
基于贝叶斯优化超参数的图卷积网络(BO-GCN)分类模型
本文介绍一种将**贝叶斯优化(Bayesian Optimization)与图卷积网络(GCN)**相结合的分类方法,通过智能超参数搜索实现分类性能的自动优化。
一、背景与动机
在机器学习建模过程中,超参数的选择往往决定了模型的最终性能。传统做法依赖人工经验反复试错,不仅耗时耗力,而且难以找到全局最优组合。
图卷积网络(GCN)作为处理图结构数据的强大工具,在节点分类、图分类等任务中表现出色。然而,GCN的超参数(如隐层维度、学习率、训练轮次等)对模型性能影响显著,手动调参效率低下。
本文提出的 BO-GCN 框架,利用贝叶斯优化自动搜索GCN的最优超参数组合,实现了"一键调参",让模型训练更加高效和智能。
二、整体流程
整个BO-GCN分类模型的流程可以概括为以下五个步骤:
数据预处理 → 图结构构建 → 贝叶斯优化超参数 → 最优模型训练 → 性能评估下面逐一展开介绍。
三、数据预处理
3.1 数据读取与划分
模型从Excel文件中读取样本数据,其中最后一列为类别标签,其余列为输入特征。数据预处理包括:
- 随机打乱:对样本顺序进行随机重排,消除数据排列带来的偏差
- 分层划分:按类别比例将数据划分为训练集(70%)和测试集(30%),确保各类别在两个集合中比例一致
- 归一化:将特征映射到 0, 1 区间,加速模型收敛
3.2 关键代码逻辑
matlab
% 按类别分层划分
for i = 1 : num_class
mid_res = res((res(:, end) == i), :);
mid_tiran = round(0.7 * size(mid_res, 1));
% 前70%进入训练集,后30%进入测试集
end
% 归一化到 [0, 1]
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);四、图结构构建
GCN的核心在于利用样本间的拓扑关系 进行信息传递。本文采用Spearman秩相关系数来衡量样本之间的相似性,构建邻接矩阵:
matlab
ATrain_full = corr(P_train', 'type', 'Spearman');为什么选择Spearman相关系数?
- 对非线性关系具有更好的捕捉能力
- 对异常值具有鲁棒性
- 基于秩次计算,不依赖数据的绝对数值
邻接矩阵 A 描述了样本间的相似性关系,是GCN消息传递的基础------每个样本的表示会通过邻接矩阵聚合其"邻居"的信息。
五、贝叶斯优化超参数搜索
5.1 什么是贝叶斯优化?
贝叶斯优化是一种高效的全局黑箱优化方法,特别适合评估成本高昂的超参数搜索问题。其核心思想是:
| 组件 | 说明 |
|---|---|
| 代理模型(Surrogate) | 使用高斯过程(GP)对目标函数建模,给出每个点的预测均值和不确定性 |
| 采集函数(Acquisition) | 基于代理模型的后验分布,平衡"探索"(高不确定性区域)和"利用"(低目标值区域) |
| 迭代更新 | 选择采集值最大的超参数组合进行真实评估,将结果反馈给代理模型,循环往复 |
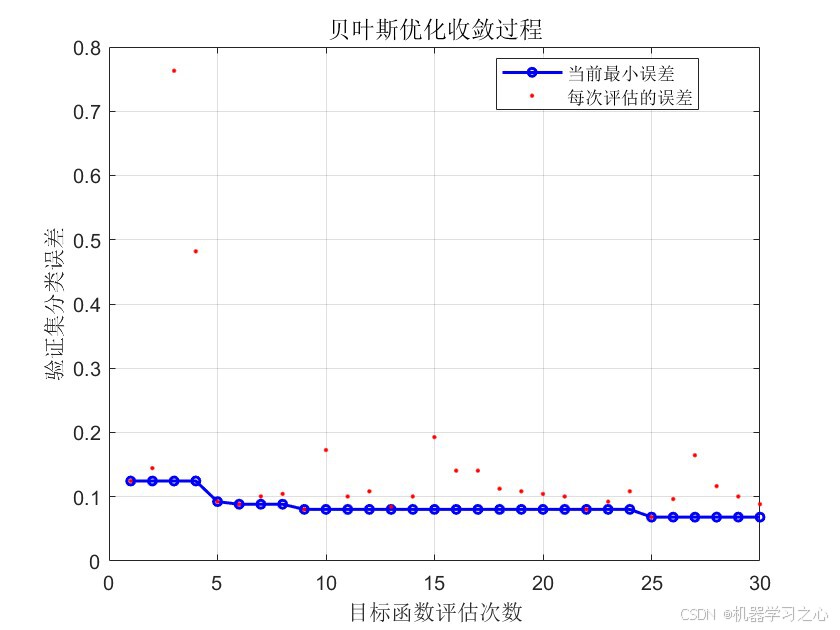
相比网格搜索和随机搜索,贝叶斯优化的优势在于:用更少的评估次数找到更优的超参数组合。
5.2 搜索空间定义
本文对以下三个关键超参数进行优化:
| 超参数 | 搜索范围 | 类型 | 说明 |
|---|---|---|---|
numHiddenFeatureMaps |
16, 128 | 整数 | 隐藏层特征维度 |
learnRate |
1e-4, 1e-1 | 对数尺度 | Adam优化器学习率 |
numEpochs |
200, 2000 | 整数 | 训练迭代次数 |
matlab
optimVars = [
optimizableVariable('numHiddenFeatureMaps', [16, 128], 'Type', 'integer')
optimizableVariable('learnRate', [1e-4, 1e-1], 'Transform', 'log')
optimizableVariable('numEpochs', [200, 2000], 'Type', 'integer')
];设计亮点:学习率采用对数尺度搜索,因为学习率的合理取值往往跨越多个数量级,对数尺度能更均匀地覆盖有效区域。
5.3 优化执行
使用 expected-improvement-plus 采集函数,最大评估次数设为30次:
matlab
results = bayesopt(objFcn, optimVars, ...
