循环神经网络(Recurrent Neural Network,RNN)是深度学习中专门用于处理序列数据的一类神经网络。与前馈神经网络不同,RNN 不只是把输入从前向后逐层传递,而是在处理序列时引入"隐藏状态",让模型能够把前面时间步的信息传递到后面时间步。
在很多任务中,数据并不是彼此独立的静态样本,而是按照时间、位置或顺序排列的序列。
例如:
• 一句话中的词语有前后顺序
• 一段语音由连续声音帧组成
• 一支股票的价格随时间变化
• 一个用户的行为记录具有先后关系
• 一段传感器数据由连续采样点组成
这类数据的核心特点是:当前输入的含义往往依赖前面的上下文。
循环神经网络正是为这类序列数据设计的基础模型。它通过在时间步之间传递隐藏状态,使模型能够在处理当前输入时"记住"前面已经看到的信息。
一、为什么需要循环神经网络
普通前馈神经网络(Feedforward Neural Network,FNN)通常假设输入是固定长度向量,并且一次性完成从输入到输出的映射。
例如,一个前馈网络可以写为:
其中:
• x 表示输入样本
• ŷ 表示模型预测结果
• f 表示由多层计算组成的函数
• θ 表示模型中的可训练参数
这种结构适合处理固定长度、整体输入的任务,例如表格分类、图像分类中的分类头等。
但是,序列数据通常具有两个特点。
第一,序列长度可能不固定。
一句话可能有 5 个词,也可能有 50 个词;一段时间序列可能有几十个时间点,也可能有几千个时间点。
第二,序列中的元素具有顺序依赖。
同一个词出现在不同上下文中,含义可能不同;同一个数值在不同时间趋势中,也可能代表不同含义。
例如,句子:
go
这部电影一点也不好看如果只看"好看"两个字,可能会误判为正面评价;但结合前面的"一点也不",整体语义实际上是负面评价。
普通前馈网络如果直接把句子或时间序列展平成固定向量,通常难以自然表示这种前后依赖关系。
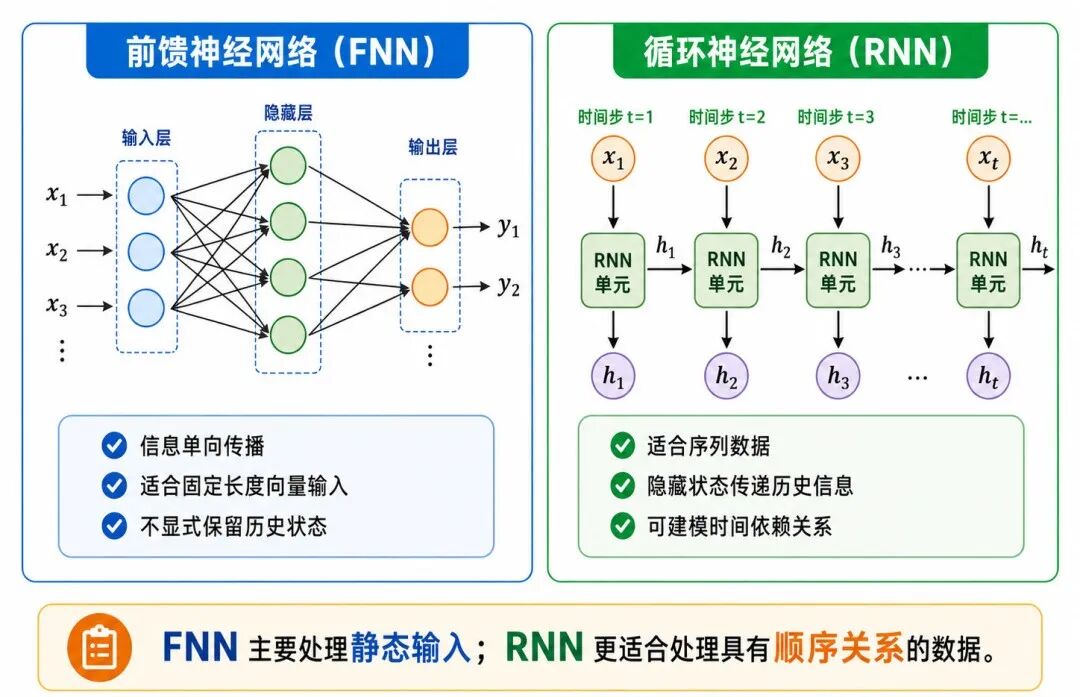
图 1:从前馈神经网络到循环神经网络
循环神经网络的基本思想是:按时间步依次读取序列,并在每个时间步更新隐藏状态,使模型能够把历史信息传递到后续计算中。
可以简单理解为:
• 前馈神经网络:一次性处理一个整体输入
• 循环神经网络:按顺序处理输入,并不断更新"记忆"
这里的"记忆"并不是人工写入的规则,而是模型在训练过程中学习到的隐藏状态表示。
二、RNN 的基本结构
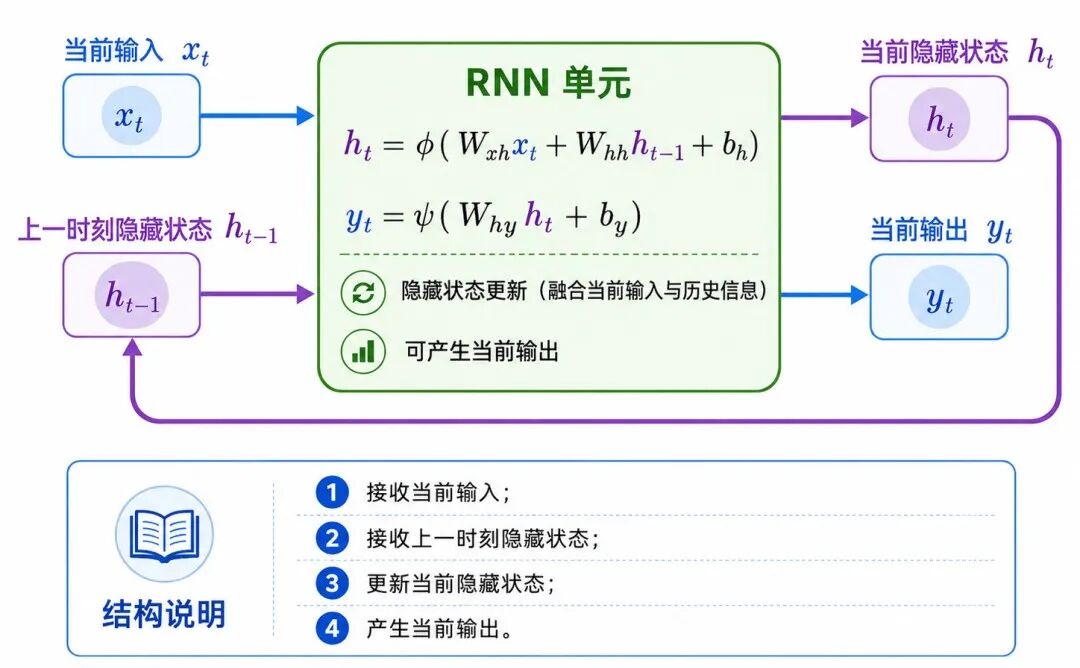
图 2:RNN 的基本循环结构
循环神经网络的核心结构是循环单元。它在每个时间步接收两个输入:
• 当前时间步的输入 xₜ
• 上一个时间步的隐藏状态 hₜ₋₁
然后计算当前时间步的隐藏状态 hₜ:
其中:
• xₜ 表示第 t 个时间步的输入
• hₜ₋₁ 表示上一个时间步的隐藏状态
• hₜ 表示当前时间步的隐藏状态
• Wₓ 表示输入到隐藏状态的权重矩阵
• Wₕ 表示隐藏状态到隐藏状态的权重矩阵
• b 表示偏置向量
• φ 表示激活函数,常见为 tanh 或 ReLU
如果需要在每个时间步输出结果,可以继续写为:
其中:
• yₜ 表示第 t 个时间步的输出
• Wᵧ 表示隐藏状态到输出的权重矩阵
• c 表示输出层偏置
• g 表示输出层变换
从结构上看,RNN 的关键不是某一层有多复杂,而是它在时间维度上反复使用同一组参数。
