前言
在移动端开发的演进浪潮中,声明式 UI(Declarative UI)已经成为了毋庸置疑的行业标准。伴随着 HarmonyOS 及其核心开发框架 ArkUI 的繁荣,开发者们体验到了状态驱动视图的极速快感。然而,在享受 UI = f(State) 这一优雅公式的同时,无数大型项目也正悄然陷入工程化的泥沼:当网络请求、复杂的数据清洗、甚至核心的业务算法被随意地揉捏在组件的 build() 函数或是生命周期钩子中时,"面条代码"便应运而生。这不仅会导致极高的代码认知负载,更会因为滥用状态绑定而引发频繁的冗余渲染,最终侵蚀应用的运行性能。

《轻心记 (MoodLite)》作为一款主打情绪追踪与自我觉察的原生应用,在其架构设计的初期便确立了极高的工程标准。面对日历热力图、时间轴列表、月度趋势统计等高度复杂且视角各异的数据可视化需求,MoodLite 团队坚决摒弃了散装的代码堆砌,全面引入了严格的模块化与分层解耦思想。
本文将深入剖析 MoodLite 是如何在 ArkUI (ArkTS) 环境下,从底层数据模型、中间态视图模型(ViewModel)到最上层的纯粹 UI 组件,一步步实现数据逻辑与 UI 渲染的彻底解耦,构建出一套高内聚、低耦合的现代化鸿蒙应用底座。
一、声明式 UI 的工程化阵痛与架构破局

在传统的命令式 UI(如 Android 的 View 体系或 iOS 的 UIKit)中,开发者习惯于通过 findViewById 拿到控件实例,然后主动调用 setText() 或 setBackground()。而在 ArkUI 的声明式范式下,控件变成了"数据的映射",开发者只需要修改被 @State 或 @Prop 修饰的变量,框架便会自动触发组件的重新渲染。
这种机制的"双刃剑"效应在于:它太容易让开发者模糊数据与视图的边界。 假设我们需要在屏幕上渲染一个"情绪热力图"。底层数据库拉取上来的往往是扁平的记录数组,而 UI 层需要的却是一个包含 35 个格子(含前后月占位符)、且每个格子带有具体颜色代码的二维网格结构。如果将这层"数据变形"逻辑直接写在 UI 组件内部,就会导致:
- 主线程阻塞:复杂的数组遍历和日期计算会抢占 ArkUI 的主线程资源,导致页面切换时发生掉帧。
- 幽灵重绘:一旦状态变量发生细微改变,整个包含复杂计算的组件树可能被全量重建,带来极大的性能灾难。
- 不可测试:夹杂在 UI 组件中的业务逻辑无法脱离鸿蒙设备或模拟器进行独立的单元测试。
