决策树:从西瓜分类到机器学习的"分而治之"艺术
夏天买西瓜时,你是不是会下意识地先看色泽、再摸根蒂、最后敲敲听声音?其实这个过程就是在无意识地使用决策树------通过一系列"是/否"问题逐步缩小范围,最终判断瓜甜不甜。决策树是机器学习中最直观、最贴近人类思考方式的算法,它把人类的经验转化为可执行的数学模型,完美诠释了"分而治之"的思想精髓。
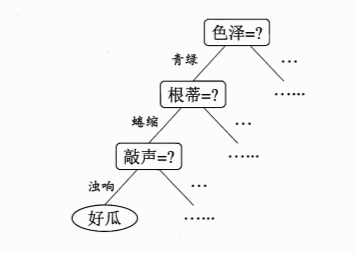
1 决策树的基本逻辑:像玩"20个问题"游戏
决策树是一种树状结构的分类模型,它的每一个内部节点对应一个"问题"(属性测试),每一条分支对应问题的一个答案,每一个叶节点对应一个类别标签。整个过程就像玩"20个问题"游戏:每次问一个最能区分样本的问题,把样本分成不同的子集,直到子集里的样本基本属于同一类别,或者问完所有问题。
1.1 决策树的组成
- 根节点:整个树的起点,对应第一个要问的问题
- 内部节点:中间的问题节点,对应某个属性的测试
- 分支:属性测试的结果,连接不同的节点
- 叶节点:最终的分类结果,对应某个类别
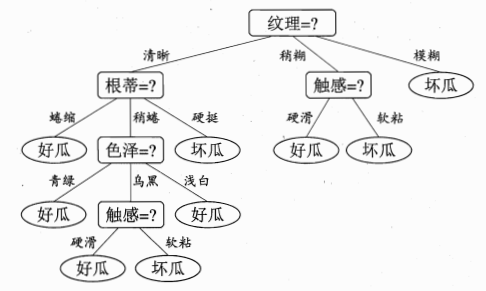
1.2 决策树的基本生成流程
决策树的生成遵循"递归划分"的原则:从根节点开始,每次选择最优的属性对样本集进行划分,直到满足停止条件。核心流程如下:
python
def decision_tree_generate(D, A, default_label):
"""
决策树生成基本算法
参数:
D: 训练样本集
A: 候选属性集合
default_label: 默认类别(当样本集为空时返回)
返回:
决策树根节点
"""
# 情况1:D中所有样本属于同一类别,返回该类别作为叶节点
if all_samples_same_class(D):
return LeafNode(label=D[0].label)
# 情况2:候选属性集为空,或D中所有样本在所有属性上取值相同,返回D中最多的类别
if not A or all_samples_same_attribute(D, A):
return LeafNode(label=most_common_class(D))
# 选择最优划分属性a*
best_attr = select_best_attribute(D, A)
# 生成根节点
root = InternalNode(attribute=best_attr)
# 遍历最优属性的每个取值v
for v in get_attribute_values(best_attr):
# 取出D中属性best_attr取值为v的样本子集Dv
Dv = get_subset_by_attribute(D, best_attr, v)
# 情况3:Dv为空,返回D中最多的类别作为叶节点
if not Dv:
root.add_branch(v, LeafNode(label=most_common_class(D)))
else:
# 递归生成子树,从候选属性集中移除已使用的best_attr
root.add_branch(v, decision_tree_generate(Dv, A - {best_attr}, most_common_class(D)))
return root通俗解释:这个算法就像你给朋友指路,先问"你在哪个路口?"(最优属性),然后根据不同的路口给出不同的下一步指引(分支),直到朋友到达目的地(叶节点)。如果朋友说的路口你不知道(Dv为空),就告诉他最常见的目的地(默认类别)。
2 怎么选"最好的问题":三大划分准则