也就是说,第 1 个时间步、第 2 个时间步、......、第 T 个时间步,使用的是同一个 RNN 单元和同一组参数。
这类似于 CNN 中的"权重共享":CNN 在空间位置上共享卷积核参数,RNN 在时间步上共享循环单元参数。
三、按时间展开:理解隐藏状态如何传递
RNN 的循环结构可以按时间展开(Unroll)来理解。
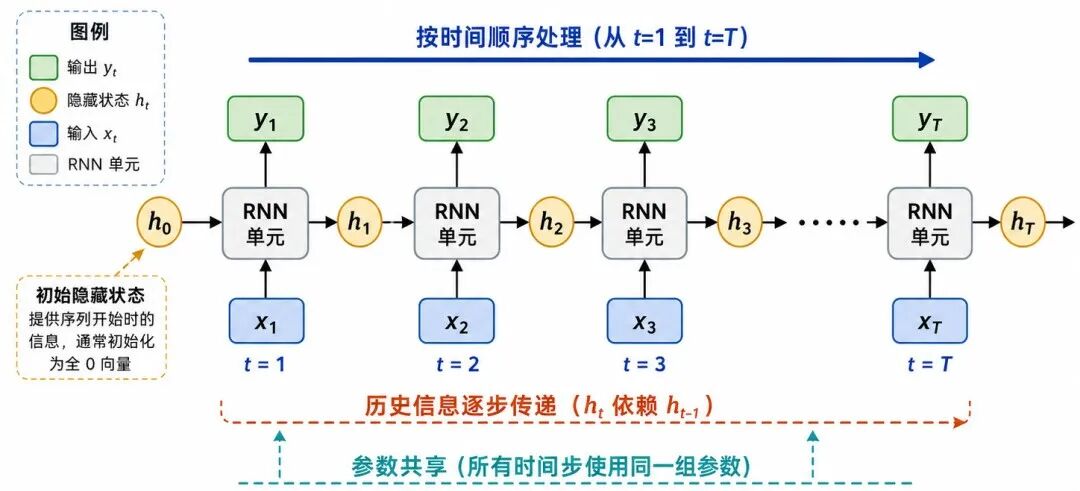
图 3:RNN 按时间展开的结构
假设输入序列为:
RNN 会依次计算:
一直到:
其中:
• T 表示序列长度
• h₀ 表示初始隐藏状态,通常可以设为零向量
• h₁、h₂、...、hₜ 表示不同时间步的隐藏状态
从这个过程可以看出,hₜ 不只依赖当前输入 xₜ,也间接依赖前面所有时间步的信息。
例如:
• h₃ 依赖 x₃ 和 h₂
• h₂ 依赖 x₂ 和 h₁
• h₁ 依赖 x₁ 和 h₀
因此,h₃ 实际上包含了 x₁、x₂、x₃ 的历史信息。
这就是 RNN 能够处理序列数据的原因。
四、RNN 的输入、输出与常见任务形式
RNN 可以根据任务需要设计不同的输入输出形式。常见形式包括一对一、一对多、多对一和多对多。
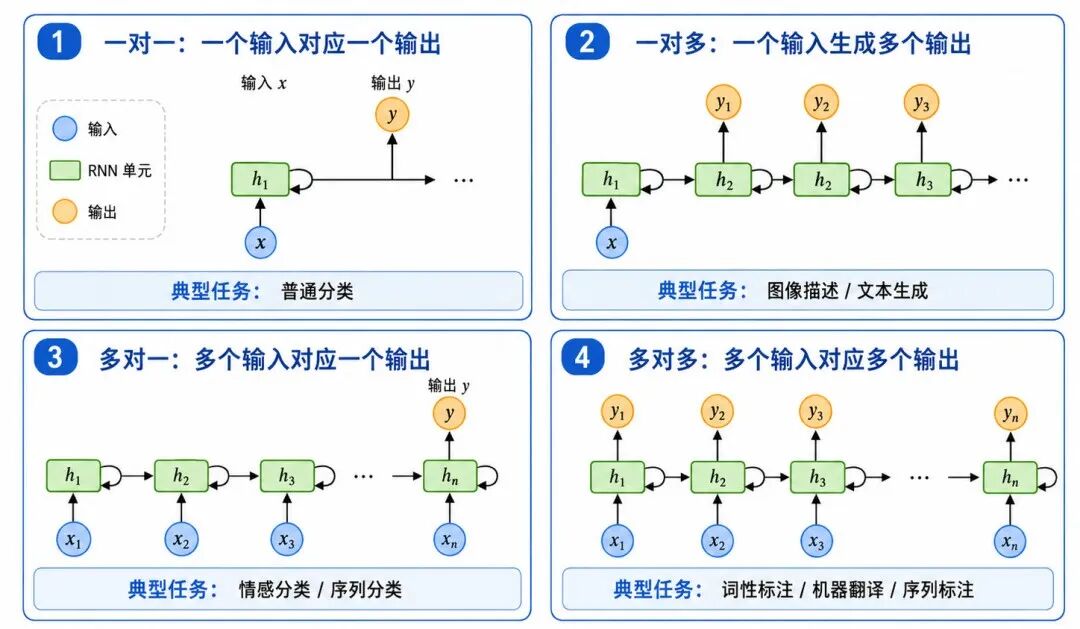
图 4:RNN 的常见输入输出形式
1、一对一:普通非序列任务
一对一形式类似普通前馈网络:
一个输入 → 一个输出
例如:
• 图像分类
• 表格分类
• 单样本回归
这类任务本身不一定需要 RNN。
2、一对多:从一个输入生成一个序列
一对多形式是:
一个输入 → 多个输出
例如:
• 图像生成文字描述
• 给定主题生成文本
• 给定初始条件生成时间序列
这类任务需要模型从一个初始信息开始,逐步生成序列输出。
3、多对一:序列分类
多对一形式是:
多个输入 → 一个输出
例如:
• 文本情感分类
• 用户流失预测
• 时间序列故障判断
• 语音片段分类
在这种任务中,模型读取完整序列后,根据最后的隐藏状态或聚合后的隐藏状态给出一个整体预测。
例如,文本情感分类可以理解为:
词语序列 → RNN → 最终隐藏状态 → 情感类别
4、多对多:序列标注或序列生成
多对多形式是:
多个输入 → 多个输出
例如:
• 词性标注
• 命名实体识别
• 机器翻译
• 语音识别
• 每个时间点的状态预测
如果输入序列和输出序列长度相同,可以在每个时间步输出一个预测结果。
如果输入序列和输出序列长度不同,则通常需要编码器---解码器结构。
五、隐藏状态、记忆能力与局限
RNN 的隐藏状态可以理解为模型对历史信息的压缩表示。
在第 t 个时间步,隐藏状态 hₜ 汇总了当前输入 xₜ 和此前隐藏状态 hₜ₋₁ 中的信息。这样,模型就能在处理后续输入时利用前面的上下文。
从直观角度看:
隐藏状态 = 当前输入 + 历史信息的综合表示
但是,普通 RNN 的记忆能力并不是无限的。
在较长序列中,早期信息需要经过很多时间步才能影响后面的输出。反向传播时,梯度也需要沿时间步不断向前传递。这会带来两个经典问题:
• 梯度消失
• 梯度爆炸
1、梯度消失
梯度消失(Vanishing Gradient)是指梯度在反向传播过程中逐渐变得非常小,导致较早时间步的参数难以有效更新。
在长序列任务中,这意味着模型很难学习远距离依赖。
例如,在句子:
go