为了破局,MoodLite 确立了以 MVVM 为基础,并融合领域驱动设计(DDD)理念的分层架构:
- Model 层:作为全局唯一的"单一事实来源(Single Source of Truth)",定义最原生的数据结构。
- ViewModel 层(数据聚合引擎):充当防腐层。它吸收原生数据,进行重组、聚合、清洗,最终输出极其纯粹的、UI 可以直接"拿来即用"的属性集合。
- View 层:绝对的"哑终端"。仅负责根据 ViewModel 提供的数据进行布局描述和样式渲染。
二、坚如磐石的地基:构建单一事实来源(SSOT)

在解耦的第一步,我们必须定义清楚"什么是数据"。在 MoodLite 中,所有的情绪交互最终都会收敛为一个核心的领域模型:MoodRecord。
2.1 领域模型 MoodRecord 的严谨定义
为了保证各页面、各组件对数据结构的认知绝对统一,项目中严禁在页面层(如 pages/ 目录下)私自 interface 或 class 重复的数据结构,而是强制统一引用 model/MoodRecord.ets 中的定义:
TypeScript
/**
* 单条情绪记录
*/
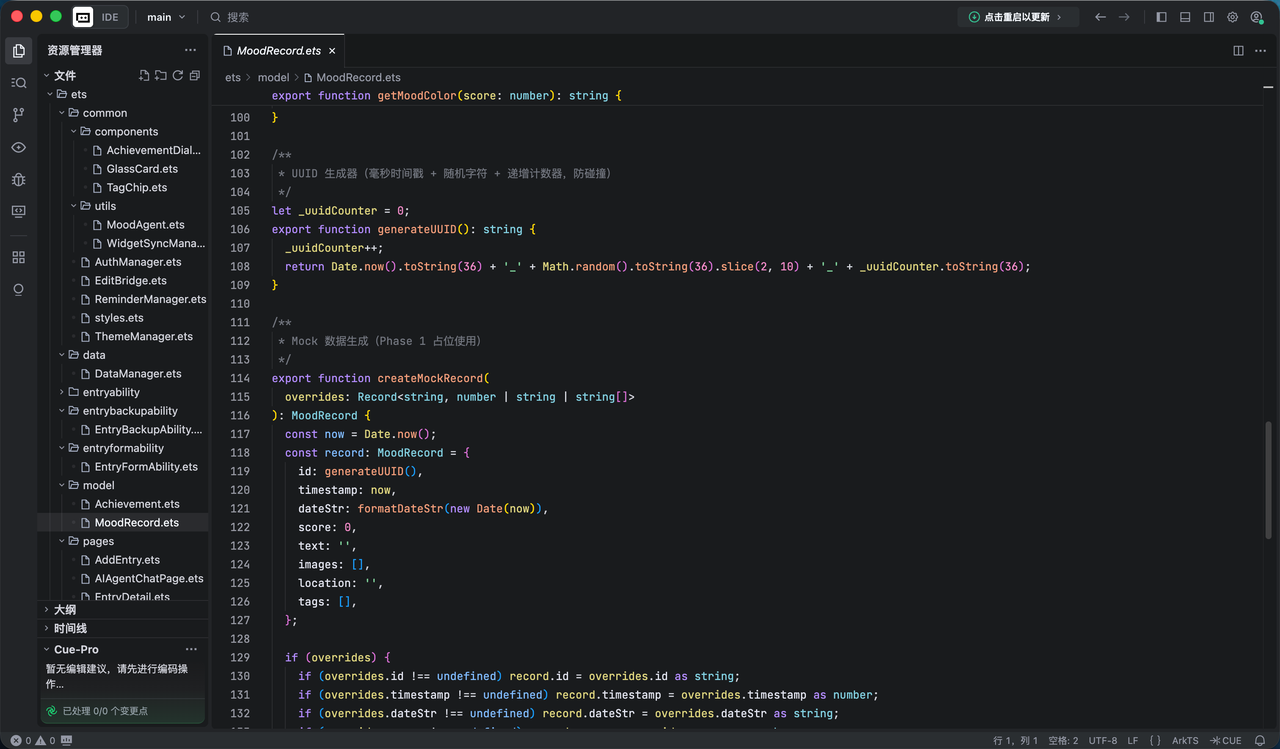
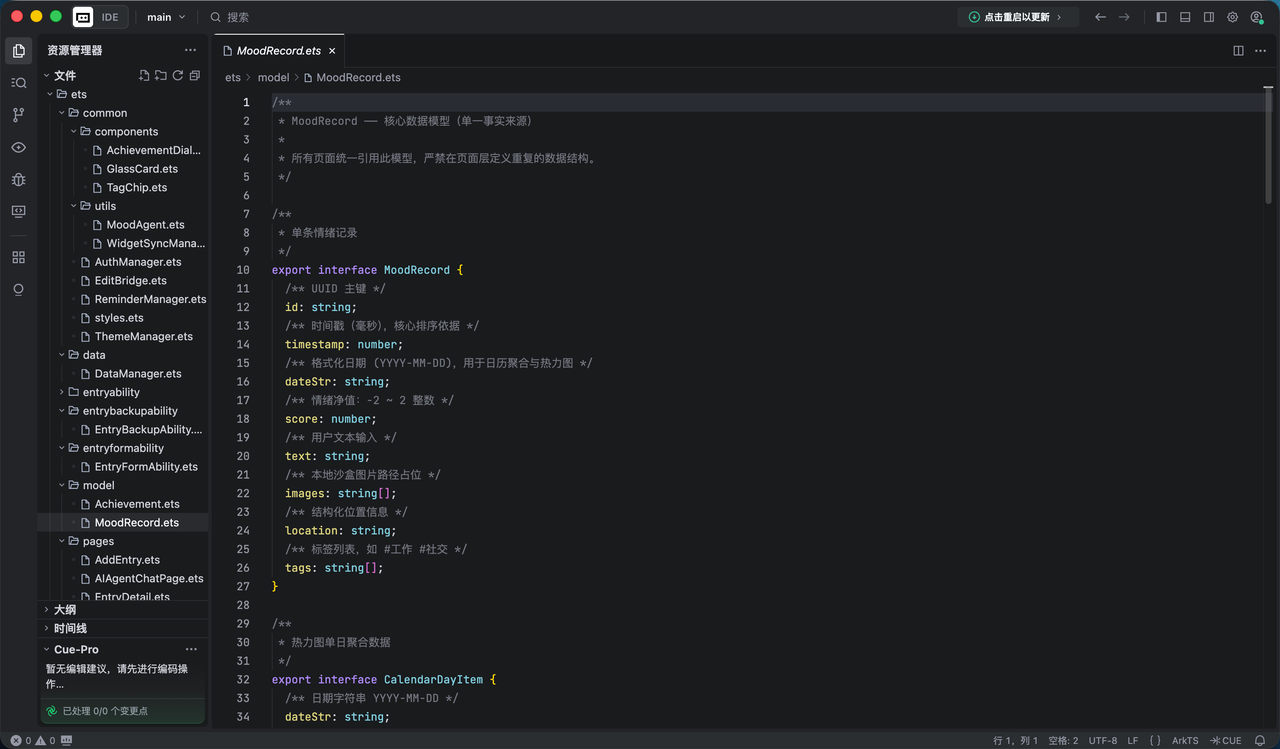
export interface MoodRecord {
/** UUID 主键 */
id: string;
/** 时间戳(毫秒),核心排序依据 */
timestamp: number;
/** 格式化日期 (YYYY-MM-DD),用于日历聚合与热力图 */
dateStr: string;
/** 情绪净值:-2 ~ 2 整数 */
score: number;
/** 用户文本输入 */
text: string;
/** 本地沙盒图片路径占位 */
images: string[];
/** 结构化位置信息 */
location: string;
/** 标签列表,如 #工作 #社交 */
tags: string[];
}
这个接口看似简单,实则包含了多项工程考量:
- 确定性的核心指标 :
score被严格限制在 -2 到 2 的整数。这个量化指标是所有后续统计、颜色映射的基础。 - 唯一标识 :
