垃圾分类识别数据集介绍
1. 数据集概述
本项目使用的数据集位于 datasets/GarbageSorting 目录下,主要用于垃圾分类目标检测任务。数据集采用 YOLO 标准目录结构组织,包含图像文件、对应标注文件以及数据集配置文件 data.yaml,可直接用于 YOLOv8 系列模型训练、验证和测试。
该数据集面向垃圾分类识别场景,检测目标共分为 4 类:
| 类别ID | 英文类别名 | 中文含义 |
|---|---|---|
| 0 | recyclable waste | 可回收垃圾 |
| 1 | hazardous waste | 有害垃圾 |
| 2 | kitchen waste | 厨余垃圾 |
| 3 | other waste | 其他垃圾 |
数据集整体包含 2743 张图片和 2743 个标注文件,标注目标框总数为 3925 个。所有图片均为 .jpg 格式,图片与标签文件一一对应,未发现缺失标签文件。
2. 数据集目录结构
datasets/GarbageSorting ├── data.yaml ├── images │ ├── train │ ├── val │ └── test └── labels ├── train ├── val └── test
各目录说明如下:
| 路径 | 说明 |
|---|---|
| data.yaml | YOLO 数据集配置文件,定义数据路径、类别数量和类别名称 |
| images/train | 训练集图片 |
| images/val | 验证集图片 |
| images/test | 测试集图片 |
| labels/train | 训练集 YOLO 标注文件 |
| labels/val | 验证集 YOLO 标注文件 |
| labels/test | 测试集 YOLO 标注文件 |
3. data.yaml 配置说明
当前 data.yaml 内容如下:
path: datasets/GarbageSorting train: images/train val: images/val test: images/test nc: 4 names: ['recyclable waste', 'hazardous waste', 'kitchen waste', 'other waste']
其中:
| 字段 | 含义 |
|---|---|
| path | 数据集根目录,当前使用相对路径,便于项目移动 |
