【大模型LLM学习】Agentic RL---基于Qwen3-4b训练Travel Planning Agent
- [0 前言](#0 前言)
- [1 开放生成任务现有RL使用LLM-as-judge的问题](#1 开放生成任务现有RL使用LLM-as-judge的问题)
- [2 ArenaRL](#2 ArenaRL)
- [3 本地实现旅行规划助手](#3 本地实现旅行规划助手)
-
- [3.1 工具接入](#3.1 工具接入)
- [3.2 本地模型训练](#3.2 本地模型训练)
-
- [A - 轨迹数据收集和SFT](#A - 轨迹数据收集和SFT)
- [B - 在线RL](#B - 在线RL)
- [4 demo](#4 demo)
-
- [4.1 执行过程](#4.1 执行过程)
- [4.2 输出结果](#4.2 输出结果)
- [5 效果和开销](#5 效果和开销)
0 前言
通义千问的deepresearch系列最新的一篇,高德公开了旅行规划助手的训练方法,论文为《ArenaRL: Scaling RL for Open-Ended Agents via Tournament based Relative Ranking》,并且这种方法不只是可以用于旅行规划助手,还可以扩展到其他Open-ended生成任务,解决开放生成任务里面llm-as-judge打分太随机把奖励信号淹没的问题。
在这篇中记录尝试训练本地的旅行规划助手,需要使用到高德的地理API接口,阿里百炼的Qwen-Max以及websearch接口,以及4张A100-40GB以上的显卡。
1 开放生成任务现有RL使用LLM-as-judge的问题
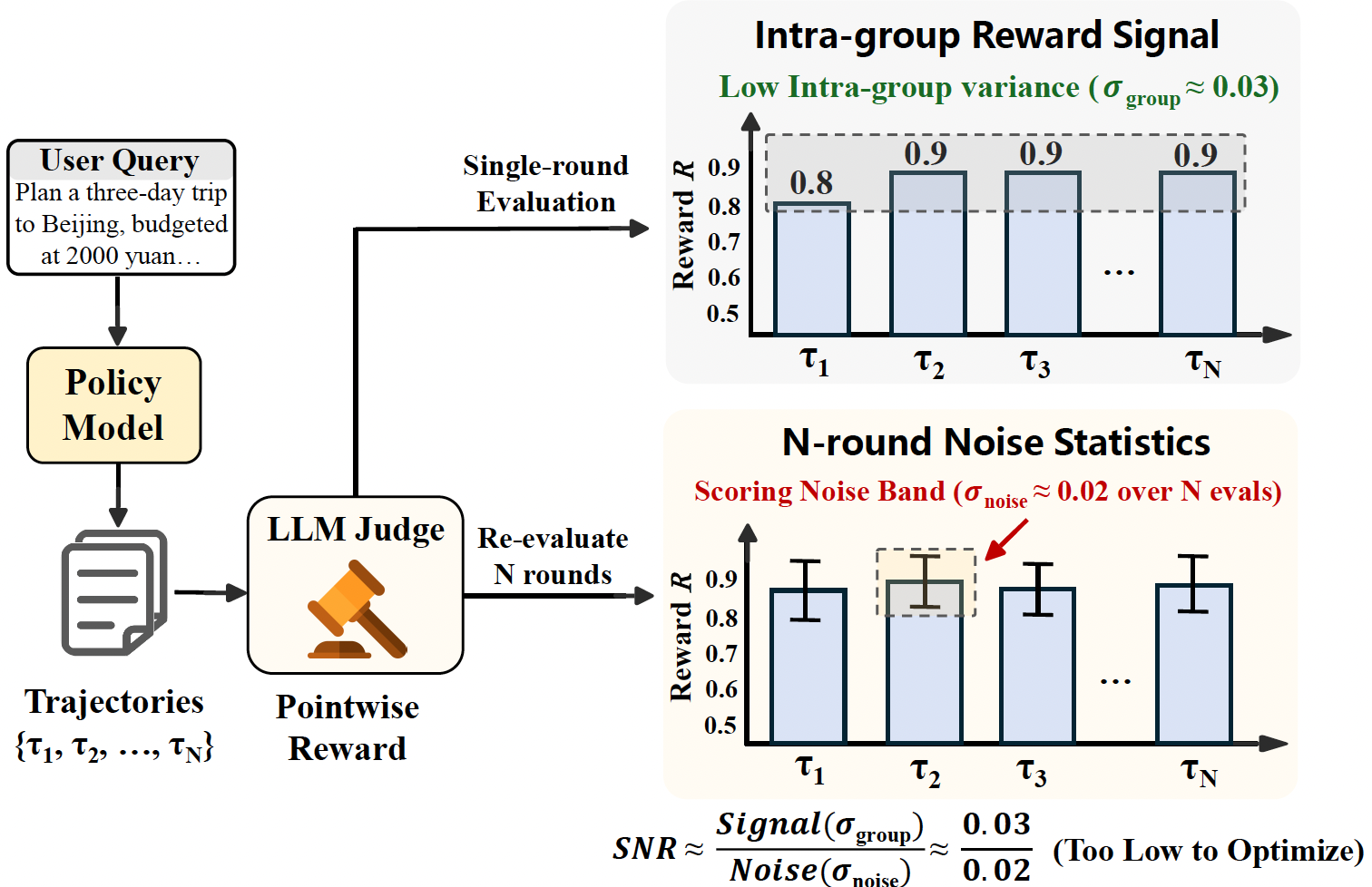
在《ArenaRL: Scaling RL for Open-Ended Agents via Tournament based Relative Ranking》这篇论文中,指出了一个很有意思的现象------歧视性崩溃。
对于开放生成任务,在做强化学习时,rollout生成一批样本(比如num_generation=8),然后用LLM-as-judge的方式从各个维度打质量分,然后相加,或许许多已有流程都是这么做的,但是这篇论文中发现,这样的打分存在较大的方差,方差把奖励信号淹没了。GRPO里面,组内的方差,和多跑几次的这个方差一样大,仿佛是随机的score。
"随着策略不断优化,生成的轨迹在分布上变得越来越相似。因此,同一组内轨迹的奖励被点式打分方案压缩到一个狭窄范围 (例如,在 0-1 分制上集中在 0.8-0.9),导致奖励无法区分。此外,由于 LLM 裁判固有的噪声 (如解码随机性和长度偏好),奖励结果表现出一定程度的不可靠性,奖励信号与干扰噪声之间的信噪比 (SNR) 极低。"
2 ArenaRL
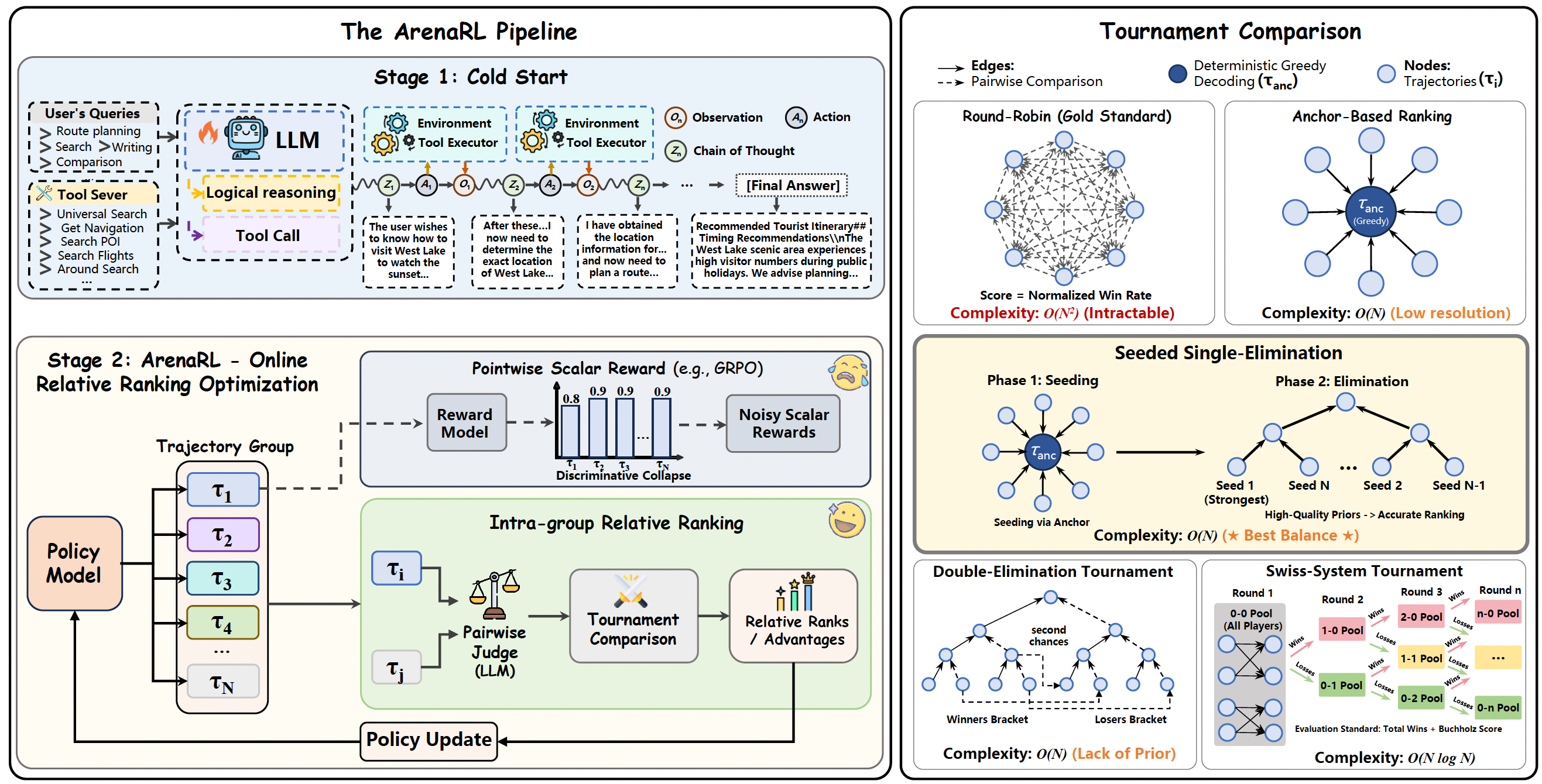
为此,ArenaRL提出,开放生成任务里面,没有标准答案,也很难有金标准和SOP明确什么样的分数对应的答案应该长什么样,所以直接打分很难打准。但是,如果给定2个答案,区分那个答案好,哪个答案坏是容易的,这种相对好坏可以作为奖励信号。
此外,对于 τ 1 \tau_{1} τ1和 τ 2 \tau_{2} τ2这2个答案在prompt里面顺序不一样,一个在前面是A,一个在后面是B,让模型选哪个好,有可能存在顺序上的歧视与偏见。所以ArenaRL提出,打分时把 τ 1 \tau_{1} τ1和 τ 2 \tau_{2} τ2输入两次给LLM打分,两次顺序反过来,取均值作为分数。
具体地,对于rollout里面N=8时,如何给这N个rollout打分呢?让它们两两PK,取赢的次数作为reward,赢的次数越高,reward越高。
s c o r e ( τ i ) = 1 N − 1 ∑ i ≠ j 1 ( s i > s j ) score(\tau_{i})=\frac{1}{N-1}\sum_{i \neq j}\mathcal {1}({s_i>s_j}) score(τi)=N−11i=j∑1(si>sj)
特别地,两两PK是round-robin的方式,比较次数是O(N*N),文中还提出了其他的一些低复杂度的方法,Seeded Single-Elimination可以实现更好的开销和效果的trade-off。
3 本地实现旅行规划助手
3.1 工具接入