id采用自定义的 UUID 策略(结合毫秒时间戳、随机字符与递增计数器generateUUID()),确保在多端同步或高频连续快速记录时绝对不会发生主键碰撞。
2.2 空间换时间的智慧:dateStr 与 timestamp 的共存哲学
细心的开发者会发现,MoodRecord 中同时存在 timestamp(毫秒级时间戳)和 dateStr(格式化日期字符串,如 2026-05-28)。
从传统数据库范式来看,这属于数据冗余,因为字符串完全可以在运行时通过时间戳转换得出。但这就是架构设计中"空间换时间"的典型权衡。
在 ArkUI 中,Date 对象的实例化以及字符串拼接(如 date.getFullYear() + '-' + ...)在大量循环中是昂贵的操作。当用户打开年度统计视图,系统需要瞬间处理上千条记录并将其归类到 365 个天数桶中。如果此时再临时解析时间戳,将会直接导致界面卡顿。
通过在数据创建时(Data Creation Phase)就计算好 dateStr 并在底层持久化,后续所有的按日聚合、匹配、查询,就全部降维成了极其轻量级的字符串哈希匹配(HashMap Key-Value Lookup)。UI 渲染层甚至可以直接将 dateStr 当作文本组件的入参,彻底剥离了时间格式化逻辑。
三、防腐层与数据泵:StatsViewModel 聚合引擎
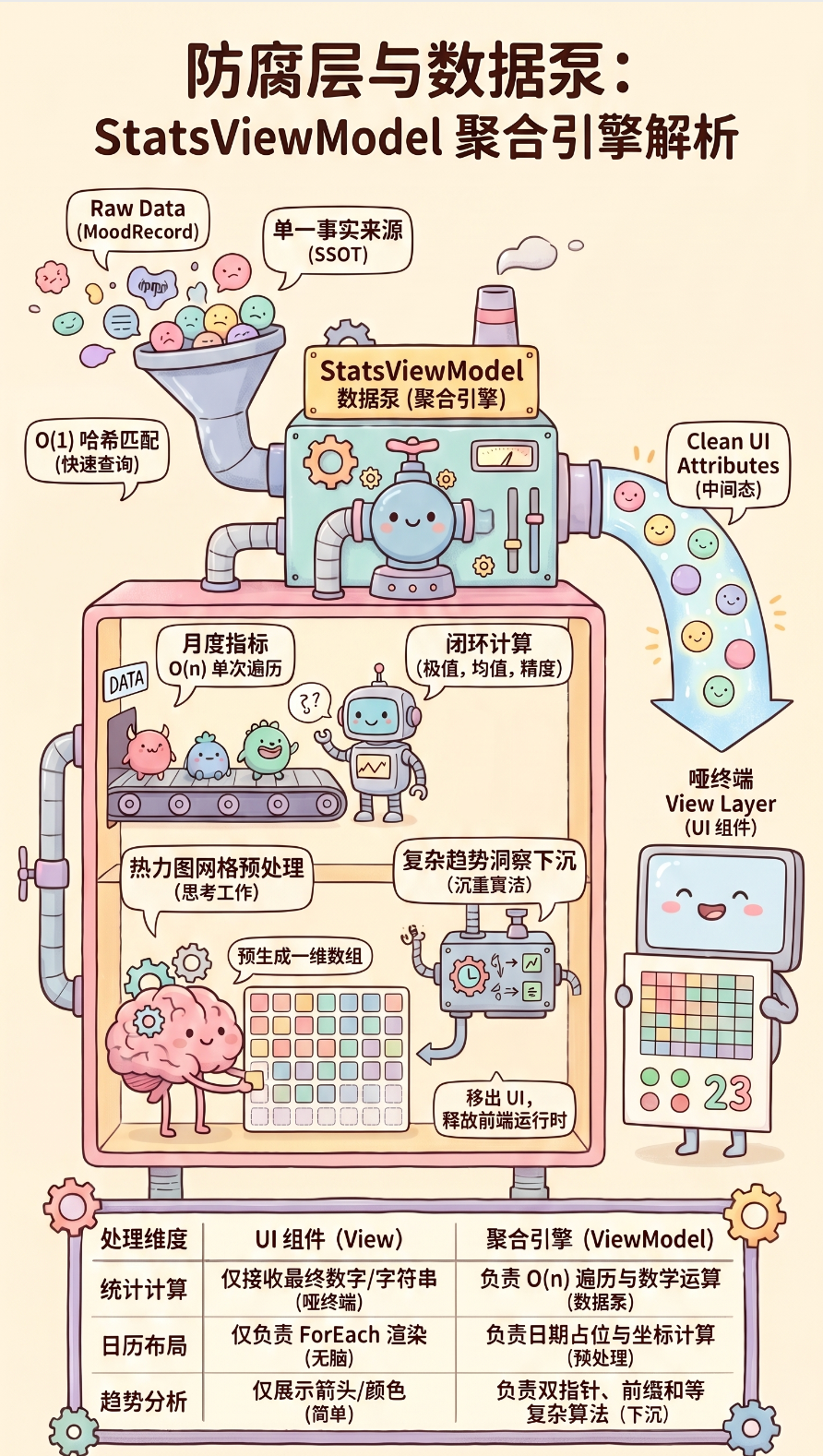
有了原生的 MoodRecord,我们依然不能将其直接抛给视图。例如,月度统计概览卡片需要展示"本月平均分"、"最高分"、"愉悦天数",这些派生数据(Derived Data)如果让 UI 组件自己去算,就破坏了纯粹性。
为此,MoodLite 构建了极其强大的 StatsViewModel.ets,它作为专门的数据聚合层,承担了所有的"脏活累活"。
3.1 剥离计算逻辑:月度指标聚合分析
在 StatsViewModel.ets 中,我们定义了专为概览卡片服务的视图模型 MonthlyStats:
TypeScript
export interface MonthlyStats {
year: number;
month: number;
totalDays: number;
happyRecords: number;
neutralRecords: number;
sadRecords: number;
averageScore: number;
