一、题目背景
「下一个排列」是一道非常经典的数组原地修改问题。
题目要求:给定一个整数数组 nums,将它重新排列成字典序中的下一个更大的排列。
如果不存在下一个更大的排列,则将数组重新排列成字典序最小的排列,也就是升序排列。
例如:
nums = [1, 2, 3]它的下一个排列是:
[1, 3, 2]再例如:
nums = [3, 2, 1]由于 [3, 2, 1] 已经是所有排列中字典序最大的排列,因此它的下一个排列需要回到最小排列:
[1, 2, 3]这道题的限制是:
必须原地修改,只允许使用额外常数空间。因此不能暴力生成所有排列,也不能额外开数组存储结果。
二、什么是字典序排列?
所谓字典序,可以理解为数字序列之间的大小比较规则。
例如对于数字 1, 2, 3,它的所有排列按照字典序从小到大排列如下:
123
132
213
231
312
321因此:
123 的下一个排列是 132
132 的下一个排列是 213
321 没有更大的排列,因此回到 123对于更长的序列,例如 1,2,3,4,5,6,它的排列顺序可以看成:
123456
123465
123546
...
654321题目的核心就是:
在这些有序排列中,找到当前排列的下一个排列。
换句话说,我们要找的是:
刚好比当前排列大一点点的排列而不是随便找一个更大的排列。
三、问题本质:如何让排列"刚好变大一点"
假设当前排列是:
123456如果我们想让它变大,可以交换后面的某些数字。
例如交换 5 和 6:
123456 -> 123465显然,123465 比 123456 大。
但是问题并不只是"变大",而是要变成"下一个更大的排列"。
也就是说,增加的幅度必须尽可能小。
因此我们需要满足两个原则。
原则一:尽可能在靠右的位置进行修改
数字越靠左,对整体大小的影响越大。
例如:
123456如果修改第一个数字,可能会变成:
213456这个变化幅度非常大。
但如果只修改最后两个数字:
123456 -> 123465变化幅度就小得多。
所以,要找到下一个排列,应当尽量从右侧低位开始调整。
这就是为什么算法需要:
从后向前查找原则二:用尽可能小的"大数"替换前面的"小数"
如果要让排列变大,就需要把后面的一个较大的数换到前面。
例如:
123465如果我们希望得到它的下一个排列,需要从后往前分析。
当前后缀中存在:
4, 6, 5我们可以用 5 或 6 去替换 4。
如果用 6 替换 4:
123465 -> 123645如果用 5 替换 4:
123465 -> 123564显然:
123564 < 123645所以应该选择刚好比 4 大的那个数字,也就是 5。
这说明,交换时不能随便找一个大数,而要找:
右侧所有大于当前数字的元素中,最小的那个原则三:交换后,后缀要变成最小排列
继续看:
123465我们已经知道要交换 4 和 5。
交换后得到:
123564但是这还不是最终答案。
因为 5 后面的部分是:
6, 4它不是最小排列。
为了让整个结果尽可能小,需要把后缀调整成升序:
6, 4 -> 4, 6最终得到:
123546所以:
123465 的下一个排列是 123546这一步非常关键。
因为当我们已经让前面的某一位变大之后,后面的部分就应该尽可能小,才能保证整个排列是"刚好变大"的。
四、算法整体过程
标准的"下一个排列"算法可以分为三步。
假设数组为 nums,长度为 n。
第一步:从后向前找到第一个升序位置
从右往左查找第一个满足:
nums[i] < nums[i + 1]的位置 i。
这个位置就是需要被替换的"小数"。
为什么要找这个位置?
因为如果从右往左看,后面一直是降序,说明后面的部分已经是最大排列,无法仅靠调整后缀变得更大。
例如:
12385764从右往左看:
6 > 4
7 > 6
5 < 7因此第一个满足升序关系的位置是:
nums[i] = 5此时可以把数组分成两部分:
1238 | 5764其中 5 是我们要修改的位置。
第二步:从后向前找到第一个大于 numsi 的元素
找到 nums[i] 之后,需要在它右边找到一个刚好比它大的数。
由于右侧后缀是降序排列,因此从右往左扫描,遇到的第一个大于 nums[i] 的元素,就是最小的大数。
对于:
12385764我们已经找到:
nums[i] = 5右侧部分为:
7, 6, 4从右往左查找第一个大于 5 的数:
6因此交换 5 和 6:
12385764 -> 12386754第三步:反转后缀,使其变成升序
交换后,前面的部分已经变大。
此时为了让整个排列尽可能小,需要把 i 后面的部分调整成升序。
当前结果是:
123867546 后面的部分是:
7, 5, 4这是降序的。
将其反转:
7, 5, 4 -> 4, 5, 7最终得到:
12386457因此:
12385764 的下一个排列是 12386457五、为什么后缀一定是降序?
