小编使用的是在安全机制下的跨集群能力探查,大家在链接的时候一定会经历安全机制之间的互信问题(针对于ccr的问题,其实就是调整transport证书问题),下面为大家带来了一个视频讲解和一个文章,大家可以根据这两个资料来解决这个问题:
Elasticsearch:如何为 CCR 及 CCS 建立带有安全的集群之间的互信_elasticsearch ccr 互信-CSDN博客
Elasticsearch:如何为 CCR 及 CCS 建立带有安全的集群之间的互信_哔哩哔哩_bilibili
对于CA证书的问题:
Elasticsearch:使用不同的 CA 更新安全证书 (一)_elastic-certificates.p12-CSDN博客
Elasticsearch:使用不同的 CA 更新安全证书 (二)_elasticsearch-certutil-CSDN博客
一、Cross cluster 跨集群概要介绍:
跨集群(Cross Cluster)是分布式检索与大数据架构中多集群协同的核心技术体系,广泛应用于Elasticsearch、OpenSearch等搜索引擎,核心作用是打破单集群资源、地域、业务隔离限制,将多个物理独立、网络互通的集群,构建为逻辑统一的分布式数据服务体系。
在企业实际架构中,常因业务拆分、异地部署、环境隔离(生产/测试/离线)、容灾备份等需求,部署多套独立集群。跨集群技术通过统一的集群互联协议,实现多集群的查询、更新、索引重建、数据同步等协同操作,无需人工迁移数据、切换集群入口,大幅提升分布式架构的可用性、扩展性与容灾能力。
整体核心能力可分为四大模块:跨集群数据查询、跨集群数据更新、跨集群重建索引、跨集群数据复制,四大能力各司其职,分别对应实时检索、远程写入、索引运维、数据同步容灾四大业务场景。
集群连接配置:
跨集群连接配置,用于让本地集群 发现并连接远程集群,实现跨集群通信。
集群连接配置有三种方式,分别是静态配置集群连接,动态配置和kibana可视化配置
| 配置方式 | 是否需要重启 | 生效速度 | 适用场景 | 推荐度 |
|---|---|---|---|---|
| 静态配置(yml) | 需要重启 | 慢 | 生产稳定环境 | ⭐⭐⭐ |
| 动态配置(API) | 不需要重启 | 即时 | 生产、运维、常用 | ⭐⭐⭐⭐⭐ |
| Kibana 可视化 | 不需要重启 | 即时 | 测试、快速搭建 | ⭐⭐⭐ |
kibana可视化形式配置:
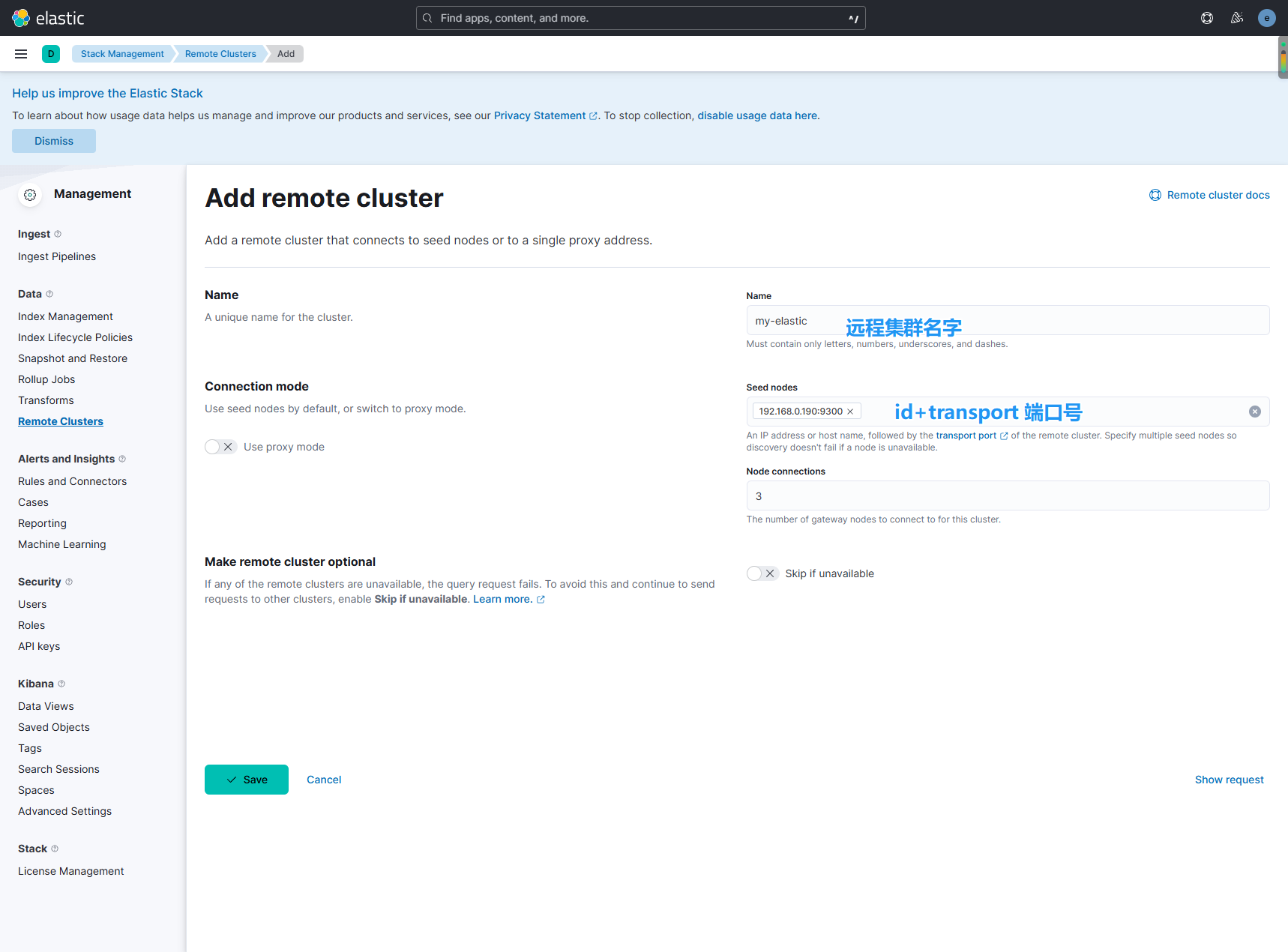
在使用安全的形式进行集群连接的时候会连接失败,这是因为CA证书的问题,大家按着我在开头的位置解决一下就行了。
下面使用最推荐的动态配置的方式展示:
二、跨集群数据查询(CCS,Cross Cluster Search)
核心定义
跨集群数据查询是联邦式实时检索能力 ,无需迁移、复制远端集群数据,通过本地集群配置远程集群白名单与互联地址,单次查询可同时下发至本地及多个远程集群执行检索,最终由本地集群统一聚合、排序、归一化结果,对外返回统一查询响应。核心特点是数据不动、计算联动。
工作原理
首先完成集群互联配置,本地集群(协调节点)记录所有远程集群的节点地址与权限信息;接收用户查询请求后,协调节点自动解析查询索引归属,将查询分片下发至对应本地、远程集群;各集群独立执行检索、过滤、聚合计算后,将结果回传至本地协调节点;最后本地节点完成全局排序、分页、聚合合并,输出最终结果。