虽然这部电影前半段节奏很慢,但结尾非常精彩,所以我还是很喜欢如果模型需要根据句子后面的"很喜欢"判断整体情感,就必须结合前面的转折结构。如果序列很长,普通 RNN 可能难以稳定保留远处信息。
2、梯度爆炸
梯度爆炸(Exploding Gradient)是指梯度在反向传播过程中不断放大,导致参数更新过大,训练不稳定,甚至出现损失变成异常值的情况。
常见缓解方法包括:
• 梯度裁剪
• 更合适的初始化
• 使用 LSTM 或 GRU
• 使用更稳定的优化器
在 PyTorch 中,梯度裁剪常用写法是:
apache
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)3、普通 RNN 的主要局限
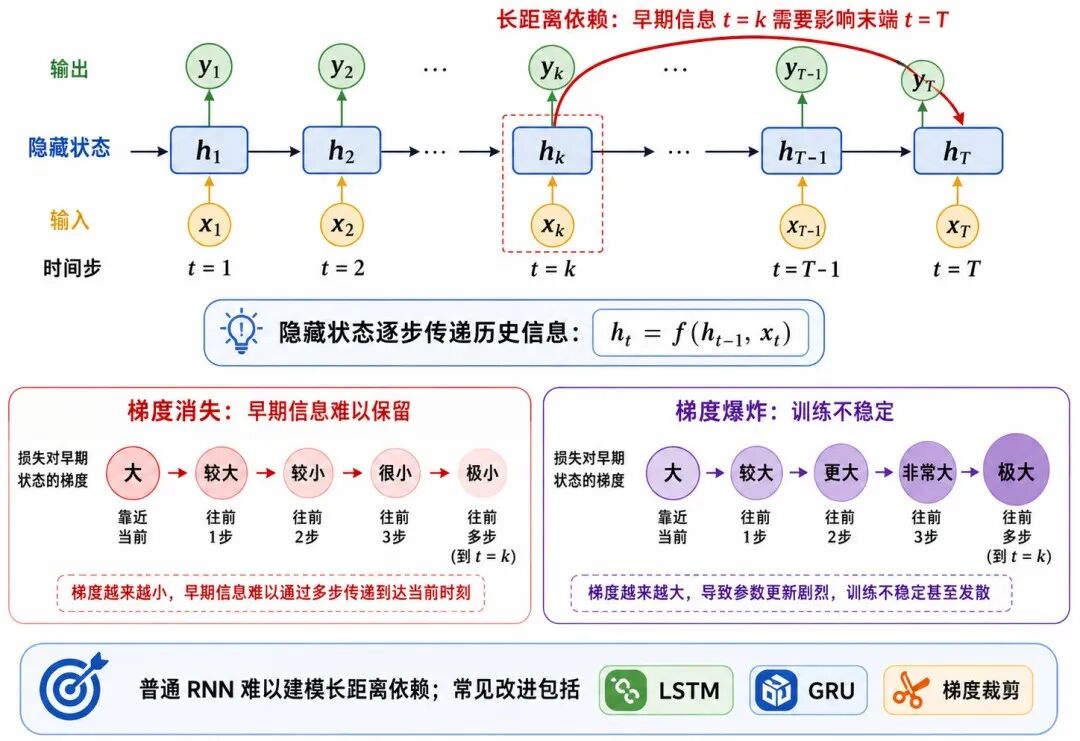
图 5:RNN 的隐藏状态与长距离依赖问题
普通 RNN 的主要局限包括:
• 难以建模长距离依赖
• 训练时可能出现梯度消失或梯度爆炸
• 序列计算难以完全并行
• 对较长文本或复杂上下文任务表现有限
因此,在很多实际任务中,普通 RNN 常被 LSTM、GRU、Transformer 等结构替代或扩展。
六、LSTM 与 GRU:对普通 RNN 的改进
为了解决普通 RNN 难以建模长距离依赖的问题,研究者提出了更复杂的循环结构,其中最经典的是 LSTM 和 GRU。
1、LSTM:加入门控机制与记忆单元
长短期记忆网络(Long Short-Term Memory,LSTM)在普通 RNN 的基础上引入了记忆单元和门控机制。
LSTM 的核心思想是:让模型自己学习哪些信息应该保留,哪些信息应该遗忘,哪些新信息应该写入。
它通常包含三个重要门控:
• 遗忘门:决定保留多少过去信息
• 输入门:决定写入多少当前信息
• 输出门:决定输出多少内部记忆
可以简单理解为:
• 普通 RNN:所有信息都混合在隐藏状态中
• LSTM:通过门控机制管理信息的保留、写入和输出
LSTM 更适合处理较长序列和复杂上下文关系。
2、GRU:更简化的门控循环单元
门控循环单元(Gated Recurrent Unit,GRU)可以看作一种更简化的门控 RNN。它通常包含:
• 更新门
• 重置门
GRU 的结构比 LSTM 更简单,参数更少,训练速度通常更快。在很多任务中,GRU 能取得接近 LSTM 的效果。
3、普通 RNN、LSTM 与 GRU 的关系
可以粗略理解为:
• RNN:基础循环结构,简单但长距离记忆能力有限
• LSTM:加入更完整的门控机制,适合长序列建模
• GRU:结构更简洁的门控循环网络,在效率和效果之间折中
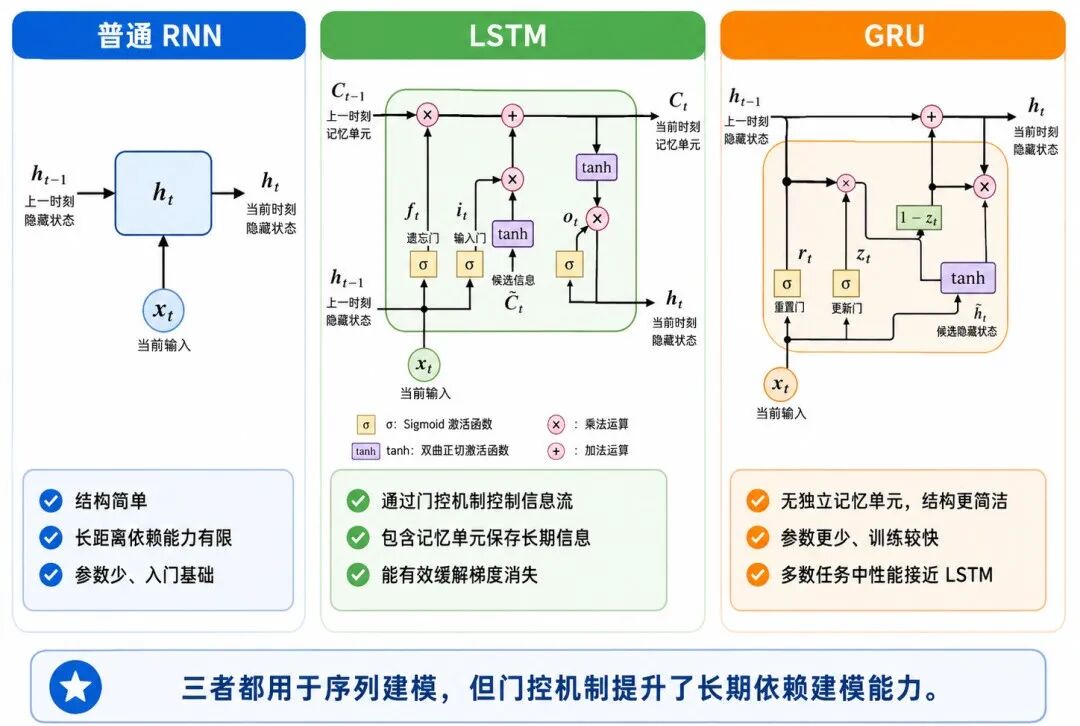
图 6:RNN、LSTM 与 GRU 的结构对比
在学习路径上,普通 RNN 适合帮助理解序列建模的基本思想;LSTM 和 GRU 则是更常见的实用循环网络结构。
七、PyTorch 实现:使用 RNN 进行文本情感分类
下面使用 PyTorch 构建一个简单 RNN,用于演示文本情感分类的基本流程。
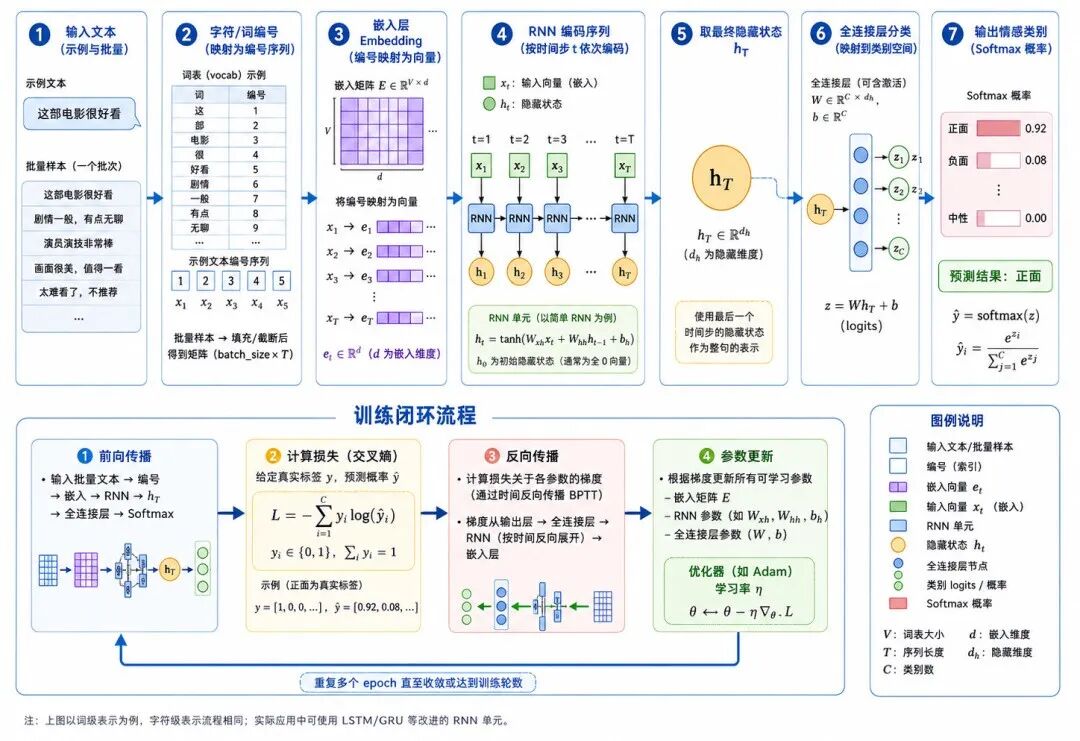
图 7:RNN 文本分类的训练与预测流程
为了避免依赖外部大型数据集,示例使用一个小型中文样例数据集。这个示例的目标不是训练高性能模型,而是帮助理解 RNN 的基本输入、隐藏状态和训练闭环。
任务是:根据一句中文短句,判断它是正面情感还是负面情感。
