引言
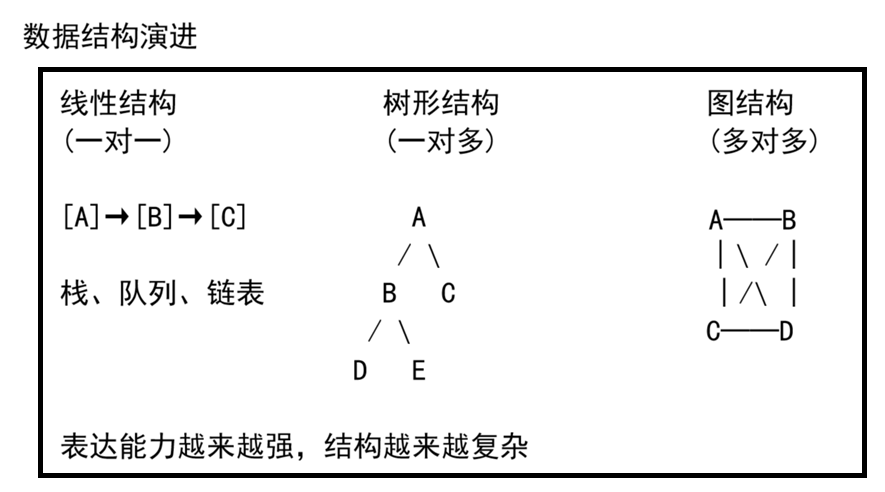
在前面的数据结构系列中,我们学习了线性结构(数组、链表、栈、队列)和树形结构(二叉树、B 树、哈希表)。今天要讲的图,是比树更复杂、表达能力更强的非线性结构。
如果说树表达的是"一对多"的层级关系(一个文件目录、一个公司组织架构),那图表达的就是**"多对多"的网状关系**------社交网络中的好友关系、地图上的城市道路、互联网中的路由器连接、编译器中的模块依赖......这些全都是图。
图论是数据结构与算法中内容最丰富的领域之一,也是面试中的常客。本文作为图系列的第一篇,将详细讲解图的基本概念、两种存储方式和两种核心遍历算法。
第一部分:图的基本概念
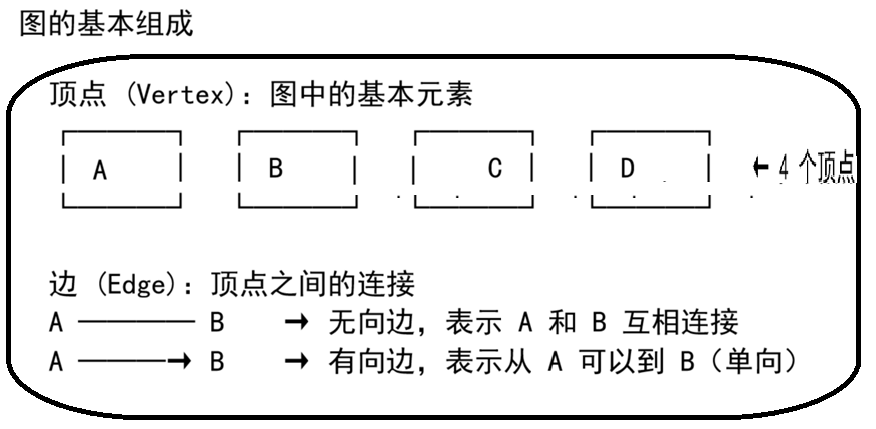
一、图的定义
图(Graph)是由顶点集合和边集合组成的数据结构。形式化地定义为:

通俗地说:顶点 就是图中的"点"(人、城市、任务),边就是点之间的"连线"(好友关系、道路、依赖)。
二、图的分类
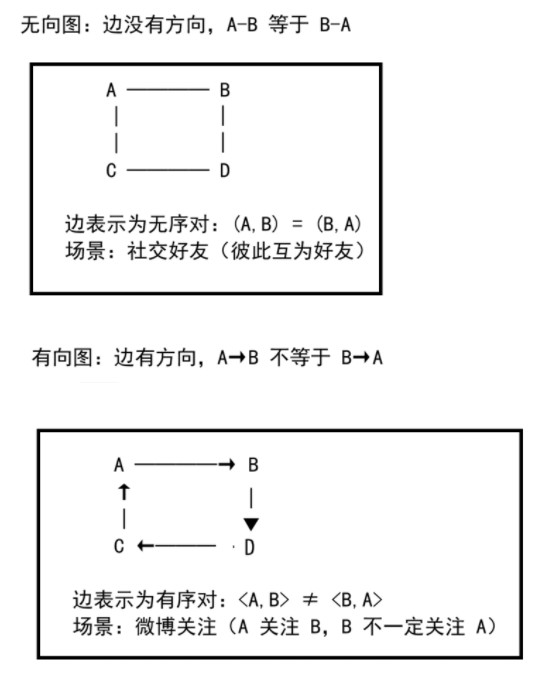
1. 无向图 vs 有向图
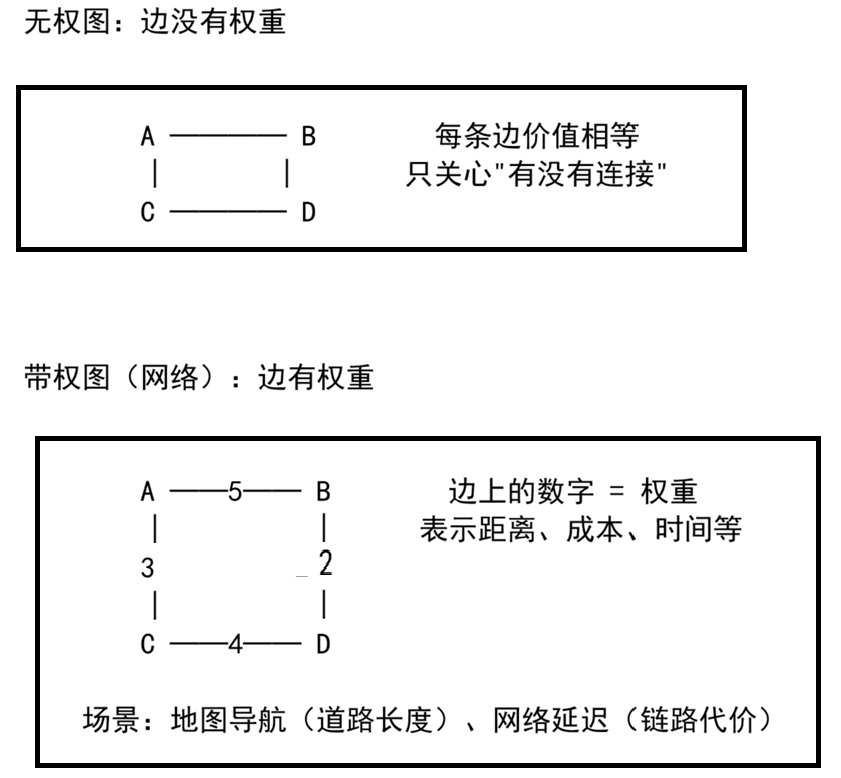
2. 带权图 vs 无权图
3. 完全图
完全图:图中每一对顶点之间都有边。
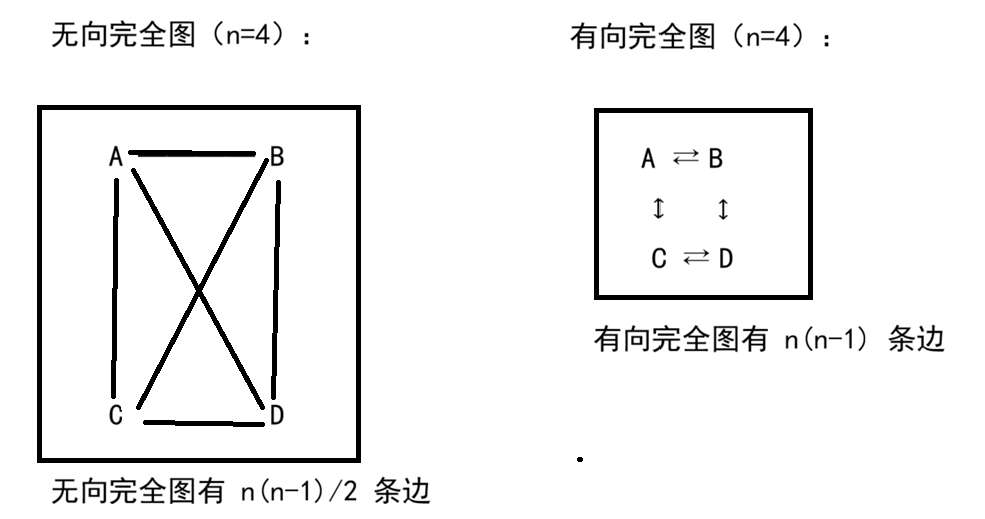
| 图的类型 | 最多边数 |
|---|---|
| 无向完全图 | n(n-1)/2 |
| 有向完全图 | n(n-1) |
4. 稀疏图 vs 稠密图
| 类型 | 定义 | 判断标准 |
|---|---|---|
| 稀疏图 | 边数远小于 n² | ` |
| 稠密图 | 边数接近 n² | ` |
为什么区分稀疏和稠密? 因为它们适合不同的存储方式------稀疏图用邻接表省空间,稠密图用邻接矩阵更快。
三、图的核心术语
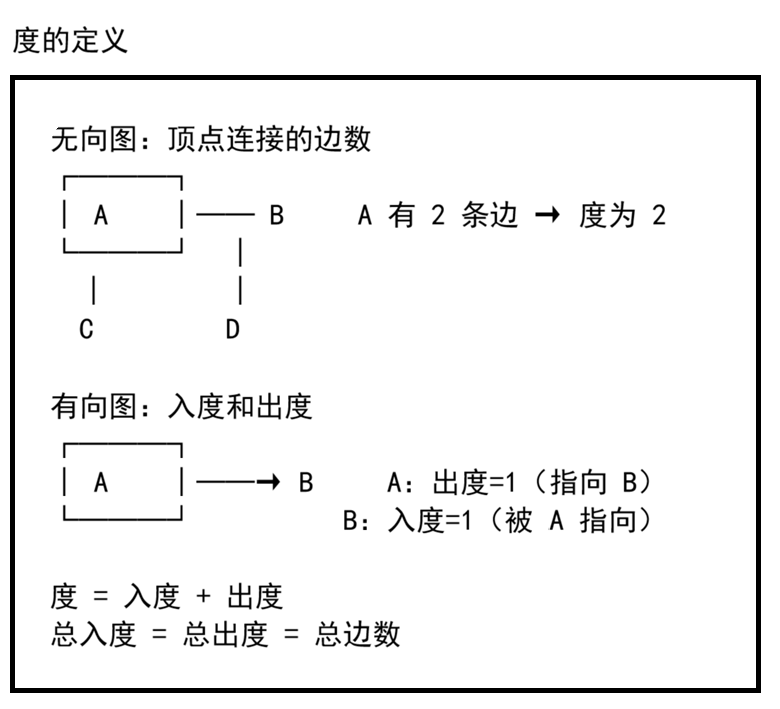
1. 度(Degree)
2. 路径与回路

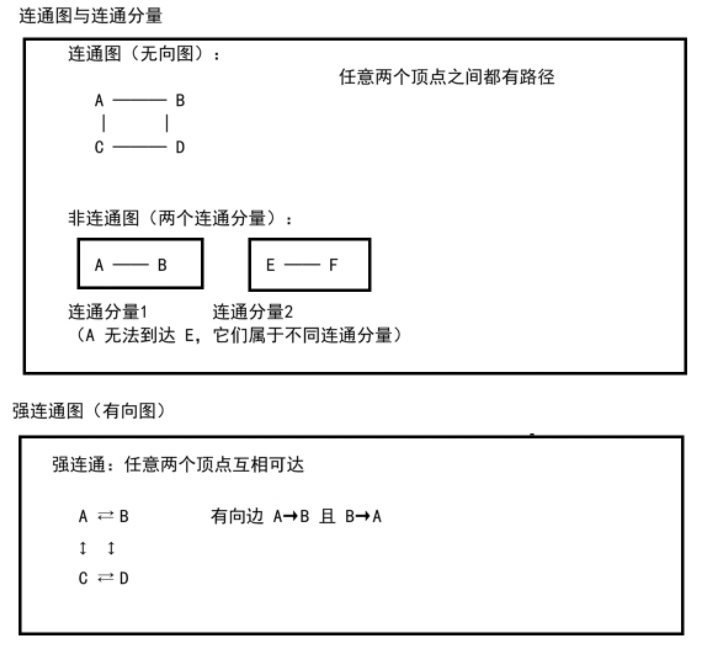
3. 连通性
第二部分:图的存储方式
一、邻接矩阵
用一个 n×n 的二维数组存储顶点之间的连接关系

代码实现:
cpp
#define MAX_V 100
typedef struct {
int vertexNum; // 顶点数量
int edgeNum; // 边数量
int matrix[MAX_V][MAX_V]; // 邻接矩阵
} GraphMatrix;
