
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》 《MySQL数据库学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

在学习后端开发、数据管理或系统架构的过程中,数据库几乎是绕不开的一项核心技术.而 MySQL 作为目前应用非常广泛的关系型数据库之一,凭借开源、稳定、易上手、生态成熟等特点,被大量用于网站开发、业务系统、数据存储以及各类企业级应用中.对于初学者来说,刚接触 MySQL 时可能会遇到很多概念:数据库、数据表、字段、主键、SQL 语句、增删改查、约束、索引等.这些内容看似零散,但它们共同构成了 MySQL 数据库学习的基础框架.只有先理解这些基础概念,才能更顺利地掌握后续的数据查询优化、事务处理、表结构设计以及项目中的数据库应用.本文将围绕 MySQL 数据库基础 展开学习,从数据库的基本概念入手,逐步了解 MySQL 的作用、特点、常见操作以及基础 SQL 语句的使用,帮助读者建立对 MySQL 的整体认识,为后续深入学习数据库开发打下良好的基础.废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!

目录
- [1.MySQL在Ubuntu 22.04环境下安装](#1.MySQL在Ubuntu 22.04环境下安装)
- 2.数据库基础(重点)
1.MySQL在Ubuntu 22.04环境下安装
Ubuntu官方文档当前仍推荐直接安装mysql-server,安装后服务通常会自动启动;Ubuntu 22.04 可以直接用APT安装MySQL8.0:
bash
sudo apt update
bash
sudo apt install mysql-server -y
从图中看,mysql-server已经安装完成了!接下来按这几步检查和初始化即可:
1.检查 MySQL 服务状态
bash
sudo systemctl status mysql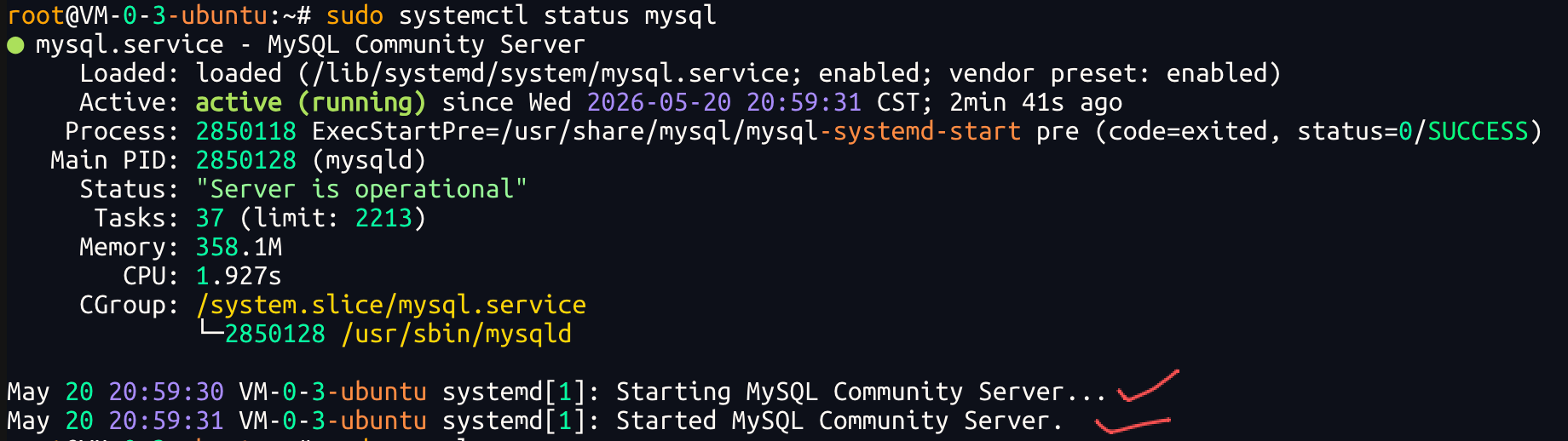
看到打勾这样的显示时,说明已经启动成功.!
2.进入 MySQL
Ubuntu 22.04 默认 root 通常用 socket 登录,所以直接执行:
bash
sudo mysql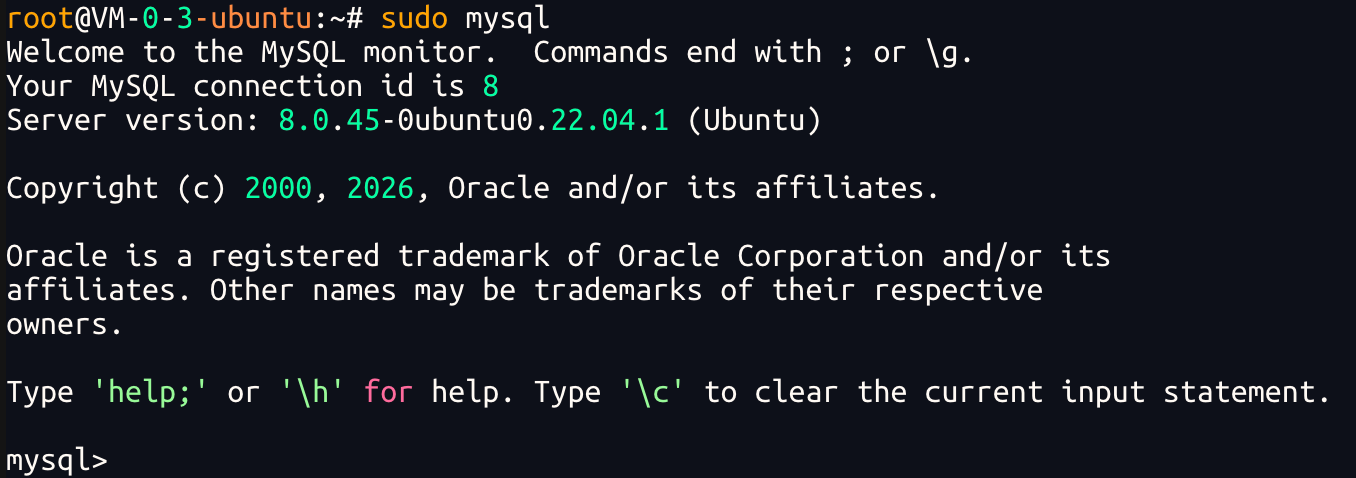
进入后你会看到类似上面这样的信息
3.做安全初始化
