Fake Emotion
内心OS:感觉这道题目比较吸引,就看了好久,可惜没搞出来,复盘一下
附件:
model.py
首先看model.py
py
#!/usr/bin/env python3
import torch.nn as nn
class ExpressionNet(nn.Module):
def __init__(self, num_classes=7): #这里默认7个表情
super().__init__()
self.features = nn.Sequential(
# Block 1
nn.Conv2d(1, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
# Block 2
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
# Block 3
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
# Block 4
nn.Conv2d(128, 256, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(256 * 3 * 3, 512),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x线下断网,这段代码最开始没看懂,一点一点翻函数手册,一点一点一点现场学
Conv2d:卷积层 (我理解就是找面部特征)
Relu:激活函数
``MaxPool2d`:池化层(保留关键信息下缩小图片)
4个Block :最后图片变成256个特征图x3x3大小
1.输入1通道灰度图
2.块 1:提取简单特征 → 图片变小
3.块 2:提取更复杂特征 → 再变小
4.块 3:更复杂 → 再变小
5.块 4:最复杂特征 → 再变小
self.classifier = nn.Sequential(
nn.Flatten(), # 把 3x3x256 展平成一维
nn.Linear(256 * 3 * 3, 512), # 全连接层:学习特征组合
nn.ReLU(),
nn.Dropout(0.5), # 随机丢一半神经元,防止过拟合
nn.Linear(512, num_classes), # 最后输出 7 类概率
)把图片特征拉成一条长向量 ,用两层全连接层判断是哪种表情,最后输出 7 个数字,分别对应 7 种表情的概率
def forward(self, x):
x = self.features(x) # 第一步:提取特征
x = self.classifier(x) # 第二步:分类判断
return x # 输出结果大致流程:图片 → 提取特征 → 分类 → 输出表情
verifier.py
再看verifier.py
py
#!/usr/bin/env python3
from __future__ import annotations
from pathlib import Path
import numpy as np
from PIL import Image
import torch
from skimage.metrics import structural_similarity as ssim
try:
from .model import ExpressionNet
except ImportError:
from model import ExpressionNet
ROOT = Path(__file__).resolve().parent
MODEL_PATH = ROOT / "model.pt"
SEED_PATH = ROOT / "seed_angry.png"
EPS = 0.03
SSIM_THRESHOLD = 0.95
HAPPY_PROB_THRESHOLD = 0.8
SOURCE_LABEL = 0
TARGET_LABEL = 3
FER_CLASSES = {
0: "Angry",
1: "Disgust",
2: "Fear",
3: "Happy",
4: "Sad",
5: "Surprise",
6: "Neutral",
}
def compute_ssim(a: np.ndarray, b: np.ndarray) -> float:
return float(ssim(np.clip(a, 0.0, 1.0), np.clip(b, 0.0, 1.0), data_range=1.0))
def load_model() -> ExpressionNet:
model = ExpressionNet(num_classes=7)
state = torch.load(MODEL_PATH, map_location="cpu")
if isinstance(state, dict) and "model_state" in state:
state = state["model_state"]
model.load_state_dict(state)
model.eval()
return model
def load_seed() -> np.ndarray:
return np.array(Image.open(SEED_PATH).convert("L").resize((48, 48)), dtype=np.float32) / 255.0
def verify_delta(delta_path: Path) -> dict:
result = {"valid": False, "passed": False, "message": "", "flag": None, "details": {}}
try:
delta = np.load(delta_path)
except Exception as exc:
result["message"] = "Verification failed."
return result
result["valid"] = True
if delta.shape != (1, 48, 48):
result["message"] = "Verification failed."
return result
if delta.dtype != np.float32:
result["message"] = "Verification failed."
return result
model = load_model()
seed = load_seed()
seed_t = torch.from_numpy(seed).unsqueeze(0).unsqueeze(0)
with torch.no_grad():
orig_probs = torch.softmax(model(seed_t), dim=1)[0].cpu().numpy()
orig_pred = int(np.argmax(orig_probs))
adv = np.clip(seed + delta[0], 0.0, 1.0).astype(np.float32)
adv_t = torch.from_numpy(adv).unsqueeze(0).unsqueeze(0)
with torch.no_grad():
adv_probs = torch.softmax(model(adv_t), dim=1)[0].cpu().numpy()
adv_pred = int(np.argmax(adv_probs))
linf = float(np.max(np.abs(delta)))
ssim_val = compute_ssim(seed, adv)
checks = [
("Shape (1,48,48)", delta.shape == (1, 48, 48)),
("Dtype float32", delta.dtype == np.float32),
(f"Original label == {SOURCE_LABEL}", orig_pred == SOURCE_LABEL),
(f"L_inf <= {EPS}", linf <= EPS + 1e-6),
(f"SSIM >= {SSIM_THRESHOLD}", ssim_val >= SSIM_THRESHOLD - 1e-6),
(f"Attack successful ({TARGET_LABEL})", adv_pred == TARGET_LABEL),
("P(Happy) > P(Angry)", adv_probs[TARGET_LABEL] > adv_probs[SOURCE_LABEL]),
(f"P(Happy) > {HAPPY_PROB_THRESHOLD}", adv_probs[TARGET_LABEL] > HAPPY_PROB_THRESHOLD),
]
failed = [name for name, passed in checks if not passed]
if not failed:
result["passed"] = True
result["message"] = (
"All constraints satisfied!\n"
f" Original: {orig_pred} ({FER_CLASSES[orig_pred]})\n"
f" Adversarial: {adv_pred} ({FER_CLASSES[adv_pred]})\n"
f" L_inf: {linf:.6f} (<= {EPS})\n"
f" SSIM: {ssim_val:.4f} (>= {SSIM_THRESHOLD})\n"
f" P(Angry): {adv_probs[SOURCE_LABEL]:.6f}\n"
f" P(Happy): {adv_probs[TARGET_LABEL]:.6f}"
)
else:
result["message"] = "Verification failed."