'MaxObjectiveEvaluations', 30, ...
'AcquisitionFunctionName', 'expected-improvement-plus', ...
'IsObjectiveDeterministic', false, ...
'PlotFcn', {@plotMinObjective, @plotElapsedTime}, ...
'Verbose', 1);其中 IsObjectiveDeterministic 设为 false,以应对训练过程中随机性带来的影响。
六、GCN网络结构
6.1 网络架构
模型采用四层结构,包含三个图卷积层和一个分类全连接层:
输入 X → [图卷积层1 + 残差] → [图卷积层2 + 残差] → [图卷积层3] → [分类层] → 输出 Y6.2 核心代码
matlab
function Y = model(parameters, X, A)
Z1 = X;
% 图卷积层1:A·Z1·W + 残差连接
Z2 = pagemtimes(pagemtimes(A, Z1), parameters.mult1.Weights);
Z2 = relu(Z2) + Z1; % ReLU激活 + 残差连接
% 图卷积层2:A·Z2·W + 残差连接
Z3 = pagemtimes(pagemtimes(A, Z2), parameters.mult2.Weights);
Z3 = relu(Z3) + Z2; % ReLU激活 + 残差连接
% 图卷积层3:A·Z3·W → 标量输出
Z4 = pagemtimes(pagemtimes(A, Z3), parameters.mult3.Weights);
Z4 = squeeze(Z4);
% 分类层:全连接 + Softmax
Z5 = parameters.mult4.Weights' * Z4;
Y = softmax(Z5, DataFormat="BC")';
end6.3 设计亮点
- 残差连接(Residual Connection) :前两层采用
relu(Z) + Z_prev的残差结构,有效缓解深层网络的梯度消失问题,使信息能够更顺畅地流动 - Glorot初始化:权重采用Glorot均匀分布初始化,根据输入/输出维度自适应调整初始化范围,有利于训练稳定性