// 初始化
void initGraph(GraphMatrix* g, int n) {
g->vertexNum = n;
g->edgeNum = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
g->matrix[i][j] = 0; // 无边
}
}
}
// 添加边(无向图)
void addEdge(GraphMatrix* g, int u, int v) {
g->matrix[u][v] = 1;
g->matrix[v][u] = 1; // 无向图对称
g->edgeNum++;
}
// 添加带权边(无向图)
void addWeightedEdge(GraphMatrix* g, int u, int v, int w) {
g->matrix[u][v] = w;
g->matrix[v][u] = w;
g->edgeNum++;
}邻接矩阵的复杂度:
| 操作 | 复杂度 |
|---|---|
| 判断 u、v 是否有边 | O(1) |
| 获取某个顶点的所有邻居 | O(n) |
| 空间 | O(n²) |
| 添加/删除边 | O(1) |
适用场景:稠密图(边多)、需要快速判断两点是否相邻。
二、邻接表
每个顶点维护一个链表,存储它连接的所有邻居。

代码实现:
cpp
#include <stdio.h>
#include <stdlib.h>
#define MAX_V 100
// 邻接表的边节点
typedef struct EdgeNode {
int adjVertex; // 邻接顶点下标
int weight; // 权重(带权图用)
struct EdgeNode* next; // 下一条边
} EdgeNode;
// 邻接表
typedef struct {
EdgeNode* adjList[MAX_V]; // 每个顶点的边链表
int vertexNum;
int edgeNum;
} GraphList;
// 初始化
void initGraphList(GraphList* g, int n) {
g->vertexNum = n;
g->edgeNum = 0;
for (int i = 0; i < n; i++) {
g->adjList[i] = NULL;
}
}
// 添加边(无向图,头插法)
void addListEdge(GraphList* g, int u, int v, int w) {
// u → v
EdgeNode* node = (EdgeNode*)malloc(sizeof(EdgeNode));
