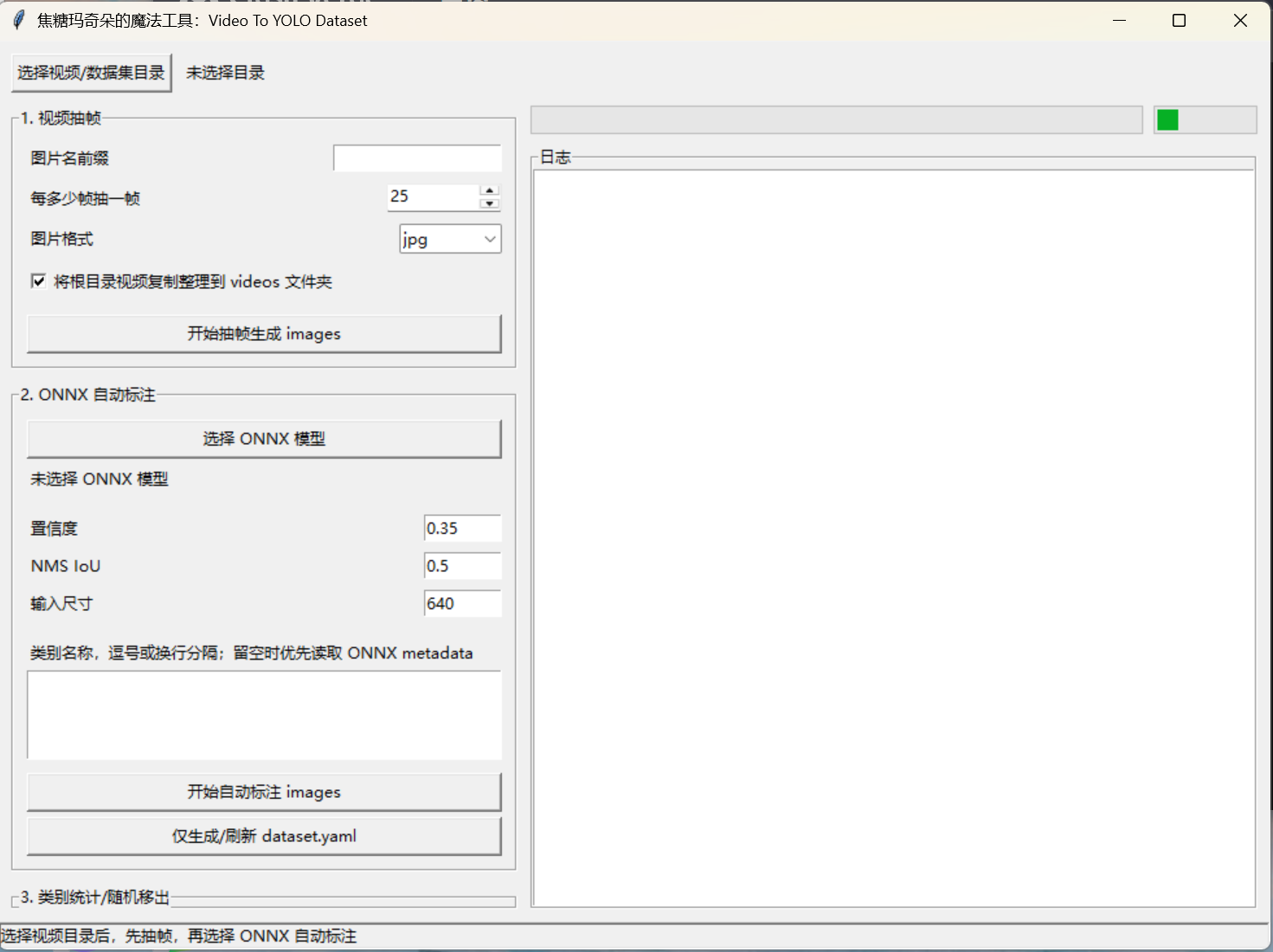
Video To YOLO Dataset
这个工具用于把视频文件夹转换成 YOLO 检测数据集,可作为 dataset_clean_tool.py 的前置工具。
输出结构
选择一个目录后,工具会在该目录下创建或使用:
text
selected_dir/
videos/
images/
labels/
dataset.yamlvideos:可选地把所选目录根部的视频复制整理到这里。images:按指定帧间隔抽帧得到的图片。labels:ONNX 自动标注生成的 YOLO txt。empty_images:模型没有输出任何目标<TOOLS_USER_GUIDE.md>的图片,会从images移到这里,不生成 txt。dataset.yaml:YOLO 训练配置文件。
运行
powershell
pip install -r requirements.txt
python .\video_to_yolo_tool.py使用流程
- 点击
选择视频/数据集目录。 - 设置
图片名前缀和每多少帧抽一帧,点击开始抽帧生成 images。 - 选择 YOLO ONNX 模型。
- 如 ONNX 没有类别 metadata,手动填写类别名称,每行一个或逗号分隔。
- 点击
开始自动标注 images,工具会生成对应 txt 和dataset.yaml。
图片命名
抽帧图片统一使用 ASCII 文件名:
text
图片名前缀_视频序号_帧序号.jpg例如:
text
efall_0520_3_24.jpg这样可以避免中文路径或特殊字符在训练、跨平台拷贝、dataloader 中引发问题。
说明
自动标注逻辑兼容常见 YOLOv8 ONNX 输出,也尽量兼容带 objectness 的 YOLO 输出。若模型导出时带 NMS 且输出为 [x1,y1,x2,y2,score,class],也会按该格式解析。
启动
保存为run_video_to_yolo_yolov8.bat
bash
@echo off
echo [VideoToYolo] Activating yolov8 environment...
cd /d "%~dp0"
call "C:\ProgramData\Anaconda3\Scripts\activate.bat" "C:\Users\zhang\.conda\envs\yolov8"
set "CUDA_PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1"
set "PATH=C:\Users\zhang\.conda\envs\yolov8;C:\Users\zhang\.conda\envs\yolov8\DLLs;C:\Users\zhang\.conda\envs\yolov8\Library\bin;C:\Users\zhang\.conda\envs\yolov8\Lib\site-packages\onnxruntime\capi;C:\Users\zhang\.conda\envs\yolov8\Lib\site-packages\torch\lib;C:\Users\zhang\.conda\envs\yolov8\Lib\site-packages\torchvision;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin;%PATH%"
echo [VideoToYolo] Current Python:
where python
echo [VideoToYolo] Checking onnxruntime...