- Adam优化器:使用自适应矩估计优化器,自动调节各参数的学习步长
七、损失函数
模型使用**交叉熵损失(Cross-Entropy Loss)**作为训练目标:
matlab
function [loss, gradients] = modelLoss(parameters, X, A, T)
Y = model(parameters, X, A);
loss = crossentropy(Y, T, DataFormat="BC");
gradients = dlgradient(loss, parameters);
end利用MATLAB的自动微分(dlfeval + dlgradient)高效计算损失和梯度,无需手动推导反向传播公式。
八、实验结果
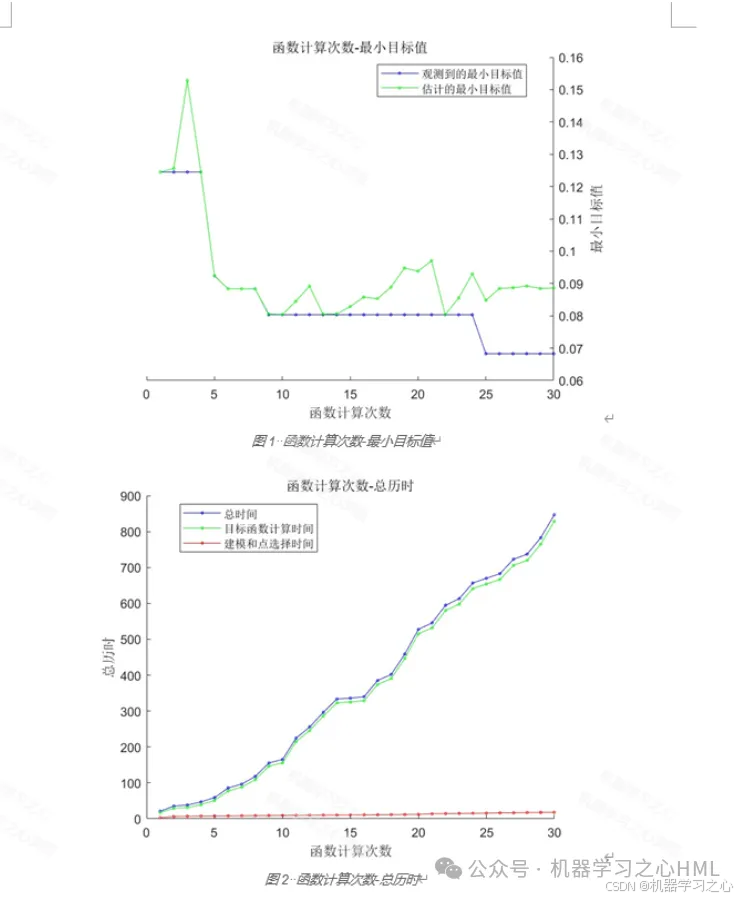
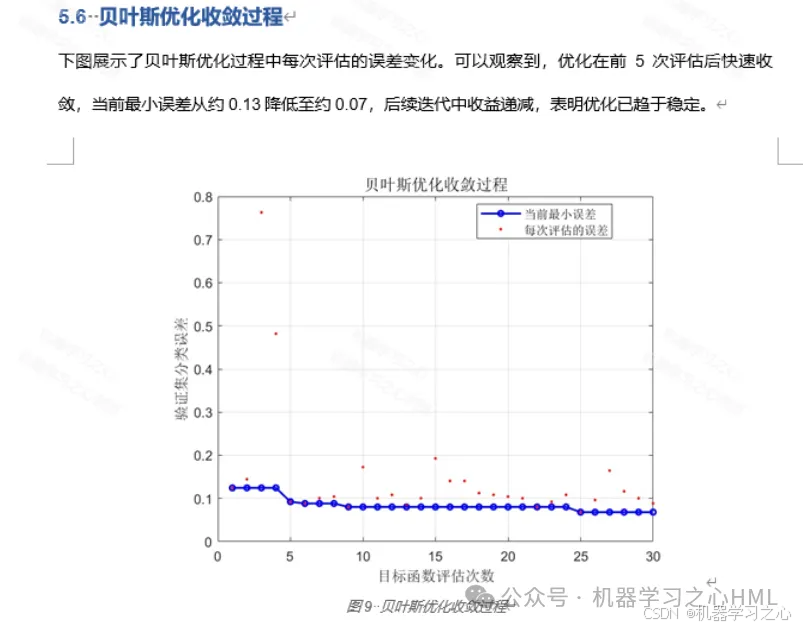