maxScore: number;
minScore: number;
}
其对应的计算引擎 calcMonthlyStats 方法,接受年份、月份和一维的记录数组,通过单次遍历(O(n) 时间复杂度),利用 Set 计算去重后的记录天数,并累加分值。所有的极值判断(Math.max / Math.min)、除法求平均值、以及浮点数的精度保留(Math.round(x * 10) / 10),全都被死死地封锁在这个纯 TypeScript 函数内部。
最终,UI 组件拿到的 averageScore 已经是一个处理完美的数字,只需负责设置 FontSize 和 FontColor 即可。
3.2 抹平视图差异:热力图网格的数据预处理
热力图组件的渲染是重灾区。ArkUI 的 Grid 组件本身是"无脑"的,它不知道当前月的第一天是星期几,也不知道上个月需要留出几个空格来填充。
如果让 Grid 去动态计算位置,代码将不堪入目。因此,我们在 StatsViewModel 中设计了 CalendarDayItem 视图模型,并提供了 generateCalendarGrid 方法。
TypeScript
// StatsViewModel.ets 节选
export function generateCalendarGrid(
year: number,
month: number,
monthRecords: MoodRecord[]
): CalendarDayItem[] {
// ... (日期计算逻辑)
// 1. 填充上个月的占位白块 (isCurrentMonth: false)
for (let i = 0; i < startWeekday; i++) {
// 构造空数据推进数组
}
// 2. 利用 Map 实现 O(1) 的当日数据聚合
const dayMap = new Map<string, DayAgg>();
for (const r of monthRecords) {
// ... 计算单日内的所有情绪和,统计正负情绪数量
}
// 3. 生成本月实体数据
for (let d = 1; d <= daysInMonth; d++) {
// 提取日均分、计算当天的混合情绪代码 moodCode
}
// 4. 填充下个月的占位白块,凑齐 6 行 (DAYS_IN_WEEK * 6)
return grid;