node->adjVertex = v;
node->weight = w;
node->next = g->adjList[u];
g->adjList[u] = node;
// v → u(无向图对称)
node = (EdgeNode*)malloc(sizeof(EdgeNode));
node->adjVertex = u;
node->weight = w;
node->next = g->adjList[v];
g->adjList[v] = node;
g->edgeNum++;
}邻接表的复杂度:
| 操作 | 复杂度 |
|---|---|
| 判断 u、v 是否有边 | O(degree(u)) |
| 获取某个顶点的所有邻居 | O(degree(u)) |
| 空间 | O(n + e) |
| 添加/删除边 | O(1) |
三、邻接矩阵 vs 邻接表
| 对比项 | 邻接矩阵 | 邻接表 |
|---|---|---|
| 空间 | O(n²) | O(n + e) |
| 判断 u、v 是否有边 | O(1) | O(degree(u)) |
| 获取所有邻居 | O(n) | O(degree(u)) |
| 添加边 | O(1) | O(1) |
| 适合场景 | 稠密图 | 稀疏图 |
选择原则:边数少用邻接表(省空间),边数多用邻接矩阵(快)。实际开发中邻接表更常用,因为大多数现实图都是稀疏的。
第三部分:深度优先搜索(DFS)
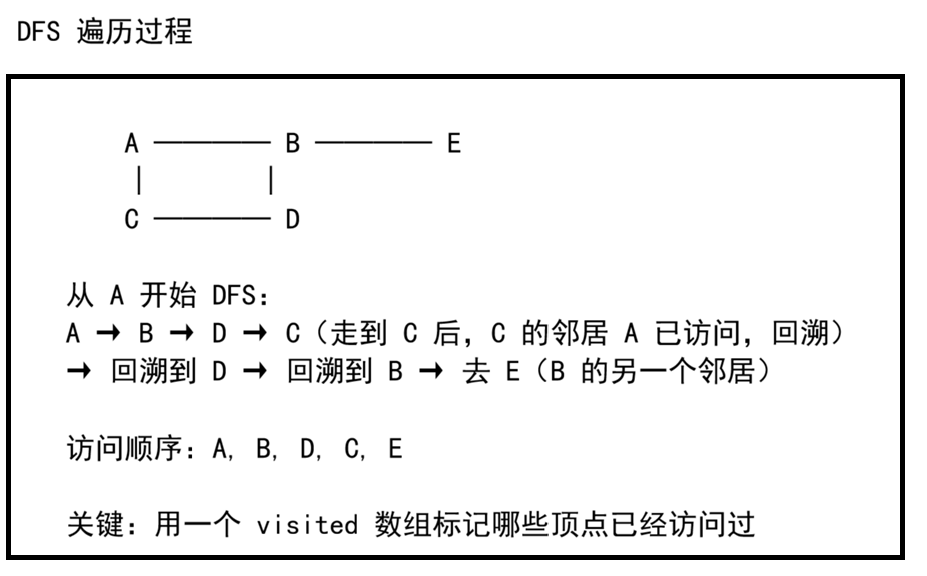
一、DFS 的核心思想
DFS = 一条路走到黑,走不通再回头。从起点开始,沿着一条路径一直走到最深处,然后回溯,换一条路继续走。
二、DFS 代码实现(邻接矩阵)
cpp
int visited[MAX_V];
// DFS 递归实现
void DFS_Matrix(GraphMatrix* g, int v) {
visited[v] = 1;
printf("%c ", 'A' + v); // 访问顶点 v
// 遍历 v 的所有邻居
for (int i = 0; i < g->vertexNum; i++) {
if (g->matrix[v][i] != 0 && !visited[i]) {
DFS_Matrix(g, i); // 递归访问未访问的邻居
}
}
}
// 遍历整个图(处理不连通的情况)
void DFS_Traverse(GraphMatrix* g) {
// 初始化访问标记
for (int i = 0; i < g->vertexNum; i++) {
visited[i] = 0;