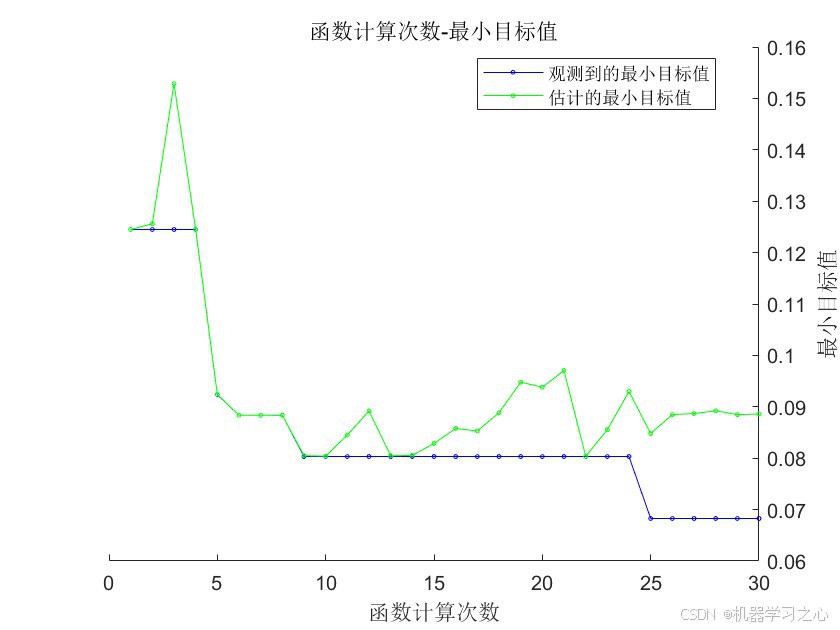
8.1 贝叶斯优化结果
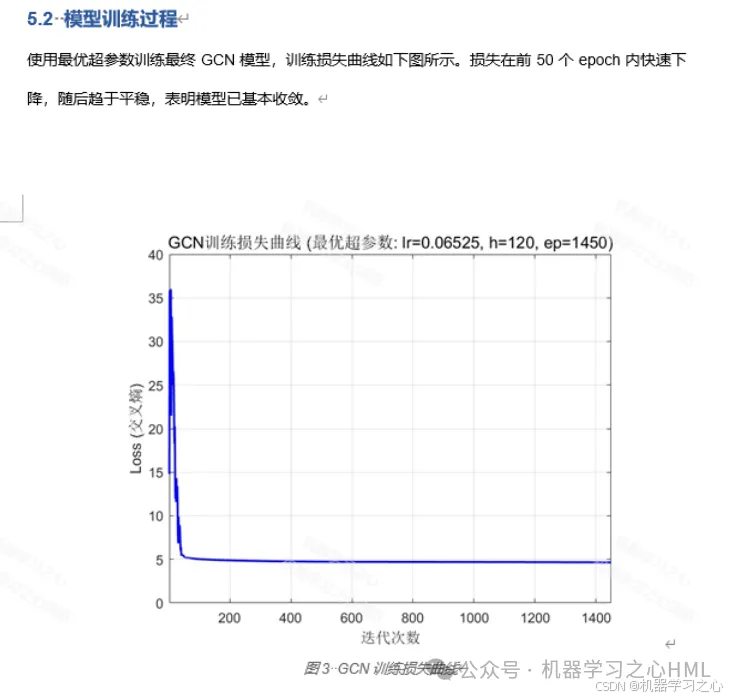
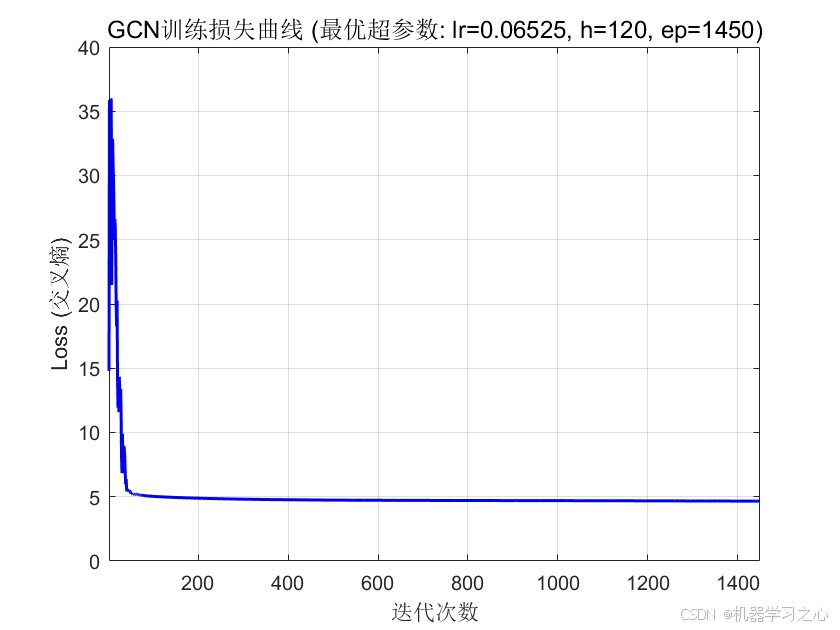
经过30次迭代评估,贝叶斯优化搜索到的最优超参数组合为:
| 超参数 | 最优值 |
|---|---|
| 隐层特征数 | 120 |
| 学习率 | 0.065247 |
| 训练迭代数 | 1450 |
| 最小训练误差 | 0.0683 |
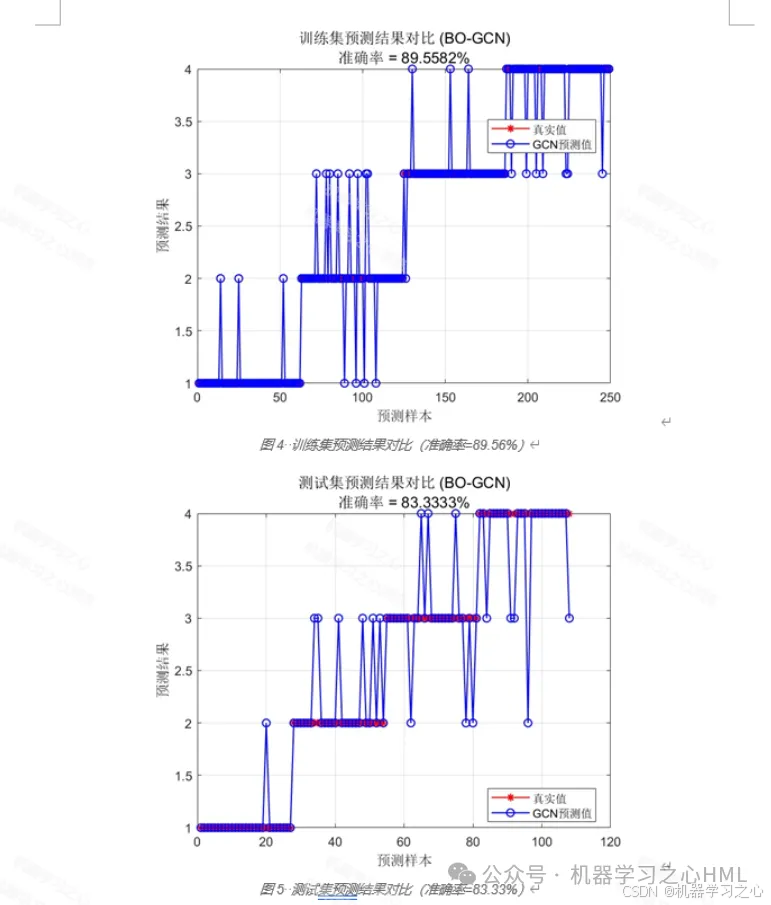
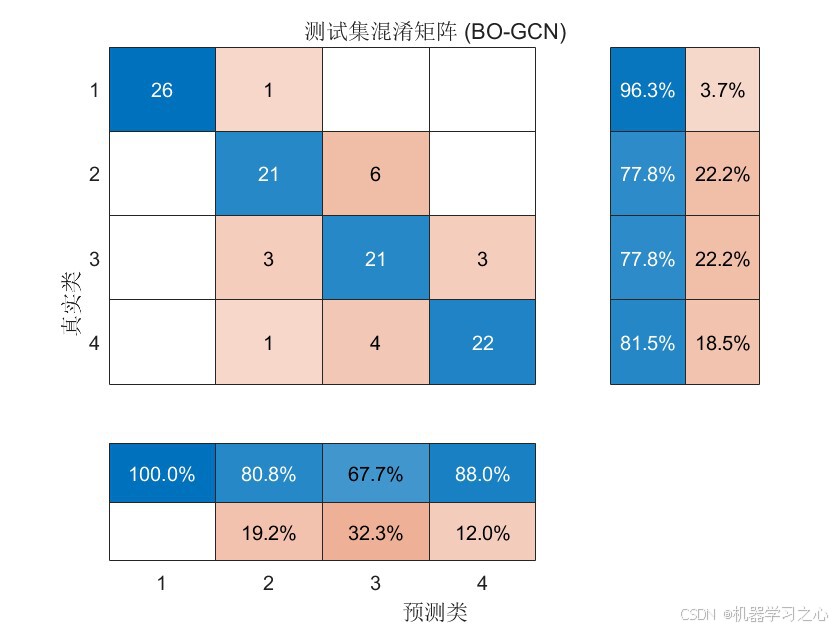
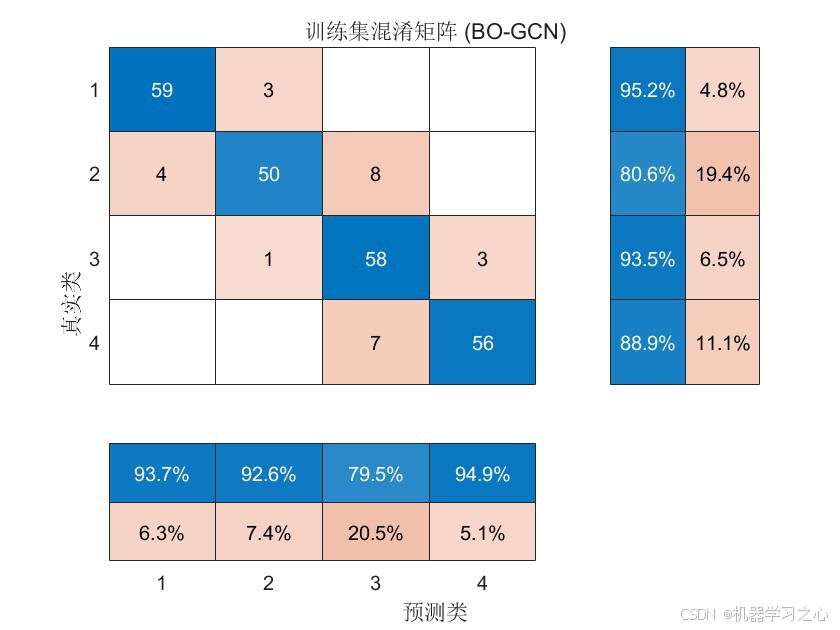
8.2 分类性能
| 指标 | 值 |
|---|---|
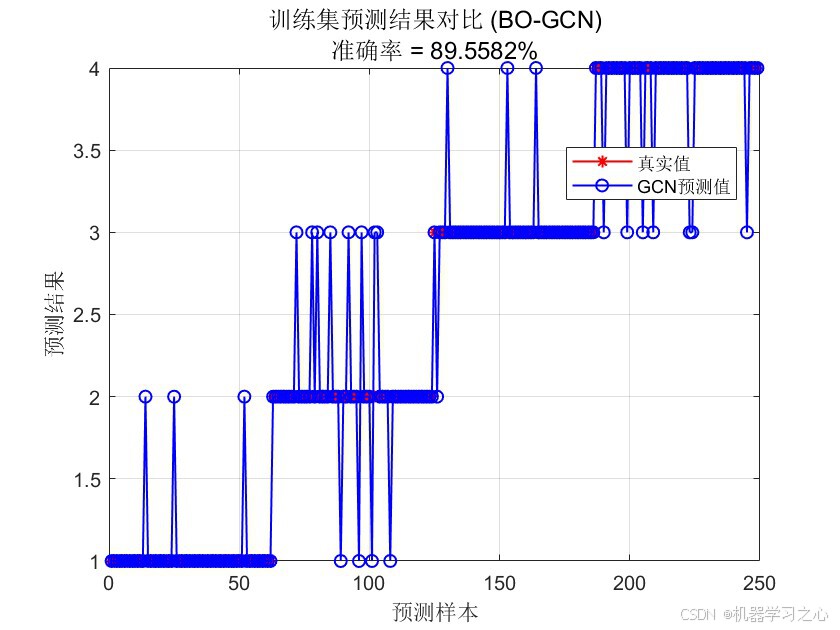
| 训练集准确率 | 89.56% |
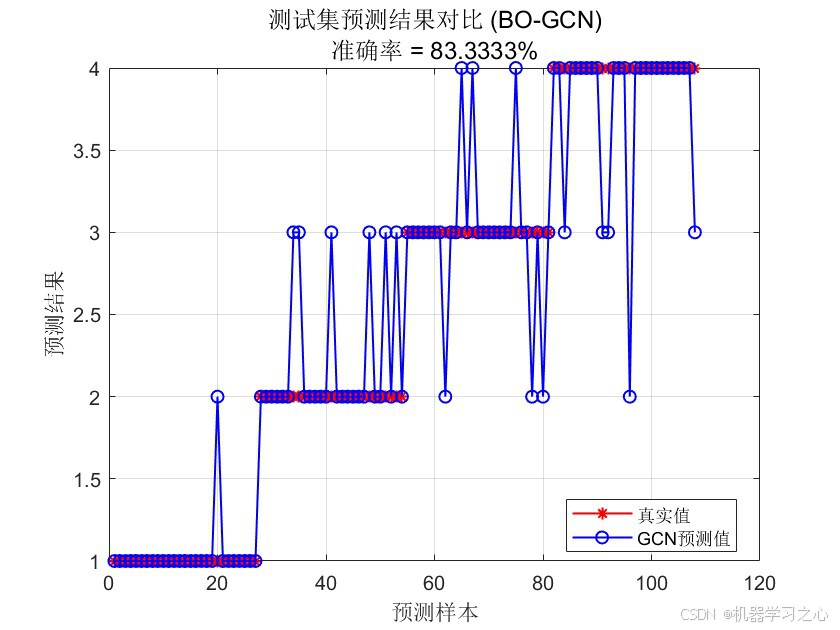