这是这道题最核心的逻辑之一。
我们从右往左寻找第一个满足:
nums[i] < nums[i + 1]的位置。
在找到这个位置之前,说明右侧所有相邻元素都不满足升序关系,也就是:
nums[k] >= nums[k + 1]所以右侧后缀一定是非递增的,也就是降序结构。
例如:
12385764当我们找到 5 < 7 时,5 后面的部分是:
7, 6, 4它是降序的。
这就带来两个好处:
第一,从右往左找第一个大于 nums[i] 的元素,就能找到最小的大数。
第二,交换完成后,只需要反转后缀,就能让后缀变成升序,而不需要额外排序。
这也是该算法能做到 O(n) 时间复杂度和 O(1) 空间复杂度的关键。
六、完整 C++ 代码
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
public:
void nextPermutation(vector<int>& nums) {
int n = nums.size();
// 从右往左找到第一个 nums[i] < nums[i + 1] 的位置
int i = n - 2;
while (i >= 0 && nums[i] >= nums[i + 1]) {
i--;
}
// 如果 i >= 0,说明当前排列不是最大排列
if (i >= 0) {
int j = n - 1;
// 从右往左找到第一个大于 nums[i] 的元素
while (j >= 0 && nums[j] <= nums[i]) {
j--;
}
// 交换"小数"和"大数"
swap(nums[i], nums[j]);
}
// 反转 i + 1 到末尾的后缀,使其变成升序
reverse(nums.begin() + i + 1, nums.end());
}
};七、代码详细解析
1. 查找第一个升序位置
int i = n - 2;
while (i >= 0 && nums[i] >= nums[i + 1]) {
i--;
}这里从倒数第二个元素开始向前扫描。
原因是我们需要比较:
nums[i] 和 nums[i + 1]如果一直满足:
nums[i] >= nums[i + 1]说明当前部分是降序的。
一旦找到:
nums[i] < nums[i + 1]就说明 nums[i] 可以被右侧某个更大的元素替换,从而让整个排列变大。
2. 查找交换对象
if (i >= 0) {
int j = n - 1;
while (j >= 0 && nums[j] <= nums[i]) {
j--;
}
swap(nums[i], nums[j]);
}如果 i >= 0,说明当前排列还不是最大排列。
接下来需要在 i 的右侧找到一个比 nums[i] 大的元素。
由于右侧后缀是降序排列,所以从右往左找到的第一个大于 nums[i] 的元素,就是最小的大数。
这一步保证了新排列只会比原排列大一点点。
3. 反转后缀
reverse(nums.begin() + i + 1, nums.end());交换之后,前缀已经变大。
为了让结果尽可能小,后缀必须变成升序。
由于后缀原本是降序,所以只需要执行一次反转即可。
如果当前数组本身就是降序,例如:
[3, 2, 1]那么第一步结束后:
i = -1此时执行:
reverse(nums.begin(), nums.end());数组就会变成:
[1, 2, 3]刚好符合题目要求。
八、示例推演:12385764
下面用一个完整例子来走一遍算法流程。
初始数组:
1 2 3 8 5 7 6 4
第一步:从右往左找第一个升序位置
从右往左观察:
6 > 4
7 > 6
5 < 7
因此:
nums[i] = 5当前结构为:
1 2 3 8 [5] 7 6 4其中 5 是需要被替换的小数。
第二步:从右往左找第一个大于 5 的数
从右往左扫描 5 右侧部分:
7 6 4第一个大于 5 的元素是:
6
交换 5 和 6:
1 2 3 8 6 7 5 4
第三步:反转后缀
交换后,6 后面的部分是:
7 5 4将其反转为升序:
4 5 7
最终结果:
1 2 3 8 6 4 5 7也就是:
12385764 -> 12386457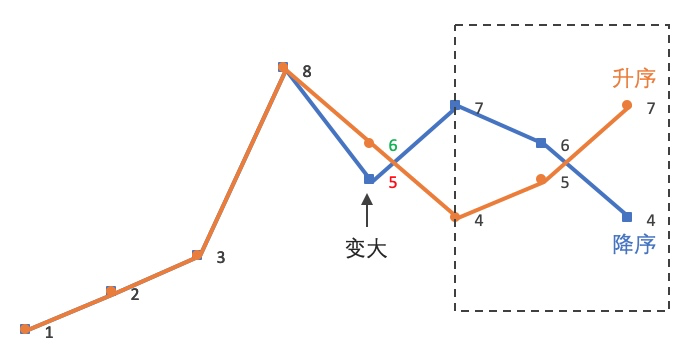
九、边界情况分析
1. 当前排列已经是最大排列
例如:
nums = [3, 2, 1]整个数组从左到右是降序排列。
