目录
1.摘要
针对具有障碍约束与风力干扰的不规则3D环境,本文提出一种融合强化学习的流形感知差分进化算法(MTCMDE),由探索、开发及平衡子种群组成的三层协同演化框架;引入流形感知微扰算子利用局部拓扑信息;基于多臂老虎机模型构建强化学习驱动多算子方案,实现变异策略自适应分配。
2.背景知识
三维路径规划
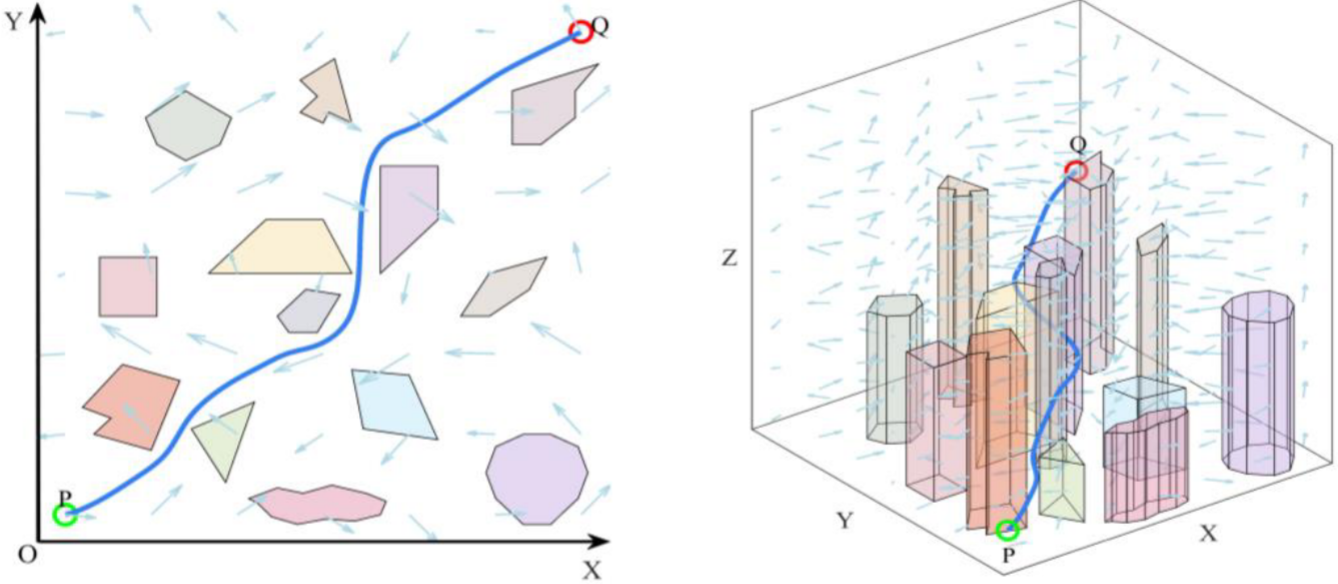
三维路径规划在规避威胁区域 Γ \Gamma Γ的前提下,规划一条自起点至终点的可行路径 Θ = { P 1 , P 2 , ... , P N } \Theta=\{P_1,P_2,\ldots,P_N\} Θ={P1,P2,...,PN}:
min f ( Θ ) = ∑ i = 1 M ω i ⋅ f i ( Θ ) s . t . P ∩ Γ = ∅ \min f(\Theta)=\sum_{i=1}^M\omega_i\cdot f_i(\Theta)\quad\mathrm{s.t.}\quad P\cap\Gamma=\emptyset minf(Θ)=i=1∑Mωi⋅fi(Θ)s.t.P∩Γ=∅
其中, f i ( Θ ) f_i(\Theta) fi(Θ)为第 i i i项评估指标的性能代价。