python -c "import sys, os; import onnxruntime as ort; print('python=', sys.executable); print('providers=', ort.get_available_providers()); print('CONDA_PREFIX=', os.environ.get('CONDA_PREFIX'))" > "%~dp0video_to_yolo_startup.log" 2>&1
if errorlevel 1 (
echo onnxruntime import failed. See "%~dp0video_to_yolo_startup.log"
type "%~dp0video_to_yolo_startup.log"
pause
exit /b 1
)
type "%~dp0video_to_yolo_startup.log"
echo [VideoToYolo] Starting GUI...
python "%~dp0video_to_yolo_tool.py"源码
python
from __future__ import annotations
import ast
import argparse
import math
import os
import queue
import random
import shutil
import subprocess
import sys
import threading
import traceback
from dataclasses import dataclass
from pathlib import Path
from tkinter import (
BOTH,
BOTTOM,
DISABLED,
END,
LEFT,
NORMAL,
RIGHT,
TOP,
X,
Y,
BooleanVar,
Button,
Checkbutton,
DoubleVar,
Entry,
Frame,
IntVar,
Label,
LabelFrame,
StringVar,
Text,
Tk,
filedialog,
messagebox,
)
from tkinter import ttk
def configure_conda_dll_paths() -> None:
if os.name != "nt" or not hasattr(os, "add_dll_directory"):
return
prefixes = [Path(sys.prefix)]
conda_prefix = os.environ.get("CONDA_PREFIX")
if conda_prefix:
prefixes.insert(0, Path(conda_prefix))
cuda_home = os.environ.get("CUDA_PATH") or os.environ.get("CUDA_HOME")
seen: set[Path] = set()
for prefix in prefixes:
for path in (
prefix,
prefix / "DLLs",
prefix / "Library" / "bin",
prefix / "Lib" / "site-packages" / "onnxruntime" / "capi",
prefix / "Lib" / "site-packages" / "torch" / "lib",
prefix / "Lib" / "site-packages" / "torchvision",
):
if path in seen or not path.exists():
continue
seen.add(path)
try:
os.add_dll_directory(str(path))
except OSError:
pass
os.environ["PATH"] = str(path) + os.pathsep + os.environ.get("PATH", "")
if cuda_home:
cuda_bin = Path(cuda_home) / "bin"
if cuda_bin.exists():
try:
os.add_dll_directory(str(cuda_bin))
except OSError:
pass
os.environ["PATH"] = str(cuda_bin) + os.pathsep + os.environ.get("PATH", "")
def build_runtime_env() -> dict[str, str]:
env = os.environ.copy()
prefix = Path(env.get("CONDA_PREFIX") or sys.prefix)
cuda_path = env.get("CUDA_PATH") or r"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1"
path_parts = [
prefix,
prefix / "DLLs",
prefix / "Library" / "bin",
prefix / "Lib" / "site-packages" / "onnxruntime" / "capi",
prefix / "Lib" / "site-packages" / "torch" / "lib",
prefix / "Lib" / "site-packages" / "torchvision",
Path(cuda_path) / "bin",
]
existing = env.get("PATH", "")
env["PATH"] = os.pathsep.join(str(path) for path in path_parts if path.exists()) + os.pathsep + existing
env["CUDA_PATH"] = cuda_path
env.setdefault("CONDA_PREFIX", str(prefix))
return env
configure_conda_dll_paths()
import cv2
import numpy as np
import yaml
VIDEO_EXTS = {".mp4", ".avi", ".mov", ".mkv", ".flv", ".wmv", ".m4v", ".mpeg", ".mpg"}
IMAGE_EXTS = {".jpg", ".jpeg", ".png", ".bmp", ".webp"}
@dataclass
class Detection:
class_id: int
score: float
xyxy: tuple[float, float, float, float]
class VideoToYoloApp:
def __init__(self, root: Tk) -> None:
self.root = root
self.root.title("焦糖玛奇朵的魔法工具:Video To YOLO Dataset")
self.root.geometry("980x700")
self.root.minsize(820, 560)
self.dataset_dir: Path | None = None
self.model_path: Path | None = None
self.worker: threading.Thread | None = None
self.log_queue: queue.Queue[str] = queue.Queue()
self.dataset_var = StringVar(value="未选择目录")
self.model_var = StringVar(value="未选择 ONNX 模型")
self.prefix_var = StringVar(value="")
self.interval_var = IntVar(value=25)
self.image_ext_var = StringVar(value="jpg")
self.copy_videos_var = BooleanVar(value=True)
self.conf_var = DoubleVar(value=0.35)
self.iou_var = DoubleVar(value=0.50)
self.imgsz_var = IntVar(value=640)
self.balance_class_var = IntVar(value=0)
self.balance_percent_var = DoubleVar(value=90.0)
self.balance_seed_var = IntVar(value=20260521)
self.names_var = StringVar(value="")
self.status_var = StringVar(value="选择视频目录后,先抽帧,再选择 ONNX 自动标注")
self._build_ui()
self._poll_log_queue()
def _build_ui(self) -> None:
top_bar = Frame(self.root, padx=10, pady=10)
top_bar.pack(side=TOP, fill=X)
Button(top_bar, text="选择视频/数据集目录", command=self.choose_dataset_dir).pack(side=LEFT, padx=(0, 8))
Label(top_bar, textvariable=self.dataset_var, anchor="w").pack(side=LEFT, fill=X, expand=True)
body = Frame(self.root, padx=10, pady=0)
body.pack(side=TOP, fill=BOTH, expand=True, pady=(0, 10))
left_panel = Frame(body, width=390)
left_panel.pack(side=LEFT, fill=Y, padx=(0, 10))
left_panel.pack_propagate(False)
extract_frame = LabelFrame(left_panel, text="1. 视频抽帧")
extract_frame.pack(side=TOP, fill=X)
row = Frame(extract_frame)
row.pack(fill=X, padx=10, pady=(10, 4))
Label(row, text="图片名前缀").pack(side=LEFT)
Entry(row, textvariable=self.prefix_var, width=18).pack(side=RIGHT)
row = Frame(extract_frame)
row.pack(fill=X, padx=10, pady=4)
Label(row, text="每多少帧抽一帧").pack(side=LEFT)
ttk.Spinbox(row, from_=1, to=100000, textvariable=self.interval_var, width=10).pack(side=RIGHT)
row = Frame(extract_frame)
row.pack(fill=X, padx=10, pady=4)
