生成对抗网络(Generative Adversarial Network,GAN)是深度学习中非常重要的一类生成模型。与分类模型、回归模型不同,GAN 的目标不是根据输入判断类别,也不是预测一个连续数值,而是学习真实数据的分布,并生成看起来像真实数据的新样本。
例如:
• 生成一张手写数字图片
• 生成一张看起来真实的人脸图像
• 修复图像缺失区域
• 提升图像分辨率
• 把一种图像风格转换为另一种风格
• 根据条件信息生成指定类型的样本
GAN 的核心思想可以概括为:让两个神经网络相互竞争,一个负责生成假样本,另一个负责判断样本真假。通过这种对抗过程,生成器逐渐学会生成越来越接近真实数据的样本。
一、为什么需要生成对抗网络
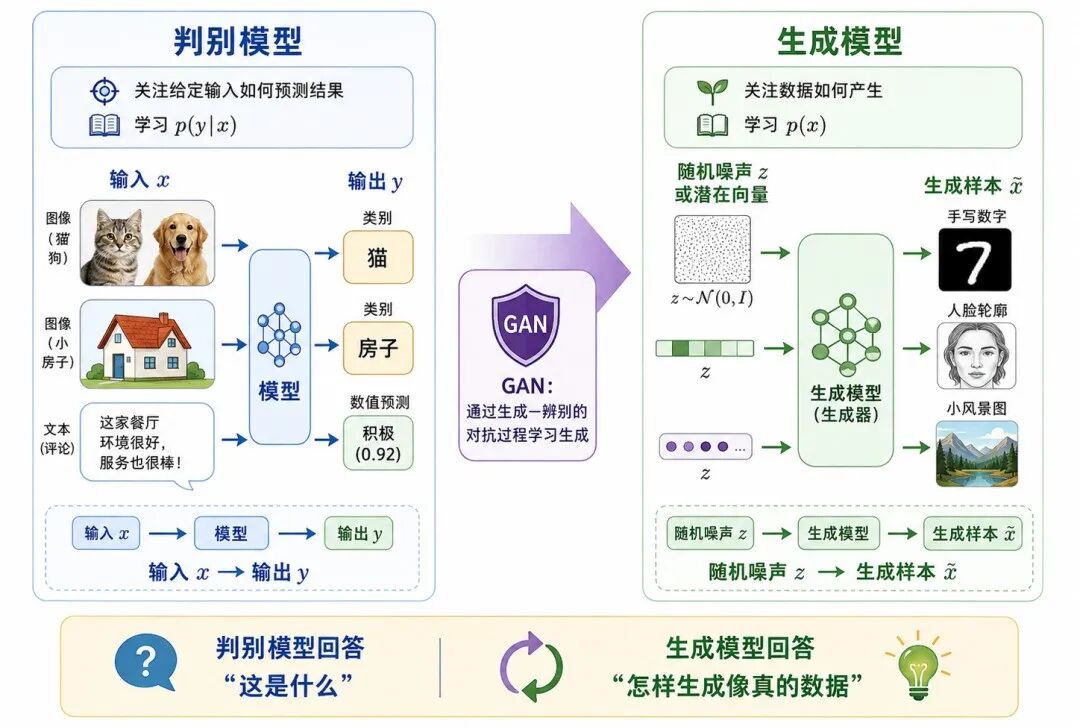
图 1:从判别模型到生成模型
在很多深度学习任务中,我们训练的是判别模型(Discriminative Model)。判别模型的目标是根据输入判断结果。
例如:
• 输入图像 → 判断是猫还是狗
• 输入评论 → 判断是正面还是负面
• 输入房屋信息 → 预测房价
这类模型关注的是:给定输入 x,预测目标 y。
可以写成:
其中:
• x 表示输入数据
• y 表示目标标签
• p(y|x) 表示在给定 x 的条件下,y 出现的概率
但是,生成模型(Generative Model)关注的是另一个问题:数据本身是如何产生的?