包括6个工具:
- web_search:网页内容搜索
- search_flights:航班搜索
- search_train_tickets:火车票搜索
- search_weather:天气查询
- search_navigation:路径导航规划
- search_poi:搜索keyword地点信息
- search_around:搜索目标经纬度附近地点信息
Agent使用通义千问的deepresearch里面resum的框架,加入工具即可,支持上下文超长时进行动态压缩。
3.2 本地模型训练
A - 轨迹数据收集和SFT
从ArenaRL提供的训练集中,抽取与旅行规划相关的数据,去掉海外相关数据,剩下551条。使用其中的400条交给Qwen-max来跑出teacher轨迹,过滤掉格式不对的部分(例如tool、answer的tag缺失,网络错误导致多个assistant连着出现等),得到的部分进行DFT的lora训练提升Qwen3-4b的指令遵循能力。这里使用ms-swift框架进行训练,5个epoch收敛:
bash
nproc_per_node=4
CUDA_VISIBLE_DEVICES=0,1,2,3 \
NPROC_PER_NODE=$nproc_per_node \
swift sft \
--model /data/coding/Qwen3-4B-Instruct-2507 \
--dataset /data/coding/teacher_traj_top400_legal.jsonl \
--tuner_type lora \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--output_dir /data/coding/travel_finetune/dft_0517/ \
--enable_dft_loss true \
--num_train_epochs 5 \
--lorap_lr_ratio 10 \
--freeze_vit false \
--freeze_aligner false \
--freeze_llm false \
--save_steps 20 \
--eval_steps 20 \
--save_total_limit 2 \
--logging_steps 10 \
--seed 42 \
--max_length 28672 \
--learning_rate 1e-4 \
--init_weights true \
--lora_rank 8 \
--lora_alpha 32 \
--adam_beta1 0.9 \
--adam_beta2 0.95 \
--adam_epsilon 1e-08 \
--weight_decay 0.1 \
--gradient_accumulation_steps 4 \
--max_grad_norm 1 \
--lr_scheduler_type cosine \
--warmup_ratio 0.05 \
--warmup_steps 0 \
--gradient_checkpointing true \
--deepspeed zero3B - 在线RL
首先需要配置上工具,主要需要修改好orm.py和multi_turn.py,在multi_turn.py中处理rollout,用orm.py进行打分。multi_turn.py部分,相比前面deep search agent,只需要修改工具部分,以及建议把轨迹记录下来,记录到'rollout_infos'键中便于在ORM中读取。
python
def check_finished(self, infer_request: 'RolloutInferRequest', response_choice: 'ChatCompletionResponseChoice',
current_turn: int) -> bool:
completion = response_choice.message.content
tool_calls = self._extract_tool_calls(completion)
tokenizer = self.tokenizer
# 统计token总数
total_tokens = sum(len(tokenizer.encode(msg['content'], add_special_tokens=False)) for msg in infer_request.messages)