bash
sudo mysql_secure_installation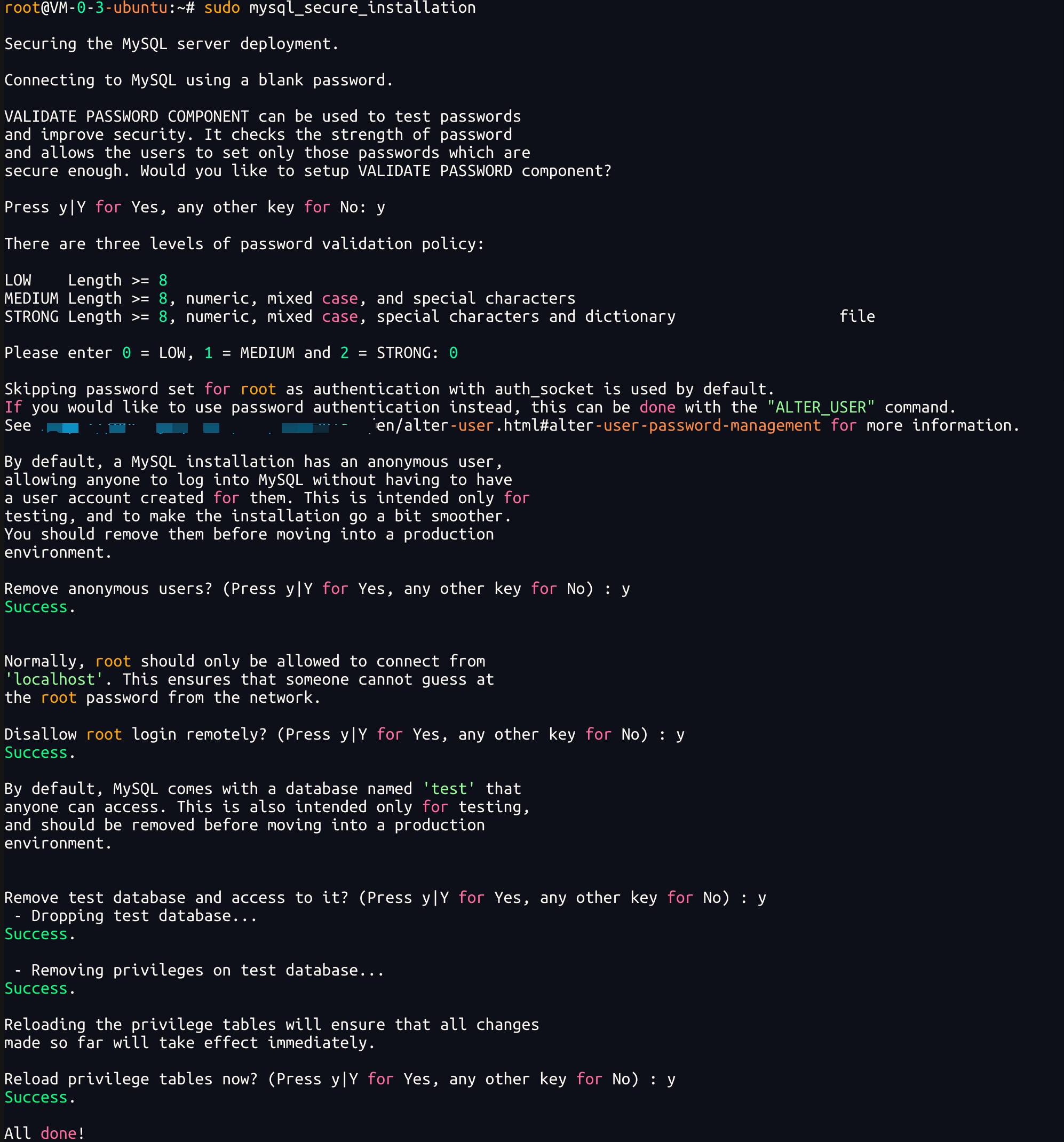
按照这样的方法来,就初始化好啦!
4.创建数据库和用户
注意:初期练习,mysql不进⾏⽤⼾管理,全部使⽤root进⾏,尽快适应mysql语句,后⾯学了⽤⼾管
理,在考虑新建普通⽤⼾.但是小编可以演示给大家看一下!
进入 MySQL 后执行:
sql
CREATE DATABASE appdb DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;//意思是创建一个数据库,名字叫appdb.utf8mb4表示数据库使用完整的UTF-8 编码,支持中文、emoji 等字符.utf8mb4_unicode_ci表示排序和比较规则.ci 是 case-insensitive,意思是不区分大小写.
CREATE USER 'appuser'@'localhost' IDENTIFIED BY 'StrongPassword_123!';//意思是创建一个 MySQL 用户:用户名:appuser 允许登录来源:localhost 密码:StrongPassword_123! localhost 表示这个用户只能从本机连接 MySQL,适合本机项目开发。
GRANT ALL PRIVILEGES ON appdb.* TO 'appuser'@'localhost';//意思是把 appdb 这个数据库的所有权限都给 appuser. appdb.*表示 appdb 数据库里的所有表。也就是说,appuser 可以对 appdb 执行建表、查询、插入、修改、删除等操作。
FLUSH PRIVILEGES;//意思是刷新权限,让刚才的用户和权限设置立即生效。退出:
sql
exit测试新用户能否登录:
bash
mysql -u appuser -p输入密码:
bash
StrongPassword_123!如果登录成功,可以查看数据库:
sql
SHOW DATABASES;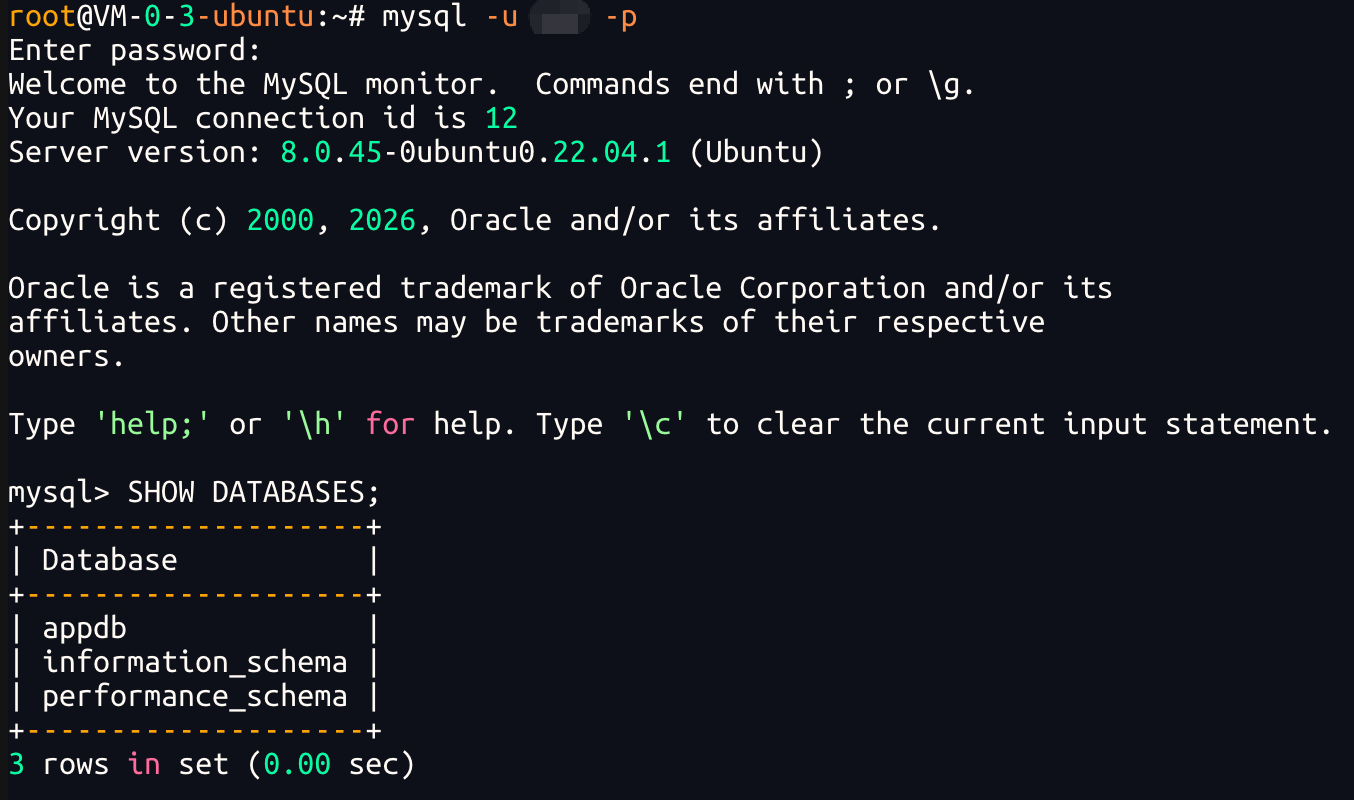
如果你只是本机项目连接 MySQL,到这里就可以用了.连接信息是:
host: localhost
port: 3306
database: appdb
username: appuser
password: StrongPassword_123!这样子MySQL就安装好啦!