它希望学习真实数据的分布,并从这个分布中生成新样本。
可以简单写为:
其中:
• x 表示数据样本
• p(x) 表示数据样本出现的概率分布
例如,如果模型学习的是手写数字图像分布,那么它应该能够生成新的手写数字图片;如果模型学习的是人脸图像分布,那么它应该能够生成新的人脸图像。
GAN 的特别之处在于:它不直接写出一个明确的数据分布公式,而是通过两个网络的对抗训练,让生成器逐渐逼近真实数据分布。
可以简单理解为:
• 判别模型:学习如何判断
• 生成模型:学习如何创造
GAN 通过"生成---辨别"的对抗过程学习生成。
二、GAN 的基本结构
GAN 通常由两个神经网络组成:
• 生成器
• 判别器
生成器(Generator)负责"生成假样本",判别器(Discriminator)负责"判断真假"。二者在训练过程中相互竞争、共同变化。
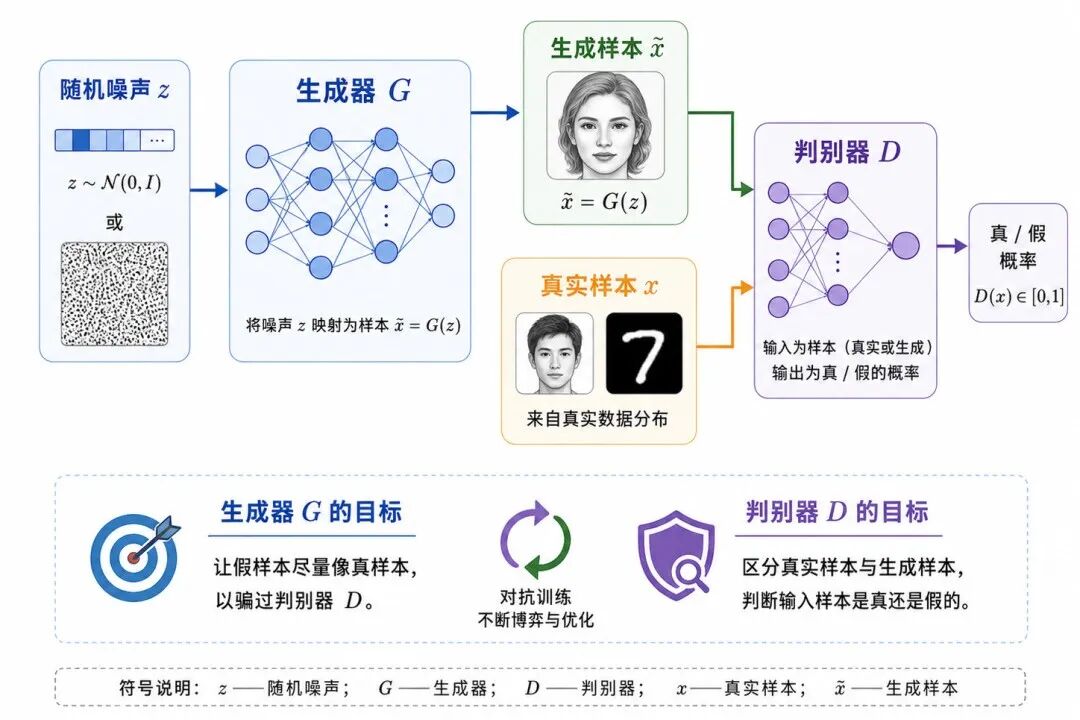
图 2:GAN 的基本结构
1、生成器:从随机噪声生成样本
生成器的输入通常是一个随机噪声向量 z。这个 z 可以来自正态分布或均匀分布。
生成器把 z 映射为一个假样本:
其中:
• z 表示随机噪声向量
• G 表示生成器
• G(z) 表示生成器输出的假样本
• x̃ 表示生成样本
如果任务是生成手写数字图像,那么 G(z) 就是一张模型生成的手写数字图片。
生成器的目标是:让生成样本尽可能像真实样本,使判别器难以分辨真假。
2、判别器:判断样本是真是假
判别器接收一个样本 x,并输出它是真实样本的概率:
其中:
• D 表示判别器
• x 表示输入样本
• D(x) 表示判别器认为 x 来自真实数据的概率
如果 D(x) 接近 1,表示判别器认为样本很可能是真实样本。
如果 D(x) 接近 0,表示判别器认为样本很可能是生成器伪造的样本。
判别器的目标是:尽可能把真实样本判断为真,把生成样本判断为假。
3、生成器与判别器的对抗关系
GAN 的训练过程类似一个"生成者"和"鉴别者"的博弈:
• 生成器 G:尽量生成更逼真的假样本
• 判别器 D:尽量分辨真实样本和生成样本
随着训练进行:
• 判别器会越来越擅长识别真假
• 生成器会根据判别器反馈不断改进
• 当生成器足够强时,判别器很难区分真假样本
理想情况下,生成器学到的数据分布会逐渐接近真实数据分布。
三、GAN 的对抗训练目标