if total_tokens>28*1024: # 超长了
return True
elif (tool_calls is None and '<response>' not in completion) or ('<answer>' in completion and '</answer>' in completion):
# 关键:添加 encoding='utf-8' 强制UTF-8编码
with open('/data/coding/travel_finetune/grpo_final/end_reason.jsonl', 'a', encoding='utf-8') as f:
# 1. 写入请求信息:ensure_ascii=False 保证中文正常
f.write(json.dumps({'infer_request': infer_request.messages, 'turn': current_turn}, ensure_ascii=False) + '\n')
# 2. 写入结果:删除手动转义,json自动处理双引号
f.write(json.dumps({'completion': completion, 'turn': current_turn}, ensure_ascii=False) + '\n')
if tool_calls is None and '<response>' not in completion:
f.write(json.dumps({'reason': 'no_tool_calls', 'turn': current_turn}, ensure_ascii=False) + '\n')
else:
f.write(json.dumps({'reason': 'has_answer_tags', 'turn': current_turn}, ensure_ascii=False) + '\n')
return True
return super().check_finished(infer_request, response_choice, current_turn)
def step(self, infer_request: 'RolloutInferRequest', response_choice: 'ChatCompletionResponseChoice',
current_turn: int) -> Dict:
completion = response_choice.message.content
token_ids = response_choice.token_ids
loss_mask = [1] * len(token_ids)
tool_calls = self._extract_tool_calls(completion)
# assert len(tool_calls) == 1, 'this scheduler is designed for one tool call per turn'
tool_results = self._execute_tools(tool_calls)
# append tool result to the completion
infer_request.messages.append({'role': 'user', 'content': "<response>"+(tool_results[0])+"\n</response>"})
return {
'infer_request': infer_request,
'rollout_infos': {
'num_turns': current_turn,
'infer_request_all': infer_request
}
} 重点是orm.py,prompt可以直接参考ArenaRL的judge prompt,因为本次试验num_generation本来就不大,所以下面实现了round-robin的方式。特别的,ms-swift中steps_per_generation=num_generations时,ORM里面可以拿到一批次完整的生成结果:
python
class OpenTravalOriginalReward(ORM):
"""
调试专用:并发 LLM judge + 工具调用格式校验 reward