| train | 训练集图片相对路径 |
| val | 验证集图片相对路径 |
| test | 测试集图片相对路径 |
| nc | 类别数量,共 4 类 |
| names | 类别名称列表,类别顺序必须与标注文件中的类别ID一致 |
4. 数据集划分统计
| 数据划分 | 图片数量 | 标注文件数量 | 目标框数量 | 图片占比 | 目标框占比 |
|---|---|---|---|---|---|
| 训练集 train | 1920 | 1920 | 2750 | 70.00% | 70.06% |
| 验证集 val | 548 | 548 | 757 | 19.98% | 19.29% |
| 测试集 test | 275 | 275 | 418 | 10.03% | 10.65% |
| 合计 | 2743 | 2743 | 3925 | 100.00% | 100.00% |
从划分比例看,数据集约按照 7:2:1 的比例划分为训练集、验证集和测试集,整体划分较适合常规目标检测训练流程。
5. 类别分布统计
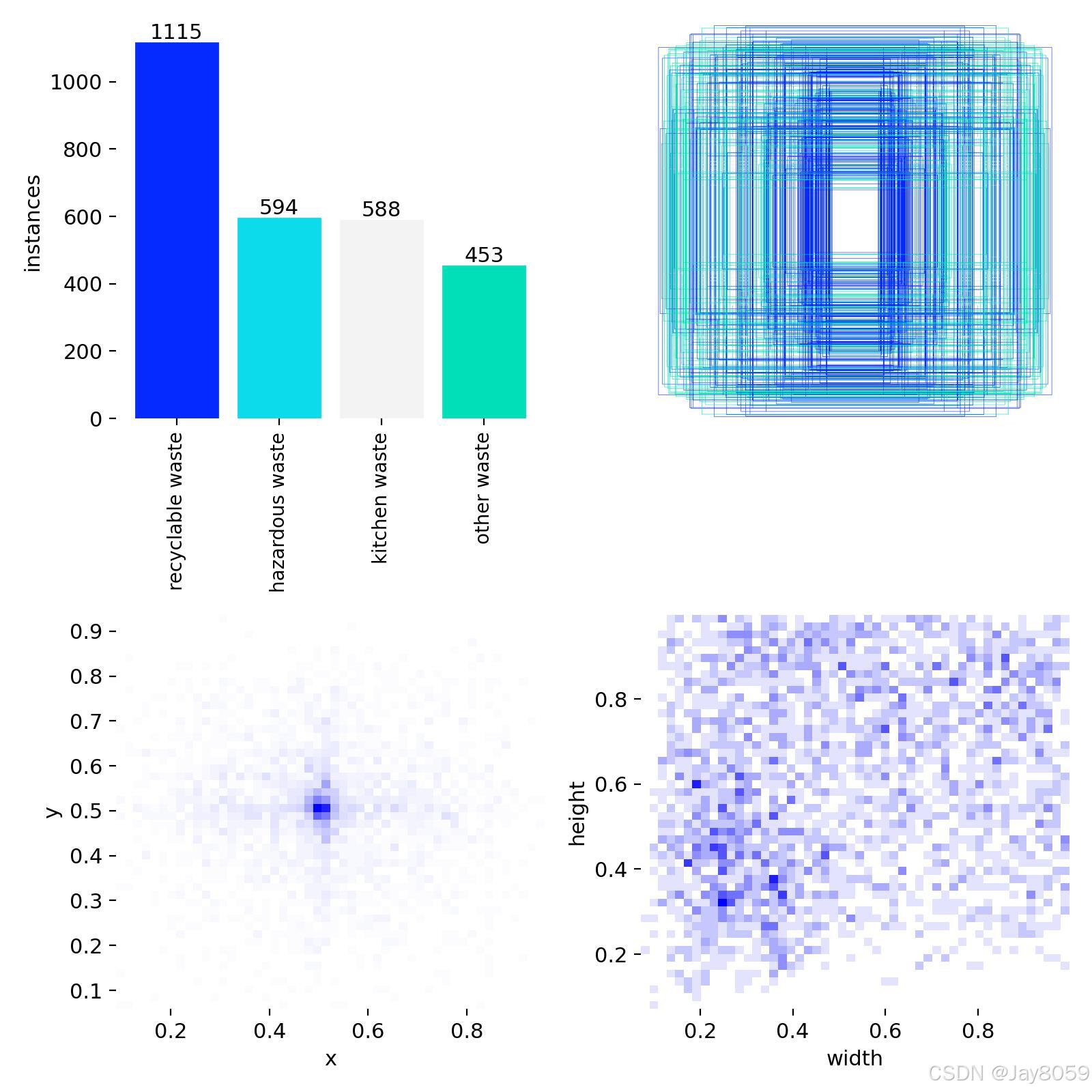
5.1 全量类别分布
| 类别ID | 类别名称 | 中文含义 | 目标框数量 | 占比 |
|---|---|---|---|---|
| 0 | recyclable waste | 可回收垃圾 | 1609 | 40.99% |
| 1 | hazardous waste | 有害垃圾 | 800 | 20.38% |
| 2 | kitchen waste | 厨余垃圾 | 834 | 21.25% |
| 3 | other waste | 其他垃圾 | 682 | 17.38% |
| 合计 | - | - | 3925 | 100.00% |
从类别数量看,recyclable waste 样本最多,占比约 40.99%;other waste 样本最少,占比约 17.38%。数据集存在一定类别不均衡问题,训练时可适当关注少样本类别的召回效果。
5.2 各数据划分类别分布
| 数据划分 | 类别ID | 类别名称 | 目标框数量 | 划分内占比 |
|---|---|---|---|---|
| train | 0 | recyclable waste | 1115 | 40.55% |
| train | 1 | hazardous waste | 594 | 21.60% |
