扩散模型(Diffusion Model)是近年来生成式深度学习中非常重要的一类模型。与生成对抗网络(GAN)通过"生成器---判别器"的对抗训练生成样本不同,扩散模型采用另一种思路:先把真实数据逐步加噪声,直到它接近纯随机噪声;再训练神经网络学习反向去噪过程,从随机噪声一步步还原出清晰样本。
扩散模型的核心思想可以概括为:
• 前向过程:把真实数据逐步加噪,变成接近纯噪声的数据
• 反向过程:训练模型逐步去噪,从噪声还原出真实样本
例如,在图像生成任务中,扩散模型可以从一张随机噪声图开始,经过多步去噪,逐渐生成一张清晰图像。文本生成图像、图像编辑、图像修复、超分辨率等任务,都可以在扩散模型框架下实现。
一、为什么需要扩散模型
生成模型的目标,是学习真实数据分布,并生成新的样本。
在 GAN 中,生成器直接把随机噪声映射为图像:
其中:
• z 表示随机噪声
• G 表示生成器
• x̃ 表示生成样本
这种方式很直接,但训练中需要同时平衡生成器和判别器。若判别器过强,生成器可能难以学习;若生成器只学会少数典型样本,又可能出现模式崩塌。
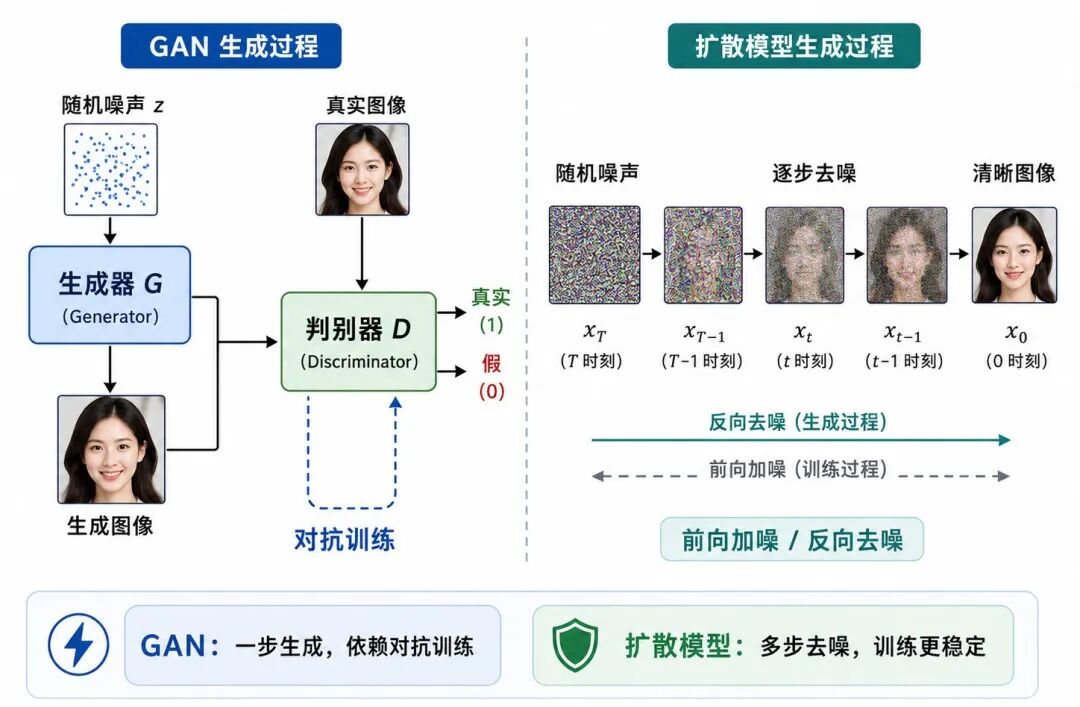
图 1:从 GAN 到扩散模型
扩散模型换了一种思路。
它不要求模型一步从噪声生成完整图像,而是把生成过程拆成很多小步骤:
纯噪声 → 稍微清晰一点 → 更清晰一点 → 接近真实图像 → 清晰图像
从直观角度看,扩散模型更像是在学习:如何一步一步把噪声擦掉。
这种思想带来几个好处:
• 训练目标相对稳定
• 不需要判别器进行对抗训练
• 生成样本多样性较好
• 可以自然支持图像编辑、修复和条件生成
• 生成过程具有较清晰的概率建模解释
当然,扩散模型也有代价。由于生成时通常需要多步迭代去噪,采样速度往往比 GAN 慢。因此,如何提高采样效率,是扩散模型的重要研究方向之一。
二、扩散模型的基本结构
扩散模型通常包含两个过程:
• 前向扩散过程
• 反向去噪过程
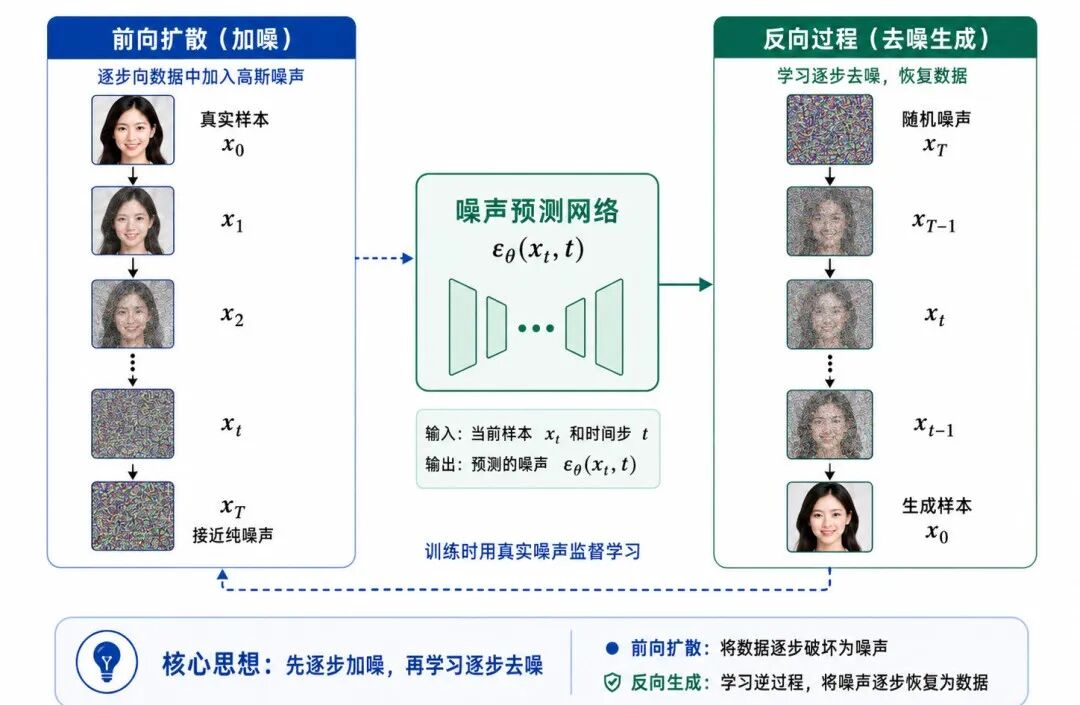
图 2:扩散模型的基本结构
1、前向扩散:逐步加入噪声
前向扩散过程从真实样本 x₀ 开始,逐步向其中加入高斯噪声,得到一系列越来越模糊、越来越接近纯噪声的中间状态:
x₀ → x₁ → x₂ → ... → xₜ → ... → x_T
其中:
• x₀ 表示真实数据,例如一张真实图像
• xₜ 表示第 t 步加噪后的数据
• x_T 表示接近纯噪声的数据
• T 表示总扩散步数
在图像任务中,x₀ 是清晰图像;随着 t 增大,图像逐渐被噪声覆盖;当 t 足够大时,x_T 看起来几乎就是随机噪声。
可以简单理解为:
前向扩散 = 有控制地破坏数据
2、反向去噪:逐步还原数据
反向去噪过程则从随机噪声 x_T 开始,逐步去除噪声,最终生成清晰样本:
x_T → x_{T-1} → ... → xₜ → ... → x₁ → x₀
这个反向过程不是人工写死的,而是由神经网络学习出来的。
模型在训练时学习:给定带噪图像 xₜ 和时间步 t,预测其中的噪声成分; 然后在生成时根据预测噪声一步步修正图像,使它越来越接近真实数据。
可以简单理解为:
反向去噪 = 学会逐步修复数据
3、噪声预测网络
扩散模型中常用一个神经网络来预测噪声。这个网络通常记为:
其中:
• εθ 表示由参数 θ 控制的噪声预测网络
• xₜ 表示第 t 步的带噪数据
• t 表示时间步
• εθ(xₜ,t) 表示模型预测出的噪声
在图像扩散模型中,噪声预测网络常用 U-Net 结构。U-Net 能够同时利用局部细节和多尺度语义信息,因此非常适合图像去噪任务。
不过,为了理解扩散模型的基本原理,本文后面的 PyTorch 示例会使用一个简化网络完成 MNIST 风格图像去噪与生成演示。
三、前向加噪过程
扩散模型的前向过程,是一个固定的、无需学习的加噪过程。它按照预设的噪声强度表,在每一步向数据中加入少量噪声。
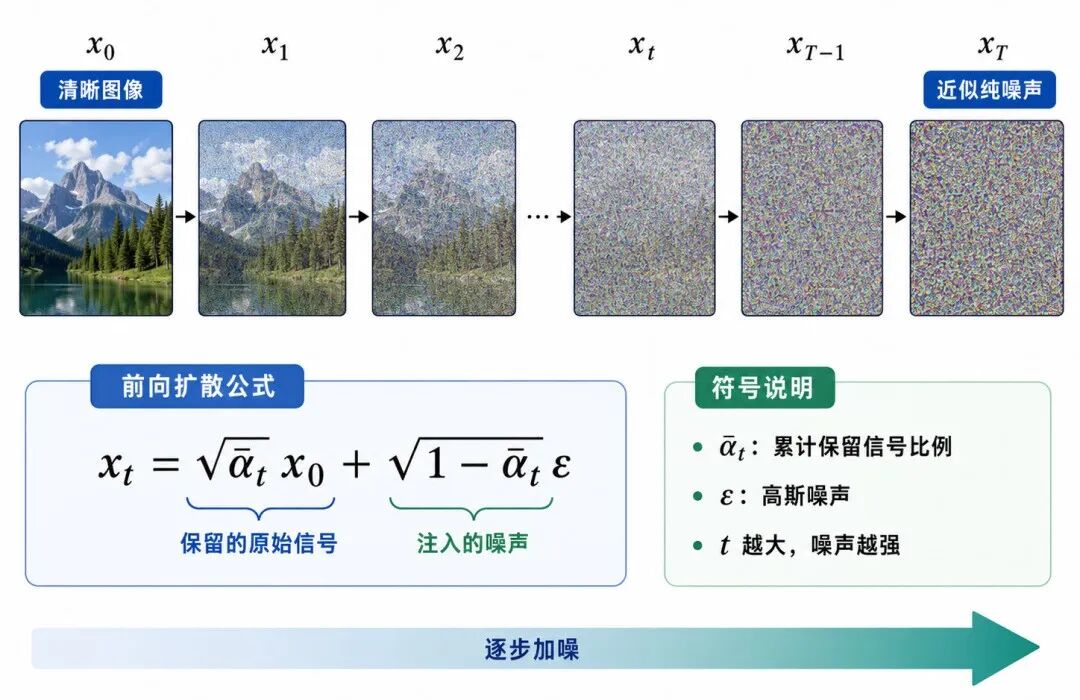