决策树的核心是选择最优划分属性------我们希望每次划分后,子集的"纯度"尽可能高,也就是子集里的样本尽可能属于同一类别。衡量纯度的三大经典准则分别是信息增益(ID3算法)、增益率(C4.5算法)和基尼指数(CART算法)。
2.1 信息熵:样本集"混乱程度"的度量
在讲信息增益之前,我们先引入信息熵的概念,它用来衡量样本集的不确定性(混乱程度)。熵越大,样本集越混乱;熵越小,样本集越纯净。
信息熵的公式为:
Ent(D)=−∑k=1∣Y∣pklog2pkEnt(D) = -\sum_{k=1}^{|Y|} p_k \log_2 p_kEnt(D)=−k=1∑∣Y∣pklog2pk
其中:
- DDD:当前样本集
- ∣Y∣|Y|∣Y∣:类别总数(比如西瓜分类有"好瓜"和"坏瓜"两类,∣Y∣=2|Y|=2∣Y∣=2)
- pkp_kpk:样本集DDD中第kkk类样本所占的比例
通俗解释:想象一个班级,如果所有同学都喜欢数学,那么这个班级的熵是0(完全纯净);如果一半喜欢数学一半喜欢语文,熵是1(最混乱)。
2.2 信息增益(ID3算法)
信息增益表示通过属性aaa的划分,样本集的熵减少了多少。熵减少得越多,说明这个属性的划分效果越好。
信息增益的公式为:
Gain(D,a)=Ent(D)−∑v=1V∣Dv∣∣D∣Ent(Dv)Gain(D,a) = Ent(D) - \sum_{v=1}^{V} \frac{|D^v|}{|D|} Ent(D^v)Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
其中:
- aaa:待评估的属性
- VVV:属性aaa的所有可能取值的集合(比如属性"色泽"有"青绿""乌黑""浅白"三个取值,V=3V=3V=3)
- DvD^vDv:样本集DDD中属性aaa取值为vvv的样本子集
- ∣D∣|D|∣D∣:样本集DDD的样本总数,∣Dv∣|D^v|∣Dv∣:子集DvD^vDv的样本总数
西瓜数据集实战:计算信息增益
我们以经典的西瓜数据集2.0为例,计算各个属性的信息增益,选择根节点。
表1 西瓜数据集2.0(出自《机器学习》周志华 表4.1)
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
步骤1:计算根节点的信息熵
数据集共有17个样本,其中好瓜8个,坏瓜9个,因此:
Ent(D)=−(817log2817+917log2917)≈0.998Ent(D) = -\left( \frac{8}{17}\log_2\frac{8}{17} + \frac{9}{17}\log_2\frac{9}{17} \right) \approx 0.998Ent(D)=−(178log2178+179log2179)≈0.998
步骤2:计算属性"色泽"的信息增益
属性"色泽"有3个取值:青绿、乌黑、浅白,对应的子集分别为:
- D1D^1D1(青绿):6个样本,好瓜3个,坏瓜3个,Ent(D1)=1.0Ent(D^1) = 1.0Ent(D1)=1.0
- D2D^2D2(乌黑):6个样本,好瓜4个,坏瓜2个,Ent(D2)≈0.918Ent(D^2) \approx 0.918Ent(D2)≈0.918
- D3D^3D3(浅白):5个样本,好瓜1个,坏瓜4个,Ent(D3)≈0.722Ent(D^3) \approx 0.722Ent(D3)≈0.722
因此信息增益为:
Gain(D,色泽)=0.998−(617×1.0+617×0.918+517×0.722)≈0.109Gain(D,色泽) = 0.998 - \left( \frac{6}{17}\times1.0 + \frac{6}{17}\times0.918 + \frac{5}{17}\times0.722 \right) \approx 0.109Gain(D,色泽)=0.998−(176×1.0+176×0.918+175×0.722)≈0.109