| train | 2 | kitchen waste | 588 | 21.38% |
| train | 3 | other waste | 453 | 16.47% |
| val | 0 | recyclable waste | 314 | 41.48% |
| val | 1 | hazardous waste | 152 | 20.08% |
| val | 2 | kitchen waste | 146 | 19.29% |
| val | 3 | other waste | 145 | 19.15% |
| test | 0 | recyclable waste | 180 | 43.06% |
| test | 1 | hazardous waste | 54 | 12.92% |
| test | 2 | kitchen waste | 100 | 23.92% |
| test | 3 | other waste | 84 | 20.10% |
训练集、验证集和测试集中均包含 4 个类别。测试集中 hazardous waste 占比相对较低,评估时该类别的单类指标可能更容易受样本数量影响。
6. 标注格式说明
数据集采用 YOLO 目标检测标注格式。每张图片对应一个同名 .txt 标注文件,例如:
images/train/fimg_1.jpg labels/train/fimg_1.txt
标注文件中每一行表示一个目标框,格式如下:
class_id x_center y_center width height
字段说明:
| 字段 | 说明 |
|---|---|
| class_id | 类别ID,取值范围为 0 到 3 |
| x_center | 目标框中心点 x 坐标,已按图片宽度归一化 |
| y_center | 目标框中心点 y 坐标,已按图片高度归一化 |
| width | 目标框宽度,已按图片宽度归一化 |
| height | 目标框高度,已按图片高度归一化 |
坐标数值均为 0 到 1 之间的归一化浮点数。一个标注文件可以包含多行,表示同一张图片中存在多个垃圾目标。
7. 单图目标数量统计
| 数据划分 | 图片数量 | 目标框数量 | 平均每图目标数 | 最少目标数 | 最多目标数 |
|---|---|---|---|---|---|
| train | 1920 | 2750 | 1.43 | 1 | 13 |