}这段代码展现了极致的解耦思维。ViewModel 主动承担了日历学算计的责任,它直接输出一个固定长度(通常为 35 或 42)的一维数组。数组里的每一个 CalendarDayItem 都明确标明了 isCurrentMonth 标志和 moodCode。
UI 组件 Grid 拿到这个数组后,无论它是哪年哪月,只需要直接无脑地配合 ForEach 渲染方块,将 moodCode 丢给颜色映射函数即可。这不仅消灭了 UI 层的计算逻辑,更完美规避了 ArkUI 在复杂布局计算中可能出现的测量溢出问题。
3.3 复杂趋势洞察:连胜打卡与走向判定
对于一款以长期记录为导向的应用,鼓励用户持续记录(Streak)和分析情绪走向是核心体验。这些高级功能的算法极为复杂:
calcStreak:需要遍历历史数据,计算用户当前的连续记录天数,还要容错(比如今天还没记录,但昨天记录了,不能直接把当前连胜清零)。calcTrendDirection:需要将一个月分为上下半月,对比两段周期的平均情绪分数,得出improving(好转)、declining(恶化)或stable(平稳)的趋势结论。
通过将这些沉重的算法下沉到 ViewModel 中,并在其中运用双指针、前缀和等算法思想优化时间复杂度,应用的前端运行时得到了极大的释放。UI 层仅仅是在接收到 improving 这个字符串时,展示一个向上的绿色箭头而已。
四、让 View 纯粹如镜:TimelineTab 的渲染哲学
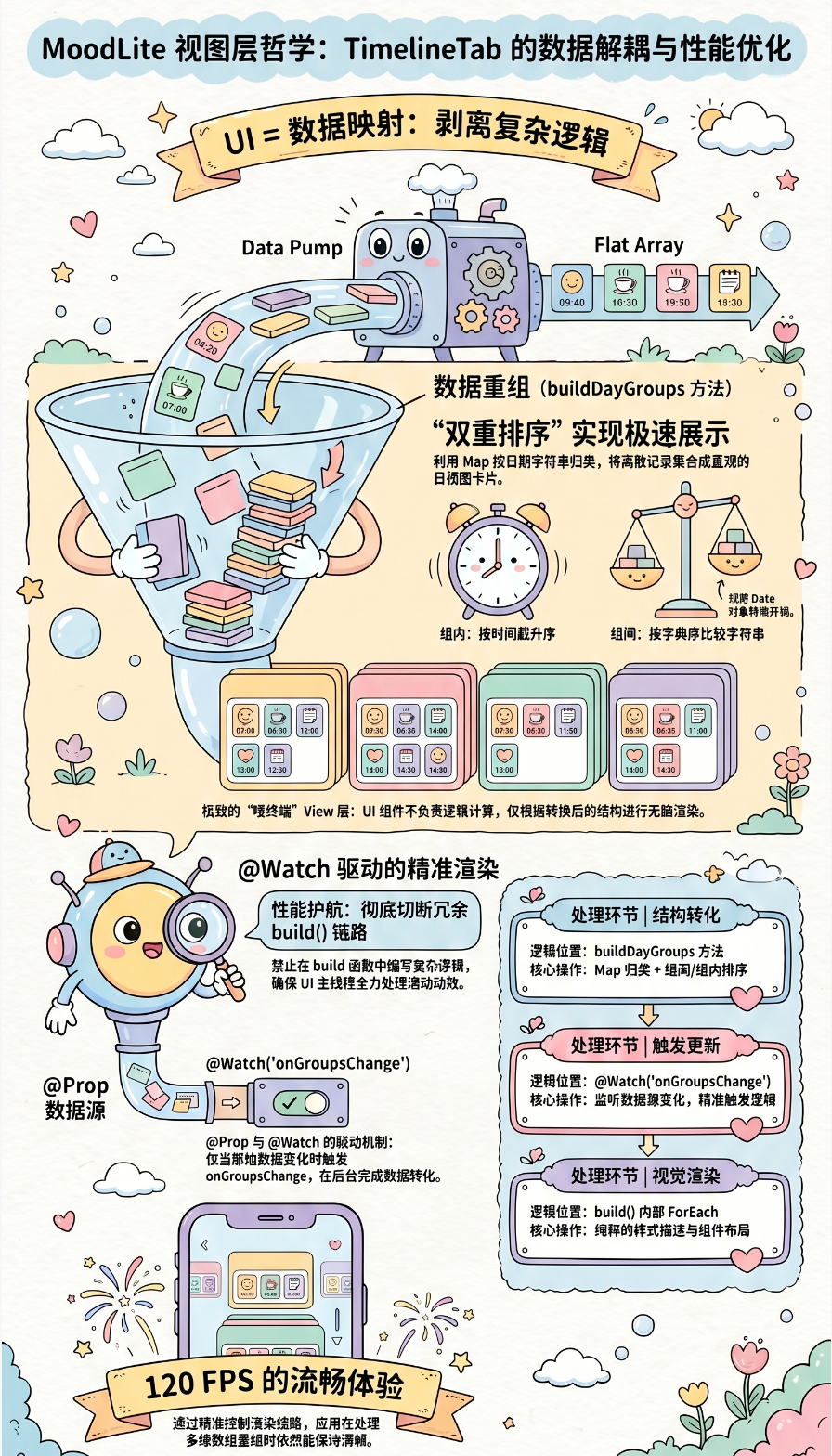
我们已经有了完美的底层数据和中间态聚合引擎,那么真正的 UI 组件应该长什么样?项目中 TimelineTab.ets(记录时间线)为我们交出了一份纯粹的答卷。
4.1 数据重组:从扁平数组到结构化卡片分组
在时间线页面中,我们需要按"天"作为卡片,把同一天内的多条记录塞进同一个卡片里。这就要求原本扁平的 MoodRecord[] 被转换为类似分组列表的形式。
在 TimelineTab.ets 的内部,定义了一个局部的视图接口 DayGroup:
TypeScript
interface DayGroup {
dateStr: string;
records: MoodRecord[];
dominantScore: number;
}