图 3:前向扩散过程:从清晰图像到纯噪声
常见写法是:
其中:
• q(xₜ|xₜ₋₁) 表示从 xₜ₋₁ 生成 xₜ 的前向加噪分布
• βₜ 表示第 t 步加入噪声的强度
• I 表示单位矩阵
• N 表示高斯分布
• √(1 − βₜ)xₜ₋₁ 表示保留一部分上一时刻的数据
• βₜI 表示加入的高斯噪声方差
从直观角度看,每一步都做两件事:
• 保留一部分原始信息
• 加入一部分随机噪声
为了简化公式,通常定义:
并定义累计乘积:
其中:
• αₜ 表示第 t 步保留信号的比例
• ᾱₜ 表示从第 1 步到第 t 步累计保留的信号比例
• ∏ 表示连乘
一个非常重要的性质是:可以直接从 x₀ 采样得到任意时间步的 xₜ,而不必真的一步一步加噪。
公式为:
其中:
• x₀ 表示原始真实样本
• xₜ 表示第 t 步的带噪样本
• ᾱₜ 表示累计保留信号比例
• ε 表示从标准正态分布采样的噪声
• √ᾱₜx₀ 表示保留下来的原始信号
• √(1 − ᾱₜ)ε 表示加入的噪声部分
这条公式非常关键。它说明训练时可以随机选择一个时间步 t,直接把真实图像 x₀ 加噪成 xₜ,然后让模型学习预测其中的噪声 ε。
四、反向去噪过程
前向过程是已知的加噪过程,反向过程则是需要学习的去噪过程。
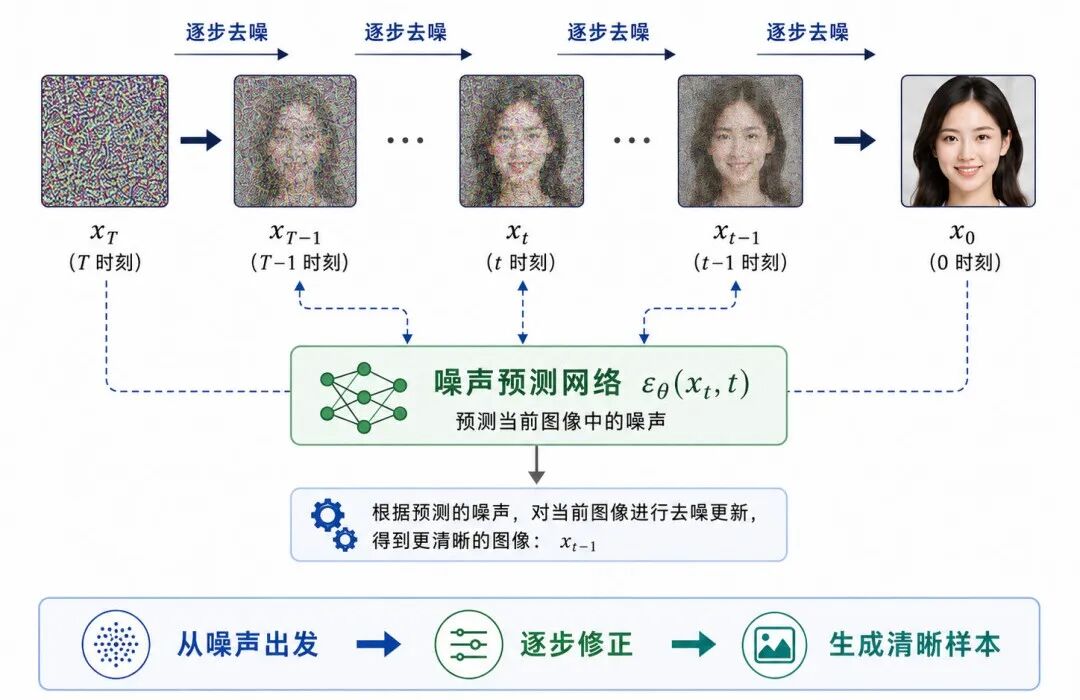
图 4:反向去噪过程:从随机噪声到清晰图像
理想情况下,如果我们知道每一步如何从 xₜ 还原到 xₜ₋₁,就可以从纯噪声 x_T 开始,一步步生成清晰样本。
反向过程可以写成:
其中:
• pθ(xₜ₋₁|xₜ) 表示模型学习到的反向去噪分布
• θ 表示神经网络参数
• xₜ 表示当前带噪样本
• xₜ₋₁ 表示去噪一步后的样本
实际训练中,常见做法不是让模型直接预测 xₜ₋₁,而是让模型预测前向过程中加入的噪声 ε:
其中:
• ε 表示真实加入的噪声
• εθ(xₜ,t) 表示模型预测的噪声
• ≈ 表示希望二者尽量接近
为什么预测噪声有用?
