决策树与随机森林
本文适合谁:了解基本编程、想知道"为什么神经网络之外还要学树模型"的读者。树模型在表格数据上至今仍是首选,理解它也是理解集成学习这一核心思想的最佳切入点。
本文阅读时间:约12分钟
决策树是最直观的机器学习模型,随机森林是工业界的"瑞士军刀"。本篇从"线性模型为什么不够用"出发,一步步建立你对树模型的直觉理解。
一、为什么需要决策树:线性模型的局限
线性模型只能画直线边界
上一篇介绍的线性回归和逻辑回归,都有一个根本性的假设:数据可以用一条直线(或超平面)分开。在很多真实场景中,这个假设并不成立。
考虑一个例子:判断一笔交易是否是欺诈。欺诈交易的特征可能是:"金额在1000元到5000元之间,且发生在凌晨2点到4点之间,且是新注册用户"。这个规则是三个条件的组合,在特征空间中形成的是一个"矩形区域",而不是一条直线。逻辑回归无法学出这种边界,因为它的决策边界只能是直线。
更本质地说,线性模型假设"每个特征对预测结果的贡献是独立的"。但现实中,特征之间往往有交互:"年龄<25"单独看不能判断是否欺诈,但"年龄<25 且 消费金额>10000"组合在一起就是一个强烈的信号。线性模型很难捕捉这种特征交互。
决策树提供了一种完全不同的思路:不用直线划分,而是用一系列if-else规则。每个规则关注一个特征,通过逐层嵌套,就能描述任意复杂的区域边界。
二、决策树:像玩猜动物游戏一样做决策
猜动物游戏的类比
小时候玩过猜谜游戏吗?一个人心里想一种动物,另一个人通过问"是/否"问题来猜:
问:有四条腿吗?
答:有
问:体型很大吗?
答:不是(体型中等)
问:会游泳吗?
答:不会
问:主要是黑白两色吗?
答:不是
→ 猜测:猫每个问题都能把可能性缩小一半。问题提得越好,猜的速度越快。决策树做的事情完全相同:通过一系列"是/否"问题,逐步缩小范围,直到给出最终预测。
是否下雨?
├── 是 → 带伞
└── 否 → 气温是否超过30度?
├── 是 → 穿短袖
└── 否 → 穿外套
决策树示例:天气穿搭决策树
这就是决策树:一系列if-else判断,每个节点(树中的每个判断点)基于某个特征做分裂。
信息增益:选哪个特征分割最有效
决策树的关键问题是:每一步应该选哪个特征来做分割?
直觉是:好的问题能把数据分得更"纯"。如果一堆数据里既有猫又有狗,一个好问题(比如"有没有胡须")可以把猫和狗大部分分开,问完之后每个分支里基本都是同一类动物。而一个差问题(比如"体重是否超过3公斤")可能分完之后每个分支里还是乱的。
**基尼不纯度(Gini Impurity)**度量"混乱程度":
- 一个节点里只有一种类别(完全"纯"):Gini = 0,最好
- 一个节点里各类别各占一半(完全"混"):Gini = 0.5(二分类),最差
信息增益(Information Gain) = 分割前的不纯度 - 分割后的加权不纯度。增益越大,说明这个分割越有价值。
每次分裂,决策树会穷举所有特征和所有可能的分割点,选择信息增益最大的那个------这就是决策树的"贪心"策略:每一步都做当前最优的选择。
决策树代码实战
这段代码在做什么:加载鸢尾花数据集(150个样本,4个特征,3类),训练决策树,限制深度为3防止过拟合,然后可视化决策规则。
python
from sklearn.tree import DecisionTreeClassifier, export_text, plot_tree
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 训练决策树