GAN 的核心是对抗训练。它不是训练一个网络,而是同时训练生成器 G 和判别器 D。
判别器希望真实样本被判断为真,生成样本被判断为假;生成器则希望生成样本被判别器判断为真。
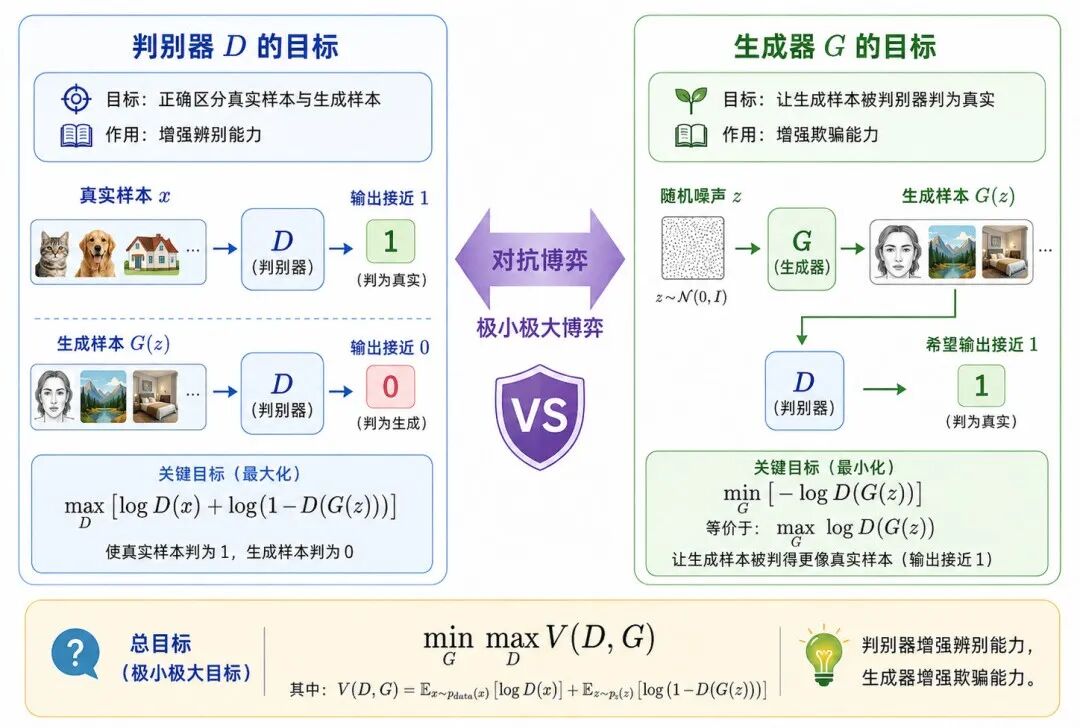
图 3:GAN 的对抗训练目标
1、判别器的目标
对于真实样本 x,判别器希望:
对于生成样本 G(z),判别器希望:
因此,判别器希望最大化:
其中:
• D(x) 表示判别器认为真实样本为真的概率
• D(G(z)) 表示判别器认为生成样本为真的概率
• log D(x) 鼓励真实样本被判断为真
• log(1 − D(G(z))) 鼓励生成样本被判断为假
从直观角度看,判别器在学习:
• 真实样本 → 1
• 生成样本 → 0
2、生成器的目标
生成器希望自己的输出 G(z) 被判别器判断为真,也就是希望:
在原始 GAN 目标中,生成器试图最小化:
但在实际训练中,常用非饱和形式,让生成器最大化:
等价地,可以最小化:
其中:
• G(z) 表示生成器生成的假样本
• D(G(z)) 表示判别器认为该假样本为真的概率
• −log D(G(z)) 越小,说明生成器越容易骗过判别器
这种写法在训练早期通常能提供更强的梯度信号。
3、GAN 的极小极大目标
原始 GAN 的总体目标可以写为:
其中:
• G 表示生成器
• D 表示判别器
• p_data(x) 表示真实数据分布
• p_z(z) 表示噪声分布
• x ∼ p_data(x) 表示真实样本来自真实数据分布
• z ∼ p_z(z) 表示噪声来自预设噪声分布
• E 表示期望
这个目标的含义是:
• 判别器 D 尽量最大化真假区分能力
• 生成器 G 尽量最小化判别器对生成样本的识别能力
这也是 GAN 名称中"对抗"的来源。
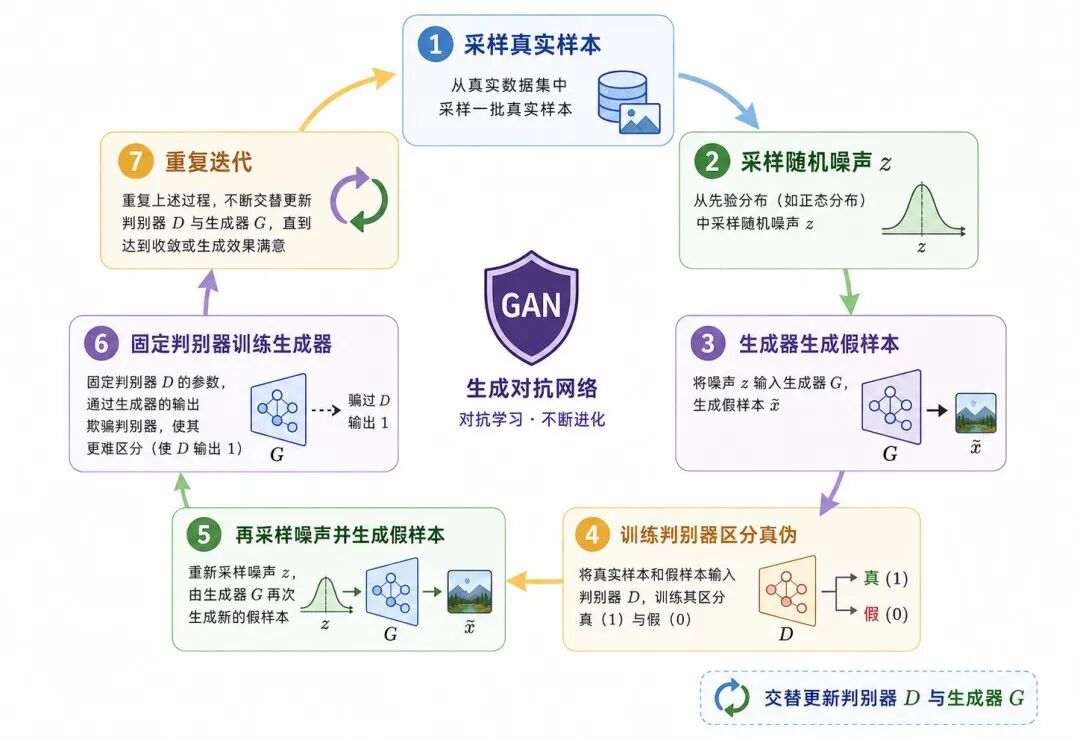
四、GAN 的训练过程
GAN 的训练通常不是一次性同时更新两个网络,而是交替更新判别器和生成器。
一个典型训练流程如下:
-
从真实数据集中取一批真实样本
-
从噪声分布中采样一批随机向量
-
生成器根据噪声生成一批假样本
-
用真实样本和假样本训练判别器
-
再采样一批噪声,生成假样本
-
固定判别器,用判别器反馈训练生成器
-
重复多轮训练
 读取中... 读取中...