| val | 548 | 757 | 1.38 | 1 | 10 |
| test | 275 | 418 | 1.52 | 1 | 21 |
整体来看,数据集中多数图片包含 1 个目标,部分图片包含多个垃圾目标。多目标图片数量如下:
| 数据划分 | 多目标图片数量 |
|---|---|
| train | 431 |
| val | 122 |
| test | 56 |
8. 图片规格统计
| 数据划分 | 图片数量 | 宽度范围 | 平均宽度 | 高度范围 | 平均高度 | 平均文件大小 |
|---|---|---|---|---|---|---|
| train | 1920 | 53-1600 | 473.5 | 83-1200 | 394.9 | 27.7 KB |
| val | 548 | 111-1200 | 472.4 | 90-1200 | 395.1 | 29.1 KB |
| test | 275 | 134-1024 | 463.9 | 130-1024 | 384.2 | 27.6 KB |
数据集中图片分辨率不完全统一,训练时 YOLO 会根据输入尺寸进行缩放和填充。由于原始图片尺寸差异较大,模型训练阶段应保留合理的数据增强策略,以提升模型对不同尺寸图片的适应能力。
9. 目标框尺度分布
按目标框归一化面积 width * height 统计,目标尺度分布如下:
| 目标尺度 | 判定标准 | 目标框数量 |
|---|---|---|
| 小目标 | 面积 < 1% | 1 |
| 中等目标 | 1% <= 面积 < 9% | 505 |
| 大目标 | 面积 >= 9% | 3419 |
目标框归一化面积统计:
| 指标 | 数值 |
|---|---|
| 最小面积 | 0.006579 |
| 最大面积 | 0.977423 |
| 平均面积 | 0.319718 |
从统计结果看,数据集中大尺寸目标占比较高,中等目标次之,小目标数量较少。但在实际检测场景中,垃圾目标可能会因拍摄距离、遮挡、背景复杂度等因素变小,因此训练和部署时仍需关注小目标、边缘目标和遮挡目标的识别效果。
10. 数据质量检查结果
对当前数据集进行基础检查后,结果如下:
| 检查项 | 结果 |
|---|---|
| 图片格式 | 全部为 .jpg |
| 图片总数 | 2743 |
| 标注文件总数 | 2743 |
| 图片与标注是否一一对应 | 是 |