具体语法:
GET my-elastic:index_190/_search三、跨集群数据更新
跨集群之间不允许执行数据的写入操作
四、跨集群重建索引Reindex
1. 核心定义
跨集群重建索引是跨集群运维的核心能力,支持将源集群索引 的全量数据、映射结构、配置,通过远程读取、本地写入的方式,重建至目标集群索引,实现跨集群索引迁移、结构升级、数据规整、冷热数据迁移。主流架构中可通过reindex远程接口实现一键跨集群重建。
在开启安全的集群下,连个集群之间因为互信的问题,直接进行reindex的话会产生问题,这是我在文章十四:ElasticSearch Reindex重建索引_elasticsearch remote reindex-CSDN博客文章中通过将http_ca.ca文件加入到JDK的信任库中,解决了互信问题,
但是因为在上面的跨集群交互的连接中,使用了同一个transport.ca文件的方式,也就是使用同一个(或公司中的证书)证书的方式解决的问题,所以这里我们使用同一个ca.ca证书解决问题,下面为大家带来这个方式的具体步骤:
但是需要注意的是,前置条件下是你已经使用了上面的两个文章,将transport.p12文件和http.p12文件已经都使用统一 CA签发了。
我们的./bin/elasticsearch-certutil ca --pem 方式生成新的同意的 CA 证书之后,解压之后,他的文件夹中的ca.crt就是我们需要的文件,之后在每个节点下执行下面的命令:
cp ca/ca.crt ./config/certs/http_ca.crt
只有再发起的集群中配置白名单:
多个节点用英文逗号分隔,不能有空格 reindex.remote.whitelist: "192.168.0.190:9200,192.168.0.191:9200"
之后我们再进行reindex的时候,还是会出现下面的问题:
PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
我们在执行跨集群远程 Reindex 时,源集群必须信任目标集群的 SSL 证书 ,否则会出现 PKIX path building failed 证书不信任报错。 由于所有 ES 集群统一使用同一个根 CA 证书 签发服务证书,因此源集群直接信任自身的根 CA 证书,即可自动信任所有同根 CA 的集群,运维成本极低。
下面是两种标准、可用的信任方案,二选一即可生效:
方案一:ES 配置文件指定信任
直接在发起 Reindex 的源集群 的 elasticsearch.yml 中,单独为 Reindex 配置信任的根 CA 证书。 该方案最小权限、不侵入 JDK、配置清晰、易于维护。
配置步骤
-
在源集群所有节点的
elasticsearch.yml中添加:远程 Reindex SSL 信任配置(信任统一根 CA)
reindex.ssl.certificate_authorities: ["/elasticsearch/es9200/config/certs/http_ca.crt"]
-
重启源集群所有节点生效。
- 因为所有集群共用同一个根 CA,信任自己的 CA = 信任所有集群
- 该配置仅作用于 Reindex 模块,不影响集群内部通信
- 新增同根 CA 集群时,无需修改任何配置
方案二:ES 内置 JDK 全局信任证书(系统级信任)