步骤3:计算其他属性的信息增益
按照同样的方法,我们可以计算出所有属性的信息增益:
- Gain(D,根蒂)≈0.143Gain(D,根蒂) \approx 0.143Gain(D,根蒂)≈0.143
- Gain(D,敲声)≈0.141Gain(D,敲声) \approx 0.141Gain(D,敲声)≈0.141
- Gain(D,纹理)≈0.381Gain(D,纹理) \approx 0.381Gain(D,纹理)≈0.381
- Gain(D,脐部)≈0.289Gain(D,脐部) \approx 0.289Gain(D,脐部)≈0.289
- Gain(D,触感)≈0.006Gain(D,触感) \approx 0.006Gain(D,触感)≈0.006
可以看到,属性"纹理"的信息增益最大,因此我们选择"纹理"作为根节点的划分属性。
2.3 增益率(C4.5算法)
ID3算法有一个明显的缺陷:偏向于取值多的属性。比如如果有一个属性是"编号",每个样本的编号都不同,那么划分后每个子集只有一个样本,熵为0,信息增益最大,但这样的划分完全没有泛化能力。
为了解决这个问题,C4.5算法使用增益率 来选择最优属性,公式为:
Gain_ratio(D,a)=Gain(D,a)IV(a)Gain\_ratio(D,a) = \frac{Gain(D,a)}{IV(a)}Gain_ratio(D,a)=IV(a)Gain(D,a)
其中IV(a)IV(a)IV(a)是属性aaa的固有值 ,用来惩罚取值多的属性:
IV(a)=−∑v=1V∣Dv∣∣D∣log2∣Dv∣∣D∣IV(a) = -\sum_{v=1}^{V} \frac{|D^v|}{|D|} \log_2 \frac{|D^v|}{|D|}IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
通俗解释 :属性的取值越多,IV(a)IV(a)IV(a)越大,增益率就越小,这样就避免了算法偏向取值多的属性。不过增益率又会偏向取值少的属性,因此C4.5算法采用了一个折中策略:先从候选属性中选出信息增益高于平均水平的属性,再从中选择增益率最高的。
2.4 基尼指数(CART算法)
CART(分类与回归树)算法使用基尼指数来衡量样本集的纯度,它反映了从样本集中随机抽取两个样本,它们的类别不一致的概率。基尼指数越小,样本集越纯净。
基尼指数的公式为:
Gini(D)=1−∑k=1∣Y∣pk2Gini(D) = 1 - \sum_{k=1}^{|Y|} p_k^2Gini(D)=1−k=1∑∣Y∣pk2
其中pkp_kpk的含义与信息熵公式中相同。
属性aaa的基尼指数定义为:
Gini_index(D,a)=∑v=1V∣Dv∣∣D∣Gini(Dv)Gini\index(D,a) = \sum{v=1}^{V} \frac{|D^v|}{|D|} Gini(D^v)Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
我们选择基尼指数最小的属性作为最优划分属性。
通俗解释:如果一个班级里所有同学都喜欢数学,那么随机抽两个同学,他们喜好不同的概率是0,基尼指数为0;如果一半喜欢数学一半喜欢语文,这个概率是0.5,基尼指数为0.5。
2.5 三大划分准则对比
表2 三大划分准则对比
| 准则 | 代表算法 | 优点 | 缺点 |
|---|---|---|---|