| 缺失标注文件数量 | 0 |
| 空标注文件数量 | 0 |
| 标注字段数量异常 | 未发现 |
| 类别ID越界 | 未发现 |
| 坐标超出 0-1 范围 | 未发现 |
整体来看,数据集目录结构清晰,标注格式规范,可直接用于 YOLOv8 目标检测模型训练。
11. 训练结果介绍
当前项目已将模型训练结果保存到 datasets/train_result 目录中,该目录记录了本次 YOLOv8 垃圾分类检测模型训练过程中生成的权重文件、指标日志、训练曲线、混淆矩阵以及预测可视化结果,可用于模型效果分析、论文说明、项目验收和后续模型部署。
11.1 训练结果目录结构
datasets/train_result
├── weights
│ ├── best.pt
│ └── last.pt
├── results.csv
├── results.png
├── labels.jpg
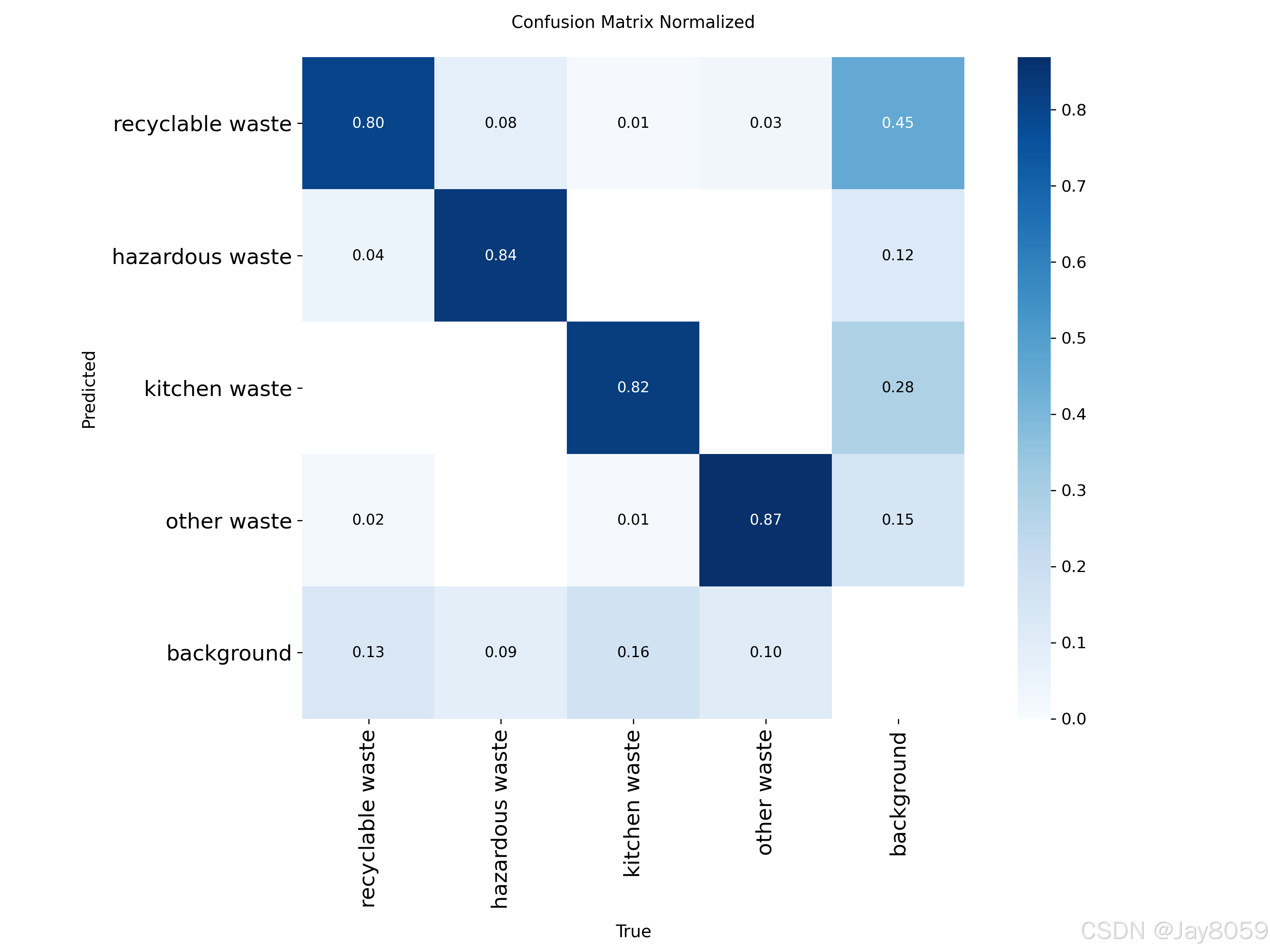
├── confusion_matrix.png
├── confusion_matrix_normalized.png
├── BoxF1_curve.png
├── BoxP_curve.png
├── BoxR_curve.png
├── BoxPR_curve.png
├── train_batch0.jpg
├── train_batch1.jpg
├── train_batch2.jpg
├── train_batch134400.jpg
├── train_batch134401.jpg
├── train_batch134402.jpg
├── val_batch0_labels.jpg
├── val_batch0_pred.jpg
├── val_batch1_labels.jpg
├── val_batch1_pred.jpg
├── val_batch2_labels.jpg
└── val_batch2_pred.jpg
各文件说明如下:
| 文件或目录 | 说明 |
|---|---|
| weights/best.pt | 训练过程中综合验证指标最优的模型权重,通常用于最终部署和推理 |
| weights/last.pt | 最后一轮训练结束后的模型权重,可用于继续训练或对比分析 |
| results.csv | 每轮训练的损失值、Precision、Recall、mAP 和学习率等详细日志 |