# max_depth=3:限制树的深度,防止过拟合(深度越大,越容易记住训练数据细节)
# min_samples_split=5:节点至少要有5个样本才能继续分裂
dt = DecisionTreeClassifier(
max_depth=3,
min_samples_split=5,
random_state=42
)
dt.fit(X_train, y_train)
print(f"训练集准确率: {dt.score(X_train, y_train):.4f}")
print(f"测试集准确率: {dt.score(X_test, y_test):.4f}")
# 打印文本形式的决策规则(人类可读)
print("\n决策树规则:")
print(export_text(dt, feature_names=list(iris.feature_names)))你应该看到类似这样的输出:
训练集准确率: 0.9750
测试集准确率: 0.9667
决策树规则:
|--- petal length (cm) <= 2.45
| |--- class: 0 ← 花瓣长度<=2.45 → setosa(直接确定)
|--- petal length (cm) > 2.45
| |--- petal width (cm) <= 1.75
| | |--- petal length (cm) <= 4.95
| | | |--- class: 1 ← versicolor
| | |--- petal length (cm) > 4.95
| | | |--- class: 2 ← virginica
| |--- petal width (cm) > 1.75
| | |--- class: 2 ← virginica这就是决策树的魅力:规则完全可读,你能直接看懂模型在做什么判断。这在需要解释模型决策的场景(医疗、金融)非常有价值。
三、决策树的致命问题:过拟合
为什么决策树容易过拟合
决策树的贪心策略有一个严重问题:如果不加限制,它会一直生长,直到每个叶子节点里只有一个样本------这时候训练集准确率是100%,但对新数据几乎没有泛化能力。
直觉:一棵极深的树,等于把训练数据的每一个细节都"记住了",包括噪声和偶然规律。就像一个学生死记硬背了所有练习题的答案,但换一道题就不会了。
python
# 不限制深度的决策树会严重过拟合
dt_overfit = DecisionTreeClassifier(random_state=42) # 没有 max_depth 限制
dt_overfit.fit(X_train, y_train)
print(f"不限深度 - 训练集: {dt_overfit.score(X_train, y_train):.4f}")
print(f"不限深度 - 测试集: {dt_overfit.score(X_test, y_test):.4f}")
# 你会看到训练集接近1.0,测试集明显低 → 过拟合解决过拟合的方案:随机森林
四、随机森林:投票委员会
为什么多棵弱树比一棵强树更好
设想你要做一个重要决策,比如是否接受一份工作。你可以:
- 方案A:找一位"最聪明的"朋友问意见
- 方案B:问20个不同背景的朋友,然后综合大家的意见
方案B往往更可靠,即使这20个人单独来看都不如那位"最聪明的"朋友。原因在于:每个人的错误往往是不同的(一个人看重薪资,另一个人看重发展空间),当你综合多人意见时,个人的偏见会相互抵消,留下的是共同的判断。
这就是**集成学习(Ensemble Learning)**的核心思想,背后有严格的理论支撑------偏差-方差权衡(Bias-Variance Tradeoff):