读取中... 读取中...
图 4:GAN 的训练闭环
1、训练判别器
训练判别器时,需要同时使用真实样本和生成样本。
真实样本的标签设为 1:
go
真实样本 → 标签 1生成样本的标签设为 0:
go
生成样本 → 标签 0判别器损失可以写为:
其中:
• L_D 表示判别器损失
• m 表示批量大小
• xᵢ 表示第 i 个真实样本
• zᵢ 表示第 i 个噪声向量
• G(zᵢ) 表示第 i 个生成样本
• D(xᵢ) 表示判别器认为真实样本为真的概率
• D(G(zᵢ)) 表示判别器认为生成样本为真的概率
训练判别器时,生成器通常不更新。
在 PyTorch 中,常用 .detach() 阻断生成样本到生成器的梯度传播:
ini
fake_images = generator(z).detach()这样判别器训练时只更新判别器参数,不会更新生成器参数。
2、训练生成器
训练生成器时,生成器希望判别器把生成样本判断为真。
生成器损失常写为:
其中:
• L_G 表示生成器损失
• zᵢ 表示第 i 个噪声向量
• G(zᵢ) 表示生成器生成的假样本
• D(G(zᵢ)) 表示判别器认为假样本为真的概率
训练生成器时,判别器参与前向计算,但判别器参数不更新;它主要为生成器提供梯度信号,告诉生成器如何调整输出,使生成样本更容易被判别为真。
从直观角度看:
• 判别器训练:提高辨别真假能力
• 生成器训练:提高欺骗判别器能力
这两个过程交替进行,就形成了 GAN 的对抗训练。
五、GAN 为什么能生成数据
GAN 能生成数据的关键,在于生成器不是直接复制训练样本,而是学习把随机噪声映射到数据空间。
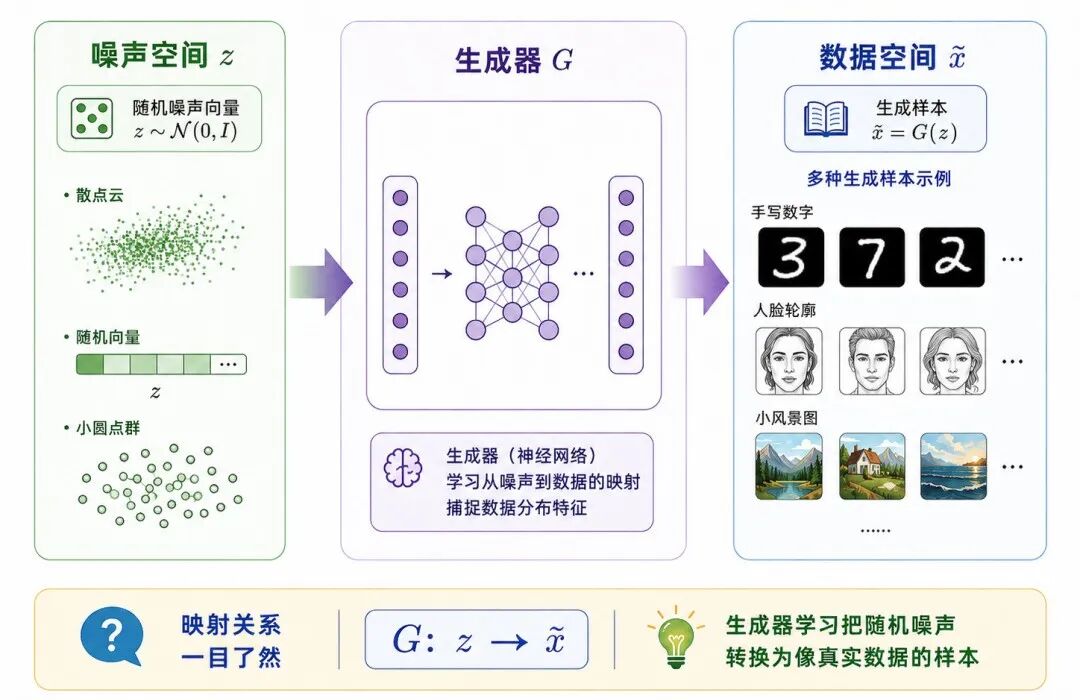
图 5:从噪声空间到数据空间的映射
可以把生成器理解为一个函数:
其中:
• z 表示低维随机噪声
• x̃ 表示生成样本
• G 表示从噪声空间到数据空间的映射
训练开始时,G(z) 通常像随机噪声,没有明显结构。随着训练进行,判别器不断指出生成样本与真实样本之间的差异,生成器则通过梯度更新逐渐修正自己的输出。
在理想情况下:
其中:
• p_g(x) 表示生成器学到的生成分布
• p_data(x) 表示真实数据分布
• ≈ 表示两者逐渐接近
此时,从噪声 z 中采样,再输入生成器,就可以得到看起来像真实数据的新样本。
六、GAN 的主要问题
GAN 的思想非常优雅,但训练并不容易。相比普通分类网络,GAN 更容易出现不稳定现象。
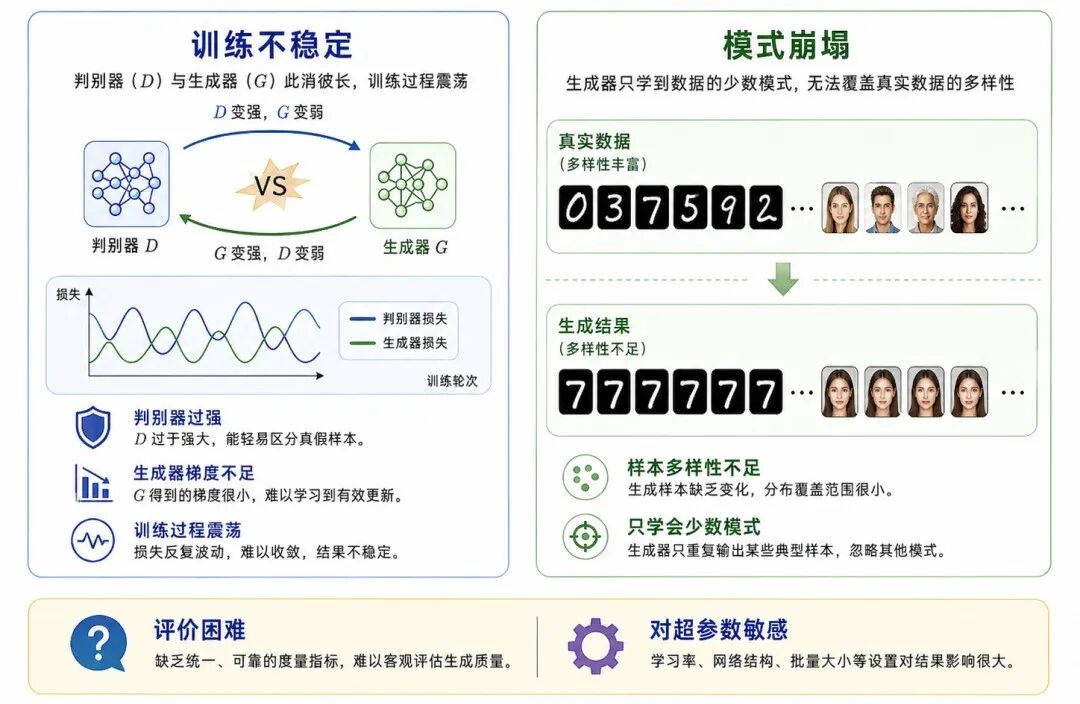
图 6:GAN 的主要问题:训练不稳定与模式崩塌
1、训练不稳定
GAN 中有两个网络同时博弈。如果判别器太强,生成器可能得不到有效梯度;如果生成器变化太快,判别器又可能跟不上。
这会导致训练过程震荡,很难像普通监督学习那样稳定下降。
2、模式崩塌
模式崩塌(Mode Collapse)是 GAN 中非常经典的问题。它指的是生成器只学会生成少数几种样本,而没有覆盖真实数据分布中的多样性。
例如,在手写数字生成任务中,生成器可能只生成类似数字 1 或 7 的图像,而很少生成其他数字。
从直观角度看:真实数据有很多种模式,生成器只学会了其中少数模式。
这会导致生成结果看似逼真,但多样性不足。
3、评价困难
分类模型可以用准确率、精确率、召回率等指标评价;回归模型可以用 MSE、MAE、R² 等指标评价。
但生成模型的评价更复杂,因为我们不仅关心生成样本是否清晰,还关心:
• 是否真实
• 是否多样
• 是否覆盖真实数据分布
• 是否与条件输入一致
• 是否具有语义合理性
因此,GAN 的评价通常比普通监督学习任务更困难。
4、对超参数敏感
GAN 对学习率、网络结构、优化器、批量大小、归一化方法等都比较敏感。不同设置可能导致训练效果差异很大。
常见改进方法包括:
• 使用更稳定的损失函数
• 使用归一化技巧
• 调整生成器和判别器的更新频率
• 使用梯度惩罚
• 使用更合理的网络结构
七、PyTorch 实现:使用 GAN 生成手写数字
下面使用 PyTorch 构建一个简单 GAN,用于生成 MNIST 风格的手写数字图像。
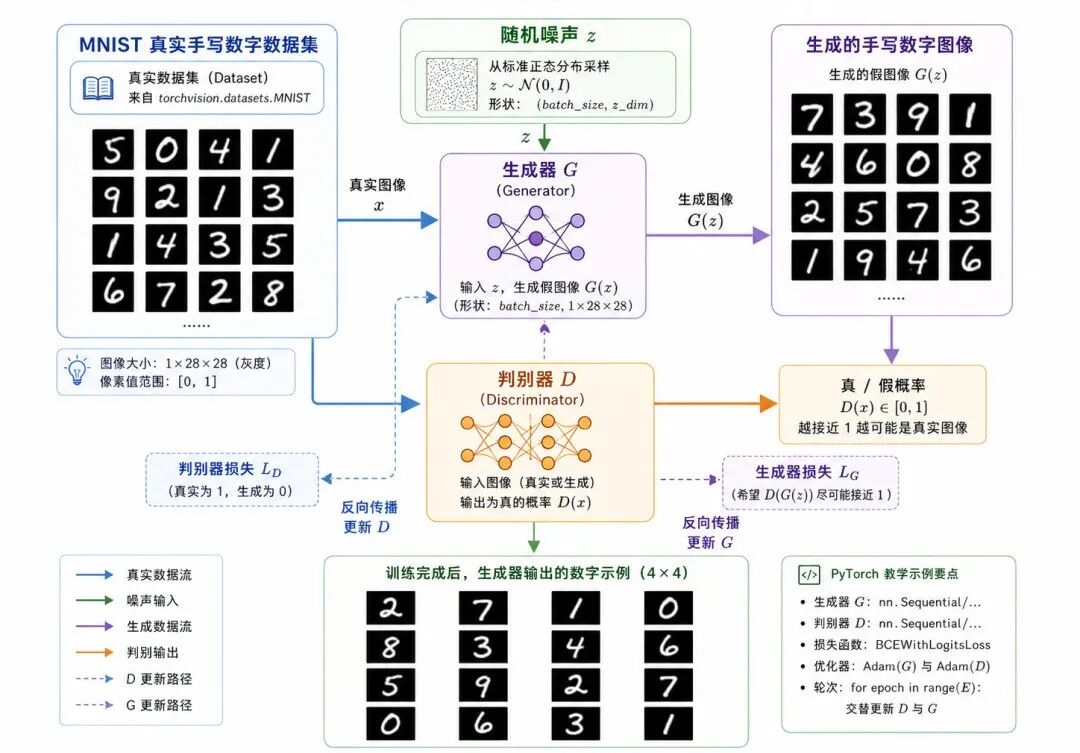
图 7:GAN 生成手写数字的训练与输出流程
为了突出 GAN 的基本训练流程,这里使用全连接网络实现生成器和判别器。真实图像生成任务中,通常会使用卷积结构,例如 DCGAN。
1、导入库
python
# 导入 PyTorch 核心模块import torchimport torch.nn as nn # 神经网络层和损失函数import torch.optim as optim # 优化器
import matplotlib.pyplot as plt # 可视化生成图像
from torch.utils.data import DataLoader # 批量数据加载from torchvision import datasets, transforms # 标准数据集和图像预处理这里使用:
• DataLoader 按批量加载数据
• torchvision.datasets 加载 MNIST 数据集
• torchvision.transforms 进行图像预处理
2、设置超参数
ini
# GAN 超参数设置latent_dim = 100 # 噪声向量维度(生成器输入)image_size = 28 * 28 # MNIST 图像展平后的像素数(28x28=784)batch_size = 128 # 每批处理的样本数num_epochs = 20 # 训练轮数learning_rate = 0.0002 # Adam优化器学习率(常见于GAN训练)MNIST 图像大小为 28 × 28,因此展平后大小为:
3、准备 MNIST 数据集
makefile
# 图像预处理:将图像转为张量并标准化到 [-1, 1] 范围(因为 tanh 输出在 -1 到 1)transform = transforms.Compose([ transforms.ToTensor(), # PIL/NumPy (H,W) → (1,28,28),值域 [0,1] transforms.Normalize((0.5,), (0.5,)) # 标准化: (x - 0.5) / 0.5 → 值域 [-1,1]])
# 加载 MNIST 训练集(60000张手写数字)train_dataset = datasets.MNIST( root="./data", train=True, download=True, transform=transform)
# 数据加载器:批量加载、打乱顺序train_loader = DataLoader( train_dataset, batch_size=batch_size, shuffle=True)这里将图像标准化到大致 −1 到 1 的范围。后面生成器最后使用 Tanh(),输出范围也是 −1 到 1,这样输入输出尺度更匹配。
4、定义生成器
生成器接收随机噪声 z,输出一张展平后的图像。
ruby
# 生成器:将随机噪声向量转换为伪造图像(784维像素值)class Generator(nn.Module): def __init__(self, latent_dim, image_size): super().__init__() # 全连接网络:噪声向量 → 逐层升维 → 最终输出图像像素(值域 -1 到 1) self.net = nn.Sequential( nn.Linear(latent_dim, 256), # 100 → 256 nn.ReLU(), nn.Linear(256, 512), # 256 → 512 nn.ReLU(), nn.Linear(512, image_size), # 512 → 784 nn.Tanh() # 输出范围 (-1, 1),匹配标准化后的真实图像 )
def forward(self, z): return self.net(z)生成器结构可以概括为:
随机噪声 z → 全连接层 → ReLU → 全连接层 → ReLU → 全连接层 → Tanh → 生成图像
其中:
• 输入是长度为 latent_dim 的随机噪声
• 输出是长度为 784 的向量
• Tanh 使输出范围接近 −1 到 1
• 输出向量可以 reshape 为 1 × 28 × 28 的图像
5、定义判别器
判别器接收一张图像,并输出它是真实图像的概率。
ruby
# 判别器:接收图像(784维),输出该图像为真实图像的概率class Discriminator(nn.Module): def __init__(self, image_size): super().__init__() # 全连接网络:逐层降维,最终输出一个概率(0~1) self.net = nn.Sequential( nn.Linear(image_size, 512), # 784 → 512 nn.LeakyReLU(0.2), # LeakyReLU 负斜率0.2,避免梯度饱和 nn.Linear(512, 256), # 512 → 256 nn.LeakyReLU(0.2), nn.Linear(256, 1), # 256 → 1 nn.Sigmoid() # 压缩到 (0,1) 表示真实概率 )
def forward(self, x): return self.net(x)判别器结构可以概括为:
图像向量 → 全连接层 → LeakyReLU → 全连接层 → LeakyReLU → 全连接层 → Sigmoid → 真假概率
其中:
• 输入是长度为 784 的图像向量
• 输出是 0 到 1 之间的概率
• 越接近 1,表示越像真实图像
• 越接近 0,表示越像生成图像
这里为了便于初学者理解,判别器最后显式使用 Sigmoid(),损失函数使用 BCELoss()。在更稳定的工程写法中,也可以让判别器输出 logits,并使用 BCEWithLogitsLoss()。
6、创建模型、损失函数和优化器
makefile
# 选择训练设备(GPU优先)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 实例化生成器和判别器,并移动到设备generator = Generator(latent_dim, image_size).to(device)discriminator = Discriminator(image_size).to(device)
# 损失函数:二分类交叉熵(适合判别器输出0/1概率)criterion = nn.BCELoss()
# 生成器优化器:Adam,学习率0.0002,beta1=0.5(GAN常用,避免震荡)optimizer_G = optim.Adam( generator.parameters(), lr=learning_rate, betas=(0.5, 0.999))
# 判别器优化器:相同配置optimizer_D = optim.Adam( discriminator.parameters(), lr=learning_rate, betas=(0.5, 0.999))其中:
• generator 表示生成器
• discriminator 表示判别器
• BCELoss 表示二元交叉熵损失
• optimizer_G 用于更新生成器
• optimizer_D 用于更新判别器
• betas=(0.5, 0.999) 是 GAN 中常见的 Adam 参数设置
