**摘要:**这是一篇关于向量数据库核心检索算法的技术博客,主要面向计算机专业学生或开发者。文章深入解析了从暴力搜索到近似最近邻(ANN)的演进,重点对比了IVF(倒排文件索引)和HNSW(分层导航小世界)两种主流算法的原理、核心参数及适用场景,旨在帮助读者理解算法背后的工程权衡,以便在实际业务中进行合理选型。
随着深度学习技术的飞速发展,向量已经成为了图像、文本、语音等非结构化数据的核心表示形式。如何在海量数据中快速找到与目标向量最相似的"邻居",成为了推荐系统、图像检索、RAG(检索增强生成)等应用的关键。在学习了向量数据库的核心检索算法后,我深感这些算法在效率与精度之间权衡的精妙之处。本文将结合我的学习笔记,深入浅出地解析从基础的暴力搜索到高效的近似算法,特别是目前主流的IVF和HNSW算法。
一、背景与应用场景
在深度学习的加持下,万物皆可"向量化"。向量搜索(Vector Search)不再仅仅是计算距离,而是成为了连接非结构化数据与业务逻辑的桥梁。
核心应用场景包括:
- RAG(检索增强生成):为大语言模型(LLM)提供"外挂大脑",从庞大的知识库中检索出最相关的内容,辅助生成更准确、更有时效性的回答,解决幻觉问题。
- 推荐系统:基于用户的向量画像(兴趣、行为),在海量商品或内容库中进行"千人千面"的精准匹配。
- 图像/视频检索:实现"以图搜图"或"以视频搜视频",通过视觉特征向量的比对,找到相似的视觉内容。
二、核心检索算法详解