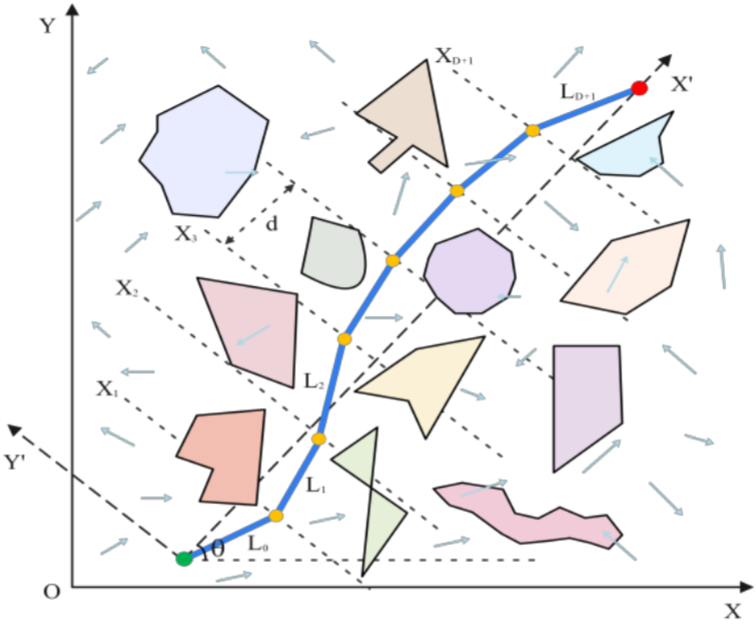
针对包含大量不规则多面体障碍物及动态风场干扰的复杂空间,研究通过将起点与终点的连线对齐为新坐标系的 X ′ X^{\prime} X′轴,将整条轨迹均匀划分为 D + 1 D+1 D+1段 (段长记为 L k L_k Lk)。
3.MTCMDE算法
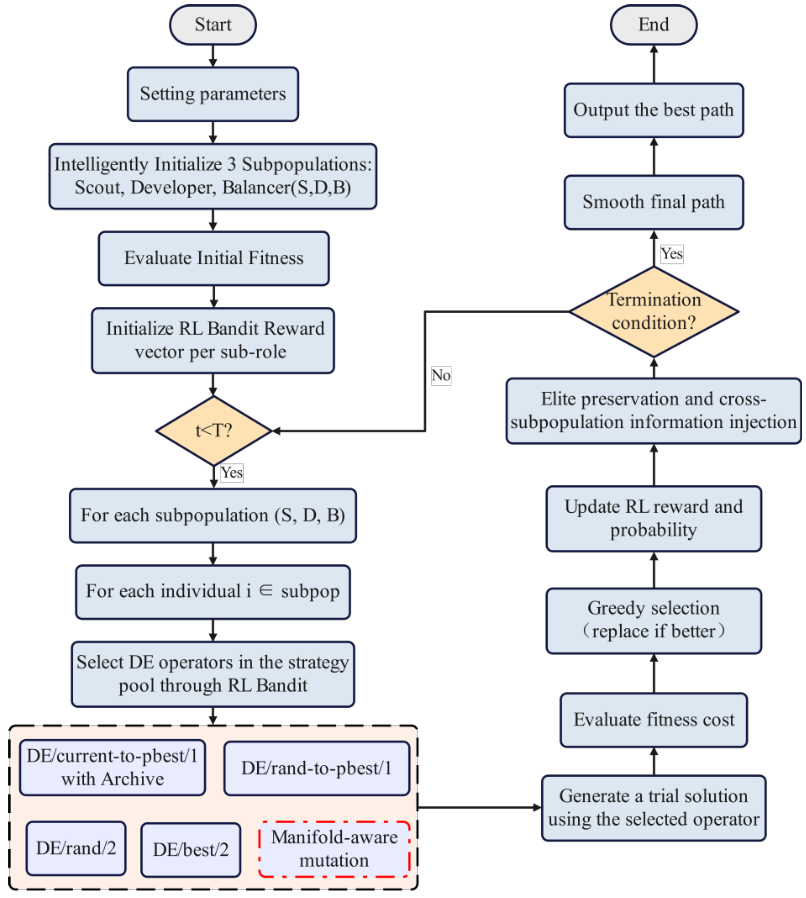
多子群分工与协同
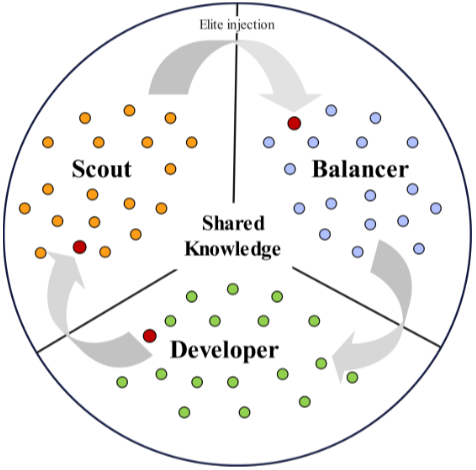
三子群并行协同演化框架通过环形精英注入机制实现子群间的信息交互,这种基于环形结构的知识共享与精英迁移,结合强化学习驱动的流形感知变异算子自适应选择。
基于上下文多臂老虎机的强化学习策略选择
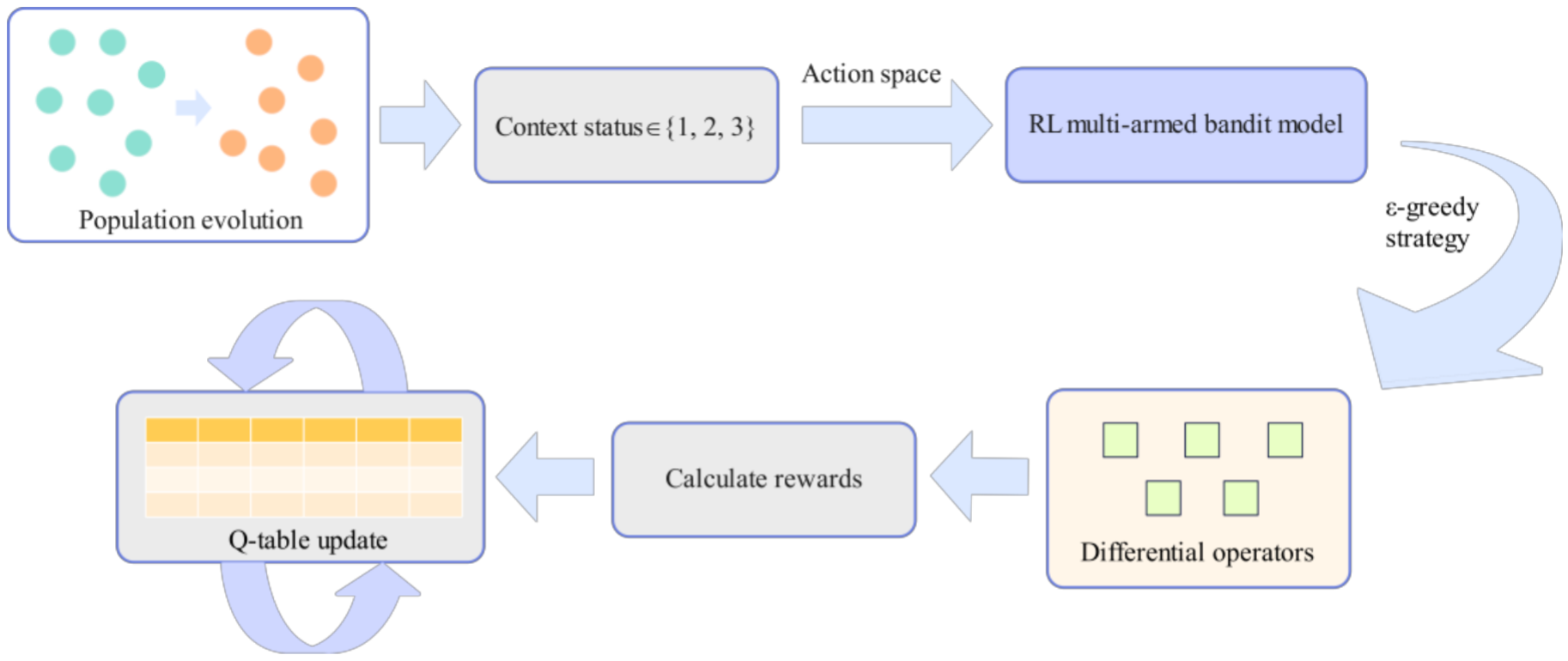
将演化进程划分为前 ( p ≤ 0.3 ) (p\leq0.3) (p≤0.3) 、中 (0.3<
p ≤ 0.7 p\leq0.7 p≤0.7)、后 ( p > 0.7 ) (p>0.7) (p>0.7)三个阶段作为上下文状态 s ∈ { 1 , 2 , 3 } s\in\{1,2,3\} s∈{1,2,3}。