7、训练 GAN
GAN 的训练通常分为两步:
• 先训练判别器
• 再训练生成器
训练代码如下:
css
# 训练循环for epoch in range(num_epochs): for real_images, _ in train_loader: batch_size_current = real_images.size(0)
# 将真实图像展平为一维向量(batch, 784)并移至设备 real_images = real_images.view(batch_size_current, -1).to(device)
# 定义标签:真实图像标签为1,生成图像标签为0 real_labels = torch.ones(batch_size_current, 1).to(device) fake_labels = torch.zeros(batch_size_current, 1).to(device)
# ========================= # 1. 训练判别器(最大化 log D(real) + log(1-D(fake))) # ========================= # 生成随机噪声向量 z = torch.randn(batch_size_current, latent_dim).to(device) fake_images = generator(z) # 生成假图像
# 判别器对真实图像和假图像的预测 real_outputs = discriminator(real_images) fake_outputs = discriminator(fake_images.detach()) # detach阻断梯度回传至生成器
loss_real = criterion(real_outputs, real_labels) # 真实图像损失 loss_fake = criterion(fake_outputs, fake_labels) # 假图像损失 loss_D = loss_real + loss_fake # 判别器总损失
optimizer_D.zero_grad() loss_D.backward() optimizer_D.step()
# ========================= # 2. 训练生成器(最大化 log D(fake)) # ========================= z = torch.randn(batch_size_current, latent_dim).to(device) fake_images = generator(z) outputs = discriminator(fake_images) # 判别器对假图像输出
loss_G = criterion(outputs, real_labels) # 生成器试图让假图像被判别为真
optimizer_G.zero_grad() loss_G.backward() optimizer_G.step()
# 每个epoch结束打印损失 print( f"Epoch [{epoch + 1}/{num_epochs}], " f"Loss_D: {loss_D.item():.4f}, " f"Loss_G: {loss_G.item():.4f}" )这段代码体现了 GAN 的核心训练闭环。
训练判别器时:
• 真实图像希望被判为 1
• 生成图像希望被判为 0
• 使用 fake_images.detach() 避免更新生成器
训练生成器时:
• 生成器希望生成图像被判别器判为 1
• 判别器参与前向计算,但目标是更新生成器参数
• 生成器通过判别器反馈改进生成图像
8、生成并查看图像
训练完成后,可以从随机噪声生成图像:
apache
