目录
[三、UDP 报文格式](#三、UDP 报文格式)
[四、UDP 封装与解包原理](#四、UDP 封装与解包原理)
[五、内核视角:UDP 报文封装过程](#五、内核视角:UDP 报文封装过程)
[六、UDP 核心特点](#六、UDP 核心特点)
[七、UDP 缓冲区机制](#七、UDP 缓冲区机制)
[八、UDP 报文大小限制](#八、UDP 报文大小限制)
[九、UDP 适用场景](#九、UDP 适用场景)
一、前言
我们在学习协议的时候,是从应用层自顶向下学习的;今天学习传输层的UDP协议
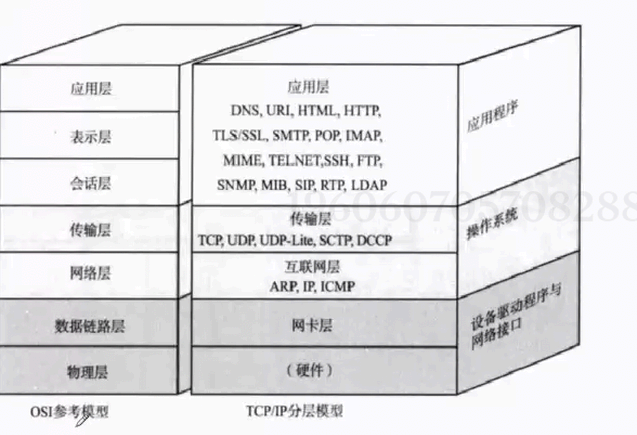
在计算机网络传输层中,最核心的两大协议就是 TCP 和 UDP。相比于复杂严谨的 TCP,UDP 更加轻量、简单。很多应用层协议如 DNS、直播、音视频通话、游戏联机等,底层都默认使用 UDP 协议。今天我们结合网络原理底层知识,完整梳理 UDP 协议的所有核心知识点。
二、网络分层与端口号基础
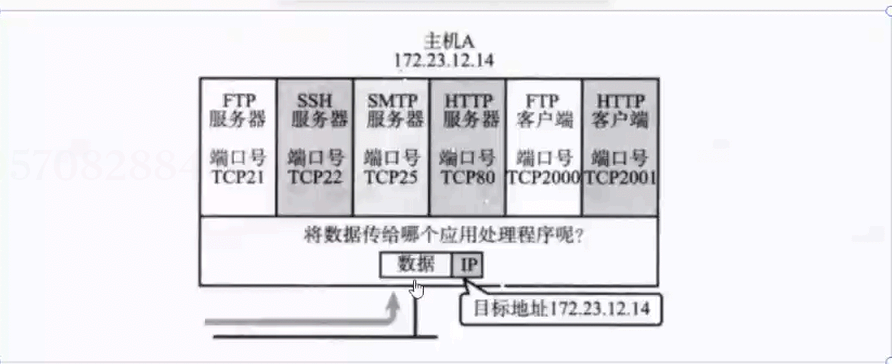
网络通信的本质,其实并不是"主机与主机之间通信",而是"主机上的进程与进程之间通信"。
在网络中,真正进行数据收发的是运行中的应用程序(进程),而不是计算机本身。
因此,想要在网络中唯一标识一个通信进程,需要依靠:
-
IP 地址:用于定位网络中的主机
-
端口号(Port):用于定位主机中的具体进程
二者组合在一起,就构成了 Socket(套接字)。
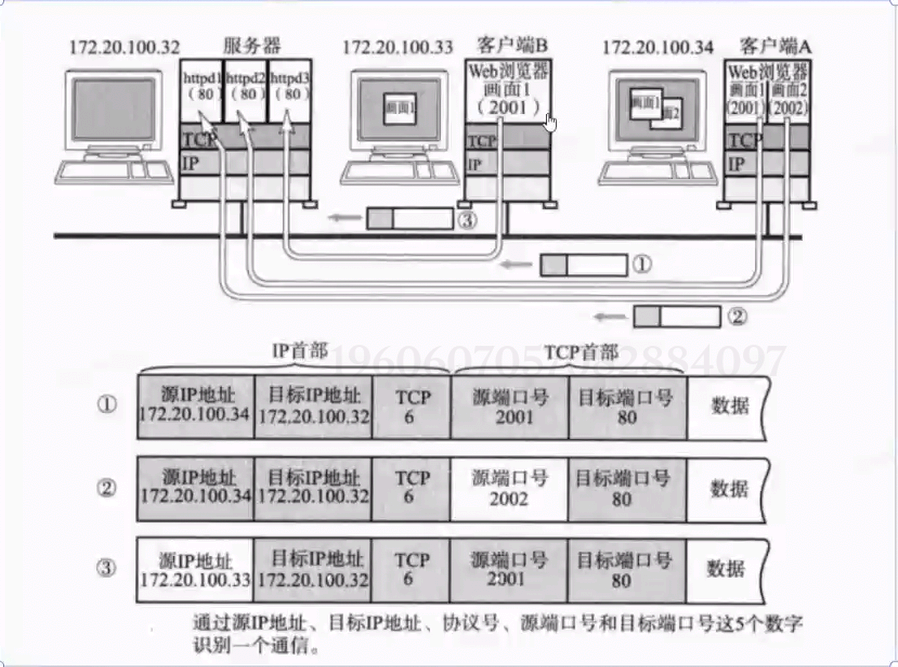
而想要唯一标识一次完整的网络通信,则需要依靠"四元组":源 IP,源端口,目的 IP,目的端口
也就是说,网络中的每一次连接,本质上都是两个 Socket 之间的通信。
端口号的范围划分
1. 0 ~ 1023:知名端口号(Well-Known Port)
这一类端口号专门留给标准的应用层协议使用,例如:
HTTP:80 HTTPS:443 FTP:21 SSH:22 SMTP:25
这些端口都是行业内约定俗成的固定端口,不能随意修改。
可以把它理解成现实生活中的"特殊号码":
110 → 报警
119 → 消防
120 → 急救
用户只需要记住号码,就能找到对应服务。
网络中的知名端口也是同样的道理------客户端通过固定端口,就能快速定位对应的网络服务。
2. 1024 ~ 65535:动态 / 临时端口号
这一部分端口通常由操作系统自动分配给客户端程序使用。
当客户端发起网络请求时,操作系统会从这个区间中临时随机选择一个空闲端口,作为当前连接的源端口。
通信结束后,该端口会被释放,供后续程序继续使用。
端口与进程绑定的两个核心问题
一个进程可以绑定多个端口号吗?
可以。一个进程本质上可以同时提供多个网络服务,因此能够绑定多个端口。
一个端口号可以被多个进程同时绑定吗?
通常不可以。
因为端口号的核心作用,就是在主机中唯一标识一个网络进程。
如果多个进程同时绑定同一个端口,操作系统就无法判断:
"收到的数据到底应该交给哪个进程处理?"
因此,同一时刻,一个端口通常只能被一个进程占用。
三、UDP 报文格式
UDP协议的格式:
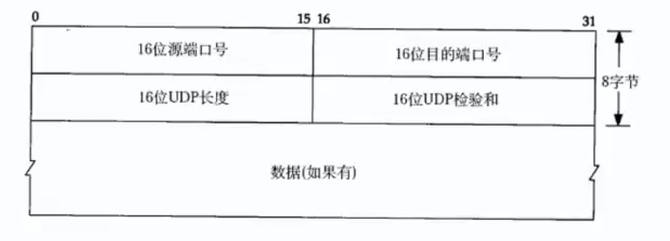
这里的数据指的是应用层(上一层)传输给传输层的数据;数据有可能是网络版本的计算器,request,response,string
| 字段 | 大小 | 作用 |
|---|---|---|
| 源端口号 | 16 位 | 标识发送方进程 |
| 目的端口号 | 16 位 | 标识接收方主机中的目标进程 |
| UDP 长度 | 16 位 | 表示整个 UDP 报文的长度(首部 + 数据) |
| UDP 校验和 | 16 位 | 用于校验数据完整性,检测传输过程中是否出现比特错误 |
我们来解释一下每个部分:
(1)源端口号
用于标识数据从哪个进程发送出来。
当服务器收到数据后,可以根据该端口号知道:
"应该把响应数据返回给客户端的哪个进程。
(2)目的端口号
用于告诉目标主机:"这个 UDP 数据应该交给哪个应用程序处理。
操作系统收到 UDP 报文后,会根据目的端口号进行分用,找到对应进程
(3) UDP 长度
表示整个 UDP 报文的总长度:
UDP 长度 = UDP 首部 + 应用层数据
由于 UDP 首部固定为 8 字节,因此:
UDP 长度 = 8 + Data
这个字段可以帮助接收方正确提取数据边界
(4)UDP 校验和
用于检测数据在传输过程中是否发生错误。
发送方会根据 UDP 数据计算出一个校验值,接收方收到后再次计算:
• 如果结果一致 → 数据正常
• 如果结果不一致 → 数据可能损坏
UDP 只能"发现错误",但不会像 TCP 一样自动重传数据。
报文·完整是报头+有效载荷,我们更多谈的是报头
从代码层面看,UDP 报头本质就是内核中的一个结构体:
cpp
struct udphdr{
_be16 source; // 源端口
_be16 dest; // 目的端口
_be16 len; // UDP长度
_sum16 check; // 校验和
};操作系统通信时无需额外序列化,可直接将结构体报头封装发送,保证内核通信效率。
四、UDP 封装与解包原理
1. 报头与有效载荷分离
UDP 采用定长报头设计,固定 8 字节。
内核读取报文时,直接前 8 字节作为 UDP 首部,剩余部分全部作为应用层有效载荷,分离逻辑简单高效。
2. 分用机制
UDP中包含16位源端口号,16位目的端口号; 根据目的端口号将有效载荷交给目标进程
依靠报文里的目的端口号,内核把解析出的有效载荷,精准交付给对应的应用进程。
3. 无粘包问题
UDP 自身携带 16 位长度字段,内核明确知道每一个 UDP 报文的边界和大小。
报文之间相互独立,一个一个向上交付数据,因此 UDP 不存在粘包问题,属于面向数据包的协议。
4. UDP 校验和作用
以特定算法校验整个报文,保证传输过程中比特位不发生错误。
校验失败:报文直接丢弃,不向上层通知错误
