文章目录
-
- [Redis Hash 哈希:字段级操作与对象存储的最佳实践](#Redis Hash 哈希:字段级操作与对象存储的最佳实践)
- 一、前言
- [二、Hash 是什么](#二、Hash 是什么)
-
- [2.1 基本概念](#2.1 基本概念)
- [2.2 和 String 存储对象的对比](#2.2 和 String 存储对象的对比)
- [三、Hash 的全部命令](#三、Hash 的全部命令)
-
- [3.1 HSET ------ 设置字段](#3.1 HSET —— 设置字段)
- [3.2 HGET ------ 获取单个字段](#3.2 HGET —— 获取单个字段)
- [3.3 HMGET ------ 批量获取字段](#3.3 HMGET —— 批量获取字段)
- [3.4 HGETALL ------ 获取所有字段和值](#3.4 HGETALL —— 获取所有字段和值)
- [3.5 HKEYS 和 HVALS ------ 获取所有字段名 / 所有值](#3.5 HKEYS 和 HVALS —— 获取所有字段名 / 所有值)
- [3.6 HEXISTS ------ 判断字段是否存在](#3.6 HEXISTS —— 判断字段是否存在)
- [3.7 HDEL ------ 删除字段](#3.7 HDEL —— 删除字段)
- [3.8 HLEN ------ 获取字段个数](#3.8 HLEN —— 获取字段个数)
- [3.9 HSETNX ------ 字段不存在时才设置](#3.9 HSETNX —— 字段不存在时才设置)
- [3.10 HINCRBY 和 HINCRBYFLOAT ------ 字段数值自增](#3.10 HINCRBY 和 HINCRBYFLOAT —— 字段数值自增)
- 四、命令速查表
- 五、内部编码
-
- [5.1 两种内部编码](#5.1 两种内部编码)
- [5.2 实际演示](#5.2 实际演示)
- 六、典型使用场景
-
- [6.1 存储对象信息](#6.1 存储对象信息)
- [6.2 Hash 与关系型数据库的两个重要区别](#6.2 Hash 与关系型数据库的两个重要区别)
- 七、三种缓存方案对比
-
- [方案一:原生 String,每个属性一个 key](#方案一:原生 String,每个属性一个 key)
- [方案二:序列化 String,整个对象一个 key(JSON 格式)](#方案二:序列化 String,整个对象一个 key(JSON 格式))
- 方案三:Hash,字段级别操作
- 三种方案横向对比
- 八、总结
-
- [8.1 使用注意事项](#8.1 使用注意事项)
Redis Hash 哈希:字段级操作与对象存储的最佳实践
一、前言
💬 这一篇讲什么:Redis 五种数据类型中的第二种 ------ Hash 哈希
🚀 核心内容:
- Hash 类型是什么?和 String 有什么区别?
- Hash 的全部命令,每条命令怎么用、什么场景用?
- Hash 的两种内部编码是什么,什么时候切换?
- 存储对象信息时,String、JSON 和 Hash 三种方案怎么选?
