Claude Code 每次调用模型 API 时,传给 API 的 payload 由三部分组成:
- System Prompt --- 定义 Agent 的身份、行为规范和会话上下文
- Tools --- 工具 schema 列表,告诉模型有哪些能力可用
- Messages --- 对话消息,包含用户指令、CLAUDE.md 配置、工具执行结果
这三部分都会在 Agent Loop 调用模型时传入,但它们的来源不同:System Prompt 和 Tools 主要在进入循环前准备好,并在循环中保持相对稳定;真正随着每轮工具执行不断追加、更新的是 Messages。Agent Loop 的核心机制,就是模型返回工具调用请求,系统执行工具并把结果追加进 Messages,再进入下一轮模型调用,直到任务完成。
typescript
// src/query.ts --- Agent Loop 中调用模型(简化示意)
for await (const message of deps.callModel({
systemPrompt: fullSystemPrompt, // System Prompt
messages: ..., // 对话消息
tools: ..., // 工具 schema 列表
}))有一个关键约束贯穿整个设计:System Prompt 和 Tools 是缓存敏感的前缀层,Messages 才是持续增长的动态层。模型 API 会尽量复用稳定请求前缀;如果 System Prompt 或 工具 schema 在中途变化,前缀缓存就会失效。
这个约束直接决定了 Claude Code 的上下文组装架构:稳定前缀,动态内容后移。也就是说,适合缓存的内容尽量放在前缀里保持稳定,运行时变化则尽量移到 Messages、attachment 附加上下文或延迟工具加载里。
Agent 运行前的上下文组装
会话开始时,Claude Code 会先构建基础 System Prompt 和工具池;后续尽量保持前缀稳定,把变化放到 Messages、attachment 附加上下文或延迟工具加载里。
System Prompt 的工程化组装
System Prompt 不是一个巨大的字符串,而是一个字符串数组。每个元素是一个独立的段落,在发送给 API 之前才拼接成最终形式。这样做的好处是:
- 每个段落职责单一,可独立维护和测试
- 静态段落和动态段落可以分离,静态部分可以直接命中模型前缀缓存
- 动态段落可按条件裁剪,灵活控制注入内容
这段代码只需要先看三件事:返回值是数组;静态 section 放在前面;动态 section 放在缓存边界之后。
typescript
export async function getSystemPrompt(tools, model, ...): Promise<string[]> {
const dynamicSections = [
systemPromptSection('session_guidance', () => getSessionSpecificGuidanceSection(...)),
systemPromptSection('memory', () => loadMemoryPrompt()),
systemPromptSection('env_info_simple', () => computeSimpleEnvInfo(model, ...)),
// ...
];
return [
// --- 静态段落 ---
getSimpleIntroSection(), // 身份声明
getSimpleSystemSection(), // 系统规则
getSimpleDoingTasksSection(), // 任务执行准则
getActionsSection(), // 操作安全
getUsingYourToolsSection(), // 工具使用偏好
getSimpleToneAndStyleSection(), // 沟通风格
getOutputEfficiencySection(), // 输出效率
// === 缓存边界标记 ===
...(shouldUseGlobalCacheScope() ? [SYSTEM_PROMPT_DYNAMIC_BOUNDARY] : []),
// --- 动态段落 ---
...dynamicSections,
].filter(s => s !== null);
}静态段落定义 Agent 的"行为规范"。它们的共同点是:通常不依赖当前用户、项目目录、MCP 连接状态或本轮输入,可以跨用户缓存,因此更适合放到最前面作为稳定前缀:
- 身份声明 + 安全指令:"You are an interactive agent that helps users with software engineering tasks",以及网络安全和 URL 生成限制
- 系统规则:工具权限、system-reminder 标签解释、外部数据的 prompt injection 警告
- 任务准则:先读文件再改、不添加多余功能、不写多余注释、安全意识(OWASP Top 10)
- 操作安全:关注可逆性和影响范围,破坏性操作需用户确认
- 工具偏好:优先专用工具(Read/Edit/Write/Grep/Glob)而非 Bash
- 沟通风格:简洁、无 emoji、代码引用带文件路径和行号
动态段落包含当前会话相关的上下文。它们会因用户环境、配置、记忆、语言偏好等不同而变化
但在单个会话内部,大部分动态段落仍会被 memoized(即计算一次后存入内存,后续直接复用结果):会话开始时计算一次,后续请求直接复用。真正需要运行时变化的内容,通常会后移到 Messages、增量 attachment 附加上下文(只发送变化部分)或延迟工具加载里,避免直接改动可缓存前缀。典型动态段落包括:
- session_guidance --- 当前可用的工具和技能列表,包括 Agent 工具(允许模型启动子 Agent 来并行处理子任务)、Skill 工具(将用户定义的 slash command 如
/review封装为模型可调用的工具)的使用指导 - memory --- 自动记忆系统的行为指令,指导模型如何保存和检索记忆
- env_info_simple --- 当前工作目录、操作系统、Shell 类型、模型名称
- language / output_style --- 用户配置的语言偏好和输出风格
- mcp_instructions --- MCP 服务器的连接状态和使用说明;它不是普通 memoized 段落,MCP 连接变化更多通过 uncached / delta 机制、Tool Search /
defer_loading,或下一次顶层上下文构建体现,而不是在同一个 Agent Loop 的每次工具 follow-up 都重算 System Prompt
两者的对比:
| 静态段落 | 动态段落 | |
|---|---|---|
| 跨会话 | 被设计为尽量稳定、适合作为更稳定的缓存前缀 | 因用户环境、配置而异 |
| 会话内 | 基本不变 | 大部分 memoized;需要变化时通常后移到 Messages / delta / deferred tools |
| 内容占比 | ~60%+ | 剩余部分 |
静态段落和动态段落之间用 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 标记分隔。这个标记的工程意义在于:它为 Prompt Cache 提供了一个确定性的切分锚点。可以把它理解为:边界前的段落尽量保持 byte-level 稳定,边界后的段落允许按会话变化,这样缓存策略就能明确复用哪一段。
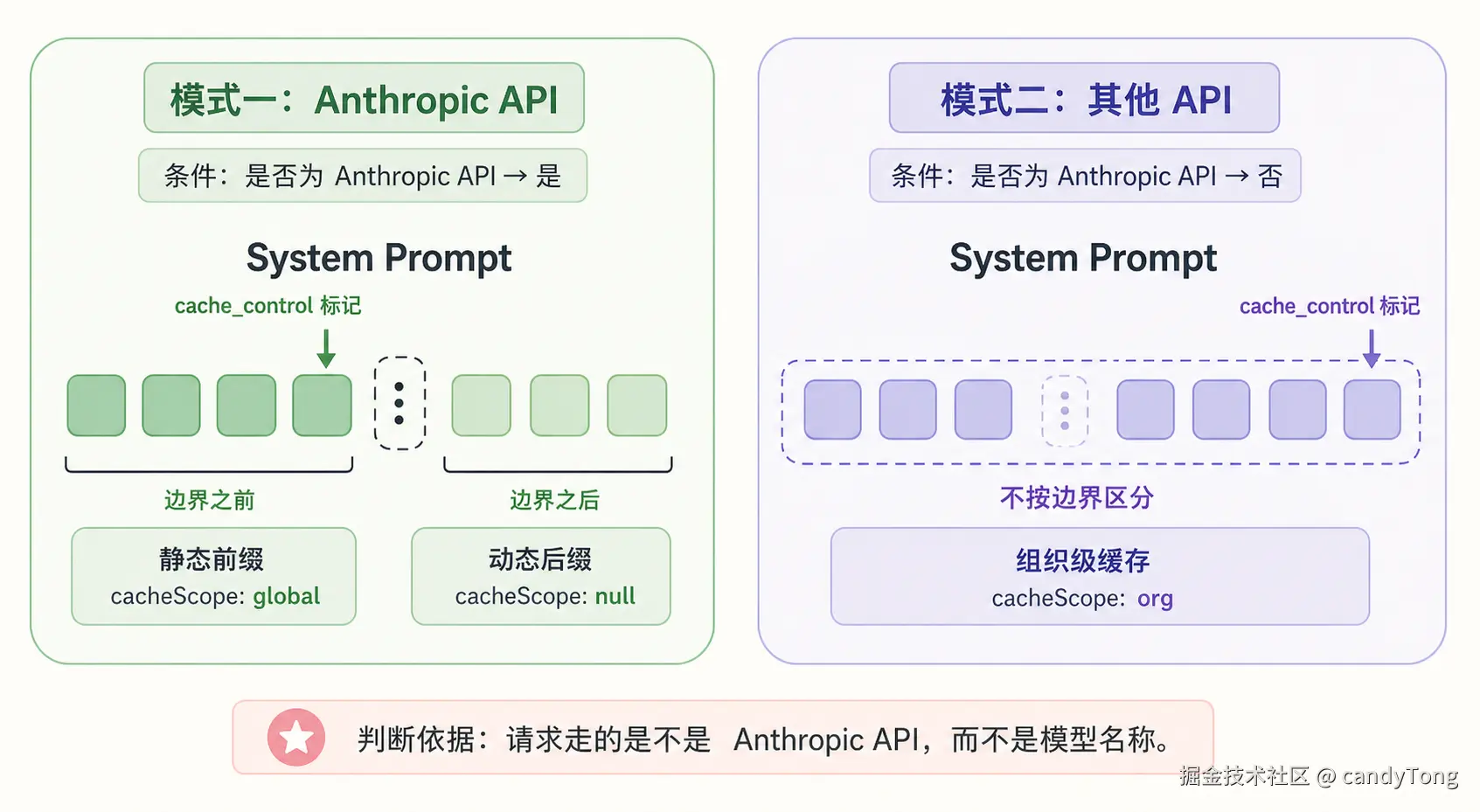
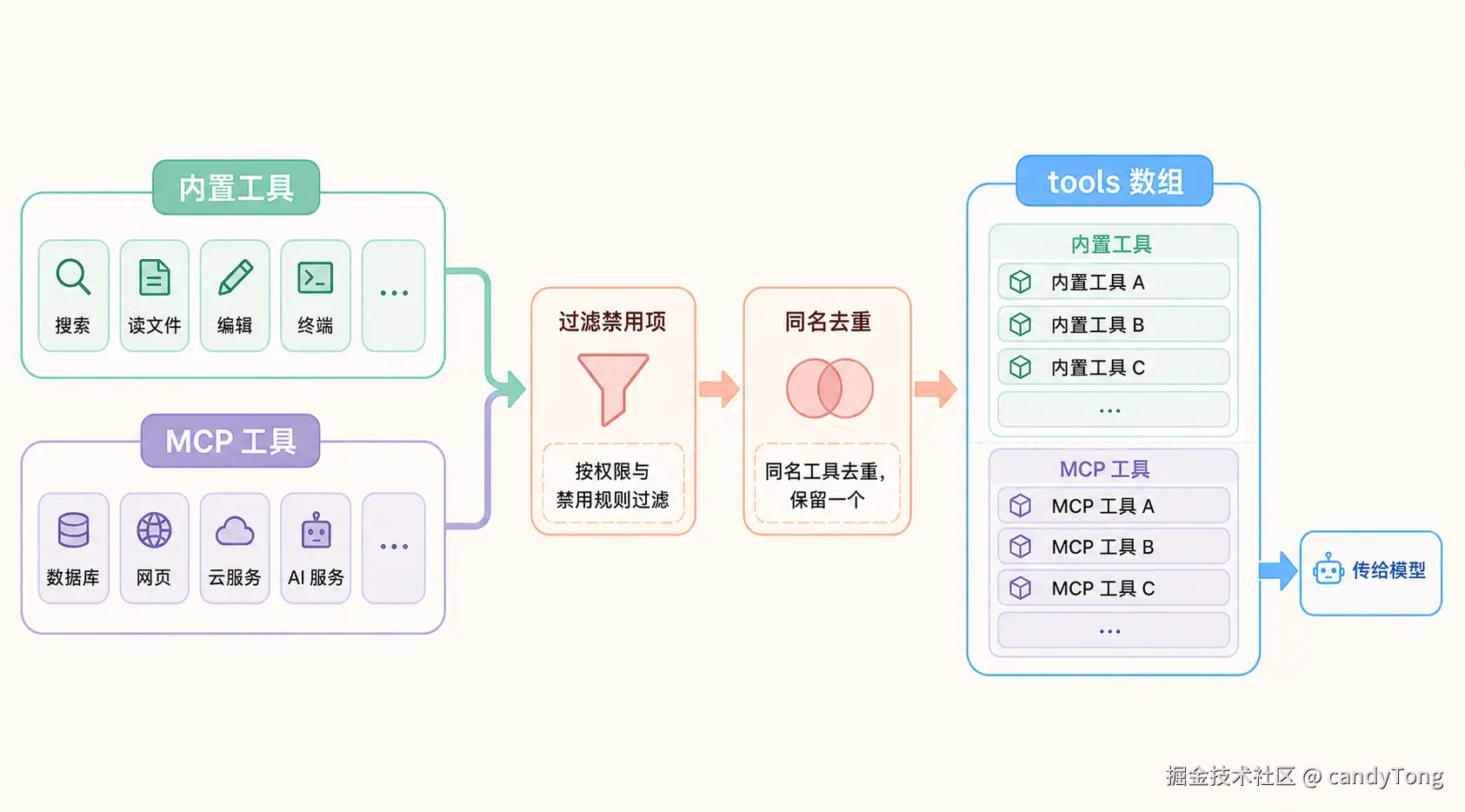
Tools
Tools 部分不是简单地"会话开始后永远不变"。Claude Code 会维护当前可用的候选工具池,再决定哪些工具直接进入本轮模型请求,哪些通过 Tool Search 延迟加载。
可以先用三层模型理解:
- 候选工具池 --- 当前会话可能用到的工具全集,来自内置工具、MCP、Skill 等来源。
- 本轮直接传入的工具 --- 直接放进模型 payload 的工具 schema,属于缓存敏感前缀的一部分,通常是高频、基础、需要立即可见的工具。
- deferred tools --- 不直接进入前缀的长尾或动态工具,通过 Tool Search /
defer_loading在需要时暴露,避免工具 schema 把稳定前缀撑大或频繁打破缓存。
延迟加载的触发方式是:当模型表达需要某类工具的意图时,系统通过 Tool Search 从候选池中提取对应 schema 补进上下文,而不是在每次请求时都把所有工具 schema 塞进前缀里。
Claude Code 的工具来源包括:
- 内置工具 --- Read、Write、Bash、Grep、Glob 等文件操作和搜索工具,约 40+ 个
- MCP 工具 --- 通过 MCP(Model Context Protocol)服务器动态注册的外部工具
- Skill 工具 --- 用户定义的 slash command 转换为可调用的工具
工具池的核心装配路径之一是 assembleToolPool()(接收当前会话的工具来源配置,返回过滤后的候选工具池):它负责把内置工具和 MCP 工具按权限过滤、排序、去重;但工具来源和后续合并不都发生在这个函数里。是否直接进入本轮请求,还要由后续工具选择和延迟加载策略决定:
Messages 的初始组装
与 System Prompt 和 Tools 不同,Messages 在会话过程中持续增长。第一次对话时,messages 数组的内容由三部分组成:
- CLAUDE.md --- 通过
prependUserContext()(将 CLAUDE.md 内容包装为 user message 并插入 messages 数组最前面)作为首条 user 消息注入。注意,这个操作在每轮调用模型前都会执行,因此 CLAUDE.md 在每一轮对话中都位于 messages 的最前面。 - 用户输入 --- 用户实际输入的消息(
createUserMessage) - attachment 附加上下文 (
AttachmentMessage)--- @提及的文件内容、IDE 选中的代码片段、hook 注入的额外上下文等
组装过程如下:
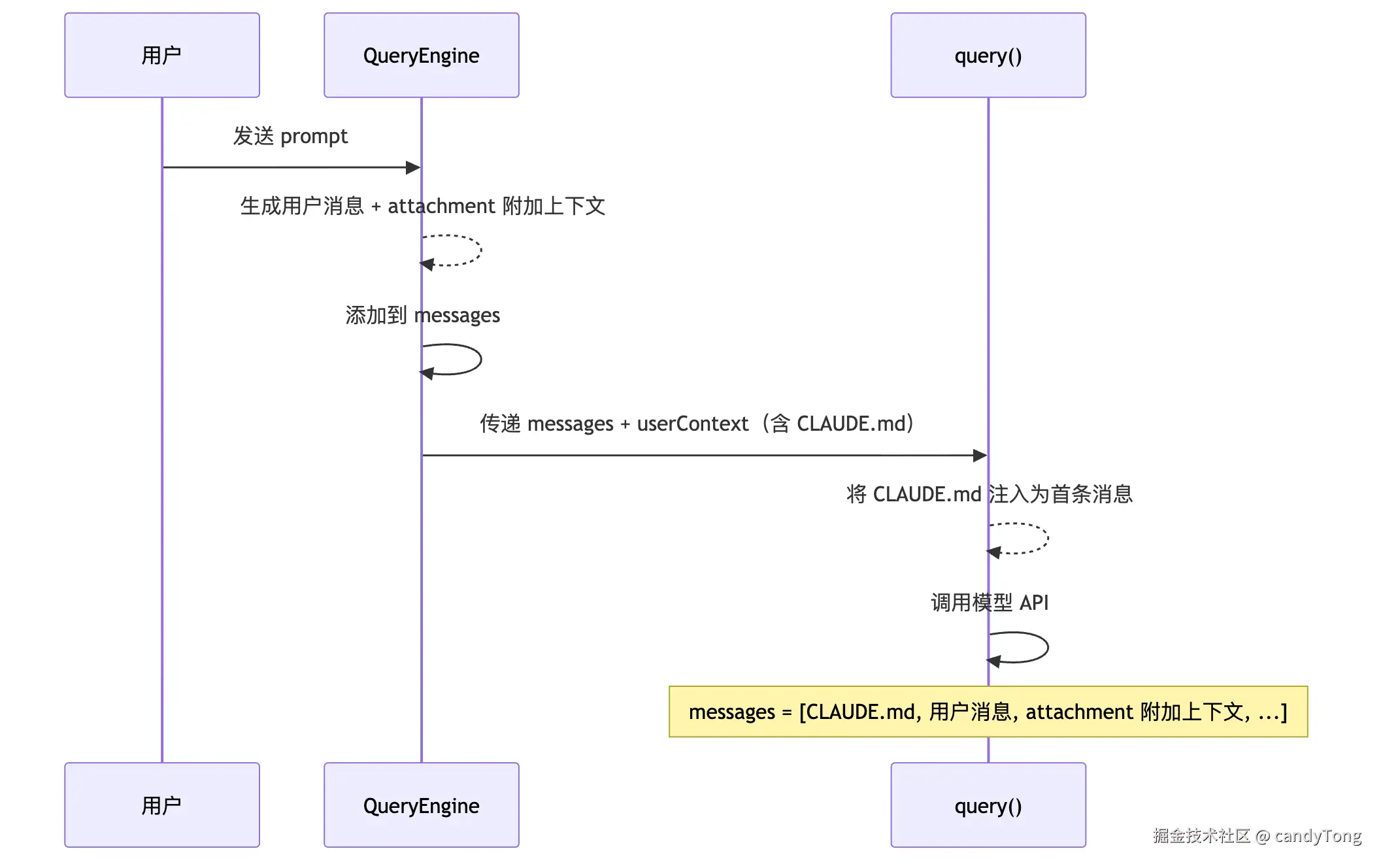
CLAUDE.md 注入
Messages 部分最核心的注入内容是 CLAUDE.md------用户通过 Markdown 文件定义 Agent 行为规范。文件按优先级从低到高加载:
- Managed ---
/etc/claude-code/CLAUDE.md,管理员全局策略 - User ---
~/.claude/CLAUDE.md,用户私有全局偏好 - Project --- 项目根目录或上级目录中的
CLAUDE.md、.claude/CLAUDE.md或.claude/rules/*.md,入库管理 - Local --- 项目根目录的
CLAUDE.local.md,本地私有覆盖
Claude Code 从当前目录向上遍历到根目录,每个层级都可能有上述文件。优先级的具体行为是:高优先级文件的内容排在低优先级之后。由于 Claude 模型从上到下阅读 messages,后出现的指令通常会被优先遵循------所以如果 User 级写"用中文回复",Project 级写"用英文回复",模型会倾向于遵循 Project 级的指令。这个排序只描述同为 CLAUDE.md 上下文时的工程策略,不代表 Project 级内容可以覆盖 System Prompt 或安全边界。
为什么 CLAUDE.md 不放在 System Prompt 里?
- System Prompt 负责定义 Claude Code 的基础行为、安全边界和工具使用方式;
- CLAUDE.md 本质上是项目级/用户级的持久上下文,不是最高优先级的系统规则。用来告诉模型这个项目的约定、目录结构、测试命令、代码风格和团队偏好。把它作为普通上下文加载,可以按不同项目、目录和个人偏好灵活变化,也能提交到仓库共享;同时避免让仓库里的文件拥有 System Prompt 那样的高权限,降低安全风险。后文示例里的
OVERRIDE any default behavior是对默认行为偏好的覆盖,不等于拥有 System Prompt 的安全优先级。
简单说:System Prompt 管"模型该如何被约束",CLAUDE.md 管"这个项目希望模型知道什么"。
CLAUDE.md 通过 <system-reminder> 标签作为首条 user 消息注入。注意:这里的 <system-reminder> 是 user message 内容里的 XML-like 标签,不等同于 API 的 system role:
xml
<system-reminder>
As you answer the user's questions, you can use the following context:
# claudeMd
Codebase and user instructions are shown below. Be sure to adhere to these
instructions. IMPORTANT: These instructions OVERRIDE any default behavior
and you MUST follow them exactly as written.
Contents of ~/.claude/CLAUDE.md (user's private global instructions for all projects):
# 全局偏好
- 默认使用中文回复
- commit message 使用英文
- 代码风格偏好:优先函数式写法,避免 class
Contents of CLAUDE.md (project instructions, checked into the codebase):
# 项目规范
- 所有接口必须返回统一的 `{ code, data, message }` 结构
- 错误处理使用 AppError 类,不要直接 throw Error
- 参数校验使用 zod schema
# currentDate
Today's date is 2026-05-17.
IMPORTANT: this context may or may not be relevant to your tasks.
</system-reminder>用户输入
用户输入会先被拆成两部分:原始输入本身包装为 UserMessage,同轮需要补充的上下文包装为 AttachmentMessage。
- 纯文本输入:直接作为
content传入 - 粘贴图片:文本和图片组合进
UserMessage.content,图片会经过必要处理以满足 API 限制 - @文件 / @目录 / @图片文件 / MCP 资源 / @agent:不会改写用户原文,而是解析成单独的
AttachmentMessage(attachment 附加上下文),跟在UserMessage后面
attachment 附加上下文
这里的 attachment 不只来自 @ 语法。用户输入预处理阶段会先调用统一的 attachment 附加上下文收集逻辑,结果和 UserMessage 一起进入 messages。简化来看,模型看到的消息序列类似这样:
text
[CLAUDE.md user message, 用户原始输入, attachment:file, attachment:diagnostics, ...]不要把 attachment 理解成一个固定、全量、每轮必有的接口表。源码里可见的 attachment 类型很多,其中一部分依赖特定功能、模式或 feature gate。为了抓住主线,可以先按用途分组:
| 分组 | 典型类型 | 作用 |
|---|---|---|
| 用户显式输入 | file、directory、pdf_reference、mcp_resource |
把 @ 文件、目录、PDF 或 MCP 资源补到用户消息旁边 |
| 已读与文件变化 | already_read_file、edited_text_file、edited_image_file |
避免重复注入,或只补文件在读入后的变化 |
| IDE 与诊断 | selected_lines_in_ide、opened_file_in_ide、diagnostics |
把用户当前正在看的代码、选区、LSP 诊断交给模型 |
| Skill / Agent / Tool 发现 | skill_discovery、dynamic_skill、skill_listing、agent_mention、agent_listing_delta、deferred_tools_delta |
让模型知道可用技能、Agent 类型,以及延迟工具变化 |
| Hook 与异步事件 | hook_additional_context、hook_success、async_hook_response、queued_command、task_status |
把 hook 输出、后台任务、异步通知补进下一轮上下文 |
| 运行模式与提醒 | plan_mode、plan_mode_exit、auto_mode、auto_mode_exit、todo_reminder、task_reminder、verify_plan_reminder、critical_system_reminder、context_efficiency、date_change |
用轻量提醒同步当前运行状态和约束 |
| 预算与输出控制 | token_usage、budget_usd、output_token_usage |
帮助模型感知上下文、预算和输出长度 |
| 特定功能路径 | nested_memory、mcp_instructions_delta、teammate_mailbox、team_context、ultrathink_effort、companion_intro |
只在对应功能、团队模式或实验路径下出现 |
Agent 运行过程中的动态上下文
前三节讲的是 Agent Loop 启动前的基础组装。进入循环后,Claude Code 会保持 System Prompt 工具稳定;主要变化集中在 Messages 数组 ,MCP 这类动态工具则优先走 Tool Search / defer_loading。
Agent Loop
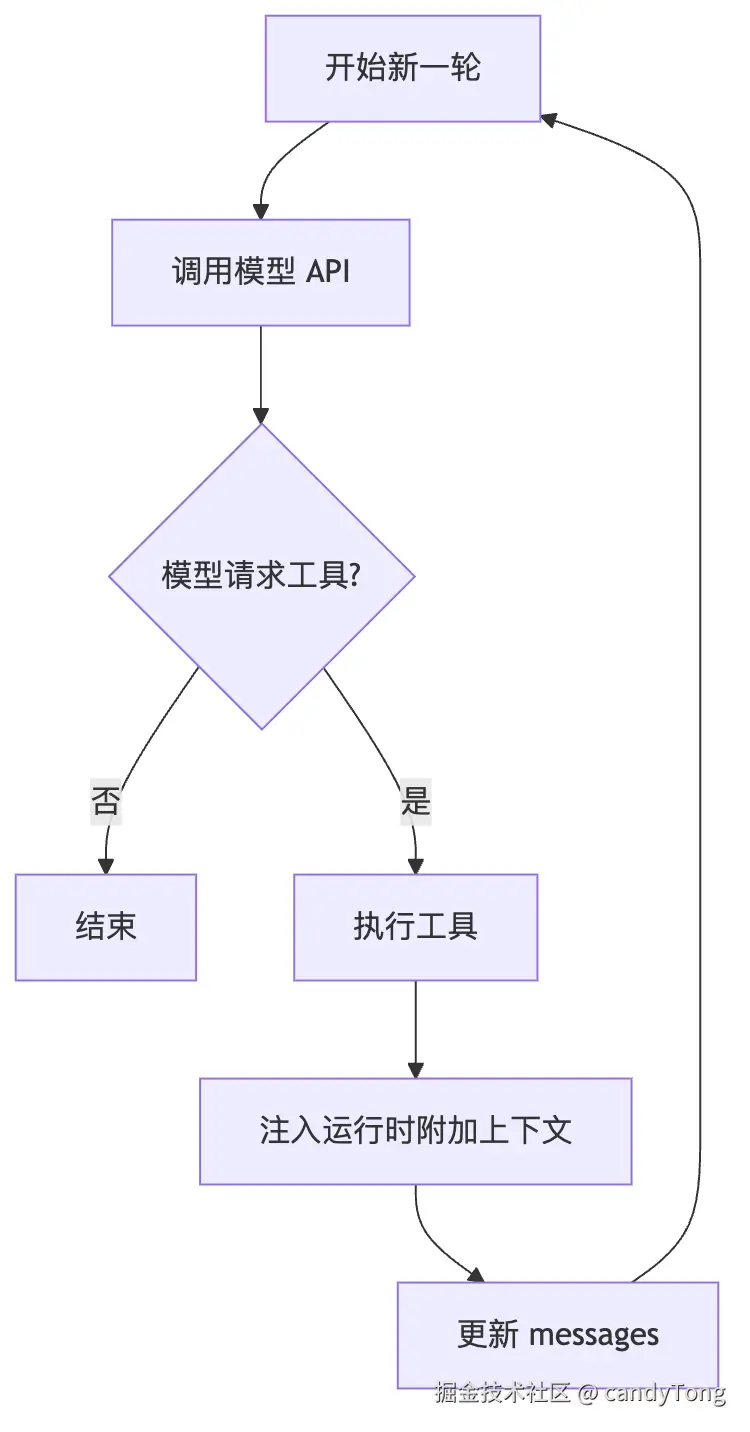
主循环在 query() 中,核心逻辑如下:
typescript
// query.ts --- Agent Loop 核心结构(已简化,保留关键调用)
while (true) {
// 1. 准备本轮要发送给模型的 messages(提取本轮需要发送的消息,可能包含历史截断逻辑)
messagesForQuery = getMessagesForCurrentTurn(state.messages);
// 2. 调用模型
for await (const message of deps.callModel({
messages: prependUserContext(messagesForQuery, userContext), // 每轮调用前把 CLAUDE.md / userContext 放回 messages 前部
systemPrompt: fullSystemPrompt,
tools: toolUseContext.options.tools,
})) {
/* 收集 assistant 消息和 tool_use 块 */
}
// 3. 没有工具调用 → 结束
if (!needsFollowUp) {
return { reason: 'completed' };
}
// 4. 执行工具(异步执行工具调用,返回 tool result 消息流)
const toolUpdates = runTools(
toolUseBlocks,
assistantMessages,
canUseTool,
toolUseContext,
);
for await (const update of toolUpdates) {
yield update.message;
toolResults.push(update.message);
}
// 5. 注入运行时附加上下文
// ...(见下文)
// 6. 更新 messages,进入下一轮
state = {
messages: [...messagesForQuery, ...assistantMessages, ...toolResults],
transition: { reason: 'next_turn' },
};
}整个循环的流程:
每轮循环刷新了什么
前面列出 attachment 附加上下文的收集逻辑,不只在第一轮运行。工具执行完成后,Claude Code 会在下一次模型调用前重新注入 attachment 附加上下文,但这不是把已经注入过的内容全量重新注入一遍。多数 attachment 都有自己的触发条件或去重状态:没有新事件、新变化或到期提醒时,就不会产生新的 attachment。去重依据也分散在各类型自己的状态里,例如已发送过的 skill name、已读文件记录、队列消费状态、文件 diff 基线等。
后续轮次最常补进的是这些"增量变化":
- 排队消息:后台任务完成、外部通知、子 Agent 消息等异步事件,消费后会从队列移除。
- 文件变更:已经读入上下文的文件,如果被工具修改,只注入新的文本 diff 或图片内容。
- 预取记忆:记忆检索在模型返回工具调用时异步启动;结果只消费一次,并会过滤模型已读/已写/已编辑的记忆文件。
- 技能发现:基于本轮消息和工具写入信号预取;技能列表本身也记录已发送过的 skill name,只补新增项。
- 诊断信息:编辑文件后 IDE/LSP 产生新的错误或警告,再作为诊断类 attachment 附加上下文补给模型。
更准确地说,循环里的 attachment 机制是在每轮工具执行后做一次增量检查:只有发现新的队列消息、文件差异、检索结果或技能变化时,才把对应信息补进下一轮 Messages。下面这张图只抽取四类最典型的增量变化。
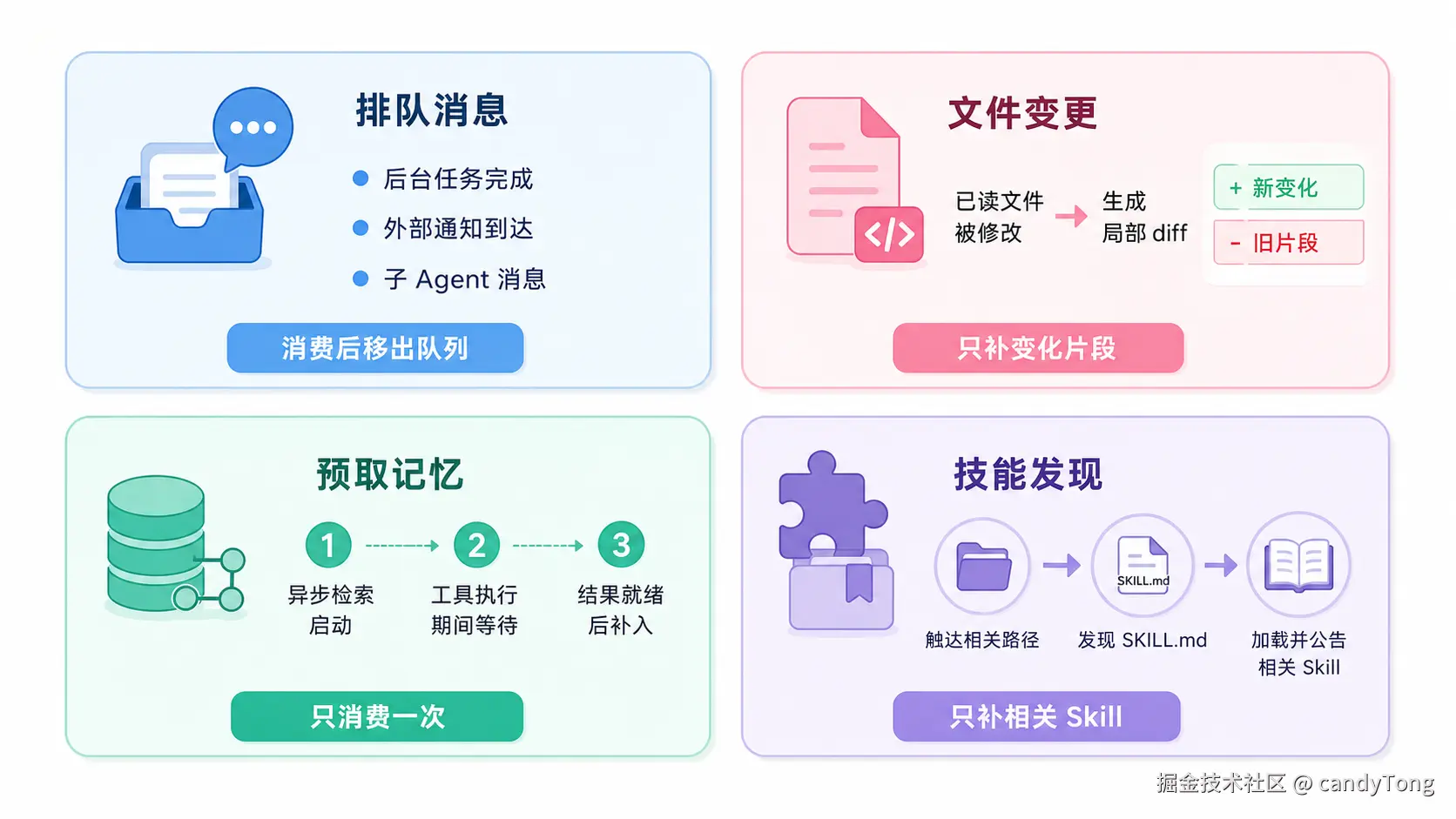
总结
Claude Code 的上下文不是一次性拼成一个静态大 prompt,而是分层组装、分阶段更新:
- System Prompt 承载稳定规则和动态段落边界,尽量让可缓存的前缀保持稳定。
- Tools 会根据内置工具、MCP、Agent、Skill 等来源组装,并在必要时通过延迟加载降低上下文负担。
- Messages 是 Agent Loop 中持续变化的主体:用户输入、模型回复、工具调用结果和 attachment 附加上下文都会按顺序进入消息流。
- attachment 附加上下文 是运行时补充上下文的关键机制:第一轮偏向用户输入和初始环境,后续轮次偏向工具执行后的增量变化。
因此,理解 Claude Code 的上下文组装,核心不是记住某一个固定 prompt 长什么样,而是看清楚三件事:哪些内容稳定、哪些内容按需装配、哪些内容会随着工具执行继续增量补进下一轮 Messages。
如果你觉得这篇文章有帮助,欢迎点赞、收藏,也可以关注我。