单棵深决策树的问题是高方差------它对训练数据太敏感,换一批训练数据,学出的树可能完全不同。随机森林的解决思路:训练很多棵各不相同的树,让它们投票。每棵树都有高方差,但因为它们的错误不相关,投票之后错误会相互抵消,整体的方差大大降低。
这就是"多棵弱树比一棵强树更好"的原因:不是因为每棵树变强了,而是因为它们的错误相互抵消了。
样本1 → 树1 → 预测A
样本1 → 树2 → 预测B → 多数投票(2:1投票A获胜)→ 最终预测A
样本1 → 树3 → 预测A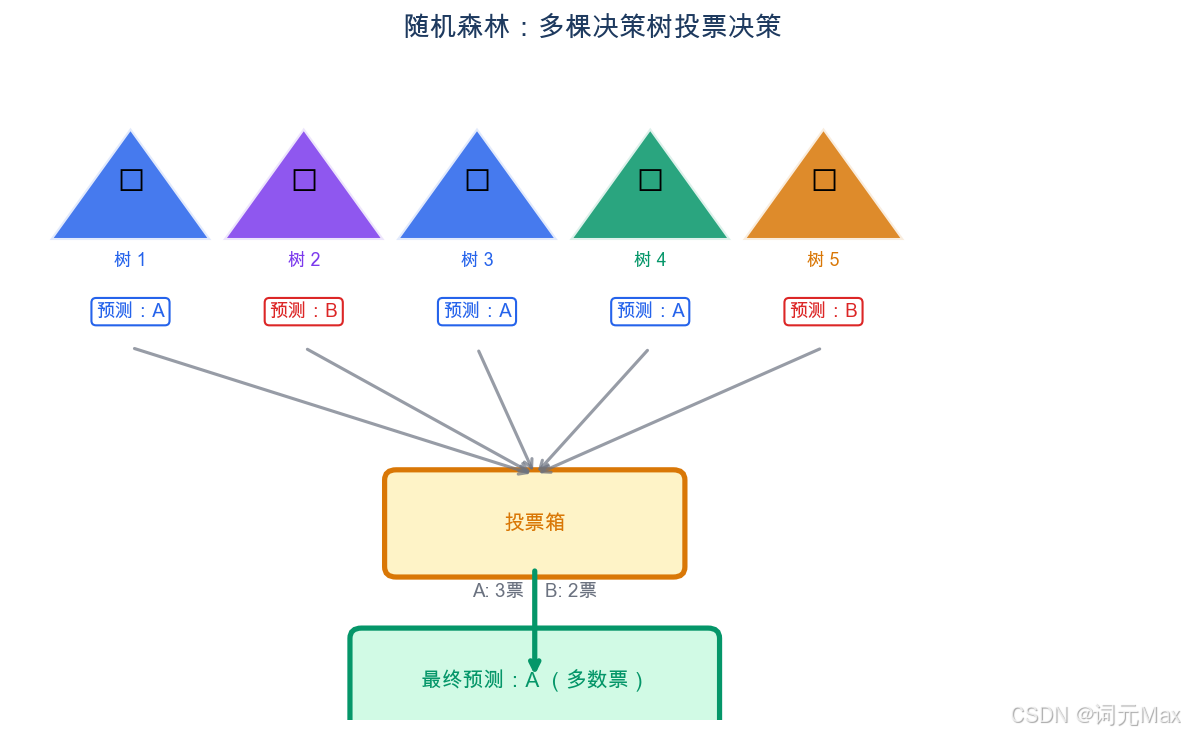
随机森林:多棵决策树投票决策
两个关键随机性:为什么要"随机"
随机森林的"随机"体现在两个地方,目的是让树与树之间更不一样(相关性更低),集成效果更好:
1. Bootstrap采样:每棵树用随机有放回抽样的样本训练。每棵树只看到约63%的数据,而且每棵树看到的数据集不同,保证了树之间的差异性。
2. 特征随机:每次分裂时,不考虑全部特征,而是随机选一个子集来考虑,进一步增加树的多样性。
随机森林代码实战
这段代码在做什么:在乳腺癌数据集上训练随机森林,展示准确率,并打印特征重要性(每个特征对预测的贡献有多大)。
python
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import pandas as pd
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 随机森林
# n_estimators=100:训练100棵树
# max_depth=10:每棵树最大深度10
# n_jobs=-1:并行训练(用全部CPU核心)
rf = RandomForestClassifier(
n_estimators=100,
max_depth=10,
min_samples_split=5,
n_jobs=-1,
random_state=42
)
rf.fit(X_train, y_train)
print(f"随机森林准确率: {rf.score(X_test, y_test):.4f}")
# 特征重要性:每个特征对预测贡献多大
feature_importance = pd.Series(
rf.feature_importances_,
index=data.feature_names
).sort_values(ascending=False)
print("\n最重要的5个特征:")
print(feature_importance.head(5))你应该看到类似这样的输出:
随机森林准确率: 0.9737
最重要的5个特征:
worst perimeter 0.1523
worst radius 0.1311
mean concave points 0.1124
worst concave points 0.0987
mean perimeter 0.0876准确率97.4%,比单棵决策树更高。特征重要性帮你理解:哪些特征对预测最有用,这对特征选择和业务理解都很有价值。
五、XGBoost:竞赛神器
梯度提升 vs 随机森林:两种不同的集成策略
随机森林是并行集成:所有树独立训练,没有先后关系,最后投票。优点是训练快(可以并行),缺点是每棵树都只是"凑数",没有针对性地改进。
梯度提升(Gradient Boosting)是串行集成:每棵树都专门针对前面所有树的错误来训练。类比:
第1棵树:做了一份预测,有些地方对有些地方错
第2棵树:专门学第1棵树预测错的那些案例
第3棵树:学前两棵树都预测错的案例
...