| 信息增益 | ID3 | 计算简单,直观易懂 | 偏向取值多的属性 |
| 增益率 | C4.5 | 解决了ID3的偏向问题 | 偏向取值少的属性 |
| 基尼指数 | CART | 计算速度快(无需对数运算) | 对不平衡数据集较敏感 |
3 防止"过拟合":给决策树"剪枝"
如果我们让决策树无限生长,它会记住训练集中的每一个样本,甚至包括噪声和异常点,导致过拟合------在训练集上表现完美,但在新的测试集上表现很差。这就像一个学生死记硬背了所有考试题,但遇到稍微变形的题目就不会做了。
解决过拟合的核心方法是剪枝 :剪掉决策树中那些对提升泛化性能没有帮助的分支。剪枝分为预剪枝 和后剪枝两种。
3.1 预剪枝:提前停止划分
预剪枝是在决策树生成过程中,对每个节点在划分前先进行估计:如果当前节点的划分不能提升模型在验证集上的精度,就停止划分,将当前节点标记为叶节点。
未剪枝决策树:
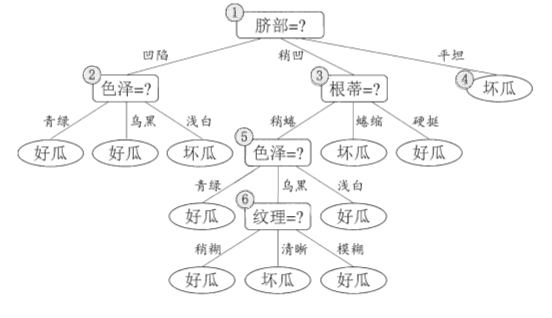
我们以西瓜数据集2.0为例,将前10个样本作为训练集,后7个作为验证集。根节点不划分时,所有样本都标记为"好瓜"(训练集中好瓜最多),验证集精度为37≈42.9%\frac{3}{7} \approx 42.9\%73≈42.9%。如果划分属性"脐部",划分后验证集精度提升到57≈71.4%\frac{5}{7} \approx 71.4\%75≈71.4%,因此允许划分。继续递归这个过程,直到划分不能提升精度为止。
预剪枝决策树:
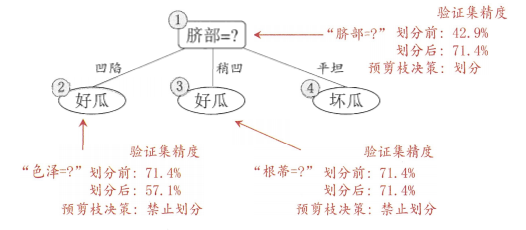
预剪枝的优缺点:
- 优点:计算速度快,降低了过拟合风险
- 缺点:容易产生欠拟合------有些分支虽然当前划分不能提升精度,但后续划分可能会显著提升精度,预剪枝会提前剪掉这些有潜力的分支
3.2 后剪枝:先生成再剪枝
后剪枝是先生成一棵完整的决策树,然后自底向上对每个非叶节点进行考察:如果将该节点的子树替换为叶节点能提升验证集精度,就剪掉这个子树。
未剪枝决策树:
后剪枝决策树:
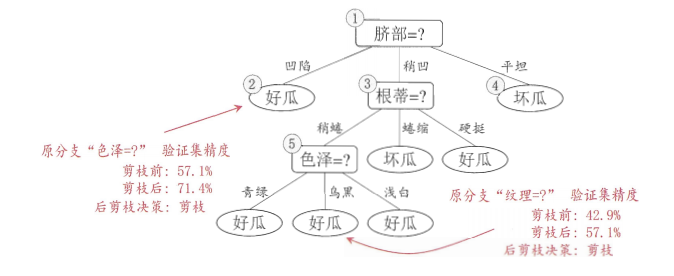
后剪枝的优缺点:
- 优点:泛化性能通常优于预剪枝,欠拟合风险低
- 缺点:计算量大,需要先生成完整的树,再自底向上逐个节点考察
4 处理复杂数据:连续值与缺失值
前面我们讨论的都是离散属性,但现实中很多属性是连续的(比如西瓜的密度、含糖率),而且数据中经常会有缺失值。决策树可以很好地处理这两种情况。
4.1 连续值处理:二分法
对于连续属性aaa,我们不能直接按其取值划分,因为连续属性的取值是无限的。C4.5算法使用二分法来处理连续属性:
- 将连续属性aaa的所有取值从小到大排序,得到{a1,a2,...,an}\{a^1, a^2, ..., a^n\}{a1,a2,...,an}
- 生成候选划分点集合:Ta={ai+ai+12∣1≤i≤n−1}T_a = \left\{ \frac{a^i + a^{i+1}}{2} \mid 1 \leq i \leq n-1 \right\}Ta={2ai+ai+1∣1≤i≤n−1},即相邻两个取值的中点
- 计算每个候选划分点的信息增益,选择信息增益最大的划分点
例如西瓜的"密度"属性取值排序后为:0.243, 0.245, 0.343, ..., 0.774,候选划分点就是0.244, 0.294, ..., 0.697。计算每个划分点的信息增益,最终选择最大的那个作为划分点。
4.2 缺失值处理:权重法
现实数据中经常会有样本的某些属性值缺失(比如某个西瓜的"触感"没记录)。处理缺失值需要解决两个问题:
- 如何计算属性的信息增益?
