一、docker 告警
1.1 告警机制与 Alertmanager 核心功能
1.1.1 告警逻辑与触发条件
布尔值判断机制:告警规则基于PromQL 表达式 (如 `up == 0` 或 `cpu_usage > 80`)进行布尔值判断。当表达式返回 `true` 时触发告警,`false` 则不告警。
组件职责分离:Prometheus Server 负责计算和判断告警条件,Alertmanager 负责处理告警通知的发送。
1.1.2 Alertmanager 高级特性
分组与去重 (Grouping & Deduplication):为避免级联告警淹没核心问题,Alertmanager 会将同一故障源(如上游 Nginx 宕机导致下游 30 个 Java 节点不可达)合并为单条通知。
抑制(Inhibition):当某个组件故障时,抑制依赖于该组件的其他服务的告警,避免产生大量冗余告警干扰。
静默(Silence):用于在计划内维护(如割接、升级)期间临时屏蔽告警,防止误报。
1.2 Prometheus 告警架构与规则配置
1.2.1 告警架构与状态流转
核心组件交互逻辑:数据流遵循 Exporter -> Prometheus -> Alertmanager -> 钉钉(DingTalk)的路径,其中 Alertmanager 负责告警通知的分发。
告警生命周期状态:告警规则存在三种状态,Inactive(正常)、Pending(等待就绪,如等待1分钟阈值)以及 Firing(异常触发)。
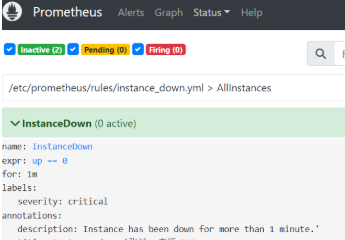
1.2.2 告警规则文件编写
布尔值表达式触发机制:规则基于 PromQL 表达式(如 `up == 0`)进行判断,结果为 true 时触发告警,并支持设置持续时间(如 `for 1m`)。
自定义标签与消息模板:支持在规则中定义独立的标签(Labels)用于分类,并通过 Annotations 字段定义告警消息的主题(Summary)和详情(Description),支持变量引用(如 `{{ $value }}`)。
1.3 钉钉集成与接口原理
1.3.1 钉钉机器人配置
安全设置与密钥获取:在钉钉群添加自定义机器人时,必须选择"加签"安全设置,并记录生成的 Webhook URL 和 Secret 密钥,用于后续鉴权。
接口标准对齐:强调了接口(Interface)的本质是标准化的访问入口(URL),双方必须遵循一致的协议标准(如 HTTPS)才能实现功能调用。
1.3.2 组件配置文件修改
DingTalk 插件配置:修改 `configure.yaml` 文件,填入 Webhook URL 和 Secret,支持配置多个群组接收告警。
Alertmanager 路由配置:修改 `alertmanager.yml` 文件,定义接收者(Receivers)为 Webhook,并将 URL 指向 DingTalk 插件监听的端口(如 8060)。
1.4 全链路测试与验证
1.4.1 服务启动与配置检查
服务启动顺序:需依次启动 DingTalk 插件、Alertmanager 和 Prometheus ,确保组件间网络可达。
配置路径校验:重点排查了 Prometheus 配置文件中 **`rule_files`**路径的正确性,避免因路径错误导致规则文件无法加载。
1.4.2 故障注入与告警触发
模拟故障场景:手动停止 Node Exporter 服务,使 `up` 指标变为 0,触发告警条件。
状态流转观察:在 Prometheus UI 中观察告警状态从 Inactive 变为 Pending,最终变为 Firing。
消息接收确认:最终在钉钉群中成功接收到由机器人发送的告警消息,验证了全链路功能正常。
1.5 钉钉告警链路配置逻辑
1.5.1 核心组件与职责划分
组件架构:系统由Prometheus、Alertmanager 和 DingTalk 三个核心组件构成。
职责分工:Prometheus 负责制定告警规则,Alertmanager 负责发送告警,DingTalk 负责具体的 API 接口对接。
1.5.2 端口与网络连接
端口映射:Prometheus 通过随机端口连接 Alertmanager 的 9093 端口,Alertmanager 连接 DingTalk 的 8060 端口。