面对海量数据,如何高效检索?算法界给出了从"精确"到"近似"的演进方案。
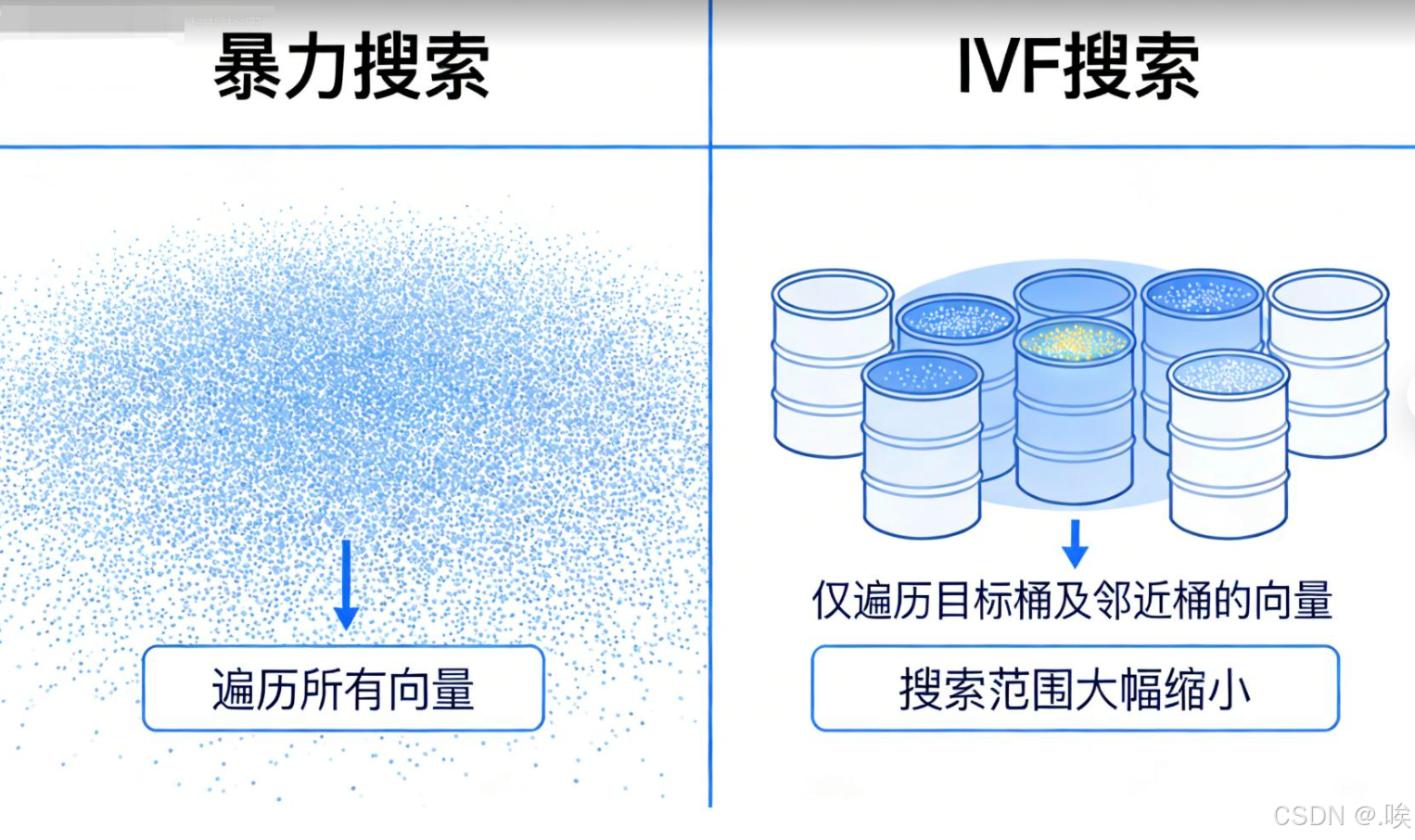
1. 暴力搜索(KNN):精确但低效的"基准线"
最朴素的思想:计算查询向量与数据库中每一个向量的距离,排序后取Top-K个最近邻。
- 优点:结果绝对精确,是衡量其他算法效果的"黄金标准"。
- 缺点:时间复杂度为O(N),在百万甚至亿级数据规模下,查询延迟极高,完全无法满足实时性要求(如推荐、搜索)。
- 地位:通常作为小数据集或算法对比的基准(Baseline)。
2. 近似最近邻(ANN):效率与精度的"平衡艺术"
为了追求极致的速度,ANN算法应运而生。它不追求绝对的"最近",而是寻找"足够近"的邻居。在RAG或推荐场景中,毫秒级的响应速度远比微小的精度损失更重要。
常见的ANN算法包括基于聚类的IVF和基于图的HNSW。

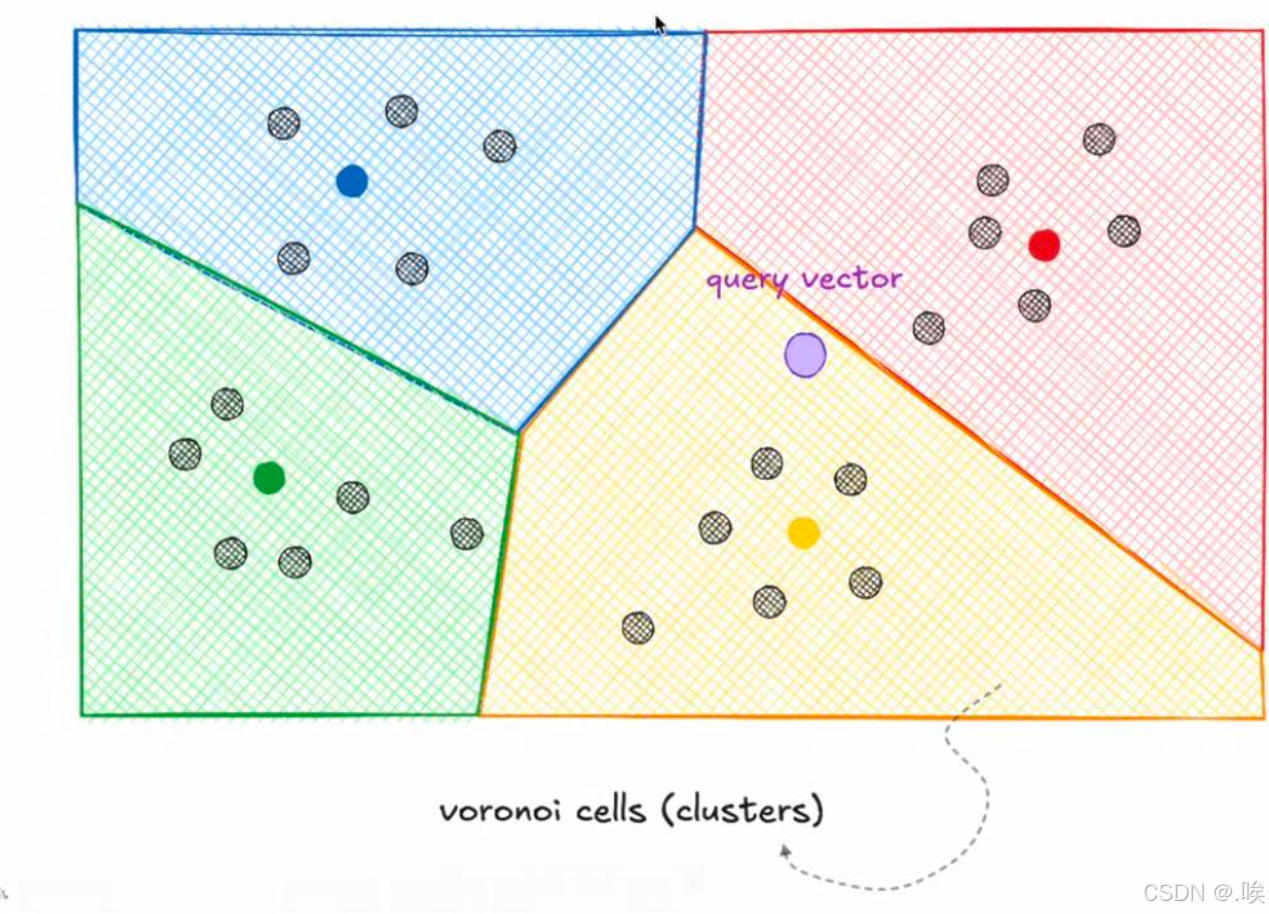
3. 倒排文件索引(IVF):化整为零的"分治策略"
IVF(Inverted File Index)借鉴了传统全文检索的倒排索引思想,通过聚类将"大海捞针"转化为"小池塘捞针"。
- 构建阶段 :
- 使用K-Means算法将全量向量聚类为K个簇,生成K个质心。
- 每个向量根据距离被分配到最近的质心所属簇中,形成"质心 → 向量列表"的倒排结构。
- 查询阶段 :
- 计算查询向量与所有质心的距离,找出最近的Top-N个簇。
