目录
[5.1 DaemonSet 功能](#5.1 DaemonSet 功能)
[5.2 DaemonSet 示例](#5.2 DaemonSet 示例)
[核心代码逐行解析(Line-by-Line Breakdown)](#核心代码逐行解析(Line-by-Line Breakdown))
[企业级生产应用(Enterprise Scenario)](#企业级生产应用(Enterprise Scenario))
[六 Job 控制器](#六 Job 控制器)
[6.1 Job 控制器功能](#6.1 Job 控制器功能)
[6.2 Job 控制器示例](#6.2 Job 控制器示例)
[核心代码逐行解析(Line-by-Line Breakdown)](#核心代码逐行解析(Line-by-Line Breakdown))
[企业级生产应用(Enterprise Scenario)](#企业级生产应用(Enterprise Scenario))
[七 CronJob 控制器](#七 CronJob 控制器)
[7.1 CronJob 控制器功能](#7.1 CronJob 控制器功能)
[7.2 CronJob 控制器 示例](#7.2 CronJob 控制器 示例)
[核心代码逐行解析(Line-by-Line Breakdown)](#核心代码逐行解析(Line-by-Line Breakdown))
[企业级生产应用(Enterprise Scenario)](#企业级生产应用(Enterprise Scenario))
5.1 DaemonSet 功能
生活类比
DaemonSet 就像每个小区单元楼必须配备的消防栓:每一栋单元楼(K8s 节点)都必须有且仅有一个消防栓(Pod 副本);新建单元楼(新节点加入集群)时,物业会自动安装消防栓;单元楼拆除(节点离开集群)时,消防栓也会同步拆除;如果物业撤掉这个小区的消防栓配置(删除 DaemonSet),所有单元楼的消防栓都会被移除。
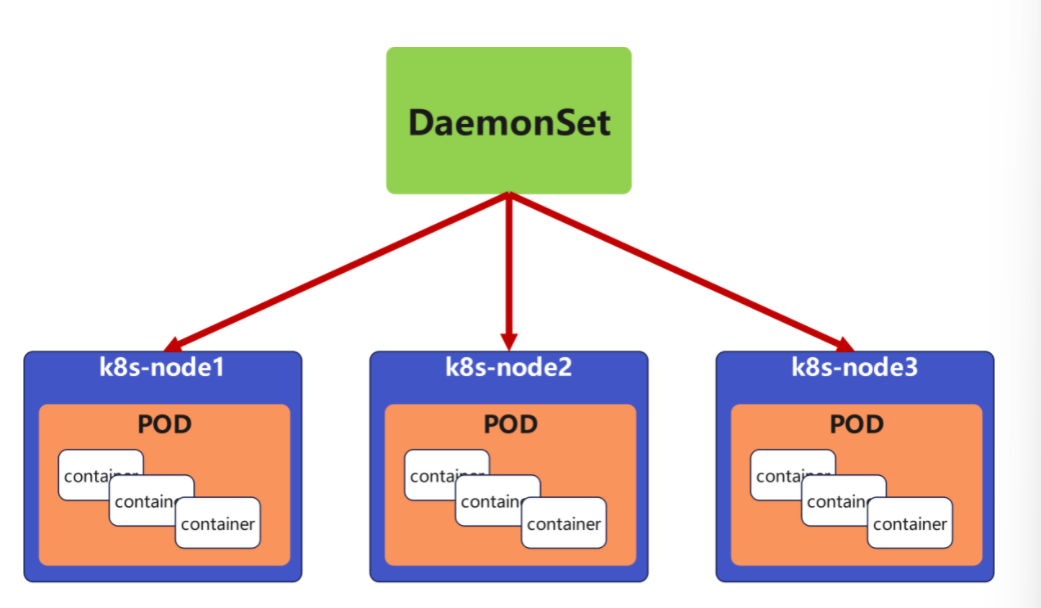
【图片位置 1:DaemonSet 节点分布示意图】
示意图内容:3 个节点 k8s-node1、k8s-node2、k8s-node3 横向排列,每个节点下方对应 1 个 Pod,每个 Pod 内部包含 3 层 container(原文档笔误修正:contaj/contai → container),直观体现 "雨露均沾每个人跑一个" 的核心特性。
DaemonSet 确保全部 (或者某些) 节点上运行一个 Pod 的副本。当有节点加入集群时,也会为他们新增一个 Pod,当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet 的典型用法:
- 在每个节点上运行集群存储 DaemonSet,例如 glusterd、ceph。
- 在每个节点上运行日志收集 DaemonSet,例如 fluentd、logstash。
- 在每个节点上运行监控 DaemonSet,例如 Prometheus Node Exporter、zabbix agent 等。
- 一个简单的用法是在所有的节点上都启动一个 DaemonSet,将被作为每种类型的 daemon 使用。