return resultEPS = 0.03 # 改动幅度不能超过 3%
SSIM_THRESHOLD = 0.95 # 图片相似度必须 ≥95%(人眼看不出区别)
HAPPY_PROB_THRESHOLD = 0.8 # AI必须有≥80%把握认为是"开心"
SOURCE_LABEL = 0 # 原始是生气(0=Angry)
TARGET_LABEL = 3 # 目标是开心(3=Happy)这一部分就是要求了
FER_CLASSES = {
0: "Angry",
1: "Disgust",
2: "Fear",
3: "Happy",
4: "Sad",
5: "Surprise",
6: "Neutral",
}必须满足的规则
def compute_ssim(a: np.ndarray, b: np.ndarray) -> float:
return float(ssim(np.clip(a, 0.0, 1.0), np.clip(b, 0.0, 1.0), data_range=1.0))这里大概是在检测两张图片的相似度
def load_model() -> ExpressionNet:
model = ExpressionNet(num_classes=7)
state = torch.load(MODEL_PATH, map_location="cpu")
if isinstance(state, dict) and "model_state" in state:
state = state["model_state"]
model.load_state_dict(state)
model.eval()
return model这里好像是加载ai模型,把model.pt读出来,恢复ai
def load_seed() -> np.ndarray:
return np.array(
Image.open(SEED_PATH).convert("L").resize((48, 48)),
dtype=np.float32
) / 255.0打开图片转灰度图,缩放48x48
def verify_delta(delta_path: Path) -> dict:
result = {"valid": False, "passed": False, "message": "", "flag": None, "details": {}}
try:
delta = np.load(delta_path)
except Exception as exc:
result["message"] = "Verification failed."
return result
result["valid"] = True
if delta.shape != (1, 48, 48):
result["message"] = "Verification failed."
return result
if delta.dtype != np.float32:
result["message"] = "Verification failed."
return result读取delta(给图片的修改),检测后缀名(.npy)及其格式
seed_t = torch.from_numpy(seed).unsqueeze(0).unsqueeze(0)
with torch.no_grad():
orig_probs = torch.softmax(model(seed_t), dim=1)[0].cpu().numpy()
orig_pred = int(np.argmax(orig_probs))让ai判断7种表情最像那个(必须是HAPPY)