- 仅在这些候选簇内进行精确的距离计算,大幅减少计算量。
优势:相比暴力搜索,速度提升显著;适合亿级数据且更新频繁的场景。
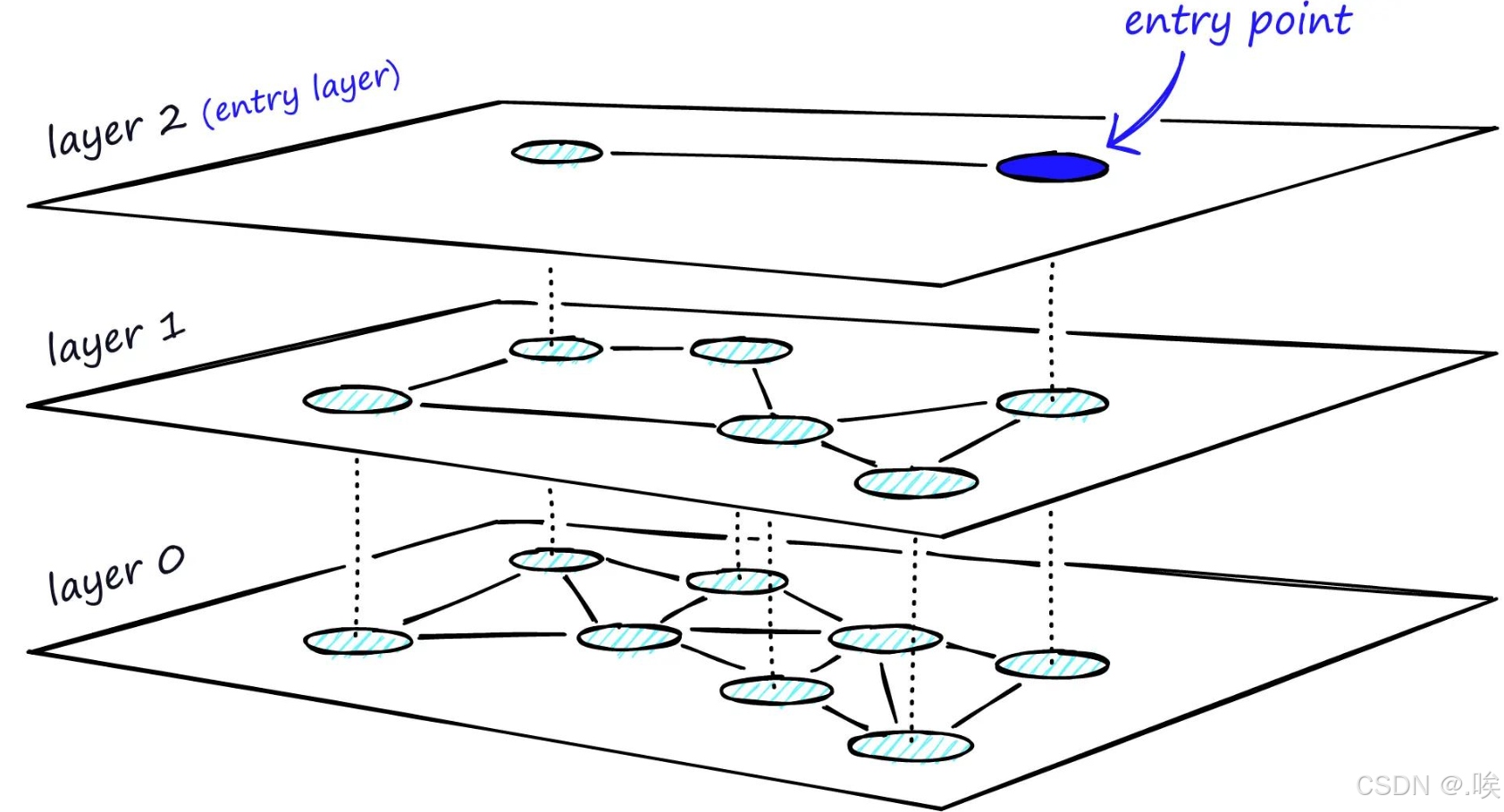
4. 分层导航小世界(HNSW):图结构的"高速公路"
HNSW(Hierarchical Navigable Small World)是目前精度和速度综合表现最强的算法之一,其核心思想类似于"跳表"(Skip List)。
- 核心结构:分层图
- 底层(0层):包含全量数据,节点连接稠密,负责精细搜索。
- 上层:包含数据的稀疏子集,节点连接稀疏但距离远,如同"高速公路",负责快速跨越。
- 搜索流程:贪心+逐层下降
- 入口:从顶层的入口点开始。
- 顶层搜索:在稀疏的高层图中贪心搜索,快速定位到目标区域附近。
- 逐层下降:将上层找到的最优节点作为下一层的入口,在更稠密的图中继续搜索。
- 底层精搜:在底层全量数据中进行精确搜索,返回Top-K结果。
HNSW的三大核心超参数
| 参数名 | 作用阶段 | 核心含义 | 影响与调参建议 |
|---|---|---|---|
| M | 构建索引 | 每层节点的最大近邻数 | 控制图的稠密程度和内存占用。M越大,精度越高,内存占用越大(常用8/16/32)。 |
| ef_construction | 构建索引 | 建图时搜索的候选数量 | 决定索引构建的质量。值越大,索引质量越好,建库越慢(常用128/200/400,需≥2×M)。 |