因为如果模型知道 xₜ 中有多少噪声,就可以从 xₜ 中减去这部分噪声,得到更干净的样本估计。
可以简单理解为:模型不是直接画出图像,而是学习判断"这张图里哪些部分是噪声"。
生成时,模型会重复执行:
预测噪声 → 去掉一部分噪声 → 得到更清晰的图像
直到从 x_T 逐步得到 x₀。
五、扩散模型的训练目标
扩散模型的训练目标可以非常简洁地表达为:让模型预测的噪声接近真实加入的噪声。
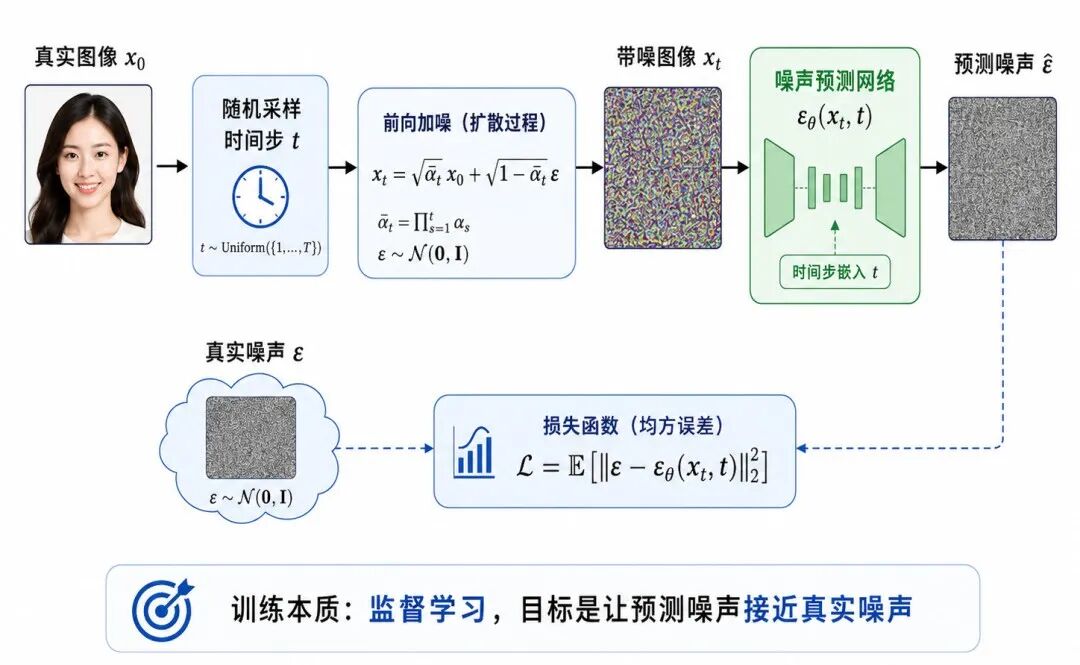
图 5:扩散模型的训练目标:预测噪声
训练时,从真实图像 x₀ 中采样一个批次,再随机采样时间步 t 和噪声 ε,构造带噪图像 xₜ:
然后让模型预测噪声:
其中:
• ε̂ 表示模型预测的噪声
• ε 表示真实加入的噪声
• εθ 表示噪声预测网络
常用损失函数是均方误差:
其中:
• L 表示训练损失
• E 表示对样本、时间步和噪声取期望
• ε 表示真实噪声
• εθ(xₜ,t) 表示模型预测噪声
• || · ||² 表示平方误差
从机器学习角度看,扩散模型训练本质上是一个监督学习问题:
• 输入:带噪图像 xₜ 和时间步 t
• 目标:真实噪声 ε
• 模型:预测噪声 εθ(xₜ,t)
• 损失:预测噪声与真实噪声之间的均方误差
这也是扩散模型训练相对稳定的重要原因:它不像 GAN 那样需要同时平衡生成器和判别器,而是直接优化一个噪声预测目标。
六、扩散模型的采样过程
训练完成后,扩散模型可以从随机噪声开始生成样本。
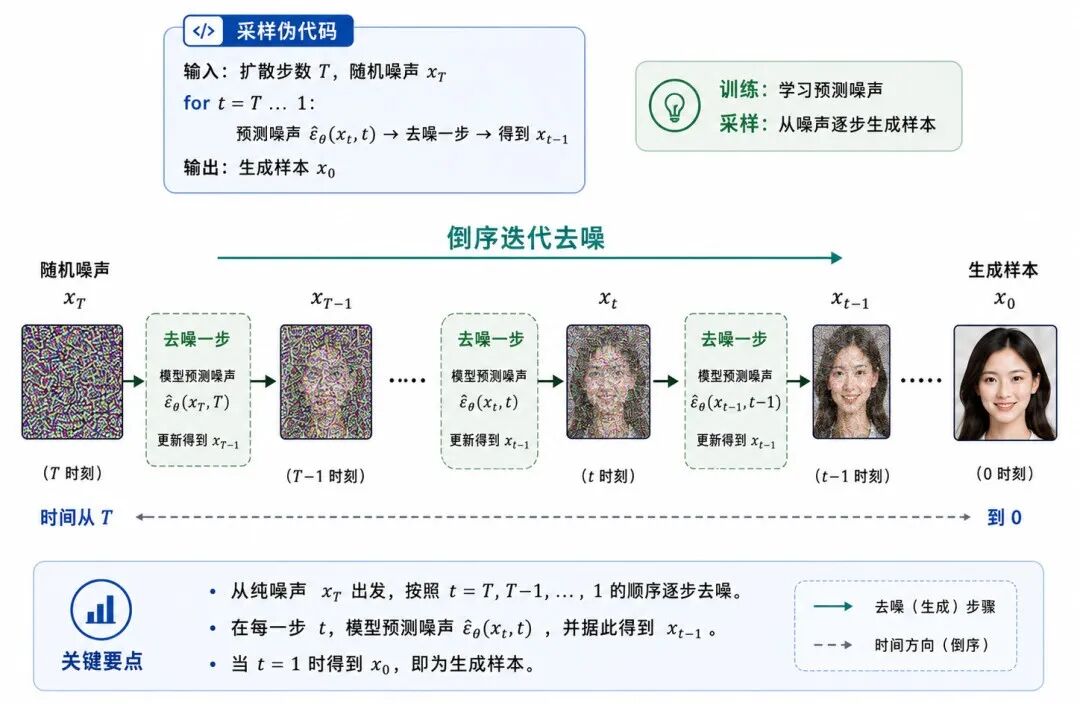
图 6:扩散模型的采样过程
采样过程大致如下:
-
从标准正态分布采样 x_T
-
从 t = T 开始倒序迭代
-
用模型预测当前图像中的噪声
-
根据预测噪声计算 x_{t-1}
-
重复直到得到 x_0
可以用伪代码表示为:
python
x = torch.randn(shape)
for t in reversed(range(T)): predicted_noise = model(x, t) x = denoise_step(x, predicted_noise, t)其中:
• x 初始为随机噪声
• model(x,t) 表示噪声预测网络
• denoise_step 表示一次反向去噪更新
• T 表示扩散步数
扩散模型生成图像的过程通常是逐步细化的:
go
纯噪声→ 模糊轮廓→ 粗略结构→ 局部细节→ 清晰图像这与 GAN 的"一步生成"不同。GAN 通常直接从 z 输出图像,而扩散模型通常需要多步采样。
因此,扩散模型的主要优势和代价也很清楚:
• 优势:训练稳定,生成质量高,多样性好
• 代价:采样通常较慢,需要多步迭代
七、PyTorch 实现:简化版扩散模型生成手写数字
下面使用 PyTorch 构建一个简化版扩散模型,用于理解扩散模型的基本训练流程。
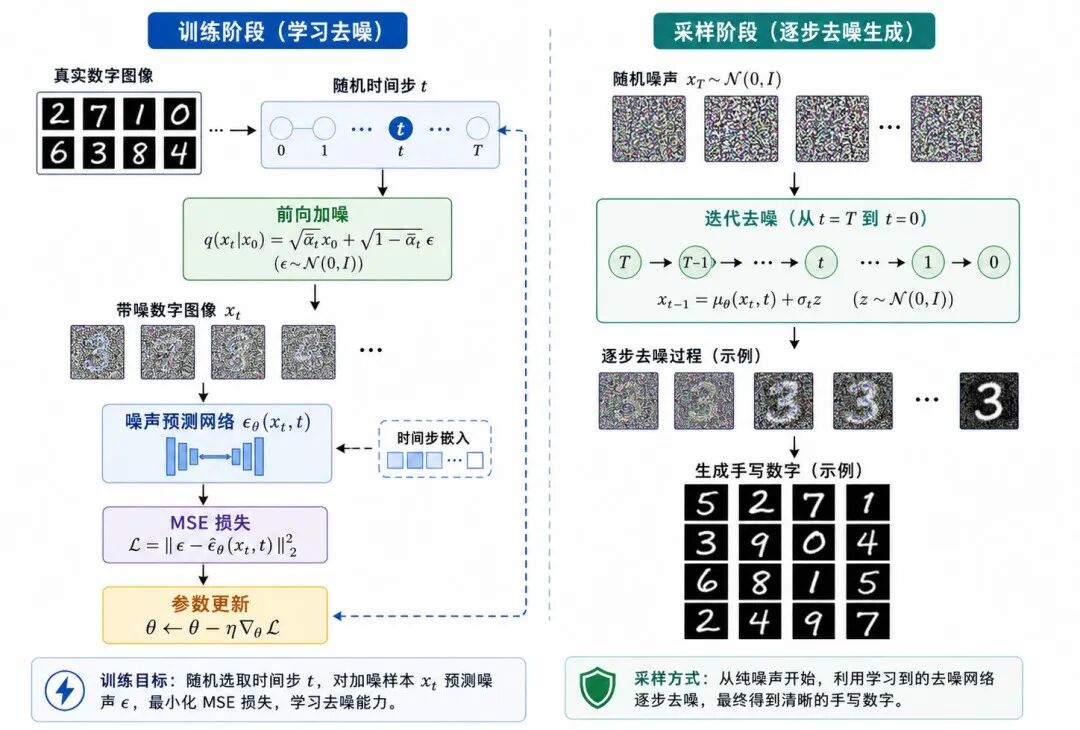
图 7:扩散模型生成手写数字的训练与采样流程
为了突出核心思想,示例使用 MNIST 手写数字数据集,并用一个简单的卷积网络预测噪声。真实高质量扩散模型通常会使用 U-Net、注意力机制和更复杂的噪声调度方法。
1、导入库
python
# 导入 PyTorch 核心模块import torchimport torch.nn as nn # 神经网络层和损失函数import torch.optim as optim # 优化器(SGD, Adam等)import matplotlib.pyplot as plt # 可视化(显示图像)
from torch.utils.data import DataLoader # 批量数据加载器from torchvision import datasets, transforms # 常用数据集和图像预处理这里使用:
• DataLoader 按批量读取数据