}
// 对每个未访问的顶点调用 DFS
// (如果图不连通,需要多次调用)
for (int i = 0; i < g->vertexNum; i++) {
if (!visited[i]) {
DFS_Matrix(g, i);
printf("(连通分量结束)\n");
}
}
}三、DFS 代码实现(邻接表)
cpp
void DFS_List(GraphList* g, int v) {
visited[v] = 1;
printf("%c ", 'A' + v);
// 遍历 v 的边链表
EdgeNode* p = g->adjList[v];
while (p != NULL) {
if (!visited[p->adjVertex]) {
DFS_List(g, p->adjVertex);
}
p = p->next;
}
}四、DFS 的非递归实现(用栈模拟递归)
cpp
#include <stdbool.h>
void DFS_NonRecursive(GraphMatrix* g, int start) {
int stack[MAX_V];
int top = -1;
bool visited[MAX_V] = {false};
stack[++top] = start;
while (top != -1) {
int v = stack[top--];
if (!visited[v]) {
visited[v] = true;
printf("%c ", 'A' + v);
// 将所有未访问的邻居入栈
// (反序入栈以保证和递归顺序一致)
for (int i = g->vertexNum - 1; i >= 0; i--) {
if (g->matrix[v][i] != 0 && !visited[i]) {
stack[++top] = i;
}
}
}
}
}递归 vs 非递归:
| 实现 | 优点 | 缺点 |
|---|---|---|
| 递归 | 代码简洁 | 深度过大可能栈溢出 |
| 非递归(栈) | 不受递归深度限制 | 代码稍复杂 |
第四部分:广度优先搜索(BFS)
一、BFS 的核心思想
BFS = 层层扩散,先近后远。从起点开始,先访问所有邻居,再访问邻居的邻居......逐层向外扩展。
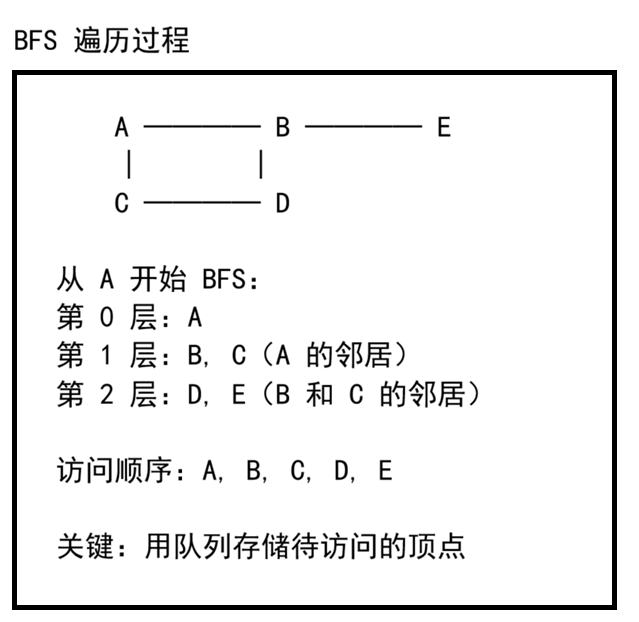
二、BFS 代码实现(邻接矩阵)
cpp
void BFS_Matrix(GraphMatrix* g, int start) {
int queue[MAX_V];
int front = 0, rear = 0;