| ef | 查询阶段 | 查询时保留的候选数量 | 直接影响查询精度和速度。ef越大,召回率越高,查询越慢(常用64/128/256,需≥目标Top-K)。 |
三、算法对比与选型建议
为了更直观地理解这些算法的差异,我整理了以下对比表格:
| 算法 | 结构 | 速度 | 精度 | 内存 | 适用场景 |
|---|---|---|---|---|---|
| 暴力搜索(KNN) | 无 | 极慢 | 极高 | 低 | 小数据集、基准测试 |
| IVF | 聚类+倒排 | 中快 | 中 | 低 | 亿级数据、频繁更新 |
| HNS- | 分层图 | 极快 | 极高 | 高 | 高维数据、高精度、低延迟 |
选型建议:
- 如果你追求极致的查询性能和召回率,且数据量在千万级以内,HNSW是首选。
- 如果你的数据量达到亿级甚至十亿级,且需要频繁更新(如实时推荐),IVF可能更具优势,因为它在索引更新和存储成本上更友好。
四、总结
通过这次学习,我深刻体会到向量数据库不仅仅是"存向量",其背后复杂的检索算法才是支撑AI应用落地的基石。从暴力搜索的"笨办法"到HNSW的"高速公路",这些算法在数学与工程之间找到了精妙的平衡。
作为大学生,我们不仅要学会使用Faiss、Milvus等工具,更要理解其背后的原理(如HNSW的分层图思想、IVF的聚类分治)。只有这样,才能在未来的项目开发中,根据业务场景(数据量、维度、QPS、延迟要求)做出最合理的架构选型,真正驾驭好这把"AI时代的利剑"。