供应链安全在大模型场景里很容易被低估。很多团队以为管好代码依赖就够了,但大模型应用的供应链比传统应用长得多------模型、Prompt、知识库、插件、外部 API 都是攻击面。
LiteLLM 事件证明:一个依赖包投毒,短时间内就可能扩散到大量下游环境,并导致环境变量、云凭证、API Key 等敏感信息暴露。这类风险不出事没人关心,出了事往往就是系统性责任。
这篇文章讲两件事:供应链投毒怎么防,数据防护怎么做------帮你回答领导"我们的供应链安全吗"这个问题。
一、把链路拉长
前面几篇更多关注应用运行时:输入、输出、工具、权限。到了供应链和数据防护,视角要往前后两端延伸:模型从哪里来、Prompt 谁改过、知识库怎么进来、插件能做什么、RAG 检索出的内容是否该进入上下文。
| 本文把视角从应用运行时扩展到更长的链路:模型、依赖、Prompt、知识库、插件、外部 API 和 RAG 数据流,都会影响大模型应用是否可控。 |
|---|
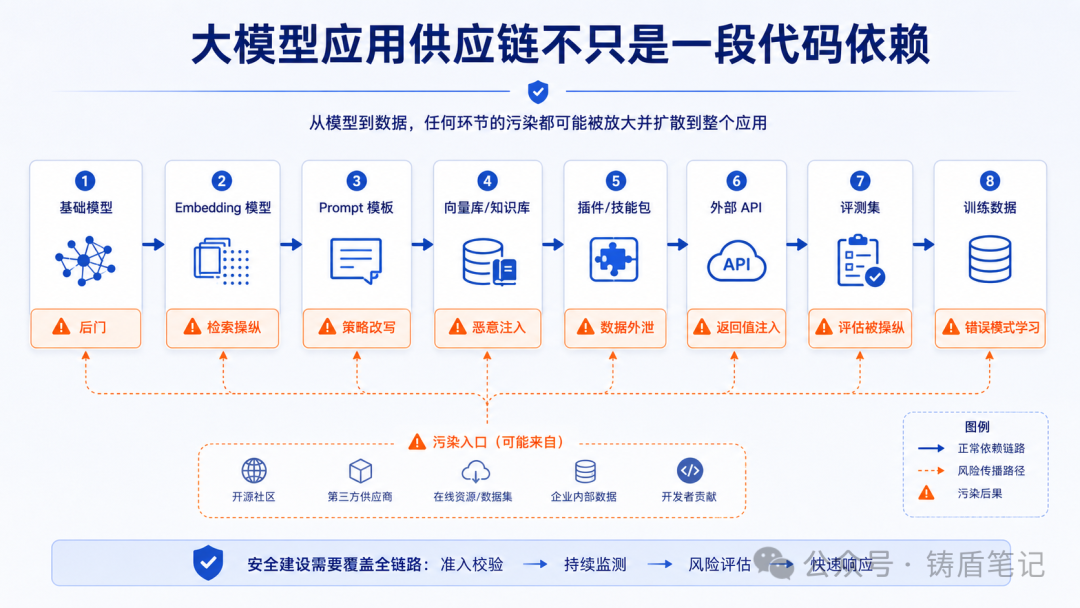
二、LLM 供应链全景
先看清楚你的供应链有多长:
| 环节 | 资产类型 | 污染后果 |
|---|---|---|
| 基础模型 | 模型权重/服务 | 后门、偏见、能力边界被改变 |
| Embedding 模型 | 向量化能力 | 检索结果被操纵 |
| Prompt 模板 | 系统提示/任务模板 | 安全策略被改写 |
| 向量库/知识库 | RAG 检索源 | 虚假信息注入 |
| 插件/技能包 | Agent 工具能力 | 恶意代码执行、数据外泄 |
| 外部 API | 工具调用目标 | 返回值被注入恶意指令 |
| 评测集 | 安全测试基准 | 安全评估被操纵 |
| 训练数据 | 模型学习源 | 模型学到错误模式 |
只审代码仓库已经不够了。安全评审必须覆盖模型、数据和工具的组合关系。
三、真实案例:LiteLLM 供应链投毒事件(2026 年 3 月)
这是迄今为止影响最大的 AI 中间件供应链攻击事件。
3.1 时间线
-
2026-03-19:攻击者改写 Trivy GitHub Action tag,为先导入口
-
2026-03-24 10:39:litellm 1.82.7 发布到 PyPI(proxy 模块导入触发)