int visited[MAX_V] = {0};
// 起点入队
queue[rear++] = start;
visited[start] = 1;
while (front < rear) {
int v = queue[front++]; // 出队
printf("%c ", 'A' + v);
// 将所有未访问的邻居入队
for (int i = 0; i < g->vertexNum; i++) {
if (g->matrix[v][i] != 0 && !visited[i]) {
queue[rear++] = i;
visited[i] = 1;
}
}
}
}三、BFS 代码实现(邻接表)
cpp
void BFS_List(GraphList* g, int start) {
int queue[MAX_V];
int front = 0, rear = 0;
int visited[MAX_V] = {0};
queue[rear++] = start;
visited[start] = 1;
while (front < rear) {
int v = queue[front++];
printf("%c ", 'A' + v);
EdgeNode* p = g->adjList[v];
while (p != NULL) {
if (!visited[p->adjVertex]) {
queue[rear++] = p->adjVertex;
visited[p->adjVertex] = 1;
}
p = p->next;
}
}
}第五部分:DFS vs BFS
| 对比项 | DFS | BFS |
|---|---|---|
| 数据结构 | 栈(递归/显式栈) | 队列 |
| 遍历顺序 | 纵向深入 | 横向扩散 |
| 找到的路径 | 不一定最短 | 一定最短(无权图) |
| 空间 | O(h),h 为深度 | O(w),w 为最大宽度 |
| 适用场景 | 路径存在性、连通分量、环检测 | 最短路径、层序遍历 |
| 实现 | 递归简单 | 队列简单 |
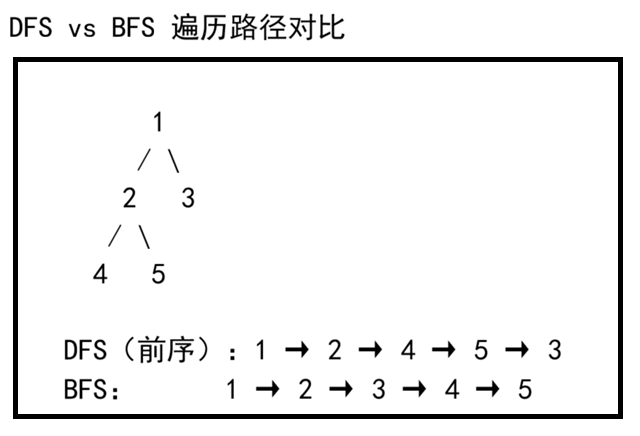
第六部分:完整测试代码
cpp
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
#define MAX_V 100
// ==================== 邻接矩阵 ====================
typedef struct {
int vertexNum;
int edgeNum;
int matrix[MAX_V][MAX_V];
