Excel Python:飞速搞定数据分析与处理

第四部分 使用 xlwings 对 Excel 应用程序进行编程
第十二章 用户定义函数
前面 3 章展示了如何使用 Python 脚本自动化 Excel,以及如何在 Excel 中一键执行这样的脚本。本章会介绍另一种利用 xlwings 在 Excel 中调用 Python 代码的方法,即用户定义函数 (user-defined function,UDF)。 UDF 是可以用在 Excel 单元格中的 Python 函数,就像使用内置的 SUM 函数和 AVERAGE函数一样。和第 11 章一样,我们首先从 quickstart 命令开始,尝试创建第一个 UDF。然后进入案例研究,学习如何从 Google Trends 上获取和处理数据,以便处理一些更复杂的 UDF:学习如何处理 pandas DataFrame 和图表,以及如何调试 UDF。最后本章会以性能优化为中心深入了解一些高级主题。不幸的是,xlwings 在 macOS 中不支持 UDF,所以本章需要你在 Windows 中运行示例代码。
12.2 案例研究:Google Trends
在本节的案例研究中,我们会先使用来自 Google Trends 的数据学习如何利用 pandas DataFrame 和动态数组(动态数组是微软在 2020 年官方发布的 Excel 最令人激动的新特性之一)。然后会创建直接连接到 Google Trends 的 UDF,以及使用 DataFrame 的 plot 方法的 UDF。最后会了解一下如何调试 UDF。下面先来简要介绍一下 Google Trends。
12.2.1 Google Trends 简介
Google Trends 是谷歌提供的一项服务,你可以利用它来分析某条谷歌搜索查询在不同时间和地区的受欢迎程度。下图展示的是在添加了一些热门编程语言名称之后的 Google Trends 页面,其选定了全世界为地区,2016 年 1 月 1 日至 2020 年 12 月 26 日为时间范围。 每个搜索关键词都在输入之后显示的下拉菜单中选择了 Programming language 为上下文。 这样就可以忽略 Python 和 Java。谷歌会以百分制来评价关键词在选定时间范围和位置的搜索热度。在我们的例子中,它表明在给定的时间范围和位置中,在 2016 年 2 月,Java 的搜索热度最高。要想了解有关 Google Trends 的更多细节,可以参见其官方博客文章。
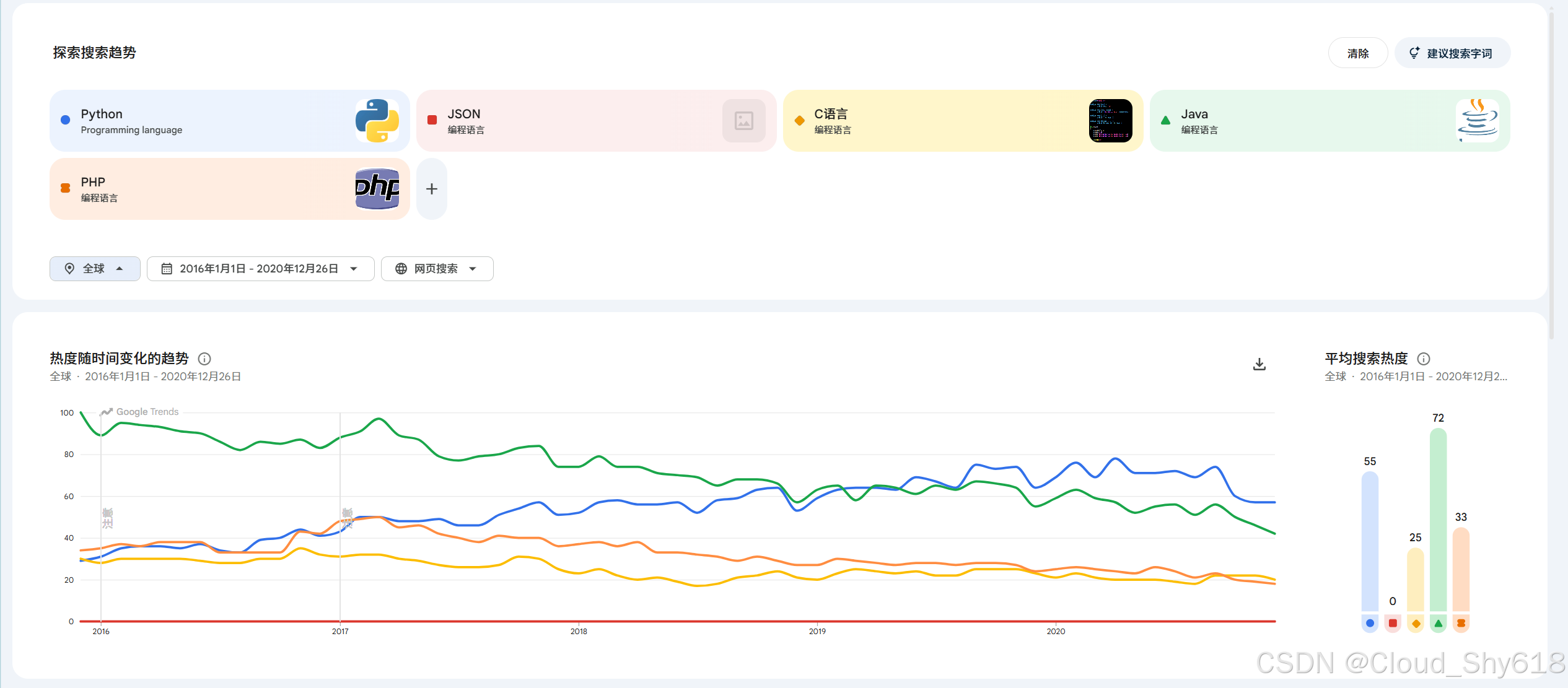
随机采样: Google Trends 的数据来源于随机采样,也就是说,即使你选择了和上图同样的位置、时间范围和搜索关键词,看到的结果也可能和图片中不一样。
按下下载按钮(参见上图)下载 CSV 文件,并将其中的数据复制到了 quickstart 项目的 Excel 工作簿中。在下一节中,会向你展示这个工作簿在哪里,并使用这个文件和 UDF 直接在 Excel 中分析数据。
12.2.2 使用 DataFrame 和动态数组
pandas DataFrame 也是 UDF 的 "好伙伴",对此你应该不会感到惊讶。为了了解 DataFrame 和 UDF 是如何协作的,并在此过程中学习动态数组,我们进入配套代码库的 udfs 目录下的 describe 文件夹中,在 Excel 中打开 describe.xlsm,在 VS Code 中打开 describe.py。这个 Excel 文件包含了来自 Google Trends 的数据,而在 Python 文件中你会看到开头有一个简单的函数,如例 12-2 所示。