从右往左无法找到:
nums[i] < nums[i + 1]说明当前排列已经是字典序最大排列。
此时直接反转整个数组:
[3, 2, 1] -> [1, 2, 3]2. 数组中存在重复元素
例如:
nums = [1, 1, 5]从右往左找到:
1 < 5交换后得到:
[1, 5, 1]本算法对重复元素同样适用。
因为寻找交换对象时使用的是严格大于关系:
nums[j] > nums[i]不会把相等元素误认为可以产生更大排列的元素。
3. 数组长度为 1
例如:
nums = [1]只有一个元素时,它的排列只有一种,下一个排列仍然是它本身。
代码中:
int i = n - 2;此时 i = -1,最后执行反转操作,结果不变。
十、正确性证明
可以从三个角度证明该算法的正确性。
1. 修改位置必须尽可能靠右
为了让新排列比原排列大,但又尽量接近原排列,应尽量保持高位不变。
从右往左找到的第一个 nums[i] < nums[i + 1],就是最靠右的、可以通过交换变大的位置。
如果不修改这个位置,那么右侧后缀已经是降序,也就是后缀的最大排列,无法再变大。
因此,i 是必须修改的最靠右位置。
2. 交换对象必须是最小的大数
当确定要修改 nums[i] 后,新数字必须比 nums[i] 大。
如果选择一个过大的数字,虽然也能让排列变大,但结果不是"下一个排列"。
由于右侧后缀是降序,从右往左扫描到的第一个大于 nums[i] 的元素,就是所有可选元素中最小的那个大数。
这保证了交换后,前缀增量最小。
3. 后缀必须调整为升序
交换完成后,前缀已经比原排列更大。
为了让整个结果在所有更大排列中最小,后缀必须取最小字典序。
对于一组数字来说,升序排列就是字典序最小的排列。
而右侧后缀本身具有降序结构,因此直接反转即可得到升序。
十一、复杂度分析
时间复杂度
算法主要包括三次线性操作:
1. 从右往左查找升序位置:O(n)
2. 从右往左查找交换对象:O(n)
3. 反转后缀:O(n)因此总时间复杂度为:
O(n)空间复杂度
算法只使用了少量指针变量,没有使用额外数组。
因此空间复杂度为:
O(1)完全满足题目"原地修改,只允许使用常数额外空间"的要求。
十二、常见错误
错误一:从左往右找交换位置
如果从左往右寻找可交换位置,可能会过早修改高位,导致结果过大。
例如:
123456如果错误地修改前面的 1 或 2,得到的结果就不是紧邻的下一个排列。
正确做法是:
从右往左找第一个可以增大的位置错误二:交换后没有反转后缀
例如:
123465交换 4 和 5 后得到:
123564但这不是最终答案。
因为后缀还可以变得更小:
64 -> 46所以正确答案是:
123546错误三:寻找交换元素时没有选择最小的大数
如果当前数组是:
123465对于数字 4,右侧比它大的数有:
6, 5应该选择 5,而不是 6。
如果选择 6,得到的排列会变得过大,不符合"下一个排列"的要求。
十三、模板总结
这道题可以总结成一个固定模板:
1. 从右往左找第一个 nums[i] < nums[i + 1] 的位置;
2. 如果找到了 i,则从右往左找第一个 nums[j] > nums[i] 的位置;
3. 交换 nums[i] 和 nums[j];
4. 反转 i + 1 到末尾的后缀。对应代码模板:
void nextPermutation(vector<int>& nums) {
int n = nums.size();
int i = n - 2;
while (i >= 0 && nums[i] >= nums[i + 1]) {
i--;
}
if (i >= 0) {
int j = n - 1;
while (j >= 0 && nums[j] <= nums[i]) {
j--;
}
swap(nums[i], nums[j]);
}
reverse(nums.begin() + i + 1, nums.end());
}十四、总结
「下一个排列」这道题的难点不在代码,而在于对字典序的理解。
它的核心思想可以概括为:
从右往左找到第一个可以变大的位置,
用右侧刚好比它大的元素替换它,
再把后缀调整为最小排列。也就是:
低位优先修改,增幅尽量小,后缀重新最小化。这道题很好地体现了贪心思想:
每一步都选择当前最小的有效改变,最终得到全局意义上的下一个排列。
掌握这道题之后,对全排列生成、字典序排序、组合搜索等问题都会有更深入的理解。