Skills 概念
简单来说,Agent Skills 是一个模块化的功能扩展包。它允许开发者将特定的专业知识、复杂的提示词模板(Prompt Templates)、示例(Few-shot examples)以及工具调用逻辑(Tool Use)封装成一个独立的单元。
这类似于为 AI 穿上一套特定的"职业装":当你需要它审代码时,它就加载"代码专家技能";当你需要它管理项目时,它就切换到"项目经理模式"。
核心亮点:从"单兵作战"到"模块化生态"
- 极高的可复用性:开发者无需再为每个新项目重写冗长的 Prompt。技能可以跨项目、跨团队甚至在开源社区中直接分享。
- 深度集成:该库不仅支持原生的 Gemini API 和 Gemini CLI,还与 Google 最新的 Agent 开发平台 Antigravity 深度互通。
- 标准化流程:通过定义标准化的"技能"格式,Google 正在推动 AI 行业向 Agent Skills 开放标准靠拢,类似于 Anthropic 提出的 Claude Skills 概念。
Agent Skills 与 Agent Rules 对比
简单来说, Rules是"预设的固定指令",是AI必须遵守的"硬约束";而Agent Skill是"习得的灵活能力",是AI运用知识解决问题的"软能力" 。
从名字上也能区分个大概,
- rule 自然是对 agent 做出限制条件的逻辑;
- skills 则反而是让 agent 学会懂得如何做某件事的操作。
从功能上的区分:
- rule 就是对相关的 ai agent 进行限制约束处理,规定 ai agent 的一些行为操作;
- 而 skill 是让 ai agent 学会相关的一些操作处理,反而是让 agent 的可操作行为增加。
Skill 的原理
agent skills 的组成
目录文件结构
bash
skill-name/
├── SKILL.md # 必需:技能定义文件
├── README.md # 可选:说明文档
├── config.json # 可选:配置文件
├── scripts/ # 可选:可执行脚本(用于确定性/重复性任务)
│ ├── build.py
│ └── validate.sh
├── references/ # 可选:参考文档(按需加载到上下文)
│ ├── aws.md
│ ├── gcp.md
│ └── azure.md
├── assets/ # 可选:输出用资源文件(模板、图标、字体等)
│ ├── template.html
│ └── logo.png
├── agents/ # 可选:专用子代理指令
│ ├── grader.md
│ └── analyzer.md
├── lib/ # 可选:依赖库
└── evals/ # 可选:评估测试用例
└── evals.jsonSKILL.md 文件内容
这个文件是这个 Skill 最重要的一个文件,这是对 Skill 的信息和执行操作逻辑的描述记载。
一个 Skill 的 SKILL.md 文件例子(以 skill-creator 为例):
- 一个
SKILL.md文件内容包含下面两部分内容
yaml
---
name: skill-creator
description: Create new skills, modify and improve existing skills, and measure skill performance. Use when users want to create a skill from scratch, edit, or optimize an existing skill, run evals to test a skill, benchmark skill performance with variance analysis, or optimize a skill's description for better triggering accuracy.
---
# Skill Creator
A skill for creating new skills and iteratively improving them.
At a high level, the process of creating a skill goes like this:
...1. Metadata 元数据(YAML Frontmatter)
Agent Skill 的基础信息,位于文件最顶部,用 --- 包裹的 YAML 格式。
name:技能的唯一标识符,必须与 skill 的文件夹名字相同description:技能的描述,是触发机制的核心。说明技能做什么、在什么场景下使用。这是模型决定是否调用该技能的主要依据
yaml
---
name: my-skill-name
description: 简明描述这个技能做什么,以及什么时候应该触发使用它。
---注意 :description 是技能触发的主要机制。要写得"主动"一些,包含技能的功能描述和具体的使用场景。例如,不要只写"如何构建仪表盘",而应该写"如何构建仪表盘。当用户提到数据可视化、内部指标展示时都应使用此技能。"
2. Instruction 指令(Markdown 正文)
--- 之后的 Markdown 正文部分,详细描述模型执行任务时需要遵循的规则、流程和注意事项。
指令编写原则:
- 使用祈使句(命令式)
- 解释为什么某件事很重要,而不是堆砌大量 MUST/NEVER
- 保持
SKILL.md在 500 行以内;如果接近上限,增加层级结构并明确指引模型去哪里获取更多信息 - 对大参考文件(>300 行),包含目录(Table of Contents)
- 用理论思维让技能具有通用性,不要过度拟合到特定示例
常用的指令结构模板:
shell
# 技能标题
简要概述技能目的。
## 工作流程
### 第一步:收集信息
描述模型需要做什么...
### 第二步:执行任务
描述执行逻辑...