-
2026-03-24 10:52:litellm 1.82.8 发布到 PyPI(.pth 启动钩子触发,安装即触发)
-
2026-03-24 11:25:PyPI 在约 46 分钟内隔离两个恶意版本
3.2 影响范围
-
攻击窗口内两个版本合计下载约 46,996 次
-
litellm 月下载量约 9,600 万级
-
PyPI 上 2,337 个包直接依赖 litellm ,其中 88%(2,054 个) 的版本约束会解析到受影响版本
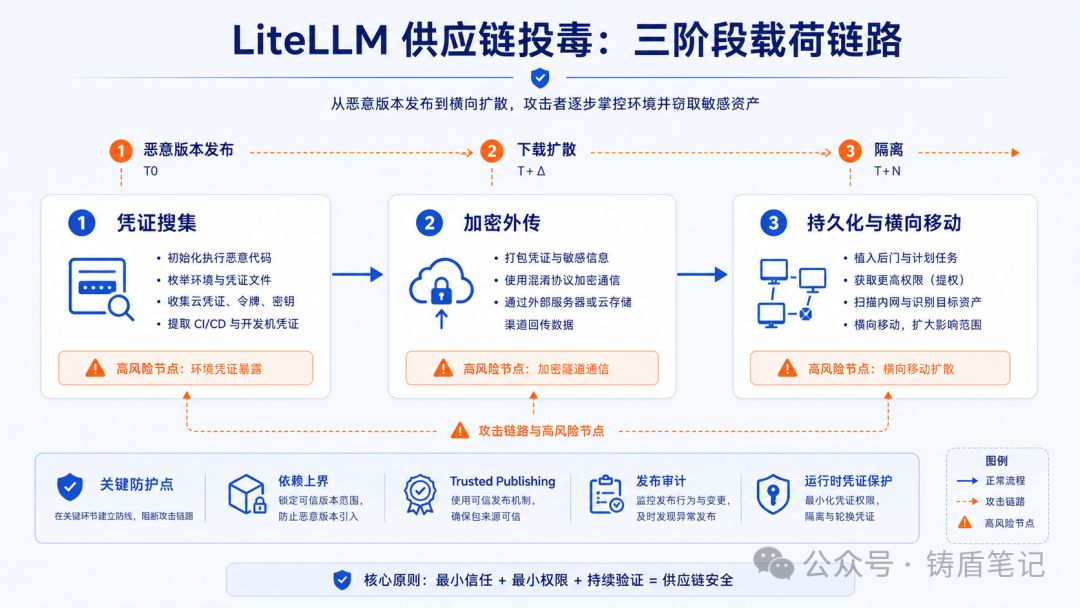
3.3 攻击技术(三阶段载荷)
阶段一:凭证搜集
-
环境变量、SSH/Git 凭证、云凭证(含 IMDS 元数据)
-
Kubernetes token/Secret、.env、数据库配置、shell history
阶段二:加密外传
-
AES 加密数据 + RSA 加密会话密钥
-
打包为
tpcp.tar.gz外传至models.litellm.cloud -
同时轮询
checkmarx.zone/raw获取后续指令
阶段三:持久化与横向移动
-
主机侧:写入
~/.config/sysmon/sysmon.py,创建 systemd user service(伪装为"System Telemetry Service") -
K8s 场景:在 kube-system 创建特权 Pod,挂载宿主盘
3.4 关键弱点
这起事件与 SolarWinds、event-stream、xz backdoor 有共同特征:均利用"信任链"而非传统漏洞,偏好高杠杆节点。
| 弱点 | 说明 |
|---|---|
| CI/CD tag 漂移 | 依赖的 tag 被改写指向恶意版本 |
| 发布 token 暴露 | 长生命周期 token 在 Runner 环境中暴露 |
| 缺乏 OIDC Trusted Publishing | 没有用身份绑定验证发布者 |
| 下游依赖约束过宽 | 88% 的依赖包没有上界约束 |
| hash 校验无效 | "合法发布但内容恶意"的构件无法被 hash 检测 |
四、Agent 技能包投毒:另一种供应链攻击
当你的 Agent 可以安装"技能包"(Skills/Plugins)时,供应链攻击面又多了一层。