连接验证:建议使用 `netstat -atp` 命令检查 Alertmanager 的连接状态,以确保组件间通信正常。
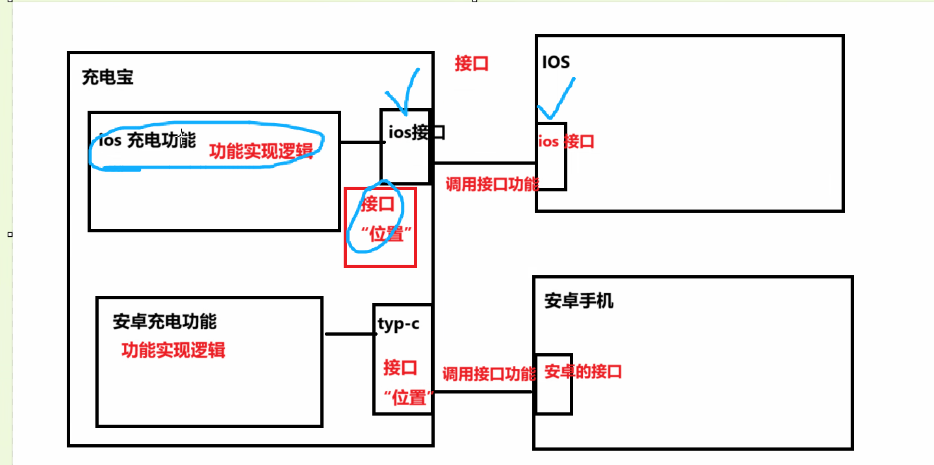
1.5.3 配置文件对接逻辑
Prometheus 配置:需在 `prometheus.yml` 中开启与 Alertmanager 的连接,并通过 `rule_files` 指向告警规则文件路径。
Alertmanager 配置:在 `alertmanager.yml` 中定义告警路由,指定接收告警的 Webhook URL(即钉钉群机器人地址)。
DingTalk配置:在 `config.yml` 中配置 Webhook 地址及加签密钥,确保消息能正确发送至指定钉钉群。
二、PromQL 语句编写与函数应用
2.1 CPU 使用率计算逻辑
指标获取:利用 `node_cpu_seconds_total{mode="idle"}` 获取 CPU 空闲时间,通过 `1m` 时间范围选择器获取过去 1 分钟的数据。
速率计算:使用 `irate` 函数计算时间序列的瞬时增长率,将计数器类型数据转换为百分比形式的空闲率。
聚合运算:使用 `avg` 函数计算所有 CPU 核心的平均空闲率,再通过 `by (instance)` 按节点进行分组,实现按节点维度的独立运算。
最终转换:通过 `100 - avg(...)` 的运算逻辑,将空闲率转换为 CPU 使用率(压力值)。
2.2 常用函数汇总
聚合函数:重点掌握 `sum`(求和)、`avg`(平均值)、`count`(计数)、`max`(最大值)、`min`(最小值)。
排序函数:`topk` 用于获取排名前 N 的样本数据,常用于排行榜或异常排查。
速率函数:`rate` 和 `irate` 用于计算时间序列的增长率,其中 `irate` 适用于快速变化的计数器。
2.3 监控指标体系与面试应答
2.3.1 SRE 四大黄金指标
延迟(Latency) :请求发出到响应的时间,如 Nginx 的请求处理耗时。
流量(Traffic): 系统接收的请求量,通常以 QPS(每秒请求数)或 TPS(每秒事务数)衡量。
错误(Errors): 请求处理失败的比率,如 HTTP 5xx 状态码的比例。
**饱和度(Saturation):**系统资源的使用程度,如 CPU、内存、磁盘 IO 的利用率。
2.3.2 其他关键监控维度
系统资源:文件描述符数量、Socket 连接数、僵尸/孤儿进程数量。
网络与磁盘:网络平均延迟、磁盘饱和度。
三、Prometheus 监控体系核心指标与实战
3.1 Prometheus监控的三大维度及四种核心指标类型,明确了业务监控的侧重点:
3.1.1 监控维度分层
系统与服务层监控:涵盖服务存活状态、容器运行状态、CPU/内存使用率等基础指标,确保底层环境稳定。
中间件与数据库监控:重点监控MySQL慢查询日志数量、平均查询延迟、线程队列等待数量及连接数等关键性能指标。
业务层与API监控:关注API接口请求失败数量、HTTP状态码分布、请求延迟(P99/P95)以及业务特定指标(如网盘业务的平均下载速率)。
3.1.2 指标类型详解
Counter(计数器):适用于单调递增的指标,如请求总数、错误数量,主要用于计算速率。
Gauge(仪表盘):适用于可增可减的瞬时值,如内存使用率、CPU负载、队列长度。
Histogram(直方图):用于分析数据分布,统计样本值分布情况,常用于网络请求延迟分析。
Summary(摘要):直接存储分位数数据(如P99、P95),适用于响应时间等指标的百分比统计。
3.2 Prometheus 架构与运维实战
3.2.1 架构选型与扩展
单机与集群方案:单机Prometheus建议监控节点数控制在200台左右;超过此规模需采用联邦集群架构,通过分片采集解决性能瓶颈。
存储方案演进:在小规模场景下使用Prometheus自带TSDB即可;当数据量巨大时,建议后端存储迁移至OpenTSDB。
3.2.2 日常运维工作流
标签治理与文档整理:强调通过标签(Label)区分不同业务和环境(如dev/prod),避免告警误报,需整理资源文档并推动开发规范标签。
可视化与告警闭环:负责在Grafana中新增业务指标图表,并配置Alertmanager进行告警路由分发,确保告警信息准确送达。