- 如何将有缺失值的样本划分到不同的分支?
C4.5算法使用权重法 来解决这两个问题:给每个样本赋予一个权重www(初始为1),然后:
- 计算信息增益时,只使用属性aaa没有缺失值的样本,信息增益公式变为:
Gain(D,a)=ρ×Gain(D~,a)Gain(D,a) = \rho \times Gain(\tilde{D},a)Gain(D,a)=ρ×Gain(D~,a)
其中ρ=∑x∈D~wx∑x∈Dwx\rho = \frac{\sum_{x \in \tilde{D}} w_x}{\sum_{x \in D} w_x}ρ=∑x∈Dwx∑x∈D~wx是无缺失值样本的权重比例,D~\tilde{D}D~是属性aaa无缺失值的样本子集。 - 划分样本时,将有缺失值的样本按权重比例同时划分到所有分支。例如一个样本的属性aaa缺失,属性aaa有3个取值,那么这个样本会被划分到3个分支,每个分支中的样本权重为原来的13\frac{1}{3}31。
5 突破轴平行限制:多变量决策树
前面介绍的决策树都是单变量决策树 ,每个节点只测试一个属性,因此它的划分边界是轴平行的------只能沿着坐标轴方向划分样本空间。这种划分方式虽然简单,但对于一些复杂的分布,需要很多次划分才能得到较好的结果,导致树的结构非常复杂。
多变量决策树解决了这个问题,它的每个节点测试的是多个属性的线性组合,划分边界可以是任意方向的直线(甚至曲线),因此可以用更简单的树结构来拟合复杂的数据分布。
单变量与多变量决策树划分边界对比
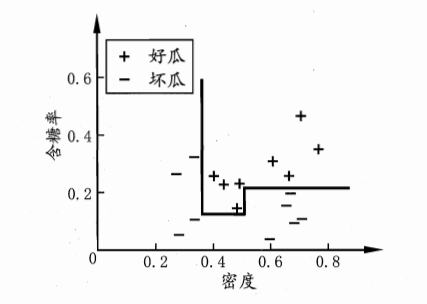
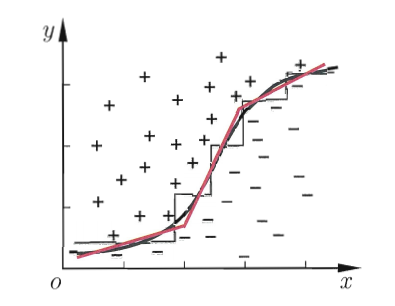
例如,单变量决策树可能需要先按"密度≥0.5"划分,再按"含糖率≥0.2"划分;而多变量决策树可以直接用"0.7×密度 + 0.3×含糖率 ≥ 0.5"这样的线性组合作为划分条件,一次划分就能得到更好的结果。
6 核心代码实现
6.1 简化版ID3算法实现
python
import numpy as np
from collections import Counter
class DecisionTreeID3:
def __init__(self):
self.tree = None
def _entropy(self, y):
"""计算信息熵"""
counts = Counter(y)
probs = [count / len(y) for count in counts.values()]
return -sum(p * np.log2(p) for p in probs if p > 0)
def _information_gain(self, X, y, feature_idx):
"""计算信息增益"""
# 原始熵
original_ent = self._entropy(y)
# 按特征取值分组
feature_values = X[:, feature_idx]
unique_values = np.unique(feature_values)
# 计算划分后的熵
new_ent = 0
for v in unique_values:
mask = feature_values == v
subset_y = y[mask]
new_ent += len(subset_y) / len(y) * self._entropy(subset_y)
return original_ent - new_ent
def _select_best_feature(self, X, y):
"""选择信息增益最大的特征"""
gains = [self._information_gain(X, y, i) for i in range(X.shape[1])]
return np.argmax(gains)
def fit(self, X, y, feature_names):
"""训练决策树"""
self.feature_names = feature_names
self.tree = self._build_tree(X, y)
def _build_tree(self, X, y):
"""递归构建决策树"""
# 所有样本属于同一类别
if len(np.unique(y)) == 1:
return y[0]
# 没有特征可选
if X.shape[1] == 0:
return Counter(y).most_common(1)[0][0]
# 选择最优特征
best_idx = self._select_best_feature(X, y)
best_feature = self.feature_names[best_idx]
# 构建树节点
tree = {best_feature: {}}