例12-2 describe.py
import xlwings as xw
import pandas as pd
@xw.func
@xw.arg("df", pd.DataFrame, index=True, header=True)
def describe(df):
return df.describe()和之前的 quickstart 项目中的 hello 函数相比,你会注意到这里还有另一个装饰器:
@xw.arg("df", pd.DataFrame, index=True, header=True)arg 是 argument 的缩写,你可以在这个装饰器中应用第 9 章在介绍 xlwings 语法时提到的那些转换器和选项。换句话说,这个装饰器之于 UDF,就像 options 方法之于 xlwings 的 range 对象一样,它们提供了同样的功能。规范地说,arg 装饰器的语法如下:
@xw.arg("argument_name", convert=None, option1=value1, option2=value2, ...)为了帮助你和第 9 章联系起来,下面是 describe 函数的等效脚本(假定 describe.xlsm 已在 Excel 中打开且应用到了 A3:F263):
import xlwings as xw
import pandas as pd
data_range = xw.Book("describe.xlsm").sheets[0]["A3:F263"]
df = data_range.options(pd.DataFrame, index=True, header=True).value
df.describe()index 和 header 选项并非必填参数,因为它们有默认值。这里把这两个参数包含进来是为了展示它们是如何用到 UDF 上的。当 describe.xlsm 为活动工作簿时,点击 Import Functions 按钮,在一个空单元格(如 H3)中输入 =describe(A3:F263)。按下回车键会发 生什么取决于 Excel 的版本,尤其是当你的 Excel 版本比较新且支持动态数组的话。如果 Excel 支持动态数组,你就会看到图 12-5 所示的情形,也就是说 describe 函数在 H3:M11 的输出会被蓝色边框包围。只有当光标在数组中时才能看到蓝色边框,图 12-5 只是一张截图,因此并未显示此效果。我们马上就会看到动态数组是如何工作的,你还可以在后文的 "动态数组" 中了解到更多知识。

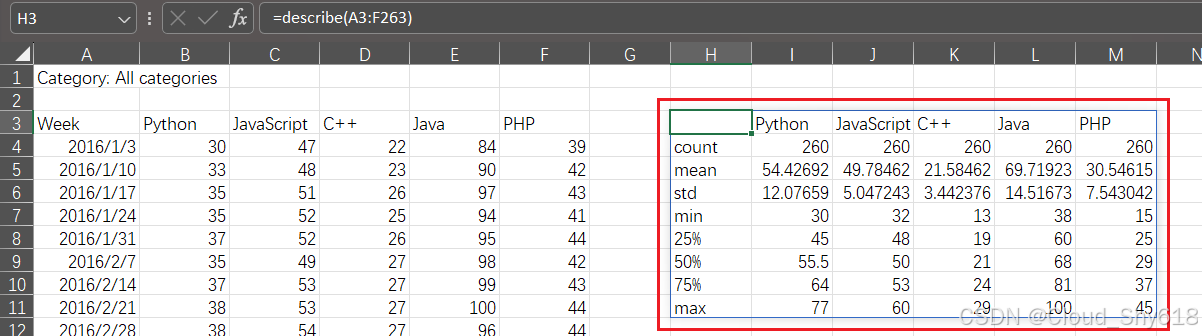
图 12-5:describe 函数和动态数组
不过,如果你使用的是不支持动态数组的 Excel,那么按下按钮之后就跟什么都没发生一样: 在默认情况下这个公式只会返回左上方的 H3 单元格,这是一个空单元格。要解决这个问题,需要使用微软如今称为旧式 CSE 数组的技术。博主使用的是 windows 自带激活的 Excel 2021 版本,如果你的 Excel 版本较低,无法实现上图的动态数组,可以看看接下来的步骤。
CSE 数组需要按快捷键 Ctrl+Shift+Enter, 而不是只按回车键,CSE 因此而得名。下面来详细了解一下它们的工作方式。