3.3 Docker 与自动化部署规划
3.3.1 技术栈演进
容器编排进阶:进入Kubernetes(K8s)核心,作为容器编排。
操作系统升级:为适配K8s环境,改用Rocky Linux 9.7(内核5.x版本)。
3.3.2 自动化部署要求
Ansible 批量管理:学员需掌握Ansible工具,实现一次性批量部署三个虚拟机内的Docker服务。
脚本编写规范:强调在编写部署脚本时需注重可读性与可维护性,要求学员具备通过AI辅助生成脚本并自行验证的能力。
总结
bash
#dockerfile 举例
Dockerfile
DROM centos:7
ADD nginx-vts-exporter-0.10.3.linux-amd64.tar.gz /opt
COPY nginx.conf /etc/nginx/
COPY start.sh "/"
WORKDIR nginx-1.18.0/
RUN ./configure --prefix=/usr/local/nginx \
--user=nginx \
--group=nginx \
--with-http_stub_status_module \
--add-module=/usr/local/nginx-module-vts && make && make install
expose 80
expose 9913
cmd ["/start.sh"]
#/bin/bash
nohup /opt/nginx-vts-exporter-0.10.3/nginx-vts-exporter &
nohup /usr/local/nginx/sbin/nginx -g daemon off &
阿里云 创建容器集群ack托管(k8s)进行管理的时候,会默认添加监控arms(prometheus )和日志sls(elk)的组件
docker prometheus elk
grafana 看板---》 prometheus 数据库9090
告警通知:
1、判断是否需要告警:
是prometheus自己的功能,prometheus可以通过写promql语句+条件判断的表达式来判断返回值是否为true,以此
来判断是否需要告警,例如:(布尔值判断 返回值"0"或"非0")
up == 0 #判断的是当返回值为true的时候,触发告警,如果是false 则不告警
100 -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)* 100 > 80
(PromQL语句,描述的内容是cpu的使用率)
2、告警信息通知给管理人员
altermanager 组件来完成的
exporter 采集数据,暴露数据 --》prometheus pull 数据 --》prometheus 告警逻辑判断
---》alertmanager 告警通知 ---》dingtalk插件 钉钉
告警规则有3个状态
SEC3f6ce52d5a77fed654abfae68b1558e55fee8dfd53d41f184cae9ef7fe1a9cd3
https://oapi.dingtalk.com/robot/send?access_token=2b49d94ea9e19d04a92b4af361dff27473e27df5aba9f0db347e14689120269a
webhook 接口地址
钉钉告警
钉钉告警
服务对接:alertmanger(发送告警) dingtalk(负责具体的api对接) prometheus(告警规则的制定))
端口的对接:prometheus 9090 --》alertmanager 9093 --》dingstalk 8060
配置文件对接:
prometheus.yml (开启alertmanger 组件的连接、指向rules告警规则文件的路径
alertmanager.yml--》告警路由 指向dingtalk的webhook位置,(钉钉群中机器人的webhhook位置)
dingtalk: 在钉钉群创建机器人,选择加签的验证方式、复制webhook 的api位置
同步到config.yml文件的webhook1中
docker 把alertmanger 和dingtalk 做出来
100 -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)* 100
