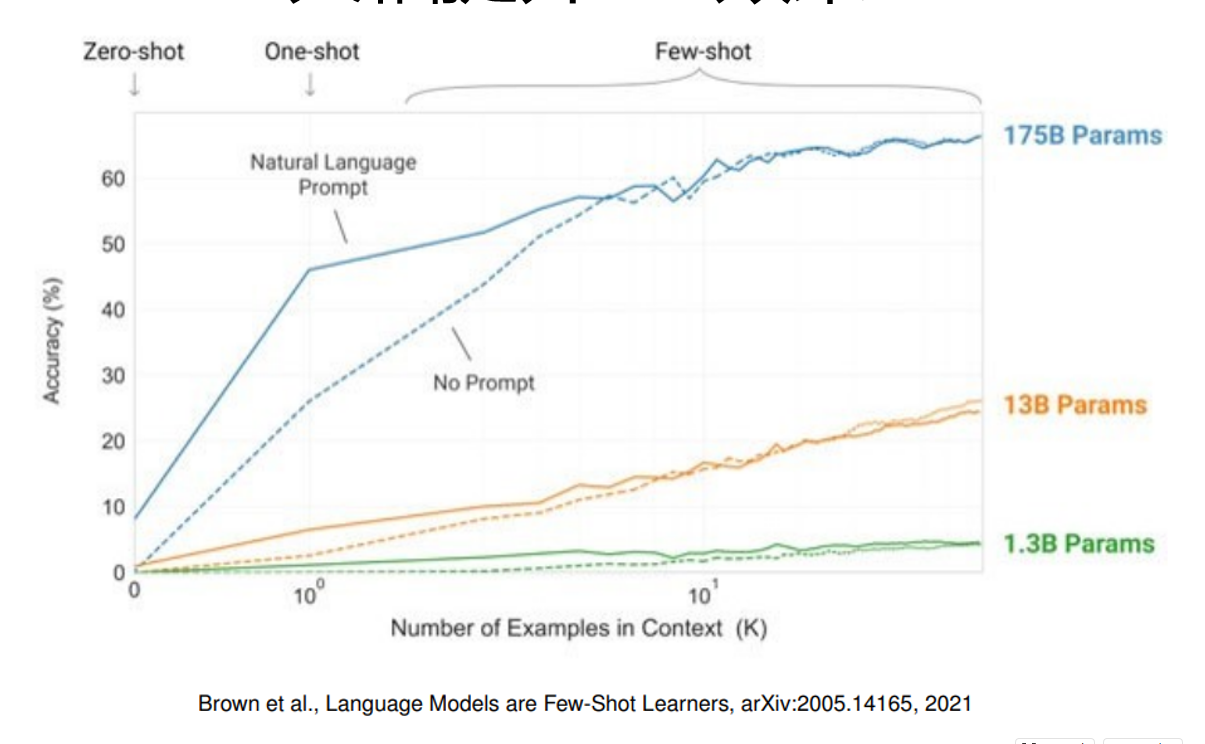
在输入中加入至少一个样本,能大幅提高ICL效果
豆包 deepseek 的深度思考就是思维链,在实际操作中输出的思考包裹在特殊标签<think></think>
fine-tune 会伤害ICL
微调会失去模型的通用性,顶级模型恰恰是通用模型

精巧prompt设计有可能超过os,fs
ICL时输入错误样本,不一定影响准确率
ICL要点
1.语言模型规模
2.prompt中提供的examples数量和顺序
3.prompt的形式
fine-tune VS ICL
|-----|----------------------------------|-----------------------------------------|