📌温馨提示:
由于小编的是Ubuntu系统,所以只展示Ubuntu系统环境下的安装,关于Centos环境安装下的安装我就不展示了,大家可以请教AI进行配置.
2.数据库基础(重点)
2.1什么是数据库?
存储数据用文件就可以了,为什么还要弄个数据库?
文件保存数据有以下几个缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
数据库存储介质:
- 磁盘
- 内存
为了解决上述问题,专家们设计出更加利于管理数据的东西------数据库,它能更有效的管理数据.数据库的水平是衡量一个程序员水平的重要指标.
数据库就是用来有组织地存储、管理和查询数据的系统.
可以把它想象成一个"电子表格仓库":
- 数据:比如用户信息、订单、商品、成绩、聊天记录等.
- 表:数据通常按表格存放,例如"用户表""订单表".
- 查询:可以快速查找数据,比如"找出所有北京用户".
- 管理:可以新增、修改、删除数据.
- 安全与稳定:控制谁能访问数据,并保证数据不容易丢失.
举个例子,电商网站可能有数据库来存:
| 用户表 | 订单表 | 商品表 |
|---|---|---|
| 用户名、手机号、地址 | 订单号、购买时间、金额 | 商品名、价格、库存 |
一句话:数据库是应用程序背后专门负责存放和管理数据的地方.
2.1主流数据库
1.关系型数据库 SQL
这类最常见,数据像 Excel 表一样按"表、行、列"组织,适合业务系统、订单、用户、财务等结构化数据.
| 数据库 | 特点 |
|---|---|
| MySQL | 使用广泛,互联网项目常见 |
| PostgreSQL | 功能强、标准化好,适合复杂查询 |
| Oracle Database | 企业级数据库,金融、电信常见 |
| SQL Server | 微软生态常用 |
| SQLite | 轻量级,本地应用、移动端常见 |
| MariaDB | MySQL 的开源分支 |
2.非关系型数据库 NoSQL
这类不一定用表格结构,适合海量数据、高并发、灵活数据结构.
| 数据库 | 类型 | 特点 |
|---|---|---|
| MongoDB | 文档数据库 | 存 JSON 类数据,结构灵活 |
| Redis | 键值数据库 | 速度极快,常用于缓存 |
| Cassandra | 列式数据库 | 适合大规模分布式数据 |
| DynamoDB | 键值/文档数据库 | AWS 云服务数据库 |
| Neo4j | 图数据库 | 适合关系网络、推荐系统 |
3.数据仓库 / 分析型数据库
主要用于数据分析、报表、BI、大数据查询.
| 数据库 | 特点 |
|---|---|
| Snowflake | 云数据仓库,企业数据分析常见 |
| BigQuery | Google 云分析数据库 |
| Redshift | AWS 数据仓库 |
| ClickHouse | 高性能列式分析数据库 |
| DuckDB | 本地分析型数据库,适合数据科学 |
4.向量数据库
近几年 AI 应用常用,用来存储和检索向量,比如语义搜索、RAG、推荐系统.
| 数据库 | 特点 |
|---|---|
| Pinecone | 托管向量数据库 |
| Milvus | 开源向量数据库 |
| Weaviate | 向量搜索 + 语义检索 |
| FAISS | Meta 开源向量检索库 |
| pgvector | PostgreSQL 的向量扩展 |
2.3基本使用
2.3.1MySQL安装教程指导
CentOS 6.5下编译安装MySQL 5.6.14
CentOS 7 通过 yum 安装 MariaDB
Windows下通过MySQL Installer安装MySQL服务
大家可以看看上面这三个链接里面你内容,对于安装有一定的帮助.