• torchvision.datasets 加载 MNIST 数据集
• torchvision.transforms 处理图像
2、设置超参数
ini
# 设置训练设备(GPU优先)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
image_size = 28 # 图像尺寸(MNIST 28x28)batch_size = 128 # 批量大小num_epochs = 5 # 训练轮数learning_rate = 1e-3 # 学习率
T = 200 # 扩散模型的总时间步数(噪声调度步数)其中,T 表示扩散总步数。
为了让示例运行更轻量,这里使用 T = 200。真实扩散模型中,扩散步数可能更大。
3、准备 MNIST 数据集
makefile
# 图像预处理:转为张量并标准化到 [-1, 1] 范围transform = transforms.Compose([ transforms.ToTensor(), # 将 PIL 图像或 numpy 数组转为 (C,H,W) 张量,值域 [0,1] transforms.Normalize((0.5,), (0.5,)) # 归一化: (x - 0.5) / 0.5 → 值域 [-1,1]])
# 加载 MNIST 训练集(60000 张手写数字)train_dataset = datasets.MNIST( root="./data", # 数据集存放目录 train=True, # 加载训练集 download=True, # 若本地无则下载 transform=transform # 应用预处理)
# 创建数据加载器:批量加载、打乱顺序train_loader = DataLoader( train_dataset, batch_size=batch_size, # 每批样本数 shuffle=True # 每个 epoch 打乱顺序)这里把 MNIST 图像归一化到大致 −1 到 1 的范围,便于和高斯噪声配合。
4、定义噪声调度表
扩散模型需要为每个时间步设置噪声强度 βₜ。这里使用简单的线性调度:
ini
# 扩散模型的噪声调度参数beta_start = 1e-4 # 初始噪声水平beta_end = 0.02 # 最终噪声水平
# 线性插值生成 T 个 beta 值(从 beta_start 到 beta_end)betas = torch.linspace(beta_start, beta_end, T).to(device)
# 计算 alpha = 1 - betaalphas = 1.0 - betas# 累积乘积:alpha_bar_t = ∏_{s=1}^t alpha_salpha_bars = torch.cumprod(alphas, dim=0)其中:
• betas 表示每一步加入噪声的强度
• alphas 表示每一步保留信号的比例
• alpha_bars 表示累计保留信号比例
对应前文公式中的:
5、实现前向加噪函数
根据公式:
实现前向加噪函数:
python
def add_noise(x0, t): """前向扩散:根据时间步 t 对原始图像 x0 添加噪声,得到带噪图像 xt 和噪声 noise""" noise = torch.randn_like(x0) # 生成标准高斯噪声
# 取出对应时间步的 alpha_bar 值,并调整形状以便广播(batch, 1, 1, 1) alpha_bar_t = alpha_bars[t].view(-1, 1, 1, 1)
# 重参数化采样:xt = sqrt(alpha_bar_t) * x0 + sqrt(1 - alpha_bar_t) * noise xt = torch.sqrt(alpha_bar_t) * x0 + torch.sqrt(1 - alpha_bar_t) * noise
return xt, noise其中:
• x0 表示真实图像
• t 表示每张图像对应的随机时间步
• noise 表示真实加入的噪声
• xt 表示加噪后的图像
这里的 t 是一个批量向量,因此 alpha_barst 会为每个样本取出对应时间步的 ᾱₜ。
6、定义时间嵌入
噪声预测网络不仅需要看到带噪图像 xₜ,还需要知道当前时间步 t。因为不同 t 对应不同噪声强度。
为了简化实现,可以使用一个嵌入层把时间步 t 转换为向量:
ruby
# 时间步嵌入层:将离散的时间步 t 映射为稠密向量class TimeEmbedding(nn.Module): def __init__(self, T, embed_dim): super().__init__() # 嵌入层:T 个时间步,每个映射为 embed_dim 维向量 self.embedding = nn.Embedding(T, embed_dim)
def forward(self, t): # t: 形状 (batch,) 的时间步索引 return self.embedding(t) # 输出形状 (batch, embed_dim)其中:
• T 表示时间步总数
• embed_dim 表示时间嵌入维度
• embedding(t) 把整数时间步转换为向量
真实扩散模型中,常用正弦时间嵌入或更复杂的时间编码方式。这里使用 nn.Embedding 是为了方便初学者理解。
7、定义噪声预测网络
下面定义一个简化卷积网络,用于预测噪声:
apache
# 简单去噪网络:接收带噪图像 x 和时间步 t,预测添加的噪声class SimpleDenoiseNet(nn.Module): def __init__(self, T, time_dim=32): super().__init__() # 时间步嵌入层,将 t 映射为 time_dim 维向量 self.time_embed = TimeEmbedding(T, time_dim)
# 卷积层:输入通道 = 图像通道(1) + 时间嵌入通道(time_dim) self.conv1 = nn.Conv2d(1 + time_dim, 64, kernel_size=3, padding=1) self.conv2 = nn.Conv2d(64, 64, kernel_size=3, padding=1) self.conv3 = nn.Conv2d(64, 1, kernel_size=3, padding=1)
self.act = nn.ReLU()
def forward(self, x, t): batch_size, _, height, width = x.shape
# 获取时间嵌入并调整形状以拼接至空间维度 t_embed = self.time_embed(t) # (batch, time_dim) t_embed = t_embed.view(batch_size, -1, 1, 1) # (batch, time_dim, 1, 1) t_embed = t_embed.expand(-1, -1, height, width) # 扩展到 (batch, time_dim, h, w)
# 沿通道维度拼接图像和时间嵌入 x = torch.cat([x, t_embed], dim=1) # (batch, 1+time_dim, h, w)
# 通过两个卷积层(ReLU激活) x = self.act(self.conv1(x)) x = self.act(self.conv2(x)) # 输出层,预测噪声 x = self.conv3(x) return x这个网络的输入包括:
• 带噪图像 xₜ
• 时间步 t 的嵌入表示
输出是:与 xₜ 形状相同的噪声预测图。也就是说,模型要为每个像素位置预测噪声值。
创建模型:
ini