## 输出格式
ALWAYS use this exact template:
# [标题]
## 摘要
## 关键发现
## 建议
## 示例
**Example 1:**
Input: 用户输入内容
Output: 期望输出内容
## 注意事项
- 规则1
- 规则2Reference(参考文件)
references/ 目录存放按需加载的文档资料。SKILL.md 中应明确指引何时需要读取哪个参考文件。
markdown
## 参考文件
当你需要部署到特定云平台时,请阅读对应的参考文件:
- AWS 部署 → 读取 `references/aws.md`
- GCP 部署 → 读取 `references/gcp.md`
- Azure 部署 → 读取 `references/azure.md`对于大文件(>300 行),参考文件内应包含目录。
领域组织模式:当一个技能支持多个框架/变体时,按变体组织参考文件:
bash
cloud-deploy/
├── SKILL.md # 工作流程 + 选择逻辑
└── references/
├── aws.md # AWS 特定部署指南
├── gcp.md # GCP 特定部署指南
└── azure.md # Azure 特定部署指南模型只会读取相关的参考文件,避免加载不必要的内容。
Script(脚本)
scripts/ 目录存放可执行脚本,用于确定性、重复性的任务。脚本可以在不被加载到上下文的情况下直接执行。
何时使用脚本:
- 需要确定性输出的任务(如数据格式转换、文件校验)
- 多个测试用例中反复出现的重复操作
- 需要程序化验证的断言检查
在 SKILL.md 中引用脚本:
markdown
## 执行步骤
1. 运行 `scripts/validate.py` 校验输入数据
2. 执行转换逻辑...
3. 运行 `scripts/format.sh` 格式化输出最佳实践: 如果在测试过程中发现多个子代理都在独立编写类似的辅助脚本(如 create_docx.py),这强烈暗示应该将该脚本捆绑到技能中------写一次放在 scripts/ 目录,后续所有调用都复用它。
ai 时代下的感悟
在 AI 的冲击下,这块还有必要进行了解原理吗?
没有的啦,代码源码原理全都是垃圾,不如学习如何使用操作 AI 来帮你写更好罢了。
见仁见智吧,已经说不清了。最大的感受就是"我的代码不是我的"。
Skills 的应用
Skill 的安装与使用
现在基本上主流的 AI 厂商都已经支持 Agent Skill 了,并且已经是被广泛应用 AI agent 当中了。
这里,我们就使用一个著名的开源 AI 资源管理工具:CC Switch来对相关主流的 AI 进行资源的管理操作。
- github.com/farion1231/...
- 这里就不再详细介绍 CC Switch 这个软件的使用了,感兴趣的童鞋可以自行了解使用。
在 CC Switch 当中,有相关的一个 Skill 商城,我们能够从上面来下载安装使用社区开放提供的 Skills。
我们这里就来试着安装这个 skill-creator这个 Skill,这个 Skill 能够让 Agent 来辅助我们更好的创建一个自定义 Skill。
安装成功后,我们在 CC Switch 当中进行对 skill 进行启用管理(全局的);
配置启用后,我们就能够在相关的 ai 工具链当中输入/skillname,如果能像下图搜索展示出相关匹配的 skill,就能直接调用该 skill 来处理。
正所谓实践当中出真理,我们就直接干脆在自定义编写 Skill 的这个过程当中顺带进行对已安装的 Skill 进行使用应用实践。在现代化的 AI 开发当中,哪里还需要自己真的一行行代码进行编写操作处理,就应该更加好好的利用 AI 的能力。
自定义 Skills 的落地实践
笔者在上一篇的 MCP 文章当中是介绍了三个在项目开发迭代流程当中比较实用的几个工具 MCP 服务。
- TAPD 需求的读取,并且出相关的技术实现方案
- 技术方案文档的读取内容进行开发操作
- 浏览器进行看效果和自测冒烟操作
- git 操作
这里就将这些 MCP 进行基础协议调用来进行扩展来作为 skill 的能力,简单的对相关单个工作需求操作的应用场景进行
1. 自动提交代码和远程代码库 PR 操作