| results.png | 训练过程指标曲线汇总图 |
| labels.jpg | 数据集标签分布与目标框分布可视化图 |
| confusion_matrix.png | 混淆矩阵,用于观察不同类别之间的误判情况 |
| confusion_matrix_normalized.png | 归一化混淆矩阵,更便于比较各类别识别比例 |
| BoxF1_curve.png | F1 分数随置信度变化曲线 |
| BoxP_curve.png | Precision 随置信度变化曲线 |
| BoxR_curve.png | Recall 随置信度变化曲线 |
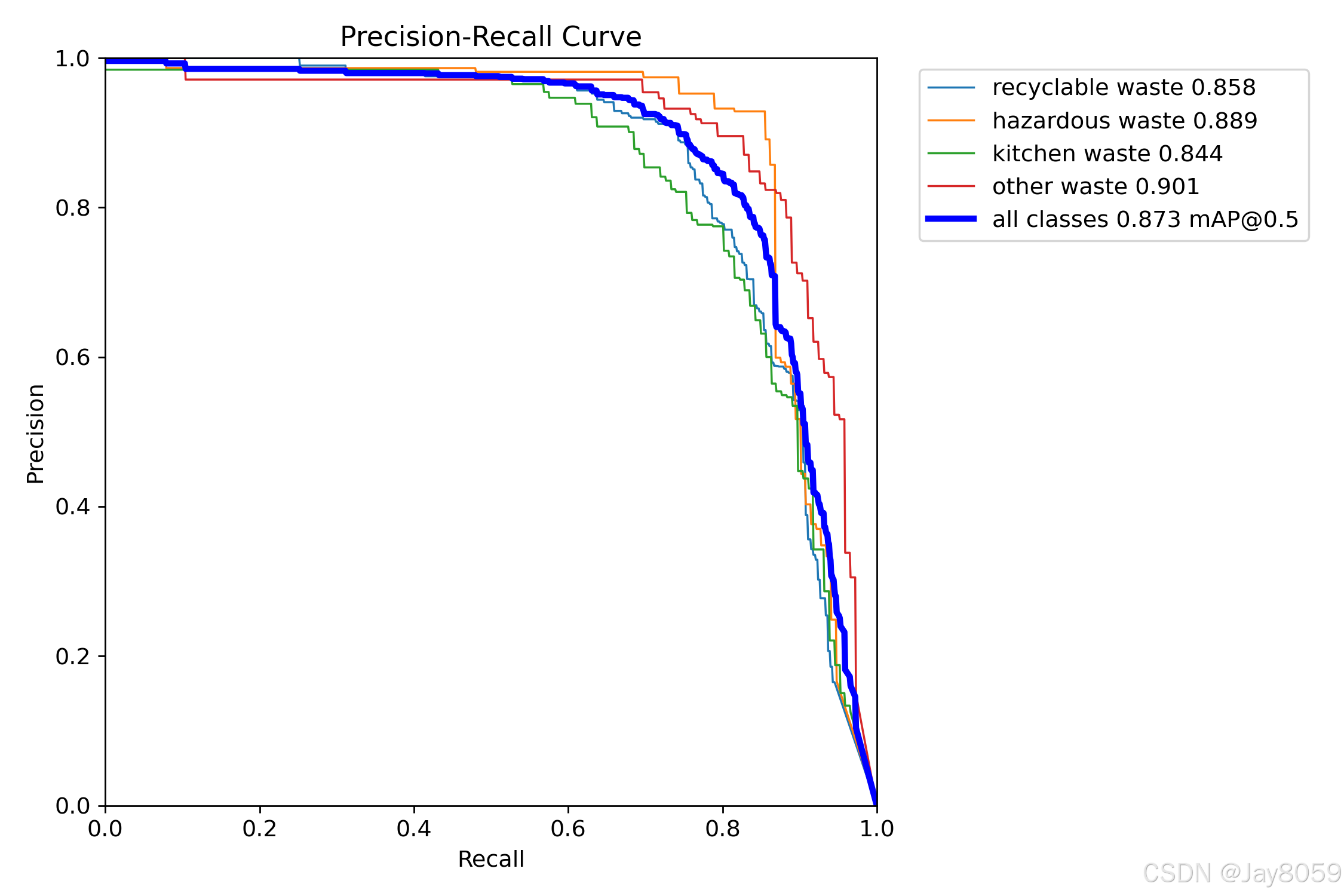
| BoxPR_curve.png | Precision-Recall 曲线 |
| train_batch*.jpg | 训练批次样本可视化结果,用于检查训练数据和标注效果 |
| val_batch*_labels.jpg | 验证集真实标签可视化 |
| val_batch*_pred.jpg | 验证集模型预测结果可视化 |
11.2 训练日志概况
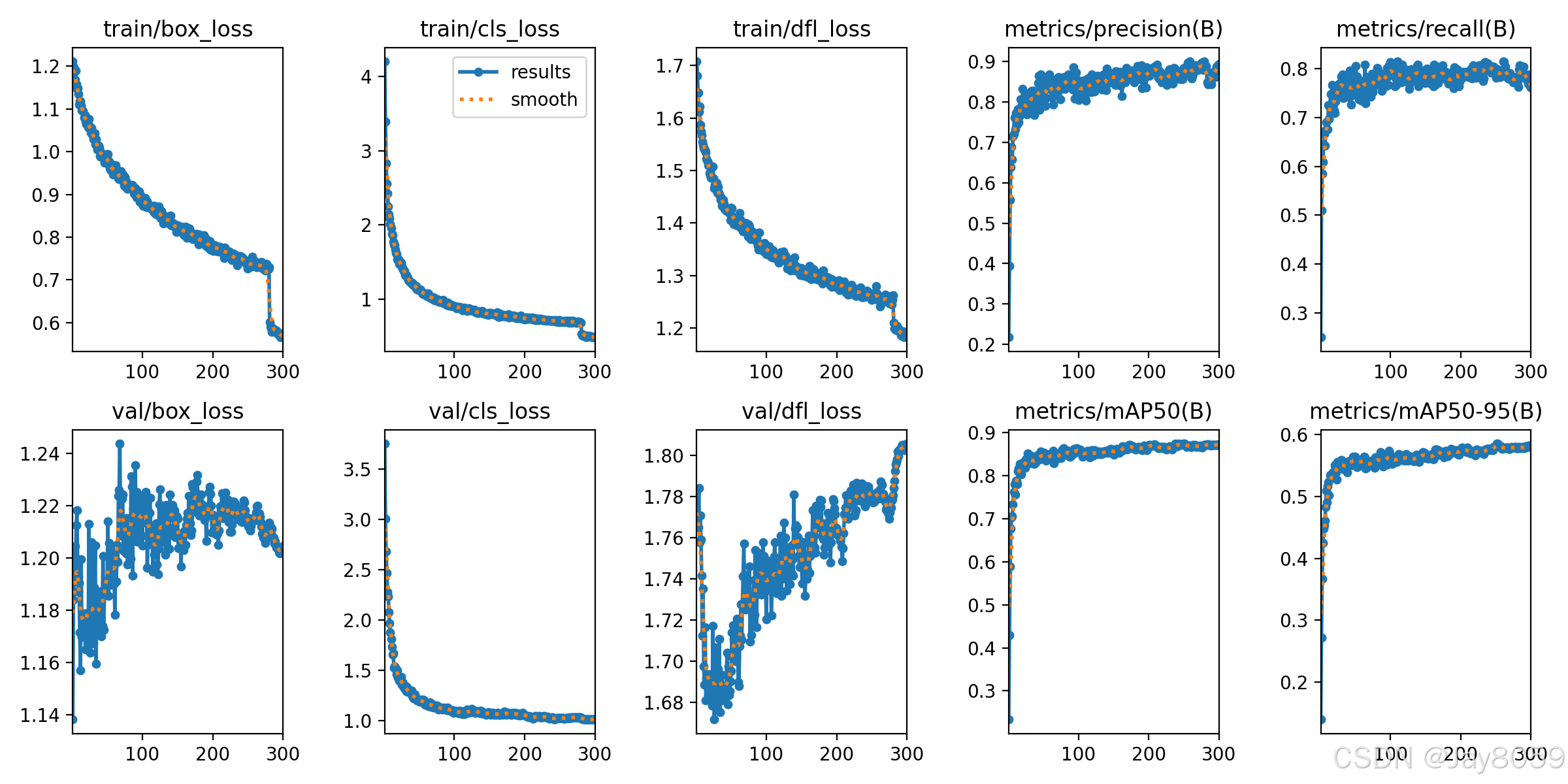
本次训练日志记录于 datasets/train_result/results.csv,共包含 300 轮训练结果。根据日志统计,训练总耗时约 6047.49 秒,约 100.79 分钟。
| 指标 | 数值 |
|---|---|
| 训练轮数 | 300 |
| 最终 Precision | 0.89368 |
| 最终 Recall | 0.76075 |
| 最终 mAP50 | 0.87324 |
| 最终 mAP50-95 | 0.58176 |
| 最终训练 box_loss | 0.57260 |
| 最终训练 cls_loss | 0.48940 |
| 最终训练 dfl_loss | 1.19121 |
| 最终验证 box_loss | 1.20444 |
| 最终验证 cls_loss | 1.01379 |
| 最终验证 dfl_loss | 1.80593 |
从训练过程看,模型的 mAP50 从第 1 轮的 0.23325 提升到最终的 0.87324,mAP50-95 从 0.13927 提升到最终的 0.58176,说明模型在训练后已具备较好的垃圾目标定位和分类能力。