# 实例化去噪网络(使用默认时间嵌入维度32),并移动到设备model = SimpleDenoiseNet(T=T).to(device)
# Adam 优化器,优化模型所有参数optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 均方误差损失:用于预测噪声与真实噪声之间的差异criterion = nn.MSELoss()这里使用 MSELoss,因为训练目标是让预测噪声接近真实噪声。
8、训练扩散模型
训练流程如下:
python
# 训练扩散模型:学习预测添加的噪声for epoch in range(num_epochs): model.train() total_loss = 0.0
for images, _ in train_loader: # 批量加载真实图像 images = images.to(device) # 移至设备 batch_size_current = images.size(0)
# 随机采样每个样本的时间步 t ∈ [0, T-1] t = torch.randint( low=0, high=T, size=(batch_size_current,), device=device )
# 前向扩散:为图像添加对应时间步的噪声 xt, noise = add_noise(images, t)
# 预测噪声 predicted_noise = model(xt, t)
# 计算预测噪声与真实噪声的均方误差 loss = criterion(predicted_noise, noise)
# 反向传播,更新参数 optimizer.zero_grad() loss.backward() optimizer.step()
total_loss += loss.item() * batch_size_current
avg_loss = total_loss / len(train_loader.dataset) print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {avg_loss:.4f}")这段代码体现了扩散模型训练的核心闭环:
真实图像 → 随机时间步 → 加噪得到 xₜ → 模型预测噪声 → 计算 MSE → 反向传播 → 更新参数
其中:
• t 是随机采样的时间步
• add_noise() 负责构造带噪图像
• model(xt,t) 预测噪声
• loss 衡量预测噪声和真实噪声之间的差距
9、简化采样函数
训练完成后,可以从随机噪声开始逐步去噪。
下面给出一个简化采样函数:
python
@torch.no_grad()def sample(model, num_samples=16): """从训练好的扩散模型中采样生成新图像""" model.eval()
# 从标准高斯分布采样初始噪声(T 步后的纯噪声) x = torch.randn(num_samples, 1, image_size, image_size).to(device)
# 逆向去噪过程:从 t = T-1 到 0 for t_value in reversed(range(T)): # 构造当前时间步张量,形状 (num_samples,) t = torch.full((num_samples,), t_value, device=device, dtype=torch.long)
# 预测当前步的噪声 predicted_noise = model(x, t)
# 获取当前步的噪声调度参数 beta_t = betas[t_value] alpha_t = alphas[t_value] alpha_bar_t = alpha_bars[t_value]
# 除最后一步外添加随机噪声,最后一步不加 if t_value > 0: noise = torch.randn_like(x) else: noise = torch.zeros_like(x)
# DDPM 采样更新公式: # x_{t-1} = 1/√α_t * (x_t - β_t/√(1-ᾱ_t) * ε_θ) + √β_t * z x = ( 1 / torch.sqrt(alpha_t) * ( x - (beta_t / torch.sqrt(1 - alpha_bar_t)) * predicted_noise ) + torch.sqrt(beta_t) * noise )
# 将像素值从 [-1,1] 恢复到 [0,1] 范围,便于可视化 x = (x.clamp(-1, 1) + 1) / 2
return x这个采样过程从随机噪声开始,按时间步倒序更新。每一步都用模型预测噪声,并根据预测结果修正当前图像。
需要注意:这是教学版简化实现,目的是帮助理解扩散模型的基本流程。真实高质量扩散模型会使用更精细的反向方差设置、噪声调度、U-Net 结构和更复杂的采样器。
10、生成并显示图像
apache
# 从模型中采样生成 16 张图像samples = sample(model, num_samples=16)
# 创建 4x4 子图网格fig, axes = plt.subplots(4, 4, figsize=(6, 6))
# 遍历每个子图,显示生成的图像for i, ax in enumerate(axes.flat): # 移除通道维度,转为 numpy,显示灰度图 ax.imshow(samples[i].cpu().squeeze(), cmap="gray") ax.axis("off") # 隐藏坐标轴
plt.show() # 展示图像如果模型训练足够,生成图像会逐渐呈现 MNIST 手写数字的形状。
八、扩散模型的适用场景、局限与扩展方向
扩散模型是当前生成式深度学习中的重要模型之一,尤其在图像生成、图像编辑和多模态生成任务中具有重要影响。
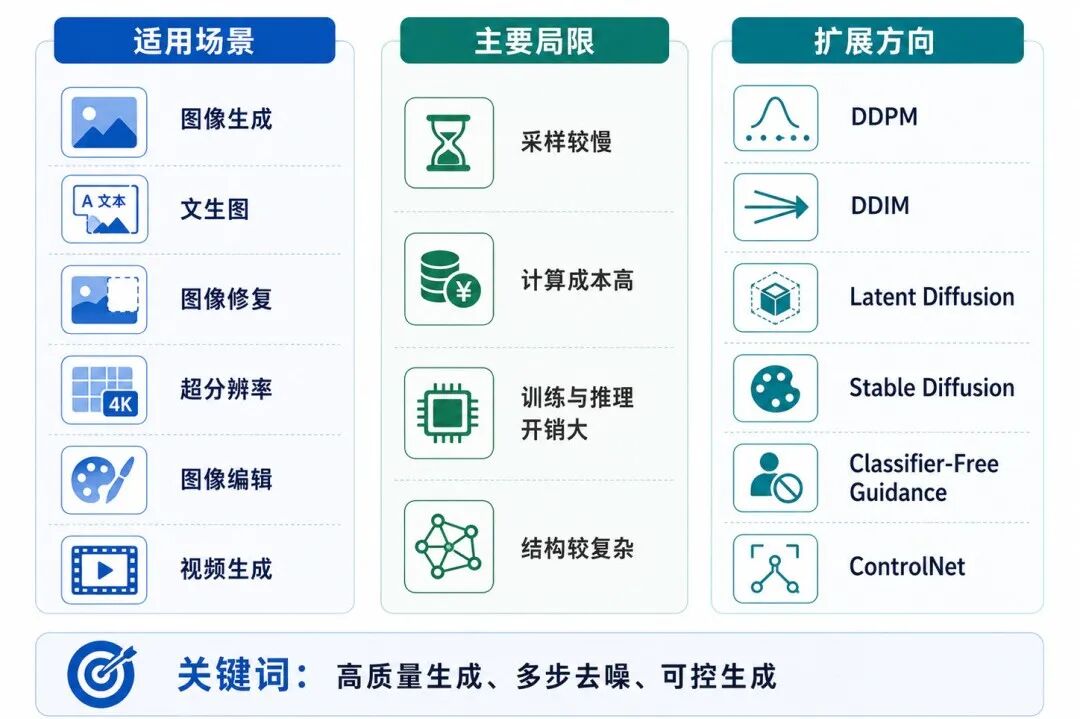
图 8:扩散模型的适用场景、局限与扩展方向
1、适用场景
扩散模型常用于:
• 图像生成
• 文本生成图像
• 图像修复
• 图像超分辨率
• 图像编辑
• 风格迁移
• 视频生成
• 三维内容生成
其中,文本生成图像是扩散模型最具代表性的应用方向之一。模型可以在文本条件的引导下,从噪声逐步生成符合描述的图像。
2、主要优势
扩散模型的主要优势包括:
• 训练过程相对稳定
• 生成样本质量高
• 样本多样性较好
• 不容易出现 GAN 式模式崩塌
• 易于结合条件信息进行可控生成
• 具有较清晰的逐步去噪解释
扩散模型的思想非常直观:先学习如何去噪,再通过不断去噪完成生成。
3、主要局限
扩散模型也有明显局限:
• 采样通常较慢
• 训练和推理计算成本较高
• 高质量图像生成通常需要复杂网络结构
• 对噪声调度、采样器和条件控制方式较敏感
• 生成过程多步迭代,不如 GAN 一步生成直接
因此,扩散模型虽然生成质量很强,但在实际应用中仍然需要考虑效率、成本和部署难度。
4、扩展方向
从基础扩散模型出发,可以继续学习:
• DDPM:去噪扩散概率模型
• DDIM:更高效的确定性采样方法
• Latent Diffusion:在潜空间中进行扩散,降低计算成本
• Stable Diffusion:基于潜空间扩散的大规模文本生成图像模型
• Classifier Guidance:用分类器引导生成方向
• Classifier-Free Guidance:无需单独分类器的条件引导方法
• ControlNet:通过边缘、姿态、深度图等条件控制生成结果
这些模型和技术都可以从一个基本问题出发理解:如何更高效、更可控地从噪声生成高质量数据?
📘 小结
扩散模型通过"前向加噪---反向去噪"的方式学习数据生成过程。训练时,模型学习预测加入到真实样本中的噪声;生成时,模型从随机噪声出发,逐步去噪得到清晰样本。扩散模型训练稳定、生成质量高、多样性好,是理解现代图像生成和多模态生成模型的重要基础。

"点赞有美意,赞赏是鼓励"