1、导入库并准备数据
javascript
import torchimport torch.nn as nnfrom torch.utils.data import Dataset, DataLoader构造一个简单数据集:
ini
# 定义样本数据:(文本, 标签) 其中标签1表示正面,0表示负面samples = [ ("《主角》这部电视连续剧非常好看", 1), ("演员表演非常精彩", 1), ("剧情紧凑我很喜欢", 1), ("这家餐厅味道不错", 1), ("服务态度很好", 1), ("这部电影太难看了", 0), ("剧情拖沓让人失望", 0), ("演员表演很糟糕", 0), ("这家餐厅味道很差", 0), ("服务态度不好", 0),]为了简化演示,这里按"单字"构建词表。真实任务中通常会使用分词器、子词模型或预训练词向量。
2、构建字符表与编码函数
cs
# 构建字符表:将所有文本中的字符去重后排序chars = sorted(set("".join(text for text, _ in samples)))
# 为每个字符分配一个唯一ID(从1开始,0留作填充符)char_to_id = { char: idx + 1 for idx, char in enumerate(chars)}
# 填充符ID为0pad_id = 0
# 编码函数:将文本转为ID序列def encode_text(text): return [char_to_id[char] for char in text]其中:
• char_to_id 用于把字符转换为整数编号
• pad_id=0 表示填充符
• encode_text() 把文本转换为编号序列
例如:
bash
print(encode_text("电影好看"))输出可能类似:
cs
[33, 22, 16, 34]3、定义数据集与填充函数
因为不同句子的长度可能不同,所以需要在一个批次中把它们填充到相同长度。
python
class SentimentDataset(Dataset): """情感分析数据集,将文本转为ID序列""" def __init__(self, samples): self.samples = samples # 存储原始样本列表 (text, label)
def __len__(self): return len(self.samples) # 返回数据集大小
def __getitem__(self, index): text, label = self.samples[index] # 获取一个样本 ids = encode_text(text) # 将文本编码为ID列表 # 返回ID张量和标签张量,类型均为long return torch.tensor(ids, dtype=torch.long), torch.tensor(label, dtype=torch.long)
def collate_fn(batch): """批处理函数:将多个样本填充到相同长度,并返回长度信息""" sequences, labels = zip(*batch) # 分离ID序列和标签