Label(row, text="图片格式").pack(side=LEFT)
ttk.Combobox(row, textvariable=self.image_ext_var, values=("jpg", "png"), width=8, state="readonly").pack(
side=RIGHT
)
Checkbutton(extract_frame, text="将根目录视频复制整理到 videos 文件夹", variable=self.copy_videos_var).pack(
anchor="w", padx=8, pady=4
)
Button(extract_frame, text="开始抽帧生成 images", command=self.start_extract_frames).pack(
fill=X, padx=10, pady=(8, 10)
)
label_frame = LabelFrame(left_panel, text="2. ONNX 自动标注")
label_frame.pack(side=TOP, fill=X, pady=(10, 0))
Button(label_frame, text="选择 ONNX 模型", command=self.choose_model).pack(fill=X, padx=10, pady=(10, 4))
Label(label_frame, textvariable=self.model_var, anchor="w", wraplength=360).pack(fill=X, padx=10, pady=(0, 8))
grid = Frame(label_frame)
grid.pack(fill=X, padx=10, pady=4)
Label(grid, text="置信度").grid(row=0, column=0, sticky="w", pady=3)
Entry(grid, textvariable=self.conf_var, width=8).grid(row=0, column=1, sticky="e", pady=3)
Label(grid, text="NMS IoU").grid(row=1, column=0, sticky="w", pady=3)
Entry(grid, textvariable=self.iou_var, width=8).grid(row=1, column=1, sticky="e", pady=3)
Label(grid, text="输入尺寸").grid(row=2, column=0, sticky="w", pady=3)
Entry(grid, textvariable=self.imgsz_var, width=8).grid(row=2, column=1, sticky="e", pady=3)
grid.columnconfigure(0, weight=1)
Label(label_frame, text="类别名称,逗号或换行分隔;留空时优先读取 ONNX metadata").pack(
anchor="w", padx=10, pady=(8, 2)
)
self.names_text = Text(label_frame, height=5, wrap="word")
self.names_text.pack(fill=X, padx=10)
Button(label_frame, text="开始自动标注 images", command=self.start_auto_label).pack(fill=X, padx=10, pady=(10, 4))
Button(label_frame, text="仅生成/刷新 dataset.yaml", command=self.write_yaml_from_ui).pack(
fill=X, padx=10, pady=(0, 10)
)
balance_frame = LabelFrame(left_panel, text="3. 类别统计/随机移出")
balance_frame.pack(side=TOP, fill=X, pady=(10, 0))
Button(balance_frame, text="统计 labels 类别数量", command=self.show_label_stats).pack(
fill=X, padx=10, pady=(10, 6)
)
balance_grid = Frame(balance_frame)
balance_grid.pack(fill=X, padx=10, pady=4)
Label(balance_grid, text="类别ID").grid(row=0, column=0, sticky="w", pady=3)
Entry(balance_grid, textvariable=self.balance_class_var, width=8).grid(row=0, column=1, sticky="e", pady=3)
Label(balance_grid, text="移出百分比").grid(row=1, column=0, sticky="w", pady=3)
Entry(balance_grid, textvariable=self.balance_percent_var, width=8).grid(row=1, column=1, sticky="e", pady=3)
Label(balance_grid, text="随机种子").grid(row=2, column=0, sticky="w", pady=3)
Entry(balance_grid, textvariable=self.balance_seed_var, width=8).grid(row=2, column=1, sticky="e", pady=3)
balance_grid.columnconfigure(0, weight=1)
Button(balance_frame, text="随机移出仅包含该类别的图片", command=self.start_prune_single_class).pack(
fill=X, padx=10, pady=(6, 10)
)
right_panel = Frame(body)
right_panel.pack(side=RIGHT, fill=BOTH, expand=True)
progress_frame = Frame(right_panel)
progress_frame.pack(side=TOP, fill=X)
self.progress = ttk.Progressbar(progress_frame, orient="horizontal", mode="determinate")
self.progress.pack(side=LEFT, fill=X, expand=True)
self.busy = ttk.Progressbar(progress_frame, orient="horizontal", mode="indeterminate", length=80)
self.busy.pack(side=RIGHT, padx=(8, 0))
log_frame = LabelFrame(right_panel, text="日志")
log_frame.pack(side=TOP, fill=BOTH, expand=True, pady=(8, 0))
self.log_text = Text(log_frame, wrap="word", state=DISABLED)
self.log_text.pack(side=LEFT, fill=BOTH, expand=True)
scrollbar = ttk.Scrollbar(log_frame, command=self.log_text.yview)
scrollbar.pack(side=RIGHT, fill=Y)
self.log_text.configure(yscrollcommand=scrollbar.set)
ttk.Label(self.root, textvariable=self.status_var, anchor="w", relief="sunken").pack(side=BOTTOM, fill=X)
def choose_dataset_dir(self) -> None:
path = filedialog.askdirectory(title="选择包含视频的目录,或已存在 videos 的数据集目录")
if not path:
return
self.dataset_dir = Path(path)
self.dataset_var.set(str(self.dataset_dir))
self.prefix_var.set(default_dataset_prefix(self.dataset_dir))
self.log(f"选择目录: {self.dataset_dir}")
self.log("工具会在该目录下创建/使用 images、labels、videos 三个文件夹。")
def choose_model(self) -> None:
path = filedialog.askopenfilename(
title="选择 ONNX 模型",
filetypes=(("ONNX model", "*.onnx"), ("All files", "*.*")),
)
if not path:
return
self.model_path = Path(path)
self.model_var.set(str(self.model_path))
self.log(f"选择模型: {self.model_path}")
names = try_read_onnx_names(self.model_path)
if names:
self.names_text.delete("1.0", END)
self.names_text.insert("1.0", "\n".join(names))
self.log(f"已从 ONNX metadata 读取 {len(names)} 个类别名。")
def start_extract_frames(self) -> None:
if not self.dataset_dir:
messagebox.showwarning("缺少目录", "请先选择视频/数据集目录")
return
interval = max(1, int(self.interval_var.get()))
ext = self.image_ext_var.get().lstrip(".").lower()
copy_videos = bool(self.copy_videos_var.get())
prefix = sanitize_prefix(self.prefix_var.get()) or default_dataset_prefix(self.dataset_dir)
def job() -> None:
self.set_busy(True)
try:
total = extract_frames_from_dataset(
self.dataset_dir,
interval=interval,
image_ext=ext,
prefix=prefix,
copy_root_videos=copy_videos,
progress=self.set_progress,
log=self.log,
)
(self.dataset_dir / "labels").mkdir(parents=True, exist_ok=True)
self.log(f"抽帧完成,共生成 {total} 张图片。")
self.set_status(f"抽帧完成: {total} 张图片")
except Exception as exc:
error = str(exc)
self.log(f"抽帧失败: {error}")
self.log(traceback.format_exc())
self.root.after(0, lambda error=error: messagebox.showerror("抽帧失败", error))
finally:
self.set_busy(False)
self.run_worker(job)
def start_auto_label(self) -> None:
if not self.dataset_dir:
messagebox.showwarning("缺少目录", "请先选择视频/数据集目录")
return
if not self.model_path:
messagebox.showwarning("缺少模型", "请先选择 ONNX 模型")
return
names = self.get_names_from_ui()
conf = float(self.conf_var.get())
iou = float(self.iou_var.get())
imgsz = int(self.imgsz_var.get())
def job() -> None:
self.set_busy(True)
try:
self.run_auto_label_subprocess(
dataset_dir=self.dataset_dir,
model_path=self.model_path,
names=names,
conf=conf,
iou=iou,
imgsz=imgsz,
)
self.set_status("自动标注完成")
except Exception as exc:
error = str(exc)
self.log(f"自动标注失败: {error}")
self.log(traceback.format_exc())
self.root.after(0, lambda error=error: messagebox.showerror("自动标注失败", error))
finally:
self.set_busy(False)
self.run_worker(job)
def run_auto_label_subprocess(
self,
dataset_dir: Path,
model_path: Path,
names: list[str],
conf: float,
iou: float,
imgsz: int,
) -> None:
script_path = Path(__file__).resolve()
command = [
sys.executable,
str(script_path),
"--auto-label-cli",
"--dataset",
str(dataset_dir),
"--model",
str(model_path),
"--conf",
str(conf),
"--iou",
str(iou),
"--imgsz",
str(imgsz),
]
if names:
command.extend(["--names", "|".join(names)])
self.log(f"启动自动标注子进程: {sys.executable}")
process = subprocess.Popen(
command,
cwd=str(script_path.parent),
env=build_runtime_env(),
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
text=True,
encoding="utf-8",
errors="replace",
)
assert process.stdout is not None
for line in process.stdout:
line = line.rstrip()
if line.startswith("PROGRESS "):
_tag, current, total = line.split()
self.set_progress(int(current), int(total))
else:
self.log(line)
return_code = process.wait()
if return_code != 0:
raise RuntimeError(f"自动标注子进程失败,退出码 {return_code}")
def write_yaml_from_ui(self) -> None:
if not self.dataset_dir:
messagebox.showwarning("缺少目录", "请先选择视频/数据集目录")
return
names = self.get_names_from_ui()
if not names:
messagebox.showwarning("缺少类别", "请填写类别名称,或先选择带 metadata 的 ONNX 模型")
return
write_dataset_yaml(self.dataset_dir, names)
self.log(f"已生成: {self.dataset_dir / 'dataset.yaml'}")
def show_label_stats(self) -> None:
if not self.dataset_dir:
messagebox.showwarning("缺少目录", "请先选择视频/数据集目录")
return
names = self.get_names_for_stats()
stats = compute_label_stats(self.dataset_dir, names)
log_label_stats(stats, self.log)
def start_prune_single_class(self) -> None:
if not self.dataset_dir:
messagebox.showwarning("缺少目录", "请先选择视频/数据集目录")
return
class_id = int(self.balance_class_var.get())
percent = float(self.balance_percent_var.get())
seed = int(self.balance_seed_var.get())
if percent <= 0 or percent > 100:
messagebox.showwarning("比例无效", "移出百分比需要在 0-100 之间")
return
names = self.get_names_for_stats()
def job() -> None:
self.set_busy(True)
try:
result = prune_single_class_images(
self.dataset_dir,
class_id=class_id,
percent=percent,
seed=seed,
names=names,
log=self.log,
)
self.log(
f"随机移出完成: 候选 {result['candidates']} 张,移出 {result['moved']} 张,保留 {result['kept']} 张"
)
log_label_stats(compute_label_stats(self.dataset_dir, names), self.log)
self.set_status("随机移出完成")
except Exception as exc:
error = str(exc)
self.log(f"随机移出失败: {error}")
self.log(traceback.format_exc())
self.root.after(0, lambda error=error: messagebox.showerror("随机移出失败", error))
finally:
self.set_busy(False)
self.run_worker(job)
def get_names_from_ui(self) -> list[str]:
text = self.names_text.get("1.0", END).strip()
if not text:
return []
names: list[str] = []
for chunk in text.replace(",", "\n").splitlines():
name = chunk.strip()
if name:
names.append(name)
return names
def get_names_for_stats(self) -> list[str]:
if self.dataset_dir is None:
return self.get_names_from_ui()
return self.get_names_from_ui() or read_dataset_yaml_names(self.dataset_dir / "dataset.yaml")
def run_worker(self, target) -> None:
if self.worker and self.worker.is_alive():
messagebox.showinfo("正在运行", "当前任务还没有结束")
return
self.progress.configure(value=0, maximum=100)
self.worker = threading.Thread(target=target, daemon=True)
self.worker.start()
def set_progress(self, current: int, total: int) -> None:
def update() -> None:
self.progress.configure(maximum=max(total, 1), value=current)
self.root.after(0, update)
def set_busy(self, busy: bool) -> None:
def update() -> None:
if busy:
self.busy.start(10)
else:
self.busy.stop()
self.root.after(0, update)
def set_status(self, message: str) -> None:
self.root.after(0, lambda message=message: self.status_var.set(message))
def log(self, message: str) -> None:
self.log_queue.put(message)
def _poll_log_queue(self) -> None:
while True:
try:
message = self.log_queue.get_nowait()
except queue.Empty:
break
self.log_text.configure(state=NORMAL)
self.log_text.insert(END, message + "\n")
self.log_text.see(END)
self.log_text.configure(state=DISABLED)
self.root.after(100, self._poll_log_queue)
def discover_videos(dataset_dir: Path) -> list[Path]:
candidates: list[Path] = []
for base in (dataset_dir, dataset_dir / "videos"):
if not base.exists():
continue
for path in sorted(base.iterdir()):
if path.is_file() and path.suffix.lower() in VIDEO_EXTS:
candidates.append(path)
seen: set[Path] = set()
videos: list[Path] = []
for path in candidates:
resolved = path.resolve()
if resolved not in seen:
seen.add(resolved)
videos.append(path)
return videos
def extract_frames_from_dataset(
dataset_dir: Path,
interval: int,
image_ext: str,
prefix: str,
copy_root_videos: bool,
progress,
log,
) -> int:
videos_dir = dataset_dir / "videos"
images_dir = dataset_dir / "images"
labels_dir = dataset_dir / "labels"
videos_dir.mkdir(parents=True, exist_ok=True)
images_dir.mkdir(parents=True, exist_ok=True)
labels_dir.mkdir(parents=True, exist_ok=True)
videos = discover_videos(dataset_dir)
if not videos:
raise FileNotFoundError("所选目录或 videos 子目录下没有找到视频文件")
prepared_videos: list[Path] = []
for video in videos:
if copy_root_videos and video.parent.resolve() == dataset_dir.resolve():
dest = unique_path(videos_dir / video.name) if not (videos_dir / video.name).exists() else videos_dir / video.name
if not dest.exists():
shutil.copy2(video, dest)
log(f"复制视频到 videos: {dest.name}")
prepared_videos.append(dest)
else:
prepared_videos.append(video)
total_saved = 0
for video_idx, video in enumerate(sorted(prepared_videos), start=1):
log(f"开始抽帧 [{video_idx}/{len(prepared_videos)}]: {video.name}")
saved = extract_video_frames(video, images_dir, interval, image_ext, prefix, video_idx)
total_saved += saved
progress(video_idx, len(prepared_videos))
log(f"{video.name}: 生成 {saved} 张图片")
return total_saved
def extract_video_frames(
video_path: Path,
images_dir: Path,
interval: int,
image_ext: str,
prefix: str,
video_index: int,
) -> int:
cap = cv2.VideoCapture(str(video_path))
if not cap.isOpened():
raise RuntimeError(f"无法打开视频: {video_path}")
frame_idx = 0
saved = 0
try:
while True:
ok, frame = cap.read()
if not ok:
break
if frame_idx % interval == 0:
image_name = f"{prefix}_{video_index}_{frame_idx}.{image_ext}"
safe_imwrite(images_dir / image_name, frame)
saved += 1
frame_idx += 1
finally:
cap.release()
return saved
class YoloOnnxDetector:
def __init__(self, model_path: Path, imgsz: int, names: list[str], log) -> None:
try:
import onnxruntime as ort
except Exception as exc:
raise RuntimeError(
"onnxruntime 导入失败。建议用 yolov8 conda 环境运行本工具,"
"或重新安装 onnxruntime/onnxruntime-gpu。"
) from exc
self.model_path = model_path
self.ort = ort
self.log = log
self.session = self._create_session(prefer_cuda=True)
self.input = self.session.get_inputs()[0]
self.input_name = self.input.name
self.input_h, self.input_w = resolve_input_size(self.input.shape, imgsz)
self.names = names or try_read_onnx_names(model_path)
log(f"模型输入: {self.input_name}, size={self.input_w}x{self.input_h}")
def _create_session(self, prefer_cuda: bool):
available = self.ort.get_available_providers()
provider_attempts: list[list[str]] = []
if prefer_cuda and "CUDAExecutionProvider" in available:
provider_attempts.append(["CUDAExecutionProvider", "CPUExecutionProvider"])
provider_attempts.append(["CPUExecutionProvider"])
last_exc: Exception | None = None
for providers in provider_attempts:
providers = [provider for provider in providers if provider in available]
if not providers:
continue
try:
session = self.ort.InferenceSession(str(self.model_path), providers=providers)
self.active_providers = session.get_providers()
self.log(f"ONNX Runtime providers: {self.active_providers}")
return session
except Exception as exc:
last_exc = exc
self.log(f"创建 ONNX session 失败,providers={providers}: {exc}")
if last_exc:
raise last_exc
raise RuntimeError(f"没有可用的 ONNX Runtime provider: {available}")
def predict(self, image_bgr: np.ndarray, conf_threshold: float, iou_threshold: float) -> list[Detection]:
input_tensor, ratio, pad_x, pad_y = preprocess_yolo(image_bgr, self.input_w, self.input_h)
try:
outputs = self.session.run(None, {self.input_name: input_tensor})
except Exception as exc:
if "CPUExecutionProvider" in getattr(self, "active_providers", []):
raise
self.log(f"CUDA 推理失败,自动切换 CPU 后重试: {exc}")
self.session = self._create_session(prefer_cuda=False)
self.input = self.session.get_inputs()[0]
self.input_name = self.input.name
outputs = self.session.run(None, {self.input_name: input_tensor})
detections = postprocess_yolo_output(
outputs[0],
image_shape=image_bgr.shape[:2],
ratio=ratio,
pad_x=pad_x,
pad_y=pad_y,
conf_threshold=conf_threshold,
iou_threshold=iou_threshold,
num_classes=len(self.names) if self.names else None,
)
return detections
def auto_label_images(
dataset_dir: Path,
detector: YoloOnnxDetector,
conf_threshold: float,
iou_threshold: float,
progress,
log,
) -> int:
images_dir = dataset_dir / "images"
labels_dir = dataset_dir / "labels"
empty_images_dir = dataset_dir / "empty_images"
labels_dir.mkdir(parents=True, exist_ok=True)
empty_images_dir.mkdir(parents=True, exist_ok=True)
if not images_dir.is_dir():
raise FileNotFoundError(f"未找到 images 目录: {images_dir}")
images = [path for path in sorted(images_dir.rglob("*")) if path.is_file() and path.suffix.lower() in IMAGE_EXTS]
if not images:
raise FileNotFoundError("images 目录中没有图片")
max_class = -1
empty_count = 0
for idx, image_path in enumerate(images, start=1):
image = safe_imread(image_path)
if image is None:
log(f"跳过无法读取图片: {image_path.name}")
progress(idx, len(images))
continue
detections = detector.predict(image, conf_threshold, iou_threshold)
label_path = labels_dir / image_path.relative_to(images_dir).with_suffix(".txt")
label_path.parent.mkdir(parents=True, exist_ok=True)
if not detections:
if label_path.exists():
label_path.unlink()
empty_dest = unique_path(empty_images_dir / image_path.relative_to(images_dir))
empty_dest.parent.mkdir(parents=True, exist_ok=True)
shutil.move(str(image_path), str(empty_dest))
empty_count += 1
progress(idx, len(images))
continue
write_yolo_txt(label_path, detections, image.shape[1], image.shape[0])
max_class = max(max_class, max(det.class_id for det in detections))
if idx % 20 == 0 or idx == len(images):
log(f"已标注 {idx}/{len(images)}")
progress(idx, len(images))
if empty_count:
log(f"空检出图片已移动到 empty_images: {empty_count} 张")
return max_class
def preprocess_yolo(image_bgr: np.ndarray, input_w: int, input_h: int) -> tuple[np.ndarray, float, float, float]:
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
h, w = image_rgb.shape[:2]
ratio = min(input_w / w, input_h / h)
new_w = int(round(w * ratio))
new_h = int(round(h * ratio))
resized = cv2.resize(image_rgb, (new_w, new_h), interpolation=cv2.INTER_LINEAR)
canvas = np.full((input_h, input_w, 3), 114, dtype=np.uint8)
pad_x = (input_w - new_w) / 2
pad_y = (input_h - new_h) / 2
left = int(round(pad_x - 0.1))
top = int(round(pad_y - 0.1))
canvas[top : top + new_h, left : left + new_w] = resized
tensor = canvas.astype(np.float32) / 255.0
tensor = np.transpose(tensor, (2, 0, 1))[None, ...]
return tensor, ratio, left, top
def postprocess_yolo_output(
output: np.ndarray,
image_shape: tuple[int, int],
ratio: float,
pad_x: float,
pad_y: float,
conf_threshold: float,
iou_threshold: float,
num_classes: int | None,
) -> list[Detection]:
pred = np.asarray(output)
if pred.ndim == 3:
pred = pred[0]
if pred.ndim != 2:
raise ValueError(f"暂不支持的 ONNX 输出维度: {pred.shape}")
if pred.shape[0] < pred.shape[1] and pred.shape[0] <= 256:
pred = pred.T
raw: list[Detection] = []
image_h, image_w = image_shape
for row in pred:
parsed = parse_prediction_row(row, num_classes)
if parsed is None:
continue
cx, cy, bw, bh, score, class_id, coords_are_xyxy = parsed
if score < conf_threshold:
continue
if coords_are_xyxy:
x1, y1, x2, y2 = cx, cy, bw, bh
else:
x1 = cx - bw / 2
y1 = cy - bh / 2
x2 = cx + bw / 2
y2 = cy + bh / 2
x1 = (x1 - pad_x) / ratio
y1 = (y1 - pad_y) / ratio
x2 = (x2 - pad_x) / ratio
y2 = (y2 - pad_y) / ratio
x1 = float(np.clip(x1, 0, image_w))
y1 = float(np.clip(y1, 0, image_h))
x2 = float(np.clip(x2, 0, image_w))
y2 = float(np.clip(y2, 0, image_h))
if x2 <= x1 or y2 <= y1:
continue
raw.append(Detection(class_id=class_id, score=float(score), xyxy=(x1, y1, x2, y2)))
keep = nms(raw, iou_threshold)
return [raw[idx] for idx in keep]
def parse_prediction_row(row: np.ndarray, num_classes: int | None) -> tuple[float, float, float, float, float, int, bool] | None:
row = row.astype(float)
if row.shape[0] == 6:
return row[0], row[1], row[2], row[3], row[4], int(row[5]), True
if row.shape[0] < 6:
return None
if num_classes and row.shape[0] == num_classes + 5:
class_scores = row[5 : 5 + num_classes]
class_id = int(np.argmax(class_scores))
score = float(row[4] * class_scores[class_id])
return row[0], row[1], row[2], row[3], score, class_id, False
if num_classes and row.shape[0] == num_classes + 4:
class_scores = row[4 : 4 + num_classes]
class_id = int(np.argmax(class_scores))
score = float(class_scores[class_id])
return row[0], row[1], row[2], row[3], score, class_id, False
class_scores = row[4:]
class_id = int(np.argmax(class_scores))
score = float(class_scores[class_id])
return row[0], row[1], row[2], row[3], score, class_id, False
def nms(detections: list[Detection], iou_threshold: float) -> list[int]:
if not detections:
return []
boxes = np.array([det.xyxy for det in detections], dtype=np.float32)
scores = np.array([det.score for det in detections], dtype=np.float32)
classes = np.array([det.class_id for det in detections], dtype=np.int32)
keep: list[int] = []
for class_id in sorted(set(classes.tolist())):
idxs = np.where(classes == class_id)[0]
order = idxs[np.argsort(scores[idxs])[::-1]]
while order.size > 0:
current = int(order[0])
keep.append(current)
if order.size == 1:
break
ious = box_iou(boxes[current], boxes[order[1:]])
order = order[1:][ious <= iou_threshold]
keep.sort(key=lambda idx: detections[idx].score, reverse=True)
return keep