- 一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet,但具有不同的标志,并且对不同硬件类型具有不同的内存、CPU 要求。
5.2 DaemonSet 示例
原文件完整命令与代码
[root@k8s2 pod]# cat daemonset-example.ymlyaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-example
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
tolerations: #对于污点节点的容忍
- effect: NoSchedule
operator: Exists
containers:
- name: nginx
image: nginx
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
daemonset-87h6s 1/1 Running 0 47s 10.244.0.8 k8s-master <none> <none>
daemonset-n4vs4 1/1 Running 0 47s 10.244.2.38 k8s-node2 <none> <none>
daemonset-vhxmq 1/1 Running 0 47s 10.244.1.40 k8s-node1 <none> <none>
#回收
[root@k8s2 pod]# kubectl delete -f daemonset-example.yml核心代码逐行解析(Line-by-Line Breakdown)
表格
| 代码行 | 底层触发动作 |
|---|---|
apiVersion: apps/v1 |
向 kube-apiserver 声明使用apps/v1 API 组,apiserver 将请求路由到 DaemonSet 控制器的 v1 版本处理逻辑;废弃的 extensions/v1beta1 版本已在 K8s 1.16 + 移除 |
kind: DaemonSet |
告诉 apiserver 当前创建的资源类型是 DaemonSet,触发 DaemonSet 控制器的监听循环 |
metadata: name: daemonset-example |
在 etcd 中创建一个 key 为/apis/apps/v1/namespaces/default/daemonsets/daemonset-example的资源对象 |
spec: selector: matchLabels: app: nginx |
DaemonSet 控制器会持续筛选集群中所有标签为app=nginx的 Pod,作为自己的管控对象;这是 DaemonSet 的核心关联逻辑 |
template: metadata: labels: app: nginx |
定义 Pod 模板的标签,必须与 selector.matchLabels 完全一致,否则控制器无法关联 Pod,创建失败 |
tolerations: - effect: NoSchedule operator: Exists |
向 kube-scheduler 注册容忍规则:允许该 Pod 被调度到带有任意 NoSchedule 类型污点的节点上;原示例中用于让 Pod 能调度到 master 节点(默认 master 有 node-role.kubernetes.io/master:NoSchedule 污点) |