# 记录每个序列的原始长度 lengths = torch.tensor( [len(seq) for seq in sequences], dtype=torch.long )
# 使用pad_sequence将序列填充到同一长度(右侧填充),batch_first=True输出形状 (B, T) padded_sequences = nn.utils.rnn.pad_sequence( sequences, batch_first=True, padding_value=pad_id # 使用预设的填充符ID (0) )
labels = torch.stack(labels) # 将标签堆叠成一维张量
return padded_sequences, lengths, labels # 返回填充后的序列、原始长度、标签其中:
• Dataset 用于定义样本读取方式
• collate_fn 用于处理一个 batch 中不同长度的序列
• pad_sequence 用于把序列填充到相同长度
• batch_first=True 表示输出形状为 batch_size × sequence_length
构建 DataLoader:
makefile
# 创建情感分析数据集实例,传入样本列表dataset = SentimentDataset(samples)
# 创建DataLoader,用于批量加载数据train_loader = DataLoader( dataset, # 数据集对象 batch_size=4, # 每批4个样本 shuffle=True, # 每个epoch打乱数据顺序 collate_fn=collate_fn # 自定义批处理函数,负责填充和对齐序列)4、定义 RNN 文本分类模型
文本输入需要先经过嵌入层(Embedding Layer),把整数编号转换为稠密向量。
python
class RNNTextClassifier(nn.Module): """基于RNN的文本分类器""" def __init__(self, vocab_size, embed_dim, hidden_size, num_classes): super().__init__()
# 词嵌入层:将词ID映射为稠密向量 self.embedding = nn.Embedding( num_embeddings=vocab_size, # 词汇表大小 embedding_dim=embed_dim, # 嵌入维度 padding_idx=pad_id # 填充词ID不参与梯度更新 )
# RNN层(简单循环神经网络) self.rnn = nn.RNN( input_size=embed_dim, # 输入特征维度(嵌入维) hidden_size=hidden_size, # 隐藏状态维度 batch_first=True # 输入形状为 (batch, seq, feature) )
# 全连接分类层:将最后一层隐藏状态映射到类别logits self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x, lengths): # x: 填充后的序列 (batch, seq_len) # lengths: 各序列原始长度(本例未直接用于RNN,仅作接口保留)
# 嵌入层:输出 (batch, seq_len, embed_dim) embedded = self.embedding(x)
# RNN前向传播 # output: 所有时间步的隐藏状态 (batch, seq_len, hidden_size) # hidden: 最后一层各时间步的隐藏状态 (num_layers, batch, hidden_size) output, hidden = self.rnn(embedded)
# 取最后一层的最后一个时间步(即RNN的最终隐藏状态)作为文档表示 last_hidden = hidden[-1] # 形状 (batch, hidden_size)
# 分类输出 logits = self.fc(last_hidden) # 形状 (batch, num_classes) return logits这个模型包含三部分:
Embedding → RNN → Linear
其中:
• Embedding 把字符编号转换为向量
• RNN 按顺序读取字符向量并更新隐藏状态
• Linear 根据最终隐藏状态输出类别得分
需要注意:
• x 的形状是 batch_size × sequence_length
• embedded 的形状是 batch_size × sequence_length × embed_dim
• hidden 的形状是 num_layers × batch_size × hidden_size
• last_hidden 表示最后一层 RNN 的最终隐藏状态
• logits 的形状是 batch_size × num_classes
5、定义模型、损失函数和优化器
makefile
# 词汇表大小:字符ID数(从1开始) + 1(填充符0)vocab_size = len(char_to_id) + 1embed_dim = 16 # 嵌入向量维度hidden_size = 32 # RNN隐藏层维度num_classes = 2 # 二分类(正面/负面)
# 实例化RNN文本分类器model = RNNTextClassifier( vocab_size=vocab_size, embed_dim=embed_dim, hidden_size=hidden_size, num_classes=num_classes)
# 损失函数:交叉熵(适用于多分类,此处二分类)criterion = nn.CrossEntropyLoss()# 优化器:Adam,学习率0.01optimizer = torch.optim.Adam(model.parameters(), lr=0.01)其中:
• vocab_size 表示词表大小
• embed_dim 表示字符向量维度
• hidden_size 表示隐藏状态维度
• num_classes=2 表示二分类
• CrossEntropyLoss 用于多类分类,包括二分类的两个类别输出
• Adam 用于更新模型参数
这里模型最后输出的是 logits,不需要手动添加 Softmax。
6、训练模型
python
num_epochs = 30 # 训练轮数
for epoch in range(num_epochs): model.train() # 设置为训练模式
total_loss = 0.0 # 累计本轮所有样本损失