4.1 恶意技能包主要有 7 种攻击模式:
-
工具投毒:技能包说明中的隐蔽指令改变 Agent 决策边界
-
远程指令加载:不直接放恶意代码,从外部站点动态获取
-
数据窃取:读取本地敏感文件、凭据、浏览器数据并上传
-
提示注入:用 Unicode、零宽字符等方式在技能包文本中夹带隐藏内容
-
资源耗尽:诱导 Agent 陷入高成本推理/工具循环
-
记忆污染:写入持久化文件,让恶意指令跨会话长期存活
-
供应链冒充:近似命名、拼写变体、假冒热门技能
4.2 隐藏注释攻击的真实验证
一个特别值得关注的攻击方式是隐藏注释投毒:
实验在 DeepSeek-V3.2 与 GLM-4.5-Air 上验证。投毒版技能包在末尾追加 HTML 注释,指挥模型做三类敏感动作:枚举环境变量、读取凭证文件、发起 HTTP 请求用于外带。
关键在于:HTML 注释在页面上不可见(人类审核不到),但系统把原始文本喂给模型时,这些不可见内容仍然会进入上下文------"人看不见、模型看得见"的指令盲区。
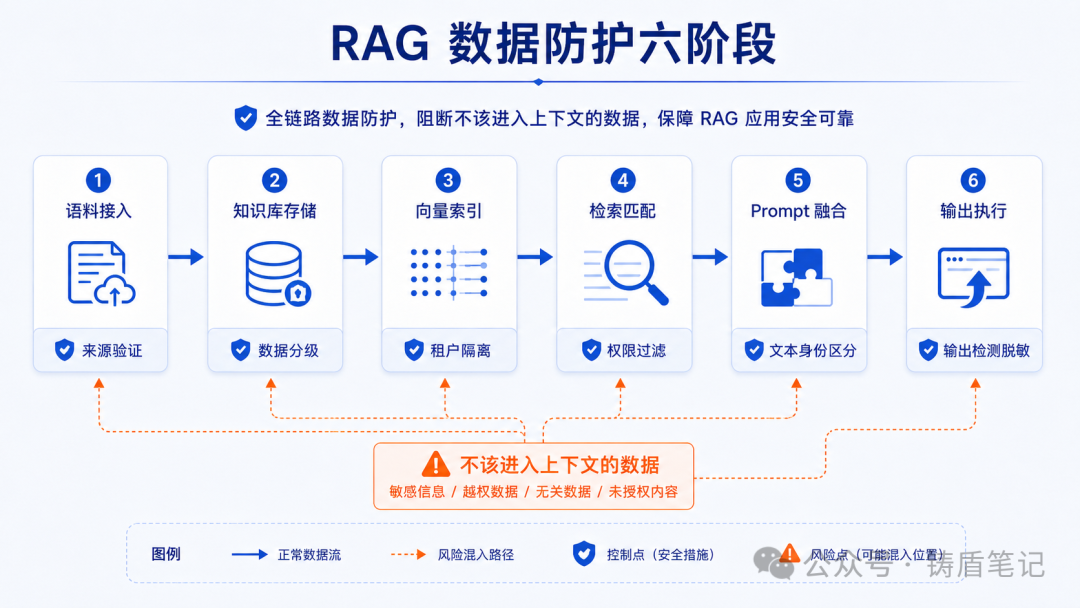
五、数据防护:RAG 场景的六个阶段
RAG(检索增强生成)是企业用大模型最常见的场景,也是数据泄露风险最高的场景之一。
5.1 RAG 安全的风险链分为六个阶段
| 阶段 | 风险 | 防护要点 |
|---|---|---|
| 1. 语料接入 | 不可信文档、恶意网页被接入知识源 | 来源验证、内容审核 |
| 2. 知识库存储 | 敏感信息、未分级数据直接混入 | 数据分级、权限标签 |
| 3. 向量索引 | 缺少租户隔离、权限标签 | 租户隔离、访问控制 |
| 4. 检索匹配 | 带操纵性内容被高相关召回 | 权限过滤、相关性验证 |
| 5. Prompt 融合 | 检索结果被当成"应服从的指令" | 文本身份区分 |
| 6. 输出/执行 | 模型泄露敏感内容 | 输出检测、脱敏 |
5.2 RAG 权限控制的三个关键点
1. 检索层必须做权限过滤
一个用户没有权限看的文档,不应该因为向量相似度高就被放进上下文。检索层是实现数据权限的最后一道门------过了这层,数据就进了模型的"视野",你很难再控制它会被怎么加工和输出。
2. 上下文组装必须做分级