def box_iou(box: np.ndarray, boxes: np.ndarray) -> np.ndarray:
x1 = np.maximum(box[0], boxes[:, 0])
y1 = np.maximum(box[1], boxes[:, 1])
x2 = np.minimum(box[2], boxes[:, 2])
y2 = np.minimum(box[3], boxes[:, 3])
inter = np.maximum(0, x2 - x1) * np.maximum(0, y2 - y1)
area1 = max(0.0, (box[2] - box[0]) * (box[3] - box[1]))
area2 = np.maximum(0, boxes[:, 2] - boxes[:, 0]) * np.maximum(0, boxes[:, 3] - boxes[:, 1])
return inter / np.maximum(area1 + area2 - inter, 1e-9)
def write_yolo_txt(label_path: Path, detections: list[Detection], image_w: int, image_h: int) -> None:
lines: list[str] = []
for det in detections:
x1, y1, x2, y2 = det.xyxy
cx = ((x1 + x2) / 2) / image_w
cy = ((y1 + y2) / 2) / image_h
bw = (x2 - x1) / image_w
bh = (y2 - y1) / image_h
lines.append(f"{det.class_id} {cx:.6f} {cy:.6f} {bw:.6f} {bh:.6f}")
label_path.write_text("\n".join(lines) + ("\n" if lines else ""), encoding="utf-8")
def write_dataset_yaml(dataset_dir: Path, names: list[str]) -> Path:
data = {
"path": str(dataset_dir.resolve()),
"train": "images",
"val": "images",
"names": {idx: name for idx, name in enumerate(names)},
}
yaml_path = dataset_dir / "dataset.yaml"
yaml_path.write_text(yaml.safe_dump(data, allow_unicode=True, sort_keys=False), encoding="utf-8")
return yaml_path
def read_dataset_yaml_names(yaml_path: Path) -> list[str]:
if not yaml_path.exists():
return []
try:
data = yaml.safe_load(yaml_path.read_text(encoding="utf-8")) or {}
names = data.get("names")
if isinstance(names, list):
return [str(name) for name in names]
if isinstance(names, dict):
return [str(names[key]) for key in sorted(names, key=lambda item: int(item))]
except Exception:
return []
return []
def read_label_class_ids(label_path: Path) -> list[int]:
ids: list[int] = []
try:
with label_path.open("r", encoding="utf-8") as f:
for line in f:
parts = line.strip().split()
if not parts:
continue
ids.append(int(float(parts[0])))
except Exception:
return []
return ids
def compute_label_stats(dataset_dir: Path, names: list[str]) -> dict:
labels_dir = dataset_dir / "labels"
if not labels_dir.is_dir():
raise FileNotFoundError(f"未找到 labels 目录: {labels_dir}")
object_counts: dict[int, int] = {}
image_counts: dict[int, int] = {}
only_class_image_counts: dict[int, int] = {}
total_labels = 0
empty_labels = 0
for label_path in sorted(labels_dir.rglob("*.txt")):
total_labels += 1
ids = read_label_class_ids(label_path)
if not ids:
empty_labels += 1
continue
for class_id in ids:
object_counts[class_id] = object_counts.get(class_id, 0) + 1
unique_ids = set(ids)
for class_id in unique_ids:
image_counts[class_id] = image_counts.get(class_id, 0) + 1
if len(unique_ids) == 1:
class_id = next(iter(unique_ids))
only_class_image_counts[class_id] = only_class_image_counts.get(class_id, 0) + 1
class_ids = sorted(set(object_counts) | set(image_counts) | set(only_class_image_counts) | set(range(len(names))))
return {
"total_labels": total_labels,
"empty_labels": empty_labels,
"class_ids": class_ids,
"names": names,
"object_counts": object_counts,
"image_counts": image_counts,
"only_class_image_counts": only_class_image_counts,
}
def log_label_stats(stats: dict, log) -> None:
log("类别统计:")
log(f" label文件数: {stats['total_labels']},空txt: {stats['empty_labels']}")
for class_id in stats["class_ids"]:
names = stats["names"]
name = names[class_id] if 0 <= class_id < len(names) else f"class_{class_id}"
log(
" "
f"{class_id}: {name} | "
f"目标数 {stats['object_counts'].get(class_id, 0)} | "
f"出现图片数 {stats['image_counts'].get(class_id, 0)} | "
f"仅含该类图片数 {stats['only_class_image_counts'].get(class_id, 0)}"
)
def prune_single_class_images(
dataset_dir: Path,
class_id: int,
percent: float,
seed: int,
names: list[str],
log,
) -> dict[str, int]:
images_dir = dataset_dir / "images"
labels_dir = dataset_dir / "labels"
if not images_dir.is_dir():
raise FileNotFoundError(f"未找到 images 目录: {images_dir}")
if not labels_dir.is_dir():
raise FileNotFoundError(f"未找到 labels 目录: {labels_dir}")
candidates: list[Path] = []
for label_path in sorted(labels_dir.rglob("*.txt")):
ids = read_label_class_ids(label_path)
if ids and set(ids) == {class_id}:
candidates.append(label_path)
move_count = int(len(candidates) * percent / 100.0)
selected = sorted(random.Random(seed).sample(candidates, move_count)) if move_count else []
class_name = names[class_id] if 0 <= class_id < len(names) else f"class_{class_id}"
bucket = dataset_dir / "class_balance_removed" / f"class_{class_id}_{sanitize_prefix(class_name)}_{percent:g}pct"
bucket.mkdir(parents=True, exist_ok=True)
manifest_lines = ["old_image,new_image,old_label,new_label"]
moved = 0
for label_path in selected:
rel_label = label_path.relative_to(labels_dir)
image_path = find_image_for_label(images_dir, rel_label)
dest_label = unique_path(bucket / "labels" / rel_label)
dest_label.parent.mkdir(parents=True, exist_ok=True)
shutil.move(str(label_path), str(dest_label))
if image_path is not None:
rel_image = image_path.relative_to(images_dir)
dest_image = unique_path(bucket / "images" / rel_image)
dest_image.parent.mkdir(parents=True, exist_ok=True)
shutil.move(str(image_path), str(dest_image))
manifest_lines.append(f"{rel_image.as_posix()},{dest_image.relative_to(bucket).as_posix()},{rel_label.as_posix()},{dest_label.relative_to(bucket).as_posix()}")
else:
manifest_lines.append(f",{rel_label.as_posix()},{rel_label.as_posix()},{dest_label.relative_to(bucket).as_posix()}")
moved += 1
(bucket / "manifest.csv").write_text("\n".join(manifest_lines) + "\n", encoding="utf-8")
log(f"已移出到: {bucket}")
return {"candidates": len(candidates), "moved": moved, "kept": len(candidates) - moved}
def find_image_for_label(images_dir: Path, rel_label: Path) -> Path | None:
rel_stem = rel_label.with_suffix("")
for ext in IMAGE_EXTS:
candidate = images_dir / rel_stem.with_suffix(ext)
if candidate.exists():
return candidate
return None
def try_read_onnx_names(model_path: Path) -> list[str]:
try:
import onnxruntime as ort
providers = ["CPUExecutionProvider"]
available = ort.get_available_providers()
providers = [provider for provider in providers if provider in available] or available
session = ort.InferenceSession(str(model_path), providers=providers)
metadata = session.get_modelmeta().custom_metadata_map
except Exception:
return []
for key in ("names", "classes", "labels"):
raw = metadata.get(key)
if not raw:
continue
parsed = parse_names_value(raw)
if parsed:
return parsed
return []
def parse_names_value(value: str) -> list[str]:
try:
parsed = ast.literal_eval(value)
except Exception:
parsed = None
if isinstance(parsed, dict):
return [str(parsed[key]) for key in sorted(parsed, key=lambda item: int(item))]
if isinstance(parsed, list):
return [str(item) for item in parsed]
if isinstance(value, str):
names = [part.strip() for part in value.replace(",", "\n").splitlines() if part.strip()]
return names
return []
def resolve_input_size(shape: list, fallback: int) -> tuple[int, int]:
if len(shape) >= 4:
h = shape[2]
w = shape[3]
if isinstance(h, int) and isinstance(w, int) and h > 0 and w > 0:
return h, w
return fallback, fallback
def safe_imread(path: Path) -> np.ndarray | None:
data = np.fromfile(str(path), dtype=np.uint8)
if data.size == 0:
return None
return cv2.imdecode(data, cv2.IMREAD_COLOR)
def safe_imwrite(path: Path, image: np.ndarray) -> None:
path.parent.mkdir(parents=True, exist_ok=True)
ok, encoded = cv2.imencode(path.suffix, image)
if not ok:
raise RuntimeError(f"图片编码失败: {path}")
encoded.tofile(str(path))
def unique_path(path: Path) -> Path:
if not path.exists():
return path
parent = path.parent
stem = path.stem
suffix = path.suffix
for idx in range(1, 100000):
candidate = parent / f"{stem}_{idx}{suffix}"
if not candidate.exists():
return candidate
raise RuntimeError(f"无法生成不重复路径: {path}")
def safe_stem(path: Path) -> str:
stem = path.stem.strip() or "video"
cleaned = "".join(ch if ch.isalnum() or ch in ("-", "_") else "_" for ch in stem)
return cleaned[:80] or "video"
def sanitize_prefix(value: str) -> str:
cleaned = "".join(ch if ch.isascii() and (ch.isalnum() or ch in ("-", "_")) else "_" for ch in value.strip())
while "__" in cleaned:
cleaned = cleaned.replace("__", "_")
return cleaned.strip("_")
def default_dataset_prefix(dataset_dir: Path) -> str:
name = dataset_dir.name.strip()
lowered = name.lower()
if lowered.endswith("efall") and lowered[:-5].isdigit():
return f"efall_{lowered[:-5]}"
cleaned = sanitize_prefix(name)
return cleaned or "dataset"
def main() -> int:
if len(sys.argv) > 1 and sys.argv[1] == "--auto-label-cli":
return auto_label_cli(sys.argv[2:])
root = Tk()
VideoToYoloApp(root)
root.mainloop()
return 0
def auto_label_cli(argv: list[str]) -> int:
parser = argparse.ArgumentParser()
parser.add_argument("--dataset", required=True)
parser.add_argument("--model", required=True)
parser.add_argument("--conf", type=float, default=0.35)
parser.add_argument("--iou", type=float, default=0.50)
parser.add_argument("--imgsz", type=int, default=640)
parser.add_argument("--names", default="")
args = parser.parse_args(argv)
dataset_dir = Path(args.dataset)
model_path = Path(args.model)
names = [name for name in args.names.split("|") if name] if args.names else []
def cli_log(message: str) -> None:
print(message, flush=True)
def cli_progress(current: int, total: int) -> None:
print(f"PROGRESS {current} {total}", flush=True)
try:
cli_log(f"子进程 Python: {sys.executable}")
detector = YoloOnnxDetector(model_path, imgsz=args.imgsz, names=names, log=cli_log)
final_names = names or detector.names
max_class = auto_label_images(
dataset_dir,
detector=detector,
conf_threshold=args.conf,
iou_threshold=args.iou,
progress=cli_progress,
log=cli_log,
)
if not final_names:
final_names = [f"class_{idx}" for idx in range(max_class + 1)] if max_class >= 0 else ["class_0"]
write_dataset_yaml(dataset_dir, final_names)
cli_log(f"自动标注完成,dataset.yaml 已生成,类别数 {len(final_names)}。")
log_label_stats(compute_label_stats(dataset_dir, final_names), cli_log)
return 0
except Exception:
traceback.print_exc()
return 1
if __name__ == "__main__":
raise SystemExit(main())