# 遍历DataLoader,每次获取一个batch for batch_x, lengths, batch_y in train_loader: # 前向传播:计算logits logits = model(batch_x, lengths) # 计算交叉熵损失 loss = criterion(logits, batch_y)
# 反向传播:清空梯度、计算梯度、更新参数 optimizer.zero_grad() loss.backward() optimizer.step()
# 累加该batch的总损失(乘以batch内样本数) total_loss += loss.item() * batch_x.size(0)
# 计算本轮平均损失(总损失 / 总样本数) avg_loss = total_loss / len(dataset)
# 每10轮输出一次平均损失 if (epoch + 1) % 10 == 0: print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {avg_loss:.4f}")训练流程仍然是深度学习中的标准闭环:
前向传播 → 计算损失 → 清空旧梯度 → 反向传播 → 更新参数
其中:
• logits = model(batch_x, lengths) 表示前向传播
• loss = criterion(logits, batch_y) 表示计算分类损失
• optimizer.zero_grad() 清空旧梯度
• loss.backward() 自动计算新梯度
• optimizer.step() 根据梯度更新参数
7、预测新句子
python
def predict_sentiment(text): """预测单条文本的情感倾向(正面/负面)""" model.eval() # 切换到推理模式(关闭Dropout等)
# 将文本编码为ID张量,并添加batch维度(形状: 1, seq_len) ids = torch.tensor( encode_text(text), dtype=torch.long ).unsqueeze(0)
# 计算序列长度(此处为全部有效长度,无填充) lengths = torch.tensor([ids.size(1)])
# 无梯度环境下前向传播 with torch.no_grad(): logits = model(ids, lengths) # 输出形状 (1, num_classes) pred = logits.argmax(dim=1).item() # 取最大概率的类别索引
# 将类别索引(0或1)转换为文字 return "正面" if pred == 1 else "负面"测试预测:
bash
print(predict_sentiment("电影非常精彩"))print(predict_sentiment("服务太差了"))可能输出:
go
正面负面由于这里的数据集非常小,模型只是演示 RNN 的基本流程,不能代表真实中文情感分析系统的效果。真实任务通常需要更大数据集、更可靠的分词方法、更复杂的模型结构,以及验证集和测试集评估。
8、查看张量形状
可以通过打印形状来理解 RNN 的输入输出:
python