- 选中 H3 单元格并按下 Delete 键以确认其为空单元格。
- 选择从 H3 开始到 M11 结束的输出区域中的所有单元格。
- 选中 H3:M11 区域之后,输入公式 =describe(A3:F263),按快捷键 Ctrl+Shift+Enter 确认。
你应该会看到和图 12-5 差不多的画面,但是有以下区别。
- 在 H3:M11 区域周围没有蓝色边框。
- 公式被花括号包围表明它是 CSE 数组:{=decribe(A3:F263)}。
- 选中左上角单元格并按下 Delete 键即可删除动态数组,但是如果想删除 CSE 数组,则必须选中整个数组才可以。
现在来引入可选参数以使这个函数更加有用。这个名为 selection 的可选参数可以让我们指定想在输出中包含的列。如果你有很多列但是只想在 describe 函数中包含其中的一个子集,那么这就会成为一个很好用的特性。将函数做如下改动。
@xw.func
@xw.arg("df", pd.DataFrame) ➊
def describe(df, selection=None): ➋
if selection is not None:
return df.loc[:, selection].describe() ➌
else:
return df.describe()➊ 这里省去了 index 参数和 header 参数,直接使用了默认值。不过你也可以保留它们。
➋ 添加可选参数 selection,以 None 为默认值。
➌ 如果提供了 selection,则可以用它来筛选 DataFrame 的列。
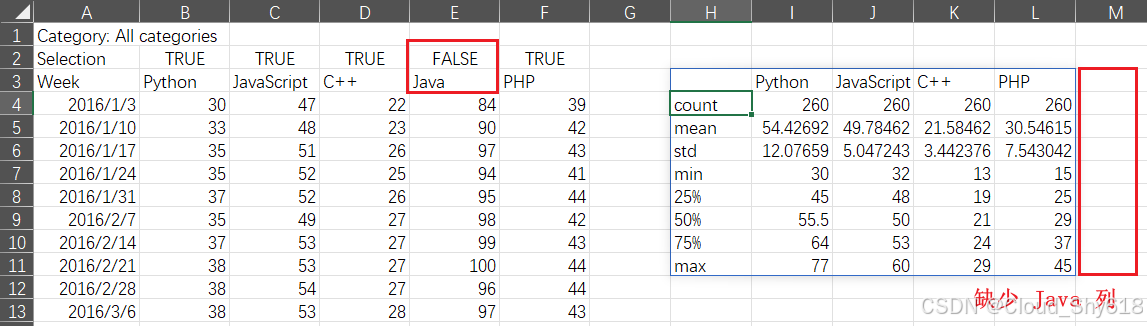
函数修改完毕后,要记得保存,然后再按下 xlwings 插件上的 Import Functions 按钮。因为添加了新的参数,所以必须这样做。将 Selection 写入 A2 单元格,将 TRUE 写入 B2:F2 单元格区域。最后,根据你的 Excel 版本是否支持动态数组,对 H3 单元格中的公式进行相应的改动。
- 支持动态数组: 选中 H3 单元格,将公式修改为 =describe(A3:F263, B2:F2),按下回车键。
- 不支持动态数组: 从 H3 单元格开始,选中 H3:M11 区域,然后按下 F2 键激活 H3 单元格的编辑模式,将公式修改为 =describe(A3:F263, B2:F2)。最后按下快捷键 Ctrl+Shift+Enter。
为了测试一下改进后的函数,把 E2 单元格中 Java 的 TRUE 改成 FALSE 来看看会发生什么: 支持动态数组时,你会看到表格神奇地缩小了一列。而使用 CSE 数组时,你会得到一列难看的 #N/A,如下图所示。
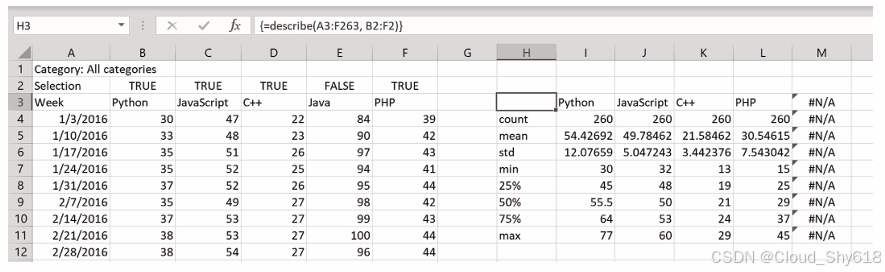
要避免这种问题,xlwings 可以利用返回装饰器来调整旧式 CSE 数组的大小。像下面这样添加这个装饰器:
@xw.func
@xw.arg("df", pd.DataFrame)
@xw.ret(expand="table") ➊
def describe(df, selection=None):
if selection is not None:
return df.loc[:, selection].describe()
else:
return df.describe()➊ 添加返回装饰器并设置参数 expand="table",xlwings 会调整 CSE 数组的大小以匹配返回的 DataFrame 的维度。