# 遍历最优特征的所有取值
unique_values = np.unique(X[:, best_idx])
for v in unique_values:
mask = X[:, best_idx] == v
subset_X = X[mask]
subset_y = y[mask]
# 移除已使用的特征
subset_X = np.delete(subset_X, best_idx, axis=1)
sub_feature_names = [f for i, f in enumerate(self.feature_names) if i != best_idx]
# 递归构建子树
tree[best_feature][v] = self._build_tree(subset_X, subset_y)
return tree
def predict(self, x):
"""预测单个样本"""
node = self.tree
while isinstance(node, dict):
feature = next(iter(node.keys()))
feature_idx = self.feature_names.index(feature)
value = x[feature_idx]
node = node[feature][value]
return node
# 测试:西瓜数据集2.0简化版
X = np.array([
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘'],
])
y = np.array(['是', '是', '是', '否', '否'])
feature_names = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感']
# 训练模型
model = DecisionTreeID3()
model.fit(X, y, feature_names)
print("生成的决策树:", model.tree)
# 预测
x_test = ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑']
print("预测结果:", model.predict(x_test))6.2 sklearn调用决策树分类器
python
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 加载鸢尾花数据集
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
# 训练CART决策树(基尼指数)
clf_gini = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=42)
clf_gini.fit(X_train, y_train)
# 训练C4.5风格决策树(信息增益)
clf_entropy = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=42)
clf_entropy.fit(X_train, y_train)
# 评估模型
y_pred_gini = clf_gini.predict(X_test)
y_pred_entropy = clf_entropy.predict(X_test)
print(f"基尼指数模型精度:{accuracy_score(y_test, y_pred_gini):.2f}")
print(f"信息增益模型精度:{accuracy_score(y_test, y_pred_entropy):.2f}")
# 可视化决策树
plt.figure(figsize=(12, 8))
plot_tree(clf_gini, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()7 总结
决策树是机器学习中最基础、最实用的算法之一,它的核心思想是"分而治之",通过递归划分样本集来构建树状模型。我们学习了:
- 基本流程:从根节点开始,递归选择最优属性划分样本,直到满足停止条件
- 三大划分准则:信息增益、增益率、基尼指数,分别对应ID3、C4.5、CART算法
- 剪枝技术:预剪枝和后剪枝,用于防止过拟合
- 复杂数据处理:用二分法处理连续值,用权重法处理缺失值
- 多变量决策树:突破轴平行限制,用线性组合属性进行划分
决策树的优点是可解释性强、无需特征缩放、能处理离散和连续数据;缺点是容易过拟合、对数据敏感、泛化能力有限。不过,基于决策树的集成学习算法(如随机森林、梯度提升树)很好地解决了这些问题,成为了工业界最常用的机器学习模型之一。