11.3 最佳验证指标
根据 results.csv 中的验证指标统计,本次训练的最佳指标如下:
| 指标 | 最佳轮次 | 最佳值 |
|---|---|---|
| Precision | 279 | 0.90107 |
| Recall | 110 | 0.81519 |
| mAP50 | 251 | 0.87455 |
| mAP50-95 | 252 | 0.58577 |
其中,mAP50 表示 IoU 阈值为 0.5 时的平均精度,适合观察模型是否能较好地检测出目标;mAP50-95 是多个 IoU 阈值下的综合平均精度,对目标框定位质量要求更高。当前最佳 mAP50 达到 0.87455,说明模型在该垃圾分类数据集上具有较好的整体检测效果。
11.4 权重文件说明
训练后的模型权重位于 datasets/train_result/weights 目录:
| 权重文件 | 文件大小 | 推荐用途 |
|---|---|---|
| best.pt | 约 4.17 MB | 推荐用于系统部署、图片检测、视频检测和摄像头检测 |
| last.pt | 约 4.17 MB | 适合继续训练或复现实验最后一轮状态 |
项目部署和实际检测时,通常优先选择 best.pt。如果后续需要在当前训练基础上继续训练,可以使用 last.pt 作为恢复训练权重。
11.5 可视化结果说明
训练结果目录中的可视化图片可以辅助判断模型训练质量:
| 可视化文件 | 主要作用 |
|---|---|
| results.png | 查看训练损失、验证损失、Precision、Recall、mAP 等指标随训练轮数变化趋势 |
| confusion_matrix.png | 查看模型容易混淆的垃圾类别 |
| confusion_matrix_normalized.png | 查看各类别归一化识别比例,适合分析类别不均衡影响 |
| BoxPR_curve.png | 观察不同类别的 Precision-Recall 表现 |
| BoxF1_curve.png | 选择较合适的置信度阈值 |
| val_batch*_pred.jpg | 直观看模型在验证集上的检测框位置、类别和漏检误检情况 |
结合训练指标和可视化结果可知,该模型整体检测效果较好,但由于数据集中类别数量不完全均衡,实际评估时仍建议重点查看 hazardous waste、other waste 等样本相对较少类别的召回率和混淆情况。