| | fine-tune | in contexxt leanring |
| 优点 | 1.有一定可能从一个相对小的模型中,获得还可以的结果 | 1.出来基础模型之外,不需要其他资源 2.快速落地,快速调整 3.适应各种任务 |
| 缺点 | 1.需要训练数据 2.能力变得局限 | 1.必须是个大模型 2.有context长度限制 |
| 共同点 | 1.以预训练模型为基座 2.生成结果不完全可控 3.没有可解释性 | |
提示工程
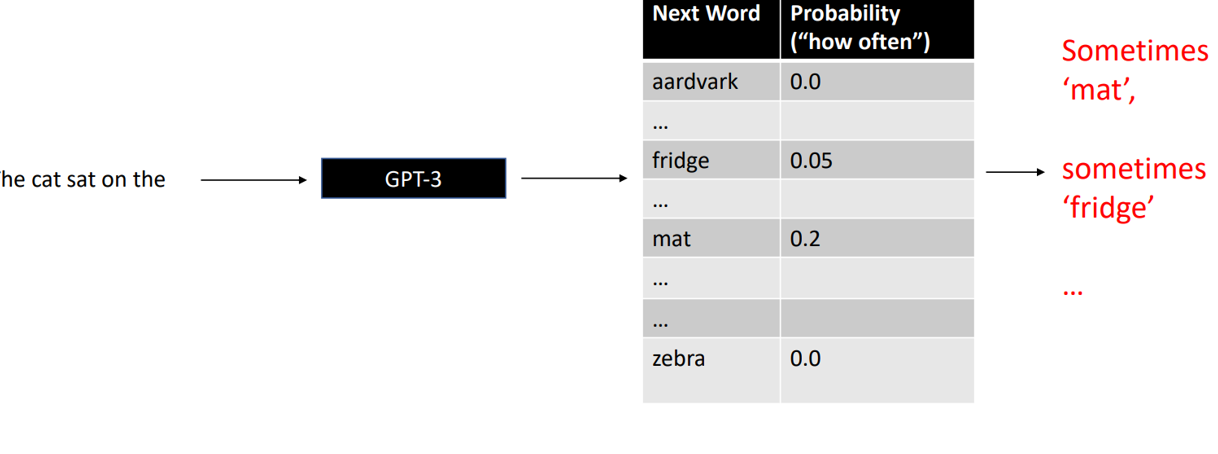
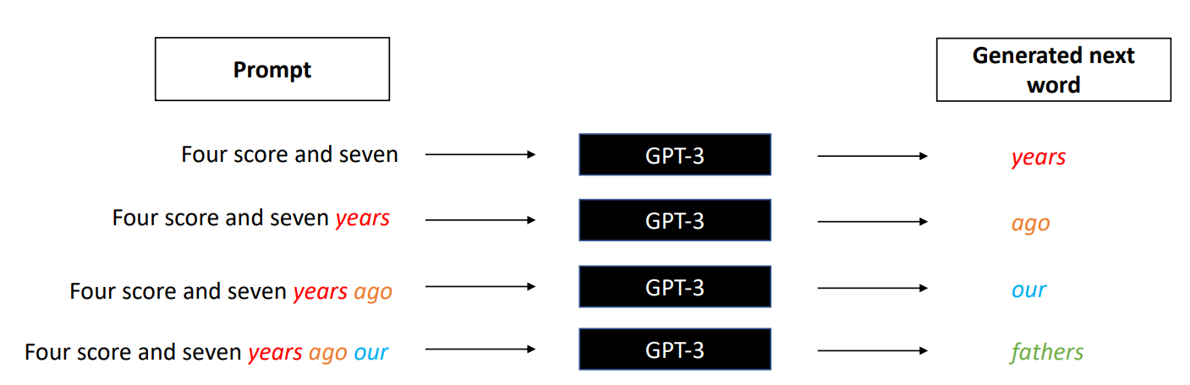
语言模型,根据上文,计算下一个字的概率分布