上一篇学完了 String 类型和全局命令基础,这一篇进入第二种数据类型 ------ Hash。Hash 在存储对象信息、部分字段更新这类场景下比 String 更自然、更高效,是实际业务中使用非常频繁的类型。
二、Hash 是什么
2.1 基本概念
如果你用过 C++ 的 unordered_map、Python 的 dict,那你已经理解 Hash 的核心思想了。
在 Redis 中,Hash 类型是指 value 本身又是一个键值对结构:
text
key = "user:1"
value = {
"name" → "James",
"age" → "28",
"city" → "Beijing"
}这里 Hash 内部的键叫做 field ,对应的值叫做 value(注意区分:Redis 整体的 key-value 中的 value 指的是这整个 Hash 结构;Hash 内部的 field-value 中的 value 指的是某个字段的值,两者所处的上下文不同)。
2.2 和 String 存储对象的对比
假设要存储一个用户的信息(uid=1,姓名 James,年龄 28),用 String 和 Hash 各是什么样子:
用 String 存(每个属性一个 key):
bash
SET user:1:name "James"
SET user:1:age "28"
SET user:1:city "Beijing"用 Hash 存:
bash
HSET user:1 name "James" age "28" city "Beijing"Hash 把同一个对象的所有属性聚合在一个 key 下面,结构更清晰,也更便于整体操作。
三、Hash 的全部命令
3.1 HSET ------ 设置字段
设置 hash 中一个或多个字段的值。字段不存在则新建,已存在则覆盖。
语法:
bash
HSET key field value [field value ...]时间复杂度:插入一个 field 为 O(1),插入 N 个 field 为 O(N)。
返回值:新增的 field 的个数(已有字段被覆盖不计入)。
示例:
bash
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HGET myhash field1
"Hello"
# 一次性设置多个字段
redis> HSET user:1 name "James" age "28" city "Beijing"
(integer) 33.2 HGET ------ 获取单个字段
获取 hash 中指定 field 的值。field 不存在返回 nil。
语法:
bash
HGET key field时间复杂度:O(1)
示例:
bash
redis> HSET myhash field1 "foo"
(integer) 1
redis> HGET myhash field1
"foo"
redis> HGET myhash field2
(nil)3.3 HMGET ------ 批量获取字段
一次获取 hash 中多个 field 的值。不存在的 field 返回 nil。
语法:
bash
HMGET key field [field ...]时间复杂度:O(N),N 为查询 field 个数。
示例:
bash
redis> HSET myhash field1 "Hello" field2 "World"
(integer) 2
redis> HMGET myhash field1 field2 nofield
1) "Hello"
2) "World"
3) (nil)HMGET 和 MGET 的逻辑一样,减少网络往返次数,在需要读取对象多个属性时优先使用。
3.4 HGETALL ------ 获取所有字段和值
获取 hash 中所有的 field 和对应的 value,交替返回(field1, value1, field2, value2 ...)。
语法:
bash
HGETALL key时间复杂度:O(N),N 为 field 个数。
示例:
bash
redis> HSET myhash field1 "Hello" field2 "World"
(integer) 2
redis> HGETALL myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"❗ 使用 HGETALL 要小心 :如果 hash 中存了几千个甚至更多的 field,
HGETALL会一次性返回所有数据,占用大量网络带宽,而且因为是 O(N) 操作,会阻塞 Redis。如果只需要部分字段,用HMGET;如果必须遍历全部,用HSCAN(渐进式遍历,后续章节介绍)。
3.5 HKEYS 和 HVALS ------ 获取所有字段名 / 所有值
HKEYS 返回所有 field 名称;HVALS 返回所有 field 对应的 value。
语法:
bash
HKEYS key