} GraphMatrix;
void initMatrix(GraphMatrix* g, int n) {
g->vertexNum = n;
g->edgeNum = 0;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
g->matrix[i][j] = 0;
}
void addMatrixEdge(GraphMatrix* g, int u, int v) {
g->matrix[u][v] = 1;
g->matrix[v][u] = 1;
g->edgeNum++;
}
// ==================== 邻接表 ====================
typedef struct EdgeNode {
int adjVertex;
struct EdgeNode* next;
} EdgeNode;
typedef struct {
EdgeNode* adjList[MAX_V];
int vertexNum;
int edgeNum;
} GraphList;
void initList(GraphList* g, int n) {
g->vertexNum = n;
g->edgeNum = 0;
for (int i = 0; i < n; i++)
g->adjList[i] = NULL;
}
void addListEdge(GraphList* g, int u, int v) {
EdgeNode* node;
node = (EdgeNode*)malloc(sizeof(EdgeNode));
node->adjVertex = v;
node->next = g->adjList[u];
g->adjList[u] = node;
node = (EdgeNode*)malloc(sizeof(EdgeNode));
node->adjVertex = u;
node->next = g->adjList[v];
g->adjList[v] = node;
g->edgeNum++;
}
// ==================== DFS ====================
int visited[MAX_V];
void DFS_Matrix(GraphMatrix* g, int v) {
visited[v] = 1;
printf("%c ", 'A' + v);
for (int i = 0; i < g->vertexNum; i++)
if (g->matrix[v][i] && !visited[i])