UI 组件并不直接循环原始数据,而是依赖 buildDayGroups 方法将传入的记录进行转化。在这个方法中,使用 Map 对 dateStr 进行归类,并且严格执行了两次排序:
- 组内排序 :同一天内的数据,按照
timestamp升序排列(旧的在上,新的在下)。 - 组间排序 :不同日期的分组,按照
dateStr的字符串字典序进行比较(localeCompare),实现日期的有序排列。
因为在之前的 MoodRecord 定义中保留了格式统一的 dateStr (如 2026-05-28 永远比 2026-05-01 在字典序上靠后),这里的日期排序甚至连转换为 Date 对象的开销都省了,直接利用底层字符串比较的 C++ 实现,速度极快。
4.2 响应式与性能约束:@Watch 的精准控制
在声明式 UI 中,如何监听父组件传递的数据并更新自身状态是一门学问。在 TimelineTab 中,采用了 @Prop 结合 @Watch 的机制:
TypeScript
@Prop @Watch('onGroupsChange') groupedRecords: MonthGroup[] = [];
onGroupsChange(): void {
this.refreshDays();
}
refreshDays(): void {
const monthKey = this.currentYear + '年' + this.currentMonth + '月';
const group = this.groupedRecords.find(g => g.monthTitle === monthKey);
this.dayGroups = group ? this.buildDayGroups(group.records) : [];
}这种写法的巧妙之处在于:组件并没有将繁重的数据重组逻辑(buildDayGroups)写在被高频调用的 build() 函数里。
只有当外部传入的 groupedRecords 发生实质性变化时,系统才会回调 onGroupsChange,进而在后台执行数据转化,最后更新被 @State 修饰的 dayGroups。
此时 build() 函数内部的 List 和 ForEach 只需要监听 dayGroups 即可。这彻底切断了"非必要渲染"的链路,将 UI 的主线程完全留给了列表的滚动动效和绘制操作。