在添加返回装饰器之后,保存 Python 源文件,切换至 Excel,按下快捷键 Ctrl+Alt+F9 重新计算:CSE 数组的大小会发生变化,同时全是 #N/A 的列也被移除了。由于这只是一种妥协的做法,因此强烈建议还是尽可能地使用支持动态数组的 Excel 版本。
注意:函数装饰器的顺序,一定要把 xw.func 装饰器放在 xw.arg 装饰器和 xw.ret 装饰器上方,不过 xw.arg 和 xw.ret 的顺序无关紧要。
返回装饰器 在概念上和参数装饰器的工作方式是一样的,只不过你不必指定参数的名称。 例如,返回装饰器的语法看起来是这样的:
@xw.ret(convert=None, option1=value1, option2=value2, ...)通常情况下不必显式地提供 convert 参数,因为 xlwings 会自动识别返回值类型。这和第 9 章中将值写入 Excel 所用到的 options 方法是一样的行为。
如果不想在返回的 DataFrame 中包含索引,那么可以像下面这样使用这个装饰器。
@xw.ret(index=False)动态数组:
见识过动态数组在 describe 函数下的工作方式后,我敢肯定你也认同动态数组是微软这么久以来为 Excel 加入的最关键、最振奋人心的功能。动态数组在 2020 年首次和使用最新版本的 Microsoft 365 订阅用户见面。要想知道你使用的版本是否支持这项功能, 可以检查 UNIQUE 函数是否存在:在单元格中输入 =UNIQUE,如果 Excel 提示了这个函数名,那么就是支持动态数组的。关于动态数组的行为,这里有一些技术上的要点。
- 如果动态数组用一个值覆盖了一个单元格,你就会得到 #SPILL! 错误。在删除或移动发生重叠的单元格为动态数组腾出空间之后,数组就会完成写入。注意,xlwings 的带有 expand="table" 的返回装饰器则没有那么智能,它会覆盖现有单元格中的值 而不会发出警告!
- 可以使用左上角单元格地址加上 # 符号来应用动态数组的一个区域。如果你的动态数组位于 A1:B2,你想对所有单元格进行求和,就可以写成 =SUM(A1#)。
- 如果你想让动态数组表现得和旧式 CSE 数组一样,就需要在公式前加上 @ 符号。 例如,要让矩阵乘法运算返回旧式 CSE 数组,需要写成 =@MMULT()。
对于这里这个介绍性的例子来说,下载一个 CSV 文件然后将里面的值复制并粘贴到 Excel 文件里面也没什么问题。但是复制粘贴这个过程本身就很容易出错,所以在能够避免这种操作的时候应该尽量避免。使用 Google Trends 的时候,你自然能够避免复制粘贴,下一 节会展示应该怎样做。
12.2.3 从 Google Trends 上获取数据
前面的例子没什么复杂的,基本上就是包装了一个简单的 pandas 函数。要着手操作更贴近现实的例子,需要创建一个从 Google Trends 上下载数据的 UDF,这样你就不用到网页上去手动下载 CSV 文件了。Google Trends 没有官方的 API,但是有一个叫作 pytrends 的 Python 包填补了这一空缺。非官方 API 意味着只要谷歌想修改 API,它随时都能改。所以有可能在某个时候本节中的例子就用不了了。不过,考虑到在撰写本书时 pytrends 已经面世 5 年多了,即使出现问题它也很有可能会更新修复。在第 1 章中提到存在着万能的Python包,pytrends 就是一个绝佳的例子。如果你无法使用 Power Query,那么可能需要再投入一点儿资金才可以,至少我没能找到一种免费的即插即用的解决方案。由于 pytrends 不是 Anaconda 的一部分,也不是官方 Conda 包,如果你还没有安装的话,可以用来 pip 安装:
(base) C:\Users\SHY>pip install pytrends为了复现网页版 Google Trends 的情形,需要在 "Programming language" 上下文中为搜索关键词找到正确的标识符。要做到这一点,pytrends 可以打印出 Google Trends 在下拉菜单中建议的各种搜索上下文或者类别。在下面的示例代码中,mid 代表 Machine ID, 这就是我们要找的 ID:
In [4]: from pytrends.request import TrendReq
In [5]: # 首先,来实例化一个TrendRequest对象
trend = TrendReq()
In [6]: # 现在就能打印出输入"Python"后出现在
# 网页版Google Trends下拉菜单中的那些建议
trend.suggestions("Python")
Out[6]: [{'mid': '/m/05z1_', 'title': 'Python', 'type': 'Programming language'},
{'mid': '/m/05tb5', 'title': 'Python family', 'type': 'Snake'},
{'mid': '/m/0cv6_m', 'title': 'Pythons', 'type': 'Snake'},
{'mid': '/m/06bxxb', 'title': 'CPython', 'type': 'Topic'},
{'mid': '/g/1q6j3gsvm', 'title': 'python', 'type': 'Topic'}]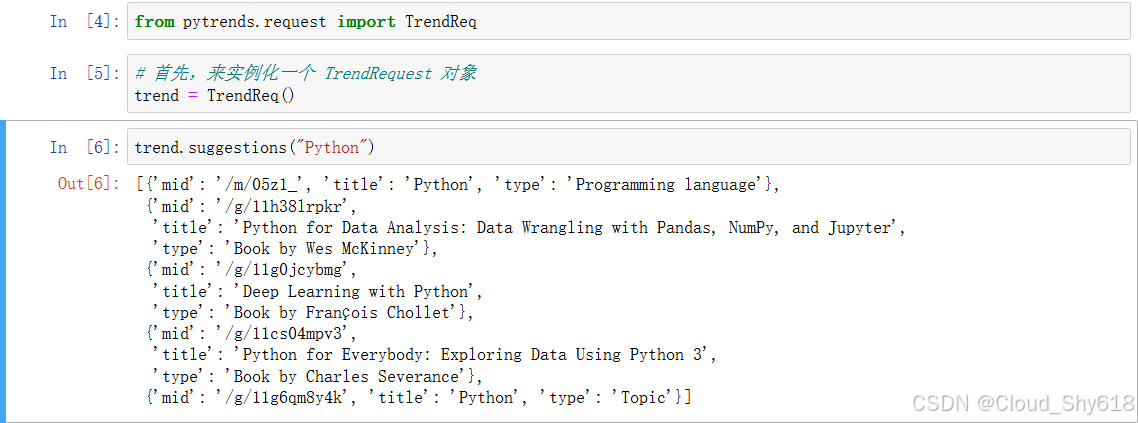
对其他编程语言也重复这个过程以获取所有编程语言关键词的 mid,有了这些 mid 后就能编写例 12-3 中的 UDF 了。你可以在配套代码库的 udfs 文件夹的 google_trends 目录中找到源代码。
例 12-3 google_trends.py 中的 get_interest_over_time 函数(只摘录了相关部分的 import
语句)
import pandas as pd
from pytrends.request import TrendReq
import xlwings as xw
@xw.func(call_in_wizard=False) ➊
@xw.arg("mids", doc="Machine IDs: A range of max 5 cells") ➋
@xw.arg("start_date", doc="A date-formatted cell")
@xw.arg("end_date", doc="A date-formatted cell")
def get_interest_over_time(mids, start_date, end_date):
"""查询 Google Trends:在返回值中将常见编程语言的 Machine ID (mid)
替换成人类可读的名称,例如,对于 Machine ID "/m/05z1_" 会返回 "Python"
""" ➌
# 检查并转换参数
assert len(mids) <= 5, "Too many mids (max: 5)" ➍
start_date = start_date.date().isoformat() ➎
end_date = end_date.date().isoformat()
# 构造 Google Trends 请求并返回 DataFrame
trend = TrendReq(timeout=10) ➏
trend.build_payload(kw_list=mids,
timeframe=f"{start_date} {end_date}") ➐
df = trend.interest_over_time() ➑
# 用人类可读的单词替换谷歌的 mid
mids = {"/m/05z1_": "Python", "/m/02p97": "JavaScript",
"/m/0jgqg": "C++", "/m/07sbkfb": "Java", "/m/060kv": "PHP"}
df = df.rename(columns=mids) ➒
# 删去 isPartial 列
return df.drop(columns="isPartial") ➓➊ 在默认情况下,在函数向导(Function Wizard)中打开这个函数时 Excel 会调用这个函数。这个过程会很费时间,特别是当函数涉及 API 请求时,所以这里关闭了这个功能。
➋ 可以为函数参数添加文档字符串,在你编辑各个参数时,函数向导会显示这些内容, 如图 12-8 所示。
➌ 函数的文档字符串会显示在函数向导中,如图 12-8 所示。
➍ 当用户提供了过多的 mid 时,可以方便地利用 assert 语句引发错误。Google Trends 允许每个查询最多有 5 个 mid。
➎ pytrends 要求用格式为 YYYY-MM-DD 的单个字符串来表示开始日期和结束日期。由于我们用的是格式为日期的单元格来表示开始日期和结束日期,因此它们在 Python 代码中是 datetime 对象的形式。调用它们的 date 方法和 isoformat 方法可以将它们正确格式化为 pytrends 所需形式。
➏ 此处在初始化一个 pytrends request 对象。为其将 timeout 设置为 10 秒可以降低发生 requests.exceptions.ReadTimeout 错误的风险,如果 Google Trends 花了较长时间进行响应,那么时不时就会发生这种错误。如果你依然看到了这样的错误,则可以再运行一次这个函数或者延长超时时间。
➐ 为请求对象提供 kw_list 参数和 timeframe 参数。
➑ 通过调用 interest_over_time 执行实际的请求,它会返回一个 pandas DataFrame。
➒ 将 mid 重命名为人类可读的内容。
➓ 最后一列叫作 isPartial。为了保持简单性且和网页版对应,在返回 DataFrame 时会丢弃这一列。
现在打开配套代码库中的 google_trends.xlsm,点击 xlwings 插件上的 Import Functions 按钮,然后在 A4 单元格中调用 get_interest_over_time 函数,如图 12-7 所示。

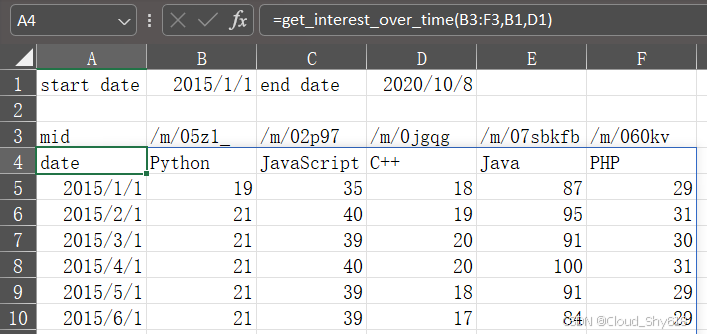
图 12-7:google_trends.xlsm