2.3.2连接服务器
输入:
bash
mysql -h 127.0.0.1 -P 3306 -u root(如果你是root用户就用root,如果你是个人项目开发,就写你自己创建的名字) -p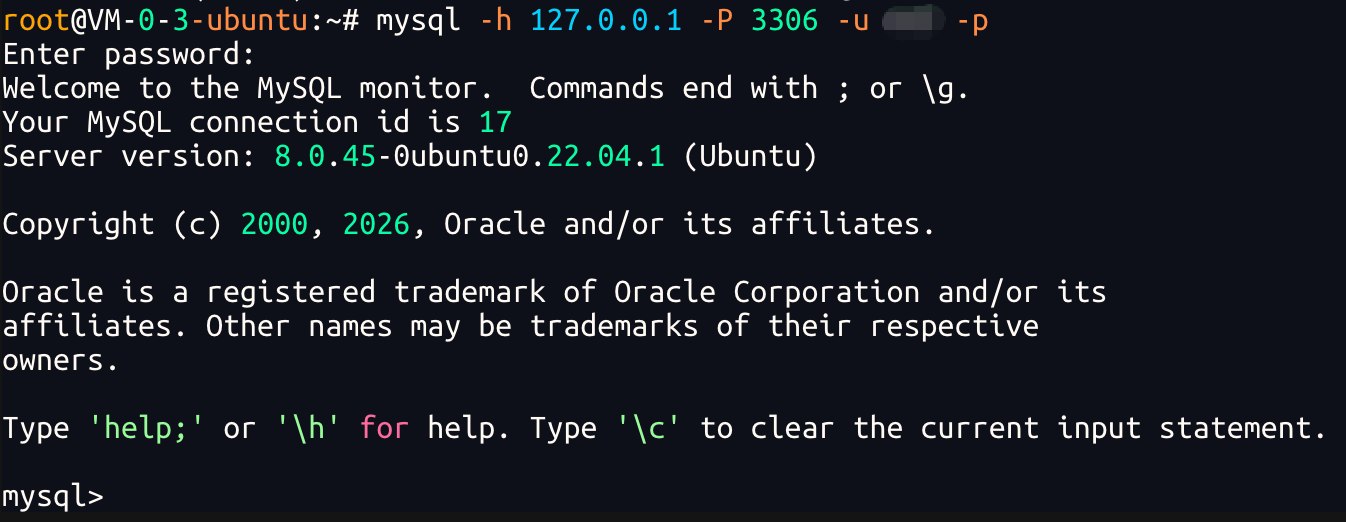
📌注意:
如果没有写 -h 127.0.0.1 默认是连接本地.
如果没有写 -P 3306 默认是连接3306端口号.
2.3.3服务器管理
执行 win+r 输入 services.msc 打开服务管理器.
通过下图左侧停止,暂停,重启动按钮进行服务管理.
2.3.4服务器、数据库和表之间关系
所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库.为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据.数据库服务器、数据库和表的关系如下:
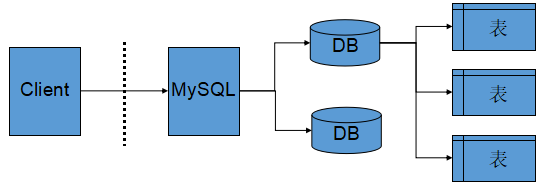
这图是在说明 Client、MySQL、数据库 DB、表之间的关系 .
从左到右看:
1.Client:客户端
左边的 Client 指的是客户端,也就是发起请求的一方.
例如:
- Java / Python / Go 程序
- 后端服务
- 命令行工具
- 数据库管理工具,比如 Navicat、DBeaver
- 网站应用
客户端不会直接操作磁盘上的数据,而是向 MySQL 发送请求.
2.虚线:网络 / 连接边界
Client 和 MySQL 中间的虚线表示它们之间通常通过网络连接.
比如客户端发送 SQL:
sql
SELECT * FROM users;这个请求会通过 TCP 连接发送给 MySQL 服务.
3.MySQL:数据库管理系统
中间的 MySQL 不是某一个具体数据库,而是一个 数据库管理系统 DBMS .
它负责:
- 接收客户端请求
- 解析 SQL
- 检查权限
- 找到对应数据库
- 读取或修改表中的数据
- 把结果返回给客户端
所以 MySQL 更像是"管家"或"服务端程序".
4.DB:数据库
右边两个圆柱形的 DB 表示两个数据库.
在 MySQL 里,可以创建多个数据库,例如:
sql
CREATE DATABASE shop;
CREATE DATABASE school;一个 MySQL 服务里面可以管理很多个数据库.
比如:
text
MySQL
├── shop 数据库
├── school 数据库
└── blog 数据库5.表:Table
最右边的"表"表示数据库里的表.
一个数据库里面可以有很多张表,例如电商系统中的 shop 数据库可能有:
text
shop 数据库
├── user 表
├── product 表
├── order 表
└── payment 表表是真正存放业务数据的地方.
例如 user 表:
| id | name | age |
|---|---|---|
| 1 | 张三 | 20 |
| 2 | 李四 | 25 |
可以理解成:
text
客户端 Client
↓ 发送 SQL 请求
MySQL 服务
↓ 管理多个数据库
数据库 DB
↓ 包含多张表
表 Table
↓ 存储具体数据
行 / 列一句话总结:
Client 通过网络连接 MySQL,MySQL 管理多个数据库,每个数据库里面有多张表,真正的数据存储在表中.
2.3.5使用案例(向数据库中建表并插入数据)
创建数据库:
sql
create database helloworld;使用数据库:
sql
use helloworld;创建数据库表:
sql
create table student(
id int,
name varchar(32),
gender varchar(2)
);表中插入数据:
sql
insert into student (id, name, gender) values (1, '张三', '男');
insert into student (id, name, gender) values (2, '李四', '女');
insert into student (id, name, gender) values (3, '王五', '男');查询表中的数据:
sql
select * from student;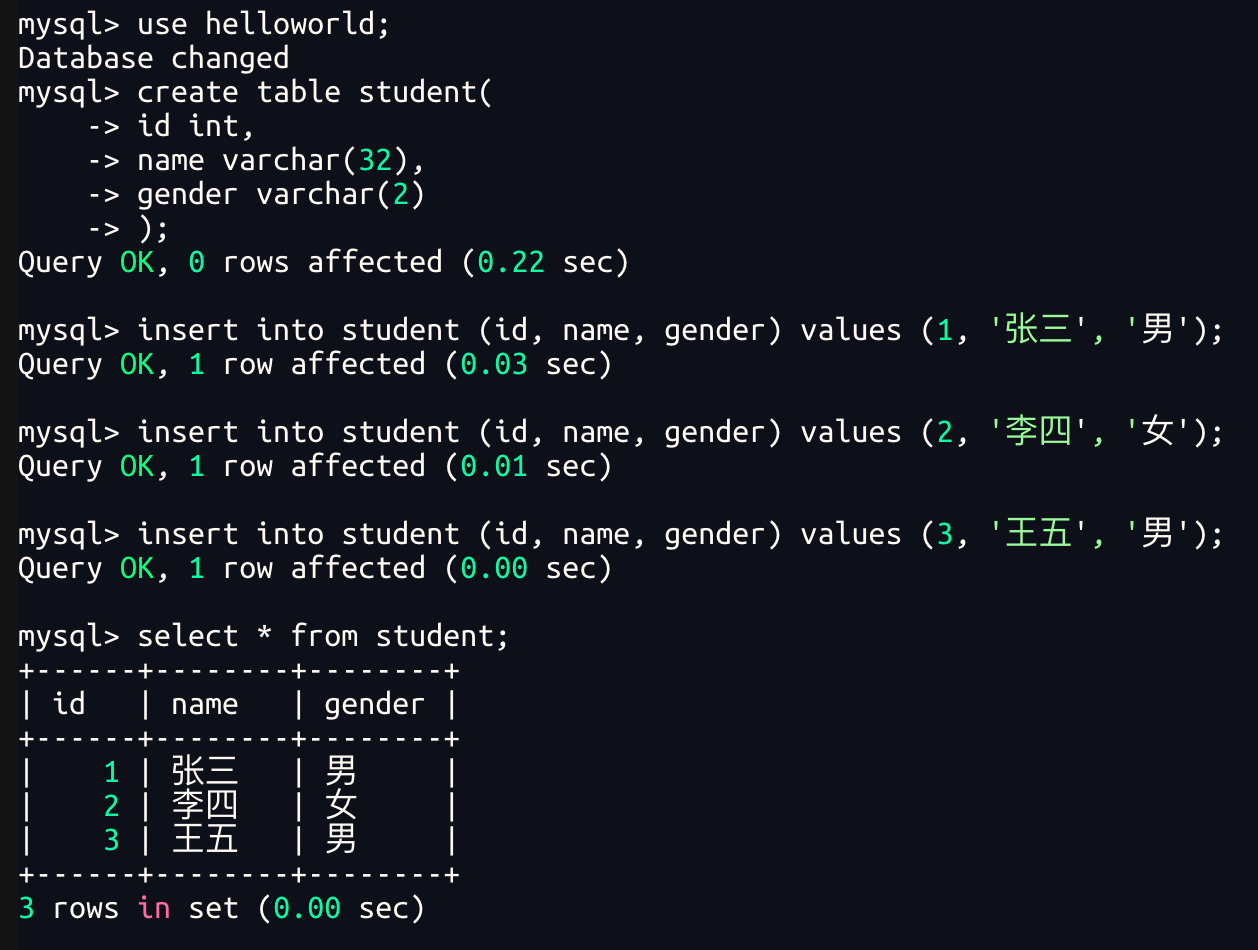
2.4MySQL架构
MySQL 是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如 Unix/Linux、Windows、Mac 和 Solaris.各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性.
