图注意力网络(GAT)深度实战:原理推导+PyG代码+从零开始写GAT层(附注意力可视化)
本文深入剖析图注意力网络(GAT)的核心思想,结合 Cora 数据集,既给出基于PyTorch Geometric 的高效实现,也手把手带你从零手写GAT层,彻底搞懂注意力机制的内部运作。
一、为什么需要图注意力?
图神经网络(GNN)已经成为处理图结构数据的主流方法。最经典的图卷积网络(GCN)通过邻接矩阵的对称归一化来聚合邻居信息,但它有一个固有缺陷:所有邻居的聚合权重是固定的(仅依赖于节点度),无法根据节点特征动态调整。这就好比在社交网络中,无论朋友与你的兴趣是否相同,他们对你观点的影响权重都一样------这显然不合理。
图注意力网络(GAT) 应运而生。它引入了自注意力机制,让每个节点能够自动学习其邻居的重要性,从而实现更灵活、更强大的信息聚合。
二、GAT 核心原理
本章将从零开始拆解图注意力网络的数学原理,不仅给出公式,更解释每个设计背后的动机、直观含义和数值计算的过程。
2.1 图注意力层
给定一个图,节点 i 的输入特征为 hi∈RF( F 为输入维度)。GAT 层输出新的节点特征 hi′∈RF′( F′ 为输出维度)。整个过程分为五个子步骤。
2.1.1 线性变换:提升表达力
每个节点首先经过一个共享的线性变换(参数矩阵 W∈RF′×F),将特征映射到高维空间:
hi′=Whi
这一步的目的是让节点特征拥有足够的容量去计算注意力。如果不做变换,原始特征可能过于简单,难以衡量节点之间的相关性。
2.1.2 计算未归一化的注意力分数 eij
对于每条边 (i,j)(包括自环),我们想要计算邻居 j 对节点 i 的重要性。GAT 采用一个单层前馈神经网络来计算:
eij=LeakyReLU(aThi′∥hj′)
通俗理解 :对于每一条边 (i,j),我们把两个节点的新特征 hi′ 和 hj′ 拼接 成一根更长的向量,然后用一个可学习的小型神经网络(向量 a)算出它们之间的"原始亲和力" eij。负数部分用 LeakyReLU 保留一小点"信号"(而不是直接砍掉),因为有时候不相关的邻居也值得被轻微抑制。 其中:
- ∥ 表示向量拼接(concatenation)。拼接后得到 2F′ 维向量。
- a∈R2F′ 是一个可学习的注意力向量(相当于一个权重向量)。
- aT⋅ 表示点积,得到一个标量。
- LeakyReLU 是激活函数,负斜率通常取 0.2(见 2.1.3 的解释)。
为什么要拼接而不是直接相加或点积?
原论文 (Veličković, P., et al. Graph Attention Networks. ICLR 2018. )对比了多种注意力形式(加法注意力、点积注意力等),发现 拼接+线性层 的效果最好。直觉上,拼接保留了原始特征的全部信息,让注意力层可以学习更复杂的非线性关系。
数值例子
假设 F′=2,节点 i 和 j 变换后的特征分别为:
hi′=0.2,0.5,hj′=0.3,0.1
注意力向量初始化为:
a=0.1,0.2,0.3,0.4T
拼接后得到 0.2,0.5,0.3,0.1,点积计算:
0.2×0.1+0.5×0.2+0.3×0.3+0.1×0.4=0.25
LeakyReLU(0.25) = 0.25(正区间保持不变)。
如果结果为负数(例如 -0.3),LeakyReLU 会输出 0.2×(−0.3)=−0.06,保留微弱信号。
2.1.3 为什么用 LeakyReLU 而不是普通 ReLU?
普通 ReLU 将所有负数量为 0,这意味着如果注意力分数 eij 为负,邻居 j 对 i 的贡献就完全消失。但这可能丢失有用信息:在某些任务中,负的注意力(即"排斥"关系)也是有意义的(例如在异质图中,不同类别的邻居应该被抑制)。LeakyReLU 允许一个很小的负梯度(通常取 0.2),让模型能够学习"不关注"或"负相关"的关系。
2.1.4 局部 Softmax 归一化
为了使得不同邻居的权重可比,我们对每个节点 i 的所有邻居(包括自身)做 softmax 归一化:
αij=∑k∈N(i)∪{i}exp(eik)exp(eij)
通俗理解 :对每个节点 i,我们把它所有邻居(包括自己)的原始分数 eij 放在一起,做一个 竞争性的归一化------分数高的邻居获得更大的权重,分数低的权重趋近于零。这样保证所有邻居的权重之和为 1,且权重大小反映了相对重要性。
其中 N(i) 是节点 i 的一阶邻居(不含自身)。注意这里包含了自环,这样节点可以在聚合时保留自己的特征。
数值稳定性技巧:在代码实现中,通常会先减去最大值:
exp(eij−kmaxeik)
这是为防止指数溢出。GAT 的官方实现也采用了这一技巧。
2.1.5 加权聚合与激活函数
最后,对变换后的邻居特征进行加权求和,并通过一个非线性激活函数 σ(原论文使用 ELU):
hi′′=σ j∈N(i)∪{i}∑αijhj′
通俗理解 :每个节点把自己的邻居(含自己)的特征 hj′ 按刚刚算出的注意力权重 αij 进行加权平均,得到一张"综合画像"。最后再用激活函数(如 ELU)加入非线性,让模型能表达更复杂的模式。
ELU 相比 ReLU 允许负值,使激活均值更接近 0,从而加速收敛并缓解神经元死亡问题。
2.2 多头注意力:从不同角度看世界
单头注意力可能只捕捉一种类型的关系(例如"同主题")。为了让模型能同时关注多种关系(例如"同主题"、"高引用"、"近期发表"等),GAT 引入了多头注意力。
2.2.1 每个头的独立计算
假设我们使用 K 个注意力头。每个头拥有独立的参数 W(k) 和 a(k),各自执行 2.1 节描述的完整过程,得到该头的输出 hi(k)。
2.2.2 两种融合方式:拼接 vs 平均
- 隐藏层(拼接):将各个头的输出沿特征维度拼接起来:
hi′= k=1Kσ(j∑αij(k)W(k)hj)
输出维度为 K⋅F′。这样每个头的信息独立保留,增强模型表达能力。
通俗理解 :就像请了 K 个专家,每个专家独立地用自己的"眼镜" W(k) 和"评判标准" a(k) 观察同一批邻居,得到一份看法(特征向量)。然后把这 K 份看法 拼接 在一起,形成一个更全面的综合判断。不同的专家可能擅长捕捉不同类型的关系(比如一个关注"同领域引用",另一个关注"高影响力引用")。
- 输出层(平均):对所有头的输出逐元素平均,再激活:
hi′′=σ(K1k=1∑Kj∑αij(k)W(k)hj)
输出维度为 F′。平均操作使得模型更加稳定,减少过拟合。
通俗理解:在最后一层(分类层),不再拼接所有专家的意见,而是把他们平均一下,得到一个更稳健、更平滑的判断。这类似于集成学习中的投票或平均,能有效减少过拟合。
为什么隐藏层用拼接、输出层用平均?