选择机制表示为:
a = { Uniform ( 1 , ... , 5 ) , ϵ arg max a Q ( s , a ) , 1 − ϵ a=\begin{cases}\text{Uniform}(1,\ldots,5),&\epsilon\\\arg\max_aQ(s,a),&1-\epsilon\end{cases} a={Uniform(1,...,5),argmaxaQ(s,a),ϵ1−ϵ
算子作用于个体 x i x_i xi生成试验解 ρ i \rho_i ρi后,利用归一化适应度增益作为即时奖励 r i r_i ri ,用于衡量性能提升幅度:
r i = J ( x i ) − J ( ρ i ) J ( x i ) + δ r_i=\frac{J(x_i)-J(\rho_i)}{J(x_i)+\delta} ri=J(xi)+δJ(xi)−J(ρi)
其中, J ( ⋅ ) J(\cdot) J(⋅)极为复合适应度值,利用学习率 γ ∈ ( 0 , 1 ] \gamma\in(0,1] γ∈(0,1]迭代更新动作价值函数 Q ( s , a ) Q(s,a) Q(s,a),实现阶段感知策略自适应调度:
Q ( s , a ) ← Q ( s , a ) + γ ( r i − Q ( s , a ) ) Q(s,a)\leftarrow Q(s,a)+\gamma\left(r_i-Q(s,a)\right) Q(s,a)←Q(s,a)+γ(ri−Q(s,a))
流形感知变异
流形感知变异算将不规则障碍物边界的几何斥力转化为拓扑伪梯度先验,引导搜索轨迹沿可行流形表面滑动。算法结合演化进度 η = g / g m a x \eta=g/g_\mathrm{max} η=g/gmax与子群角色,引入自适应微扰强度 ξ : \xi: ξ:
ξ e x p l o r e = α ⋅ ( 1 − η ) , ξ e x p l o i t = β ⋅ η \xi_{\mathrm{explore}}=\alpha\cdot(1-\eta),\quad\xi_{\mathrm{exploit}}=\beta\cdot\eta ξexplore=α⋅(1−η),ξexploit=β⋅η
各子群依其角色实施差异化微扰更新