最终:把所有树的预测加起来(加权求和)这种"查漏补缺"的方式,理论上能用更少的树达到更好的效果。**残差(Residual)**是梯度提升的核心概念:当前模型的预测值和真实值之间的差距,每棵新树学的就是"上一轮的残差"。
XGBoost(极端梯度提升,eXtreme Gradient Boosting)是这类算法的最佳实现之一,Kaggle竞赛中最常用的算法。
python
# pip install xgboost
import xgboost as xgb
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
xgb_model = xgb.XGBClassifier(
n_estimators=100,
max_depth=6,
learning_rate=0.1, # 每棵树的贡献权重,越小越保守
subsample=0.8, # 每棵树随机使用80%的样本
colsample_bytree=0.8, # 每棵树随机使用80%的特征
random_state=42,
eval_metric='logloss'
)
xgb_model.fit(X_train, y_train)
print(f"XGBoost准确率: {xgb_model.score(X_test, y_test):.4f}")随机森林 vs XGBoost:如何选择
| 对比 | 随机森林 | XGBoost |
|---|---|---|
| 训练方式 | 并行(树之间独立) | 串行(每棵树修正前一棵的错误) |
| 训练速度 | 快 | 较慢,但有优化 |
| 过拟合风险 | 不容易过拟合 | 需要调参控制 |
| 最终效果 | 很好 | 通常更好 |
| 调参难度 | 较简单 | 较复杂 |
| 选择建议 | 快速验证可行性 | 追求最佳效果 |
实践中,先用随机森林快速验证方案可行性,再用XGBoost追求最高精度。
六、实战:信用卡欺诈检测
这个场景完美展示了随机森林的优势:数据不平衡(欺诈比例极低)、特征之间有交互关系、需要一定的可解释性。
这段代码在做什么:生成模拟的信用卡交易数据(99%正常,1%欺诈),用随机森林训练,观察它在极度不平衡数据下的表现。
python
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
np.random.seed(42)
n_samples = 10000
n_fraud = 100 # 1%欺诈率(类别不平衡问题)
# 正常交易:5个特征,来自标准正态分布
normal = np.random.randn(n_samples - n_fraud, 5)
normal_labels = np.zeros(n_samples - n_fraud)
# 欺诈交易:特征分布有明显偏移(欺诈行为模式不同)
fraud = np.random.randn(n_fraud, 5) + [2, -2, 3, -1, 2]
fraud_labels = np.ones(n_fraud)
X = np.vstack([normal, fraud])
y = np.concatenate([normal_labels, fraud_labels])
# 随机打乱顺序
idx = np.random.permutation(len(X))
X, y = X[idx], y[idx]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42,
stratify=y # 保证训练/测试集中欺诈比例一致
)
# class_weight='balanced':自动给少数类(欺诈)更高权重
# 如果不设置,模型可能会完全忽略欺诈,只预测"正常",准确率99%但没意义
rf = RandomForestClassifier(
n_estimators=100,
class_weight='balanced',
random_state=42
)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
print(classification_report(y_test, y_pred, target_names=['正常', '欺诈']))你应该看到 欺诈检测的召回率明显高于不加class_weight的版本,说明平衡类权重对不平衡数据集很重要。
小结
| 模型 | 核心思想 | 适用场景 | 关键参数 |
|---|---|---|---|
| 决策树 | if-else规则树 | 需要可解释性 | max_depth, min_samples_split |
| 随机森林 | 多棵树投票 | 通用,稳定,快速 | n_estimators, max_depth |
| XGBoost | 串行补短板 | 追求最佳效果 | n_estimators, learning_rate, max_depth |
决策树解决了线性模型"只能画直线边界"的问题。随机森林通过"多树投票"解决了决策树容易过拟合的问题。XGBoost通过"串行补短板"在大多数任务上进一步提升了效果。
这三个算法(以及XGBoost的变体LightGBM)至今仍然是表格数据任务的首选,在很多实际业务中的效果甚至超过神经网络。
下一篇,我们学模型评估------怎么知道模型是否真的好?这是一个被很多初学者忽视但极其重要的话题。