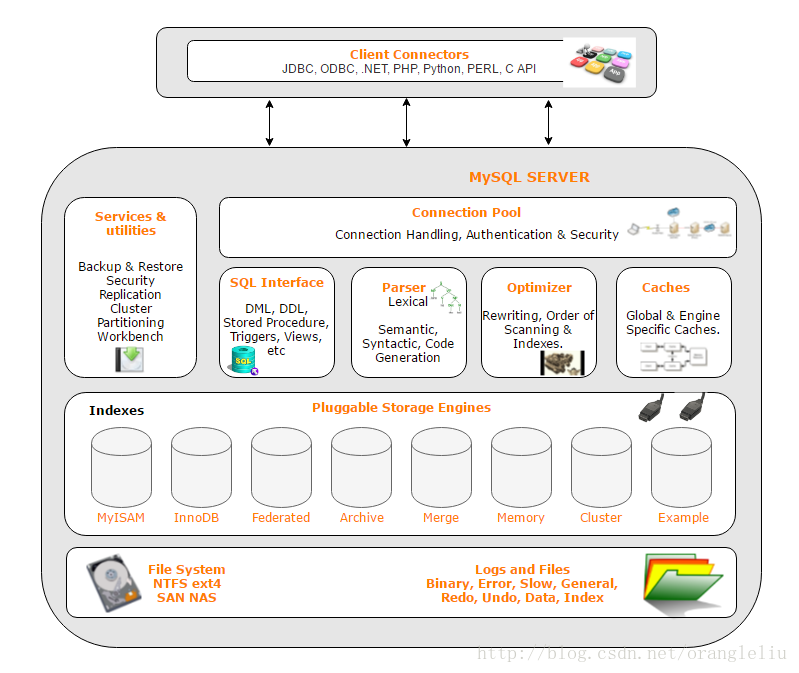
这图展示的是 MySQL Server 的整体架构,可以理解为:客户端发起 SQL 请求,MySQL Server 负责解析、优化、执行,最后通过不同的存储引擎去读写底层文件.
1.Client Connectors:客户端连接器
最上面是各种客户端连接方式,例如:
JDBC、ODBC、.NET、PHP、Python、Perl、C API 等.
也就是说,不同语言或工具都可以通过这些连接器连接 MySQL,然后发送 SQL 语句.
2.MySQL Server:MySQL 服务层
中间的大框是 MySQL Server 的核心部分,主要负责 SQL 的处理逻辑.
Connection Pool:连接池
负责处理客户端连接,包括:
连接管理、身份认证、安全控制等.
当客户端连接 MySQL 时,首先会经过这一层.
3.SQL Interface:SQL 接口
这一层接收客户端传来的 SQL 语句,例如:
SELECT、INSERT、UPDATE、DELETE、CREATE TABLE、存储过程、触发器、视图等.
它是 SQL 请求进入 MySQL 内部处理流程的入口.
4.Parser:解析器
解析器会检查 SQL 语句是否合法,并把 SQL 转换成 MySQL 能理解的内部结构.
例如你执行:
sql
SELECT name FROM user WHERE id = 1;Parser 会判断语法是否正确,并识别出:
表名是 user,字段是 name,条件是 id = 1.
5.Optimizer:优化器
优化器负责决定 SQL 怎么执行效率最高.
比如:
同一条查询语句,可能有多种执行方式.优化器会决定是否使用索引、表的扫描顺序、连接顺序等.
例如:
sql
SELECT * FROM user WHERE id = 1;如果 id 上有索引,优化器可能会选择走索引,而不是全表扫描.
6.Caches:缓存
缓存层用于保存一些常用信息,减少重复计算或重复读取.
图中提到的是全局缓存和存储引擎相关缓存.
不过需要注意:早期 MySQL 有 Query Cache,但在 MySQL 8.0 中已经被移除了.
7.Pluggable Storage Engines:可插拔存储引擎
这是 MySQL 的一个重要特点.
MySQL 的 Server 层和存储层是分离的,不同表可以使用不同存储引擎,例如:
- InnoDB:最常用,支持事务、行级锁、外键.
- MyISAM:老式引擎,不支持事务.
- Memory:数据存储在内存中,速度快但断电丢失.
- Archive:适合归档大量历史数据.
- Federated:可以访问远程 MySQL 表.
- Merge:可以把多个 MyISAM 表合并使用.
现在实际生产环境中,最常用的是 InnoDB.
8.Indexes:索引
图中索引放在存储引擎上方,表示索引和数据的具体组织方式由存储引擎负责.
例如 InnoDB 使用 B+ 树索引,并且主键索引和数据是聚簇存储的.
索引的作用是提高查询速度,避免每次都扫描整张表.
9.File System / Logs and Files:文件系统、日志和数据文件
最底层是操作系统文件系统和 MySQL 的各种文件.