新增规则1:每步仅1个<reason>,如果后面不是<answer>,必须是一个<tool>,然后后面必须紧跟着<response>;连续<tool>越多惩罚越重
新增规则2:<response>为工具调用次数,调用次数少于2次,奖励打折
"""
def tournament_two_completion(self, comp1, comp2, user_input, traj1, traj2):
infer_traj_1 = messages_to_text(traj1[2:]) # 跳过system和第一个user
infer_traj_2 = messages_to_text(traj2[2:]) # 跳过system和第一个user
content_match = re.search(r'<answer>(.*?)</answer>', comp1, re.DOTALL)
answer1 = content_match.group(1).strip() if content_match else comp1
content_match = re.search(r'<answer>(.*?)</answer>', comp2, re.DOTALL)
answer2 = content_match.group(1).strip() if content_match else comp2
# 任务1:comp1 vs comp2
def task1():
time.sleep(random.uniform(0.5, 8))
judge_prompt = open_traval_llm_judge_system_prompt_ori.replace('[用户原始提问]', user_input).replace('[LLM Agent A 的完整回答]', answer1).replace('[LLM Agent B 的完整回答]', answer2).replace('[LLM Agent A 的完整推理路径]', infer_traj_1).replace('[LLM Agent B 的完整推理路径]', infer_traj_2)
with open('/data/coding/travel_finetune/grpo_final/judge_debug_log.jsonl', 'a', encoding='utf-8') as f:
f.write(json.dumps({"prompt": judge_prompt}, ensure_ascii=False) + '\n')
try:
resp = call_openai(judge_prompt, used_model="qwen-plus-2025-09-11")
with open('/data/coding/travel_finetune/grpo_final/judge_debug_log.jsonl', 'a', encoding='utf-8') as f:
f.write(json.dumps({"response": resp}, ensure_ascii=False) + '\n')
parsed_scores = extract_travel_judge_full_scores_ori(resp)
return parsed_scores['Agent_A_combined'], parsed_scores['Agent_B_combined']
except:
return 0.0, 0.0
# 任务2:comp2 vs comp1
def task2():
time.sleep(random.uniform(0.5, 8))
judge_prompt = open_traval_llm_judge_system_prompt_ori.replace('[用户原始提问]', user_input).replace('[LLM Agent A 的完整回答]', answer2).replace('[LLM Agent B 的完整回答]', answer1).replace('[LLM Agent A 的完整推理路径]', infer_traj_2).replace('[LLM Agent B 的完整推理路径]', infer_traj_1)
with open('/data/coding/travel_finetune/grpo_final/judge_debug_log.jsonl', 'a', encoding='utf-8') as f:
f.write(json.dumps({"prompt": judge_prompt}, ensure_ascii=False) + '\n')
try:
resp = call_openai(judge_prompt, used_model="qwen-plus-2025-09-11")
with open('/data/coding/travel_finetune/grpo_final/judge_debug_log.jsonl', 'a', encoding='utf-8') as f:
f.write(json.dumps({"response": resp}, ensure_ascii=False) + '\n')
parsed_scores = extract_travel_judge_full_scores_ori(resp)
return parsed_scores['Agent_A_combined'], parsed_scores['Agent_B_combined']
except:
return 0.0, 0.0
# 并发执行两个LLM调用
with ThreadPoolExecutor(max_workers=2) as executor:
f1 = executor.submit(task1)
f2 = executor.submit(task2)
overall_a1, overall_b1 = f1.result()
overall_b2, overall_a2 = f2.result()
return overall_a1 + overall_a2, overall_b1 + overall_b2
def __call__(self, completions: List[str], user_inputs: List[str], **kwargs) -> List[float]:
group_size = len(completions)
rollout_infos = kwargs.get('rollout_infos', {})
# 从dict list里面获取dict的value
num_turns = [rollout_info.get('num_turns', 1) for rollout_info in rollout_infos]
infer_requests = [rollout_info.get('infer_request_all', {}) for rollout_info in rollout_infos]
infer_request_list = [infer_requests[i].get('messages', []) for i in range(len(infer_requests))]
print('num_turns:', num_turns)
print('len(completions):', len(completions))
wins = [0.0] * group_size
for i in range(group_size):
for j in range(i+1, group_size):
score_i, score_j = self.tournament_two_completion(completions[i], completions[j],user_inputs[0],infer_request_list[i],infer_request_list[j])
if score_i > score_j:
wins[i] += 1
elif score_i < score_j:
wins[j] += 1
else: # ties
wins[i] += 0.5
wins[j] += 0.5
ranks = pd.Series(wins).rank(method="min", ascending=False).tolist()
max_rank = max(ranks)
if max_rank == 1:
group_rewards = [0.0] * group_size
else:
group_rewards = [(max_rank - r) / (max_rank - 1) for r in ranks]
# 记录具体的rewards和winrate,便于后续排查,记录到jsonl
with open('/data/coding/travel_finetune/grpo_final/reward_output.jsonl', 'a', encoding='utf-8') as f:
json.dump({
"wins": wins,
"group_rewards": group_rewards,
"num_turns": num_turns,
"user_inputs": user_inputs[0]
}, f, ensure_ascii=False)
f.write('\n')
# ============================================================================
print('wins = ', wins)
print('最终总奖励:', group_rewards)
return group_rewards
multi_turns = {
'math_tip_trick': MathTipsScheduler,
'gym_scheduler': GYMScheduler,
'thinking_tips_scheduler': ThinkingModelTipsScheduler,
'deep_search_scheduler': DeepSearchScheduler,
'open_traval_scheduler': OpenTravelScheduler # 记得注册
}检查无误后,开启rollout服务器负责产生rollout:
python
CUDA_VISIBLE_DEVICES=0 \
swift rollout \
--model /data/coding/travel_finetune/dft_0517/v0-20260517-202958/checkpoint-55-merged \
--vllm_use_async_engine true \
--vllm_enable_lora true \
--multi_turn_scheduler open_traval_scheduler \
--vllm_max_lora_rank 8 \
--vllm_max_model_len 32768 \
--vllm_gpu_memory_utilization 0.8 \
--max_turns 28 \
--port 9123在rollout服务器启动后,可以启动开始RL。为了便于ORM取到完整一批次结果,让steps_per_generation=num_generations。使用上面551条剩余的部分150条做RL:
python
CUDA_VISIBLE_DEVICES=1,2,3 \
NPROC_PER_NODE=3 \
swift rlhf \
--rlhf_type grpo \
--model /data/coding/travel_finetune/dft_0517/v0-20260517-202958/checkpoint-55-merged \
--output_dir /data/coding/travel_finetune/grpo_final/ \
--tuner_type lora \
--reward_funcs open_traval_ori_reward \
--multi_turn_scheduler open_traval_scheduler \
--max_turns 28 \
--use_vllm true \
--vllm_mode server \
--vllm_server_host 127.0.0.1 \
--vllm_server_port 9124 \
--vllm_server_pass_dataset true \
--torch_dtype bfloat16 \
--dataset /data/coding/trip_plan_rl_dataset.jsonl \
--overlong_filter true \
--loss_scale default \
--split_dataset_ratio 0 \
--epsilon_high 0.28 \
--max_completion_length 8192 \
--max_length 28672 \
--completion_length_limit_scope total \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 1 \
--steps_per_generation 4 \
