PyTorch 的 torch.nn 模块,是构建神经网络最核心的模块。它提供了模型基类、常用网络层、激活函数、损失函数、容器结构、参数管理和训练状态控制等能力。
简单地说,torch.nn 模块回答的是:神经网络在 PyTorch 中如何表示、如何组织、如何完成前向计算,以及模型参数如何被自动管理。
如果说 torch 模块负责张量与基础计算,那么 torch.nn 模块就负责把这些张量计算组织成"模型"。在实际深度学习项目中,我们很少只写零散的矩阵乘法,而是会把线性层、卷积层、激活函数、归一化层、Dropout 层和损失函数组合成一个完整的神经网络。
一、认识 torch.nn 模块
torch.nn 是 PyTorch 中专门用于神经网络建模的模块。它并不是只提供几个网络层,而是围绕模型构建提供了一套完整机制。
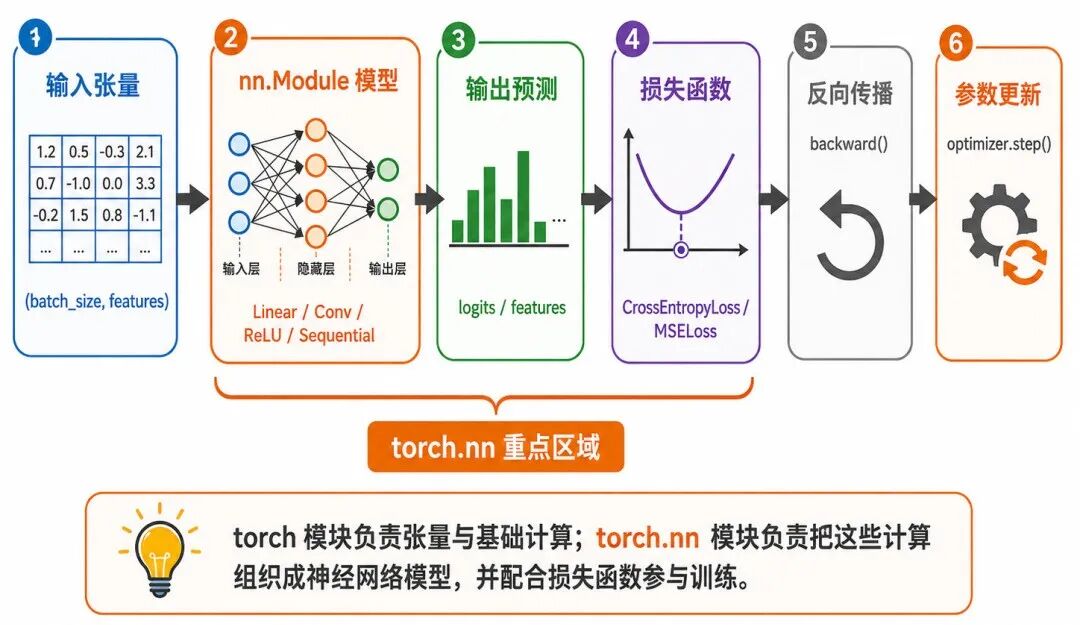
图 1:torch.nn 模块在 PyTorch 训练流程中的位置
在 PyTorch 中,一个神经网络通常由以下部分组成:
• 模型基类:nn.Module
• 网络层:如 nn.Linear、nn.Conv2d、nn.Embedding
• 激活函数:如 nn.ReLU、nn.Sigmoid、nn.GELU
• 损失函数:如 nn.CrossEntropyLoss、nn.MSELoss
• 容器结构:如 nn.Sequential、nn.ModuleList
• 参数管理:如 parameters()、state_dict()
• 训练与推理状态:如 train()、eval()
一个最简单的使用方式如下:
apache
import torchimport torch.nn as nn
# 定义一个线性层:输入特征数为 4,输出特征数为 3layer = nn.Linear(4, 3)
# 构造 2 个样本,每个样本有 4 个特征x = torch.randn(2, 4)
# 前向计算,得到 2 个样本在 3 个输出维度上的结果y = layer(x)
print(y.shape)输出形状为:
apache
torch.Size([2, 3])这里可以看出,nn.Linear 不只是一个普通函数,而是一个带有可学习参数的模块。它内部保存了权重和偏置,并会在训练过程中被更新。
二、nn.Module:所有神经网络模块的基础
在 PyTorch 中,大多数神经网络模型都会继承 nn.Module。它是模型组织的基础。
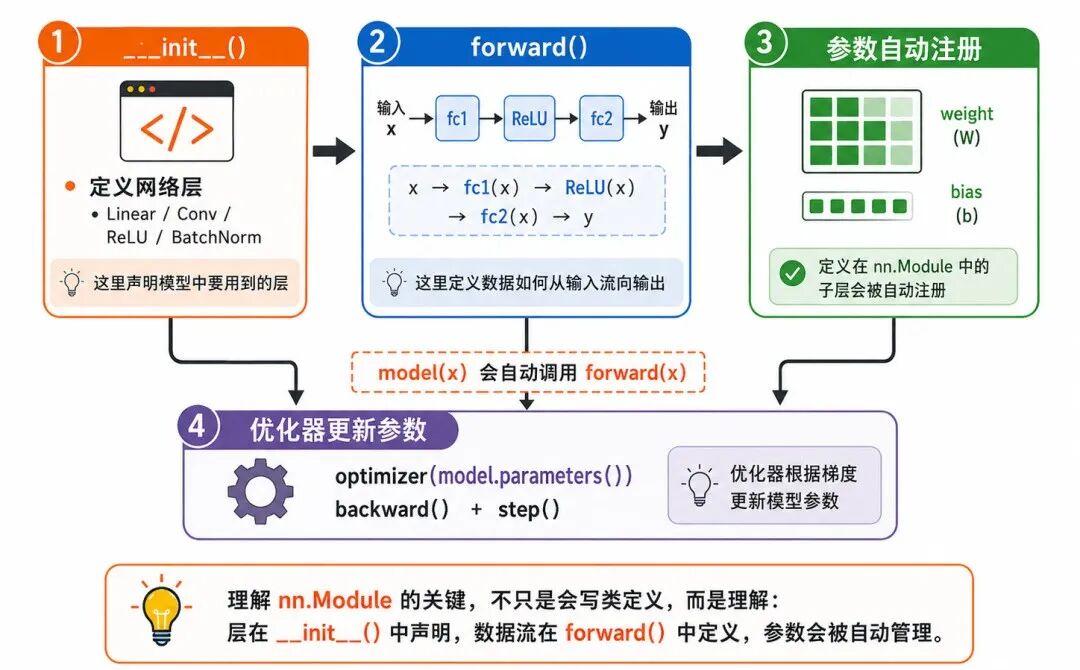
图 2:nn.Module 的基本结构
一个典型模型通常包含两个部分:
• init():定义模型中需要用到的层
• forward():定义数据如何从输入流向输出
例如:
python
import torchimport torch.nn as nn
class SimpleNet(nn.Module): def __init__(self): super().__init__()
# 定义第一层:4 个输入特征映射到 16 个隐藏特征 self.fc1 = nn.Linear(4, 16)
# 定义激活函数 self.relu = nn.ReLU()
# 定义第二层:16 个隐藏特征映射到 3 个输出类别 self.fc2 = nn.Linear(16, 3)
def forward(self, x): # 输入先经过第一层 x = self.fc1(x)
# 再经过非线性激活 x = self.relu(x)
# 最后得到输出结果 x = self.fc2(x)
return x
model = SimpleNet()
x = torch.randn(8, 4)y = model(x)
print(y.shape) # torch.Size([8, 3])这里最重要的不是代码长度,而是理解模型的组织方式:
• init() 负责"有哪些层"
• forward() 负责"数据怎么流动"
• model(x) 会自动调用 forward(x)
• 模型中的层会被自动注册,参数也会被自动管理
这就是 PyTorch 模型定义的基本范式。
三、forward():定义前向传播逻辑
forward() 方法决定输入张量如何一步步变成输出张量。它体现的是模型的计算路径。
例如,一个两层神经网络可以理解为:
css
输入 x→ 线性层 fc1→ 激活函数 ReLU→ 线性层 fc2→ 输出 logits对应代码是:
ruby
def forward(self, x): x = self.fc1(x) x = self.relu(x) x = self.fc2(x) return x在分类任务中,模型最后输出的通常不是直接类别,而是一组分数,常称为 logits。
例如:
bash
logits = model(x)print(logits.shape)如果 logits.shape 是 (8, 3),可以理解为:
• 有 8 个样本
• 每个样本对应 3 个类别分数
• 分数越大,模型越倾向于该类别
需要注意的是,很多分类模型的最后一层不需要手动加 Softmax。如果后面使用 nn.CrossEntropyLoss(),它会在内部处理与分类概率相关的计算。因此,模型通常直接输出原始分数即可。
四、nn.Linear:全连接层
nn.Linear 是最基础、最常用的神经网络层之一。它常用于多层感知机、分类头、回归头和 Transformer 中的前馈网络部分。
全连接层(也称为"线性层")的核心计算可以理解为:
其中:
• X 表示输入张量
• W 表示权重矩阵
• b 表示偏置
• Y 表示输出张量
代码示例:
python
import torchimport torch.nn as nn
# 输入特征数为 4,输出特征数为 2linear = nn.Linear(4, 2)
# 5 个样本,每个样本 4 个特征x = torch.randn(5, 4)
# 输出形状为 (5, 2)y = linear(x)
print(y.shape)print(linear.weight.shape)print(linear.bias.shape)需要注意的是,nn.Linear(4, 2) 中的 4 和 2 分别表示:
• in_features=4:每个样本输入特征数
• out_features=2:每个样本输出特征数
它并不表示有 4 个样本或 2 个样本。样本数量通常由输入张量的第 0 维决定。
五、激活函数:引入非线性能力
如果神经网络只有线性层,那么多层线性变换叠加后,本质上仍然可以合并成一个线性变换。为了让模型表达更复杂的非线性关系,需要引入激活函数。
常见激活函数包括:
• nn.ReLU
• nn.Sigmoid
• nn.Tanh
• nn.LeakyReLU
• nn.GELU
• nn.Softmax
示例:
apache
import torchimport torch.nn as nn
x = torch.tensor([-2.0, -1.0, 0.0, 1.0, 2.0])
# ReLU 会把负数变为 0,正数保持不变relu = nn.ReLU()
# Sigmoid 会把数值压缩到 0 到 1 之间sigmoid = nn.Sigmoid()
# Tanh 会把数值压缩到 -1 到 1 之间tanh = nn.Tanh()
print(relu(x))print(sigmoid(x))print(tanh(x))在现代深度学习中,ReLU 和它的变体非常常见;在 Transformer、BERT、GPT 等模型中,GELU 也经常出现。
需要注意的是,激活函数并不是随便添加的。它通常位于线性层或卷积层之后,用于增加模型的非线性表达能力。
六、nn.Sequential:按顺序组织模型
如果模型结构是简单的"从前到后依次执行",可以使用 nn.Sequential 简化代码。
例如,下面这个模型与前面手写 forward() 的两层网络等价:
python
import torchimport torch.nn as nn
model = nn.Sequential( nn.Linear(4, 16), # 输入层到隐藏层 nn.ReLU(), # 非线性激活 nn.Linear(16, 3) # 隐藏层到输出层)
x = torch.randn(8, 4)y = model(x)
print(y.shape)nn.Sequential 的优点是简洁,适合线性堆叠结构。例如:
• 多层感知机
• 简单卷积网络
• 分类头
• 回归头
• 特征映射模块
但如果模型中包含复杂分支、跳跃连接、多输入多输出或条件逻辑,nn.Sequential 就不够灵活。这时更适合继承 nn.Module 并手写 forward()。
七、ModuleList 与 ModuleDict:保存多个子模块
有些模型中,层的数量可能比较多,或者需要在循环中组织多个子模块。这时可以使用 nn.ModuleList 或 nn.ModuleDict。
1、ModuleList:列表形式保存子模块
python
import torchimport torch.nn as nn
class DeepMLP(nn.Module): def __init__(self): super().__init__()
# 用 ModuleList 保存多个线性层 self.layers = nn.ModuleList([ nn.Linear(4, 16), nn.Linear(16, 16), nn.Linear(16, 3) ])
self.relu = nn.ReLU()
def forward(self, x): # 前两层后接 ReLU,最后一层直接输出 for layer in self.layers[:-1]: x = self.relu(layer(x))
x = self.layers[-1](x) return x
model = DeepMLP()
x = torch.randn(8, 4)y = model(x)
print(y.shape) # torch.Size([8, 3])ModuleList 的关键作用是:让 PyTorch 能够正确识别并管理其中的子模块参数。
不要简单地用普通 Python 列表保存网络层。普通列表中的层可能不会被模型正确注册,从而导致参数无法被优化器更新。
2、ModuleDict:字典形式保存子模块
python
import torchimport torch.nn as nn
class MultiHeadModel(nn.Module): def __init__(self): super().__init__()
self.shared = nn.Linear(4, 16)
# 用 ModuleDict 保存多个任务头 self.heads = nn.ModuleDict({ "classification": nn.Linear(16, 3), "regression": nn.Linear(16, 1) })
self.relu = nn.ReLU()
def forward(self, x, task): x = self.relu(self.shared(x)) x = self.heads[task](x) return x
model = MultiHeadModel()
x = torch.randn(8, 4)
y_cls = model(x, task="classification")y_reg = model(x, task="regression")
print(y_cls.shape) # torch.Size([8, 3])print(y_reg.shape) # torch.Size([8, 1])ModuleDict 适合需要按名称选择不同子模块的场景,例如多任务学习、多个输出头、多种特征处理分支等。
八、损失函数:衡量预测与目标的差异
神经网络训练不仅需要模型输出,还需要损失函数。损失函数用于衡量模型预测结果与真实目标之间的差异。
常见损失函数包括:
• nn.CrossEntropyLoss:多分类任务常用
• nn.BCELoss:二分类概率输出场景
• nn.BCEWithLogitsLoss:二分类或多标签任务常用
• nn.MSELoss:回归任务常用
• nn.L1Loss:平均绝对误差损失
• nn.NLLLoss:负对数似然损失
1、分类任务中的 CrossEntropyLoss
python
import torchimport torch.nn as nn
class DeepMLP(nn.Module): def __init__(self): super().__init__()
# 用 ModuleList 保存多个线性层 self.layers = nn.ModuleList([ nn.Linear(4, 16), nn.Linear(16, 16), nn.Linear(16, 3) ])
self.relu = nn.ReLU()
def forward(self, x): # 前两层后接 ReLU,最后一层直接输出 for layer in self.layers[:-1]: x = self.relu(layer(x))
x = self.layers[-1](x) return x
model = DeepMLP()
x = torch.randn(8, 4)y = model(x)
print(y.shape) # torch.Size([8, 3])这里需要特别注意:
• logits 的形状通常是 (batch_size, num_classes)
• target 的形状通常是 (batch_size,)
• target 中保存的是类别编号,不是 one-hot 向量
• 使用 CrossEntropyLoss 时,模型最后通常不需要手动加 Softmax
这是初学者非常容易出错的地方。如果把标签写成 one-hot,或者提前对 logits 做了不必要的 Softmax,可能会导致训练效果异常。
2、回归任务中的 MSELoss
apache
import torchimport torch.nn as nn
# 8 个样本,每个样本预测 1 个连续数值pred = torch.randn(8, 1)
# 对应的真实连续数值target = torch.randn(8, 1)
# 均方误差损失criterion = nn.MSELoss()
loss = criterion(pred, target)
print(loss)回归任务中,预测值和真实值通常都使用浮点张量,并且形状应尽量保持一致。
例如,如果 pred 的形状是 (8, 1),而 target 的形状是 (8,),有时可能会触发广播,导致计算含义不符合预期。因此,回归任务中要特别注意预测值和目标值的形状。
九、卷积层、池化层与图像特征提取
在图像任务中,常用的神经网络层包括卷积层、归一化层、激活函数和池化层。
典型组合可以写成:
css
import torchimport torch.nn as nn
class SmallCNN(nn.Module): def __init__(self): super().__init__()
self.features = nn.Sequential( nn.Conv2d(3, 16, kernel_size=3, padding=1), # 输入 3 通道,输出 16 通道 nn.BatchNorm2d(16), # 对 16 个通道做批量归一化 nn.ReLU(), # 引入非线性 nn.MaxPool2d(kernel_size=2), # 高宽减半
nn.Conv2d(16, 32, kernel_size=3, padding=1), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(kernel_size=2) )
self.classifier = nn.Linear(32 * 8 * 8, 10)
def forward(self, x): x = self.features(x)
# 保留批次维度,把每张图像的特征展平成向量 x = torch.flatten(x, start_dim=1)
x = self.classifier(x) return x
model = SmallCNN()
# 8 张 32×32 RGB 图像x = torch.randn(8, 3, 32, 32)
y = model(x)
print(y.shape) # torch.Size([8, 10])这里的结构可以理解为:
• 卷积层负责提取局部特征
• 激活函数引入非线性
• 池化层降低空间尺寸
• 展平操作把特征图变成向量
• 全连接层输出分类结果
在卷积网络中,输入通常采用 (N, C, H, W) 格式。如果图像数据是 (N, H, W, C),需要先调整维度顺序。
十、Dropout 与归一化层
在神经网络训练中,除了线性层和卷积层,还经常使用 Dropout 与归一化层来改善训练效果。
1、Dropout:随机失活
python
import torchimport torch.nn as nn
dropout = nn.Dropout(p=0.5)
x = torch.ones(10)
# 训练模式下,部分元素会被随机置为 0dropout.train()print(dropout(x))
# 推理模式下,Dropout 不再随机丢弃元素dropout.eval()print(dropout(x))Dropout 常用于缓解过拟合。它在训练阶段随机丢弃部分神经元输出,使模型不要过度依赖某些局部特征。
需要注意的是,Dropout 在训练模式和推理模式下行为不同。因此,训练时要调用 model.train(),推理或验证时要调用 model.eval()。
2、BatchNorm 与 LayerNorm
常见归一化层包括:
• nn.BatchNorm1d
• nn.BatchNorm2d
• nn.LayerNorm
示例:
apache
import torchimport torch.nn as nn
# 常用于全连接网络或一维特征bn1d = nn.BatchNorm1d(16)
# 常用于卷积网络中的特征图bn2d = nn.BatchNorm2d(16)
# 常用于 Transformer 等结构ln = nn.LayerNorm(16)
x1 = torch.randn(8, 16)x2 = torch.randn(8, 16, 32, 32)
print(bn1d(x1).shape)print(bn2d(x2).shape)归一化层的作用不是改变任务目标,而是让中间特征的数值分布更稳定,从而帮助模型更顺利地训练。
十一、Embedding、RNN 与 Transformer 相关层
torch.nn 不只用于普通前馈网络和卷积网络,也提供了文本、序列和注意力模型相关的常用层。
1、Embedding:把离散编号映射为向量
nn.Embedding 常用于自然语言处理和推荐系统。它可以把词编号、用户编号、物品编号等离散 ID 映射为连续向量。
示例:
apache
import torchimport torch.nn as nn
# 词表大小为 1000,每个词映射为 64 维向量embedding = nn.Embedding(num_embeddings=1000, embedding_dim=64)
# 4 个样本,每个样本包含 10 个词编号token_ids = torch.randint(0, 1000, (4, 10))
# 输出形状为 (4, 10, 64)x = embedding(token_ids)
print(x.shape)这里可以理解为:
• 输入是整数编号
• 输出是连续向量
• 每个编号都有一个可学习的向量表示
2、RNN、LSTM 与 GRU:处理序列数据的循环网络结构
RNN、LSTM 与 GRU 都属于处理序列数据的循环神经网络结构,常用于文本、语音、时间序列等任务。
RNN(循环神经网络)是基础循环结构,LSTM(长短期记忆网络)和 GRU(门控循环单元)是对普通 RNN 的改进版本,目的都是让模型更好地处理序列中的上下文信息。
示例:
python
import torchimport torch.nn as nn
# 输入特征维度为 32,隐藏状态维度为 64rnn = nn.LSTM(input_size=32, hidden_size=64, batch_first=True)
# 8 个样本,每个样本长度为 10,每个时间步 32 个特征x = torch.randn(8, 10, 32)
# output 保存每个时间步的输出,h_n 和 c_n 保存最终隐藏状态与记忆状态output, (h_n, c_n) = rnn(x)
print(output.shape)print(h_n.shape)print(c_n.shape)当 batch_first=True 时,输入形状通常是:
go
(batch_size, sequence_length, input_size)序列模型中最容易混淆的是维度顺序。写代码时要特别确认:
• 哪一维是批次
• 哪一维是时间步
• 哪一维是特征
3、MultiheadAttention 与 Transformer
nn.MultiheadAttention 和 nn.Transformer 可用于构建注意力机制与 Transformer 结构。
python
import torchimport torch.nn as nn
# 嵌入维度为 64,注意力头数为 4attention = nn.MultiheadAttention(embed_dim=64, num_heads=4, batch_first=True)
# 8 个样本,序列长度为 10,每个 token 是 64 维向量x = torch.randn(8, 10, 64)
# 自注意力中,query、key、value 可以来自同一个输入output, weights = attention(x, x, x)
print(output.shape)print(weights.shape)这里重点是理解:
• 输入通常是序列张量
• 每个位置会与其他位置建立关系
• 输出形状通常与输入主结构保持一致
Transformer 结构较复杂,初学阶段不必急于展开所有细节。先理解 Embedding、序列张量形状和注意力输入输出关系,会更稳妥。
十二、参数管理:parameters() 与 state_dict()
神经网络训练的本质,是不断更新模型中的可学习参数。nn.Module 会自动管理模型中的参数。
1、查看模型参数
python
import torch.nn as nn
model = nn.Sequential( nn.Linear(4, 16), nn.ReLU(), nn.Linear(16, 3))
# 遍历模型中所有可学习参数for name, param in model.named_parameters(): print(name, param.shape)输出结果类似:
apache
0.weight torch.Size([16, 4])0.bias torch.Size([16])2.weight torch.Size([3, 16])2.bias torch.Size([3])这里可以看到,ReLU 没有可学习参数,而 Linear 有权重和偏置。
2、parameters():交给优化器更新
apache
import torch.optim as optim
model = nn.Linear(4, 3)
# 优化器通过 model.parameters() 获取需要更新的参数optimizer = optim.Adam(model.parameters(), lr=0.001)这也是为什么模型层必须正确注册到 nn.Module 中。如果某些层没有被注册,优化器可能无法找到它们的参数。
3、state_dict():保存模型参数
python
import torchimport torch.nn as nn
model = nn.Linear(4, 3)
# 查看模型参数字典state = model.state_dict()
print(state.keys())
# 保存模型参数torch.save(model.state_dict(), "model.pth")加载参数通常写成:
apache
model = nn.Linear(4, 3)
# 加载已保存的参数model.load_state_dict(torch.load("model.pth"))state_dict() 是 PyTorch 中非常常用的模型保存方式。它保存的是参数,而不是完整训练代码。因此,加载时通常需要先重新定义相同结构的模型。
十三、train() 与 eval():训练模式和推理模式
某些层在训练和推理时行为不同,例如:
• Dropout:训练时随机丢弃,推理时不丢弃
• BatchNorm:训练时使用当前批次统计量,推理时使用累计统计量
因此,在训练和验证时要明确切换模式。
makefile
# 进入训练模式model.train()
# 训练阶段:通常会执行前向传播、计算损失、反向传播和参数更新logits = model(x)loss = criterion(logits, target)
# 进入推理模式model.eval()
# 推理阶段:通常还会配合 torch.no_grad()with torch.no_grad(): logits = model(x)需要注意:
• model.train() 不会自动训练模型,只是切换为训练模式
• model.eval() 不会停止梯度计算,只是切换为推理模式
• 推理时通常还要使用 torch.no_grad() 关闭梯度记录
十四、一个完整示例:用 nn 构建并训练简单分类模型
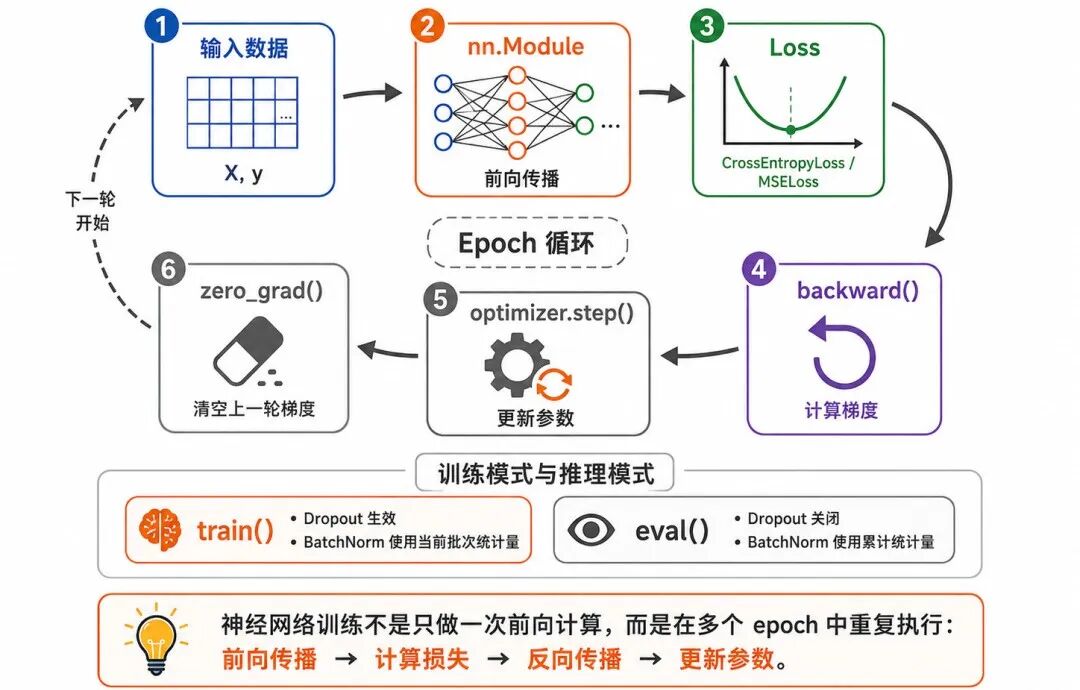
图 3:torch.nn 模型训练闭环
下面用一个完整示例,把 torch.nn、损失函数和优化器串起来。
python
import torchimport torch.nn as nnimport torch.optim as optim
# 1. 构造模拟数据:200 个样本,每个样本 4 个特征,类别数为 3X = torch.randn(200, 4)y = torch.randint(0, 3, (200,))
class MLPClassifier(nn.Module): def __init__(self): super().__init__()
# 使用 Sequential 组织简单多层感知机 self.net = nn.Sequential( nn.Linear(4, 16), nn.ReLU(), nn.Linear(16, 3) )
def forward(self, x): return self.net(x)
# 2. 创建模型model = MLPClassifier()
# 3. 多分类任务常用交叉熵损失criterion = nn.CrossEntropyLoss()
# 4. Adam 优化器负责更新模型参数optimizer = optim.Adam(model.parameters(), lr=0.01)
# 5. 训练模型for epoch in range(10): model.train()
# 前向传播 logits = model(X)
# 计算损失 loss = criterion(logits, y)
# 清空上一轮梯度 optimizer.zero_grad()
# 反向传播 loss.backward()
# 更新参数 optimizer.step()
print(f"第 {epoch + 1} 轮,损失:{loss.item():.4f}")这个示例体现了神经网络训练的基本闭环:
输入数据 → 模型前向计算 → 计算损失 → 清空梯度 → 反向传播 → 参数更新
其中,torch.nn 主要负责模型结构和损失函数;优化器负责根据梯度更新参数。
十五、使用 torch.nn 时应注意的问题
1、不要忘记继承 nn.Module 并调用 super().init()
自定义模型时,通常要写:
ruby
class MyModel(nn.Module): def __init__(self): super().__init__()如果忘记调用 super().init(),子模块和参数可能无法被正常注册,后续训练会出现问题。
2、网络层应定义在 init() 中
推荐写法:
ruby
class MyModel(nn.Module): def __init__(self): super().__init__() self.fc = nn.Linear(4, 3)
def forward(self, x): return self.fc(x)不推荐在 forward() 中反复新建带参数的层:
ruby
def forward(self, x): # 不推荐:每次前向传播都会新建一层 fc = nn.Linear(4, 3) return fc(x)原因是:训练需要持续更新同一组参数。如果每次前向传播都创建新层,模型参数就无法稳定学习。
3、注意输入输出形状
神经网络层对输入形状有明确要求。例如:
• nn.Linear 通常关注输入最后一维
• nn.Conv2d 通常要求输入为 (N, C, H, W)
• nn.LSTM 在 batch_first=True 时常用 (N, T, D)
• nn.CrossEntropyLoss 常用 (N, C) 的预测值和 (N,) 的类别标签
很多错误都可以通过打印形状定位:
bash
print(x.shape)print(logits.shape)print(target.shape)4、区分 logits、概率和类别
分类模型中,常见三个概念:
• logits:模型输出的原始分数
• 概率:经过 Softmax 后得到的归一化结果
• 类别:分数最大或概率最大的类别编号
例如:
apache
import torch
logits = torch.randn(4, 3)
# 将原始分数转换为概率probs = torch.softmax(logits, dim=1)
# 取概率最大的类别编号pred = torch.argmax(probs, dim=1)
print(pred)训练时使用 CrossEntropyLoss,通常直接输入 logits,不需要先手动计算 Softmax。
5、训练与推理模式要切换
涉及 Dropout、BatchNorm 等层时,训练和推理行为不同。
训练阶段:
go
model.train()验证或推理阶段:
javascript
model.eval()
with torch.no_grad(): output = model(x)这两个操作不应省略。否则,验证结果可能不稳定,推理结果也可能受到训练行为影响。
6、用 ModuleList 保存多个层,而不是普通列表
如果多个层需要放在列表里,推荐使用:
ini
self.layers = nn.ModuleList([ nn.Linear(4, 16), nn.Linear(16, 3)])不要简单写成:
ini
self.layers = [ nn.Linear(4, 16), nn.Linear(16, 3)]普通列表中的层可能不会被正确注册,优化器也可能无法更新其中的参数。
7、损失函数要匹配任务类型
不同任务应该使用不同损失函数:
• 多分类任务:常用 CrossEntropyLoss
• 二分类任务:常用 BCEWithLogitsLoss
• 回归任务:常用 MSELoss 或 L1Loss
• 多标签任务:常用 BCEWithLogitsLoss
损失函数选错,模型即使能运行,也可能学不到正确目标。
📘 小结
torch.nn 模块负责神经网络模型的构建与组织,是从张量计算走向深度学习建模的关键模块。学习这一模块,重点不只是记住层名称,而是理解 nn.Module 如何管理层和参数,forward() 如何定义数据流,损失函数如何连接预测与目标,以及训练模式和推理模式为何必须区分。

"点赞有美意,赞赏是鼓励"