包括:
- 数据文件
- 索引文件
- 二进制日志 Binlog
- 错误日志 Error Log
- 慢查询日志 Slow Log
- Redo Log
- Undo Log
这些文件最终存储在磁盘、SAN、NAS 等存储设备上.
10.总体流程
一条 SQL 的执行流程大致是:
text
客户端发送 SQL
↓
连接池处理连接和权限
↓
SQL 接口接收语句
↓
解析器检查语法
↓
优化器生成执行计划
↓
调用存储引擎
↓
通过索引和数据文件读写磁盘
↓
返回结果给客户端MySQL Server 负责 SQL 的解析、优化和调度;存储引擎负责真正的数据存取;底层文件系统负责持久化保存数据和日志.
2.5SQL分类
SQL通常按功能分为 5 类:
| 分类 | 全称 | 作用 | 常见语句 |
|---|---|---|---|
| DDL | Data Definition Language,数据定义语言 | 定义或修改数据库对象 | CREATE、ALTER、DROP、TRUNCATE |
| DML | Data Manipulation Language,数据操作语言 | 增删改表中的数据 | INSERT、UPDATE、DELETE |
| DQL | Data Query Language,数据查询语言 | 查询数据 | SELECT |
| DCL | Data Control Language,数据控制语言 | 权限控制 | GRANT、REVOKE |
| TCL | Transaction Control Language,事务控制语言 | 管理事务 | COMMIT、ROLLBACK、SAVEPOINT |
简单记忆:
text
DDL:建表、改表、删表
DML:增、删、改数据
DQL:查数据
DCL:管权限
TCL:管事务例如:
sql
-- DDL:创建表
CREATE TABLE user (
id INT,
name VARCHAR(20)
);
-- DML:插入数据
INSERT INTO user VALUES (1, 'Tom');
-- DQL:查询数据
SELECT * FROM user;
-- DCL:授权
GRANT SELECT ON test.user TO 'jack'@'localhost';
-- TCL:提交事务
COMMIT;2.6存储引擎
MySQL 的存储引擎 可以理解为:真正负责数据存储、读取、索引、事务、锁机制的模块.MySQL Server 层负责 SQL 解析、优化、权限检查等;而数据最终怎么存、怎么查、是否支持事务、是否支持外键,主要由存储引擎决定.
2.6.1什么是存储引擎?
在 MySQL 中,表的数据并不是由 MySQL Server 层直接管理的,而是交给不同的存储引擎处理.
例如创建表时可以指定存储引擎:
sql
CREATE TABLE user (
id INT PRIMARY KEY,
name VARCHAR(20)
) ENGINE = InnoDB;这里的 ENGINE = InnoDB 就表示这张表使用 InnoDB 存储引擎.
查看 MySQL 支持哪些存储引擎:
sql
SHOW ENGINES;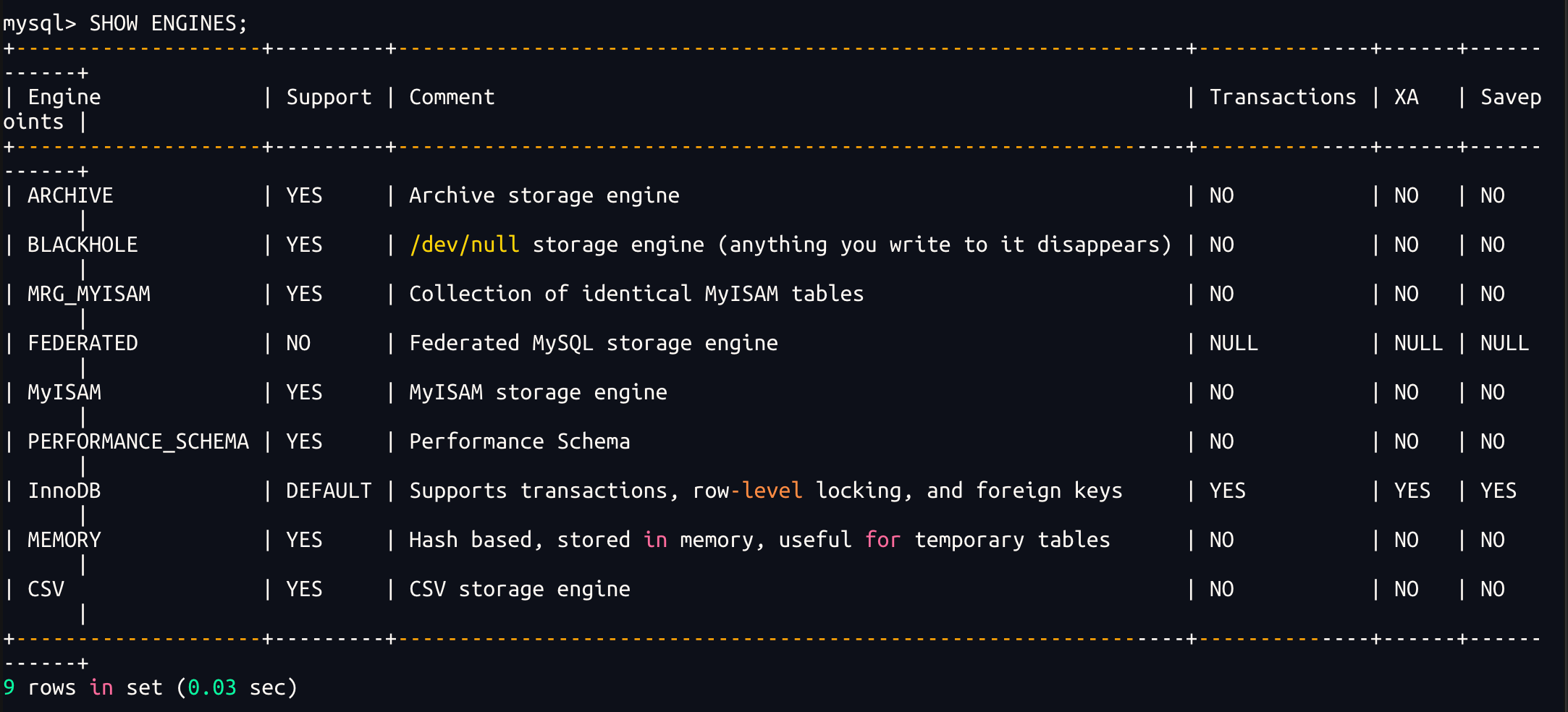
2.6.2常见存储引擎
1.InnoDB
InnoDB 是 MySQL 默认且最常用的存储引擎.
它的特点是:
- 支持事务
- 支持行级锁
- 支持外键
- 支持崩溃恢复
- 支持 MVCC
- 并发性能好
适合大多数业务场景,例如订单、用户、支付、库存等.
示例:
sql
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
amount DECIMAL(10,2)
) ENGINE = InnoDB;InnoDB 的一个重要特点是:数据和主键索引存储在一起 ,这种结构叫做聚簇索引.