我们可以直接和 AI 说,我们想要开发一个关于 "自动流转 TAPD 缺陷 "的 skill。
- 如果我们使用 plan 模式来进行处理的话,AI 则会进一步询问这个 Skill 相关的内容描述、逻辑处理等。
- 接着我们根据 ai agent 的提示完善好相关的技能 skill 描述和执行逻辑,AI agent 就会自动识别到需要使用
skill-creator这个 Skill来进行实现这个 Skill。
使用 skill-creator 创建一个自动提交工作代码并进行远程仓库分支管理的 skill:
-
触发关键词,提交需求、提交代码;
-
将当前文件都放到提交暂存区当中;
-
检查暂存区的文件修改内容当中是否有相关 todo 等注释文案的修改记录或者增加,如果有则拦截中断行为直接进行提示用户相关处理;
-
根据现在暂存区文件的修改内容生成符合 commitlint 格式的提交 message 并且进行代码提交并且推送到 origin 的远程仓库当中;
-
使用 gitlab mcp 来进行相关公共仓库的 MR 创建和合并处理,默认推送到 master 并且合并,根据用户的输入,如果包含测试sit,灰度pre,生产prod等字样的情况则增加公共仓库的对应的分支的创建并且合并 MR 操作处理;要根据用户描述有可能只是创建 MR 并不需要合并操作
创建这个 skill 之后,我们使用 CC Switch 导入这个 Skill,但是这样处理的 Skill 是引入全局的;
当然如果这个 Skill 非全局的,也可以根据自己使用的 AI 工具的应用说明,将 Skill 文件放置到对应的项目文件夹当中去也可以。
接着当然就是尝试使用这个 skill 来进行使用 AI 来辅助我们进行处理代码的提交推送合并等操作了:
我们直接说 "提交开发的代码",看看效果;
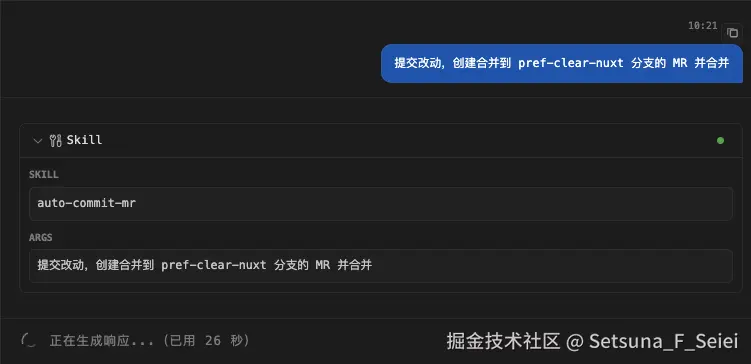
好,我们能够看到 agent 工具当中对相关 skill 的调用了,具体执行逻辑就看 skill 的描述内容和 AI 执行的实际操作了。
2. 自动流转 TAPD 缺陷
接着我们继续使用 ai 辅助帮我们直接创建一个自动流转 TAPD 缺陷的 skill,相关的描述与处理逻辑:
-
- 缺陷类型和缺陷描述;
-
- 流转缺陷给测试人员,填写缺陷开发责任人是谁;
-
- 缺陷原因、解决方式等等完善相关信息;
将相关信息都完善后,我们就能接着让 AI 生成这个 Skill 并且使用 CC-Switch 导入开启使用处理。
然后我们拿来进行测试调用看是否能正常触发想要的效果:
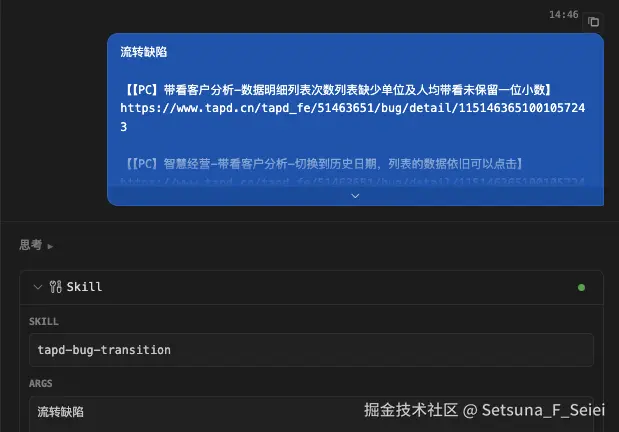
todo 补图
基本上我们能够从图当中看到 agent 调用了这个对应的 tapd-bug-transitionskill;
并且能够成功的进行缺陷的流转操作了,将我们的一些手工操作省略掉了。
Skill 的实践应用简单总结
经过上面的两个简单的 Skill 的编写和使用例子,能够更加真实的体会到 Skill 给 AI Agent 带来的变化,那就是前面提及到的 Skill 是让 ai agent 学会相关的一些操作处理,能够将一些流程化的操作进行封装,让 AI 能够根据规定的路线对相关的任务进行流水线的处理(能够进一步解放我们曾经繁杂枯燥的手工操作)。
这里有几个 Skill 实践的要点可以分享下:
- 推荐一开始创建 Skill 时候尽可能就先构思好相对完整的流程,细节可能可以有忽略,让 AI Plan 的时候多确认询问清楚;
- 然后创建 Skill 尽可能使用相对高级一点的模型,不要用国内的流口水的模型来和稀泥了;
- 修改的时候要学会让 AI 做减法走正确的路,不要一直让 AI 一直做加法打补丁的形式去添加改动内容,不然这个 Skill 会变得越来越难维护和执行变得无法预测的方向发展。
关于 Skill 的吐槽
不知道是不是相关的提示触发词写的并不是很好,经常性需要更加明确提示 agent 需要使用触发具体某个 skill 才能够有效的进行相关的触发;当然也有可能是因为使用的是国产的淌口水的模型,相比国外的一些顶级的模型,无论是编码能力还是理解分析能力来说,我感觉这些淌口水的国产模型自然和国外的顶级先进模型来比还是有一定的差距,因此可能就造成 skill 的编写质量和触发场景有偏差(嗨蠢)。