运算cpu的压力值
1 - cpu空闲值 / 总计
node_cpu_seconds_total{mode='idle'}[1m] 指标:cpu统计的过去1min内空闲值的样本数据(4次)
#irate 函数 (速率运算)
irate(node_cpu_seconds_total{mode='idle'}[1m]) 所有节点所有cpu的空闲率
{cpu="0", instance="192.168.110.129:9100", job="nodes", mode="idle"}
0.9945340621249336
{cpu="0", instance="192.168.110.130:9100", job="nodes", mode="idle"}
0.9980000000000776
{cpu="0", instance="192.168.110.131:9100", job="nodes", mode="idle"}
0.9994665955461796
{cpu="1", instance="192.168.110.129:9100", job="nodes", mode="idle"}
0.992534328756127
#avg 平均数运算(cpu空闲率)
avg(irate(node_cpu_seconds_total{mode='idle'}[1m]))
#所有节点的所有cpu 平均的压力值
100 - avg(irate(node_cpu_seconds_total{mode='idle'}[1m]))*100
#分组,以节点为单位进行分组 (by (instance))
#得到 每个节点1min前的平均压力值
100 - avg(irate(node_cpu_seconds_total{mode='idle'}[1m]))by (instance) *100
{instance="192.168.110.129:9100"} 0.9166666666654493
{instance="192.168.110.130:9100"} 0.14999999999417923
{instance="192.168.110.131:9100"} 0.3666666666686069
1、promql语句怎么写(你得说出来)
100 -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)* 100
话术:由内向外介绍
比如cpu使用率promql
① 总体使用1-cpu使用率 方式得出需要样本数据
② 使用node_cpu_seonds_total cpu空闲值的指标,再使用[1m]表示时间区间
③ 然后先使用irate做速率运算、再做avg 聚合运算得出平均空闲率
④ 再用by instance 进行分组
⑤ 最后 1 - 数据 就等于压力值
2、promql中你用过哪些聚合函数
sum():
min()
max()
avg()
count()
topk() 排序 排名
irate() 速率运算
3、prometheus 监控哪些具体的指标
① 系统:
延迟
流量 :每秒请求数(QPS)、每秒事务数(TPS)
错误: 状态码 4xx/5xx 系列
饱和度:饱和度是指系统资源的使用情况。包括但不限于CPU、内存、磁盘 I/O、网络带宽等。
fd 文件描述符的使用率
socket 连接数量
文件打开数
僵尸、孤儿进程数量
网络平均延迟
服务:
服务的存活(健康状态)
容器的运行状态
服务的一些个性化监控,比如mysql:
慢查询日志数量
平均查询延迟
队列的长度
线程任务平均处理时长
socket 连接的平均延迟
http/https 状态码
业务:
api 接口请求失败的数量
api 请求延迟
线索平均处理时长,最大处理时长
和实际业务
PromQL 的指标类型
① Counter(计数器):单调递增的计数器,适用于请求数、错误数等。
- 常用函数:`rate()`、`irate()`、`increase()`
② Gauge:可增可减的仪表盘,适用于内存使用率、CPU 使用率等。
- 常用函数:`delta()`、`predict_linear()`
③ Histogram:累积直方图,用于分析数据分布。
- 常用函数:`histogram_quantile()`
④ Summary:直接存储百分位数的摘要,适用于延迟时间、响应大小等。