2.MyISAM
MyISAM 是 MySQL 早期常用的存储引擎.
它的特点是:
- 不支持事务
- 不支持外键
- 使用表级锁
- 查询速度较快
- 崩溃恢复能力较弱
适合读多写少、对事务要求不高的场景.
例如一些历史数据、日志查询类数据,以前可能会使用 MyISAM.
sql
CREATE TABLE article (
id INT PRIMARY KEY,
title VARCHAR(100)
) ENGINE = MyISAM;不过现在实际开发中,MyISAM 使用已经比较少了.
3.Memory
Memory 存储引擎把数据存储在内存中.
特点是:
- 速度快
- 数据存储在内存
- 数据库重启后数据会丢失
- 适合临时数据
- 默认使用表级锁
示例:
sql
CREATE TABLE temp_data (
id INT,
name VARCHAR(20)
) ENGINE = Memory;它适合临时缓存、临时计算结果等场景,但不适合保存重要数据.
4.Archive
Archive 存储引擎适合归档数据.
特点是:
- 适合大量插入
- 压缩存储
- 占用空间小
- 查询能力相对弱
- 通常不适合频繁更新和删除
适合保存历史日志、审计记录等.
sql
CREATE TABLE log_archive (
id INT,
content TEXT,
create_time DATETIME
) ENGINE = Archive;5.CSV
CSV 存储引擎会把数据保存成 CSV 文件.
特点是:
- 数据以文本 CSV 格式存储
- 方便和其他系统交换数据
- 不支持索引
- 性能较弱
示例:
sql
CREATE TABLE csv_table (
id INT NOT NULL,
name VARCHAR(20) NOT NULL
) ENGINE = CSV;实际业务系统中很少作为核心存储使用.
6.Federated
Federated 存储引擎可以访问远程 MySQL 服务器上的表.
特点是:
- 本地表不真正保存数据
- 数据实际存储在远程 MySQL
- 可以用于跨服务器访问数据
不过它对网络依赖较强,性能和稳定性要谨慎考虑.
7.InnoDB 和 MyISAM 对比
| 对比项 | InnoDB | MyISAM |
|---|---|---|
| 是否支持事务 | 支持 | 不支持 |
| 是否支持外键 | 支持 | 不支持 |
| 锁粒度 | 行级锁 | 表级锁 |
| 崩溃恢复 | 较强 | 较弱 |
| 并发能力 | 较好 | 较差 |
| 主键索引 | 聚簇索引 | 非聚簇索引 |
| 适用场景 | 大多数业务系统 | 读多写少、非事务场景 |
现在一般建议:
text
默认使用 InnoDB。除非有非常特殊的需求,否则不建议优先选择 MyISAM.
2.6.3存储引擎主要影响什么?
存储引擎会影响这些方面:
1.是否支持事务
例如 InnoDB 支持:
sql
START TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;
COMMIT;如果中途失败,可以:
sql
ROLLBACK;MyISAM 不支持事务,所以不能保证这种操作的原子性.
2.锁机制
InnoDB 支持行级锁 ,只锁住被操作的行.
MyISAM 使用表级锁 ,写入时可能锁住整张表.
所以在高并发写入场景下,InnoDB 更合适.
3.索引结构
InnoDB 的主键索引是聚簇索引,数据和主键索引放在一起.
MyISAM 的索引和数据是分开的.
这会影响查询性能、主键设计和二级索引查询方式.
4.数据安全和恢复能力
InnoDB 有 redo log、undo log 等机制,崩溃恢复能力强.
MyISAM 如果异常宕机,表损坏的概率更高.
2.6.4存储引擎对比
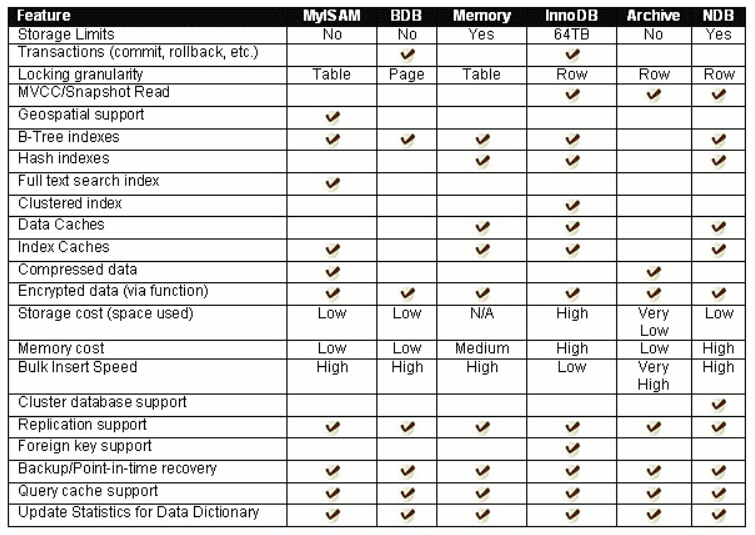 这图是在对比 MySQL 不同存储引擎的功能特性 ,横向是存储引擎,纵向是功能项.
这图是在对比 MySQL 不同存储引擎的功能特性 ,横向是存储引擎,纵向是功能项.
主要对比的存储引擎有:
text
MyISAM、BDB、Memory、InnoDB、Archive、NDB其中现在最重要、最常用的是 InnoDB.
1.Storage Limits:存储限制
表示该存储引擎能支持的数据存储容量.
图中可以看到:
- InnoDB:支持较大容量,图中写的是 64TB
- Memory:数据在内存中,受内存大小限制
- Archive:适合大量归档数据
- MyISAM:早期引擎,容量和可靠性不如 InnoDB
2.Transactions:事务支持
事务指的是 commit、rollback 等操作.
图中:
- InnoDB 支持事务
- BDB 支持事务
- MyISAM 不支持事务
- Memory 不支持事务
- Archive 不支持事务
- NDB 支持事务
所以如果业务需要事务,例如转账、订单、库存扣减,一般选 InnoDB .
例如:
sql
START TRANSACTION;
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;
COMMIT;如果中途失败,可以使用:
sql
ROLLBACK;这种能力主要依赖事务型存储引擎,比如 InnoDB.
3.Locking granularity:锁粒度
锁粒度表示修改数据时锁定的范围.
图中显示:
| 存储引擎 | 锁粒度 |
|---|---|
| MyISAM | 表级锁 |
| BDB | 页级锁 |
| Memory | 表级锁 |
| InnoDB | 行级锁 |
| Archive | 行级锁 |
| NDB | 行级锁 |
表级锁 :锁整张表.
行级锁:只锁某几行.
所以 InnoDB 在高并发写入场景下表现更好,因为它支持行级锁.