将根 CA 证书导入 ES 自带 JDK 的全局信任库,让 JVM 层面直接信任该证书。 该方案属于全局信任,ES 所有基于 HTTPS 的功能都会自动信任该 CA。
配置步骤
-
进入 ES 安装目录(使用 ES 自带 JDK,不使用系统 JDK)
-
执行命令导入根 CA 证书:
./jdk/bin/keytool -importcert
-alias es-root-ca
-file ./config/certs/ca.crt
-keystore ./jdk/lib/security/cacerts
-storepass changeit
-noprompt -
重启 ES 集群生效。
通过上述得方式,在执行下面得任务就可以成功了:
POST _reindex
{
"source": {
"remote": {
"host": "https://192.168.0.190:9200",
"username": "elastic",
"password": "*y3b8X"
},
"index": "index_190"
},
"dest": {
"index":"index_189"
},
"script": {
"source": """
ctx._source.state="success";
ctx._source.sync_time = System.currentTimeMillis();
ctx._source.create_by=params.name
""",
"lang": "painless",
"params": {
"name":"lihua"
}
}
}通过上述方式配置,成功执行了跨集群得索引重建。
五、跨集群数据实时复制(CCR,Cross Cluster Replication)
核心定义
跨集群数据复制是近实时异步数据同步能力,也是多集群容灾、读写分离的核心方案。通过主从集群架构,将Leader主集群的索引全量数据、增量变更(新增/修改/删除),持续异步同步至Follower从集群,从集群生成只读副本索引,实现多集群数据一致性备份。
核心架构与原理
采用主从异步复制模型,Leader集群承担所有写操作,记录索引操作日志(Translog);Follower集群后台常驻线程,持续轮询拉取(典型得拉模型)Leader集群的增量日志,回放执行变更操作,同步数据、映射及索引元数据;支持手动创建副本索引与自动匹配时序索引两种模式,同时支持单向、双向复制架构。
核心参数
下面展示了一些参数,但是实际上在开发中我们大多数场景是不需要进行修改的。
|-----------------------------------|---------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------|-----------------------------------|-------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Elasticsearch CCR 核心参数详细说明表 |||||||
| 参数名称 | 中文释义 | 官方定义 | 默认值 | 取值示例 | 核心作用 | 调优建议 |
| Max read request operation count | 单次从远程集群读取的最大操作数 | The maximum number of operations to pull per read from the remote cluster. | 5120 | 1024、 2048、 5120、 10240 | 控制单次读取请求从远程主集群拉取的事务操作数量,直接影响读取吞吐量和单次请求的资源占用 | 1. 主集群写入TPS高、单条文档体积小时,可调大至8192~10240,提升读取效率;2. 单条文档体积大(如超过10KB)、网络带宽有限时,调小至1024~2048,避免单次请求超时;3. 需与Max outstanding read requests配合调整,避免总未完成请求数过高 |
| Max outstanding read requests | 对远程集群的最大未完成读取请求数 | The maximum number of outstanding read requests from the remote cluster. | 12 | 4、 8、 12、 16、 24 | 限制从远程主集群发起的并发未完成读取请求总数,控制读取端的并发压力和网络连接占用 | 1. 主集群节点多、读写性能充足、网络带宽高时,可调大至16~24,提升同步并发度;2. 主集群负载高、网络延迟大时,调小至4~8,避免给主集群造成额外压力;3. 该值与Max read request operation count的乘积,决定了单次可拉取的最大总操作数,需根据集群性能合理匹配 |
| Max read request size | 单次从远程集群读取的批量操作最大字节数 | The maximum size in bytes of per read of a batch of operations pulled from the remote cluster. | 32mb | 10b、 1024kb、 1mb、 32mb、 64mb | 限制单次读取请求的总数据量,避免单次请求数据量过大导致的网络超时、内存溢出,平衡读取效率和资源占用 | 1. 大文档场景(单条文档>10KB)、高带宽环境下,可调大至64mb~128mb,减少请求次数;2. 小文档场景、低带宽/高延迟网络下,调小至4mb~16mb,降低单次请求的传输风险;3. 该值需与Max read request operation count配合,确保单次请求的总数据量不超过该阈值 |
| Max write request operation count | 在跟随者集群执行的单次批量写入请求的最大操作数 | The maximum number of operations per bulk write request executed on the follower. | 5120 | 1024、 2048、 5120、 10240 | 控制跟随者集群单次批量写入的事务操作数量,直接影响写入吞吐量和跟随者集群的写入压力 | 1. 跟随者集群节点多、写入性能充足、单条文档体积小时,可调大至8192~10240,提升写入效率;2. 单条文档体积大、跟随者集群负载高时,调小至1024~2048,避免单次写入请求超时或节点负载过高;3. 需与Max outstanding write requests配合调整,平衡写入并发和吞吐量 |