要获取各个函数参数的帮助,在选中 A4 单元格时点击公式栏左侧的插入函数按钮,点 击按钮后会打开函数向导,你可以在其中的 xlwings 分类下找到你的 UDF。
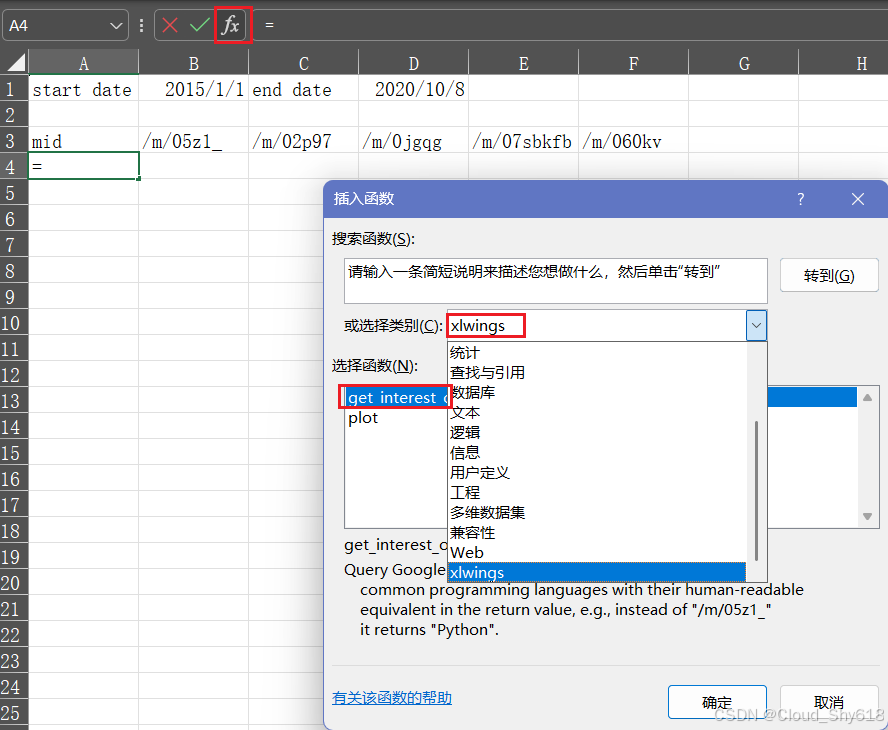
在选中 get_ interest_over_time 后,你会看到函数参数的名称以及作为描述的文档字符串(仅显示前 256 个字符),如图 12-8 所示。
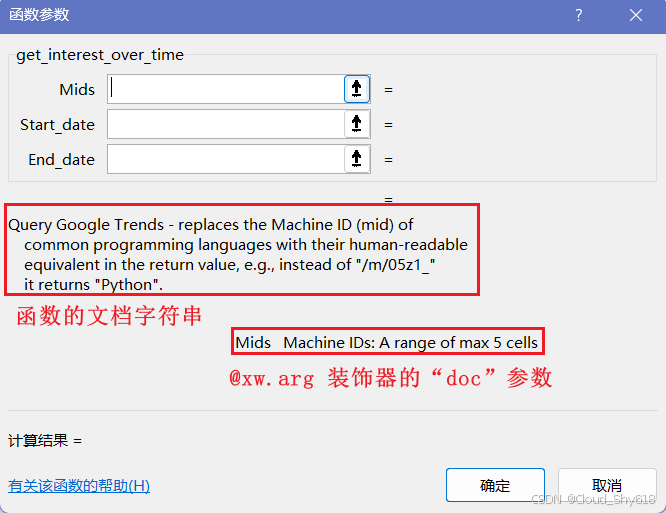
图 12-8:函数向导
另外,你也可以在 A4 单元格中输入 =get_interest_over_ time((这个左括号也要输进去),然后再按下插入函数按钮,这样就可以直接进入图 12-8 所示的界面。注意,UDF 返回的日期是没有格式化的。要修复这个问题,在包含日期的列上右键单击,选择格式化单元格,然后在日期分类下选择想要的日期格式。
如果仔细观察图 12-7,看到结果数组的蓝色边框 你就会明白我再次用到了动态数组。如果你的 Excel 不支持动态数组,则可以通过为 get_interest_over_time 函数添加下面的返回装饰器(加在其他装饰器下面)来凑合一下:
@xw.ret(expand="table")现在你已经知道如何处理更为复杂的 UDF,接下来看看如何通过 UDF 绘制图表。
12.2.4 使用 UDF 绘制图表
回顾第 5 章中,调用 DataFrame 的 plot 方法会默认返回一张 Matplotlib 的图像。在第 9 章和第 11 章中,我们已经见到了如何将这样的图像以图片形式插入 Excel 中。 在使用 UDF 时,有一种更简单的方法可以生成图表。来看一下例 12-4 中的 google_trends.py 的第二部分。
例 12-4 google_trends.py 中的 plot 函数(仅节选了相关的 import 语句)
import xlwings as xw
import pandas as pd
import matplotlib.pyplot as plt
@xw.func
@xw.arg("df", pd.DataFrame)
def plot(df, name, caller): ➊
plt.style.use("seaborn-v0_8") ➋
if not df.empty: ➌
caller.sheet.pictures.add(df.plot().get_figure(), ➍
top=caller.offset(row_offset=1).top, ➎
left=caller.left,
name=name, update=True) ➏
return f"<Plot: {name}>" ➐➊ caller 参数是 xlwings 保留的一个特殊参数:当你从 Excel 单元格调用这个函数时,它并不会被暴露给用户。caller 参数在幕后由 xlwings 给出,它代表着调用该函数的单元格(以 xlwings range 对象的形式)。有了以 range 对象表示的调用方单元格,我们就可以更方便地利用 pictures.add 的 top 参数和 left 参数来放置图表。name 参数定义了放置在 Excel 中的图片名称。
➋ 使用 seaborn 样式可以让图表在视觉上更具吸引力。 博主这里修改为 seaborn-v0_8,才能执行成功。
➌ 只有在 DataFrame 非空时才调用 plot方法。在空 DataFrame 上调用 plot 方法会引发错误。
➍ get_figure() 从 DataFrame 图像中返回了一个 Matplotlib 的图表对象,这正是 pictures. add 所需要的参数类型。
➎ 只有在你第一次插入图片时才需要 top 参数和 left 参数。这些参数会把图表放在一个方便的地方------就在调用该函数的单元格下方的一个单元格。
➏ update=True 参数能够确保重复的函数调用会更新具有指定名称的既存图片,且不会修改其位置或大小。如果不设置这个参数,则 xlwings 会指出已经在 Excel 中存在同名图片。
➐ 虽然并不是一定要返回点儿什么,但是返回一个字符串会很方便:你可以从返回的字符串中识别出你的绘图函数在工作表中的位置。
如果你的 Excel 版本支持动态数组,则用 A4# 代替 A4:F263 使数据源动态化,如图 12-9 所示。
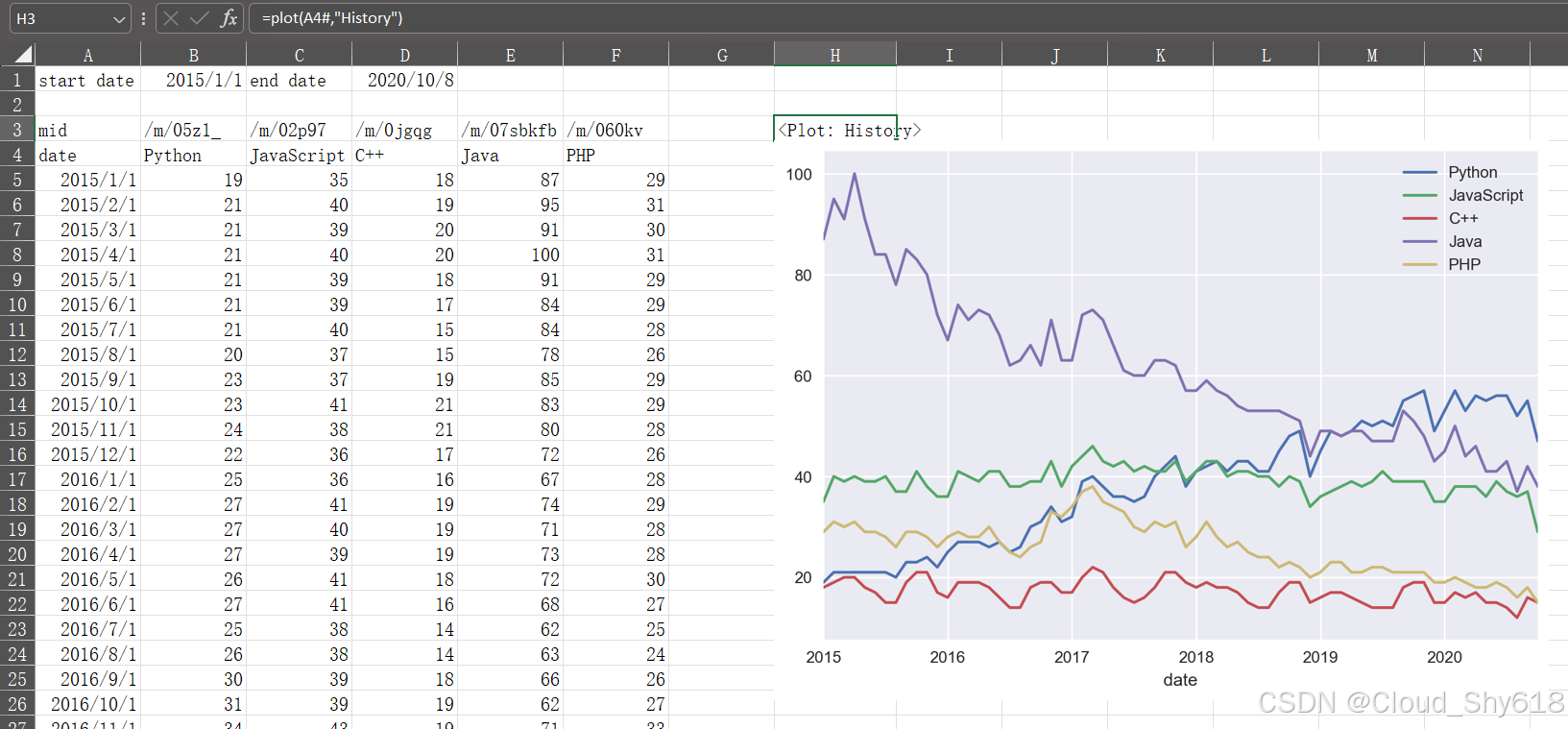
图 12-9:工作中的 plot 函数
你可能对 get_interest_over_time 函数的工作方式感觉有点儿迷惑。要想更好地理解其中的奥妙,调试代码是一种选择。下一节会向你展示如何调试 UDF 代码。
12.2.5 调试 UDF
调试 UDF 的一种简单方法是使用 print 函数。如果在 xlwings 插件中启用了 Show Console 选项,你就可以在调用 UDF 时将变量的值打印到命令提示符中。另一种更舒服的方法是使用 VS Code 的调试器,这样你既可以在断点处暂停代码,也可以一行一行地执行代码。 要使用 VS Code 调试器(或者其他 IDE 的调试器),你需要做以下两件事。
-
在 Excel 插件中,勾选 Debug UDFs(调试 UDF)多选框。这样 Excel 就不会自动启动 Python,也就是说,就像下一点中解释的那样,你需要手动启动。
-
手动启动 Python UDF 服务器的最简单方法是在要调试的文件底部加上下面这两行代码。 已经在配套代码库的 google_trends.py 文件中加上了它们。
if name == "main":
xw.serve()
还记得第 11 章中讲过,这里的 if 语句可以确保仅在以脚本形式运行该文件时才执行这段代码。也就是说,如果将其作为一个模块导入,则这段代码不会运行。添加了 serve 命令之后,在 VS Code 中按下 F5 键使其在调试模式下运行,选择 "Python文件"。 一定不要点击运行文件按钮来运行这个文件,因为这样做会无视断点。
点击第 29 行左侧来设置一个断点。如果不熟悉如何使用 VS Code 的调试器,请参考附录 B 中对此所做的更详细的介绍。现在重新计算 A4 单元格,你的函数调用会在断点处暂停,进而可以检查变量的情况。在调试过程中可以多加利用 df.info()。激活调试控制台标签页,在底部的命令提示符中输入 df.info(),再按下回车键确认,如下图所示。

如果程序在断点处暂停了 90 秒以上,则 Excel 会弹出窗口表示 "Microsoft Excel 正在等待另一个应用程序完成 OLE 操作"。这个提示应该不会对你的调试体验造成问题,只不过你需要在完成调试之后进行确认以让它消失。要结束调试会话,点击 VS Code 的停止按钮,并且一定要取消勾选 xlwings 功能区插件中的 Debug UDFs 选项。如果你忘记了取消勾选,那么在下一次重新计算时,这些函数会发生错误。