4.MVCC / Snapshot Read:多版本并发控制
MVCC 可以理解为:读写互不阻塞的一种机制.
图中 InnoDB 支持 MVCC .
这意味着在很多情况下:
- 查询数据时不会阻塞修改
- 修改数据时也不会完全阻塞查询
- 可以提高并发性能
这也是 InnoDB 适合高并发业务系统的重要原因.
5.Index:索引支持
图中列出了几类索引:
B-Tree indexes:B 树索引
大多数存储引擎都支持 B-Tree 索引,比如:
- MyISAM
- BDB
- Memory
- InnoDB
- NDB
B-Tree 索引适合范围查询、排序、等值查询.
Hash indexes:哈希索引
图中 Memory、InnoDB、NDB 支持 Hash 索引.
Hash 索引适合等值查询,例如:
sql
WHERE id = 1但不适合范围查询,例如:
sql
WHERE id > 10Full text search index:全文索引
图中 MyISAM 支持全文索引.
早期 MySQL 中全文索引主要是 MyISAM 的特点.现在 InnoDB 也支持全文索引,但这张图可能是基于较早版本的 MySQL.
Clustered index:聚簇索引
图中 InnoDB 支持聚簇索引 .
InnoDB 的主键索引就是聚簇索引,特点是:
text
主键索引的叶子节点直接存放整行数据所以 InnoDB 中主键设计很重要.
6.Data Caches / Index Caches:缓存
图中区分了:
- Data Caches:数据缓存
- Index Caches:索引缓存
InnoDB 同时支持数据缓存和索引缓存.
InnoDB 有一个重要组件叫 Buffer Pool,会缓存数据页和索引页,减少磁盘 IO,提高查询性能.
MyISAM 主要缓存索引,不像 InnoDB 那样强依赖统一的 Buffer Pool.
7.Compressed data:压缩数据
图中显示:
- MyISAM 支持压缩
- Archive 支持压缩
Archive 的特点就是适合压缩归档数据,节省空间.
所以如果是历史日志、审计数据、只插入少修改的数据,可以考虑 Archive.
8.Encrypted data:加密数据
图中表示多个引擎可以通过函数方式支持加密数据.
这里的意思通常不是引擎天然透明加密,而是可以通过加密函数处理字段,例如:
sql
AES_ENCRYPT()
AES_DECRYPT()现代 MySQL 中还支持更多层面的加密能力,但这张图主要是在比较早期存储引擎特性.
9.Storage cost:存储成本
表示占用磁盘空间的多少.
图中大致是:
| 存储引擎 | 存储成本 |
|---|---|
| MyISAM | Low |
| BDB | Low |
| InnoDB | High |
| Archive | Very Low |
| NDB | Low |
InnoDB 因为支持事务、日志、MVCC、崩溃恢复等机制,所以存储成本相对更高.
Archive 因为压缩存储,空间成本非常低.
10.Memory cost:内存成本
表示运行时占用内存的情况.
图中:
- MyISAM:Low
- BDB:Low
- Memory:Medium
- InnoDB:High
- NDB:High
InnoDB 内存成本高,是因为它依赖 Buffer Pool、事务信息、锁信息等结构.
Memory 引擎数据本身就在内存中,所以也会占用一定内存.
11.Bulk Insert Speed:批量插入速度
批量插入指大量数据快速写入.
图中:
- MyISAM:High
- BDB:High
- Memory:High
- InnoDB:Low
- Archive:Very High
- NDB:High
Archive 很适合大量插入归档数据.
InnoDB 因为要维护事务、redo log、undo log、索引、锁等,所以在一些场景下批量插入成本较高.不过实际生产中通过关闭自动提交、批量提交、合理建索引等方式可以优化.
12.Cluster database support:集群数据库支持
图中主要是 NDB 支持集群数据库 .
NDB 是 MySQL Cluster 使用的存储引擎,适合分布式、高可用场景.
普通业务开发中较少直接使用 NDB,更多还是使用 InnoDB.
13.Replication support:复制支持
复制指主从复制、数据同步.
图中多个引擎都支持复制,包括:
- MyISAM
- BDB
- Memory
- InnoDB
- Archive
- NDB
不过实际生产中,主从复制最常见的还是基于 InnoDB 表.
14.Foreign key support:外键支持
图中 InnoDB 支持外键 .
MyISAM、Memory、Archive 等一般不支持外键.
外键用于维护表之间的引用完整性,例如:
sql
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT,
FOREIGN KEY (user_id) REFERENCES user(id)
) ENGINE = InnoDB;不过在很多互联网业务中,即使使用 InnoDB,也可能不使用数据库外键,而是在业务代码中维护关联关系.
15.Backup / Point-in-time recovery:备份和时间点恢复
图中大多数引擎都支持备份和时间点恢复.
时间点恢复通常依赖:
- 全量备份
- binlog 二进制日志
例如可以把数据库恢复到某个具体时间点.
16.Query cache support:查询缓存支持
图中很多引擎都支持 Query Cache.
但要注意:MySQL 8.0 已经移除了 Query Cache .
所以这张图应该是较早版本 MySQL 的特性对比表.
17.Update Statistics for Data Dictionary:更新数据字典统计信息
图中所有引擎基本都支持.
统计信息用于帮助优化器判断执行计划,例如是否使用索引、表连接顺序等.
18.总结
这张图的核心意思是:不同 MySQL 存储引擎支持的能力不同,选择存储引擎要看业务场景.
最重要的对比可以记成这样:
| 场景 | 推荐引擎 |
|---|---|
| 普通业务系统 | InnoDB |
| 需要事务 | InnoDB |
| 高并发读写 | InnoDB |
| 需要外键 | InnoDB |
| 临时内存数据 | Memory |
| 大量历史归档数据 | Archive |
| MySQL 集群 | NDB |
| 老版本读多写少场景 | MyISAM |
实际开发中最常见的结论是:
text
默认选择 InnoDB。因为 InnoDB 支持事务、行级锁、MVCC、崩溃恢复、外键,是现代 MySQL 最主流的存储引擎.

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
敬请期待下一篇文章内容
每日心灵鸡汤: 掌握自己的节奏,把生活调到喜欢的频道!
有人3分钟泡面,有人3小时煲汤,有人外卖已送达,有人才切好蒜苔和肉.每个人都是独一无二的,擅长的事情不同,生活节奏也不同.所以,如果你没能活成别人嘴里的"标准答案",千万别因此焦虑和难过.每个人都有自己的人生节奏,别因为别人的步伐打乱自己的节奏,最重要的是选择适合自己的方式.真正的幸福,并不是拥有更多东西,而是拥有的东西都能让你感到快乐.今天起,试着把生活调到自己喜欢的频道,为自己的梦想全力以赴,只要你知道自己想要什么,那么你脚下的每一步,都是通往未来最正确的路.