| Max write request size | 在跟随者集群执行的单次批量写入请求的最大总字节数 | The maximum total bytes of operations per bulk write request executed on the follower. | 922 33720 36854 7758 07b (无限制) | 10b、 1024kb、 1mb、 5gb、 2tb | 限制跟随者集群单次批量写入的总数据量,避免单次写入数据量过大导致的节点内存溢出、写入超时,默认无限制 | 1. 大文档批量写入场景、跟随者集群内存有限时,建议设置为64mb~128mb,避免单次写入占用过多内存;2. 小文档高吞吐场景,可保持默认无限制,或设置为256mb~512mb,最大化写入效率;3. 需与Max write request operation count配合,确保单次写入的总数据量符合预期 |
| Max outstanding write requests | 跟随者集群的最大未完成写入请求数 | The maximum number of outstanding write requests on the follower. | 9 | 3、 6、 9、 12、 18 | 限制跟随者集群的并发未完成写入请求总数,控制写入端的并发压力,避免跟随者集群因写入并发过高导致的性能下降或不稳定 | 1. 跟随者集群节点多、磁盘IO性能充足、CPU核心数多时,可调大至12~18,提升写入并发度;2. 跟随者集群负载高、磁盘IO瓶颈明显时,调小至3~6,降低写入压力,保证集群稳定性;3. 该值与Max write request operation count的乘积,决定了单次可写入的最大总操作数,需根据集群性能合理匹配 |
| Max write buffer count | 可排队等待写入的最大操作数;达到该限制时,将暂停从远程集群读取数据,直到排队操作数低于该限制 | The maximum number of operations that can be queued for writing; when this limit is reached, reads from the remote cluster will be deferred until the number of queued operations goes below the limit. | 214748 3647(无限制) | 10240、 65535、 1048576、 2147483647 | 控制写入缓冲区的最大排队操作数,实现读取与写入的流量控制,避免写入速度跟不上读取速度导致的缓冲区无限膨胀、内存溢出 | 1. 主集群写入TPS远高于跟随者集群写入能力时,建议设置为1048576~2097152,避免缓冲区无限增长;2. 跟随者集群写入性能充足、主集群写入TPS稳定时,可保持默认无限制,最大化同步效率;3. 该值需与Max write buffer size配合,实现双维度的缓冲区流量控制 |
| Max write buffer size | 可排队等待写入的操作最大总字节数;达到该限制时,将暂停从远程集群读取数据,直到排队操作的总字节数低于该限制 | The maximum total bytes of operations that can be queued for writing; when this limit is reached, reads from the remote cluster will be deferred until the total bytes of queued operations goes below the limit. | 512mb | 10b、 1024kb、 1mb、 512mb、 1gb、 2gb | 控制写入缓冲区的最大总数据量,从字节维度实现读取与写入的流量控制,避免写入缓冲区占用过多内存,导致节点内存溢出 | 1. 大文档场景、主集群写入吞吐量高时,可调大至1gb~2gb,提升缓冲区的抗抖动能力;2. 跟随者集群节点内存有限(如小于8GB)、小文档高并发场景,调小至128mb~256mb,避免缓冲区占用过多内存;3. 该值与Max write buffer count配合,实现更精准的缓冲区控制 |
| Max retry delay | 异常失败的操作重试前的最大等待时间;重试时采用指数退避策略 | The maximum time to wait before retrying an operation that failed exceptionally; an exponential backoff strategy is employed when retrying. | 500ms | 100ms、 500ms、 1s、 5s、 30s | 控制同步操作异常失败后的重试最大间隔,采用指数退避策略,避免频繁重试给集群造成额外压力,同时保证异常操作的最终重试成功 | 1. 网络波动频繁、主集群负载高导致的临时异常场景,可调大至1s~5s,提升重试成功率;2. 对同步延迟要求高、网络稳定的场景,保持默认500ms,或调小至100ms~200ms,降低重试带来的同步延迟;3. 需注意,指数退避的最大间隔不会超过该值,需根据业务的RTO要求合理设置 |
| Read poll timeout | 当跟随者索引与主集群索引同步完成后,等待远程集群新操作的最大时间;超时后,读取请求将返回跟随者以更新统计信息,随后跟随者将立即再次尝试从主集群读取 | The maximum time to wait for new operations on the remote cluster when the follower index is synchronized with the leader index; when the timeout has elapsed, the poll for operations will return to the follower so that it can update some statistics, and then the follower will immediately attempt to read from the leader again. | 1m | 10s、 30s、 1m、 2m、 5m | 控制主集群无新数据写入时,跟随者的长轮询超时时间,平衡同步的实时性和请求开销,同时确保跟随者能定期更新同步统计信息 | 1. 对同步实时性要求极高的在线业务场景,可调小至10s~30s,降低新数据的同步延迟;2. 主集群写入TPS低、数据更新不频繁的场景,可调大至2m~5m,减少无效的轮询请求,降低集群和网络开销;3. 需注意,超时后跟随者会立即发起新的轮询,不会出现同步中断,仅影响统计信息更新频率和请求开销 |
创建CCR:
使用kibana的方式进行配置就行了。
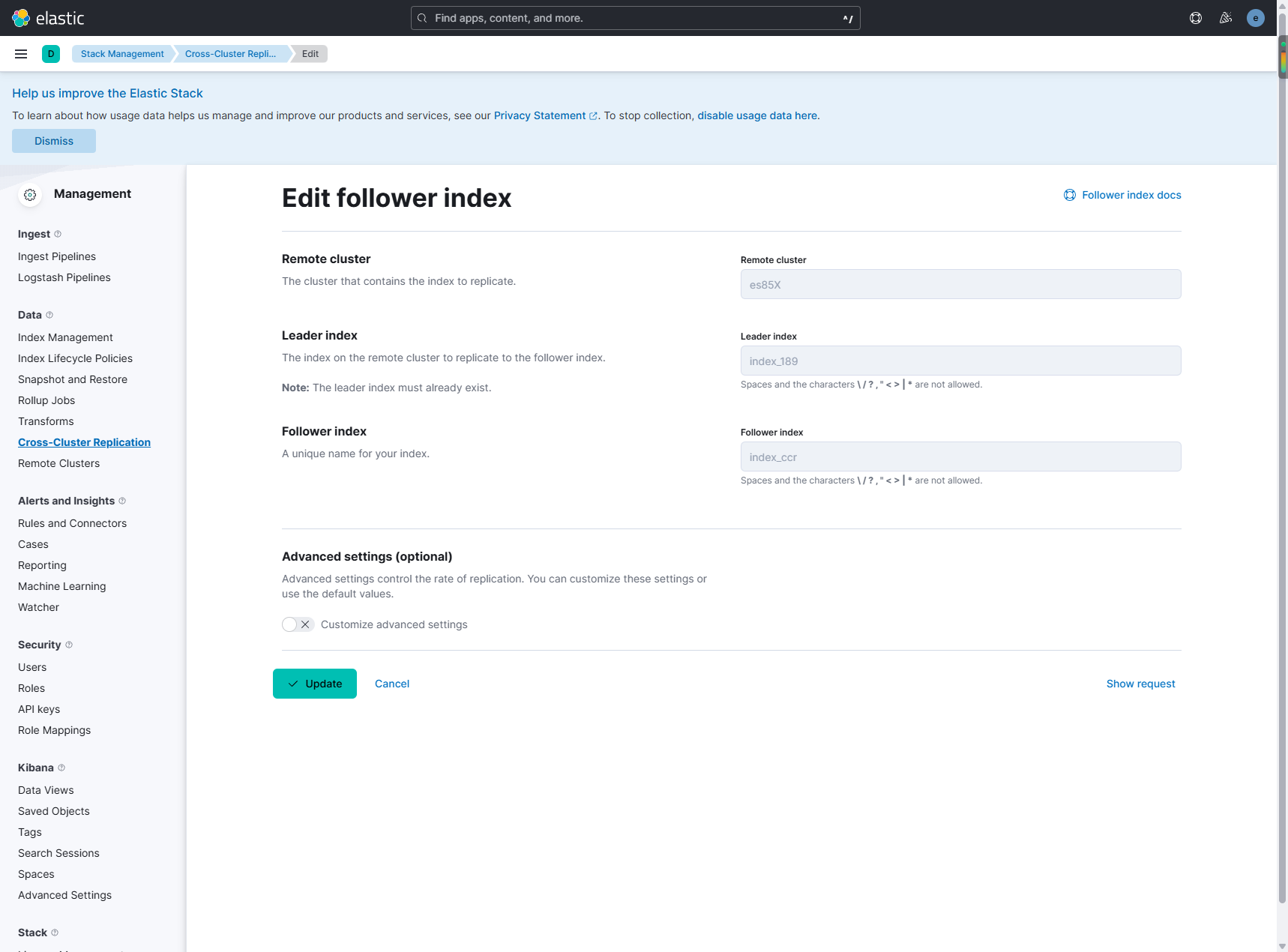
之后点击启动和暂停就可以控制数据的同步了。
注意点:
- follow索引在没有进行unfollow操作时,只是可以读取,不可以进行写入
- unfollow操作时不可逆的,操作之后如果要再次执行的话,需要重新创建,重新拉取全量数量