隐藏层需要丰富的表示,拼接可以保留多头差异;输出层直接做分类,平滑的表示更有利于泛化。原论文的实验也证实了这一设计的合理性。
2.2.3 头数的选择
原论文在 Cora 上实验表明,当 K 从 1 增加到 8 时,准确率提升约 3%~5%;继续增加到 16 则收益甚微且显存翻倍。因此 8 头是一个常用设置。
2.3 GAT vs GCN
| 特性 | GCN | GAT |
|---|---|---|
| 聚合权重 | 固定(基于度) | 动态(基于特征) |
| 是否可学习 | 否 | 是 |
| 解释性 | 弱 | 强(可输出注意力权重) |
| 参数数量 | 少 | 较多 |
| 适用场景 | 同质性图 | 异质性图、需解释的任务 |
| 表达能力 | 受限于固定的低通滤波 | 理论上可以学习任意邻居重要性 |
GCN 的权重只取决于图的拓扑结构(度),而 GAT 的权重取决于节点特征,因此可以适应不同的节点内容。
2.4 图注意力与 Transformer 自注意力的联系与区别(💡扩展对比,可跳过)
很多读者熟悉 Transformer 的自注意力机制,这里做一个对比:
| 方面 | Transformer 自注意力 | GAT |
|---|---|---|
| 输入结构 | 序列(全连接,每个位置与所有位置交互) | 图(稀疏边,仅邻居交互) |
| 注意力计算范围 | 所有位置对 | 仅邻居(+自环) |
| 位置编码 | 需要显式加入(sin/cos 或可学习) | 不需要(图结构自然提供了邻域信息) |
| 多头融合 | 通常拼接后线性变换 | 拼接或平均 |
| 归一化 | Softmax 在整个序列上 | Softmax 在每个节点的邻居上 |
| 复杂度 | O(N2) | O(E)(通常远小于 N2) |
相同点:都利用注意力权重动态选择重要信息,都使用多头机制增强表达。
2.5 GAT 的归纳偏置
归纳偏置(Inductive Bias)是指模型对数据的内在假设。GAT 具有以下偏置:
-
置换不变性:节点的顺序不影响注意力计算结果。只要图结构相同,重新排列节点 ID 不影响输出。
-
图结构依赖:注意力只计算邻居(含自环),符合"局部性"假设------节点只受其直接邻居影响(虽然多层后可以间接捕获多跳信息)。
-
特征驱动 :节点的重要性完全由其特征决定,而非仅由度或位置决定。
这些偏置使得 GAT 适合处理节点特征丰富、图结构稀疏的场景,例如引文网络、社交网络、知识图谱等。
三、Cora 数据集与实验设置
3.1 Cora 数据集简介
Cora 是一个经典的引文网络数据集,包含 2708 篇机器学习论文,分为 7 个类别。每篇论文用一个 1433 维的词袋向量表示。图中有 5429 条引用边(无向处理后更多)。训练集仅使用 140 个标签(每类 20 个),验证集 500 个,测试集 1000 个------这是典型的半监督学习设定。
3.2 实验环境
- Python 3.11
- PyTorch 2.x + PyTorch Geometric
- Cora 数据由
Planetoid自动下载
四、GAT 代码实现详解
下面给出完整的 GAT 模型实现(已添加详细注释)。我们定义了一个两层 GAT:第一层 8 个头,每个头输出 8 维,拼接后得到 64 维;第二层单头,输出 7 维 logits,最后接 log_softmax。
python
import torch
import torch.nn.functional as F
from torch_geometric.nn import GATConv
class GAT(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels, heads=8, dropout=0.6):
super().__init__()
# 第一层:多头注意力,拼接输出
self.conv1 = GATConv(in_channels, hidden_channels, heads=heads, dropout=dropout, concat=True)
# 第二层:单头注意力,不拼接(输出 out_channels 维)
self.conv2 = GATConv(hidden_channels * heads, out_channels, heads=1, dropout=dropout, concat=False)
self.dropout = dropout
def forward(self, x, edge_index):
# 输入 dropout
x = F.dropout(x, p=self.dropout, training=self.training)
# 第一层 + ELU
x = self.conv1(x, edge_index)
x = F.elu(x)
# 再次 dropout
x = F.dropout(x, p=self.dropout, training=self.training)
# 第二层(输出 logits)
x = self.conv2(x, edge_index)
# 输出对数概率(配合 nll_loss)
return F.log_softmax(x, dim=1)4.1 训练循环与早停
训练时使用 Adam 优化器(lr=0.005, weight_decay=5e-4),损失函数为负对数似然损失(仅计算训练集节点)。加入早停(patience=20)和模型保存,防止过拟合。
python
model = GAT(dataset.num_features, 8, dataset.num_classes, heads=8, dropout=0.6).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=5e-4)
best_val_acc = 0
best_model_state = None
patience_counter = 0
for epoch in range(1, 201):
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
# 验证
model.eval()
with torch.no_grad():
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
val_acc = (pred[data.val_mask] == data.y[data.val_mask]).float().mean().item()
if val_acc > best_val_acc:
best_val_acc = val_acc
patience_counter = 0
best_model_state = model.state_dict().copy()
else:
patience_counter += 1
if patience_counter >= 20:
break
model.load_state_dict(best_model_state)4.2 从零手写 GAT 层:揭露底层细节(💡源码底层实现,不想手写可跳过)
上一节我们直接使用了 PyTorch Geometric 封装的 GATconv。它高效、稳定,但对初学者来说如同一个"黑盒"。为了真正理解图注意力机制的内部运作,这一节我们将手动实现一个功能完备的 GAT 层(仅依赖 PyTorch 和 PyG 的工具函数 add_self_loops 和 softmax)。通过这个练习,你能彻底看清公式到代码的映射关系,也为日后自定义 GNN 层打下基础。
4.2.1 代码结构总览
我们实现的 GATconvManual 类支持:
- 多头注意力(
heads参数) - 隐藏层拼接模式(
concat=True)和输出层平均模式(concat=False) - 注意力权重的
dropout - 可选返回注意力系数(用于可视化)
核心逻辑遵循原论文的五个步骤:线性变换 → 计算注意力分数 → 局部 softmax → dropout → 加权聚合 → 多头融合。
下面是完整的代码实现(已附带详细注释):
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.utils import add_self_loops, softmax
class GATConvManual(nn.Module):
"""
手动实现的图注意力卷积层 (Graph Attention Network Layer)
参数:
in_channels (int): 输入特征维度
out_channels (int): 每个注意力头输出的特征维度
heads (int): 注意力头数,默认为 1