DFS_Matrix(g, i);
}
void DFS_List(GraphList* g, int v) {
visited[v] = 1;
printf("%c ", 'A' + v);
for (EdgeNode* p = g->adjList[v]; p; p = p->next)
if (!visited[p->adjVertex])
DFS_List(g, p->adjVertex);
}
// ==================== BFS ====================
void BFS_Matrix(GraphMatrix* g, int start) {
int queue[MAX_V], front = 0, rear = 0;
int vis[MAX_V] = {0};
queue[rear++] = start;
vis[start] = 1;
while (front < rear) {
int v = queue[front++];
printf("%c ", 'A' + v);
for (int i = 0; i < g->vertexNum; i++)
if (g->matrix[v][i] && !vis[i]) {
queue[rear++] = i;
vis[i] = 1;
}
}
}
void BFS_List(GraphList* g, int start) {
int queue[MAX_V], front = 0, rear = 0;
int vis[MAX_V] = {0};
queue[rear++] = start;
vis[start] = 1;
while (front < rear) {
int v = queue[front++];
printf("%c ", 'A' + v);
for (EdgeNode* p = g->adjList[v]; p; p = p->next)
if (!vis[p->adjVertex]) {
queue[rear++] = p->adjVertex;
vis[p->adjVertex] = 1;
}
}
}
// ==================== 测试 ====================
int main() {
GraphMatrix gm;
initMatrix(&gm, 5);
addMatrixEdge(&gm, 0, 1); // A-B
addMatrixEdge(&gm, 0, 2); // A-C
addMatrixEdge(&gm, 1, 3); // B-D
addMatrixEdge(&gm, 2, 3); // C-D