12. 使用建议
- 训练时建议直接使用 datasets/GarbageSorting/data.yaml 作为数据配置文件。
- 当前 data.yaml 使用相对路径,项目移动到其他位置后,只要保持目录结构不变,一般不需要修改数据路径。
- 类别顺序必须保持一致,不能随意调整 names 中的顺序,否则会导致模型预测类别与中文类别解释不匹配。
- 数据存在一定类别不均衡,尤其是 other waste 和测试集中的 hazardous waste 样本相对较少,评估时应关注各类别单独的 Precision、Recall 和 mAP。
- 图片尺寸差异较大,训练时建议使用 YOLO 默认的自适应缩放、Mosaic、HSV 增强等策略,以提升模型泛化能力。
- 如果后续新增数据,应保持 images 与 labels 的同名对应关系,并确保标注坐标仍为 YOLO 归一化格式。
- 模型部署时建议优先使用 datasets/train_result/weights/best.pt 权重文件。
- 如果需要继续训练或复现实验最后状态,可使用 datasets/train_result/weights/last.pt。
13. 适用任务
该数据集适合用于以下任务:
| 任务类型 | 说明 |
|---|---|
| 垃圾目标检测 | 检测图像中的垃圾位置并输出类别 |
| 垃圾分类识别 | 根据检测框类别判断垃圾所属分类 |
| YOLOv8 模型训练 | 可直接作为 YOLOv8 数据集输入 |
| 桌面端检测系统 | 可用于本项目垃圾分类检测系统的模型训练与效果验证 |
| 部署效果测试 | 可使用测试集评估模型在未参与训练图片上的检测效果 |
14. 总结
GarbageSorting 是一个面向垃圾分类识别的 YOLO 格式目标检测数据集,共包含 4 类垃圾目标、2743 张图片和 3925 个目标框。数据集已完成训练集、验证集和测试集划分,图片与标注文件匹配完整,标注格式规范,适合用于 YOLOv8 垃圾分类检测模型训练和评估。
需要注意的是,数据集中可回收垃圾样本占比最高,其他垃圾样本占比最低,整体存在一定类别不均衡。模型训练和结果分析时,应重点关注少样本类别的识别效果,并结合混淆矩阵、单类 mAP、召回率等指标判断模型是否存在类别偏向。当前训练结果已保存到 datasets/train_result,其中 best.pt 可作为后续系统部署和检测推理的主要模型权重。