adv = np.clip(seed + delta[0], 0.0, 1.0).astype(np.float32)公式:新图片 = 原图 + 你的微小修改
adv_t = torch.from_numpy(adv).unsqueeze(0).unsqueeze(0)
with torch.no_grad():
adv_probs = torch.softmax(model(adv_t), dim=1)[0].cpu().numpy()
adv_pred = int(np.argmax(adv_probs))让ai预测修改后的图片
linf = float(np.max(np.abs(delta)))
ssim_val = compute_ssim(seed, adv)
checks = [
("Shape (1,48,48)", delta.shape == (1, 48, 48)),
("Dtype float32", delta.dtype == np.float32),
(f"Original label == {SOURCE_LABEL}", orig_pred == SOURCE_LABEL),
(f"L_inf <= {EPS}", linf <= EPS + 1e-6),
(f"SSIM >= {SSIM_THRESHOLD}", ssim_val >= SSIM_THRESHOLD - 1e-6),
(f"Attack successful ({TARGET_LABEL})", adv_pred == TARGET_LABEL),
("P(Happy) > P(Angry)", adv_probs[TARGET_LABEL] > adv_probs[SOURCE_LABEL]),
(f"P(Happy) > {HAPPY_PROB_THRESHOLD}", adv_probs[TARGET_LABEL] > HAPPY_PROB_THRESHOLD),
]检查规则(全部通过才行)
解题过程
目的:
1.读 seed_angry.png,把它变成 48x48 灰度图
2.载入 model.pt 和 model.py,先确认原图被模型判成 Angry(0),对输入的图求梯度,找出最敏感的像素,只在这些像素上加很小的扰动 delta,目标是把分类推到 Happy(3),反复调到同时满足:L_inf <= 0.03,SSIM >= 0.95,P(Happy) > 0.8,最后保存delta.npy,形状必须是 (1,48,48),dtype 必须是 float32
问题一的解决,还是比较顺利的,最开始尝试受用系统自带的画图软件或者photoshop,但是系统自带的改不好,突然想起来kali里有imagemagick
magick seed_angry.png -colorspace Gray -resize 48x48 seed_48x48_gray.png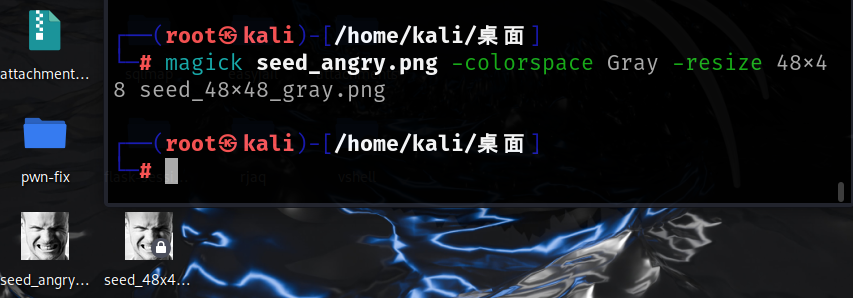
接着就是用model.py+model.pt加载模型,把修改后的图片送进去,确认模型预测结果是不是 Angry(0)
(难点就是平时ai用多了,手搓脚本的时候磕磕绊绊的,很多函数都是现场查的离线手册)后面发现好像要按照他那个模型的格式来所以又重新转成灰度、48x48......没招了
py
import numpy as np
from PIL import Image
import torch
from model import ExpressionNet
img = Image.open("seed_48x48_gray.png")
img = img.convert("L")
img = img.resize((48, 48))
img_np = np.array(img, dtype=np.float32) / 255.0
x = torch.from_numpy(img_np)
x = x.unsqueeze(0)
x = x.unsqueeze(0)
model = ExpressionNet()
model.load_state_dict(torch.load("model.pt", "cpu"))
model.eval()
with torch.no_grad():
output = model(x)
pred = torch.argmax(output).item()
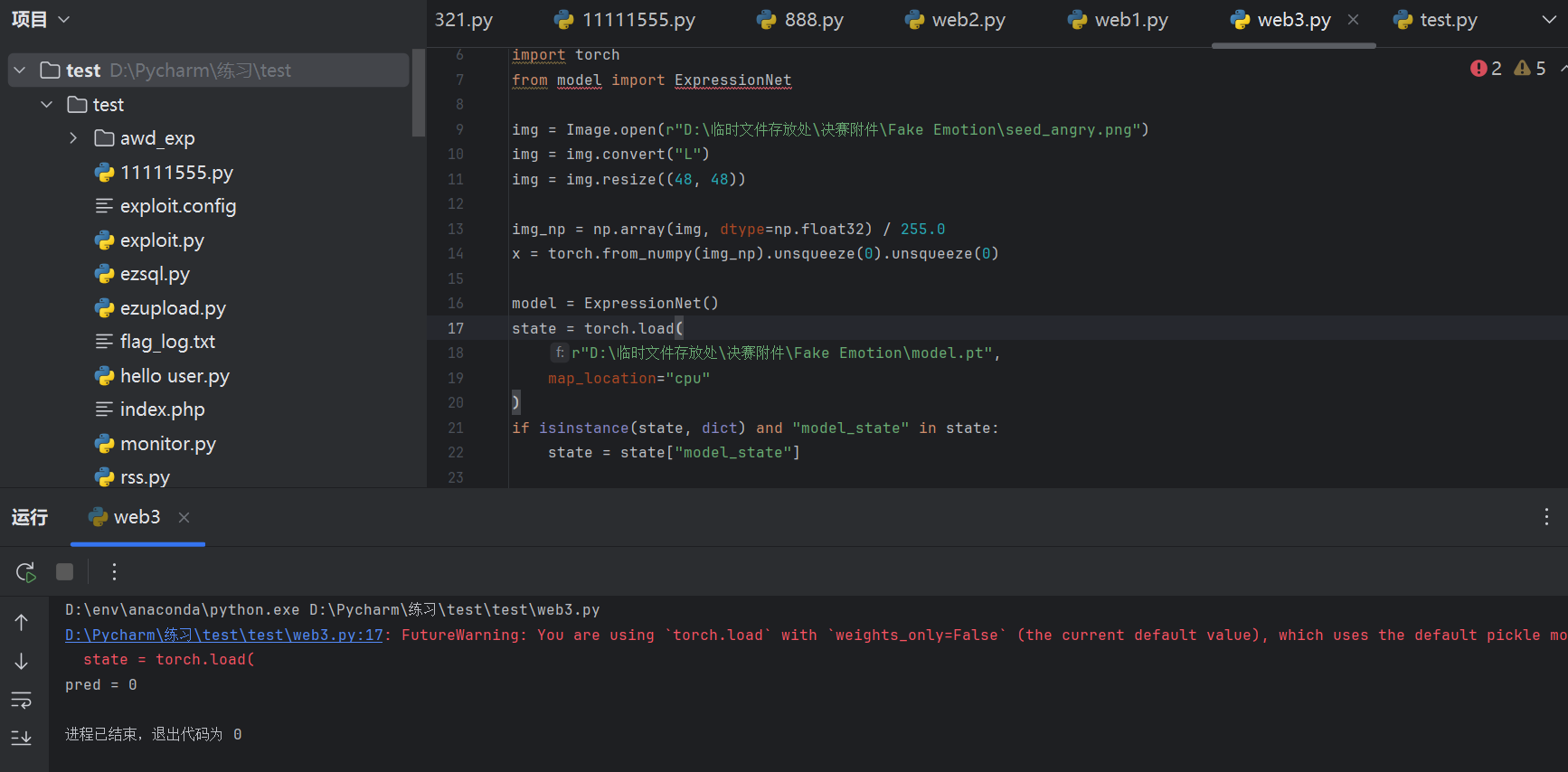
print("pred =", pred)然后就是一堆报错,主要就是文件位置问题于是重新写了一版
py
import sys
sys.path.append(r"D:\临时文件存放处\决赛附件\Fake Emotion")
import numpy as np
from PIL import Image
import torch
from model import ExpressionNet
img = Image.open(r"D:\临时文件存放处\决赛附件\Fake Emotion\seed_angry.png")
img = img.convert("L")
img = img.resize((48, 48))
img_np = np.array(img, dtype=np.float32) / 255.0
x = torch.from_numpy(img_np).unsqueeze(0).unsqueeze(0)
model = ExpressionNet()
state = torch.load(
r"D:\临时文件存放处\决赛附件\Fake Emotion\model.pt",
map_location="cpu"
)
if isinstance(state, dict) and "model_state" in state:
state = state["model_state"]
model.load_state_dict(state)
model.eval()
with torch.no_grad():
output = model(x)
pred = torch.argmax(output, dim=1).item()
print("pred =", pred)(三个人也是用尽毕生所学)
后面就是遇到新的问题,如何让模型更倾向于Happy,这里我们也是翻了好久,后面才知道求梯度
第一处,把输入张量改成可求导:x.requires_grad_()
第二处,不再用 with torch.no_grad():
第三处,拿到目标类别 Happy(3) 的分数:
output = model(x)
target_label = 3
target_score = output[0, target_label]第四处,反向传播:
model.zero_grad()
target_score.backward()第五处,取出梯度:grad = x.grad0, 0.detach().numpy()
py
import sys
sys.path.append(r"D:\临时文件存放处\决赛附件\Fake Emotion")
import numpy as np
from PIL import Image
import torch
from model import ExpressionNet
img = Image.open(r"D:\临时文件存放处\决赛附件\Fake Emotion\seed_angry.png")
img = img.convert("L")
img = img.resize((48, 48))
img_np = np.array(img, dtype=np.float32) / 255.0
x = torch.from_numpy(img_np).unsqueeze(0).unsqueeze(0)
x.requires_grad_()
model = ExpressionNet()
state = torch.load(
r"D:\临时文件存放处\决赛附件\Fake Emotion\model.pt",
map_location="cpu"
)
if isinstance(state, dict) and "model_state" in state:
state = state["model_state"]
model.load_state_dict(state)
model.eval()
output = model(x)
pred = torch.argmax(output, dim=1).item()
print("pred =", pred)
target_label = 3
target_score = output[0, target_label]
model.zero_grad()
target_score.backward()
grad = x.grad[0, 0].detach().numpy()
print("grad shape =", grad.shape)
print("grad max =", grad.max())
print("grad min =", grad.min())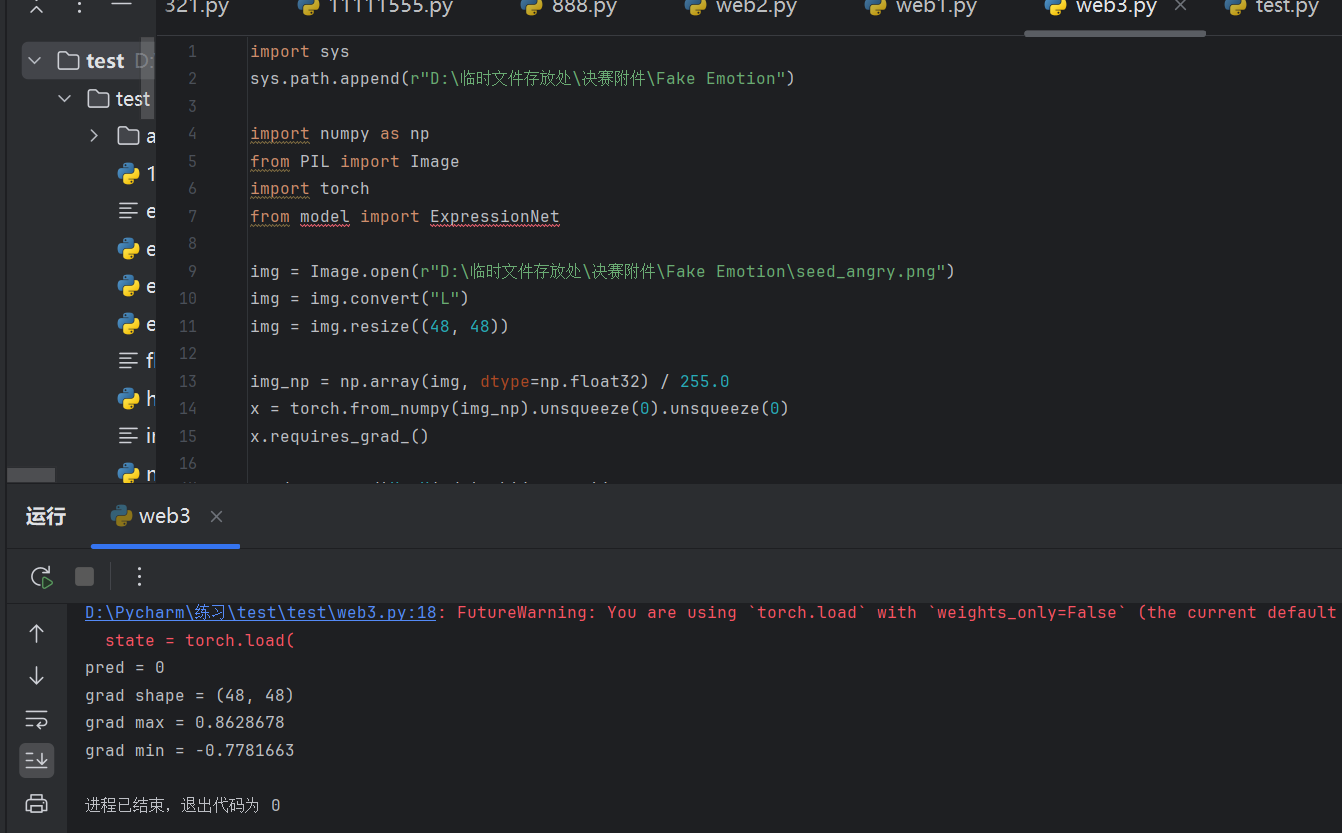
接下来就是完善grad 找最敏感的像素,把 grad 按绝对值从大到小排序,打印前 10 个最敏感像素
在脚本里加上
py
abs_grad = np.abs(grad)
flat_indices = np.argsort(abs_grad.ravel())[::-1][:10]
print("前10:")
for idx in flat_indices:
row, col = np.unravel_index(idx, abs_grad.shape)
print((row, col), "grad =", grad[row, col], "abs =", abs_grad[row, col])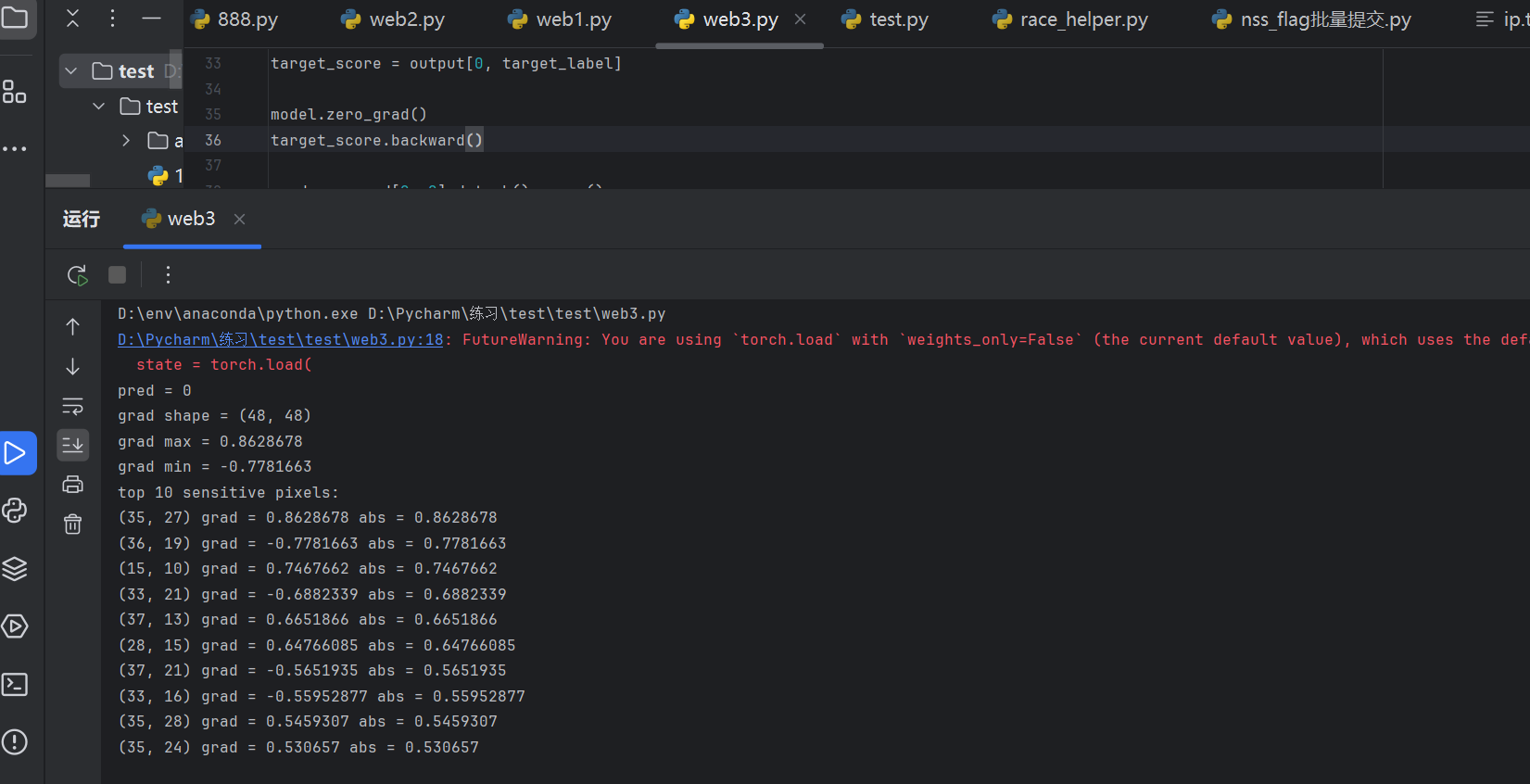
这里看运行结果,这些就是目前模型最敏感的像素位置,下面就是让模型开始从 Angry(0) 往 Happy(3) 偏
选出前 1500 个敏感像素,并生成 mask(maskrow, col = 1:这个位置允许修改,maskrow, col = 0:这个位置不修改)
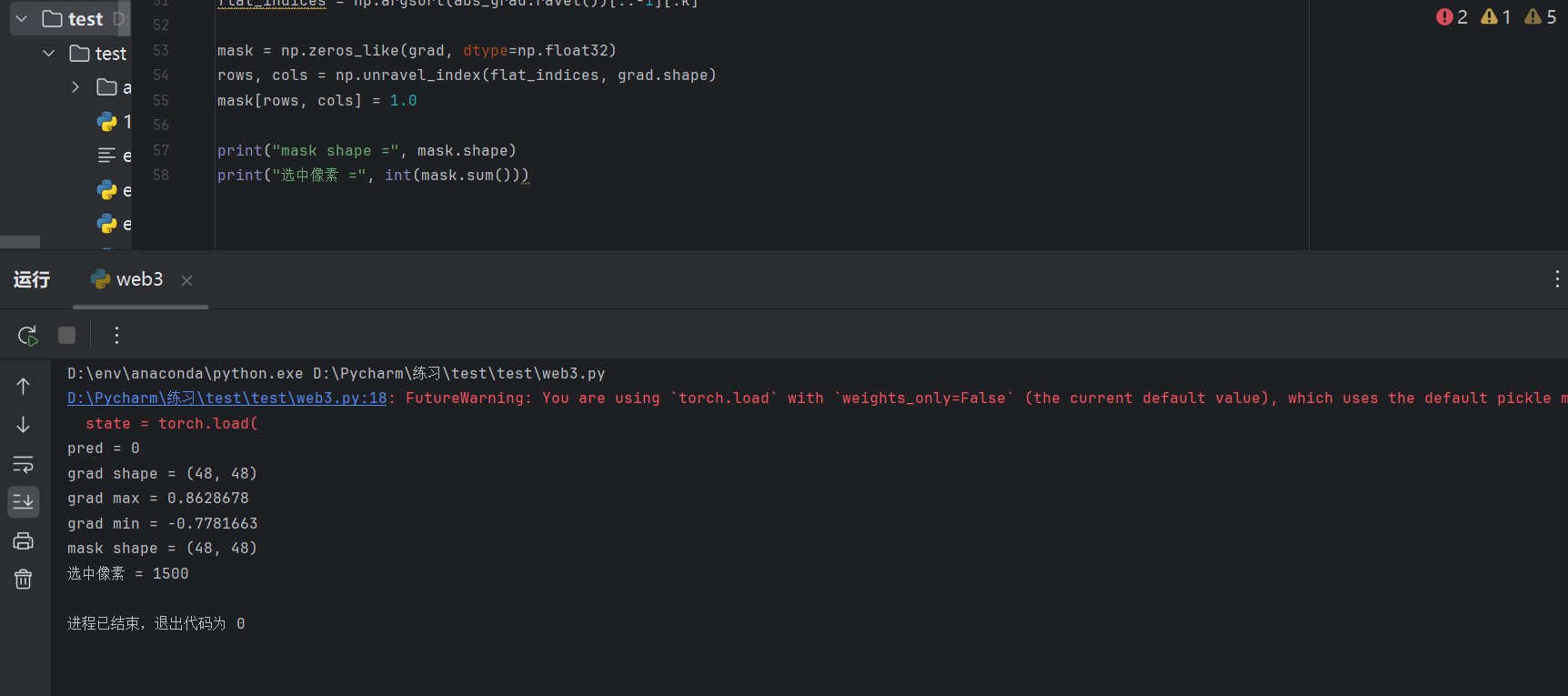
再去使用mask去生成delta
py
eps = 0.03
delta = eps * np.sign(grad) * mask
delta = delta.astype(np.float32)
delta_for_submit = delta[np.newaxis, :, :]
print("delta shape =", delta_for_submit.shape)
print("delta dtype =", delta_for_submit.dtype)
print("delta max abs =", np.max(np.abs(delta_for_submit)))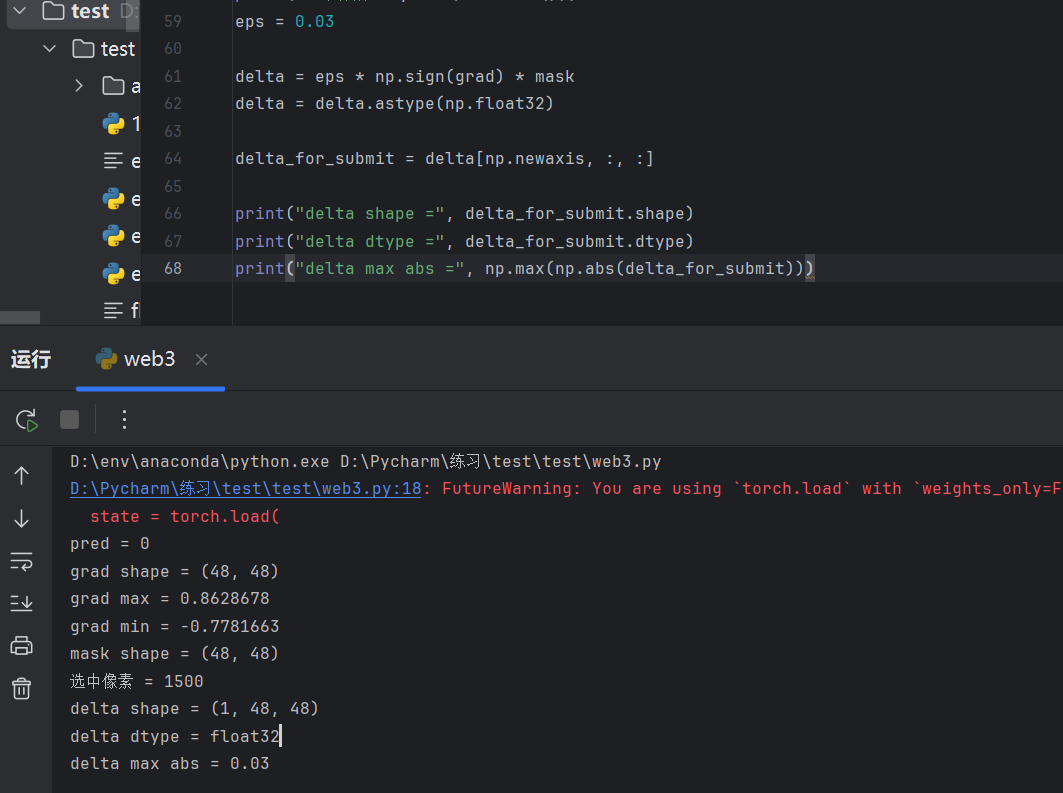
接下来让这些像素按梯度方向改 0.03
- np.sign(grad):决定每个像素往亮还是往暗改
- * mask:只改最敏感的 1500 个像素
- eps = 0.03:每个像素最多只改 0.03
- deltanp.newaxis, :, ::把形状从 (48,48) 变成题目要求的 (1,48,48)
接下来就要看adv pred 是否变成 3,adv P(Happy) 是否超过 0.8
如果 adv pred = 3,说明已经成功骗成 Happy
如果 adv P(Happy) > 0.8,说明置信度也满足题目要求
py
adv_np = img_np + delta
adv_np = np.clip(adv_np, 0.0, 1.0).astype(np.float32)
adv_x = torch.from_numpy(adv_np).unsqueeze(0).unsqueeze(0)
with torch.no_grad():
adv_output = model(adv_x)
adv_probs = torch.softmax(adv_output, dim=1)[0]
adv_pred = torch.argmax(adv_probs).item()
print("adv pred =", adv_pred)
print("adv P(Angry) =", adv_probs[0].item())
print("adv P(Happy) =", adv_probs[3].item())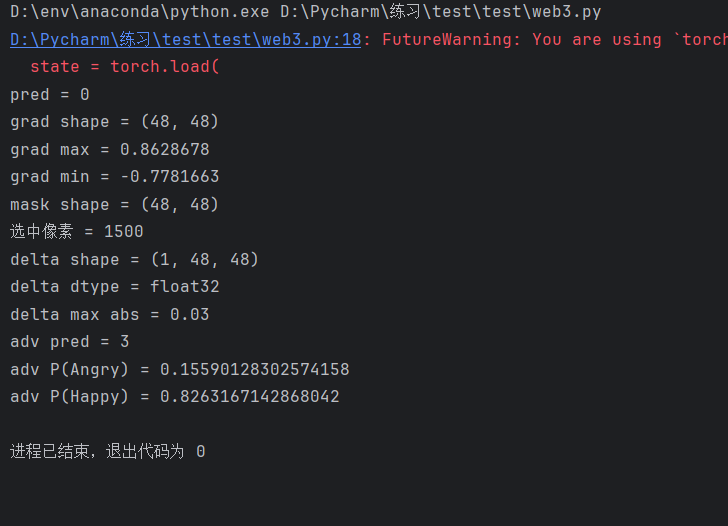
之后再检查最后一个条件:SSIM >= 0.95
最上面from skimage.metrics import structural_similarity as ssim
py
ssim_value = ssim(
np.clip(img_np, 0.0, 1.0),
np.clip(adv_np, 0.0, 1.0),
data_range=1.0
)
print("SSIM =", ssim_value)注意这里delta形状是(48,48)
py
np.save(
r"D:\临时文件存放处\决赛附件\Fake Emotion\delta.npy",
delta_for_submit
)
print("delta.npy")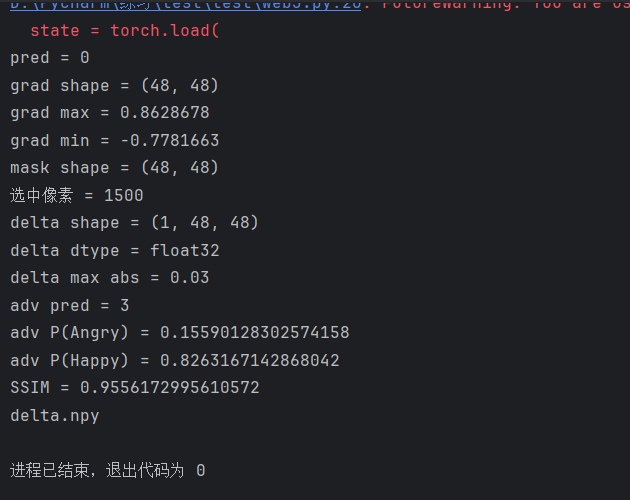
至此所有条件都满足
完整脚本
py
import sys
sys.path.append(r"D:\临时文件存放处\决赛附件\Fake Emotion")
import numpy as np
from PIL import Image
import torch
from model import ExpressionNet
from skimage.metrics import structural_similarity as ssim
img = Image.open(r"D:\临时文件存放处\决赛附件\Fake Emotion\seed_angry.png")
img = img.convert("L")
img = img.resize((48, 48))
img_np = np.array(img, dtype=np.float32) / 255.0
x = torch.from_numpy(img_np).unsqueeze(0).unsqueeze(0)
x.requires_grad_()
model = ExpressionNet()
state = torch.load(
r"D:\临时文件存放处\决赛附件\Fake Emotion\model.pt",
map_location="cpu"
)
if isinstance(state, dict) and "model_state" in state:
state = state["model_state"]
model.load_state_dict(state)
model.eval()
output = model(x)
pred = torch.argmax(output, dim=1).item()
print("pred =", pred)
target_label = 3
target_score = output[0, target_label]
model.zero_grad()
target_score.backward()
grad = x.grad[0, 0].detach().numpy()
print("grad shape =", grad.shape)
print("grad max =", grad.max())
print("grad min =", grad.min())
abs_grad = np.abs(grad)
flat_indices = np.argsort(abs_grad.ravel())[::-1][:10]
k = 1500
abs_grad = np.abs(grad)
flat_indices = np.argsort(abs_grad.ravel())[::-1][:k]
mask = np.zeros_like(grad, dtype=np.float32)
rows, cols = np.unravel_index(flat_indices, grad.shape)
mask[rows, cols] = 1.0
print("mask shape =", mask.shape)
print("选中像素 =", int(mask.sum()))
eps = 0.03
delta = eps * np.sign(grad) * mask
delta = delta.astype(np.float32)
delta_for_submit = delta[np.newaxis, :, :]
print("delta shape =", delta_for_submit.shape)
print("delta dtype =", delta_for_submit.dtype)
print("delta max abs =", np.max(np.abs(delta_for_submit)))
adv_np = img_np + delta
adv_np = np.clip(adv_np, 0.0, 1.0).astype(np.float32)
adv_x = torch.from_numpy(adv_np).unsqueeze(0).unsqueeze(0)
with torch.no_grad():
adv_output = model(adv_x)
adv_probs = torch.softmax(adv_output, dim=1)[0]
adv_pred = torch.argmax(adv_probs).item()
print("adv pred =", adv_pred)
print("adv P(Angry) =", adv_probs[0].item())
print("adv P(Happy) =", adv_probs[3].item())
ssim_value = ssim(
np.clip(img_np, 0.0, 1.0),
np.clip(adv_np, 0.0, 1.0),
data_range=1.0
)
print("SSIM =", ssim_value)
np.save(
r"D:\临时文件存放处\决赛附件\Fake Emotion\delta.npy",
delta_for_submit
)
print("delta.npy")总结
这道题比赛的时候没有做出来。现在回头看,主要问题不是题目本身特别复杂,而是当时没有第一时间判断出这是 AI 对抗样本题,拿到附件后也没有先去看清楚 verifier.py 的判题逻辑,导致一开始方向有点偏。
题目给了 model.py、model.pt、seed_angry.png 和 verifier.py。赛后重新看才发现,model.py 只是模型结构,model.pt 是训练好的模型参数,seed_angry.png 是原始图片,真正最重要的是 verifier.py。这个文件其实已经把题目的要求写得很清楚:最后要提交的不是一张新图片,而是一个 delta.npy 扰动文件。
判题器会把这个扰动加到原图上:
adv = seed + delta然后检查模型是否会把原本识别为 Angry(0) 的图片误判成 Happy(3)。同时还限制了扰动大小和图片相似度,比如 L_inf <= 0.03、SSIM >= 0.95、P(Happy) > 0.8,并且 delta.npy 的形状必须是 (1,48,48),类型必须是 float32。
赛后复盘时,先把 seed_angry.png 转成 48x48 灰度图,并归一化到 0,1。然后用 model.py 加载模型结构,再用 model.pt 加载参数,先验证原图的预测结果。结果输出是:
pred = 0说明原图确实被模型识别成 Angry。
接下来就是构造扰动。这里用到的核心思路是对输入图片求梯度。把目标类别设为 Happy(3),对这个类别的分数做反向传播,就能得到每个像素对 Happy 分数的影响。梯度为正的位置,像素调亮会更有利于提高 Happy 分数;梯度为负的位置,像素调暗会更有利;梯度绝对值越大,说明这个像素越敏感。
一开始只是打印了前几个敏感像素,后面发现真正攻击时不能只改几个点,所以改成选取一批梯度绝对值比较大的像素,构造 mask。mask 为 1 的地方允许修改,为 0 的地方不动。这样做的目的是只改模型最敏感的位置,尽量不破坏整张图的结构。
最后构造扰动的方式是:
delta = 0.03 * sign(grad) * mask这里 0.03 是题目给的最大扰动限制,sign(grad) 决定每个像素是变亮还是变暗,mask 控制只修改选中的敏感像素。
最终跑出来的结果是:
adv pred = 3 P(Angry) = 0.1559 P(Happy) = 0.8263 L_inf = 0.03 SSIM = 0.9556也就是说,攻击后的图片已经被模型识别成 Happy(3),P(Happy) 也超过了 0.8,同时扰动幅度和图片相似度都满足要求。
这题给我的教训是,遇到这种 AI/ML 附件题时,不能一上来就盯着模型或者图片乱试,应该先看验证脚本,搞清楚题目到底要提交什么、判题器检查什么。很多时候 verifier.py 就是最直接的题面。赛后也补上了对对抗样本的理解:不是训练模型,而是在已有模型上利用梯度找到最容易影响输出的像素,再在限制范围内构造一个很小的扰动,让模型产生误判。
附
赛后龙哥也是发了wp这里供参考:
Fake Emotion_wp.pdf · Oranger2538/图床 - Gitee.com(https://gitee.com/oranger2530/image-hosting/blob/78cc1b1ca95491f10eea6d618ac9985eb40284d1/Fake Emotion_wp.pdf)
注:这是我的图床,因为wp是私信,所以直接上传了,需要的自己下载