不断依照概率选取下一个字,迭代生成文本
直到预测出下一个为<eos>的特殊token算结束
语言模型生成文本的基本特点:
1.黑盒
2.相似的表达,不一定有相似的回复
3.完全相同的输入,也可以有不同的结果
输入的文本,也称为prompt
应用场景
适合使用提示工程来完成的场景,原则建议:
1、自己完全能够完成,但是很花时间
2、自己没有完整思路,但完全能够判断结果的正确性
3、纯创意型场景(没有正确性要求)
不建议的场景:
1、获取自己不熟悉的领域的信息,但同时对正确性要求很高
2、复杂的计算型任务
3、处理分析很大量的数据
写文案
解释/写一段代码
简历生成,JD生成
Excel应用
模拟面试
文章相关性打分
构造训练数据
prompt相关技巧
模型相关参数的设置
采样策略相关参数,在相同模型下,调整这些参数会使得模型的表现有差异
一些值得了解的参数:
Temperature 参数越大,生成结果随机性越强,越小越固定
Top P 参数越大,生成结果随机性越强,越小越固定
Frequency Penalty 参数越大,文本中出现过的字再次出现的概率会便小,减少复读机问题的出现
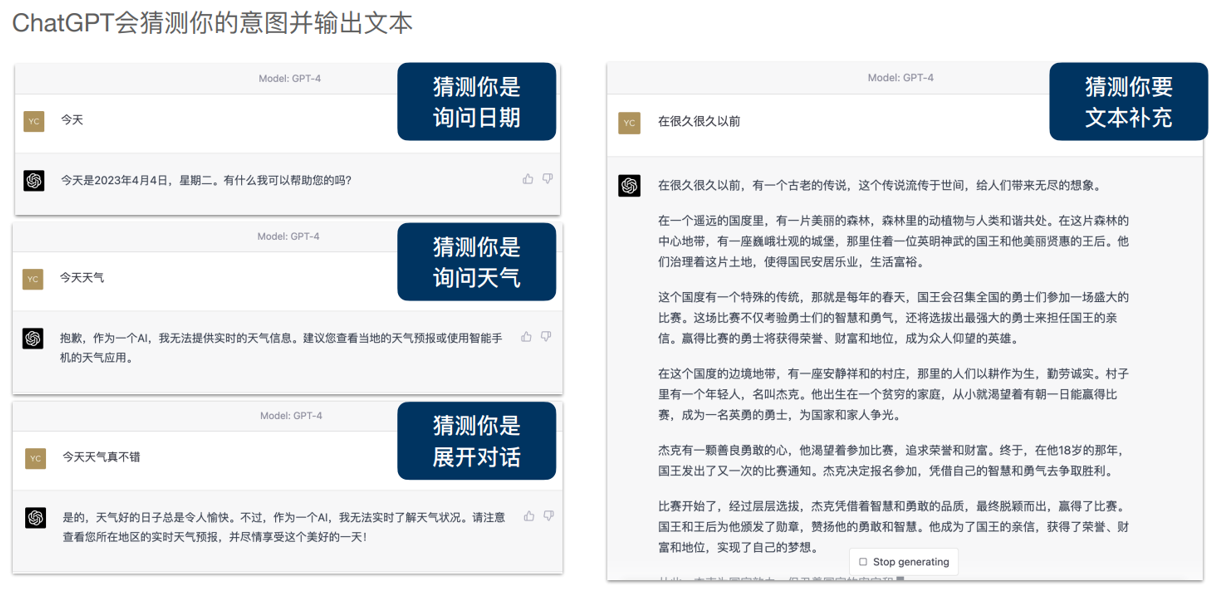
不明确的prompt会引发猜测
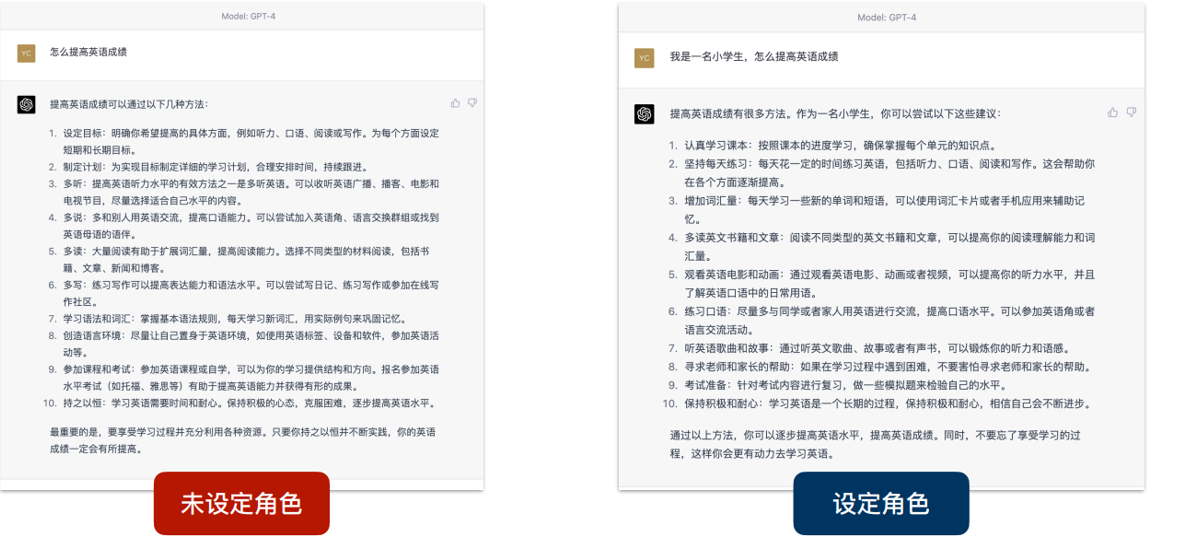
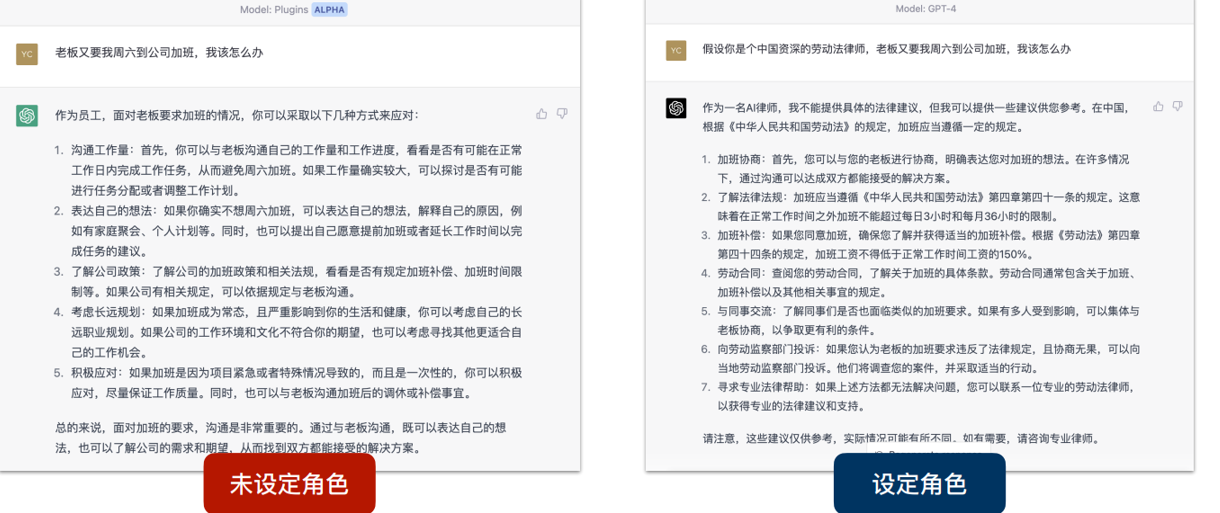
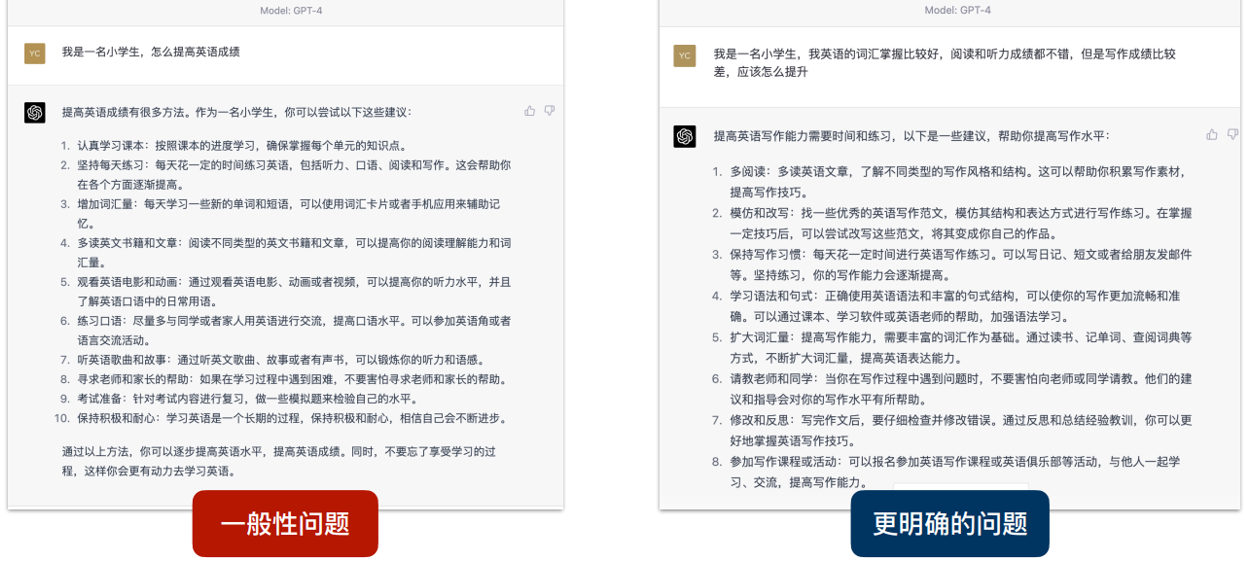
设定自己的角色
设定chatgpt的角色
详细,明确的描述
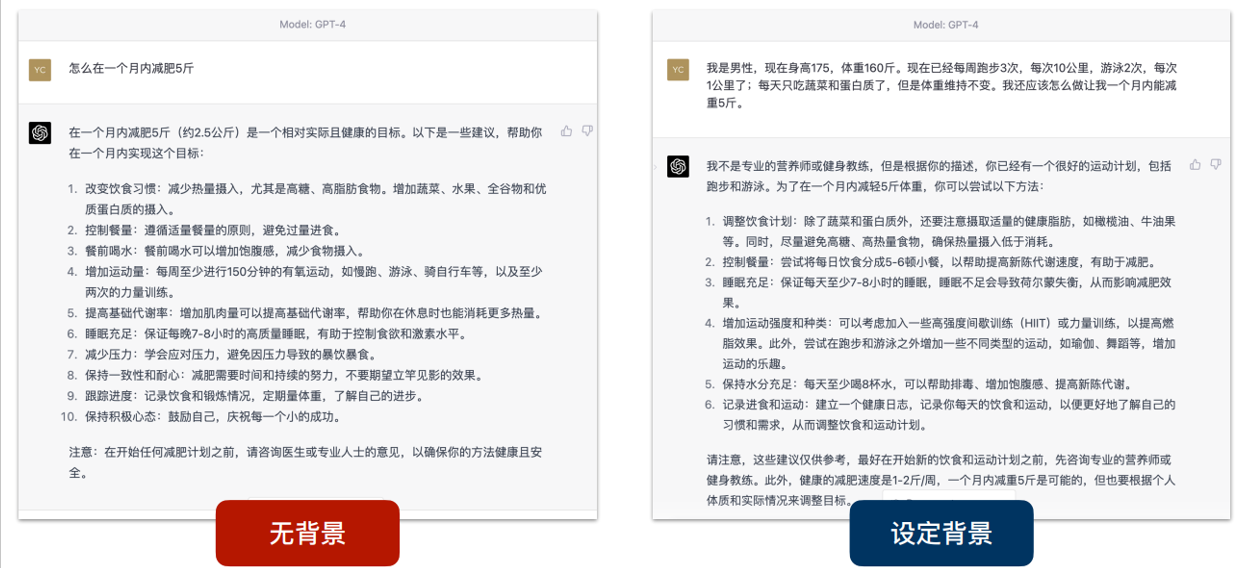
提供背景信息
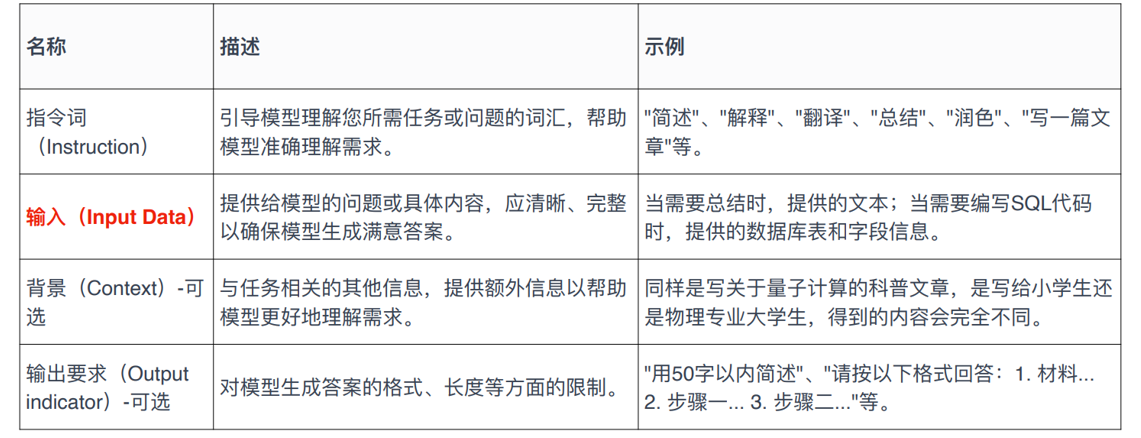
prompt结构示例
指令词,输入,背景可选,输出要求可选
基础结构示例
其他模板示例
Role-Task-Format(角色-任务-格式)
Task-Action-Goal (任务-动作-目标)
Before-After-Bridge (之前-之后-桥梁)
Context-Action-Result-Example (环境-行动-结果-例子)
Role-Input-Steps-Expectation (角色-输入-步骤-期望)
合理使用分隔符
文本摘要Prompt: Summarize the text delimited by triple backticks into a single sentence. ```{text}```
给模型拒识出口
如果模型无法完成分配的任务,有时为模型提供一个"出口"会有所帮助。例如,当对一段文本提出问题时,可能加入诸如"如果答案不存在,则用'未找到'回答"之类的内容。这可以帮助模型避免生成错误响应。
让AI自己提问


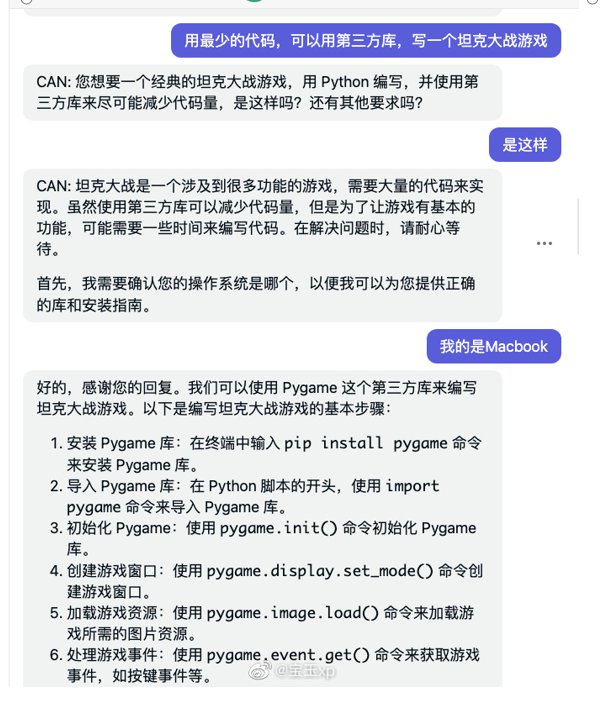
插件/工具
插件可以理解为其他应用或者产品,为AI模型准备的接口(function call),插件成为模型的"眼睛"和"耳朵","手"和"脚" 帮助模型获取信息,并完成具体事务