import matplotlib.pyplot as plt
# 切换生成器到评估模式(关闭Dropout/BatchNorm等训练行为)generator.eval()
# 禁用梯度计算,节省内存with torch.no_grad(): # 生成16个随机噪声向量 z = torch.randn(16, latent_dim).to(device) # 生成假图像(形状: 16, 784) fake_images = generator(z) # 重塑为图像格式:16张,1通道,28x28像素 fake_images = fake_images.view(-1, 1, 28, 28) # 将像素范围从 [-1,1] 还原到 [0,1](便于matplotlib显示) fake_images = (fake_images + 1) / 2
# 创建4x4子图网格fig, axes = plt.subplots(4, 4, figsize=(6, 6))
# 遍历子图,显示生成的图像for i, ax in enumerate(axes.flat): # 移除通道维度(单通道灰度图),转换为numpy,显示灰度图像 ax.imshow(fake_images[i].cpu().squeeze(), cmap="gray") ax.axis("off") # 隐藏坐标轴
plt.show() # 展示生成的图像其中:
• z 是随机噪声
• generator(z) 生成图像向量
• view(-1, 1, 28, 28) 把向量还原为图像形状
• (fake_images + 1) / 2 把图像从 −1 到 1 转回 0 到 1
八、GAN 的适用场景、局限与扩展方向
GAN 是生成式深度学习的重要代表模型之一。它在图像生成、图像编辑、风格迁移等任务中具有重要影响。
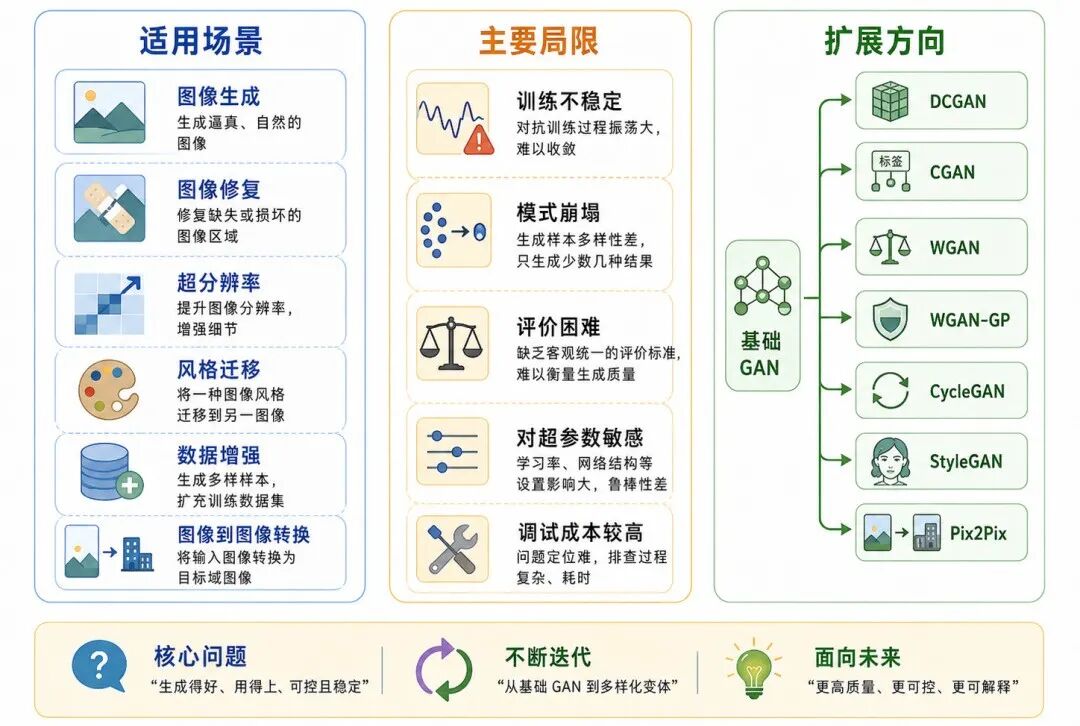
图 8:GAN 的适用场景、局限与扩展方向
1、适用场景
GAN 的常见应用包括:
• 图像生成
• 图像修复
• 图像超分辨率
• 图像风格迁移
• 数据增强
• 图像到图像转换
• 人脸生成与编辑
例如,超分辨率任务可以利用 GAN 生成更清晰、更自然的细节;图像到图像转换任务可以把草图转换为真实图像,或把白天场景转换为夜晚场景。
2、主要优势
GAN 的主要优势包括:
• 生成样本通常较清晰
• 能学习复杂数据分布
• 不需要显式写出数据分布公式
• 适合图像生成和图像编辑任务
• 对抗训练思想具有很强启发性
GAN 的重要价值不仅在于某一个具体模型,也在于它提出了一种新的训练范式:通过两个网络的竞争推动生成能力提升。
3、主要局限
GAN 的主要局限包括:
• 训练不稳定
• 容易出现模式崩塌
• 评价指标不如监督学习直观
• 对超参数和网络结构敏感
• 训练过程需要平衡生成器和判别器
• 在复杂任务中调试成本较高
这些问题使 GAN 的训练通常比普通分类模型更困难。
4、扩展方向
从基础 GAN 出发,可以继续学习以下模型:
• DCGAN:使用卷积结构改进图像生成
• CGAN:加入条件信息控制生成结果
• WGAN:改进训练稳定性
• WGAN-GP:加入梯度惩罚,进一步稳定训练
• CycleGAN:用于无配对图像到图像转换
• StyleGAN:高质量人脸与图像生成的重要代表
• Pix2Pix:用于有配对图像到图像转换
近年来,扩散模型(Diffusion Model)在许多生成任务中表现非常突出,但 GAN 仍然是理解生成建模和对抗训练思想的重要基础。
📘 小结
生成对抗网络通过生成器和判别器的对抗训练学习数据分布。生成器从随机噪声生成样本,判别器判断样本真假,二者交替优化,使生成结果逐渐接近真实数据。GAN 在图像生成和图像编辑中影响深远,但也存在训练不稳定、模式崩塌和评价困难等问题。

"点赞有美意,赞赏是鼓励"