
很多人用 Agent 写代码,最开始都会很兴奋。
你让它写一个接口,它能写;让它补一个 SQL,它能补;让它解释一段老代码,它也能讲得像模像样。于是很容易产生一个错觉:只要模型足够强,再加一段更详细的 Prompt,AI Coding 就能自然进入真实研发流程。
但一到复杂项目,问题很快就暴露出来。
你前面告诉它"金额字段单位是千元",过一会它又当成元处理;你强调"INSERT 必须带分区",它前几次记得,后面上下文一长又忘了;你让它查血缘、自测、比对数据,主会话很快被日志和表结构撑满;它生成了代码,但你不知道它哪些步骤真的验证过,哪些只是看起来合理。
这时候继续加 Prompt,通常只能缓解一轮,不能解决系统性问题。
今天这篇想讲一个更工程化的判断:
Harness 不是 Prompt,而是 Agent 的工程化底座。它把上下文、工具、权限、记忆、检查、子任务隔离和人工审查组织起来,让 Agent 从"能生成"变成"可交付"。
一、为什么更长的 Prompt 救不了复杂 Agent
简单任务里,Prompt 很有效。
比如"帮我写一个用户注册接口""解释一下这段代码""把这个 JSON 转成 Java Bean",这些任务的边界很清楚,依赖也不多。模型只要理解当前输入,就能给出可用结果。
但真实研发任务不是这样。
比如一个数仓 ETL 任务,Agent 可能需要同时记住:
- 本次迭代改哪张表;
- 哪些上游表只读,不能动;
- 金额字段单位是元、分、千元还是万元;
- 分区字段叫
dt还是partition_dt; INSERT OVERWRITE前要不要检查已有分区;- 哪些 SQL 规范必须强制遵守;
- 自测结果里哪些差异是预期,哪些是异常;
- 上线前要补哪些 DQC / SLA 规则。
这些信息不是一段 Prompt 能长期稳定承载的。
原因很简单:对话上下文是会变化的。会话变长以后,历史信息可能被压缩;工具返回会挤占上下文;日志、DDL、血缘和样本数据会把关键约束冲淡。越是复杂任务,越依赖上下文;但越复杂任务,越容易把上下文撑爆。
所以问题的本质不是"Prompt 写得不够长",而是"我们把太多系统职责交给了模型记忆"。
更稳的做法是分工:
| 事情 | 不该只靠模型 | 更适合放在哪里 |
|---|---|---|
| 长期项目规范 | 靠 Prompt 反复提醒 | CLAUDE.md、rules、仓库文档 |
| 当前迭代约束 | 靠对话记住 | 当前任务状态文件 |
| 危险操作拦截 | 靠模型自觉 | PreToolUse hook / guardrail |
| 写完代码后检查 | 靠人提醒 | PostToolUse hook / CI |
| 大量日志和血缘分析 | 塞回主会话 | subagent 独立上下文 |
| 团队 SOP | 每次重新解释 | skill / runbook |
这就是 Harness 的价值:把不稳定的"记忆"变成可治理的系统结构。
二、Harness 到底是什么
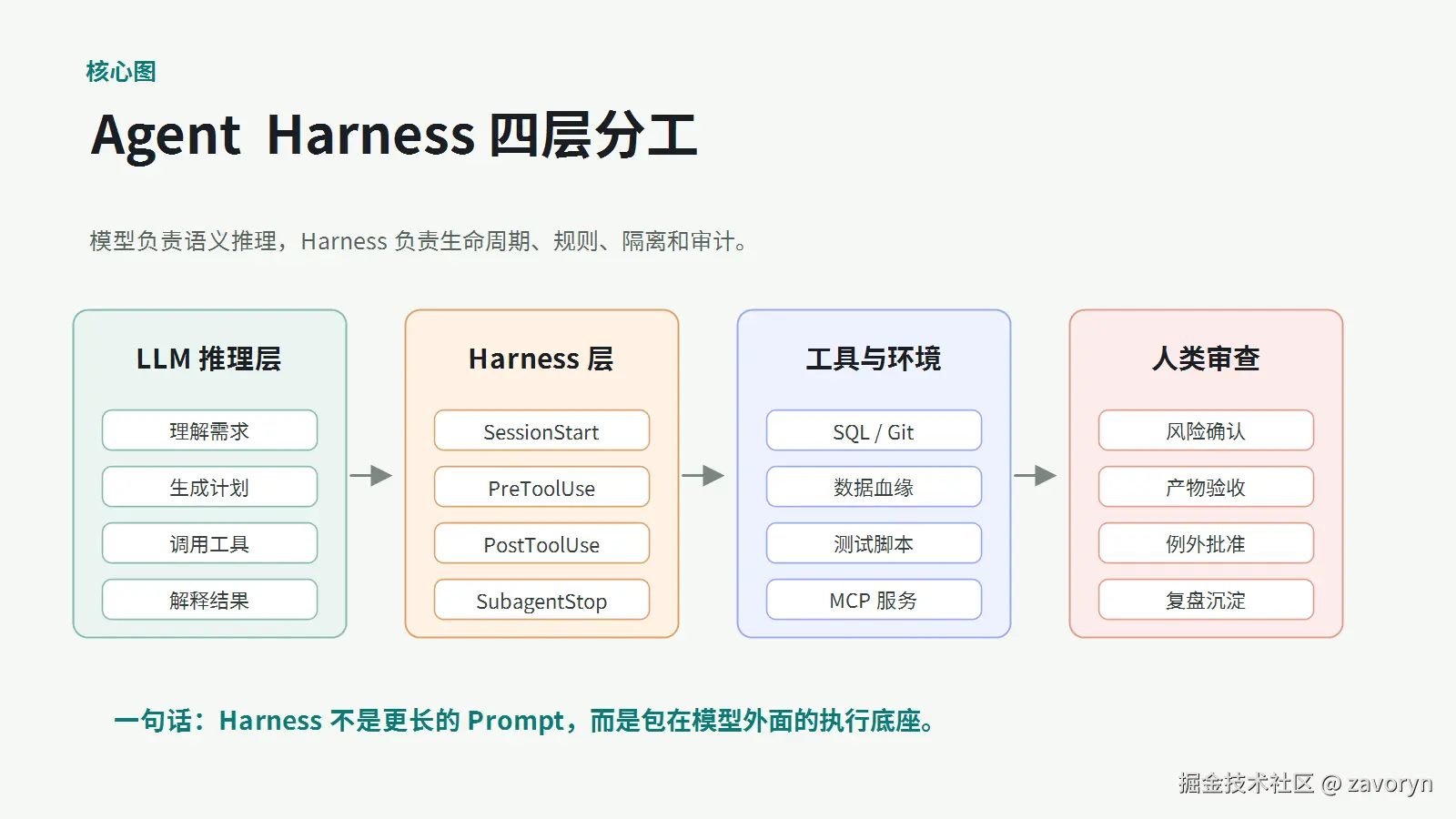
可以把 Agent 系统分成四层。
第一层是模型层。它负责语义理解、规划、生成、解释,比如 GPT、Claude、Gemini 这些模型能力。
第二层是 Harness 层。它不直接负责"想答案",而是负责管理一次 Agent 运行:什么时候加载上下文,什么时候允许工具调用,什么时候拦截危险动作,什么时候把任务交给子代理,什么时候让人类确认。
第三层是工具与环境。比如文件系统、Git、SQL、HTTP API、MCP 服务、测试脚本、CI 流水线。
第四层是人类审查。复杂任务里,人类不应该每一步都打断 Agent,但必须在关键决策、高风险动作、最终验收和复盘处介入。
这套分层背后的思想,在多个 Agent 框架里都能看到。
Claude Code 的 hooks 文档把生命周期事件拆得很细:SessionStart、UserPromptSubmit、PreToolUse、PostToolUse、SubagentStart、SubagentStop、PreCompact、PostCompact 等。这说明 Agent 不只是一次模型调用,而是一条可以被拦截、扩展、审计的运行链路。
OpenAI Agents SDK 里也有 tools、handoffs、guardrails、sessions、tracing 等概念。尤其是 guardrails,可以在输入、输出、工具调用前后做检查,并在触发 tripwire 时阻断流程。
LangGraph 强调 durable execution、human-in-the-loop、persistence 和 memory,本质上也是把 Agent 从"聊天式调用"推进到"可恢复的工作流"。
这些方向虽然实现不同,但工程目标很一致:
不要让复杂任务完全漂浮在模型输出里,要把状态、规则、工具、审查和恢复机制放进运行时。
三、四个核心组件:Memory、Hooks、Subagents、Skills
1. Memory:不要把关键状态只放在聊天里
很多 Agent 事故,本质上是状态管理事故。
人类说过一句"这次先忽略 field_a",模型当时听懂了;但半小时后上下文压缩、日志刷屏、任务切换,它可能就忘了。这个问题不能靠"你要记住"解决。
更稳的做法是把信息分层:
| 信息类型 | 推荐位置 | 示例 |
|---|---|---|
| 项目长期规范 | CLAUDE.md / AGENTS.md / rules |
命名规范、分层规范、禁止项 |
| 当前迭代状态 | 当前任务区 / issue / task file | 表名、版本、禁止修改范围 |
| 跨会话经验 | memory | 字段口径、历史踩坑、团队偏好 |
| 大量证据材料 | 文件 / 知识库 / RAG | DDL、日志、血缘、接口文档 |
核心原则是:对话只承载过程,约束必须落盘。
这和后端工程里的配置管理很像。你不会把生产数据库地址只写在聊天记录里,也不应该把 Agent 的关键工程约束只写在临时对话里。
2. Hooks:不要让规范靠模型自觉
Hook 是 Harness 里最有工程味的一层。
它的价值不是"提醒模型",而是在工具调用边界做确定性检查。
常见 hook 点可以这样理解:
| Hook 点 | 适合做什么 |
|---|---|
UserPromptSubmit |
注入上下文、检查输入是否合规 |
PreToolUse |
工具执行前拦截危险命令、限制路径、检查权限 |
PostToolUse |
文件写完后自动跑 lint、测试、SQL 规范检查 |
SessionStart |
会话开始或恢复时加载项目上下文 |
SubagentStop |
子代理结束后收集摘要和证据 |
PreCompact / PostCompact |
上下文压缩前后保存和恢复关键状态 |
比如数仓场景里,写完 SQL 后可以自动检查:
- 是否出现
SELECT *; INSERT是否带PARTITION;- 金额字段是否误用
DOUBLE; UPDATE/DELETE是否缺少WHERE;- 是否对生产表执行危险 DDL。
这类规则不应该靠模型每次"记得"。能自动检查的东西,就应该交给 hook。
面试里可以这样概括:
Hook 是 Agent 的质量门禁。它不是建议模型遵守规范,而是在工具调用前后执行检查;必要时直接阻断。
3. Subagents:不要把所有过程塞回主上下文
很多人一听 subagent,就理解成"多开几个模型一起干活"。这只说对了一半。
Subagent 更重要的价值是:上下文隔离。
比如主会话只需要知道"这张表的核心字段、上游依赖、风险点",不需要把 3000 行 DDL、几十条血缘、23 条自测 SQL 的完整日志全部塞进来。
适合交给 subagent 的任务有:
- 读取大量 DDL、接口文档、日志、血缘;
- 跑测试并分析失败原因;
- 做 SQL 校验、代码审查、安全扫描;
- 并行探索多个方案;
- 整理一个模块的上下游关系。
主会话应该拿到的是结构化摘要:
text
状态:FAIL
关键问题:
1. insert_user_order.sql 第 42 行缺少 partition_dt 分区
2. amount 字段使用 double,建议 decimal(20,4)
3. 下游 dws_order_summary 依赖 order_status 口径,需人工确认
证据:
- logs/self-test-2026-05-21.txt
- ddl/dwd_order.sql这样主会话保持干净,Agent 的全局决策也更稳定。
4. Skills:不要每次重新解释团队 SOP
Skill 更像 SOP,不是 Prompt 模板。
一个好的 Skill 应该说明:
- 什么场景触发;
- 按什么步骤做;
- 需要调用哪些工具;
- 每一步产出什么;
- 如何验证质量;
- 失败时如何回滚或升级。
比如一个后端接口变更 Skill,可以包含:
text
1. 定位 Controller / Service / Mapper
2. 检查鉴权、幂等、分页、参数校验
3. 修改接口实现
4. 补单测或集成测试
5. 跑相关测试
6. 输出影响范围和回滚说明这比"你是资深 Java 工程师,请注意代码质量"稳定得多。
四、一个数仓 Harness 怎么落地
微信原文里得物技术的案例很有代表性:数仓团队用 Claude Code 做研发提效,但真正的问题不是"AI 会不会写 SQL",而是"AI 能不能稳定遵守数仓研发流程"。
数仓任务天然适合讲 Harness,因为它同时具备:
- 强业务口径;
- 强规范约束;
- 大量上下游血缘;
- 大量自测和比对结果;
- 高风险上线动作;
- 需要人工确认的例外。
一个可落地的 8 步链路可以这样拆:
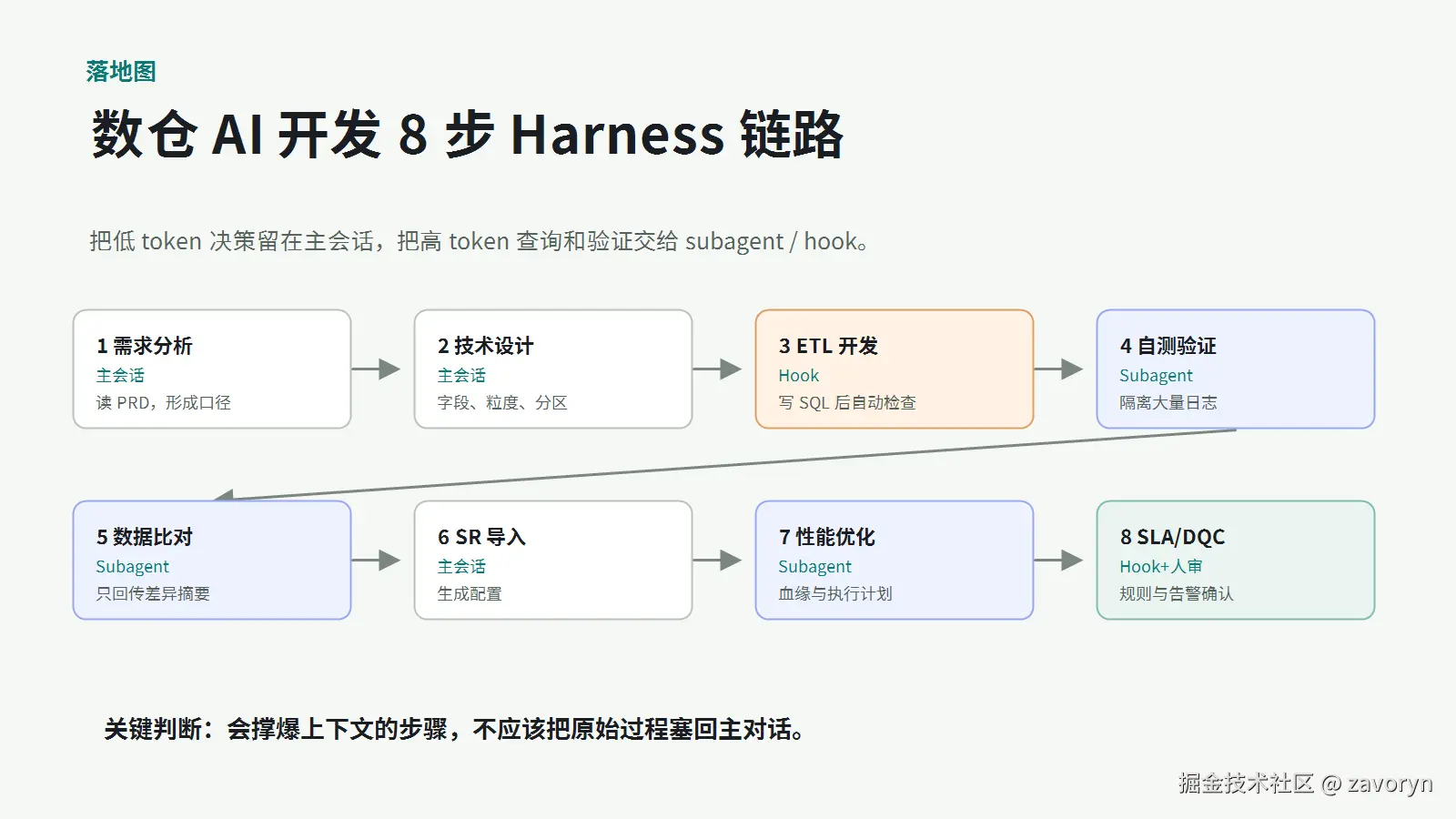
| 步骤 | 建议运行方式 | 原因 |
|---|---|---|
| 需求分析 | 主会话 | 需要理解业务目标和口径 |
| 技术设计 | 主会话 | 需要人类参与取舍 |
| ETL 开发 | 主会话 + PostToolUse hook |
写 SQL 后自动检查规范 |
| 自测验证 | Subagent | 日志多,容易污染上下文 |
| 数据比对 | Subagent | 样本和差异明细多,只回传摘要 |
| SR 导入 | 主会话 | 结构化生成配置 |
| 性能优化 | Subagent | 血缘、执行计划、DDL token 大 |
| SLA / DQC | Hook + 人审 | 规则可自动生成,但阈值要确认 |
这里的重点不是把流程画得很复杂,而是把不同类型的工作交给合适的位置。
低 token、需要全局判断的工作留在主会话;高 token、可摘要的工作交给 subagent;确定性规范交给 hook;高风险决策交给人类确认。
五、后端项目也可以这样做
你不做数仓,也一样能用这套思想。
比如一个 Java 后端项目,可以先做一个最小 Harness:
text
.claude/
├── CLAUDE.md
├── settings.json
├── hooks/
│ ├── block-dangerous-command.ps1
│ └── run-quality-gate.ps1
├── agents/
│ ├── code-reviewer.md
│ └── log-analyzer.md
└── rules/
├── api-style.md
└── database-change.md第一步,写 CLAUDE.md。
不要写成百科全书,只写最关键的项目事实:
- 项目模块边界;
- 运行和测试命令;
- 不允许直接修改的目录;
- 数据库变更规范;
- 接口返回格式;
- 当前迭代状态。
第二步,加 PreToolUse。
先拦截危险动作:
- 删除生产目录;
- 批量删除文件;
- 直接操作生产库;
- 修改敏感配置;
- 执行未确认的迁移脚本。
第三步,加 PostToolUse。
写完代码后自动跑最小质量门禁:
- Java 格式化;
- 单测;
- SQL 检查;
- OpenAPI 校验;
- 关键包的静态扫描。
第四步,加 subagent。
把这些任务隔离出去:
- "分析最近 500 行错误日志";
- "审查这个模块的接口幂等问题";
- "读取所有 Mapper XML 并总结 SQL 风险";
- "比较两种方案的影响范围"。
第五步,把高频流程沉淀成 Skill。
比如:
- 新增接口 Skill;
- 修改数据库字段 Skill;
- 排查线上报错 Skill;
- 接入第三方平台 Skill;
- 编写发布说明 Skill。

落地顺序一定要克制:先恢复状态,再自动检查,最后再做复杂编排。
六、面试怎么答
如果面试官问:"你怎么理解 Agent Harness?"可以按四段答。

第一段,先定义:
Harness 是 Agent 的运行底座,位于模型和外部环境之间,负责上下文管理、工具调用、权限边界、生命周期事件、子代理调度、记忆持久化和可观测性。
第二段,讲为什么需要:
复杂任务里,单靠 Prompt 会遇到上下文失忆、规范执行不稳定、工具调用有风险、长任务过程不可恢复等问题。Harness 把这些问题从"模型记不记得"转成"系统能不能保证"。
第三段,讲架构:
可以拆成 Memory、Hooks、Subagents、Skills 四类能力。Memory 保存状态,Hooks 做确定性门禁,Subagents 隔离高 token 任务,Skills 固化团队 SOP。
第四段,讲落地:
落地时先从
CLAUDE.md和 hook 做起,先解决状态恢复和危险动作拦截;再把日志分析、代码审查、数据比对等高 token 任务交给 subagent;最后把高频研发流程沉淀成 Skill。
这套回答比"Agent 可以自己调用工具完成任务"更像工程回答,因为它讲清楚了边界、风险和治理方式。
七、常见误区
| 误区 | 正确认知 |
|---|---|
| Harness 就是更长的 Prompt | Prompt 是输入技巧,Harness 是运行时工程结构 |
| Hook 会限制模型发挥 | Hook 限制的是危险动作和低级错误,不限制语义推理 |
| Subagent 越多越好 | 只有高 token、可隔离、可摘要的任务才适合分出去 |
| Memory 等于保存聊天记录 | Memory 应该保存可复用的状态和经验,不是无限堆历史 |
| Agent 自动化越彻底越好 | 高风险决策仍然需要人工确认和审计 |
总结
Agent 工程化的重点,不是让模型记更多,而是让系统替它守住关键边界。
Prompt 能解决"这一次怎么说清楚";Harness 解决"很多次任务怎么稳定运行"。当 Agent 进入真实研发流程,真正重要的不只是生成能力,而是状态能恢复、规范能检查、危险能阻断、过程能审查、结果能复盘。
一句话记住:
Harness 不是 Prompt,而是 Agent 从 Demo 走向生产的工程化底座。
参考资料
- 得物技术:《Claude Code Harness 工程:数仓侧落地方案》:mp.weixin.qq.com/s/KmQJU7nXm...
- Claude Code Hooks 文档:code.claude.com/docs/en/hoo...
- Claude Code Subagents 文档:code.claude.com/docs/en/sub...
- OpenAI Agents SDK Agents 文档:openai.github.io/openai-agen...
- OpenAI Agents SDK Guardrails 文档:openai.github.io/openai-agen...
- LangGraph Overview:docs.langchain.com/oss/python/...
- Google ADK Memory 文档:adk-labs.github.io/adk-docs/se...
- Microsoft Agent Framework 文档:learn.microsoft.com/en-us/agent...
- Agent Workflow Memory 论文:arxiv.org/abs/2409.07...