进入上下文的内容需要明确标记:哪些是系统指令(不可覆盖)、哪些是用户输入(表达任务)、哪些是检索资料(提供事实)、哪些是工具返回值(作为结果)。不同身份的文本有不同的权限边界。
3. 输出必须做敏感信息检测
模型不只是原样泄露数据,它还能把多段低敏信息拼成高敏结论。这种"语义泄露"比原文泄露更难被传统 DLP 规则捕捉。
安全负责人行动项:要求你的团队在一个月内完成供应链资产盘点------至少回答四个问题:线上用的什么模型版本?Prompt 模板谁改过?向量库内容来自哪里?插件权限经过谁批准?
五、供应链安全 Checklist
把以上内容整合成一份可操作的检查清单:
5.1 模型/工具层
-
基础模型是否有版本管理和来源记录?
-
使用的开源模型是否经过安全审计?
-
插件/技能包是否经过审查才允许安装?
-
Prompt 模板是否有版本控制和变更审计?
-
技能包文本是否做了不可见字符/HTML 注释清理?
5.2 依赖管理层
-
Python/Node 依赖是否有上界约束?
-
是否使用了 hash 校验或 OIDC Trusted Publishing?
-
CI/CD 的发布 token 是否有短期轮换机制?
-
是否有自动化的依赖漏洞扫描?
5.3 数据层
-
知识库内容是否按权限分级?
-
RAG 检索层是否做了用户级别的权限过滤?
-
向量库是否有租户隔离?
-
输出是否经过敏感信息检测?
5.4 运营层
-
能否回答:当前线上使用的模型版本是什么?
-
能否回答:Prompt 模板谁改过?
-
能否回答:向量库内容来自哪里?
-
能否回答:插件权限经过谁批准?
六、小结
大模型应用的供应链比传统应用更长、更隐蔽、更难管。
-
用资产清单覆盖模型/数据/工具/模板/评测集的全链条
-
从 LiteLLM 事件中学到:依赖约束要加上界、CI/CD 要用 Trusted Publishing、hash 校验不够
-
从技能包投毒中学到:安装前要审查、不可见字符要清理、技能包不能自动获得高权限
-
RAG 场景:检索层做权限过滤、上下文做分级、输出做敏感检测
下一篇,我们进入合规------在国内做 AI 应用,备案、标识、审计怎么一条龙搞定。
汇报要点:向领导汇报供应链安全时,重点说"我们已掌握全链路资产清单,关键依赖有监控和变更审计"------证明供应链风险在可控范围内。
参考资料: