简述:视觉语言大模型(VLM)
一、定义
视觉语言大模型(VLM) 是融合视觉感知与语言理解 / 生成的多模态 AI,核心是建立图像 / 视频与文本的跨模态语义对齐,实现图文问答、描述、推理、检索等联合任务。
二、原理
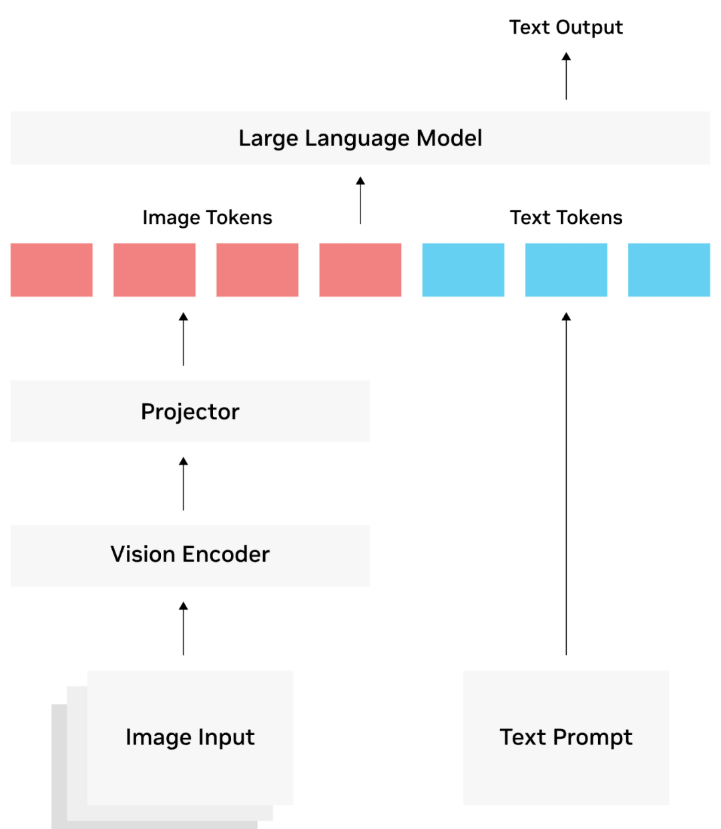
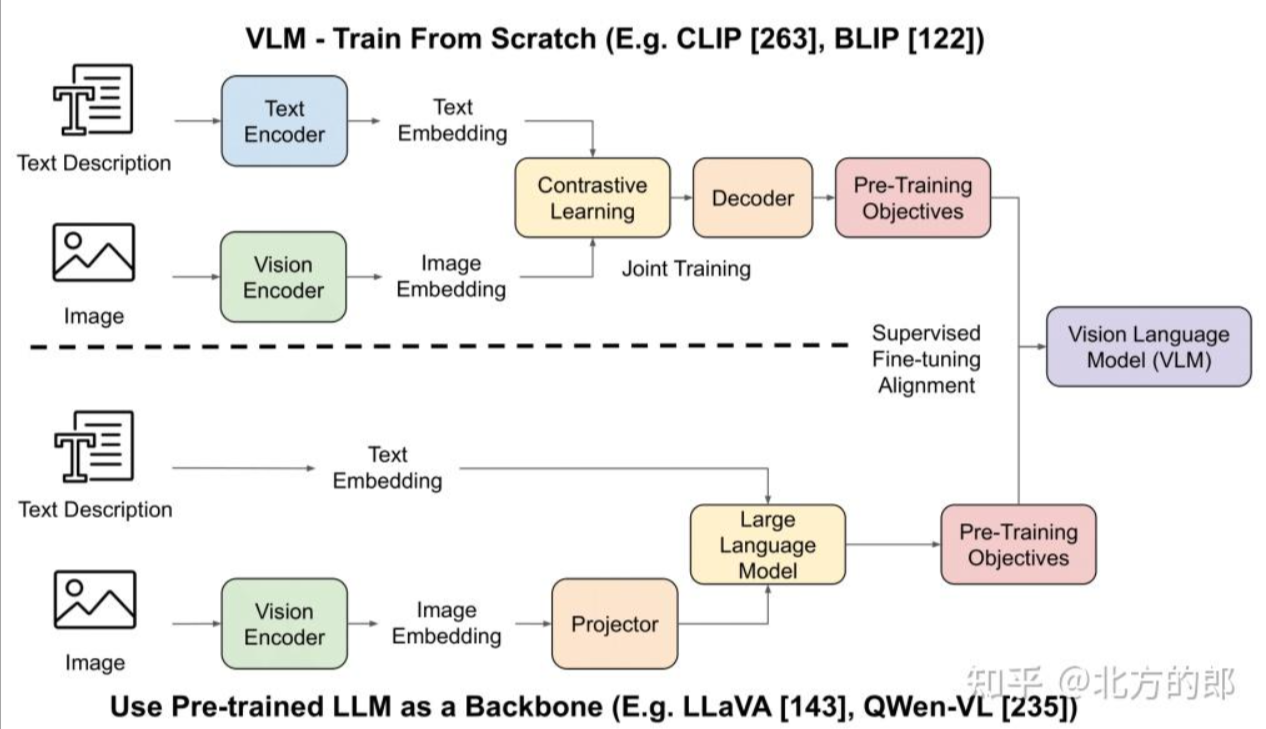
架构(三模块)
视觉编码器:ViT/CNN 将图像转为视觉 Token 序列。
跨模态连接器:投影 / 注意力对齐视觉与文本特征(如 CLIP 对比学习)。
语言解码器(LLM):基于视觉 Token 生成文本,完成问答 / 对话。
训练范式
预训练:大规模图文对(如 LAION)对比学习 / 掩码重构,学习模态关联。
微调:VQA、字幕、对话等数据适配下游任务。
对齐优化:强化学习 / 指令微调提升跨模态一致性。
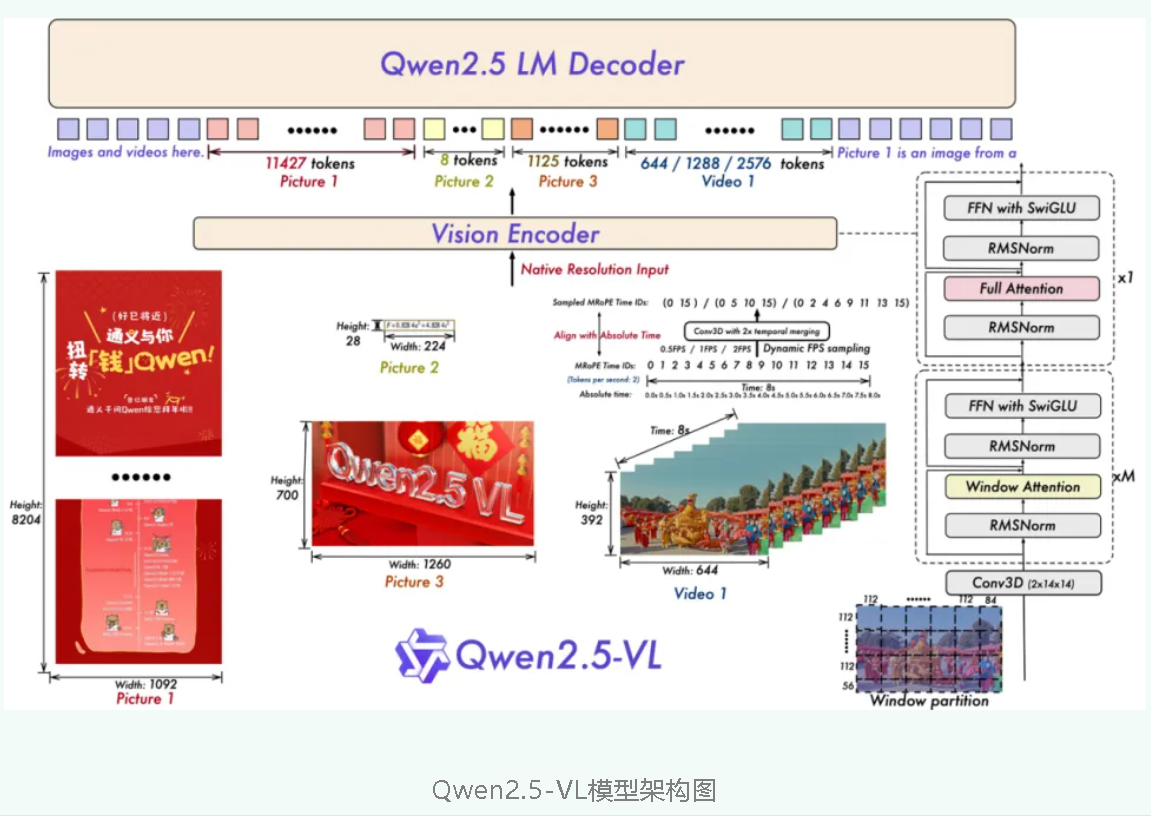
三、最新进展(2025---2026)
闭源旗舰:GPT-4V、Gemini Ultra、Claude 3 Opus,支持高分辨率、长图文、复杂推理。
开源突破
Qwen3.5-VL:MMMU 85.0,超越 GPT-5(84.2)。
InternVL3.5:级联强化学习,推理性能 + 16%。
轻量高效:FastVLM-0.5B(苹果)、SmolVLM-256M,端侧部署,TTFT 降低53%---93%。
技术融合:MoE 架构(Kimi K2.5)、原生多模态(无单独视觉编码器)、视频理解(支持长时序)。
四、技术进步
效率革命:稀疏交互(VISOR)、动态分辨率、Token 压缩,降低 60%+ 算力。
能力跃升:细粒度 OCR、图表 / 文档解析、数学推理、多轮对话、空间关系理解增强。
鲁棒性增强:反事实推理(SCI)、首 Logit 增强(FLB),缓解幻觉、提升跨语言 / 泛化能力。
部署友好:INT4 量化、模型蒸馏、单卡 / 端侧运行(消费级显卡即可)。
五、关键挑战
幻觉严重:生成内容与图像不符,长文本 / 复杂场景尤甚。
算力 / 成本高:大模型训练需千卡 GPU,推理延迟高、能耗大。
细粒度 / 3D 弱:小物体、密集文字、空间关系、3D 几何理解易出错。
数据瓶颈:高质量图文标注稀缺,长尾 / 小众领域数据不足。
多模态对齐难:跨语言、跨场景、模态分布差异导致对齐误差。
六、未来发展方向
高效轻量化:1B 级小模型逼近大模型能力,端侧实时交互。
原生多模态统一:单一架构处理图文音视频,模态无缝融合。
推理与可解释性:思维链(CoT)、因果推理,提升复杂问题解决与决策可信度。
具身智能融合:VLM + 机器人 / 自动驾驶,视觉 --- 语言 --- 动作端到端闭环。
安全与可控:幻觉抑制、偏见消除、内容审核,降低应用风险。
多模态 Agent:VLM 作为核心,自主感知 --- 推理 --- 决策 --- 执行,实现通用智能体。
七、总结
VLM 是连接感知与认知的核心技术,2025---2026 年在性能、效率、开源生态全面突破,从实验室走向规模化落地。当前瓶颈集中于幻觉、算力、细粒度理解,未来将向轻量化、统一架构、强推理、具身融合演进,是通往通用人工智能(AGI) 的关键路径。
后记
2025年是VLM研究的一个重要年份,涌现出多个新模型和技术,显著提升了模型性能和应用范围。以下是2025年发布的一些关键VLM模型及其主要特性:
最新模型概览
模型名称 发布日期 主要功能 参考链接
OmniGen2 2025年6月23日 文本到图像生成、图像编辑、上下文生成,开放源码 OmniGen2论文
BLIP3-o 2025年5月14日 统一图像理解和生成,采用扩散变换器,开放源码 BLIP3-o论文
InternVL-3 2025年4月14日 图像描述、视觉问答、多模态生成 InternVL-3论文
LLaMA4-Scout/Maverick 2025年4月4日 视觉语言推理和生成,基于LLaMA4架构 LLaMA4博客
Qwen2.5-Omni 2025年3月26日 全面多模态理解和生成 Qwen2.5-Omni论文
QWen2.5-VL 2025年1月28日 视觉问答、图像描述,开放源码 QWen2.5-VL论文
Ola 2025年 视觉语言理解,优化视觉问答性能 Ola论文
Ocean-OCR 2025年 光学字符识别(OCR),支持多语言和复杂场景 Ocean-OCR论文
SmolVLM 2025年 轻量级模型,适用于资源受限设备 SmolVLM博客
DeepSeek-Janus-Pro 2025年 多模态理解和生成,强大的基准测试表现 DeepSeek-Janus-Pro报告
其中VL原文内容解析地址: QWen2.5-VL论文
https://zhuanlan.zhihu.com/p/27593017006
本blog地址:https://blog.csdn.net/hsg77