HVALS key时间复杂度:O(N),N 为 field 个数。
示例:
bash
redis> HSET myhash field1 "Hello" field2 "World"
(integer) 2
redis> HKEYS myhash
1) "field1"
2) "field2"
redis> HVALS myhash
1) "Hello"
2) "World"3.6 HEXISTS ------ 判断字段是否存在
判断 hash 中是否存在指定的 field。
语法:
bash
HEXISTS key field时间复杂度:O(1)
返回值:1 表示存在,0 表示不存在。
示例:
bash
redis> HSET myhash field1 "foo"
(integer) 1
redis> HEXISTS myhash field1
(integer) 1
redis> HEXISTS myhash field2
(integer) 03.7 HDEL ------ 删除字段
删除 hash 中一个或多个指定的 field,不存在的 field 会被忽略。
语法:
bash
HDEL key field [field ...]时间复杂度:删除一个 O(1),删除 N 个 O(N)。
返回值:实际删除的 field 个数。
示例:
bash
redis> HSET myhash field1 "foo"
(integer) 1
redis> HDEL myhash field1
(integer) 1
redis> HDEL myhash field2
(integer) 03.8 HLEN ------ 获取字段个数
获取 hash 中 field 的总数量。
语法:
bash
HLEN key时间复杂度:O(1)
示例:
bash
redis> HSET myhash field1 "Hello" field2 "World"
(integer) 2
redis> HLEN myhash
(integer) 23.9 HSETNX ------ 字段不存在时才设置
只在 field 不存在的情况下,设置 hash 中的字段和值。如果 field 已经存在,不做任何操作。
语法:
bash
HSETNX key field value时间复杂度:O(1)
返回值:1 表示设置成功,0 表示 field 已存在未设置。
示例:
bash
redis> HSETNX myhash field "Hello"
(integer) 1
redis> HSETNX myhash field "World"
(integer) 0
redis> HGET myhash field
"Hello"3.10 HINCRBY 和 HINCRBYFLOAT ------ 字段数值自增
HINCRBY 将 hash 中指定 field 的数字值加上指定的整数(支持负数,相当于减);HINCRBYFLOAT 是浮点数版本。
语法:
bash
HINCRBY key field increment
HINCRBYFLOAT key field increment时间复杂度:O(1)
返回值:该 field 变化之后的新值。
示例:
bash
redis> HSET myhash field 5
(integer) 1
redis> HINCRBY myhash field 1
(integer) 6
redis> HINCRBY myhash field -1
(integer) 5
redis> HINCRBY myhash field -10
(integer) -5
# 浮点数版本
redis> HSET mykey field 10.50
(integer) 1
redis> HINCRBYFLOAT mykey field 0.1
"10.6"
redis> HINCRBYFLOAT mykey field -5
"5.6"四、命令速查表
| 命令 | 执行效果 | 时间复杂度 |
|---|---|---|
HSET key field value [...] |
设置一个或多个字段的值 | O(1) / O(N) |
HGET key field |
获取单个字段的值 | O(1) |
HMGET key field [...] |
批量获取多个字段的值 | O(N) |
HGETALL key |
获取所有字段和值 | O(N) |
HKEYS key |
获取所有字段名 | O(N) |
HVALS key |
获取所有字段的值 | O(N) |
HEXISTS key field |
判断字段是否存在 | O(1) |
HDEL key field [...] |
删除一个或多个字段 | O(1) / O(N) |
HLEN key |
获取字段个数 | O(1) |
HSETNX key field value |
字段不存在时才设置 | O(1) |
HINCRBY key field n |
字段整数值 +n | O(1) |
HINCRBYFLOAT key field n |
字段浮点值 +n | O(1) |
五、内部编码
5.1 两种内部编码
Hash 的内部编码有两种:
ziplist(压缩列表):当同时满足以下两个条件时使用:
- hash 中的 field 个数小于
hash-max-ziplist-entries配置(默认 512 个) - 所有 field 和 value 的长度都小于
hash-max-ziplist-value配置(默认 64 字节)
ziplist 是一种紧凑的顺序存储结构,把所有元素连续存放在一块内存里,内存利用率非常高,适合小规模数据。
hashtable(哈希表):当 hash 的规模超过上面任意一个阈值时,Redis 自动将内部编码从 ziplist 升级为 hashtable。hashtable 的读写时间复杂度是 O(1),适合大规模数据,但内存占用比 ziplist 大。
5.2 实际演示
bash
# 少量小字段 → ziplist
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2
OK
127.0.0.1:6379> object encoding hashkey
"ziplist"
# 当某个 value 超过 64 字节 → 自动升级为 hashtable
127.0.0.1:6379> hset hashkey f3 "one string is bigger than 64 bytes .................................111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111"
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"
# 当 field 个数超过 512 → 自动升级为 hashtable
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2 ... f513 v513
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"这个升级过程对用户完全透明,不需要做任何额外操作。但理解这个机制对于生产环境的内存优化很重要:如果 hash 的 field 数量和 value 大小都能控制在阈值以内,Redis 会用 ziplist 存储,显著节省内存。
六、典型使用场景
6.1 存储对象信息
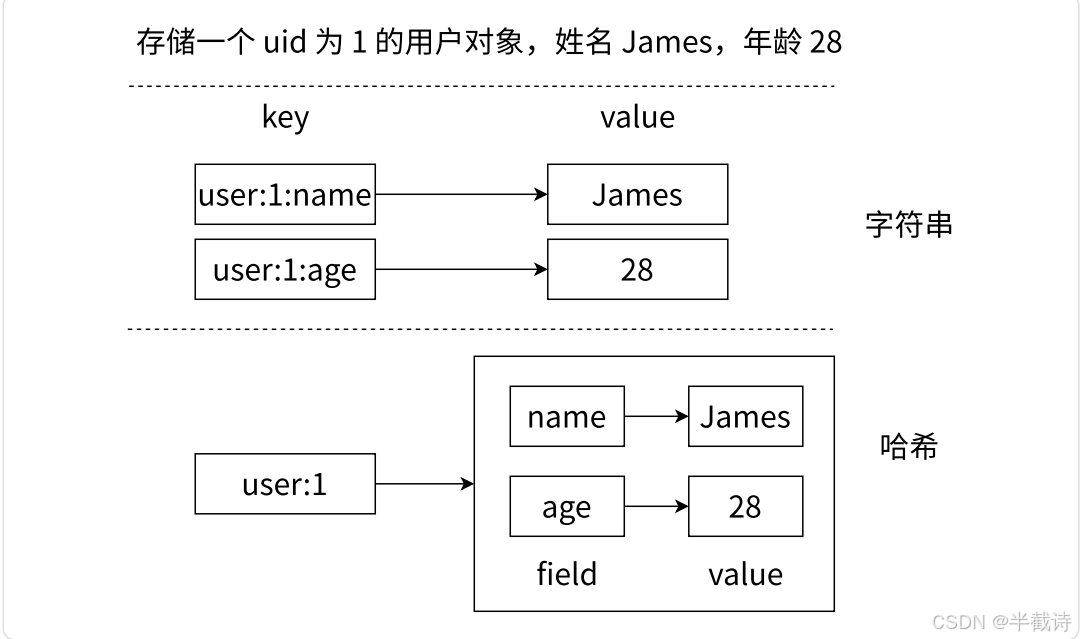
Hash 最典型的场景就是缓存数据库中的对象信息。以用户表为例:
数据库中的两条用户记录:
| uid | name | age | city |
|---|---|---|---|
| 1 | James | 28 | Beijing |
| 2 | Johnathan | 30 | Xian |
用 Hash 存储:
bash
HSET user:1 name "James" age "28" city "Beijing"
HSET user:2 name "Johnathan" age "30" city "Xian"读取用户信息时:
bash
HGETALL user:1
# 1) "name"
# 2) "James"
# 3) "age"
# 4) "28"
# 5) "city"
# 6) "Beijing"更新单个字段时(比如用户修改了城市):
bash
HSET user:1 city "Shanghai"只需要更新一个 field,而不需要把整个对象序列化后整体覆盖写入,这是 Hash 相对于 JSON 字符串方案的最大优势。
伪代码示意完整的缓存读取逻辑:
python
def get_user_info(uid):
key = "user:" + str(uid)
# 从 Redis Hash 读取用户信息
user_map = redis.hgetall(key)
if user_map:
return user_map # 缓存命中
# 缓存未命中,查数据库
user_info = mysql.query("SELECT * FROM user_info WHERE uid = %s", uid)
if user_info is None:
return None
# 写入 Hash 缓存,设置 1 小时过期
redis.hset(key, mapping={
"name": user_info.name,
"age": user_info.age,
"city": user_info.city
})
redis.expire(key, 3600)
return user_info6.2 Hash 与关系型数据库的两个重要区别
区别一:Hash 是稀疏的,关系型数据库是结构化的。
关系型数据库的表一旦添加一列,所有行都必须有这个字段(哪怕是 NULL)。而 Hash 是稀疏的,不同的 key 可以有不同的 field,互不影响:
bash
# user:1 有 name、city、favor 三个字段
HSET user:1 name "James" city "Beijing" favor "sports"
# user:2 有 name、age、gender 三个字段,和 user:1 完全不同
HSET user:2 name "Johnathan" age "30" gender "male"这种灵活性在某些场景下很有用,但也意味着应用层需要自己管理 field 的规范。
区别二:Hash 不支持复杂关系查询。
MySQL 支持多表 JOIN、聚合、分组等复杂查询。Redis Hash 是纯粹的 key-field-value 结构,没有 SQL 那样的查询语言,想在 Redis 里做多表关联查询基本上是不可能的。Redis 擅长的是按 key 快速定位,不擅长复杂关系运算。
七、三种缓存方案对比
现在我们已经有了三种在 Redis 中缓存对象信息的方式,来做一个全面的对比:
方案一:原生 String,每个属性一个 key
bash
SET user:1:name "James"
SET user:1:age "28"
SET user:1:city "Beijing"优点:实现简单,可以单独修改某个属性,非常灵活。
缺点:一个用户对象用了多个 key,如果有几百万用户,key 的数量会膨胀得非常可观,内存开销大。而且用户信息分散在多个 key 里,缺乏内聚性,使用起来不直观。实际上这个方案很少在生产中使用。
方案二:序列化 String,整个对象一个 key(JSON 格式)
bash
SET user:1 '{"name":"James","age":28,"city":"Beijing"}'优点:一个 key 存一个完整对象,内聚性强;序列化方案选对的话内存利用率也不错;编程逻辑简单。
缺点:每次读出来都要反序列化整个对象,只修改一个属性也要把整个对象读出来→修改→序列化→写回,操作粒度粗,有额外的序列化/反序列化开销。
适合场景:总是整体读写的对象,比如配置信息、权限列表等。
方案三:Hash,字段级别操作
bash
HSET user:1 name "James" age "28" city "Beijing"优点 :结构直观,支持字段级别的读写(HGET、HSET 单个字段);局部更新非常高效,不需要读出整个对象再写回;HINCRBY 可以直接对数字字段做原子性自增。
缺点 :需要注意 ziplist 和 hashtable 之间的切换,如果 field 数量或 value 大小超过阈值,内部会转换为 hashtable,内存消耗增大。另外,一次性读取整个对象需要 HGETALL,对大 hash 要小心阻塞问题。
适合场景:需要频繁读写对象的部分字段,或者需要对某些数字字段做计数的场景。
三种方案横向对比
| 对比维度 | 原生 String(每属性一 key) | 序列化 String(JSON) | Hash |
|---|---|---|---|
| key 数量 | 多(属性数 × 对象数) | 少(对象数) | 少(对象数) |
| 单字段读写 | 高效 | 低效(需整体读写) | 高效 |
| 整体读写 | 需多次请求 | 高效 | 需 HGETALL |
| 内存利用率 | 低 | 较高 | 小对象高(ziplist),大对象一般 |
| 实现复杂度 | 简单 | 简单 | 中等 |
| 推荐指数 | ❌ 不推荐 | ✅ 适合整体操作 | ✅ 适合局部操作 |
八、总结
现在你已经掌握了:
✅ Hash 是什么:value 本身是 field-value 结构的键值对,适合存储对象信息
✅ 全部命令:HSET/HGET/HMGET/HGETALL/HKEYS/HVALS/HEXISTS/HDEL/HLEN/HSETNX/HINCRBY/HINCRBYFLOAT
✅ 内部编码:field 少且小时用 ziplist(省内存),超过阈值自动升级为 hashtable(高性能)
✅ 与关系型数据库的区别:Hash 是稀疏的,不支持复杂关系查询
✅ 三种缓存方案对比:每属性一 key(不推荐)、JSON 字符串(适合整体操作)、Hash(适合局部操作)
8.1 使用注意事项
| 注意事项 | 说明 |
|---|---|
| 避免大 hash 使用 HGETALL | field 过多时会阻塞,改用 HMGET 或 HSCAN |
| 控制 field 数量和大小 | 保持在 ziplist 阈值内可以节省大量内存 |
| Hash 没有嵌套 | field 对应的 value 只能是字符串,不能再是 hash |
| HINCRBY 只对整数有效 | 浮点数计数用 HINCRBYFLOAT |
| expire 作用于整个 key | 不能给单个 field 设置过期时间,只能给整个 hash key 设置 |
下一篇预告:Redis List 列表 ------ 双端操作命令详解、阻塞命令的妙用、消息队列和时间线场景实战,以及 Set 集合的交并差运算。