addMatrixEdge(&gm, 1, 4); // B-E
GraphList gl;
initList(&gl, 5);
addListEdge(&gl, 0, 1);
addListEdge(&gl, 0, 2);
addListEdge(&gl, 1, 3);
addListEdge(&gl, 2, 3);
addListEdge(&gl, 1, 4);
printf("===== DFS(邻接矩阵)=====\n");
memset(visited, 0, sizeof(visited));
DFS_Matrix(&gm, 0);
printf("\n");
printf("===== DFS(邻接表)=====\n");
memset(visited, 0, sizeof(visited));
DFS_List(&gl, 0);
printf("\n");
printf("===== BFS(邻接矩阵)=====\n");
BFS_Matrix(&gm, 0);
printf("\n");
printf("===== BFS(邻接表)=====\n");
BFS_List(&gl, 0);
printf("\n");
return 0;
}运行结果:
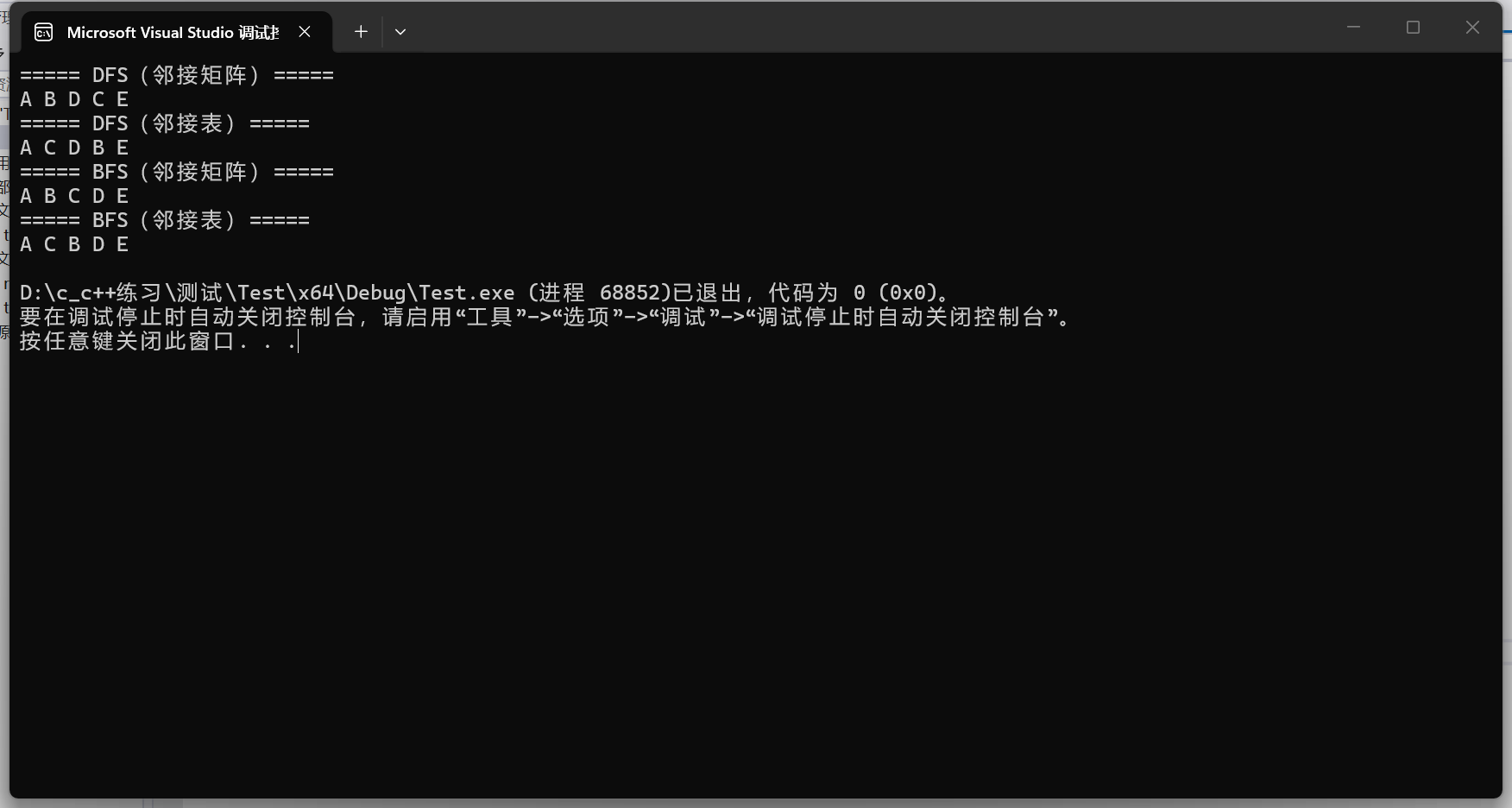
注意:DFS 的邻接矩阵和邻接表结果可能不同(因为遍历邻居的顺序不同),但这不影响正确性------两者都是合法的 DFS。
总结
一、核心概念速查
| 概念 | 含义 |
|---|---|
| 顶点 | 图中的节点 |
| 边 | 顶点之间的连接 |
| 有向图 | 边有方向 |
| 无向图 | 边无方向 |
| 带权图 | 边有权重 |
| 连通图 | 任意两点可达 |
| 度 | 顶点连接的边数 |
| 稀疏图 | 边数远小于 n² |
| 稠密图 | 边数接近 n² |
二、存储方式对比
| 方式 | 空间 | 判邻边 | 遍历邻居 | 适用 |
|---|---|---|---|---|
| 邻接矩阵 | O(n²) | O(1) | O(n) | 稠密图 |
| 邻接表 | O(n+e) | O(degree) | O(degree) | 稀疏图 |
三、DFS vs BFS
| 对比 | DFS | BFS |
|---|---|---|
| 结构 | 栈 | 队列 |
| 路径 | 不一定最短 | 最短 |
| 场景 | 连通性、环检测 | 最短路径、层级遍历 |
四、一句话记忆
图是顶点和边的集合,用邻接矩阵(稠密)或邻接表(稀疏)存储。DFS 用栈纵向深入,BFS 用队列横向扩散。BFS 能找到无权图的最短路径。