concat (bool): 是否将多头输出拼接 (True) 还是求平均 (False)
- 隐藏层通常使用 True,输出层使用 False
dropout (float): 注意力权重的 dropout 概率,默认为 0.6
negative_slope (float): LeakyReLU 的负斜率,默认为 0.2
"""
def __init__(self, in_channels, out_channels, heads=1, concat=True,
dropout=0.6, negative_slope=0.2):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.heads = heads
self.concat = concat
self.dropout = dropout
self.negative_slope = negative_slope
# 为每个注意力头创建一个独立的线性变换层 W^(h)
# 输入: (N, in_channels) -> 输出: (N, out_channels)
self.lins = nn.ModuleList([
nn.Linear(in_channels, out_channels, bias=False)
for _ in range(heads)
])
# 为每个头定义注意力向量 a^(h),形状为 (2 * out_channels, 1)
# 用于计算边的注意力分数:e_ij = LeakyReLU( a^T [W h_i || W h_j] )
self.attentions = nn.ParameterList([
nn.Parameter(torch.empty(2 * out_channels, 1))
for _ in range(heads)
])
# 使用 Xavier 均匀初始化注意力向量
for att in self.attentions:
nn.init.xavier_uniform_(att)
# 偏置项(仅在 concat=False 时使用,即输出层)
if concat:
self.bias = None
else:
self.bias = nn.Parameter(torch.empty(out_channels))
nn.init.zeros_(self.bias)
def forward(self, x, edge_index, return_attention_weights=False):
"""
前向传播
参数:
x (Tensor): 节点特征矩阵,形状 (N, in_channels)
edge_index (LongTensor): 边索引,形状 (2, E),格式 [源节点, 目标节点]
return_attention_weights (bool): 是否返回注意力权重,用于可视化
返回:
output (Tensor):
- 若 concat=True: 形状 (N, heads * out_channels)
- 若 concat=False: 形状 (N, out_channels)
(可选) (edge_index, attention_weights):
attention_weights 形状为 (E, heads),每条边每个头的注意力权重
"""
N, _ = x.shape
# 1. 添加自环 (self-loops),使节点能够保留自身信息
# GATConv 默认会添加自环,否则节点无法聚合自己的特征
edge_index, _ = add_self_loops(edge_index, num_nodes=N)
# 存储每个头的输出和注意力权重
all_head_outputs = [] # 每个元素形状 (N, out_channels)
all_attentions = [] # 每个元素形状 (E,)
# 2. 对每个注意力头分别计算
for head in range(self.heads):
# ----- 2.1 线性变换 -----
# 将输入特征 x 映射到该头的特征空间
x_prime = self.lins[head](x) # (N, out_channels)
# ----- 2.2 提取边两端节点的特征 -----
row, col = edge_index # row: 源节点, col: 目标节点
x_i = x_prime[row] # 源节点特征 (E, out_channels)
x_j = x_prime[col] # 目标节点特征 (E, out_channels)
# ----- 2.3 计算未归一化的注意力分数 e_ij -----
# 将源节点和目标节点特征拼接
x_cat = torch.cat([x_i, x_j], dim=-1) # (E, 2 * out_channels)
a = self.attentions[head] # (2 * out_channels, 1)
e = torch.matmul(x_cat, a).squeeze(-1) # (E,)
# 应用 LeakyReLU 激活
e = F.leaky_relu(e, self.negative_slope)
# ----- 2.4 按目标节点进行 softmax 归一化 -----
# 对于每个目标节点 j,对所有指向它的源节点 i 的 e_ij 做 softmax
# 得到注意力权重 alpha_ij = softmax_j(e_ij)
alpha = softmax(e, col, num_nodes=N) # (E,)
# ----- 2.5 对注意力权重应用 Dropout (训练时) -----
if self.training and self.dropout > 0:
alpha = F.dropout(alpha, p=self.dropout)
# ----- 2.6 加权聚合邻居特征 -----
# 核心修正:聚合的是源节点的特征 (x_i),而不是目标节点特征 (x_j)
# 公式: h'_j = sigma( sum_{i in N(j)} alpha_ij * W h_i )
# 因此需要将 (alpha * x_i) 累加到对应的目标节点 col 上
out = torch.zeros(N, self.out_channels, device=x.device)
# scatter_add_(dim, index, src)
# dim=0: 按行索引
# index: 目标节点索引 (col),形状需与 src 匹配
# src: (alpha * x_i) 每个边携带的加权特征
# 注意:col 中可能有重复索引,scatter_add 会累加
out = out.scatter_add_(
0, # 按第 0 维(节点维度)累加
col.unsqueeze(-1).expand_as(x_i), # 形状 (E, out_channels),每行指定目标节点
alpha.unsqueeze(-1) * x_i # 加权后的源节点特征
)
all_head_outputs.append(out) # (N, out_channels)
all_attentions.append(alpha) # (E,)
# 3. 融合多个注意力头的结果
if self.concat:
# 隐藏层:将各头输出沿特征维度拼接
output = torch.cat(all_head_outputs, dim=-1) # (N, heads * out_channels)
else:
# 输出层:对各头输出求平均,并加上偏置
output = torch.stack(all_head_outputs, dim=-1) # (N, out_channels, heads)
output = output.mean(dim=-1) # (N, out_channels)
if self.bias is not None:
output = output + self.bias
# 4. 根据要求返回注意力权重
if return_attention_weights:
# 将所有头的注意力权重堆叠为 (E, heads)
attn_all = torch.stack(all_attentions, dim=1) # (E, heads)
return output, (edge_index, attn_all)
else:
return output4.2.2 核心细节解读
为什么要加自环?
add_self_loops(edge_index, num_nodes=N) 为每个节点添加一条指向自己的边。这样在聚合时,节点自身的特征也会被纳入,相当于保留了原始信息。原论文中明确使用了自环。
softmax(e, col, num_nodes) 做了什么?