此外,UI 中的颜色决策逻辑也同样做到了极简。比如在生成侧边的时间线轴节点颜色时,直接委托给了 ViewModel 中高度成熟的工具函数:
TypeScript
computeMoodCode(records: MoodRecord[]): number {
// ... 委托至 StatsViewModel 的 computeMoodCode
return calcMoodCode(pos, neg);
}通过调用 heatmapColor(code, absScore, ...),UI 组件无需关心"愉快是粉色还是金色,暗黑模式下怎么减淡",它只索取最终渲染引擎需要的 Hex 色值。
五、解耦带来的长远工程收益

通过对 MoodLite V2.0 源码的深度剖析,我们可以清晰地看到:将 UI 渲染与数据逻辑进行强制性的物理与逻辑隔离,带来的绝不仅仅是代码层面的"美观",而是关乎应用生命周期的四大长远收益:
- 极致的性能下限:通过将耗时的字典映射、极值计算、多维数组重组等任务提前在 ViewModel 中完成,ArkUI 的主线程卸下了最沉重的包袱。无论用户滑动多快的列表,或者切换多复杂的图表,界面都能稳稳保持在 120 FPS。
- 零成本的测试驱动(TDD) :因为
StatsViewModel.ets中的所有方法(如calcWeeklyBreakdown、calcStreak)都不包含任何鸿蒙 UI 的专属 API 依赖,它们是纯粹的 TypeScript 方法。开发团队可以在没有任何模拟器介入的情况下,在 Node.js 环境中对核心算法进行毫秒级的批量单元测试,极大保障了金融级的数据统计准确性。 - 心智负担的断崖式下降 :接手项目的开发者,再也不需要在几千行的
.ets文件中寻找究竟是哪一行代码改错了数据。要修改卡片的边距和毛玻璃效果?直奔 View 层;要调整热力图的情绪权重算法?直奔 ViewModel。职责被彻底划清。 - 为大型重构和多端复用铺平道路 :如果未来 MoodLite 需要开发一款完全脱离现有设计的折叠屏版本,或者利用原生卡片(Widget)展现统计数据,其底层模型
MoodRecord与强大的聚合引擎StatsViewModel一行代码都不需要改,可以直接被全新的 UI 壳套用。
总结
在现代应用开发中,框架提供的声明式特性是加速器,但良好的分层架构设计,才是防止赛车在高速行驶中解体的安全带。MoodLite 的这次解耦实践,正是这一工程哲学在鸿蒙原生生态中的一次完美演绎。