--gradient_checkpointing true \
--save_steps 5 \
--overlong_filter true \
--logging_steps 1 \
--lora_rank 8 \
--lora_alpha 32 \
--warmup_ratio 0.05 \
--num_generations 4 \
--temperature 0.8 \
--deepspeed zero3_offload \
--log_completions true \
--log_entropy true \
--num_iterations 1 \
--rollout_importance_sampling_mode token_mask4 demo
4.1 执行过程

4.2 输出结果
以下是为您精心规划的宁波一日游行程,兼顾天一阁博物院、南塘老街和月湖公园的打卡顺序,避开天一阁闭馆时间,并确保充足时间体验小吃和公园环境:
行程概览
- 日期:2026年5月23日(周六)
- 天气:小雨,24-32℃,东南风1-3级
- 主题:文化深度+美食体验+自然休闲
详细行程安排
上午:天一阁博物院(8:30-11:30)
- 开放时间:8:30-17:30(17:00停止入园),每周一闭馆(今日为周六,正常开放)
- 推荐入园时间:8:30-9:30(避开人流高峰,享受宁静的园林环境)
- 游玩时长:约2.5小时
- 特色体验 :
- 参观藏书楼、明州碑林、范式故居等核心展区
- 游览东园和南园的江南园林景观
- 在游客中心领取手绘地图,按路线高效游览
- 交通:地铁1号线至西门口站,步行约10分钟;或乘坐公交9路、26路、371路、512路至"天一阁月湖景区"站
中午:南塘老街(11:30-14:30)
- 开放时间:9:00-22:00(全天开放,无需门票)
- 推荐游览时间:11:30-14:30(避开上午人流高峰,享受美食盛宴)
- 游玩时长:约3小时
- 特色体验 :
- 品尝宁波特色小吃:油赞子、宁波汤圆、十六格蟹黄汤包、潮牛小馄饨等
- 漫步1.2公里的江南长廊,欣赏青苔斑驳的石板路和雕花老宅
- 参观余氏宗祠、袁牧之故居等历史文化景点
- 交通:从天一阁步行约37分钟(2.8公里)至南塘老街;或乘坐地铁2号线至"客运中心站",步行约12分钟
下午:月湖公园(14:30-16:30)
- 开放时间:8:00-17:30(4月21日-10月21日),全天开放
- 推荐游览时间:14:30-16:30(避开中午烈日,享受凉爽的公园环境)
- 游玩时长:约2小时
- 特色体验 :
- 漫步月湖畔,欣赏湖光山色和古建筑群(高丽使馆遗址、银台第、贺秘监祠等)
- 在柳汀街或九曲桥旁拍照打卡
- 如果时间充裕,可租脚踩小黄鸭游船游湖
- 交通:从南塘老街步行约30分钟(2.3公里)至月湖公园;或乘坐地铁2号线至"城隍庙站",步行约7分钟
关键提示
- 天一阁闭馆提醒:务必在17:00前完成参观,避免错过闭馆时间。
- 天气应对:当天有小雨,建议携带雨具和防滑鞋,但雨天反而适合漫步公园,感受湿润的园林氛围。
- 时间管理:各景点之间步行距离较近,但需预留充足时间体验美食和公园环境。
- 交通建议:优先选择地铁出行,避免堵车;自驾可停月湖公园地下停车场(首小时免费)。
此行程兼顾文化、美食和自然,让您在一天内深度体验宁波的千年文脉与现代活力!
5 效果和开销
- 比对Qwen3-4b、Qwen3-4b-DFT和Qwen3-4b-Arena的效果
- 用Qwen3-4b-DFT、Qwen3-4b-Arena的生成文本分别与Qwen3-4b的生成文本两两比较,LLM-as-judge的方式,统计测试集上这几个Agent哪一个胜率高
- 测试集包含ArenaRL里面单日旅游规划和多日旅游规划的测试集,每个部分各自抽了20条
| 模型 | 胜率 |
|---|---|
| Qwen3-4b-DFT vs Qwen3-4b | 50% |
| Qwen3-4b-Arena vs Qwen3-4b | 57.5% |
- 看上去Qwen3-4b-DFT只是提升了指令遵循能力,RL才提升了生成质量
- 由于成本原因RL只跑了少量步数
成本统计:Qwen-Max/Qwen-Plus和阿里的IQS的searchAPI大约100元,GPU费用大约100元,高德的API官方成本非常非常贵。。。开发者的LBS搜索额度又很低,仅能支持少量训练,瓶颈在高德开放平台。。。