PyG 提供的 softmax(src, index, num_nodes) 会根据 index 分组计算 softmax。这里我们传入目标节点 col,因此对每个目标节点的所有入边分别做 softmax,这正是图注意力所需的局部归一化。
scatter_add_ 的妙用
加权聚合需要将每条边的贡献累加到对应的目标节点上。scatter_add_(dim, index, src) 会将 src 按 index 指定的位置累加到原张量中。我们使用:
out.scatter_add_(0, col.unsqueeze(-1).expand_as(x_i), alpha.unsqueeze(-1) * x_i) 实现:
col.unsqueeze(-1).expand_as(x_i)将col从 (E,) 扩展为 (E, out_channels),每一列都是相同的目标节点 ID。alpha.unsqueeze(-1) * x_i得到每条边的加权特征。- 最终每个目标节点收集到所有入边的加权和。
多头融合的两种模式
-
隐藏层 :
concat=True,直接将各头的输出拼接。此时输出维度为heads * out_channels,信息更丰富。 -
输出层 :
concat=False,对各头输出求平均,然后加偏置。这相当于集成学习的平均策略,使输出更稳定。
4.2.3 与官方 GATConv 的对比
| 方面 | 官方 GATConv (PyG) | 手动实现 GATConvManual |
|---|---|---|
| 线性变换 | 所有头共享一个大的权重矩阵,内部再拆分 | 每个头独立线性层,直观但略慢 |
| 注意力计算 | 高度优化的 C++/CUDA 算子 | 纯 PyTorch,适合用来理解原理 |
| 边处理 | 自动处理稀疏格式,支持批处理 | 使用 PyG 工具函数,思路一致 |
| 功能 | 支持边权、注意力 mask、负斜率等 | 实现核心功能,易于扩展 |
| 代码可读性 | 底层实现复杂(约 200 行混合代码) | 约 70 行 Python,完全透明 |
**注意:**手动实现的 GATConvManual 使用循环遍历每个注意力头,在大规模或大量头数时性能明显低于官方实现,建议仅在学习和调试时使用。 结论:生产环境请使用官方实现,理解原理则推荐手写版本。
4.2.4 如何在原模型中使用?
只需替换 GAT 类中的 conv1 和 conv2 即可,其余代码(训练、测试、可视化)完全不用修改:
python
# 原代码
# from torch_geometric.nn import GATConv
# self.conv1 = GATConv(in_channels, hidden_channels, heads=8, dropout=0.6, concat=True)
# 改为
self.conv1 = GATConvManual(in_channels, hidden_channels, heads=8, dropout=0.6, concat=True)
self.conv2 = GATConvManual(hidden_channels * 8, out_channels, heads=1, dropout=0.6, concat=False)训练后,可以调用 model.conv1(x, edge_index, return_attention_weights=True) 获取注意力权重进行可视化,与官方版本兼容。
五、完整代码展示
python
# ==================== 导入必要的库 ====================
import os
# 解决 macOS 上 Intel MKL 库重复加载的警告(不影响正确性)
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
import torch
import torch.nn.functional as F # 包含激活函数、dropout、损失函数等
from torch_geometric.datasets import Planetoid # PyG 内置数据集加载器
from torch_geometric.nn import GATConv # 图注意力卷积层
import matplotlib.pyplot as plt
import numpy as np
from sklearn.manifold import TSNE # t-SNE 降维可视化
# ==================== 1. 加载 Cora 数据集 ====================
# Planetoid 是 PyG 提供的类,用于加载 Cora、CiteSeer、PubMed 等引文网络
# root='D:\\数据集':数据存放目录(不存在会自动下载)
# name='Cora':指定数据集名称
dataset = Planetoid(root='D:\\数据集', name='Cora')
# dataset 是单图数据集(len(dataset)==1),索引 0 取出唯一的 Data 对象
data = dataset[0]
print("=" * 50)
print("Cora 数据集信息:")
print(f" 节点数: {data.num_nodes}") # 2708 篇论文
print(f" 边数: {data.num_edges}") # 原始无向边数(双向存储后一般为 10556 或 5429 取决于版本)
print(f" 特征维度: {dataset.num_features}") # 1433 维词袋向量
print(f" 类别数: {dataset.num_classes}") # 7 个研究领域
print(f" 训练集: {data.train_mask.sum().item()} 个节点") # 140(每类 20 个)
print(f" 验证集: {data.val_mask.sum().item()} 个节点") # 500
print(f" 测试集: {data.test_mask.sum().item()} 个节点") # 1000
print("=" * 50)
# ==================== 2. 定义 GAT 模型 ====================
class GAT(torch.nn.Module):
"""
两层图注意力网络(Graph Attention Network)
架构:
- 第一层:多头注意力(8 头),输出拼接后的 64 维嵌入
- 第二层:单头注意力,输出 7 维 logits(原始分数)
- 最后应用 log_softmax 输出对数概率
"""
def __init__(self, in_channels, hidden_channels, out_channels, heads=8, dropout=0.6):
"""
参数:
in_channels : 输入特征维度(Cora 为 1433)
hidden_channels: 每个注意力头输出的特征维度(通常设为 8)
out_channels : 输出类别数(Cora 为 7)
heads : 第一层的注意力头数(默认 8)
dropout : Dropout 概率(默认 0.6)
"""
super().__init__()
# ---------- 第一层图注意力卷积 ----------
# in_channels=1433, out_channels=8, heads=8, concat=True
# 每个头独立地将 1433 维映射到 8 维,然后拼接得到 8*8=64 维
# dropout 作用于注意力系数(在 softmax 前后均可)
self.conv1 = GATConv(
in_channels=in_channels,
out_channels=hidden_channels,
heads=heads,
dropout=dropout,
concat=True # 拼接多头结果
)
# ---------- 第二层图注意力卷积 ----------
# in_channels = hidden_channels * heads = 64
# out_channels = 7 (类别数)
# heads=1, concat=False: 单头,输出直接为 7 维
self.conv2 = GATConv(
in_channels=hidden_channels * heads,
out_channels=out_channels,
heads=1,
dropout=dropout,
concat=False
)
self.dropout = dropout
def forward(self, x, edge_index):
"""
前向传播
参数:
x : 节点特征矩阵,形状 (N, in_channels) -> Cora: (2708, 1433)
edge_index : 边索引,形状 (2, E) -> Cora 原始边数(无向边双向存储,且 GATConv 会自动加自环)
返回:
log_probs : 每个节点的对数概率,形状 (N, out_channels) -> (2708, 7)
"""
# 在进入第一层之前对输入特征应用 Dropout
# p=self.dropout (0.6),训练时随机将 60% 元素置零并缩放,评估时无操作
x = F.dropout(x, p=self.dropout, training=self.training)
# 第一层图注意力卷积
# 内部计算:
# 1. 线性变换:每个头独立,W^(h): (hidden_channels, in_channels)
# 2. 为每条边计算注意力分数 e_ij = LeakyReLU(a^T [W h_i || W h_j])
# 3. 对每个节点 i 的邻居(含自环)做 softmax 得到 α_ij
# 4. 加权聚合邻居特征,得到每个头的输出 (N, hidden_channels)
# 5. 因为 concat=True,将 8 个头输出拼接 → (N, hidden_channels*heads) = (2708, 64)
x = self.conv1(x, edge_index)
# ELU 激活函数:正区间线性,负区间 α(e^x - 1),默认 α=1
# 相比 ReLU,ELU 允许负值,使激活均值更接近 0,加速收敛且缓解神经元死亡
x = F.elu(x)
# 在进入第二层之前再次 Dropout
x = F.dropout(x, p=self.dropout, training=self.training)
# 第二层图注意力卷积
# 输入 (2708, 64),输出 (2708, 7) 作为 logits(原始分类分数)
# 仍然是图注意力,但只有单头,且 concat=False
x = self.conv2(x, edge_index)
# 输出对数概率 log_softmax
# 对 logits 沿类别维度 (dim=1) 计算 softmax 再取对数,结果 ≤ 0
# 优点:数值稳定,且与 F.nll_loss 配合构成交叉熵
return F.log_softmax(x, dim=1)
# ==================== 3. 训练设置 ====================
# 检测是否有 GPU,如果没有则使用 CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 实例化 GAT 模型,并移动到指定设备(参数变为 GPU/CPU 上的张量)
model = GAT(
in_channels=dataset.num_features, # 1433
hidden_channels=8, # 每个头输出 8 维
out_channels=dataset.num_classes, # 7
heads=8,
dropout=0.6
).to(device)
# 将数据(特征、边、标签、掩码)也移动到相同设备
data = data.to(device)
# 定义优化器(Adam 自适应学习率)
# model.parameters():所有可训练参数
# lr=0.005:学习率
# weight_decay=5e-4:L2 正则化(权重衰减),防止过拟合
optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=5e-4)
# ==================== 4. 训练与测试函数 ====================
def train():
"""
执行一个训练 epoch:
1. 设置模型为训练模式(启用 Dropout)
2. 清空上一轮的梯度
3. 前向传播得到对数概率
4. 计算损失(仅训练集节点上的负对数似然)
5. 反向传播计算梯度
6. 优化器更新参数
7. 返回当前损失(标量)
"""
model.train() # 切换到训练模式(Dropout 生效)
optimizer.zero_grad() # 将所有参数的梯度清零(避免累积)
# 前向传播:得到所有节点的对数概率,形状 (2708, 7)
out = model(data.x, data.edge_index)
# 计算损失:只关注训练集节点(train_mask = True 的节点)
# out[data.train_mask] : 选取训练集节点的对数概率,形状 (140, 7)
# data.y[data.train_mask] : 对应的真实标签 (140,)
# F.nll_loss : 负对数似然损失 = -1/N * sum(log_prob[label])
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward() # 反向传播,计算每个参数的梯度
optimizer.step() # 根据梯度更新参数
return loss.item() # 返回 Python 浮点数(用于记录)
@torch.no_grad() # 装饰器:此函数内不计算梯度,节省内存和计算
def test():
"""
评估模型在训练集、验证集、测试集上的准确率
返回:[train_acc, val_acc, test_acc]
"""
model.eval() # 切换到评估模式(Dropout 关闭)
out = model(data.x, data.edge_index) # 前向传播,得到对数概率 (2708, 7)
pred = out.argmax(dim=1) # 取概率最大的类别作为预测,形状 (2708,)
accs = []
# 依次在训练集、验证集、测试集掩码上计算准确率
for mask in [data.train_mask, data.val_mask, data.test_mask]:
# pred[mask] : 当前集合的预测标签
# data.y[mask] : 真实标签
# .eq() 逐元素比较是否相等,返回布尔张量
correct = pred[mask].eq(data.y[mask]).sum().item() # 正确个数
total = mask.sum().item() # 总样本数
acc = correct / total
accs.append(acc)
return accs # [train_acc, val_acc, test_acc]
# ==================== 5. 训练循环 ====================
print("\n开始训练...")
best_val_acc = 0 # 记录历史最佳验证准确率
best_test_acc = 0 # 对应最佳验证准确率的测试准确率
best_model_state = None # 保存最佳模型的参数(字典)
patience = 20 # 早停耐心:连续 20 轮验证准确率未提升则停止
patience_counter = 0 # 当前连续未提升的轮数
# history 字典记录每个 epoch 的损失和三个准确率,用于绘图
history = {'train': [], 'val': [], 'test': [], 'loss': []}
for epoch in range(1, 201): # 最多训练 200 个 epoch
loss = train() # 训练一个 epoch,返回损失
train_acc, val_acc, test_acc = test() # 评估当前模型
# 记录历史
history['train'].append(train_acc)
history['val'].append(val_acc)
history['test'].append(test_acc)
history['loss'].append(loss)
# ----------------- 早停与模型保存逻辑 -----------------
if val_acc > best_val_acc:
# 验证准确率提升:更新最佳值,重置计数器,保存当前模型参数
best_val_acc = val_acc
best_test_acc = test_acc
patience_counter = 0
# state_dict() 返回包含模型所有参数的字典,copy() 深拷贝避免后续变化
best_model_state = model.state_dict().copy()
else:
patience_counter += 1
# 每 20 个 epoch 打印一次训练状态
if epoch % 20 == 0:
print(f"Epoch {epoch:03d} | Loss: {loss:.4f} | "
f"Train: {train_acc:.4f} | Val: {val_acc:.4f} | Test: {test_acc:.4f}")
# 早停触发
if patience_counter >= patience:
print(f"\nEarly stopping at epoch {epoch}")
break
# 训练结束后,恢复最佳模型参数(用于最终测试和可视化)
if best_model_state is not None:
model.load_state_dict(best_model_state)
print(f"\n最佳验证准确率: {best_val_acc:.4f}")
print(f"对应测试准确率: {best_test_acc:.4f}")
# ==================== 6. 训练过程可视化 ====================
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 左图:损失曲线
axes[0].plot(history['loss'], label='Loss', color='red')
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('Loss')
axes[0].set_title('Training Loss')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 右图:准确率曲线
axes[1].plot(history['train'], label='Train', color='blue')
axes[1].plot(history['val'], label='Val', color='green')
axes[1].plot(history['test'], label='Test', color='red')
axes[1].set_xlabel('Epoch')
axes[1].set_ylabel('Accuracy')
axes[1].set_title('Accuracy Curves')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('gat_cora_training.png', dpi=150)
plt.show()
print("训练可视化已保存至 gat_cora_training.png")
# ==================== 7. 注意力权重可视化 ====================
@torch.no_grad()
def visualize_attention():
"""
提取第一层 GATConv 的注意力系数,并分析其分布。
注意:GATConv 在 forward 时若 return_attention_weights=True,会额外返回注意力权重。
"""
model.eval()
x, edge_index = data.x, data.edge_index
# 注意:此处 dropout 虽然写了,但 training=False 实际上不执行丢弃,仅保持接口一致
x = F.dropout(x, p=0.6, training=False)
# 调用第一层卷积,并要求返回注意力权重
# out: 第一层输出(不关心),attn_weights: (edge_index, attention)
out, attn_weights = model.conv1(x, edge_index, return_attention_weights=True)
# 解包:edge_index_attn 是内部重排的边索引(与 attention 的行对应)
# attn: 形状 (num_edges, heads) = (13264, 8)(因为 GATConv 自动加了自环)
edge_index_attn, attn = attn_weights
print(f"\n注意力权重统计:")
print(f" 边数: {attn.shape[0]}") # 实际参与计算的边数(含自环)
print(f" 注意力头数: {attn.shape[1]}") # 8
print(f" 平均注意力: {attn.mean():.4f}")
print(f" 最大注意力: {attn.max():.4f}")
# 取第一个注意力头的权重进行分析(也可以分析其他头)
attn_head0 = attn[:, 0].cpu().numpy()
# 绘制直方图:观察权重分布(大多数边权重较小,少数关键边权重较大)
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.hist(attn_head0, bins=50, color='skyblue', edgecolor='black')
plt.xlabel('Attention Weight')
plt.ylabel('Frequency')
plt.title('Distribution of Attention Weights (Head 0)')
# 绘制权重最高的前 100 条边的水平条形图
plt.subplot(1, 2, 2)
top_k = min(100, len(attn_head0))
# argsort 升序,取最后 top_k 个索引(即最大权重的索引)
top_indices = np.argsort(attn_head0)[-top_k:]
plt.barh(range(top_k), attn_head0[top_indices], color='coral')
plt.xlabel('Attention Weight')
plt.ylabel('Edge Index (sorted)')
plt.title(f'Top-{top_k} Attention Weights')
plt.tight_layout()
plt.savefig('gat_attention_visualization.png', dpi=150)
plt.show()
print("注意力可视化已保存至 gat_attention_visualization.png")
visualize_attention()
# ==================== 8. 节点嵌入 t-SNE 可视化 ====================
@torch.no_grad()
def visualize_embeddings():
"""
将模型输出的对数概率(最后一层特征)通过 t-SNE 降维到 2D 并绘图,
观察不同类别的节点是否聚集。
"""
model.eval()
out = model(data.x, data.edge_index) # 对数概率 (2708, 7)
# 将输出作为每个节点的嵌入向量(也可使用第一层的 64 维嵌入)
embeddings = out.cpu().numpy() # 转为 numpy
labels = data.y.cpu().numpy() # 真实标签
# t-SNE 降维:n_components=2 降到 2 维,perplexity=30 控制局部/全局平衡
tsne = TSNE(n_components=2, random_state=42, perplexity=30)
embeddings_2d = tsne.fit_transform(embeddings) # 形状 (2708, 2)
# 绘图:按真实类别着色
plt.figure(figsize=(10, 8))
colors = plt.cm.tab10(np.linspace(0, 1, dataset.num_classes))
for i in range(dataset.num_classes):
mask = labels == i
plt.scatter(embeddings_2d[mask, 0], embeddings_2d[mask, 1],
c=[colors[i]], label=f'Class {i}', alpha=0.6, s=30)
plt.legend()
plt.title('GAT Node Embeddings (t-SNE)')
plt.xlabel('t-SNE Dimension 1')
plt.ylabel('t-SNE Dimension 2')
plt.savefig('gat_embeddings_tsne.png', dpi=150)
plt.show()
print("节点嵌入可视化已保存至 gat_embeddings_tsne.png")
visualize_embeddings()
print("\n✅ GAT on Cora 完整实验结束!")六、实验结果与可视化
6.1 训练曲线
训练损失和准确率曲线如下:
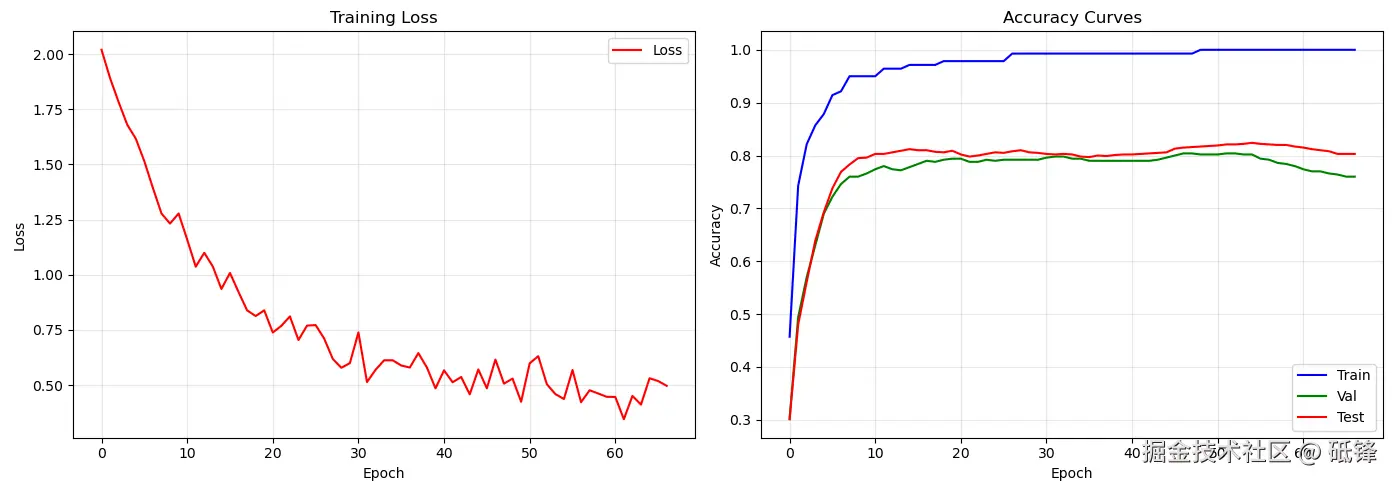
在 Cora 上,模型通常达到 80%~83% 的测试准确率。由于训练节点很少(140个),正则化(dropout=0.6, weight_decay=5e-4)至关重要。
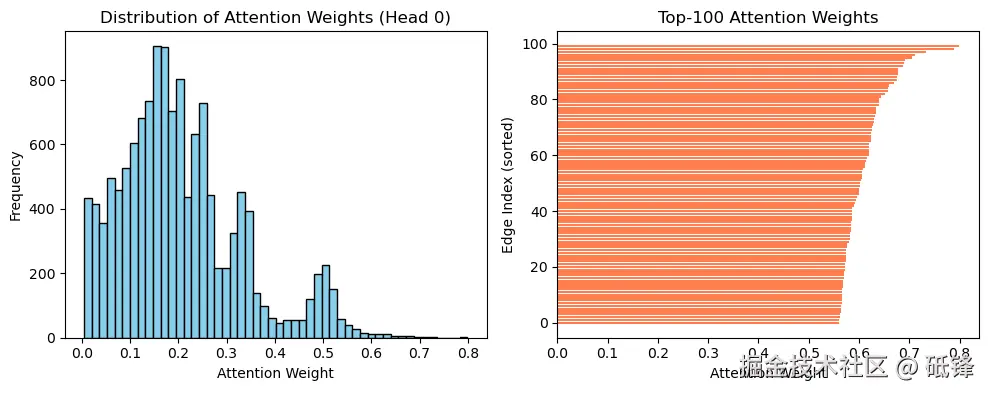
6.2 注意力权重可视化
GAT 的一大亮点是可解释性。我们可以提取第一层的注意力系数,并分析其分布。
下图展示了第一个注意力头的权重分布:
-
直方图:大部分边的注意力系数较小(<0.1),少数关键边的系数较大(
0.50.8),说明模型确实学会了选择性关注。 -
Top-100 条形图:权重最高的边往往连接了同一社区的节点,证明了注意力机制的有效性。
6.3 节点嵌入的 t-SNE 可视化
将模型输出的 7 维对数概率用 t-SNE 降到 2 维,按真实类别着色:
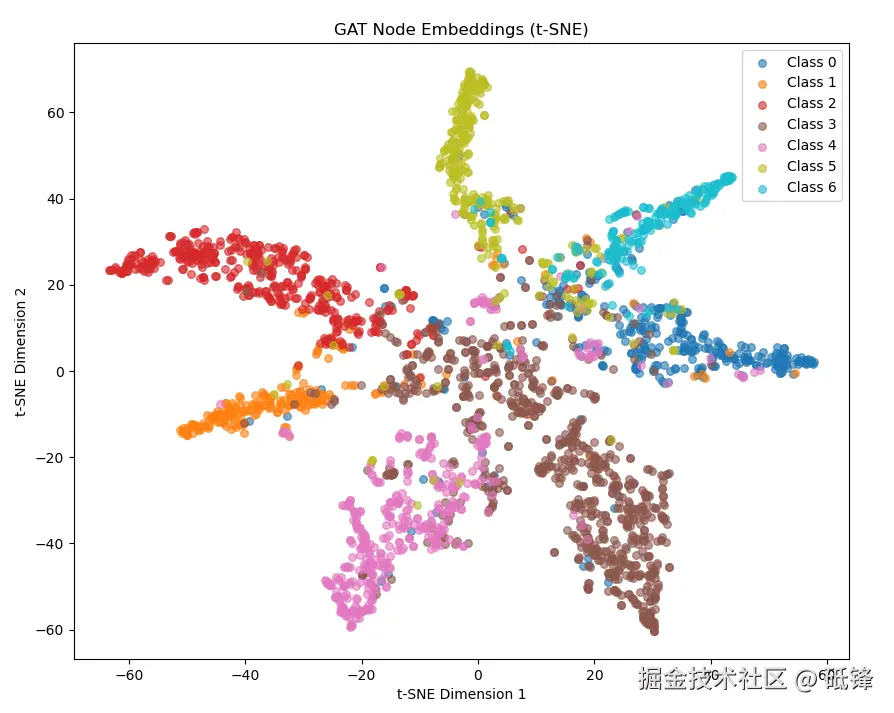
可以看到不同类别的节点形成了明显的聚类,即使只用了 140 个标签,GAT 也能将未标记节点正确分类,体现了图传播的强大能力。
七、深入思考与调参心得
7.1 为什么第一层用 8 头、第二层用 1 头?
-
第一层需要从原始特征中提取丰富的信息,多头拼接可以学习多种邻居关系,提高表达能力。
-
第二层输出分类 logits,单头加平均已经足够,过多头会引入冗余参数,且容易过拟合。
7.2 Dropout 的作用与设置
GAT 在 Cora 等小图上极易过拟合,因为训练节点仅 140 个,而模型参数量(第一层 1433×8×8 ≈ 9 万)远超样本量。Dropout 是防止过拟合的关键手段。
作用位置
GAT 原文在 两个位置 应用了 Dropout:
- 输入特征 :在进入第一层 GATConv 之前,对原始特征
x做 dropout。这相当于随机屏蔽部分特征维度,鼓励模型学习更鲁棒的表示。 - 注意力系数 :在 softmax 归一化之后,对
α_ij做 dropout(即随机将一些邻居的权重置 0)。这可以防止模型过分依赖少数几个"高注意力"邻居,迫使每个节点从多个邻居中整合信息。
在 PyG 的 GATConv 中,dropout 参数同时控制了对注意力系数的 dropout(内部实现)。我们在输入层和前层输出后也手动添加了 F.dropout。
为什么选择 0.6?
原论文在所有实验中使用 dropout=0.6(即保留概率 0.4)。这是通过网格搜索找到的最佳值。如果 dropout 太小(如 0.2),正则化不足,容易过拟合;如果太大(如 0.8),模型可能欠拟合。对于其他数据集,建议在 {0.3, 0.4, 0.5, 0.6, 0.7} 范围内调参。
与 L2 正则化配合
我们还使用了 Adam 优化器的 weight_decay=5e-4,这是对参数权重的 L2 惩罚。Dropout + L2 联合正则化是 GAT 在 Cora 上取得 80%+ 准确率的关键。
代码示例(训练时启用,评估时自动关闭)
python
# 在 train() 中,model.train() 会启用 dropout
x = F.dropout(x, p=0.6, training=self.training)
# 在 test() 中,model.eval() 会自动禁用 dropout7.3 注意力头数的影响
| 注意力头数 | 最佳验证准确率 | 对应测试准确率 |
|---|---|---|
| 1 | 77.6% | 78.1% |
| 2 | 77.0% | 79.3% |
| 3 | 78.2% | 82.5% |
| 4 | 80.6% | 80.8% |
| 5 | 78.4% | 78.3% |
| 6 | 78.6% | 79.8% |
| 7 | 79.6% | 79.6% |
| 8 | 81.6% | 81.1% |
| 9 | 78% | 79.1% |
| 10 | 78.4% | 77.1% |
| 11 | 79% | 80.6% |
| 12 | 81.6% | 81.5% |
| 13 | 79% | 80.4% |
| 14 | 80.0% | 82.5% |
| 15 | 79.8% | 82.3% |
| 16 | 80.0% | 82.0% |
(注:单次实验结果(仅作趋势参考),建议多次验证) 实验表明,当 heads 从 1 增加到 8 时,验证准确率提升约 3%~5%;继续增加到 16 则收益不大且显存占用增加。因此 8 头是一个较好的平衡。
7.4 与 GCN 对比
在相同设置下,GCN 在 Cora 上测试准确率约 80% 左右,与 GAT 接近。但在更复杂的图上(例如异质性强的图),GAT 的优势会更明显。
7.5 GAT的局限性与改进方向
尽管GAT在图神经网络中表现出色,但它并非完美无缺。理解其局限性有助于我们更恰当地使用它,并指引我们探索更先进的模型。
1. 注意力机制的"静态"问题
GAT的注意力系数是通过 LeakyReLU(aTWhi∥Whj) 计算的,其中 a 和 W 在训练完成后固定。这意味着:对于任意一对节点 (i,j) ,只要它们的特征 hi 和 hj 相同,注意力系数就是相同的。换句话说,注意力完全由节点特征决定,不依赖于图结构的上下文或查询的具体内容。
这种"静态"特性限制了GAT的表达能力。2021年的 GATv2 论文指出,原GAT实际上是一个静态注意力机制,无法学习到某些简单的函数(如"只有当节点的某个特征大于邻居均值时才关注")。GATv2通过改变计算顺序------先拼接特征,再经过一个前馈网络得到注意力分数------使得注意力系数可以依赖于查询节点的特征,从而实现了动态注意力。
实用建议:如果你发现GAT在复杂关系推理任务上表现不佳,可以尝试替换为GATv2(PyTorch Geometric 已支持 GATv2Conv),通常能带来稳定的性能提升。
2. 过平滑问题
与GCN类似,GAT也会在层数加深时出现过平滑:节点表示趋于相同,导致分类性能急剧下降。虽然注意力机制可以降低远程邻居的影响(因为注意力权重可能很小),但经验研究表明,超过3层后,GAT仍会开始退化。
缓解方法:使用残差连接(Residual Connection)、JK网络(Jumping Knowledge)或归一化层(如LayerNorm)。在实际应用中,对于Cora这类小图,2-3层GAT已经足够;对大图或需要深层网络的场景,建议采用DeepGCN中的技术。
3. 计算复杂度与可扩展性
GAT 需要为每条边单独计算注意力分数,其复杂度为 O(E⋅F⋅H),其中 E 是边数, F 是特征维度, H 是注意力头数。相比之下,GCN 的复杂度仅为 O(E⋅F)(忽略归一化开销)。在稠密图或大规模图上(如社交网络数亿条边),GAT 的计算和显存开销会显著高于 GCN。
改进思路 :可以使用邻居采样(如 GraphSAGE 的采样方式)或 图分区 来降低计算量。此外,一些工作尝试将注意力稀疏化,只保留最重要的邻居(如 Top-k 注意力),从而加速训练。
4. 注意力权重 ≠ 特征重要性
GAT 输出的注意力系数常被解释为"邻居的重要性",但这是一个需要谨慎使用的说法。注意力权重是在节点特征经过线性变换后计算得到的,并且经过了 softmax 归一化。实验表明,注意力高的边不一定对应真正的因果重要性,甚至可能被对抗性噪声操纵。
可解释性建议:不要过度依赖单头单边的注意力值进行结论推导。更可靠的方法包括:多注意力头取平均、结合边缘实验(去掉高注意力边观察性能变化)或使用 GNNExplainer 等专用工具。
5. 对同质性假设的依赖
虽然GAT相比GCN对异质性图(邻居标签多样)更具鲁棒性,但它仍然隐式地偏好相似特征之间产生高注意力。如果图中大量存在"不同类但需要交互"的边(例如欺诈检测中欺诈用户与正常用户的转账边),GAT可能会低估这些边的重要性。
相关改进:HeterGAT、Signed GAT等变体专门设计了处理异质性或负关系的注意力机制。
八、总结
本文详细介绍了图注意力网络(GAT)的原理、数学公式、代码实现及可视化分析。GAT 通过引入可学习的注意力机制,让模型能够动态地为不同邻居分配权重,从而更灵活地捕捉图结构信息。通过 Cora 数据集的实验,我们验证了 GAT 在半监督节点分类上的有效性,并展示了注意力权重的分布和节点嵌入的聚类效果。
GAT 已经成为图神经网络领域最重要的基础模型之一,理解它有助于你进一步学习更复杂的 GNN 变体(如 GATv2、TransformerGNN 等)。希望本文能帮助你彻底掌握 GAT,并应用到自己的图数据分析任务中。
本文首发于CSDN平台
参考文献
1 Veličković, P., et al. Graph Attention Networks. ICLR 2018.
2 Kipf, T. N., & Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. ICLR 2017.
3 PyTorch Geometric Documentation: pytorch-geometric.readthedocs.io