# 取一个batch的数据用于观察中间张量形状batch_x, lengths, batch_y = next(iter(train_loader))
# 通过模型的嵌入层,将ID序列转为词向量序列embedded = model.embedding(batch_x)# 通过RNN层,得到所有时间步的输出和最后一个时间步的隐藏状态output, hidden = model.rnn(embedded)
# 打印各阶段张量形状print("输入编号形状:", batch_x.shape) # (batch, seq_len)print("嵌入后形状:", embedded.shape) # (batch, seq_len, embed_dim)print("RNN 输出形状:", output.shape) # (batch, seq_len, hidden_size)print("最终隐藏状态形状:", hidden.shape) # (num_layers, batch, hidden_size)可能看到类似结果:
css
输入编号形状: torch.Size([4, 8])嵌入后形状: torch.Size([4, 8, 16])RNN 输出形状: torch.Size([4, 8, 32])最终隐藏状态形状: torch.Size([1, 4, 32])其中:
• 4 表示 batch_size
• 8 表示当前批次中填充后的序列长度
• 16 表示嵌入向量维度
• 32 表示隐藏状态维度
• 1 表示 RNN 层数
八、RNN 的适用场景、局限与扩展方向
RNN 是序列建模中的基础模型。它虽然在许多现代任务中已经被 LSTM、GRU 或 Transformer 替代,但仍然是理解序列神经网络的重要入口。
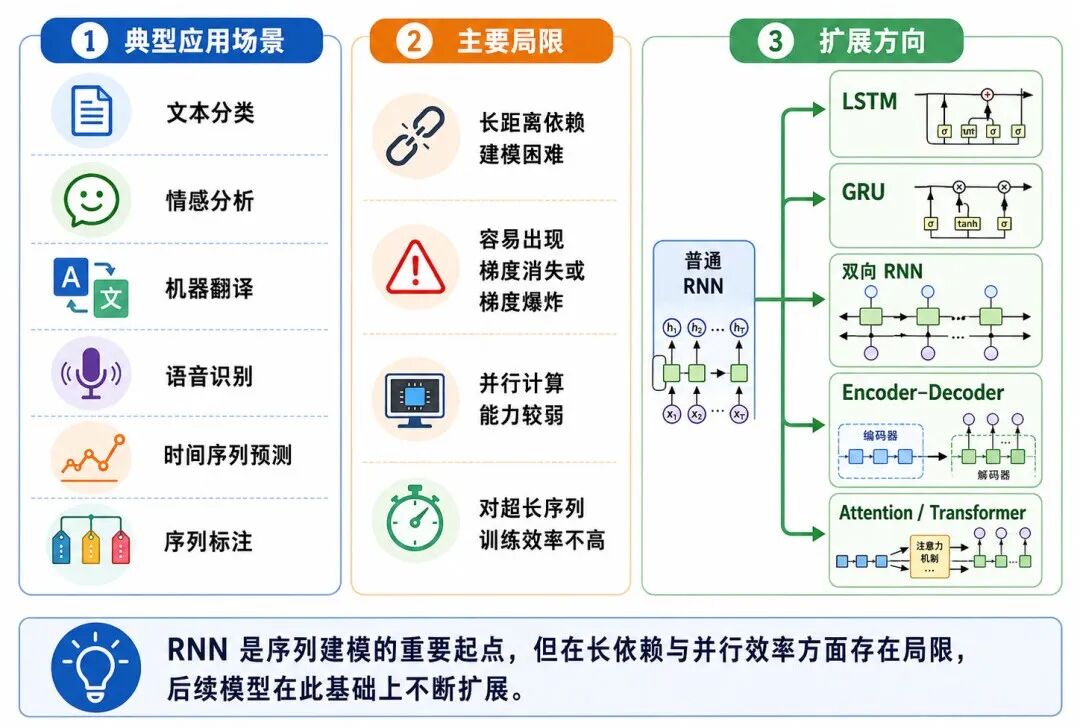
图 8:RNN 的适用场景、局限与扩展方向
1、适用场景
RNN 适合处理具有顺序关系的数据,例如:
• 文本分类
• 时间序列预测
• 语音识别
• 序列标注
• 用户行为建模
• 传感器数据分析
• 简单序列生成任务
这些任务的共同特点是:数据元素之间存在顺序依赖。
2、主要优势
RNN 的主要优势包括:
• 能处理变长序列
• 能通过隐藏状态传递历史信息
• 参数在时间步之间共享
• 适合解释序列建模的基本思想
• 可以扩展为 LSTM、GRU、编码器---解码器结构
与前馈神经网络相比,RNN 更适合处理"前后相关"的数据。
3、主要局限
普通 RNN 也有明显局限:
• 长距离依赖建模能力有限
• 容易出现梯度消失或梯度爆炸
• 时间步之间存在依赖,难以完全并行计算
• 对长文本和复杂上下文任务表现有限
• 实际应用中常被 LSTM、GRU 或 Transformer 替代
这些局限并不意味着 RNN 不重要。相反,RNN 是理解序列建模、隐藏状态和时间展开的重要基础。
4、扩展方向
从普通 RNN 出发,可以继续学习:
• LSTM:通过门控机制增强长期记忆能力
• GRU:更简洁的门控循环网络
• 双向 RNN:同时利用前向和后向上下文
• 编码器---解码器结构:用于序列到序列任务
• 注意力机制:帮助模型直接关注重要时间步
• Transformer:用自注意力机制替代循环结构,提升并行能力和长距离建模能力
这些模型虽然结构更复杂,但都可以从 RNN 的基本问题出发理解:如何让模型有效利用序列中的上下文信息。
📘 小结
循环神经网络通过隐藏状态在时间步之间传递历史信息,使模型能够处理文本、语音、时间序列等顺序数据。普通 RNN 适合理解序列建模的基本思想,但在长距离依赖上存在梯度消失和训练效率问题。LSTM、GRU 和 Transformer 等结构,正是在此基础上进一步改进而来。

"点赞有美意,赞赏是鼓励"