v i = { v i + τ ⋅ U − ξ explore ; ξ explore ⋅ ( x r 1 − x r 2 ) , Scout v i + τ ⋅ U − ξ exploit , ξ exploit ⋅ ( x r 1 − x r 2 ) , Developer v i + τ ⋅ sin ( π 2 ⋅ η ) + ξ explore ⋅ ( x r 1 − x r 2 ) , Balancer \mathbf{v}i=\begin{cases}\mathbf{v}i+\tau\cdot U-\\xi_\\text{explore};\\xi_\\text{explore}\cdot(\mathbf{x}{r1}-\mathbf{x}{r2}),&\text{Scout}\\\mathbf{v}i+\tau\cdot U-\\xi_\\text{exploit},\\xi_\\text{exploit}\cdot(\mathbf{x}{r1}-\mathbf{x}{r2}),&\text{Developer}\\\mathbf{v}i+\tau\cdot\left\\sin\\left(\\frac\\pi2\\cdot\\eta\\right)+\\xi_\\text{explore}\\right\cdot(\mathbf{x}{r1}-\mathbf{x}{r2}),&\text{Balancer}\end{cases} vi=⎩ ⎨ ⎧vi+τ⋅U−ξexplore;ξexplore⋅(xr1−xr2),vi+τ⋅U−ξexploit,ξexploit⋅(xr1−xr2),vi+τ⋅sin(2π⋅η)+ξexplore⋅(xr1−xr2),ScoutDeveloperBalancer
4.结果展示
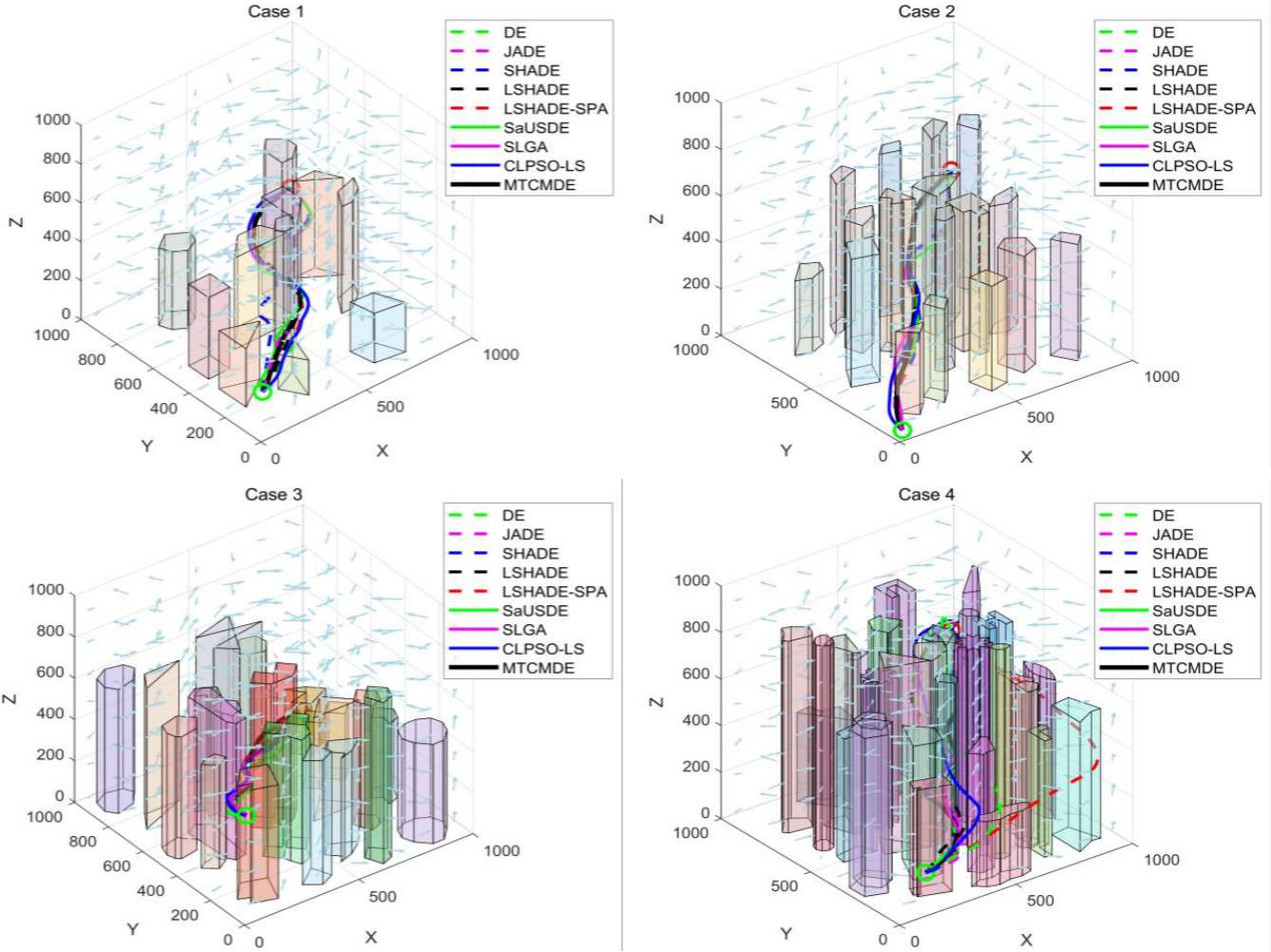
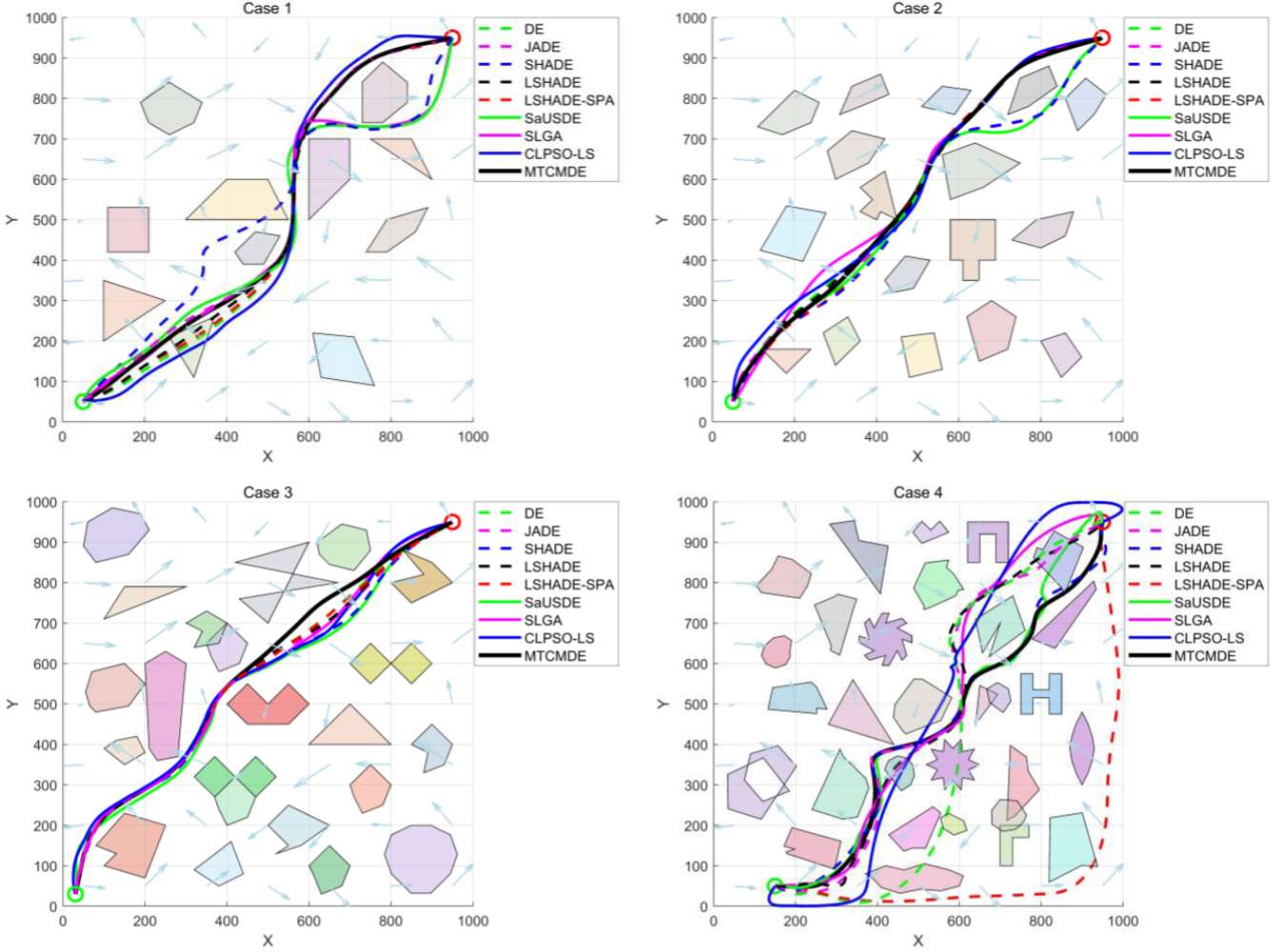
5.参考文献
Zhang Y, Du G, Tang H, et al. Manifold-Aware Triple Cooperative Multi-Population Differential Evolution with Reinforcement Learning for Irregular 3D UAV Path PlanningJ. Knowledge-Based Systems, 2026: 115863.
6.代码获取
xx
7.算法辅导·应用定制·读者交流
xx