校验成功:正常交付给应用进程
这也体现了 UDP 不可靠的特性。
五、内核视角:UDP 报文封装过程
但网卡不能直接发送数据
因为网络通信必须带:MAC 地址;IP 地址;端口号;校验信息
所以操作系统必须:
- 先管理数据
- 再逐层添加协议头
- 最后交给网卡发送
这就叫:UDP 封装
操作系统内核收到大量网络报文,遵循先描述、再组织的原则管理报文。
内核会创建 sk_buff 内核缓冲区结构体,划分出头空间、二层帧头、IP 头、传输层协议头、数据区、尾空间。
通过移动 data 指针开辟报头空间,使用 C 语言指针和内存拷贝完成协议首部封装,最终将完整报文向下交付给网络层发送。
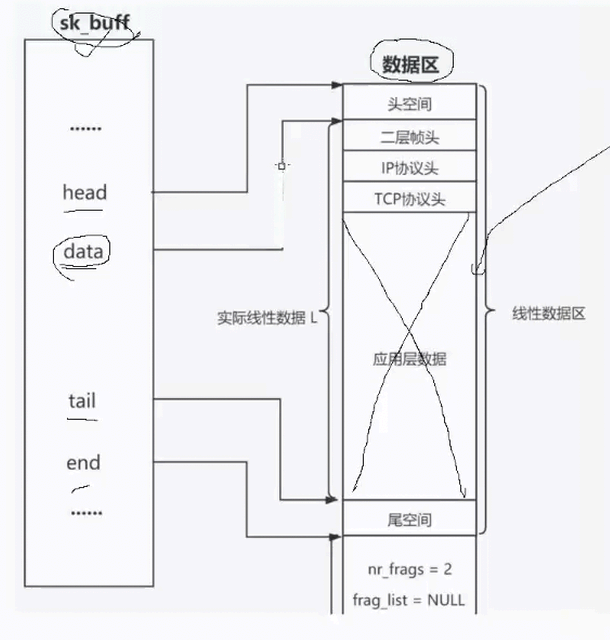
UDP 封装本质不是:
"往后拼接"而是:"data 指针不断向前移动,预留并填写协议头"
六、UDP 核心特点
UDP 传输过程可以形象理解为寄平信、发快递,核心四大特点:
1. 无连接
只需知道对方的 IP + 端口,直接发送数据,不需要提前建立连接,省去握手开销,速度极快。
2. 不可靠
无确认应答、无超时重传机制。
如果网络丢包、路由故障导致数据无法到达对方,UDP 不会重传,也不会给应用层返回任何错误提示,发出去就不管了。
注意:可靠与不可靠只是协议特点,不是优缺点,不同场景各有适用。
3. 面向数据报
应用层交给 UDP 多大的报文,UDP 就原样发送,不拆分、不合并。
发送端一次 sendto 发 100 字节,接收端必须一次 recvfrom 收 100 字节
不能拆分多次接收,收发次数完全对等
这和 TCP 面向字节流、收发次数不一致形成鲜明对比。
4. 全双工通信
UDP 的 Socket 既可以读数据,也可以写数据,支持同时收发,属于全双工模式。
七、UDP 缓冲区机制
无真正发送缓冲区
调用 sendto 发送数据时,数据直接交给内核,内核向下交付网络层直接发送。
因为 UDP 无需等待应答、不用保存已发数据,所以不需要发送缓冲区。
UDP是没有后续动作的,它发送出去的数据是不管数据有没有丢包,直接交给操作系统,所以就不需要保存数据,就没有发送缓冲区
先发送的报文一定先被操作系统接收吗?不一定
就像你和你的朋友先后去北京;你朋友先骑车去,你后去但是是做飞机去
有接收缓冲区
内核维护 UDP 接收缓冲区,但不保证报文按发送顺序到达,网络路由不同会导致报文乱序。
若缓冲区已满,后续到达的 UDP 报文会直接被丢弃。
八、UDP 报文大小限制
单个 UDP 报文最大不能超过 64KB 。
如果应用层需要传输超过 64KB 的数据,UDP 协议本身不支持拆分重组,需要程序员手动对数据分块发送,接收端再手动拼接。
九、UDP 适用场景
基于 UDP 无连接、速度快、面向数据报、允许少量丢包的特性,适合这些场景:
音视频直播、短视频、实时通话
网络游戏联机
DNS 域名解析
广播、组播通信
这类场景都能容忍少量丢包,但对实时性要求极高,正好契合 UDP 的设计理念。