containers: - name: nginx image: nginx |
定义 Pod 内运行的容器,kubelet 会拉取 nginx 镜像并启动容器,容器名称在 Pod 内唯一 |
最容易踩的坑(Gotchas)
- selector 与 template 标签不匹配 :这是 90% 新手会犯的错误。如果两者标签不一致,
kubectl apply不会报错,但 DaemonSet 不会创建任何 Pod,且没有明显错误提示。 - tolerations 格式错误 :原示例中
tolerations是数组类型,必须加-前缀;如果漏写-,会被解析为对象,导致 master 节点永远不会调度该 Pod。 - 忘记设置资源限制 :DaemonSet 的 Pod 会运行在所有节点上,如果没有设置
resources.limits,单个 Pod 可能耗尽节点资源,导致整个集群雪崩。
企业级生产应用(Enterprise Scenario)
千万级并发场景下的典型用途
- 全节点日志采集:在所有节点上部署 Fluentd DaemonSet,采集容器和宿主机日志,统一发送到 Elasticsearch 集群。千万级并发下,每个节点每秒产生 GB 级日志,DaemonSet 的本地采集模式避免了网络带宽瓶颈。
- 节点监控:部署 Prometheus Node Exporter DaemonSet,采集节点 CPU、内存、磁盘、网络等指标,是 K8s 集群监控的基础组件。
- 分布式存储客户端:部署 Ceph RBD DaemonSet,为所有节点提供块存储客户端支持,实现 Pod 的持久化存储。
进阶优化空间
- 节点亲和性 + 污点容忍精细化调度:只在 GPU 节点上部署 GPU 监控 DaemonSet,避免资源浪费。
- 滚动更新策略配置 :设置
updateStrategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1,确保更新时每个节点最多只有一个 Pod 不可用,避免监控 / 日志采集中断。 - 资源 QoS 保障 :为 DaemonSet Pod 设置
Guaranteed级别的 QoS(requests=limits),确保在节点资源紧张时,DaemonSet Pod 不会被 kubelet 驱逐。 - 本地缓存优化:日志采集 DaemonSet 使用本地磁盘缓存,避免网络抖动导致日志丢失。
课后防宕机指南(Troubleshooting)
-
问题现象:DaemonSet 创建成功,但 master 节点没有运行 Pod
- 报错信息:
kubectl describe daemonset daemonset-example会显示0 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate - 排查思路:检查
tolerations配置是否正确,是否包含对 master 节点污点的容忍;确认 master 节点是否被标记为不可调度。
- 报错信息:
-
问题现象:DaemonSet 创建后,部分节点的 Pod 一直处于 Pending 状态
- 报错信息:
kubectl describe pod <pod-name>会显示Insufficient cpu/memory - 排查思路:检查节点剩余资源是否满足 Pod 的 requests 要求;检查是否有其他 Pod 占用了大量节点资源;调整 DaemonSet 的资源限制。
- 报错信息:
六 Job 控制器
6.1 Job 控制器功能
生活类比
Job 就像快递分拣中心的一次性分拣任务:今天有 10000 个包裹需要分拣(指定任务数),安排 2 条分拣线同时工作(并行数),每条分拣线处理完一批包裹就结束(Pod 运行一次就退出);当 10000 个包裹全部分拣完成(成功 Pod 数达到指定值),整个任务就结束,分拣线全部关停。
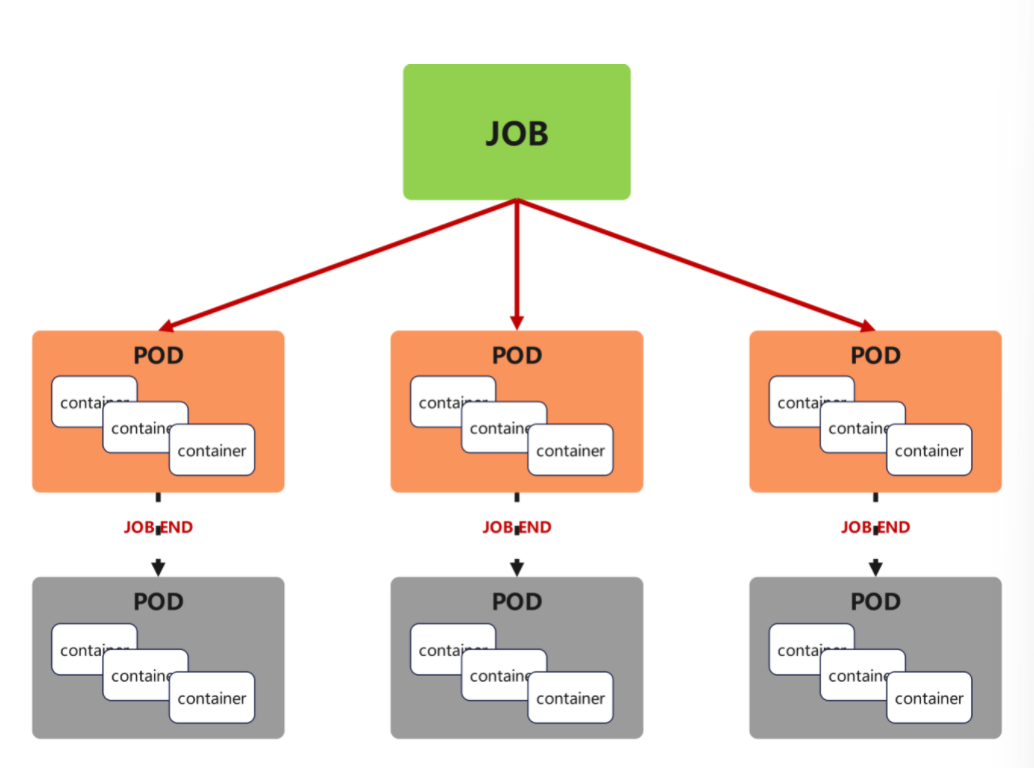
【图片位置 2:Job 控制器运行示意图】
原文档示意图内容:第一行 3 个 Pod 横向排列,每个 Pod 内部包含 3 层 container(原文档笔误修正:contaj/containg → container),下方标注 "JOB END" 表示任务完成;第二行再启动 3 个 Pod,继续完成剩余任务,直到所有任务结束。
在企业里,做一次性的任务;Job,主要用于负责批量处理 (一次要处理指定数量任务) 短暂的一次性 (每个任务仅运行一次就结束) 任务。Job 特点如下:
- 当 Job 创建的 pod 执行成功结束时,Job 将记录成功结束的 pod 数量。
- 当成功结束的 pod 达到指定的数量时,Job 将完成执行。
6.2 Job 控制器示例
原文件完整命令与代码
[root@k8s2 pod]# vim job.ymlyaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
completions: 6 # 一共完成任务数为6
parallelism: 2 # 每次并行完成2个
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"] # 计算Π的后2000位
restartPolicy: Never # 关闭后不自动重启
backoffLimit: 4 # 运行失败后尝试4重新运行
[root@k8s2 pod]# kubectl apply -f job.yml!NOTE关于重启策略设置的说明:
- 如果指定为 OnFailure,则 job 会在 pod 出现故障时重启容器,而不是创建 pod,failed 次数不变。
- 如果指定为 Never,则 job 会在 pod 出现故障时创建新的 pod,并且故障 pod 不会消失,也不会重启,failed 次数加 1。
- 如果指定为 Always 的话,就意味着一直重启。
核心代码逐行解析(Line-by-Line Breakdown)
表格
| 代码行 | 底层触发动作 |
|---|---|
apiVersion: batch/v1 |
声明使用batch/v1 API 组,apiserver 将请求路由到 Job 控制器处理;K8s 1.21 + 废弃了 batch/v1beta1 版本 |
kind: Job |
触发 Job 控制器的监听循环,在 etcd 中创建 Job 资源对象 |
spec: completions: 6 |
Job 控制器会持续统计成功结束的 Pod 数量,当数量达到 6 时,将 Job 状态标记为Completed,并停止创建新的 Pod |