| 测试集准确率 | 83.33% |
| 灵敏度(SE) | 0.81 |
| 特异性(SP) | 0.96 |
| AUC | 0.94 |
| Kappa系数 | 0.79 |
| F-measure | 0.88 |
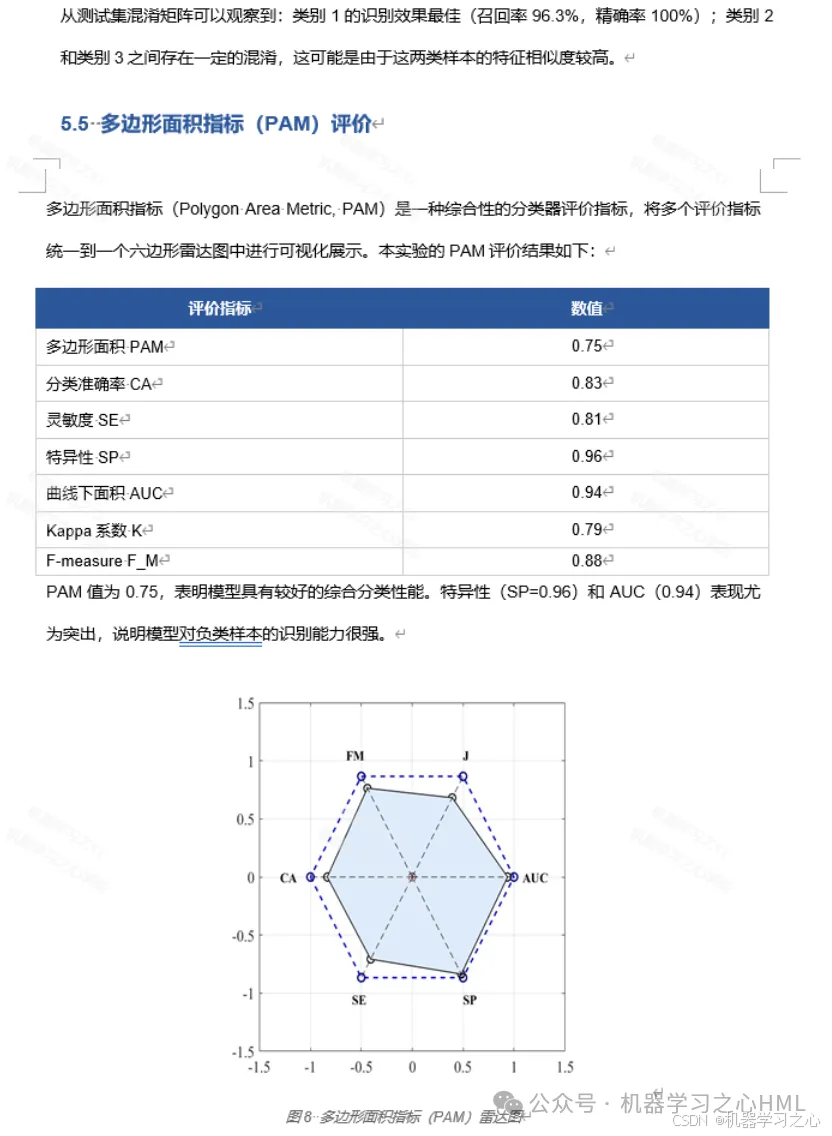
| PAM(多边形面积指标) | 0.75 |
8.3 结果分析
- 测试集准确率达83.33%,表明模型具有良好的泛化能力
- 特异性高达0.96,说明模型对负类的识别能力极强
- AUC为0.94,接近理想值1.0,证明模型具有优秀的区分能力
- 训练集与测试集准确率差距约6%,未出现严重过拟合
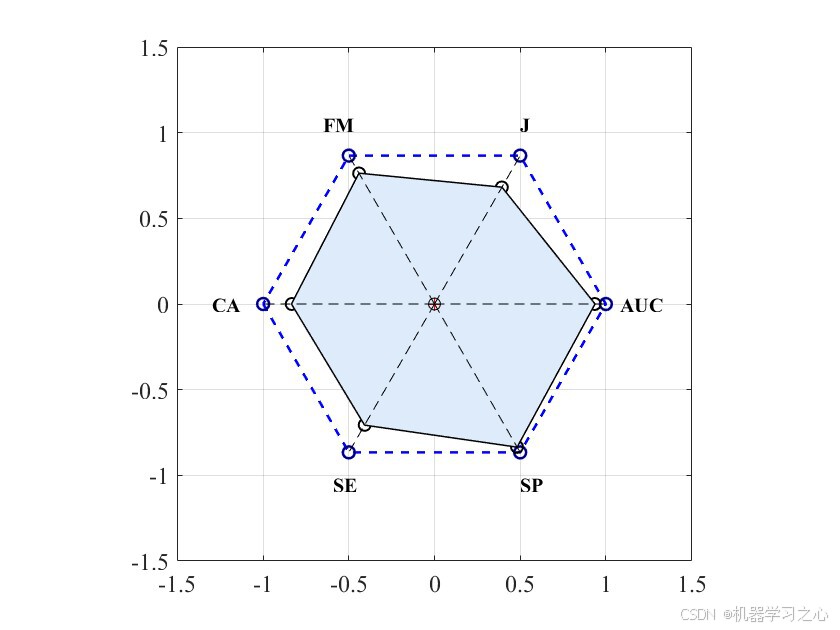
九、多维度评估:PAM指标
除了常规的分类指标外,本文还引入了**多边形面积指标(Polygon Area Metric, PAM)**进行综合评估。
PAM将分类准确率(CA)、灵敏度(SE)、特异性(SP)、AUC、Kappa系数和F-measure六个指标映射到正六边形的六个顶点上,通过计算多边形面积来综合反映分类器性能:
- PAM值越接近1,表示各维度表现越均衡、综合性能越好
- 本模型PAM = 0.75,说明在多个评价维度上均取得了较好的平衡
十、可视化输出
模型训练完成后,自动生成以下可视化图表:
- 训练损失收敛曲线 --- 展示模型训练过程中损失函数的下降趋势
- 贝叶斯优化收敛曲线 --- 展示BO搜索过程中目标值的变化
- 训练集/测试集预测结果对比图 --- 直观对比真实值与预测值
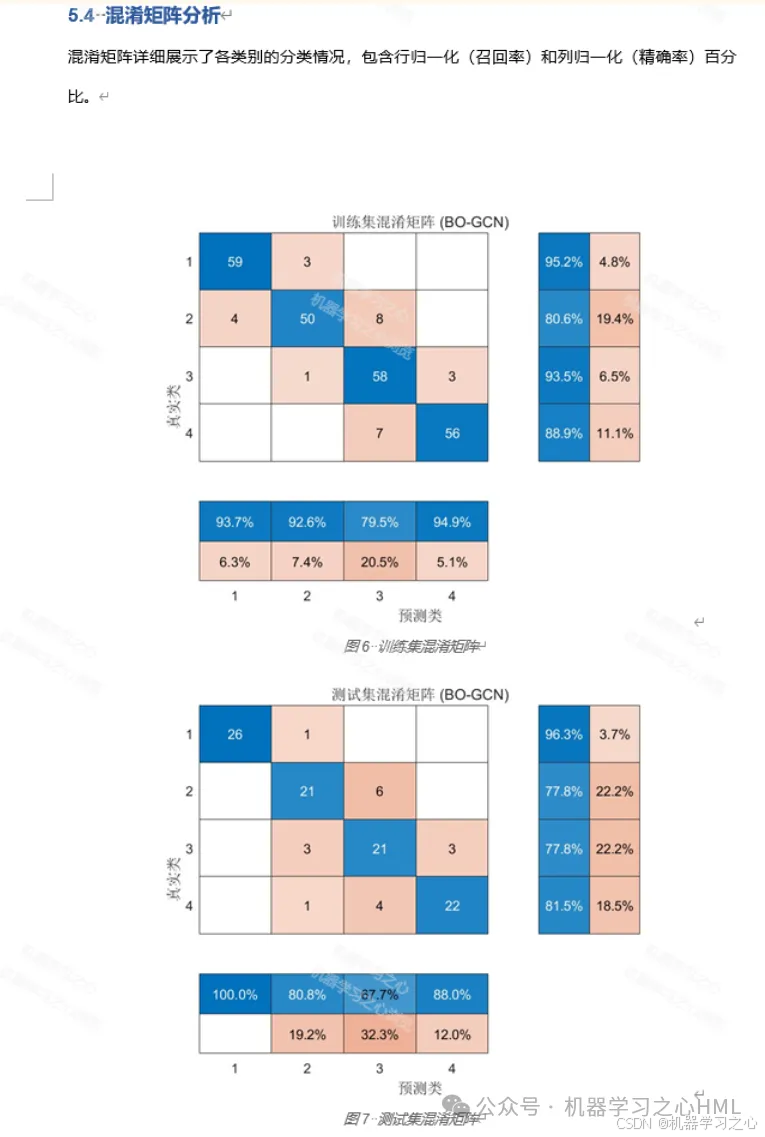
- 混淆矩阵 --- 展示各类别的分类详情
- PAM六边形图 --- 多维度综合评估可视化
十一、技术总结
核心创新点
| 创新点 | 说明 |
|---|---|
| BO + GCN 融合 | 首次将贝叶斯优化应用于GCN超参数搜索,实现自动化调参 |
| Spearman图构建 | 基于秩相关系数构建样本关系图,增强对非线性关系的捕捉 |
| 残差图卷积 | 在图卷积中引入残差连接,提升深层网络的信息传递效率 |
| 多维评估体系 | 结合PAM等多指标进行全面评估,避免单一指标的片面性 |
适用场景
- 样本数量与特征维度匹配的中小规模分类任务
- 需要挖掘样本间隐含关系的分类问题
- 对模型可解释性和调参效率有较高要求的场景
运行环境
- MATLAB R2020b及以上
- 需要Statistics and Machine Learning Toolbox、Deep Learning Toolbox
十二、代码文件说明
| 文件名 | 功能 |
|---|---|
BO_GCN_main.m |
主程序:数据预处理、BO优化、模型训练与评估 |
BO_objective.m |
贝叶斯优化目标函数:构建并评估给定超参数下的GCN |
model.m |
GCN前向传播模型:四层网络结构定义 |
modelLoss.m |
损失函数与梯度计算:交叉熵 + 自动微分 |
initializeGlorot.m |
Glorot权重初始化 |
polygonareametric.m |
PAM多边形面积综合评价指标 |
本文代码完整可运行,欢迎交流讨论!