JUC 到 Redis 分布式锁:一次关于高并发的性能压测实验
前言:看不见的"锁"
在此前JUC学习中,了解了
synchronized和ReentrantLock,但在单机环境下,面对少量的数据测试,很难直观感受到锁对系统稳定性的决定性作用。所以通过学习Jmeter对锁的效率提升有个进一步的了解初次尝试
Jmeter可以先看看JMeter的基本使用与性能测试,完整入门篇保姆式教程
1. 实验环境搭建
为了模拟真实的生产环境,我搭建了一个 Spring Boot + Redis 的简单 Demo,包含两个核心接口:
/product/breakdown/{id}:无锁版。模拟缓存失效时,大量请求直接穿透到数据库。/product/safe/{id}:分布式锁版 。使用 Redis 的setIfAbsent实现锁机制,确保同一时间只有一个线程去重建缓存。
关键代码逻辑:
为了模拟数据库查询缓慢的场景,我在查询数据库的方法中强制休眠了 1 秒:
java
private String queryFromDatabase(String id) throws InterruptedException {
// 模拟数据库IO阻塞,耗时1秒
Thread.sleep(1000);
System.out.println("查询数据库中id为" + id + "的数据");
return "商品" + id;
}2. 场景一:缓存击穿(无锁裸奔)
首先,我们测试无锁接口 /product/breakdown/{id}。
场景描述:
假设缓存中不存在该商品数据(或刚好过期),此时 JMeter 模拟 5000 个并发请求瞬间涌入。
发生了什么?
因为没有锁的保护,这 5000 个请求发现缓存没数据,于是全部冲向了 queryFromDatabase 方法。数据库瞬间面临 5000 个耗时 1 秒的查询请求。
JMeter 测试结果:
- 吞吐量 :仅 1998.4/sec。
- 95% 响应时间 :高达 1375 ms。
- 现象:系统变得非常卡顿,响应时间接近我们模拟的 1 秒数据库延迟。
结论:
无锁状态下,数据库成为了绝对的瓶颈。所有请求都在排队等待数据库的缓慢响应,系统吞吐量极低。
3. 场景二:分布式锁护航
接下来,我们测试加锁接口 /product/safe/{id}。
场景描述:
同样的 5000 并发,同样的缓存失效场景。
发生了什么?
- 请求 A 拿到锁,进入数据库查询(耗时 1s)。
- 请求 B、C、D...Z 试图拿锁失败,进入重试逻辑(或等待)。
- 请求 A 查完数据库,将数据写入 Redis 并释放锁。
- 后续请求再次尝试时,发现 Redis 中已有数据,直接返回(耗时微秒级)。
JMeter 测试结果:
- 吞吐量 :飙升至 7396.4/sec(提升了近 4 倍!)。
- 95% 响应时间 :降低至 67 ms。
- 现象:绝大多数请求几乎是瞬间返回,只有极少数请求感受到了延迟。
4. 数据对比与分析
为了更直观地展示区别,我整理了以下对比表:
表格
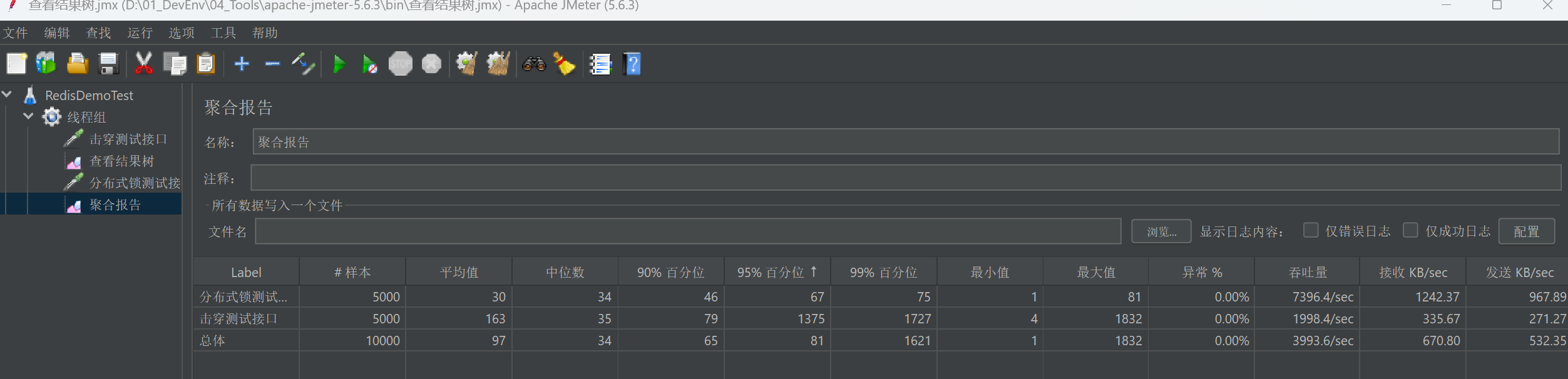
| 指标 | 无锁 (击穿场景) | 分布式锁 (安全场景) | 变化幅度 |
|---|---|---|---|
| 吞吐量 | 1998.4 /sec | 7396.4 /sec | 提升 ~370% |
| 95% 响应时间 | 1375 ms | 67 ms | 降低 ~95% |
| 数据库压力 | 5000 次慢查询 | 1 次慢查询 | 极大缓解 |
核心分析:
- 无锁时:大家都在做重复且低效的"数据库查询"工作,资源被浪费在等待 IO 上。
- 加锁时:只有一个人做低效工作,其他人都在做高效的"读缓存"或直接重试。锁将"串行"的低效操作限制在了最小范围,从而最大化了整体的并发能力。
5. 总结
通过这次 JMeter 压测,我得出了以下结论:
- 锁的代价 vs 数据库的代价:获取 Redis 锁的开销(微秒级)远小于查询数据库的开销(毫秒/秒级)。用微小的锁开销换取数据库的保护,是绝对划算的。
- 分布式锁的必要性 :在集群环境下,
synchronized无法跨 JVM 生效,只有基于 Redis 的分布式锁才能解决多实例间的资源竞争问题。 - 代码健壮性:在编写缓存读取逻辑时,必须考虑"缓存失效"的极端情况,**"双检锁"(Double-Check Locking)**模式是解决缓存击穿的标准答案。
- 结果不明显 :在请求较少的时候看不出差距,但是锁的作用不是为了让单次请求变快,而是为了保护后端资源(数据库)不被压垮,从而保证系统在高负载下的整体吞吐量