spec: parallelism: 2 |
限制 Job 同时运行的 Pod 数量最多为 2;控制器会根据当前成功 Pod 数和并行数,动态创建新的 Pod |
command: ["perl", ... "print bpi(2000)"] |
覆盖容器默认的 ENTRYPOINT,容器启动后直接执行该命令,命令执行完成后容器退出,退出码为 0 表示成功 |
restartPolicy: Never |
告诉 kubelet:如果容器退出码不为 0(失败),不要重启容器;Job 控制器会检测到 Pod 失败,创建一个新的 Pod 重试 |
backoffLimit: 4 |
限制 Job 的最大重试次数为 4 次;如果失败次数达到 4 次,Job 状态会被标记为Failed,并停止重试 |
最容易踩的坑(Gotchas)
- restartPolicy 设置错误 :如果设置为
Always,Pod 会无限重启,Job 永远不会完成;这是 Job 最常见的致命错误。 - completions 与 parallelism 顺序写反 :很多新手会把
completions(总任务数)和parallelism(并行数)写反,导致任务要么运行过慢,要么创建过多 Pod 耗尽集群资源。 - backoffLimit 理解错误 :
backoffLimit是总重试次数,不是每个 Pod 的重试次数;如果设置为 0,任务失败一次就会直接标记为 Failed。
企业级生产应用(Enterprise Scenario)
千万级并发场景下的典型用途
- 离线数据处理:每天凌晨批量处理前一天的用户行为数据,生成报表。千万级用户下,每天产生 TB 级数据,使用 Job 并行处理可以将处理时间从小时级缩短到分钟级。
- 数据库迁移:一次性迁移千万级数据从旧库到新库,使用多个 Job 并行处理不同分片的数据,提高迁移效率。
- 批量任务执行:发送千万级营销短信、生成用户账单、清理过期数据等一次性批量任务。
进阶优化空间
- 分片处理:将大任务拆分为多个小分片,每个 Pod 处理一个分片,避免单个 Pod 处理时间过长导致失败重试成本过高。
- 失败重试指数退避 :设置
backoffLimit和activeDeadlineSeconds,避免失败任务无限重试占用资源;使用指数退避算法减少重试频率。 - 资源动态调整:使用 K8s 的 Vertical Pod Autoscaler(VPA)自动调整 Job Pod 的资源请求,提高资源利用率。
- 任务队列集成:将 Job 与 RabbitMQ/Kafka 集成,实现任务的动态分发和负载均衡,支持百万级任务的并发处理。
课后防宕机指南(Troubleshooting)
-
问题现象:Job 一直处于 Running 状态,永远不会完成
- 报错信息:
kubectl describe job pi会显示Pods Statuses: 2 Running / 0 Succeeded / 0 Failed,且持续很长时间 - 排查思路:检查 Pod 的
restartPolicy是否设置为Always;检查容器内的命令是否会无限循环;查看 Pod 日志确认命令是否正常执行。
- 报错信息:
-
问题现象:Job 快速失败,状态变为 Failed
- 报错信息:
kubectl describe job pi会显示BackoffLimitExceeded: Job has reached the specified backoff limit - 排查思路:查看失败 Pod 的日志,确认命令执行失败的原因;检查镜像是否存在、是否有权限拉取;调整
backoffLimit增加重试次数。
- 报错信息:
七 CronJob 控制器
7.1 CronJob 控制器功能
生活类比
CronJob 就像小区的垃圾清运车:每天早上 6 点和晚上 8 点(固定时间)准时到达小区(触发 Job),每次到达后完成一次垃圾清运任务(运行 Job 创建 Pod 处理任务),清运完成后离开(Job 完成,Pod 销毁);如果某次清运车坏了(Job 失败),会根据配置决定是否重新清运。
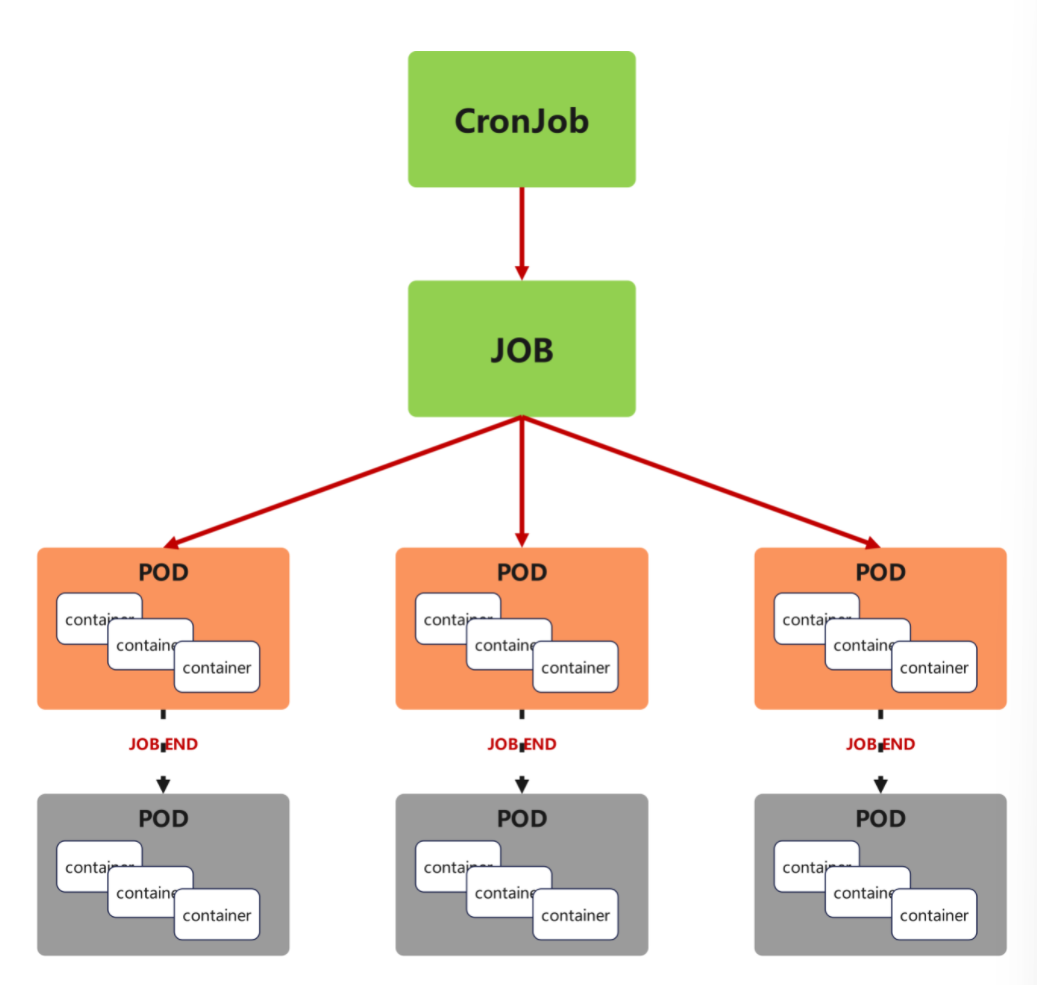
【图片位置 3:CronJob 控制器调度示意图】
原文档示意图内容:CronJob 在顶部,下方周期性生成多个 Job,每个 Job 对应 3 个 Pod,每个 Pod 内部包含 3 层 container(原文档笔误修正:conta/contaj → container),Job 完成后标注 "JOB END",体现周期性调度的特点。
定期在集群中运行指定的动作。
- Cron Job 创建基于时间调度的 Jobs。
- CronJob 控制器以 Job 控制器资源为其管控对象,并借助它管理 pod 资源对象。C
- ronJob 可以以类似于 Linux 操作系统的周期性任务作业计划的方式控制其运行时间点及重复运行的方式。
- CronJob 可以在特定的时间点 (反复的) 去运行 job 任务。
7.2 CronJob 控制器 示例
原文件完整命令与代码
[root@k8s2 pod]# vim cronjob.ymlyaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
[root@k8s2 pod]# kubectl apply -f cronjob.yml核心代码逐行解析(Line-by-Line Breakdown)
表格
| 代码行 | 底层触发动作 |
|---|---|
apiVersion: batch/v1 |
声明使用batch/v1 API 组,apiserver 将请求路由到 CronJob 控制器处理;K8s 1.21 + 废弃了 batch/v1beta1 版本 |
kind: CronJob |
触发 CronJob 控制器的监听循环,在 etcd 中创建 CronJob 资源对象 |
spec: schedule: "* * * * *" |
CronJob 控制器会每分钟解析一次该 Cron 表达式,当时间匹配时,创建一个新的 Job 资源;Cron 表达式格式与 Linux crontab 完全一致:分 时 日 月 周 |
jobTemplate: |
定义 CronJob 创建 Job 时使用的模板,所有 Job 的配置都继承自该模板 |
imagePullPolicy: IfNotPresent |
告诉 kubelet:如果本地已经存在 busybox 镜像,就不要从镜像仓库拉取;只有本地不存在时才拉取,节省网络带宽 |
command: ["/bin/sh", "-c", "..."] |
容器启动后执行 shell 命令,打印当前时间和欢迎信息,命令执行完成后容器退出 |
restartPolicy: OnFailure |
告诉 kubelet:如果容器执行失败(退出码不为 0),重启容器;只有当容器执行成功(退出码为 0)时,才标记 Pod 为成功 |
最容易踩的坑(Gotchas)
- Cron 表达式时区问题 :CronJob 默认使用 UTC 时区,而不是集群节点的本地时区;如果需要使用北京时间,必须在 CronJob 中设置
timeZone: Asia/Shanghai(K8s 1.24 + 支持)。 - 并发策略设置错误 :默认并发策略是
Allow,即允许同时运行多个 Job;如果任务不能并发执行,必须设置concurrencyPolicy: Forbid,否则会导致数据不一致。 - 历史任务保留过多 :默认 CronJob 会保留 3 个成功的 Job 和 1 个失败的 Job;如果不设置
successfulJobsHistoryLimit和failedJobsHistoryLimit,会导致 etcd 中积累大量历史 Job,影响集群性能。
企业级生产应用(Enterprise Scenario)
千万级并发场景下的典型用途
- 定时数据备份:每天凌晨 2 点自动备份数据库和分布式存储数据,确保数据安全。
- 定时报表生成:每天、每周、每月自动生成业务报表,发送给相关人员。
- 定时资源清理:每天凌晨清理过期的日志、临时文件、无用的 Pod 和镜像,释放集群资源。
- 定时任务调度:定时触发 CI/CD 流水线、定时发送通知、定时更新配置等。
进阶优化空间
- 时区统一配置 :所有 CronJob 统一使用
timeZone: Asia/Shanghai,避免时区混乱导致任务执行时间错误。 - 并发策略与超时控制 :设置
concurrencyPolicy: Forbid和activeDeadlineSeconds,避免任务重叠和长时间运行。 - 历史任务清理 :设置
successfulJobsHistoryLimit: 1和failedJobsHistoryLimit: 1,只保留最近一次的成功和失败任务,减少 etcd 压力。 - 监控与告警:为 CronJob 添加 Prometheus 监控,当任务失败或执行时间过长时,发送告警通知。
- 高可用调度:使用多个 CronJob 控制器实例,避免单点故障;使用分布式锁确保任务只执行一次。
课后防宕机指南(Troubleshooting)
-
问题现象:CronJob 到了指定时间没有创建 Job
- 报错信息:
kubectl describe cronjob hello没有显示任何新创建的 Job - 排查思路:检查 Cron 表达式是否正确;检查 CronJob 控制器是否正常运行;确认集群时间是否正确;如果是 K8s 1.24 以下版本,检查是否设置了正确的时区。
- 报错信息:
-
问题现象:CronJob 同时创建了多个 Job,导致数据重复处理
- 报错信息:
kubectl get jobs会显示多个同一时间创建的 hello-xxx Job - 排查思路:检查
concurrencyPolicy是否设置为Allow;检查上一个 Job 是否还在运行;设置concurrencyPolicy: Forbid禁止并发执行。
- 报错信息: